

In this guide, you will learn:
- How to identify when a site has complex navigation
- The best scraping tool to handle these scenarios
- How to scrape common complex navigation patterns
Let’s dive in!
When Does a Site Have Complex Navigation?
A site with complex navigation is a common web scraping challenge we have to face as developers. But what exactly does “complex navigation” mean? In web scraping, complex navigation refers to website structures where content or pages are not easily accessible.
Complex navigation scenarios often involve dynamic elements, asynchronous data loading, or user-driven interactions. While these aspects may enhance user experiences, they significantly complicate data extraction processes.
Now, the best way to understand complex navigation is by exploring some examples:
- JavaScript-rendered navigation: Websites that rely on JavaScript frameworks (like React, Vue.js, or Angular) to generate content directly in the browser.
- Paginated content: Sites with data spread across multiple pages. This becomes more complex when pagination is loaded numerically via AJAX, making it harder to access subsequent pages.
- Infinite scrolling: Pages that load additional content dynamically as users scroll down, commonly seen in social media feeds and news websites.
- Multi-level menus: Sites with nested menus that require multiple clicks or hover actions to reveal deeper layers of navigation (e.g., product category trees on large e-commerce platforms).
- Interactive maps interfaces: Websites displaying information on maps or graphs, where data points are dynamically loaded as users pan or zoom.
- Tabs or accordions: Pages where content is hidden under dynamically rendered tabs or collapsible accordions whose content is not directly embedded in the HTML page returned by the server.
- Dynamic filters and sorting options: Sites with complex filtering systems where applying multiple filters reloads the item listing dynamically, without changing the URL structure.
Best Scraping Tools for Handling Complex Navigation Websites
To effectively scrape a site with complex navigation, you must understand what tools you need to use. The task itself is inherently difficult, and not using the right scraping libraries will only make it more challenging.
What many of the complex interactions listed above have in common is that they:
- Require some form of user interaction, or
- Are executed on the client side within the browser.
In other words, these tasks need JavaScript execution, something only a browser can do. This means you cannot rely on simple HTML parsers for such pages. Instead, you must use a browser automation tool like Selenium, Playwright, or Puppeteer.
These solutions allow you to programmatically instruct a browser to perform specific actions on a web page, mimicking user behavior. These are often called headless browsers because they can render the browser without a graphical interface, saving system resources.
Discover the best headless browser tools for web scraping.
