
In this article we will discuss:
- What is a data pipeline?
- How a good data pipeline architecture can help businesses
- Data pipeline architecture examples
- Data pipeline vs ETL pipeline
What is a data pipeline?
A data pipeline is the process that data undergoes. Typically a full cycle takes place between a ‘target site’, and a ‘data lake or pool’ that services a team in their decision-making process or an algorithm in its Artificial Intelligence (AI) capabilities. A typical flow looks something like this:
- Collection
- Ingestion
- Preparation
- Computation
- Presentation
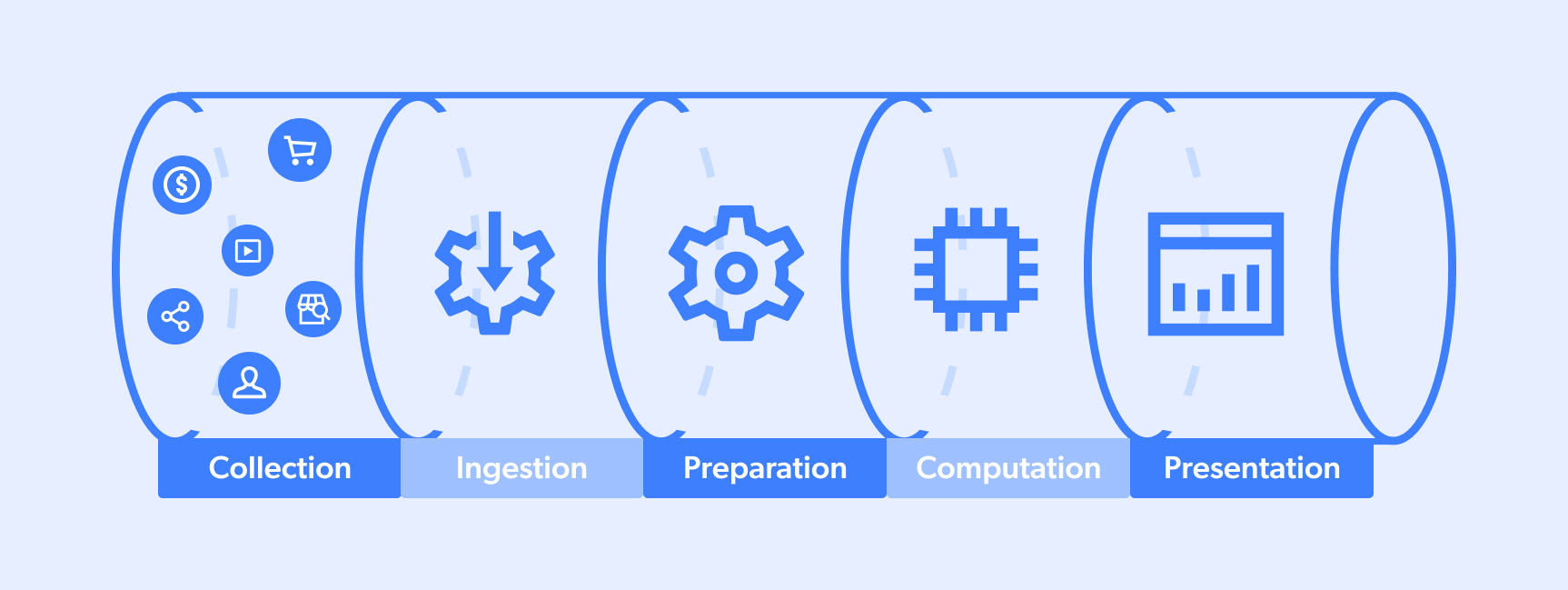
Keep in mind, however, that data pipelines can have multiple sources/destinations and that sometimes steps can take place simultaneously. Also, certain pipelines can be partial (say numbers 1-3 or 3-5, for example).
What is a big data pipeline?
Big data pipelines are operational flows that know how to deal with data collection, processing, and implementation at scale. The idea is that the larger the ‘data capture’ the smaller the margin of error when looking to make crucial business decisions.
