


Discover API: Source Discovery for AI Agents
Before an agent can extract, scrape, or enrich, it needs to know where. Discover API returns a ranked, live set of URLs from the public web, ready to feed directly into your agent’s extraction, analysis, or monitoring pipeline.
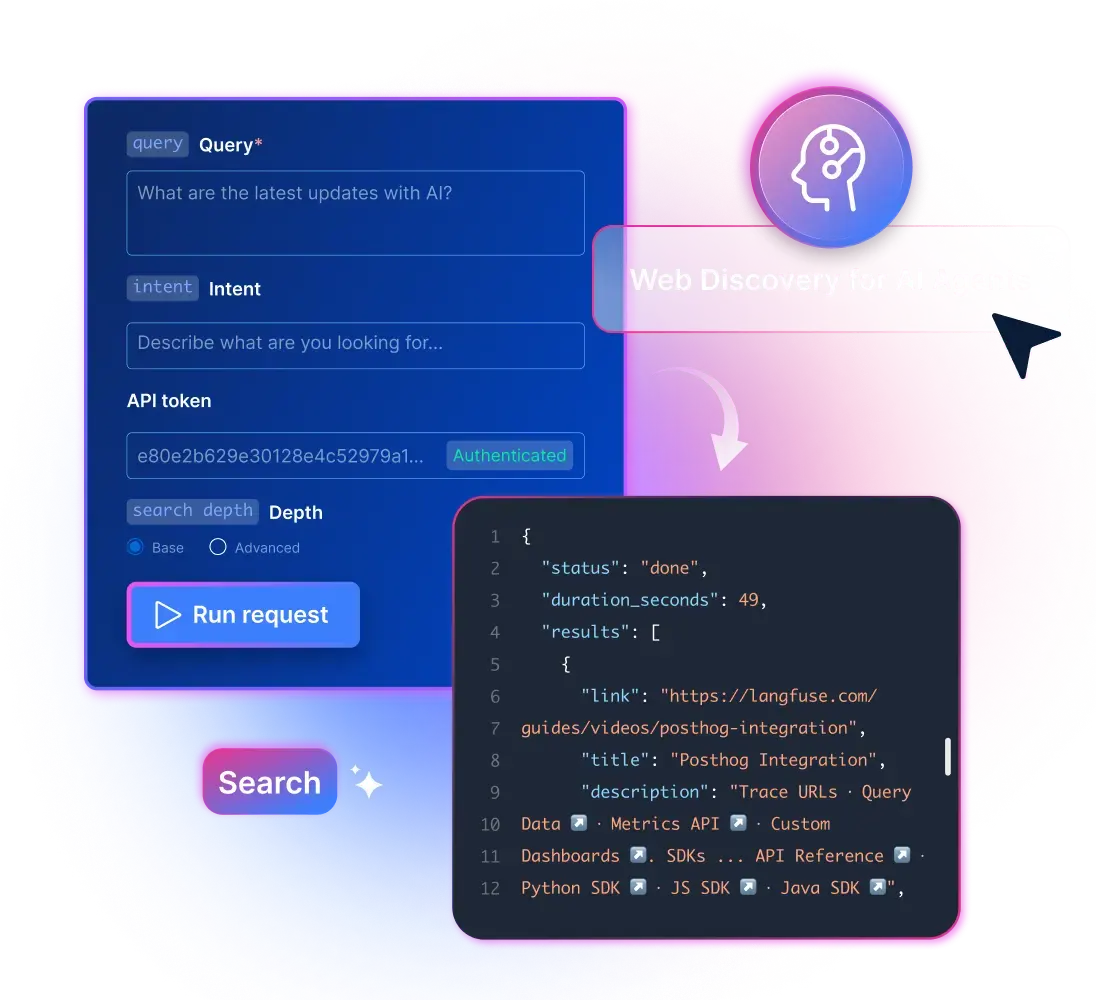
- Always live retrieval from
the web - Up to 1000 results per
request - Ranked for
intent - Built for parallel agent
workloads
Step 1 of your agentic web data pipeline
Returns the sources your agent should target next, ranked by task relevance, not SEO rank
Up to 1,000 pipeline-ready URLs per request. No pagination logic, no deduplication overhead.
Every URL is verified live. Your agent never passes a dead endpoint to the next pipeline stage.
Optional cleaned Markdown source text for verification and RAG
Built for high throughput, parallel agent workloads
Why agents use DiscoverSearch engines are for humans. Search APIs are optimized for speed and top links. Discover is built for market-aware workflows that require freshness, high recall, and verifiable context.
Prioritize sources that match the task, not sources that win SEO

Retrieve up to 1000 results without manual pagination logic

Reduce risk from stale cached or indexed paths

Optional cleaned Markdown source text for verification and RAG

Built for high throughput, parallel agent workloads

`POST https://api.brightdata.com/discover`
```bash
curl "https://api.brightdata.com/discover"
-H "Authorization: Bearer "
-H "Content-Type: application/json"
-d '{
"query": "competitor pricing changes enterprise plan 2026",
"num_results": 50,
"intent": "find official pricing pages and change notes",
"content": true,
"format": "markdown"
}'
require('request-promise')({
url: 'https://geo.brdtest.com/mygeo.json',
proxy: 'http://brd-customer-[your customerID]-zone-residential:"[your password]"@brd.superproxy.io:33335',
})
.then(function(data){ console.log(data); },
function(err){ console.error(err); });
import requests
url = "https://api.brightdata.com/datasets/snapshots/{id}/download"
headers = {"Authorization": "Bearer "}
response = requests.get(url, headers=headers)
print(response.json())
using System;
using System.Net;
class Example
{
static void Main()
{
// Replace '[your customerID]' and '[your password]' with your actual credentials
var client = new WebClient();
client.Proxy = new WebProxy("brd.superproxy.io:33335");
client.Proxy.Credentials = new NetworkCredential("brd-customer-[your customerID]-zone-residential", "[your password]");
Console.WriteLine(client.DownloadString("https://geo.brdtest.com/mygeo.json"));
}
}
Quickstart
Built for market intelligence

Competitive intelligence
Track pricing, launches, and positioning changes

Risk monitoring
Detect incidents, policy changes, and signals

Due diligence
Verify claims across many independent sources

Enrichment
Populate CRM with verified live web data

Vertical search engines
Build intent-ranked search for one domain

Alternative data
Capture long-tail signals across the web
Designed to work with Bright Data Datasets
Use Discover for live discovery and fresh evidence. Use Bright Data Datasets for baseline grounding and faster retrieval at scale. For large, repeatable data needs, Datasets are more cost effective than re-discovering the same entities over and over, and they give your agent a stronger starting point before it performs live discovery.
FAQ
Is Discover cached or indexed?
Discover is always live. Each request is executed at query time against the live web.
What does intent do?
intent tells Discover what the agent is trying to accomplish so results are ranked for the task.
When should I use include_content?
Use include_content=true when you need verification or RAG grounding with source text.
Should I use Discover or Datasets?
Use Datasets for baseline coverage. Use Discover for live discovery and fresh evidence. Most teams use both.
Can I do historical research or monitoring?
Use Web Archive API. for historical backfill and longitudinal monitoring.
What happens if I need more than 1000 results?
Chain multiple Discover calls or use Datasets for bulk ingestion, then use Discover to keep it fresh.