How to Scrape Common Complex Navigation Patterns
In this tutorial section, we will use Selenium in Python. However, you can easily adapt the logic to Playwright, Puppeteer, or any other browser automation tool. We will also assume you are already familiar with the basics of web scraping using Selenium.
Specifically, we will cover how to scrape the following common complex navigation patterns:
- Dynamic pagination: Sites with paginated data loaded dynamically via AJAX.
- ‘Load More’ button: A common JavaScript-based navigation example.
- Infinite scrolling: A page that continuously loads data as the user scrolls down.
Time to code!
Dynamic Pagination
The target page for this example is the “Oscar Winning Films: AJAX and Javascript” scraping sandbox:
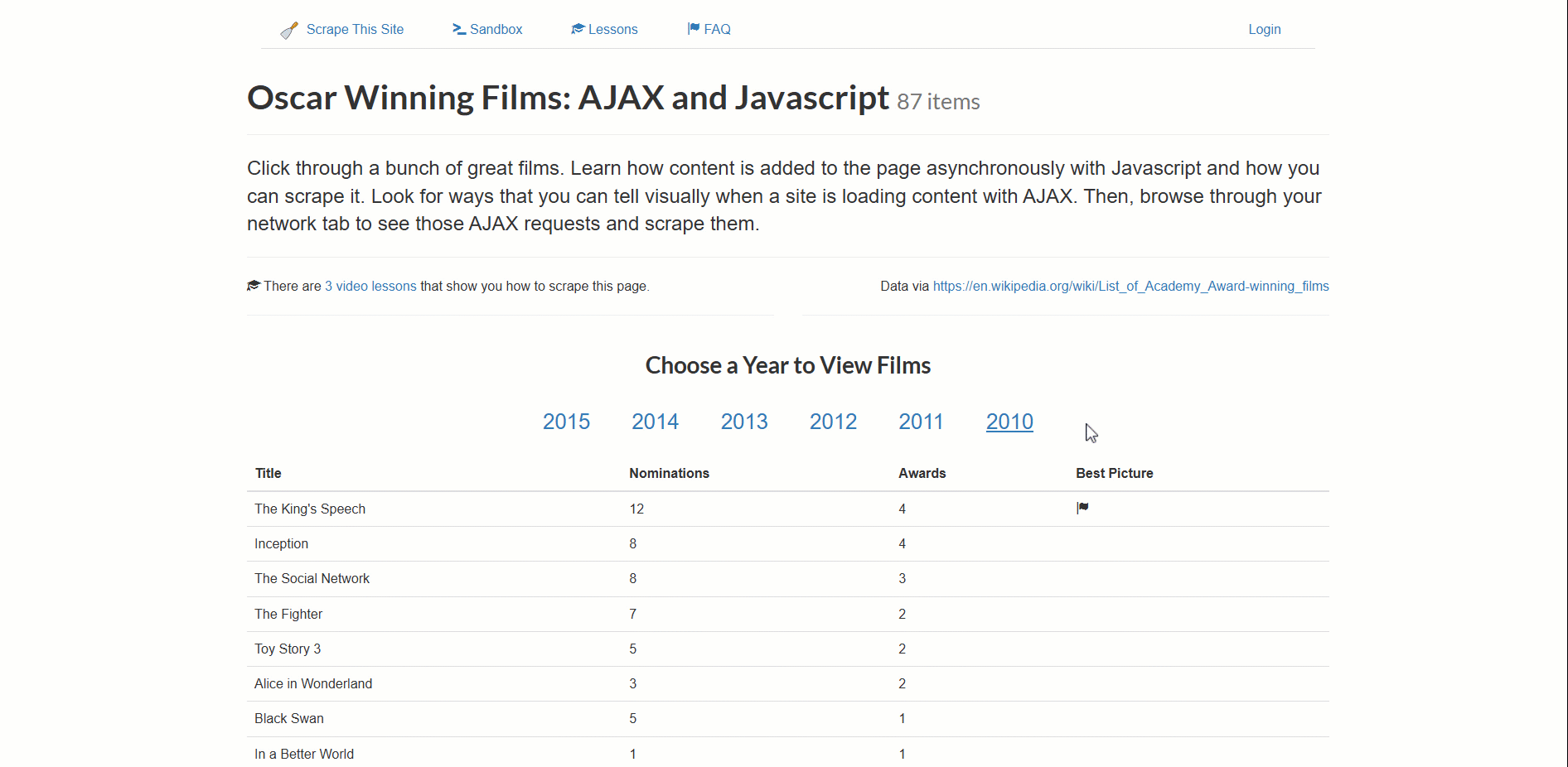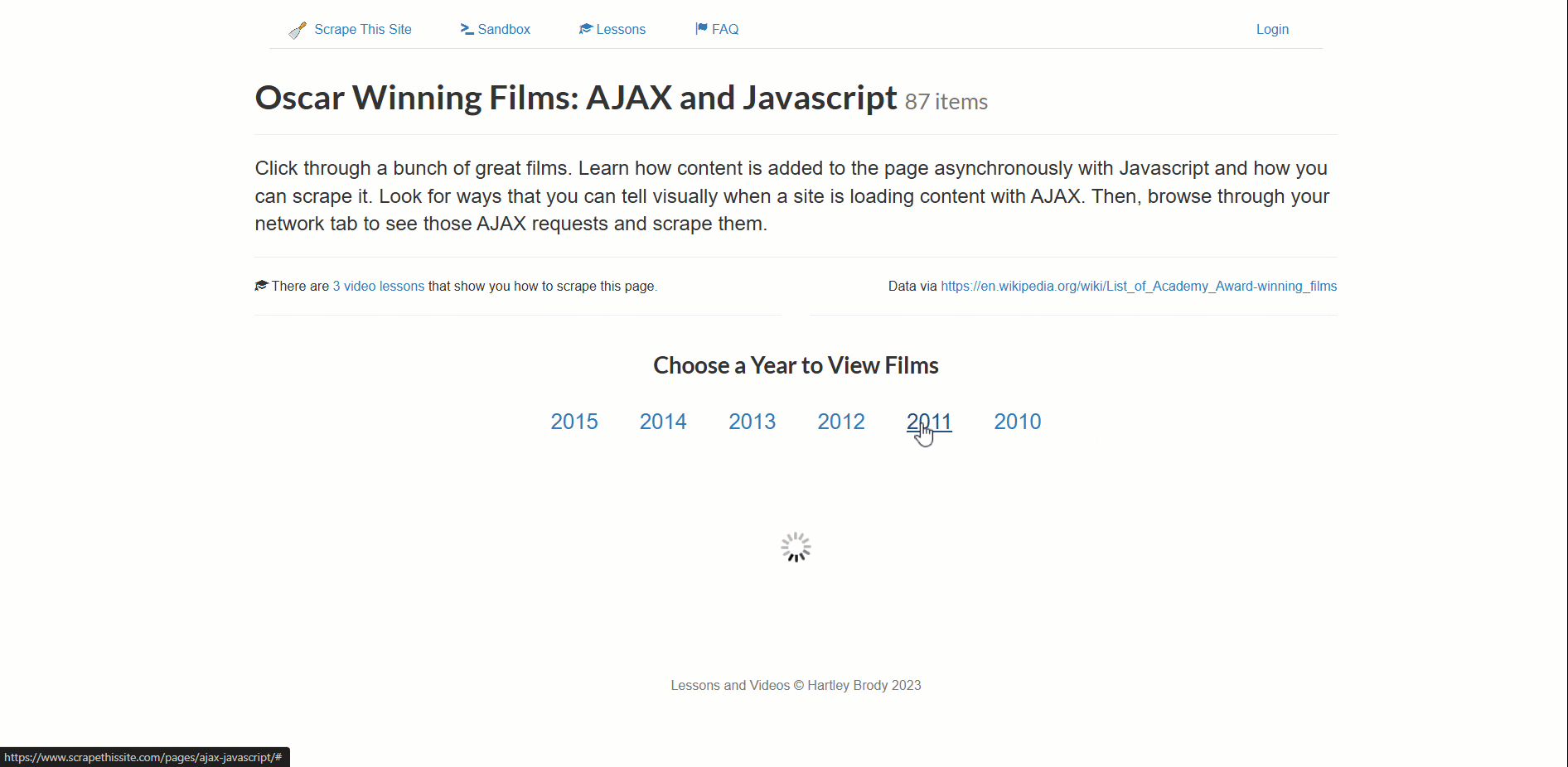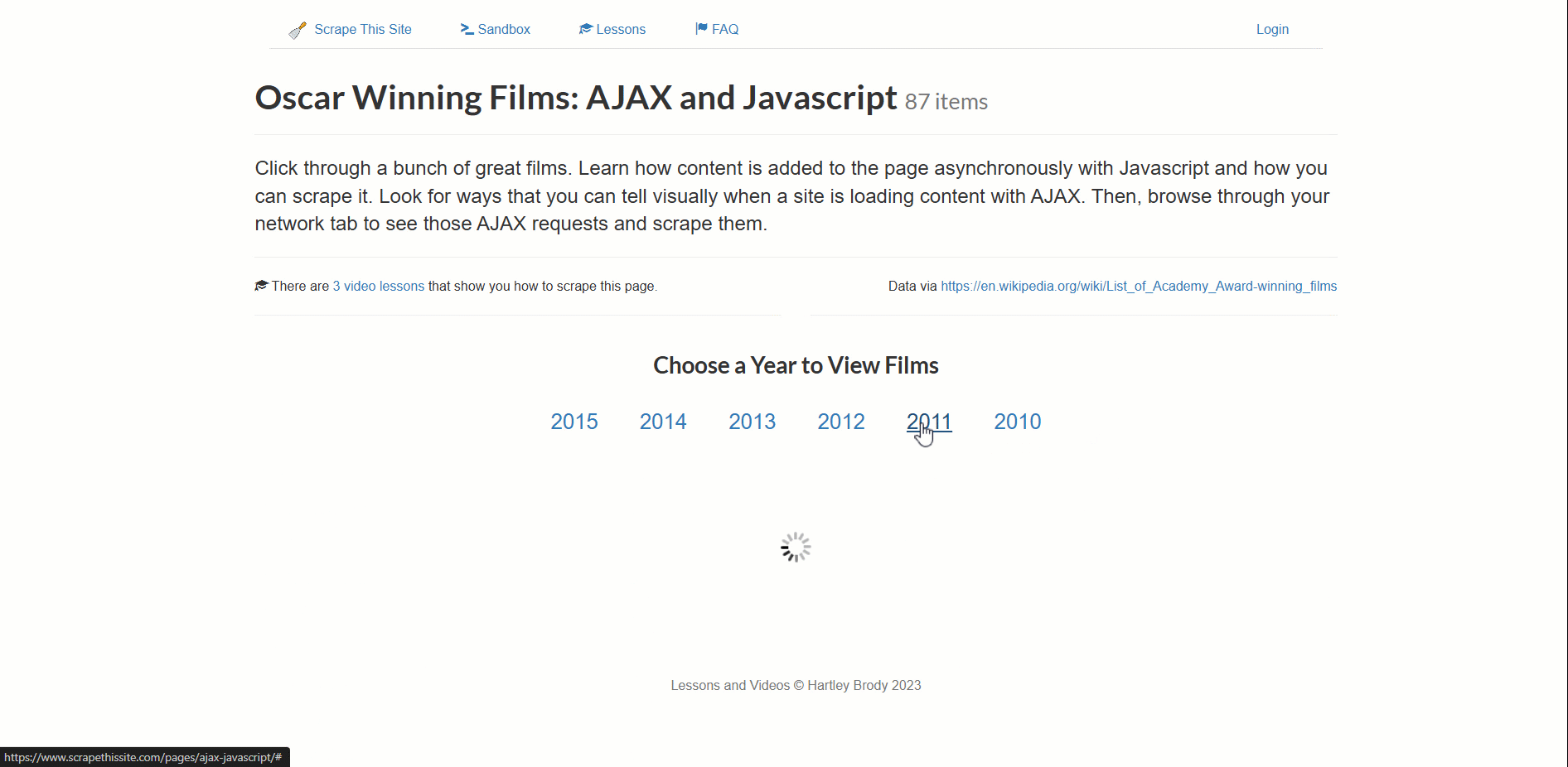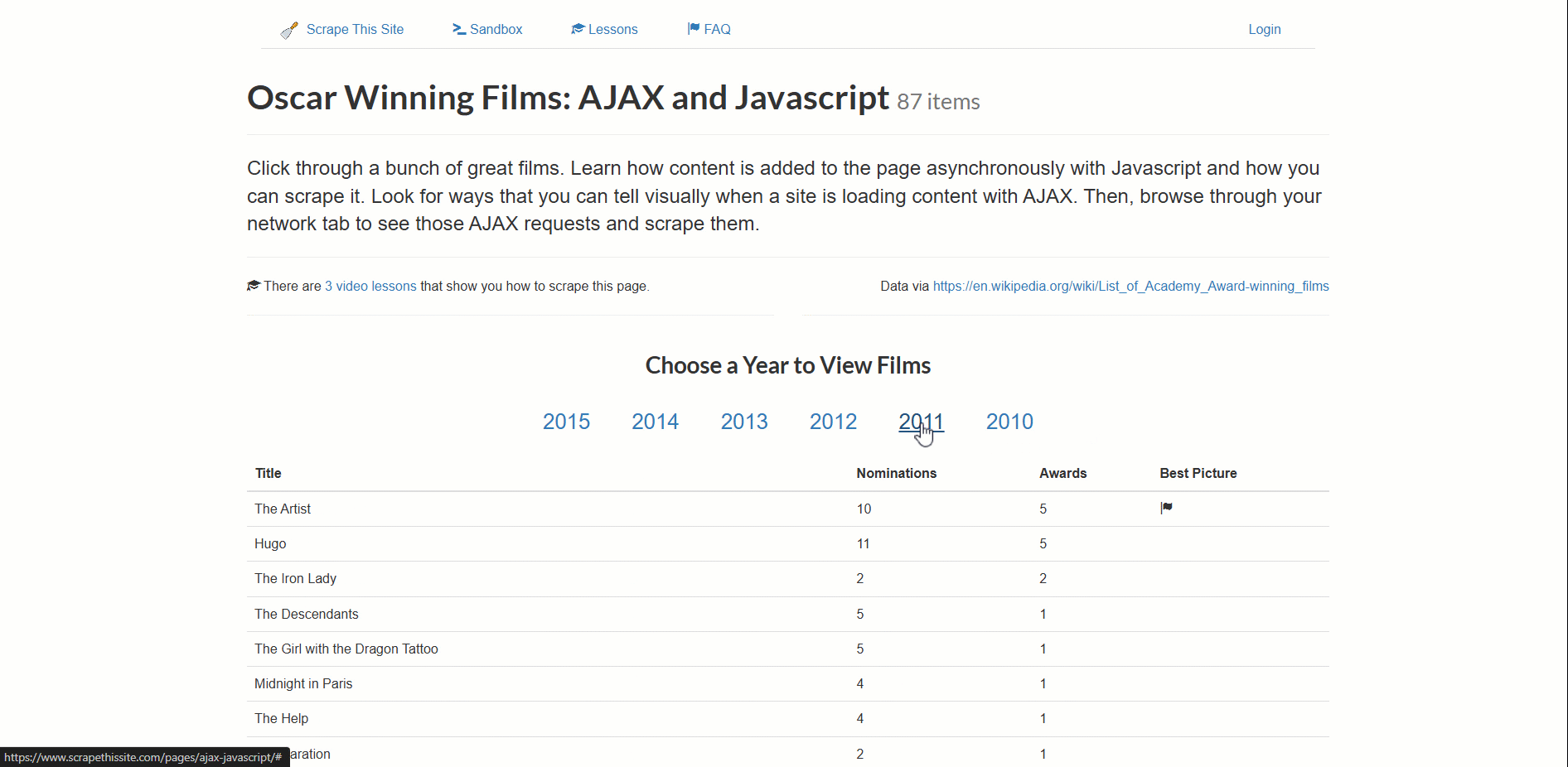
This site dynamically loads Oscar-winning film data, paginated by year.
To handle such a complex navigation, the approach is:
- Click on a new year to trigger data loading (a loader element will appear).
- Wait for the loader element to disappear (the data is now fully loaded).
- Ensure the table with the data has been rendered properly on the page.
- Scrape the data once it is available.
In detail, below is how you can implement that logic using Selenium in Python:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
# Set up Chrome options for headless mode
options = Options()
