

Most data teams do not fail because they cannot collect data. They fail because raw data arrives messy, duplicated, and inconsistent, and there is no disciplined way to turn it into something analysts and models can trust. The medallion architecture is the pattern most modern data platforms use to solve exactly that problem, by moving data through three progressively cleaner layers: bronze, silver, and gold.
This guide explains the pattern the way a data engineer needs to understand it, how each layer behaves, how data physically moves between them, and where externally sourced web data enters the picture as a raw bronze input.
In this article:
- What the medallion architecture is and why Databricks popularized it
- What the bronze, silver, and gold layers each do, and who consumes them
- How data moves through the layers with table formats, ACID transactions, and change data capture
- Where external and web data enters the pattern as a bronze source
- Best practices, common pitfalls, and the use cases where the pattern pays off
What is the medallion architecture?
The medallion architecture is a design pattern for organizing data inside a lakehouse so that its structure and quality improve at each stage, as it flows from bronze to silver to gold. The name borrows the metaphor of medals: data enters as low-value raw bronze and is refined into more valuable silver, then gold. You will also see it called a multi-hop architecture, since every record takes several hops before it is fit for consumption.
The pattern was popularized by Databricks alongside its lakehouse paradigm and the Delta Lake table format, which was open sourced in 2019. A lakehouse combines the low storage cost of a data lake with the reliability features of a data warehouse, such as ACID transactions and schema enforcement. The medallion architecture is the organizing principle that gives that lakehouse a clear flow of trust. It is now a cross-platform convention: the same bronze, silver, and gold language appears in Databricks, Microsoft Fabric, and Snowflake documentation.
The core idea is simple. Instead of cleaning data in one opaque step, you keep a permanent raw copy, then refine it in stages where each stage has a clear contract. That separation is what makes the pattern so durable, and it is the foundation for everything below.
Why data teams adopt it
The medallion architecture earns its place because it solves several problems at once.
Incremental, inspectable data quality. Quality is improved in stages rather than in a single transformation that is hard to reason about. Each hop has a defined job, so when something looks wrong you know which layer to inspect.
Reprocessing from raw. Because the bronze layer is a permanent historical archive, you can rebuild silver and gold tables at any time without going back to the source system. If a transformation has a bug, or business logic changes, you replay from bronze instead of re-collecting data that may no longer be available.
Lineage and auditability. Bronze preserves the original payload, which gives you a forensic record. Compliance and audit teams can trace any number in a dashboard back to the exact raw record it came from.
Separation of concerns across consumers. Different layers serve different audiences. Data engineers and operations teams work at bronze and silver. Analysts and data scientists work at silver. Business analysts, executives, and applications consume gold.
Multi-consumer serving. A single clean silver entity can feed many gold tables, so finance, operations, and marketing can each build their own consumption-ready views from the same trusted source.
This is also why the pattern pairs naturally with an ELT mindset. You load raw data first, then transform it inside the platform, rather than transforming everything before it lands. If you want a refresher on the broader ingestion flow, the explainer on ETL pipelines and the overview of data pipeline architecture both map cleanly onto the medallion model.
The three layers in detail
The flow is linear in concept: raw data lands in bronze, is refined into silver, and is shaped for consumption in gold.
flowchart LR
S["External and web sources"] --> B["Bronze: raw, as-is, append-only"]
B --> SI["Silver: cleaned, conformed, deduplicated"]
SI --> G["Gold: aggregated, business-level"]
G --> C["BI, dashboards, ML, applications"]Data is progressively refined as it moves from bronze to silver to gold.
Bronze layer: raw and immutable
Bronze is the landing zone for everything arriving from external source systems. Its tables mirror the shape of the source as-is, with a few extra metadata columns recording details like the load timestamp and the process that wrote the row. The priorities here are speed of capture, a durable historical archive of the source, clean lineage, and the option to reprocess later without ever rereading the origin system.
Bronze has a few defining properties. It contains the raw state of the data in its original format. It is appended incrementally and grows over time. It serves as the single source of truth, preserving the fidelity of the data exactly as it arrived. It is intended for downstream processing rather than direct analyst access.
A key implementation detail: at bronze you generally do not enforce types. Databricks recommends storing most fields as string, VARIANT, or binary to protect against unexpected schema changes from upstream. In effect, bronze is schema-on-read. You capture first and interpret later, which is exactly what you want when the source schema is outside your control. Bronze sources can be any mix of streaming and batch inputs, including cloud object storage such as Amazon S3, Google Cloud Storage, and Azure Data Lake Storage, message buses such as Kafka and Kinesis, and federated systems.
Silver layer: cleaned and conformed
Silver is where bronze records get matched, merged, conformed, and cleaned, enough to give the business a single coherent view of its core entities, concepts, and transactions. Picture master customer records, deduplicated transactions, and cross-reference tables. By reconciling data from many sources into one consistent shape, silver becomes the layer that powers self-service analytics, ad-hoc reporting, advanced analytics, and machine learning.
