

In this guide, you will see the following:
- What JavaScript-heavy sites are.
- Challenges and methods to scrape them via browser rendering.
- How AJAX call interception works, and its limitations.
- The modern solution for scraping JavaScript-heavy websites.
Let’s dive in!
What Is a JavaScript-Heavy Website?
In the realm of web scraping, a site is “JavaScript-heavy” when the data to collect is not in the initial HTML document returned by the server. Instead, the actual content is dynamically fetched and rendered by JavaScript in the user’s browser.
How a site uses JavaScript directly affects how you need to proceed to extract its data. Typically, JavaScript-based sites follow these three main patterns:
- Single-Page Applications (SPAs): An SPA is one web page that relies on JavaScript to update specific sections with new content from the server. In other words, the entire web application is just a single webpage that is not reloaded for every user interaction.
- User-driven interactions: The content appears only after you perform specific actions. Examples are “load more” buttons and dynamic pagination.
- Asynchronous data: Many sites load a basic page layout first for speed, then make background calls using AJAX to fetch data. This mechanism is common for live updates, like refreshing stock prices without reloading the page.
Scraping JavaScript-Heavy Sites via Full Browser Rendering
Browser automation tools let you write scripts that launch and control web browsers. This allows them to execute the JavaScript needed to fully render a page. You can then use the HTML element selection and data extraction APIs these tools provide to pull the data you need.
This is the fundamental approach to scraping JavaScript-heavy sites, and here we will present it with the following sections:
- How automation tools work.
- What headless and “headful” modes are.
- Challenges and solutions with this approach.
- The most used browser automation tools.
How Automation Tools Work
Browser automation tools operate by using a protocol (e.g., CDP or BiDi) to send commands directly to a browser. In simpler terms, they expose a complete API to issue commands like “navigate to this URL,” “find this element,” and “click this button”.
The browser runs those commands on the page, executing any JavaScript needed for the interactions described in your scraping script. The browser automation tool can also access the rendered DOM (Document Object Model). That is where you can find the data to scrape.
Headless vs “Headful” Browsers
When you automate a browser, you need to decide how it should run. Typically, you choose between two modes:
- Headful: The browser launches with its full graphical interface, just like when a human user opens it. You can see the browser window on your screen and watch as your script clicks, types, and navigates in real time. This is helpful for visually confirming that your script works as expected. It can also make your automation look more like real user activity to anti-bot systems. On the other hand, running a browser with a GUI is resource-intensive (we all know how memory-hungry browsers can be), which slows down your web scraping.
- Headless: The browser runs in the background without a visible interface. It uses fewer system resources and is much faster. This is the standard for production scrapers, especially when running hundreds of parallel instances on a server. On the downside, if not configured carefully, a GUI-less browser might appear suspicious. Discover the best headless browsers on the market.
Challenges and Solutions with Browser Rendering
Automating a browser is just the first step when dealing with JavaScript-heavy websites. When scraping such sites, you will inevitably face two major categories of challenges, including:
- Complex navigation: Scraping scripts must be more than just command-followers. You need to program them to handle the whole user journey. This means writing code for scraping complex navigation flows, such as waiting for new content to load and dealing with infinite scrolling. Scraping JavaScript-heavy sites includes handling multi-page forms, dropdown menus, and much more.
- Evading anti-bot systems: When not applied properly, browser automation is a red flag that anti-bot systems can detect. To succeed in a scraping scenario with browser automation tools, your scraper must somehow appear human by addressing challenges like:
- Browser fingerprinting: Anti-bots analyze hundreds of data points from the client’s browser to create a unique signature. This includes your User-Agent string, screen resolution, installed fonts, WebGL rendering capabilities, and more. Clearly, a default automation setup is easily identifiable. Setting a non-headless User-Agent is a great tip. You may also require specialized tools like undetected-chromedriver, which modifies several browser options to make it appear like a regular user’s browser.
- Behavioral analysis: Anti-bots also watch how the scraper interacts with the page. A script that clicks a button 5 milliseconds after a page loads is obviously not human. If the behavior is flagged as robotic, the defense system can ban you.