options.add_argument("--headless")
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service(), options=options)
# Connect to the target page
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/")
# Click the "2012" pagination button
element = driver.find_element(By.ID, "2012")
element.click()
# Wait until the loader is no longer visible
WebDriverWait(driver, 10).until(
lambda d: d.find_element(By.CSS_SELECTOR, "#loading").get_attribute("style") == "display: none;"
)
# Data should now be loaded...
# Wait for the table to be present on the page
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".table"))
)
# Where to store the scraped data
films = []
# Scrape data from the table
table_body = driver.find_element(By.CSS_SELECTOR, "#table-body")
rows = table_body.find_elements(By.CSS_SELECTOR, ".film")
for row in rows:
title = row.find_element(By.CSS_SELECTOR, ".film-title").text
nominations = row.find_element(By.CSS_SELECTOR, ".film-nominations").text
awards = row.find_element(By.CSS_SELECTOR, ".film-awards").text
best_picture_icon = row.find_element(By.CSS_SELECTOR, ".film-best-picture").find_elements(By.TAG_NAME, "i")
best_picture = True if best_picture_icon else False
# Store the scraped data
films.append({
"title": title,
"nominations": nominations,
"awards": awards,
"best_picture": best_picture
})
# Data export logic...
# Close the browser driver
driver.quit()
This is the breakdown of the above code:
- The code sets up a headless Chrome instance.