The operations that typically happen here are concrete: schema enforcement, handling of null and missing values, deduplication, resolution of out-of-order and late-arriving records, data quality checks, schema evolution, type casting, and joins. This is also where you start real data modeling, often using more normalized, write-performant structures. Tracking data quality metrics at this stage is what separates a trustworthy silver layer from a glorified copy of bronze.
One firm best practice: do not write to silver directly from ingestion. If you skip bronze and write straight to silver, you introduce failures from schema changes and corrupt source records, and you lose the ability to replay. Silver should always include at least one validated, non-aggregated representation of each record, so detailed analysis is still possible without dropping down to raw bronze.
Gold layer: business-ready
Gold holds consumption-ready, project-specific data. The models here are more denormalized and tuned for fast reads with fewer joins, and this is where the final transformations and business rules land. It is the home of presentation-layer work: customer and inventory analytics, segmentation, sales reporting, and the like. In practice you will often find Kimball-style star schemas or Inmon-style data marts living in this layer.
Gold represents highly refined views that drive dashboards, machine learning, and applications. The data is often heavily aggregated and filtered to specific time periods or regions. Because a single business domain rarely fits one shape, many teams build multiple gold tables, for example separate views for finance, operations, and HR, all derived from the same silver foundation.
The table below summarizes how the three layers differ.
| Layer | Data state | Typical operations | Primary consumers |
|---|---|---|---|
| Bronze | Raw, as-is, append-only | Ingest, capture metadata, preserve history | Data engineers, audit and compliance teams |
| Silver | Cleaned, conformed, deduplicated | Validation, dedup, schema enforcement, joins | Data engineers, analysts, data scientists |
| Gold | Aggregated, business-level | Final aggregates, business rules, star schemas | BI developers, executives, applications, ML |
How data moves through the layers
The medallion architecture is a logical pattern, but it rests on a specific set of physical mechanics. The full picture looks like this: many sources feed bronze, the data refines through silver and gold inside the lakehouse, and many consumers read from gold.
flowchart LR
subgraph SRC["Sources"]
WEB["Web data via Bright Data"]
DB["Databases and apps"]
MB["Message buses: Kafka, Kinesis"]
end
subgraph LH["Lakehouse: Delta, Iceberg, or Hudi on Parquet"]
BRONZE["Bronze: raw, append-only"] --> SILVER["Silver: cleaned, conformed"] --> GOLD["Gold: business aggregates"]
end
subgraph CON["Consumers"]
BI["BI and dashboards"]
ML["ML and AI"]
APP["Applications"]
end
WEB --> BRONZE
DB --> BRONZE
MB --> BRONZE
GOLD --> BI
GOLD --> ML
GOLD --> APPA reference medallion stack: many sources land in bronze, refine through silver and gold, and serve many consumers.
