

In this article, you will learn:
- What the data flywheel model is.
- What an AI data flywheel strategy is and why enterprises need it.
- How to implement an AI data flywheel using Bright Data services.
Let’s dive in!
What Is the Data Flywheel Model?
The flywheel model is a concept developed by Jim Collins in his book “Good to Great”. Through a comparative study, Collins identified the factors that enable companies to achieve sustained high performance, maintained over time.
In this scenario, the idea of the flywheel is perfectly explanatory of the underlying process. As you apply incremental force to a flywheel, its rotational speed and momentum increase over time until it becomes unstoppable. In that very moment, the flywheel works for you, and you just need to maintain its momentum with small forces.
This concept is important for organizations because the role of data has become increasingly significant in recent decades. For that reason, inspired by Collins’ idea, companies began applying the data flywheel model.
This is a model in which collecting, processing, and using information creates a continuous feedback loop. The principle at its core is simple: data optimises processes, which yield higher-quality information, and then that knowledge drives further gains. Over time, this virtuous cycle builds unstoppable momentum, just like forces do with a flywheel.
The Data Flywheel Model in Enterprises
For businesses, the data flywheel model, in its simplest form, can be schematized as follows:
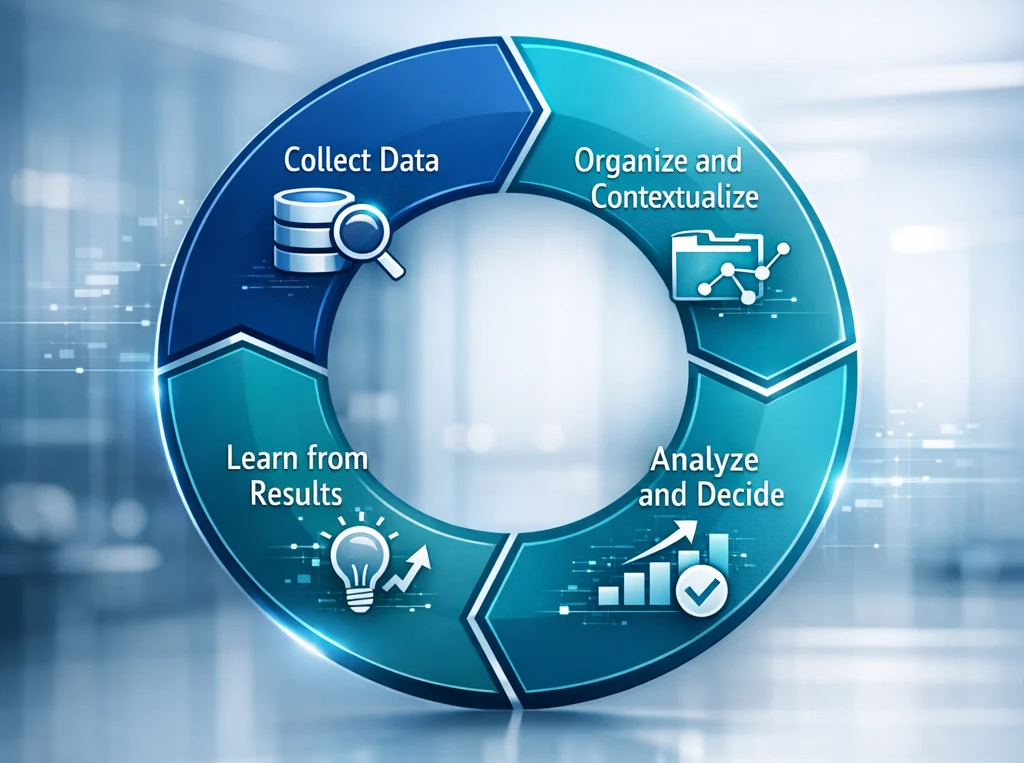
Below is an explanation of how it works:
- Collect data: The data collection step can include different sources like company internal data, web data, and customers’ interactions with your products or services.
- Organise and contextualise: After the data is collected, the next step is to organize and prepare it for analytics.
- Analyze and decide: Once the data is properly organized, you can analyze it to find patterns, deviations, and emerging trends. This helps you to make accurate and data-driven decisions.
- Learn from results: Outcomes generate new inputs, making the system smarter in subsequent cycles.
What Is an AI Data Flywheel?
With the rise of LLMs, companies got the chance to improve their data-driven processes with AI. This is where the AI data flywheel began to rise. The concept is similar to the previous one, but the underlying process is wider.