- CAPTCHAs: CAPTCHAs are often the ultimate roadblock for scraping methods that are based on browser automation. That is because standard automation scripts cannot resolve them autonomously. Overcoming this requires integrating CAPTCHA-solving services.
For more guidance, see our guide on scraping dynamic sites.
Top Browser Automation Frameworks
The three dominant frameworks for browser automation are:
- Playwright: It is a modern framework from Microsoft. It is designed from the ground up to handle the complexities of modern sites. This makes it a top choice for new scraping projects. It is available in JavaScript, Python, C#, and Java, with additional language support provided by the community. This makes web scraping with Playwright a good choice for most developers.
- Selenium: It is the open-source titan of web automation. Its greatest strengths lie in its versatility. In particular, it supports nearly every programming language and browser, and has a wide and mature ecosystem. This is why Selenium is largely used as a browser automation tool for scraping.
- Puppeteer: It is a library developed by Google that provides granular control over Chrome and Chromium-based browsers via the CDP (Chrome DevTools Protocol). It now also supports Firefox. With this library, you can appear as a regular user by simulating user behavior in a controlled browser. This makes Puppeteer widely used for web scraping.
See how these solutions (and others) compare in our repository about the best browser automation tools.
Alternative Method: Replicating AJAX Calls
Instead of bearing the cost of rendering an entire visual webpage in the browser, you can take a detective approach. What you can do instead is identify the direct API calls the website’s front end makes to its back end and replicate them yourself.
These API calls usually return the raw data that the site later renders on the page, so you can target them directly. This technique relies on mimicking AJAX calls and is commonly known as API web scraping.
Let’s see how it works!
How the AJAX Call Replication Approach Works
AJAX replication is a practical scraping technique. The core idea is to bypass rendering the entire page by mimicking the network requests (usually AJAX calls) that the web application makes to fetch data from its backend.
At a high level, this involves two main steps:
- Snoop: Open your browser’s Developer Tools (typically the “Network” tab with the “Fetch/XHR” filter enabled) and interact with the website. Watch which API calls are made in the background when new data loads. For example, during infinite scrolling or when clicking “Load more” buttons.
- Replay: Once you have identified the right API request, note its URL, HTTP method (GET, POST, etc.), headers, and payload (if any). Then replicate this request in your scraping script using an HTTP client like Requests in Python.
Those API endpoints usually return data in a structured format, most often JSON. This is a huge advantage, as you can access the JSON data without the extra hassle of parsing HTML.
For example, take a look at the API call made by a site that uses infinite scrolling to load more data:
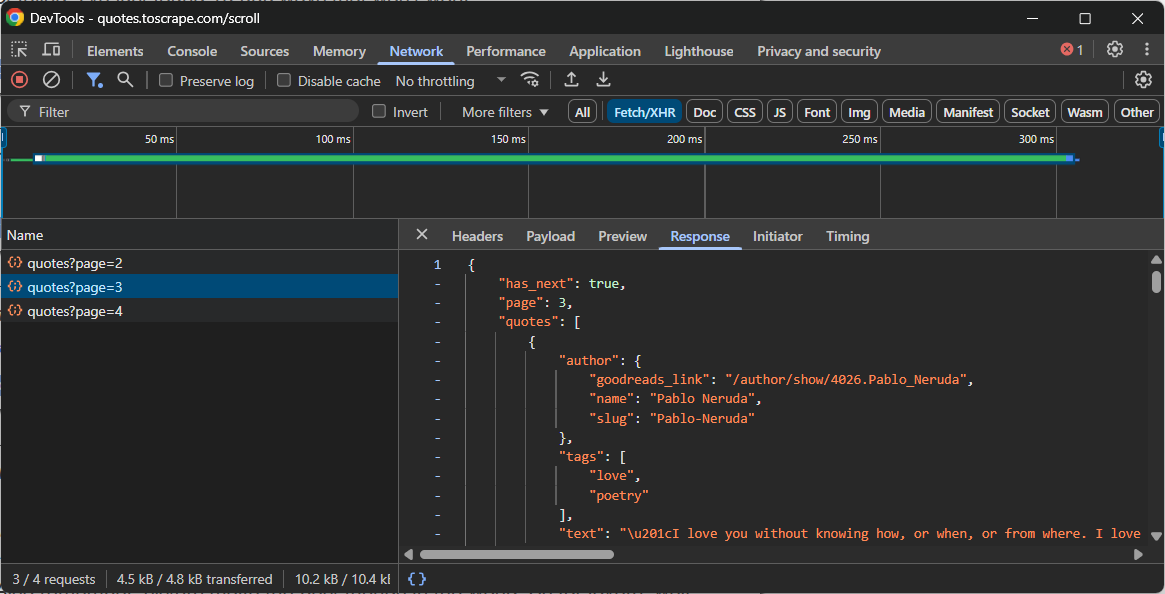
In this case, you can write a simple scraping script that reproduces the above infinite scrolling API call and then accesses the data.