Table and file formats. The layers are usually built on an open table format sitting on top of Parquet files in cloud object storage. Delta Lake is the native format on Databricks and Microsoft Fabric: internally it stores data as Parquet, but it adds a transaction log and statistics that provide reliability and performance beyond plain Parquet. Apache Iceberg is an equally capable alternative when multi-engine interoperability matters, and Apache Hudi is a strong fit for upsert-heavy, change-data-capture ingestion. All three give you the ACID guarantees the pattern depends on.
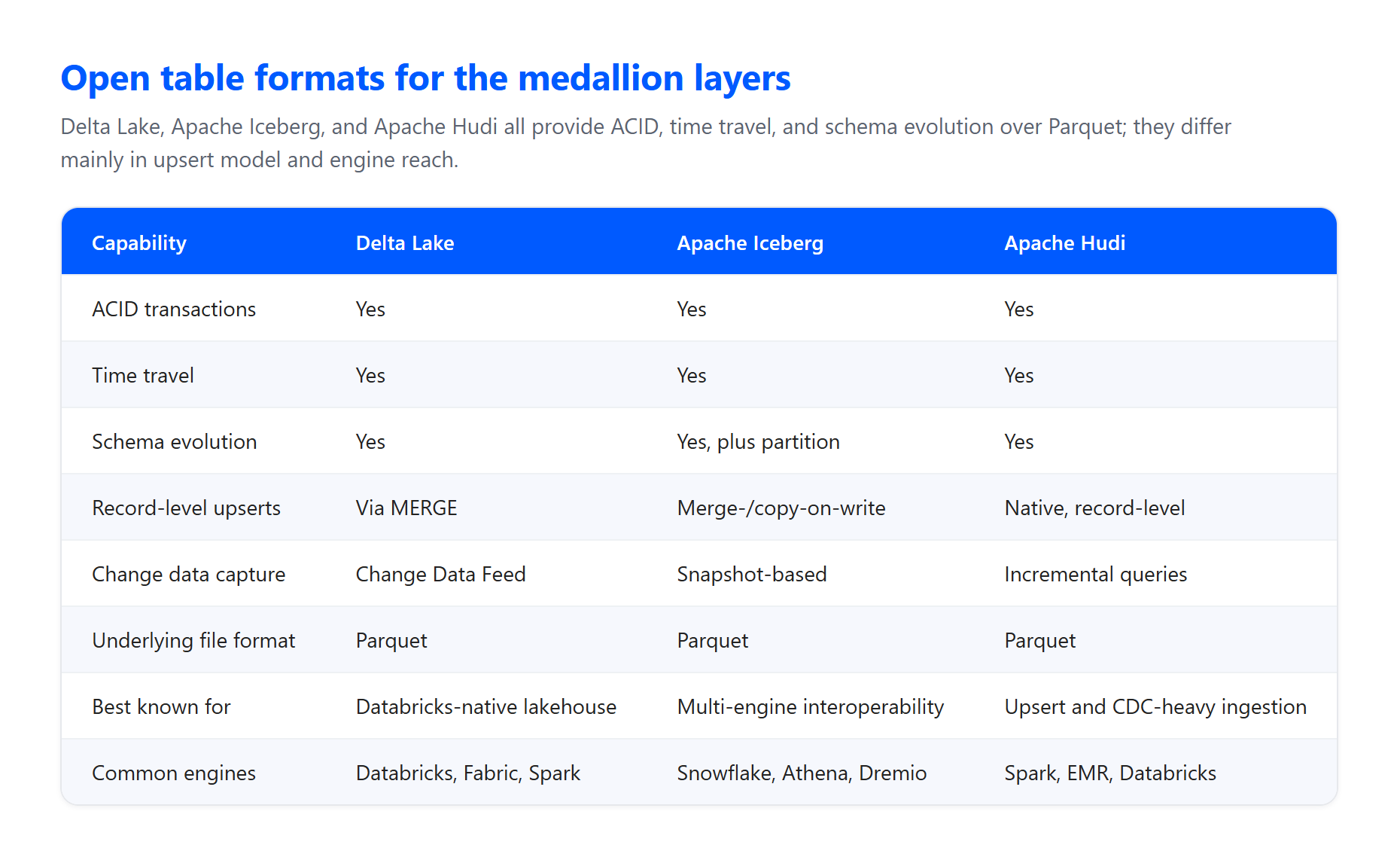
ACID transactions. The architecture guarantees atomicity, consistency, isolation, and durability as data passes through validations and transformations. That is what prevents a failed job from leaving a table half-written and corrupt, which matters enormously when many pipelines read and write concurrently.
Incremental loads and change data capture. You rarely reprocess everything on every run. Delta Lake’s Change Data Feed lets downstream layers consume only what changed. For example, you can enable the feed on a silver table and use it to incrementally update gold aggregates without a full refresh each run. Incremental ingestion at bronze is a cost and latency tradeoff: continuous streaming has the lowest latency and highest cost, triggered incremental loads cost less but add latency, and full batch loads have the highest latency.
Idempotency. Bronze ingestion should be idempotent, so re-running a load does not create duplicates or lose data. Append-only design plus deduplication at silver is what makes safe replay possible.
Orchestration, batch, and streaming. Tools like Apache Spark handle the bronze-to-silver and silver-to-gold transformations, in both batch and structured streaming modes. Declarative frameworks such as Spark Declarative Pipelines, Microsoft Fabric materialized lake views, and Snowflake tasks reduce the boilerplate of moving data between layers. Orchestrators such as Apache Airflow coordinate the runs. A worked example of this orchestration pattern, using Airflow for scheduling and Spark for transformation, is shown in this Airflow and Spark pipeline walkthrough, and a streaming variant in this guide to Spark Structured Streaming.
It is worth noting that the medallion vocabulary is not universal. The popular transformation framework dbt structures projects into staging, intermediate, and marts layers. The concerns map closely onto bronze, silver, and gold, but the names are distinct, so do not assume the two vocabularies are interchangeable when you read documentation.
Where web data enters: the bronze layer
Here is the part most architecture diagrams gloss over: where does external data actually come from, and how does it land in bronze in a usable state?
The bronze layer is defined as the landing zone for all external source systems, and Databricks explicitly lists cloud object storage such as S3, GCS, and ADLS among valid bronze sources. That is the seam where externally collected web data fits. Competitor pricing, product catalogs, public company records, search results, and review data are all raw inputs that belong in bronze in their original form, with their quirks and inconsistencies preserved for the silver layer to resolve.