An AI data flywheel loop is a self-reinforcing cycle where data collected from different sources continuously improves AI models. Below is a schema that shows how this works at a high level for enterprises:
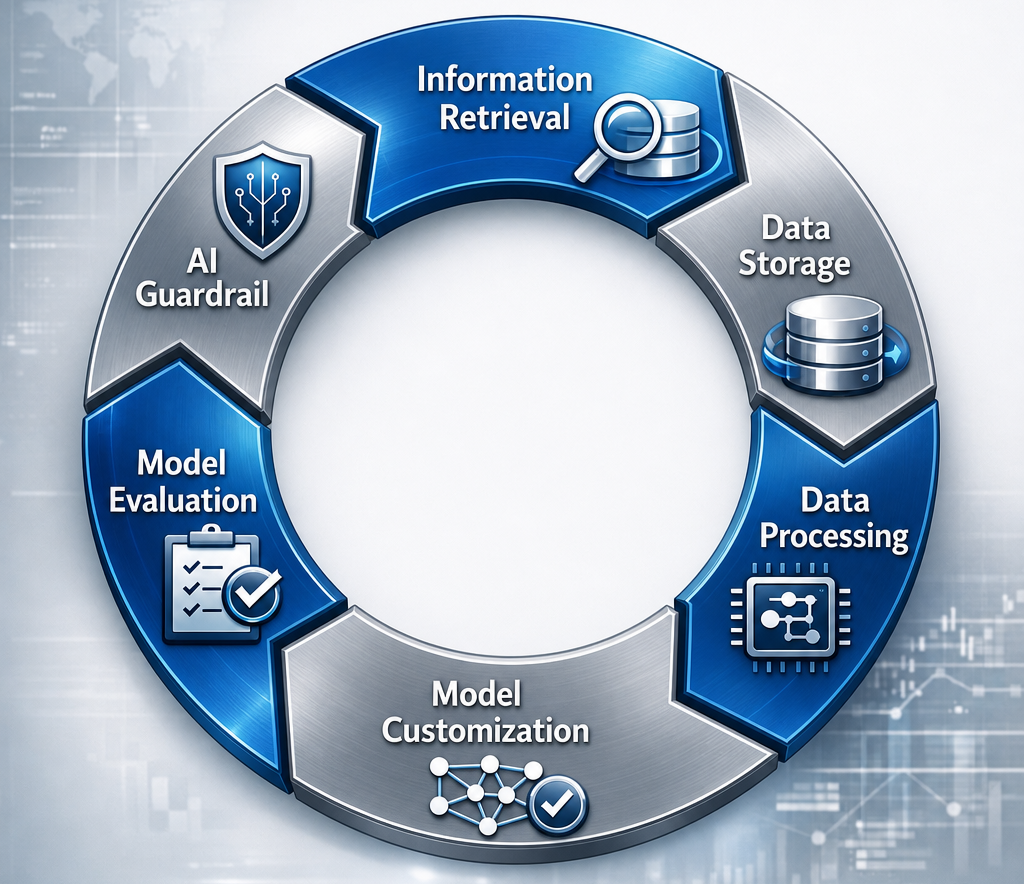
In this case, the loop is the following:
- Information retrieval: An AI data flywheel cycle starts by collecting enterprise data from different sources like the web, internal wikis and documentation, support queries and responses, interactions of customers with chatbots, and more. This also means that the data can be retrieved in different forms that include text, images, and videos.
- Data storage: The core of every data strategy, particularly for enterprises, relies on how data is stored. Since LLMs can ingest both structured and unstructured data, this means that a data storage system compatible with an AI data flywheel strategy must be able to store all the needed data types.
- Data processing: Data processing is the step of the loop that extracts the data from the storage and refines it. It is where the raw data is filtered to remove noise and prepared for LLM ingestion.
- Model customization: This step is where your AI data flywheel includes model improvements based on processes like supervised fine-tuning or Mixture of Experts (MoE). In simple terms, you feed LLMs with the data collected and processed and use it to improve the models’ capabilities. From a business point of view, this means that the LLMs learn new abilities and gain new knowledge that specifically comes from your enterprise data collection.
- Model evaluation: Customizing LLMs does not automatically guarantee that the outputs you obtain are immediately good for your application and specific use case. You have to evaluate the models’ performance and, eventually, keep improving them until the results align with your business goals.