- The script opens the target page and clicks the “2012” pagination button to trigger data loading.
- Selenium waits for the loader to disappear using
WebDriverWait(). - After the loader disappears, the script waits for the table to appear.
- After the data is fully loaded, the script scrapes film titles, nominations, awards, and whether the film won Best Picture. It stores this data in a list of dictionaries.
The result will be:
[
{
"title": "Argo",
"nominations": "7",
"awards": "3",
"best_picture": true
},
// ...
{
"title": "Curfew",
"nominations": "1",
"awards": "1",
"best_picture": false
}
]
Note that there is not always a single optimal way to handle this navigation pattern. Other options might be required depending on the behavior of the page. Examples are:
- Use
WebDriverWait()in combination with expected conditions to wait for specific HTML elements to appear or disappear. - Monitor traffic for AJAX requests to detect when new content is fetched. This may involve using browser logging.
- Identify the API request triggered by pagination and make direct requests to fetch the data programmatically (e.g., using the
requestslibrary).
‘Load More’ Button
To represent JavaScript-based complex navigation scenarios involving user interaction, we chose the ‘Load More’ button example. The concept is simple: a list of items is displayed, and additional items are loaded when the button is clicked.
This time, the target site will be the ‘Load More’ example page from the Scraping Course:

To handle this complex navigation scraping pattern, follow these steps:
- Locate the ‘Load More’ button and click it.
- Wait for the new elements to load onto the page.
Here is how you can implement that with Selenium:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# Set up Chrome options for headless mode
options = Options()
options.add_argument("--headless")
# Create a Chrome web driver instance
driver = webdriver.Chrome(options=options)