This is exactly where Bright Data operates. Bright Data is a web data platform that collects public web data at scale and delivers it as raw, structured files, which makes it a natural bronze-layer source. The alignment is direct: the destinations Bright Data delivers to are the same cloud object stores that lakehouse platforms treat as bronze inputs.
flowchart LR
W["Public web: sites, SERPs, marketplaces"] --> BD["Bright Data ingestion: Web Scraper API, Datasets, Data Firehose"]
BD -->|"JSON, NDJSON, CSV, Parquet"| L["Cloud storage: S3, GCS, Azure, or Snowflake"]
L --> BR["Bronze layer: raw, preserved as source of truth"]
BR --> SV["Silver: clean and conform"]
SV --> GD["Gold: serve analytics and ML"]External web data delivered by Bright Data lands in cloud storage as the bronze layer, then flows up through silver and gold.
There are several ways to feed bronze, depending on whether you need a batch, on-demand, or continuous stream of data:
- The Web Scraper API turns any site into a structured data endpoint with 437+ pre-built scrapers, returning data as JSON, NDJSON, or CSV. It is the on-demand trigger for fresh bronze records.
- Ready-to-use datasets provide pre-collected data from hundreds of popular domains, downloadable immediately or refreshed on a schedule. This is the batch path into bronze.
- The Data Firehose delivers a continuous, real-time stream of web records directly to Amazon S3, a webhook, or a stream, which suits a streaming bronze ingestion pattern.
- The SERP API provides structured search engine results, a common bronze input for competitive intelligence and generative-engine monitoring pipelines.
- The Scraping Browser handles JavaScript-heavy sites, supplying rendered page data that static collection would miss.
- For purpose-built feeds, the Company Data API and curated AI and LLM datasets deliver vertical data ready to drop into a pipeline, while the Web Archive API supplies historical snapshots for time-series bronze tables.
The delivery story is what makes this clean. Bright Data datasets export as JSON, NDJSON, CSV, XLSX, and, importantly, Parquet, the columnar format that lakehouse tables use natively. Delivery destinations include Amazon S3, Google Cloud Storage, Microsoft Azure Blob Storage, Snowflake, Google Cloud Pub/Sub, SFTP, webhook, and direct API download. In practice that means a scheduled dataset can land in your S3 bronze bucket as Parquet on a recurring cadence, with no glue code to write. The no-code Scraper Studio extends this further, letting you build a scraper visually and load output straight into S3, GCS, Azure, BigQuery, or Snowflake.
Two principles keep this faithful to the medallion pattern. First, preserve the raw payload. Land the provider’s output in bronze exactly as delivered, including fields you do not yet use, so you retain the full forensic record. Second, normalize in silver, not in bronze. Date formats, currency, field mapping, and cross-source deduplication all belong in the silver hop, regardless of how the external provider structured its data. If you are deciding between the batch and on-demand paths, the comparison of datasets versus web scraping APIs is a useful starting point, as is the primer on structured versus unstructured data.
Reliability matters here more than anywhere, because a bronze source that silently fails poisons every layer above it. Bright Data reports a 98.44% average success rate in an independent benchmark of eleven providers, backed by a 400M+ IP ethically sourced residential proxy network and a 99.99% uptime target. For teams with governance requirements, Bright Data maintains GDPR, CCPA, SOC 2 Type II, and ISO 27001 compliance and collects only publicly available data, which is the kind of provenance an audit trail at the bronze layer is meant to capture.
A worked example: from raw scrape to gold table
Theory is easier to trust when you can run it. Below is a minimal medallion pipeline on a small, real sample of web product data: twelve listings collected from live Amazon US and UK search results across three categories. The code is deliberately simple, so the pattern, not the tooling, is what stands out.
Bronze. Land the rows exactly as collected. Prices are still strings, currencies are mixed, and nothing is cleaned or dropped.