- AI guardrail: Enterprises need data to be compliant and secure. AI guardrails are the systems that ensure your LLMs respond in compliance with your policies.
Why Do Your Enterprise Pipelines Need an AI Data Flywheel Strategy?
Data pipelines have been built around a linear logic: data flows from a source to a destination, gets transformed along the way, and feeds downstream systems. Traditionally, these data pipelines are called ETL (Extract, Transform, Load). This approach is functional but leaves a lot of value on the table because these pipelines are static.
In a business landscape steadily shaped by AI, static pipelines are no longer sufficient because they process data but do not learn from it. This is exactly where an AI data flywheel changes the equation.
By embedding a self-reinforcing loop into your enterprise data infrastructure, your pipelines stop being passive and become active drivers of continuous improvement. That way, each interaction, query, or transaction that your AI systems handle generates new data. Once new information is fed back into the cycle, it makes those systems more accurate and aligned with your business goals.
Over time, this compounding effect translates into tangible enterprise advantages like:
- Reduced operational costs.
- Faster and more reliable decision-making.
- AI models that grow more capable as your business scales.
In other words, the more your pipelines work, the smarter they get. And the smarter they get, the more value they return to the organization.
Benefits of Using an AI Flywheel Strategy
When implemented correctly, the benefits of an AI data flywheel strategy extend beyond model performance. Here is how companies can benefit from implementing such a model:
- Continuous model improvement: Unlike static AI deployments that degrade in quality over time as data distributions shift, an AI data flywheel ensures your models are constantly refined with fresh data. Every new interaction becomes a training signal, meaning your AI systems grow more accurate and relevant. All this, without requiring costly manual retraining cycles from scratch.
- Compounding competitive advantage: The flywheel effect is, by nature, cumulative. Organizations that begin the cycle earlier accumulate proprietary data assets and model improvements that competitors cannot replicate. Over time, this creates a structural moat: the longer the flywheel spins, the harder it becomes for competitors to close the gap.
- Reduction of operational costs at scale: As AI models become more capable through active learning, they can handle increasingly complex tasks with less human intervention. This translates into the automation of repetitive workflows at a high volume.
- Faster and more accurate decision-making: An AI flywheel strategy ensures that the models powering your analytics tools are fed with the most current and contextually relevant data. This reduces the latency between events and insights, enabling leadership to act on accurate information in near real time.
- Deep enterprise personalisation: As the flywheel ingests interaction data from customers, internal users, and business processes, AI models develop a granular understanding of enterprise-specific patterns and needs. This enables a level of personalisation that general-purpose AI models cannot achieve.
- Improved data governance and compliance: A well-structured AI flywheel integrates guardrails and evaluation layers directly into the loop. This means compliance and security are built-in checkpoints that keep validating model outputs against evolving regulatory and business requirements.
How Bright Data Can Help You Implement An AI Data Flywheel Strategy
Bright Data services sit at the top of the AI data flywheel cycle, helping you by retrieving current data from the web, particularly thanks to the following services:
- Web data marketplace: A collection of 350+ AI-ready datasets covering over 250 domains. They are shipped in multiple formats, like JSON, CSV, and Parquet, via cloud delivery and other distribution methods.
- Web scraping products: A suite of API-based solutions for live web data extraction that include:
– SERP API: Delivers structured search results from search engines like Google, Bing, and others in real-time.
– Discover API: Returns a ranked set of URLs from the web, ready for AI ingestion.
– Crawl API: Performs scalable website crawling for structured data extraction.
– Scraper APIs: Cover 120+ websites for direct data extraction from popular domains.
- MCP server: Bright Data MCP server enables AI applications to access, discover, and extract web data in real-time. It allows you to create AI agents connected with clients like Claude Desktop, Cursor, and all other MCP-compatible solutions to search the web in real time, take actions, and retrieve data without getting blocked.
What makes Bright Data stand out is its enterprise-grade scraping infrastructure, which is based on:
- A 400M+ residential proxy network distributed across 195 countries, which supports highly scalable and concurrent web data collection.
- Compliant with GDPR, CCPA, and other high-level privacy and security certifications like ISO27001, SOC2, and more.
Also, what makes Bright Data particularly suitable for an AI data flywheel strategy is its integration capability. Data is usable as long as it is stored in your enterprise data storage. Bright Data services seamlessly integrate with Snowflake, S3 buckets, and several other cloud providers (GCP, Azure, AWS, etc.). This allows you to integrate Bright Data’s services while still using the storage service of your choice.