# Connect to the target page
driver.get("https://www.scrapingcourse.com/button-click")
# Collect the initial number of products
initial_product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Locate the "Load More" button and click it
load_more_button = driver.find_element(By.CSS_SELECTOR, "#load-more-btn")
load_more_button.click()
# Wait until the number of product items on the page has increased
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > initial_product_count)
# Where to store the scraped data
products = []
# Scrape product details
product_elements = driver.find_elements(By.CSS_SELECTOR, ".product-item")
for product_element in product_elements:
# Extract product details
name = product_element.find_element(By.CSS_SELECTOR, ".product-name").text
image = product_element.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
price = product_element.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# Store the scraped data
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# Data export logic...
# Close the browser driver
driver.quit()
To deal with this navigation logic, the script:
- Records the initial number of products on the page
- Clicks the “Load More” button
- Waits until the product count increases, confirming that new items have been added
This approach is both smart and generic because it does not require knowing the exact number of elements to be loaded. Still, keep in mind that other methods are possible to achieve similar results.
Infinite Scrolling
Infinite scrolling is a common interaction used by many sites to improve user engagement, especially on social media and e-commerce platforms. In this case, the target will be the same page as above but with infinite scrolling instead of a ‘Load More’ button:
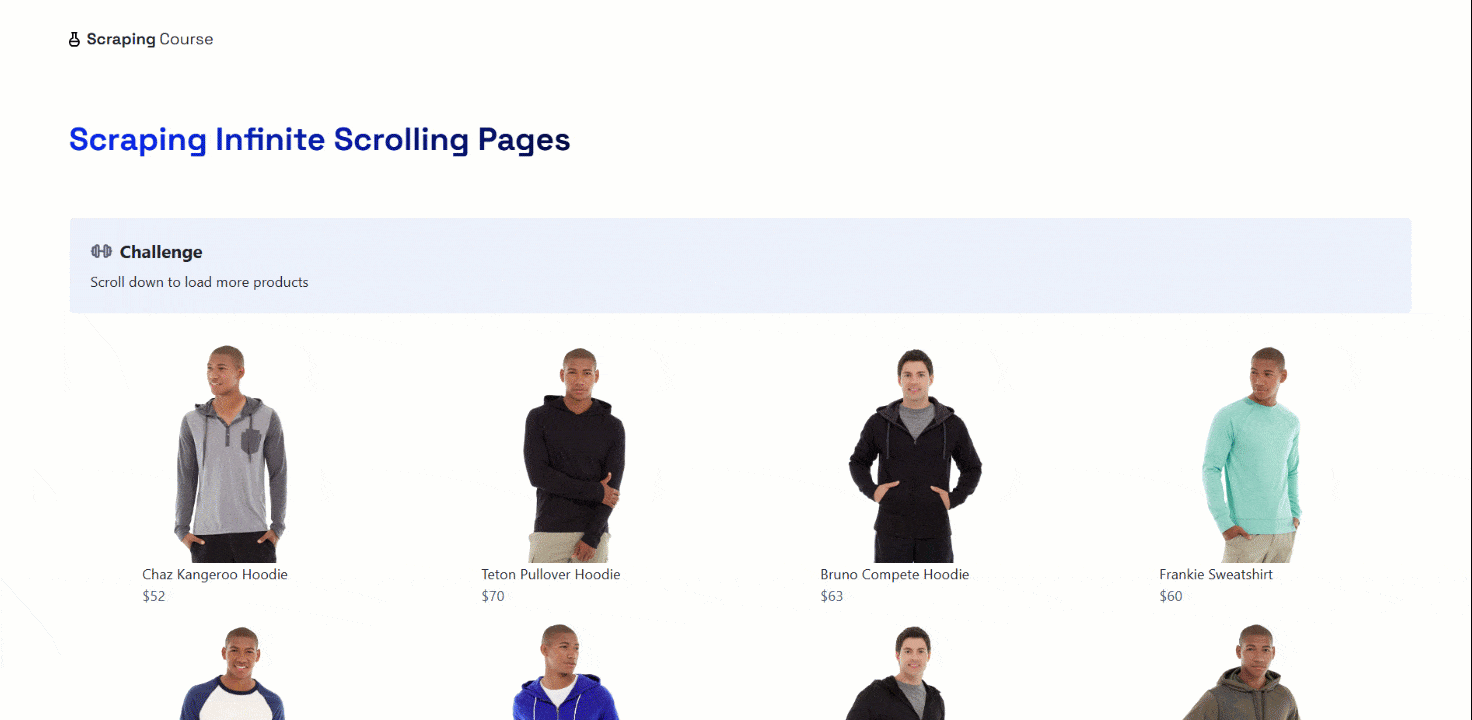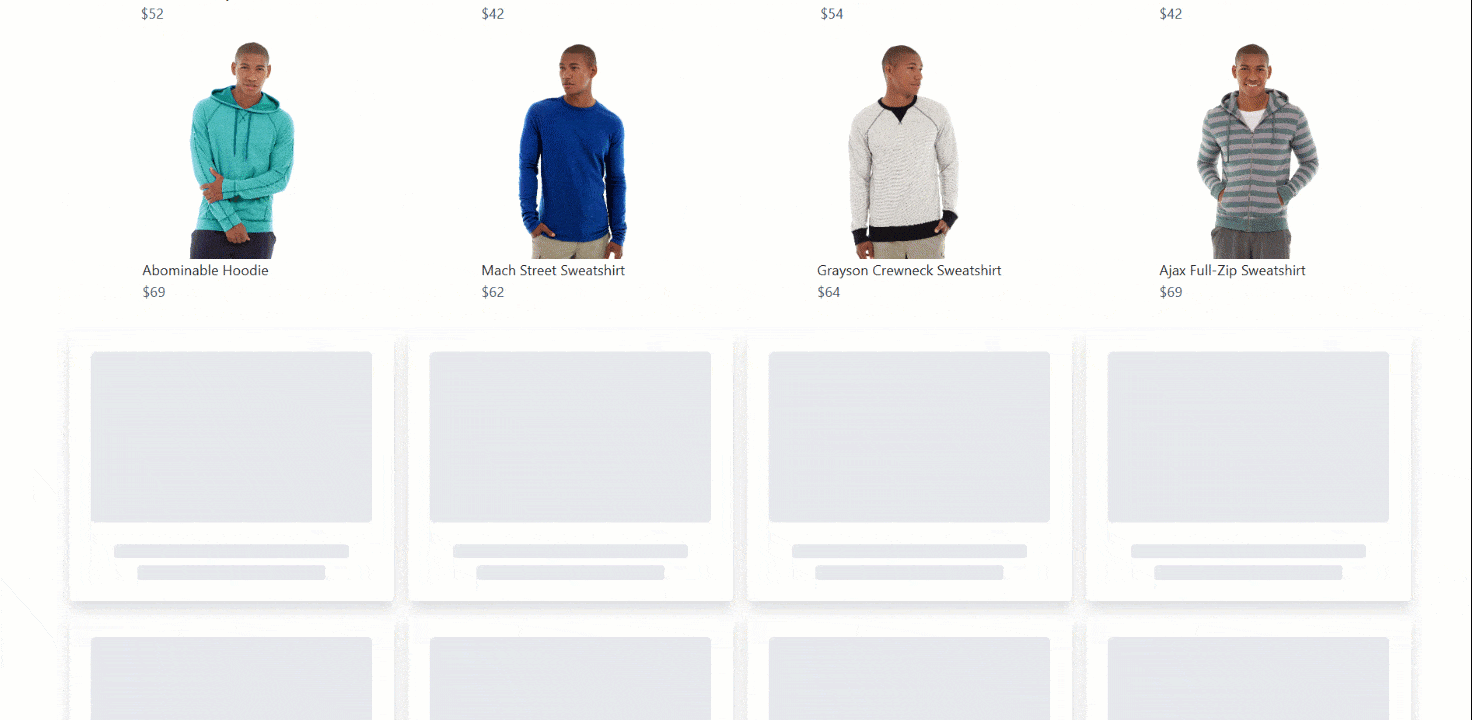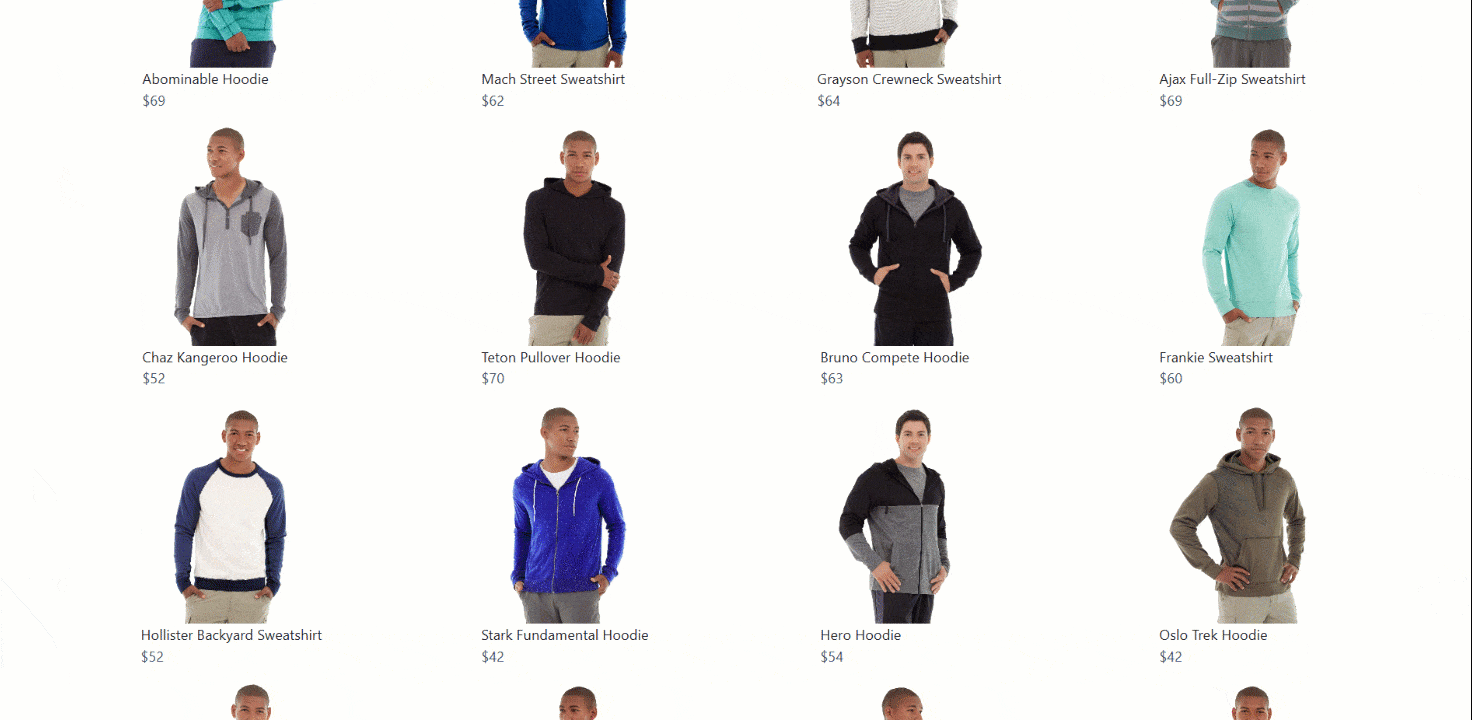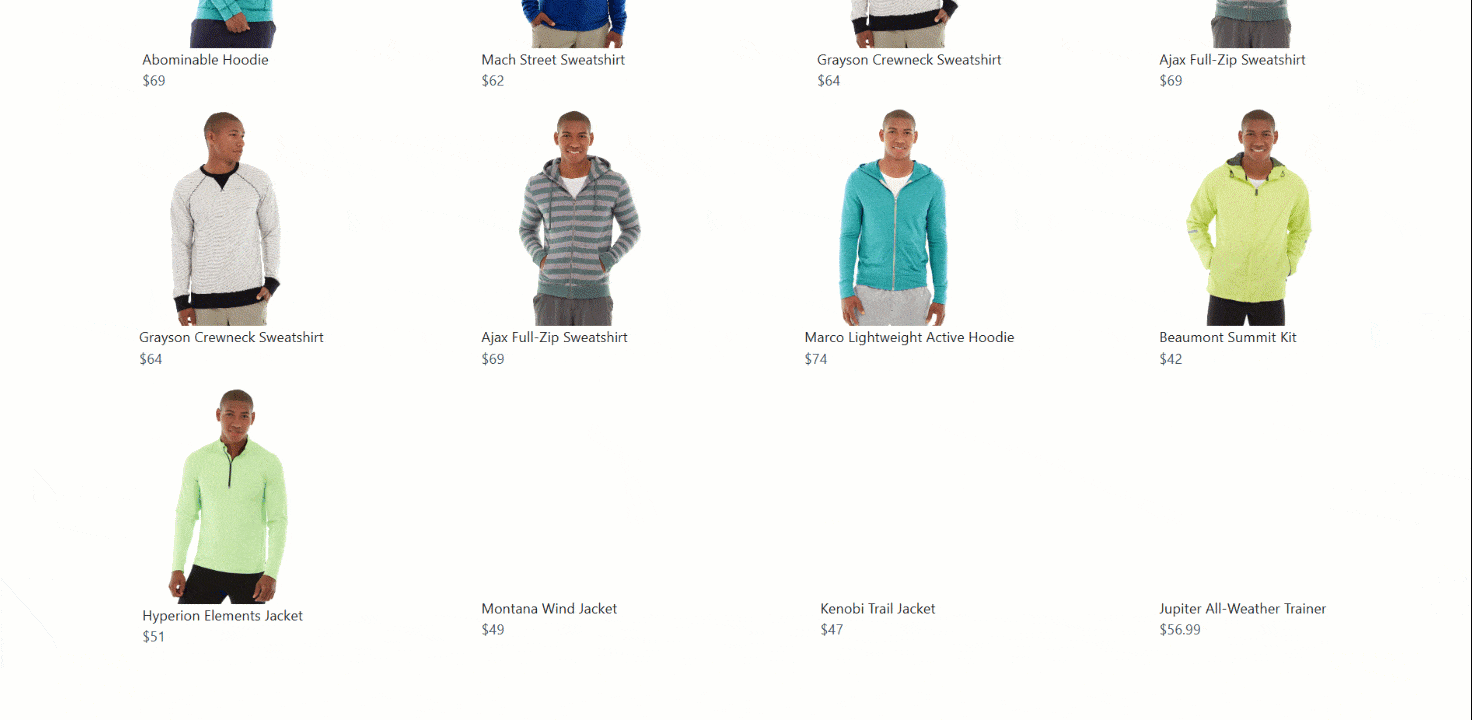