import pandas as pd
# Bronze: raw scraped rows, landed as-is with ingestion metadata
bronze = pd.DataFrame(scraped_rows)
bronze["_ingested_at"] = "2026-06-23T00:00:00Z"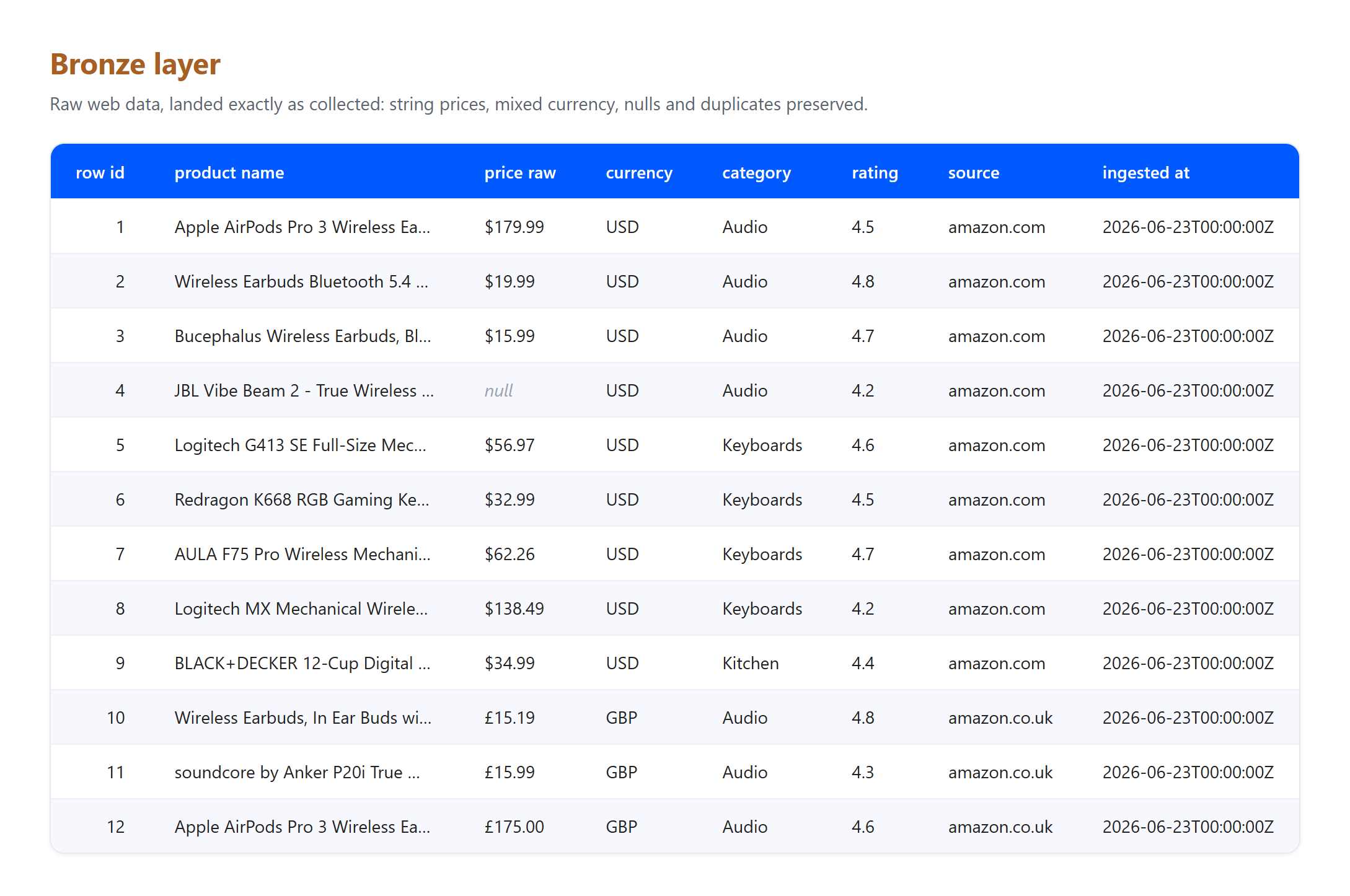
Silver. Parse prices into numbers, normalize everything to USD, decode HTML entities in titles, drop rows with no usable price, and deduplicate the same product captured more than once.
import html, re
def to_usd(price_raw, gbp_rate=1.27): # 1.27 is an illustrative fixed rate
if not price_raw:
return None # no price, the row cannot be trusted
is_gbp = "£" in price_raw
value = float(re.sub(r"[^0-9.]", "", price_raw.replace(",", "")))