Some popular applications of a big data pipeline include:
- Predictive analytics: Algorithms are able to make predictions in terms of the stock market or product demand, for example. These capabilities require ‘data training’ using historical data sets that enable systems to understand human behavioral patterns in order to predict potential future outcomes.
- Real-time market capture: This approach understands that current consumer sentiment, for example, can shift sporadically. Therefore, aggregating large amounts of information from multiple sources such as collecting social media data, eCommerce marketplace data, and competitor advertisement data on search engines. By cross-referencing these unique data points at scale they are able to make better decisions resulting in higher market share capture.
By leveraging a data collection platform, big data pipeline operational flows are capable of handling:
- Scalability – Data volumes tend to fluctuate often, and systems need to be equipped with the ability to activate/deactivate resources on command.
- Fluidity – When collecting data at scale from multiple sources, big data processing operations need the wherewithal to deal with data in many different formats (e.g., JSON, CSV, HTML) as well as the know-how to clean, match, synthesize, process, and structure unstructured target website data.
- Concurrent request management – As Bright Data’s CEO, Or Lenchner, likes to put it: ‘Data collection at scale is like waiting for beer online at a music festival. Concurrent requests are short, quick lines that get service quickly/simultaneously. Whereas the other line is slow/consecutive. When your business operations depend on it, which line would you prefer to be standing on?’

How a good data pipeline architecture can help businesses
These are some of the key ways in which good data pipeline architecture can help streamline day-to-day business processes:
One: Data consolidation
Data can originate from many different sources, such as social media, search engines, stock markets, news outlets, consumer activities on marketplaces, etc. Data pipelines function as a funnel that brings all of these together into one single location.
Two: Friction reduction
Data pipelines reduce friction and ‘time-to-insight’ by lowering the amount of effort needed in terms of cleaning and preparing data for initial analysis.
Three: Data compartmentalization
Data pipeline architecture implemented in an intelligent manner helps ensure that only relevant stakeholders gain access to specific pieces of information, helping keep each individual actor on course.
Four: Data uniformity
Data comes in many different formats from a variety of sources. Data pipeline architecture knows how to create uniformity as well as being able to copy/move/transfer between various depositories/systems.
Data pipeline architecture examples
Data pipeline architectures need to take into consideration things like anticipated collection volume, data origin and destination, as well as the type of processing that would potentially need to transpire.
Here are three archetypal data pipeline architecture examples:
- A streaming data pipeline: This data pipeline is for more real-time applications. For example, an Online Travel Agency (OTA) that collects data on competitor pricing, bundles, and advertising campaigns. This information is processed/formatted, and then delivered to relevant teams/systems for further analysis, and decision-making (e.g., an algorithm in charge of repricing tickets based on competitor price drops).
- A batch-based data pipeline: This is a more simple/straightforward architecture. It typically consists of one system/source that generates a large quantity of data points, which are then delivered to one destination (i.e., a data storage/analysis ‘facility’). A good example of this would be a financial institution that collects large amounts of data regarding investor buys/sells/volume on the Nasdaq. That information gets sent for analysis, and is then used to inform portfolio management.
- A hybrid data pipeline: This type of approach is popular with very large companies/environments enabling real-time insights as well as batch processing/analysis. Many corporations that opt for this approach prefer keeping data in raw formats in order to enable increased future versatility in terms of new queries/pipeline structural changes.
Data pipeline vs ETL pipeline
ETL, or Extraction, Transformation, and Loading pipelines, typically serve the purposes of warehousing and integration. It typically functions as a way to take data collected from disparate sources, transfer it to a more universal/accessible format, and upload it to a target system. ETL pipelines typically enable us to collect, save, and prepare data for quick access/analysis.
A data pipeline is more about creating a systemic process in which data can be collected, formatted, and transferred/uploaded to target systems. Data pipelines are more of a protocol, ensuring that all parts of ‘the machine’ are working as intended.
The bottom line
Finding and implementing the data pipeline architecture that is right for your business is extremely important to your success as a business. Whether you opt for a streaming, batch-based, or hybrid approach, you will want to leverage technology that can help automate and tailor solutions to your specific needs.