Most browser automation tools (including Selenium) do not provide a direct method for scrolling down or up a page. Instead, you need to execute a JavaScript script on the page to perform the scrolling operation.
The idea is to write a custom JavaScript script that scrolls down:
- A specified number of times, or
- Until no more data is available to load.
Note: Each scroll loads new data, incrementing the number of elements on the page.
Afterward, you can scrape the newly loaded content.
That is how you can deal with infinite scrolling in Selenium:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# Set up Chrome options for headless mode
options = Options()
# options.add_argument("--headless")
# Create a Chrome web driver instance
driver = webdriver.Chrome(options=options)
# Connect to the target page with infinite scrolling
driver.get("https://www.scrapingcourse.com/infinite-scrolling")
# Current page height
scroll_height = driver.execute_script("return document.body.scrollHeight")
# Number of products on the page
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Max number of scrolls
max_scrolls = 10
scroll_count = 1
# Limit the number of scrolls to 10
while scroll_count < max_scrolls:
# Scroll down
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Wait until the number of product items on the page has increased
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > product_count)
# Update the product count
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Get the new page height
new_scroll_height = driver.execute_script("return document.body.scrollHeight")
# If no new content has been loaded
if new_scroll_height == scroll_height:
break
# Update scroll height and increment scroll count
scroll_height = new_scroll_height
scroll_count += 1
# Scrape product details after infinite scrolling
products = []
product_elements = driver.find_elements(By.CSS_SELECTOR, ".product-item")
for product_element in product_elements:
# Extract product details
name = product_element.find_element(By.CSS_SELECTOR, ".product-name").text