return round(value * gbp_rate, 2) if is_gbp else round(value, 2)
silver = bronze.copy()
silver["price_usd"] = silver["price_raw"].map(to_usd)
silver["rating"] = silver["rating"].astype(float) # text rating to number
silver["product_name"] = silver["product_name"].map(html.unescape) # & becomes &
silver = silver[silver["price_usd"].notna()] # drop unpriced rows
silver = silver.sort_values("price_usd").drop_duplicates("product_name") # dedup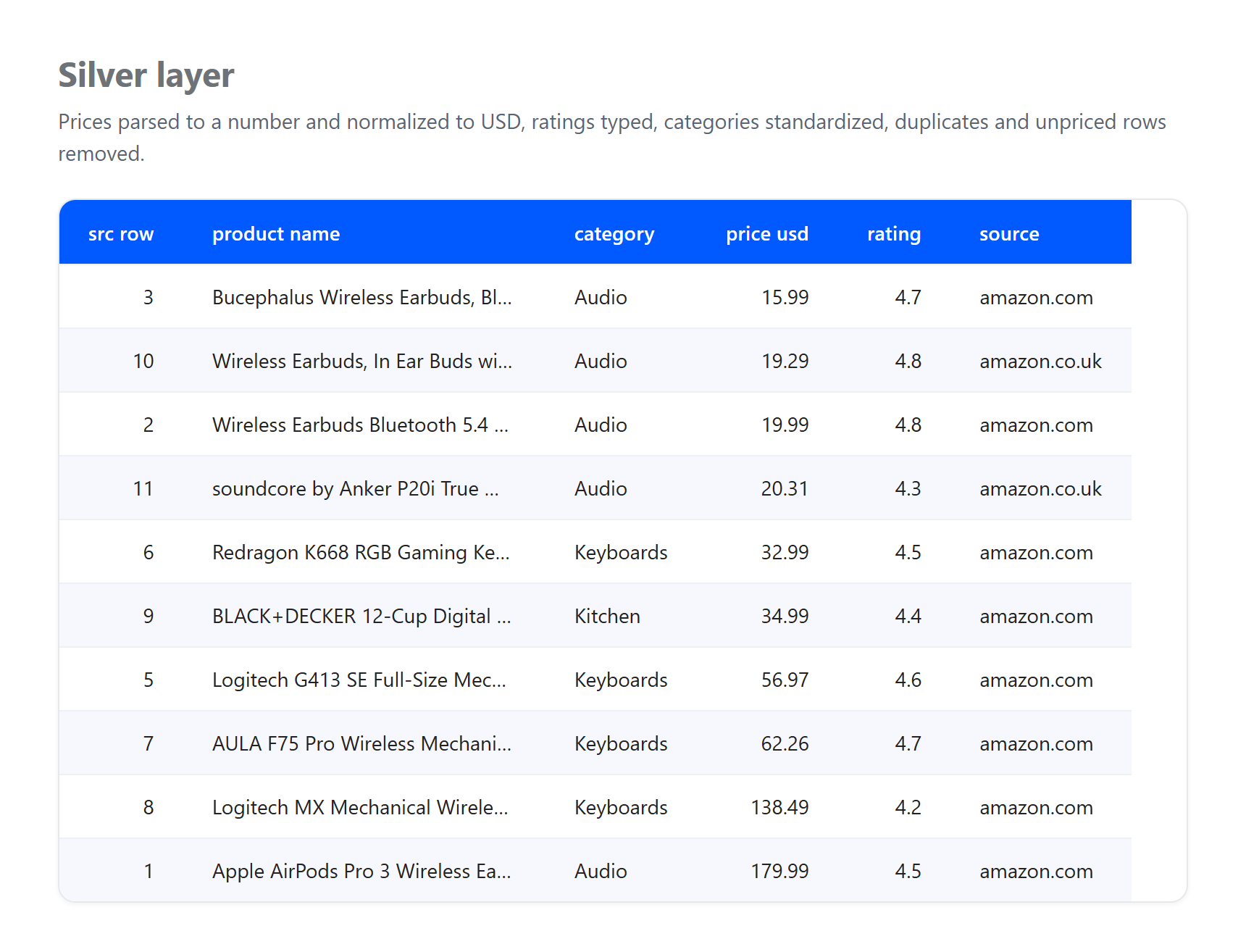
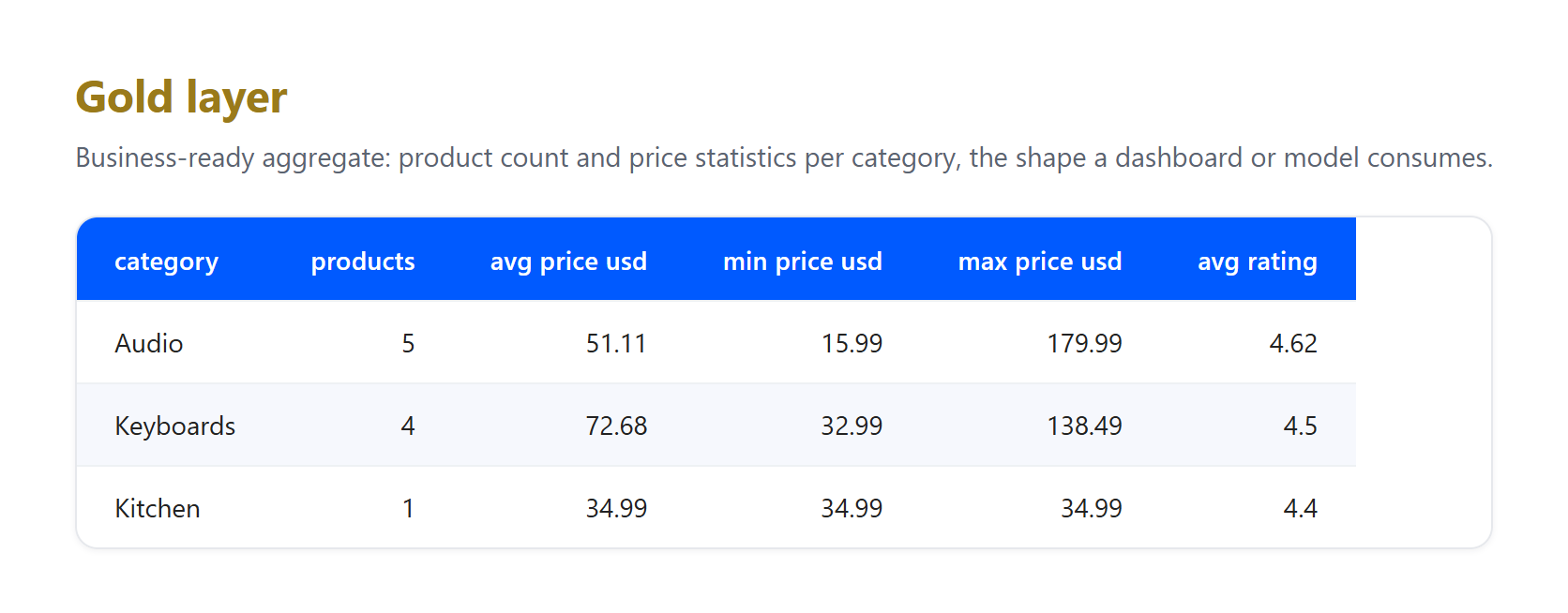
Gold. Aggregate the clean records into the business view a dashboard or model actually queries.