How To Implement an AI Data Flywheel Strategy With Bright Data
Implementing an AI data flywheel strategy requires assembling the right services at each layer of the loop. As introduced before, Bright Data fits into the data retrieval layer, acting as the entry point of the cycle.
Below is a high-level architecture of how an AI data flywheel strategy can be implemented using Bright Data services at the collection layer:
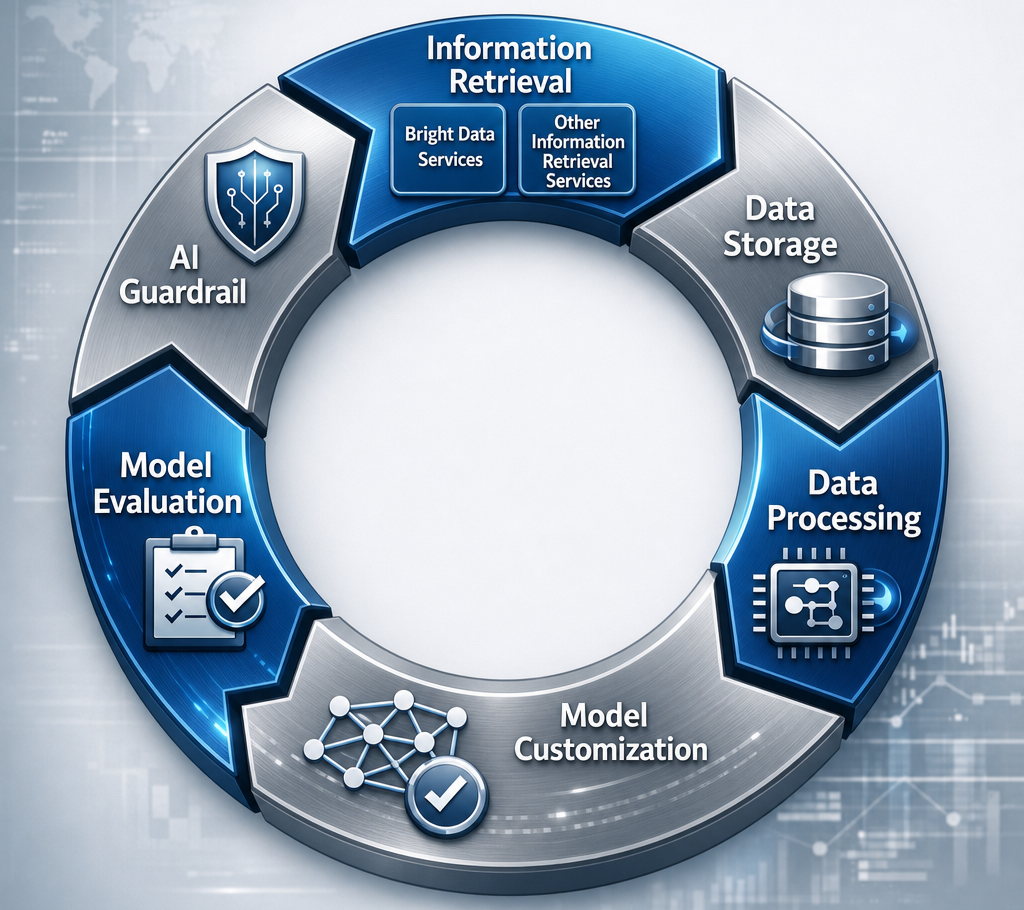
With this architecture in mind, let’s look at two concrete enterprise use cases where Bright Data powers the flywheel.
Competitive Intelligence for Financial Services
Financial institutions operate in markets where conditions change rapidly. Prices, sentiment, regulatory updates, and competitor positioning all change in near real time. A static dataset, even a recent one, quickly becomes old.
In this context, an AI data flywheel powered by Bright Data can be structured as follows:
- Data retrieval: Rely on Bright Data’s SERP API and Scraper APIs to collect structured data from financial news outlets, earnings reports, regulatory bodies, and platforms like Reddit to intercept users’ sentiment.
- Data storage and processing: Scraped data flows into a Snowflake instance via Bright Data’s native integration, where it is cleaned, deduplicated, and enriched with contextual metadata before being made available for model ingestion.
- Model customization: An LLM is periodically fine-tuned on the refreshed corpus to improve its understanding of domain-specific financial terminology, competitor strategies, and market patterns.
- AI application: The refined model powers an internal analytics tool that surfaces competitive insights, flags regulatory risks, and generates automated briefings for analysts and decision-makers.