image = product_element.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
price = product_element.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# Store the scraped data
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# Export to CSV/JSON...
# Close the browser driver
driver.quit()
This script manages infinite scrolling by first determining the current page height and product count. Then, it limits the scroll actions to a maximum of 10 iterations. In each iteration, it:
- Scrolls down to the bottom
- Waits for the product count to increase (indicating new content has loaded)
- Compares the page height to detect whether further content is available
If the page height remains unchanged after a scroll, the loop breaks, indicating no more data to load. That is how you can tackle complex infinite scrolling patterns.
Great! You are now a master of scraping websites with complex navigation.
Conclusion
In this article, you learned about sites that rely on complex navigation patterns and how to use Selenium with Python to deal with them. This demonstrates that web scraping can be challenging, but it can be made even more difficult by anti-scraping measures.
Businesses understand the value of their data and protect it at all costs, which is why many sites implement measures to block automated scripts. These solutions can block your IP after too many requests, present CAPTCHAs, and even worse.
Traditional browser automation tools, like Selenium, cannot bypass those restrictions…
The solution is to use a cloud-based, scraping-dedicated browser like Scraping Browser. This is a browser that integrates with Playwright, Puppeteer, Selenium, and other tools, automatically rotating IPs with each request. It can handle browser fingerprinting, retries, CAPTCHA solving, and more. Forget about getting blocked while dealing with complex sites!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