gold = (
silver.groupby("category")
.agg(
products=("product_name", "count"),
avg_price_usd=("price_usd", "mean"),
min_price_usd=("price_usd", "min"),
max_price_usd=("price_usd", "max"),
avg_rating=("rating", "mean"),
)
.round(2)
.reset_index()
)
Notice what the layers absorbed, because it is exactly what a real pipeline has to face. This is a small real sample collected on 23 June 2026, and the GBP to USD figure is an illustrative fixed rate, not a live conversion. Three genuine artifacts arrived at bronze and were resolved at silver: one listing arrived with no price and was dropped, the same Apple AirPods Pro 3 product was captured from both the US and UK pages and was deduplicated to a single record, and titles carrying raw HTML entities such as & were decoded into plain text. None of that cleanup belongs in bronze, whose only job is to preserve what arrived. That separation of duties is the whole point of the pattern.
The lakehouse tooling ecosystem
The medallion pattern is implemented across a familiar set of tools. None of these are interchangeable with the others, but a working architecture usually combines several.
- Databricks is the commercial lakehouse platform that coined both the lakehouse paradigm and the medallion architecture, with native Delta Lake support and declarative pipeline tooling.
- Delta Lake is the open-source table format that adds ACID transactions, schema enforcement, time travel, and change data capture on top of Parquet.
- Apache Spark is the distributed compute engine that runs the bronze-to-silver and silver-to-gold transformations in batch or streaming.
- Apache Iceberg is an open table format favored when multiple engines need to read the same tables.
- Apache Hudi is an open table format with strong record-level upsert and incremental-pull support, common at change-heavy bronze layers.
- Snowflake supports the pattern natively, including managed Iceberg tables for the gold layer.
- dbt is the SQL-first transformation framework many teams use to build the silver and gold layers.
- Microsoft Fabric implements the medallion architecture natively on OneLake, standardizing on Delta Lake.
If your platform is Snowflake or Google Cloud, the integration guides for Bright Data with Snowflake Cortex and the Vertex AI plus SERP API workflow show the bronze handoff in context.
Best practices
A handful of conventions separate a clean implementation from a fragile one.
- Do not write to silver from ingestion. Always land raw data in bronze first, so schema changes and corrupt records cannot break your refined tables.
- Keep bronze loosely typed. Store most fields as string, VARIANT, or binary so upstream schema drift does not drop data.
- Read bronze as a stream where you can. For append-only sources, streaming reads keep latency low; reserve batch reads for small datasets.
- Always keep a non-aggregated record in silver. Aggregation belongs in gold, so silver stays reusable across many consumers.
- Do not force gold to be real-time. Gold is optimized for frequently queried, batch-refreshed aggregates. Retrofitting it for low-latency workloads tends to create brittle, expensive pipelines.
- Name tables by layer. A namespace like catalog.bronze.table, catalog.silver.table, catalog.gold.table communicates the trust level of any table at a glance.
Common pitfalls and critiques
The pattern is robust, but it is misused often enough that the failure modes are well documented.
Skipping bronze. It is tempting when external data already looks clean, but skipping bronze removes the audit trail and the ability to reprocess. The semantics of your silver layer quietly change when there is no raw record behind it.
Treating silver as gold. When teams build business KPIs and heavy aggregations directly in silver, different teams define metrics differently and there is no single authoritative version. Keep aggregates in gold.
Reading raw bronze as if it were production data. Bronze is unverified and often messy. Pointing a dashboard at it leads to duplicate counts and inconsistent results. Bronze is a historical record, not a source of truth for analytics.
Cross-layer entanglement. When pipelines leak responsibilities across layers, for example ingesting raw events straight into gold, a single schema change can cascade across the whole stack.
There is also a legitimate critique of applying the pattern rigidly. As one analysis put it, applying a rigid three-layer structure to all sources leads to inefficiencies when certain datasets do not need extensive cleansing, and the sequential layering adds latency that real-time use cases may not tolerate. The practitioner community has responded by proposing extra layers in some designs, such as a pre-bronze landing zone or a platinum layer above gold for operational and machine-learning serving.