Main Challenges When Intercepting AJAX Calls
When it works, this approach is fast, effective, and simple. Still, it comes with a few challenges:
- Obfuscated payloads: The API might require encrypted payloads or not return clean, readable JSON. It could be an encrypted string that a specific JavaScript function knows how to decode. This is an anti-scraping measure that requires reverse engineering.
- Dynamic endpoints and headers: API endpoints and how to call them (e.g., setting the proper headers, adding the right payload, and so on) change over time. The primary challenge of this solution is that any evolution in the API will break the scraper. This requires code maintenance to restore functionality, which is a common issue with most (but not all, as we are about to see) web scraping approaches.
- TLS fingerprinting: The most advanced anti-bots analyze the “TLS handshake,” which is the digital signature of the program. They can easily discriminate between a request from Chrome and one from a standard Python script. To bypass this, you need specialized tools that can impersonate a browser’s TLS signature.
A Modern Approach to Scraping JavaScript-Heavy Sites: AI-Powered Browser Scraping Agents
The methods described so far still face major challenges. A more modern solution for scraping JavaScript-heavy sites requires a paradigm shift. The idea is to move from writing imperative commands to defining declarative goals using AI-driven browser agents.
An agent browser is a browser integrated with an LLM that understands the page’s content, context, and visual layout. This fundamentally changes how we approach web scraping, especially for JavaScript-heavy websites.
Those sites typically require complex user interactions to load the data you want. Traditionally, you would have to inject logic to replicate those interactions in your scripts. This approach is inherently brittle and maintenance-heavy. The problem is that every time the user flow changes, you need to manually update your automation logic.
Thanks to AI-powered browser agents, you can avoid all that. A simple descriptive prompt can drive effective automation that adapts even when the site’s UI or flow changes. This flexibility is a huge advantage and opens the door to many other automation possibilities, which is why agentic AI is rapidly gaining traction.
Now, no matter how powerful your AI browser agent library is, your scraping logic still depends on regular browsers. This means you remain vulnerable to issues like browser fingerprinting and CAPTCHAs. Scaling such solutions also becomes difficult due to rate limits and IP bans.
The real solution is a cloud-based, AI-ready scraping platform that integrates with any agentic library and is designed to avoid getting blocked. This is exactly what Bright Data’s Agent Browser provides.
Agent Browser lets you run AI-driven workflows on remote browsers that never get blocked. It is infinitely scalable, supports both headless and headful modes, and is powered by the world’s most reliable proxy network.
Conclusion
In this article, you learned what JavaScript-heavy websites are, and common challenges and solutions to scrape data from them. Each implementation described comes with its limitations, but the one that shines is using an agent browser.
As discussed, Bright Data’s Agent Browser allows you to solve all the common scraping issues while integrating with the most popular agentic AI libraries.
If you use advanced AI scraping agents, you need reliable tools to retrieve, validate, and transform web content. For all these capabilities and more, explore Bright Data’s AI infrastructure.
Create a Bright Data account and try all our products and services for AI agent development!

Technical Writer
Federico Trotta is a technical writer, editor, and data scientist. Expert in technical content management, data analysis, machine learning, and Python development.