- Flywheel feedback: Interactions with the tool are logged as new training signals. These signals re-enter the storage layer, prompting fresh data collection targeted at the gaps the model exposed.
Over time, the model becomes progressively specialized for the institution’s specific market focus, building a proprietary intelligence asset that no off-the-shelf AI product can replicate.
Customer Experience Optimization for E-Commerce
For large e-commerce enterprises, staying aligned with customer expectations is a major challenge. Product preferences shift, competitor pricing changes daily, and customer sentiment evolves across dozens of platforms. Relying on periodic surveys or quarterly reviews is no longer sufficient to remain competitive.
In this scenario, the AI data flywheel built using Bright Data’s offer can work as follows:
- Data retrieval: Bright Data’s Scraper APIs extract structured product reviews, ratings, and Q&A content from platforms like Amazon, Trustpilot, and Google Shopping. Alternatively, you can download AI-ready datasets from the Web Data Marketplace, which provides you with several refreshing options.
- Data storage and processing: Extracted data lands in an S3 bucket through Bright Data’s native cloud delivery, where it is processed and prepared for LLM ingestion.
- Model customization: An LLM is fine-tuned using the scraped and processed data. This makes the model develop a granular understanding of how real customers describe product needs, pain points, and satisfaction drivers.
- AI application: The fine-tuned model drives personalized product recommendations, proactive support responses, and dynamic pricing suggestions aligned with market positioning.
- Flywheel feedback: Every customer interaction with the system generates new behavioural signals. These are routed back into the data pipeline to update it and refine the model.
The result is a system that sharpens its understanding of customer needs, reducing churn and outperforming competitors that rely on manual analytics systems.
Pros and Cons of Implementing an AI Data Flywheel Strategy
As with any enterprise initiative, adopting an AI data flywheel strategy comes with great opportunities and challenges. Understanding both sides of the equation is essential for organizations that want to invest wisely and set realistic expectations.
👍 Pros:
- Self-sustaining value creation: Once the flywheel reaches sufficient momentum, it generates improvements autonomously. Companies no longer need to keep injecting resources to see gains as the cycle compounds on itself, delivering increasing returns over time with proportionally lower marginal effort.
- Proprietary data as a strategic asset: The flywheel incentivizes systematic data collection and pre-processing, which, over time, builds a proprietary data foundation that is unique to your business. This asset is not replicable by competitors and becomes one of the most defensible sources of long-term competitive advantage.
- Scalability without proportional cost growth: Because AI models trained through the flywheel become progressively more capable, enterprises can scale operations without a corresponding increase in headcount or infrastructure spending.
- Alignment between AI and business context: Continuous retraining on enterprise-specific data ensures that models remain tightly aligned with the language, processes, and goals of your organization. In other words, you start with a general-purpose LLM and end up with a specialized model that has a unique and profound knowledge of your business needs.
👎 Cons:
- High upfront investment: Initiating an AI data flywheel requires substantial initial capital. Building or integrating the storage, processing, and model customization is an undertaking that demands investment in both technology and talent before any return is visible.
- Expertise and talent requirements: Operating an AI data flywheel at an enterprise level is not a task that generalist IT teams can absorb. It requires specialized expertise spanning data engineering, MLOps, and AI. These profiles are scarce and costly.
- Slow start, delayed returns: The flywheel metaphor itself implies that early momentum is hard to build. In the initial phases, the benefits are modest, and the costs are high. You must be prepared for an extended ramp-up period before the compounding effects of the cycle become measurable and meaningful.
- Governance and compliance complexity: As the volume and variety of data flowing through the flywheel grows, so does the surface area for regulatory risk. Enterprises operating across multiple jurisdictions must ensure that data collection, storage, and model training practices remain compliant with frameworks such as GDPR and CCPA.
Conclusion
In this AI data flywheel article, you discovered where the concept of flywheel originated and what an AI data flywheel strategy is. You also saw why this matters for your company and how Bright Data can help you implement it.
Bright Data enters the game in the AI information retrieval layer, helping you extract data from the web without managing the scraping infrastructure. Thanks to its enterprise-grade infrastructure and broad integration capabilities, it lets you scrape the data you need and store it in the services you already use.
Create a Bright Data account for free to start integrating our web data solutions!

Technical Writer
Federico Trotta is a technical writer, editor, and data scientist. Expert in technical content management, data analysis, machine learning, and Python development.