The healthy way to read all of this is that the medallion architecture is a flexible framework, not a mandate. Databricks itself states that following the medallion architecture is a recommended best practice but not a requirement, and the Delta Lake project describes it as an optional, flexible framework. Use the layer count and the naming that fit your query patterns and your consumers.
Common use cases
The pattern pays off most clearly where raw inputs are messy and many consumers need trustworthy outputs.
- Competitive pricing and ecommerce intelligence. Product and price data collected from many retailers lands in bronze as-is, gets normalized and deduplicated in silver, and feeds gold price-tracking and assortment dashboards.
- AI and machine learning training data. Web-scale text and structured data lands raw in bronze, is cleaned and deduplicated in silver, and is shaped into model-ready features in gold. The practical steps are covered in this guide to web scraping for machine learning, and the broader strategy in the AI data flywheel piece.
- Market and alternative-data research. External signals from many sources are conformed in silver into a single research view, then aggregated into gold indicators.
- Search and SERP monitoring. A continuous stream of search results flows into bronze, is structured in silver, and rolls up into gold visibility and share-of-voice metrics.
- Firmographic and customer enrichment. Company data feeds enrich internal records at the silver layer, producing gold tables for sales and marketing.
For the engineering plumbing behind these, the walkthroughs on AWS Glue ETL, AWS Step Functions, Kubeflow pipelines, the Mage AI pipeline, and connecting live web data to Tableau each show a real bronze-to-serving path. The fundamentals of the extract step itself are covered in this primer on data extraction.
Conclusion
The medallion architecture endures because it gives teams a shared language for turning raw data into trusted data, one disciplined hop at a time. Bronze preserves the truth, silver makes it consistent, and gold makes it useful. The pattern only works as well as the raw data feeding it, which is why a reliable, well-structured bronze source is not a detail but a foundation.
For external and web data, that foundation is where Bright Data fits: production-grade collection delivered as JSON, CSV, or Parquet straight into the cloud storage your lakehouse already treats as bronze. Ready to feed your bronze layer with reliable web data? Start for free and see how quickly raw web data can flow into your pipeline.
Frequently Asked Questions
Q: What is the medallion architecture in simple terms?
It is a way to organize data in a lakehouse so that it gets cleaner and more useful as it moves through three layers. Raw data lands in the bronze layer, gets cleaned and standardized in the silver layer, and is aggregated into business-ready tables in the gold layer. Each layer has a clear job, which makes data quality easier to manage and audit.
Q: What is the difference between the bronze, silver, and gold layers?
Bronze holds raw data exactly as it arrived, append-only and untransformed, as a permanent source of truth. Silver holds cleaned and conformed data, with deduplication, schema enforcement, and joins applied so the data is trustworthy and consistent. Gold holds aggregated, business-level data modeled for specific reporting, dashboards, machine learning, and applications.
Q: Is the medallion architecture the same as ETL?
No, but they are related. ETL describes extracting, transforming, and loading data. The medallion architecture is a layering pattern that organizes where those transformations happen. In a lakehouse it usually follows an ELT style, where raw data is loaded into bronze first and transformed in stages into silver and gold inside the platform.
Q: Do I always need all three layers?
No. Databricks describes the medallion architecture as a recommended best practice, not a requirement. Some datasets that arrive clean may not need an extensive silver step, and some real-time use cases deliberately bypass parts of the flow. The number of layers and the naming should fit your query patterns and consumers. The main caution is that skipping bronze removes your raw audit trail and your ability to reprocess.
Q: What file format should I use for medallion tables?
Most implementations use an open table format such as Delta Lake, Apache Iceberg, or Apache Hudi, all of which sit on top of Parquet files in cloud object storage. These formats add ACID transactions, schema enforcement, and time travel, which the pattern depends on. Delta Lake is the native format on Databricks and Microsoft Fabric, while Iceberg is common when multiple engines read the same tables.
Q: How does external or web data fit into a medallion architecture?
External and web data is a bronze-layer input. You land the raw collected data, for example product, pricing, search, or company data, in its original form in bronze, then normalize and deduplicate it in silver. Because lakehouse platforms treat cloud object storage like S3, GCS, and Azure as valid bronze sources, a provider such as Bright Data can deliver web data as JSON, CSV, or Parquet directly into those stores, where it becomes the bronze layer.
Q: Is the medallion architecture tied to Databricks?
Databricks popularized the term alongside the lakehouse paradigm and Delta Lake, but the pattern is not exclusive to it. The same bronze, silver, and gold language is used across Microsoft Fabric and Snowflake documentation, and the underlying open table formats run on many engines. The pattern is a general convention, not a single vendor’s product.

Technical Writer
Arindam Majumder is a developer advocate, YouTuber, and technical writer who simplifies LLMs, agent workflows, and AI content for 5,000+ followers.



