

In this article, you will learn:
- What data validation is, when to use it, the checks it involves, and which libraries you should use to implement it.
- How to perform data validation with a real-world Python example.
- What data verification is, how it works, examples of verification checks, and best approaches.
- How to implement data verification using a dedicated AI agent.
- A summary table comparing data validation vs data verification.
Let’s dive in!
Data Validation: Everything You Need to Know
Start this data validation vs data verification journey by exploring the first approach: data validation.
What Is Data Validation and Why Is It Important?
Data validation is the process of checking the accuracy, quality, and integrity of data. It is typically performed before data is stored, used, or processed. Its ultimate goal is to guarantee a consistent level of quality and trust.
In particular, this technique verifies that data follows defined rules and standards. It prevents incorrect or incomplete information from entering a system, application, workflow, or continuing through a data pipeline.
Data validation is fundamental for maintaining high data quality. Validating data also plays a major role in meeting compliance requirements like GDPR and CCPA, as well as following security best practices.
By applying data validation, you can catch errors and issues in your data early. This helps identify problems in the data lifecycle before they escalate, preventing costly mistakes and serious complications.
Examples of Data Validation Checks
The data validation checks you can apply are countless and depend on your specific needs, the type of data fields, and particular scenarios. Some of the most important checks include:
- Data type check: Confirms that data entered into a field is of the correct type (e.g., ensuring that an
agefield only accepts numbers). - Format check: Verifies that data conforms to a specific pattern, such as a phone number format like
(XXX) XXX-XXXX, a date format likeYYYY-MM-DD, or an email format like[email protected]. - Range check: Ensures that a numeric value falls within a predefined minimum and maximum range (e.g., a
scorefield must be between0and100). - Presence check: Confirms that a mandatory field is not left blank or null, making sure that no critical information is missing.
- Code check: Validates that an entry is selected from a predefined list of acceptable values (e.g., a country code from the ISO 3166 list).
- Consistency check: Verifies that data across multiple fields within the same entry or across different entries is logical and consistent (e.g., an order date must be before the delivery date).
- Uniqueness check: Prevents duplicate entries in fields that require unique values, such as an employee ID or email address.
When to Perform It
As a rule of thumb, data validation should be performed continuously throughout the data lifecycle. At the same time, the earlier it occurs, the more effectively it prevents errors from spreading. This is known as a “shift-left” approach to data quality.
So, the most proactive and efficient time to validate data is at the point of entry. Catching errors there ensures that bad data never enters your systems, saving time and resources on downstream cleansing. This applies to data entered by users (e.g., via forms or file uploads), data retrieved through web scraping, or data from public or open repositories you do not fully trust.
For user-submitted data, such as via an API in a backend system, real-time validation can provide immediate feedback (e.g., flagging an incorrectly formatted email address or an incomplete phone number direcly in the API response with 400 Bad Request errors).
However, it is not always possible to validate data immediately. For example, in ETL or ELT pipelines, validation is generally applied at specific stages:
- After extraction: To check that data pulled from a source system has not been corrupted or lost during transit.
- After transformation: To verify that the output of each transformation step (e.g., aggregations) meets the expected rules and standards.
Even after data is stored, you should re-verify it periodically. That is because data is not static, as it can be updated, enriched, or repurposed. Thus, there is a need for ongoing validation.
How to Validate Data
The process of data validation involves the following steps:
- Define requirements: Establish clear validation rules based on business needs, regulatory standards, and expectations (e.g., define a schema with rules for your data).
- Collect data: Gather data from various sources, such as web scraping, APIs, or databases.
- Apply validation: Implement the defined rules to check the data for accuracy, consistency, and completeness.
- Handle errors: Log, quarantine, or correct invalid records according to organizational policies. Provide users with clear feedback when they enter incorrect data.
- Load data: Once the data is validated and clean, load it into the target system, such as a data warehouse.
Note: You will see how to apply these steps in the next chapter through a guided Python example.
Libraries for Data Validation
Below is a table with some of the best open-source libraries for data validation:
| Library | Programming Language | GitHub Stars | Description |
|---|---|---|---|
| Pydantic | Python | 25.3k+ | Data validation using Python type hints |
| Marshmallow | Python | 7.2k+ | A lightweight library for converting complex objects to and from simple Python datatypes |
| Cerberus | Python | 3.2k+ | Lightweight, extensible data validation library for Python |
| jsonschema | Python | 4.8k+ | An implementation of the JSON Schema specification for Python |
| Validator.js | JavaScript | 23.6k+ | A library of string validators and sanitizers. |
| Joi | JavaScript | 21.2k+ | The most powerful data validation library for JS |
| Yup | JavaScript | 23.6k+ | Dead simple Object schema validation |
| Ajv | JavaScript | 14.4k+ | The fastest JSON schema Validator. Supports JSON Schema draft-04/06/07/2019-09/2020-12 and JSON Type Definition (RFC8927) |
| FluentValidation | C# (.NET) | 9.5k+ | A popular .NET validation library for building strongly-typed validation rules |
| validator | Go | 19.1k+ | Go Struct and Field validation, including Cross Field, Cross Struct, Map, Slice and Array diving |
How to Apply Data Validation in Python: Step-by-Step Example
In this guided walkthrough, you will learn how to apply data validation to input data in JSON using Pydantic. This tutorial will cover the main aspects of building a process for validating data.
Scenario Description
Assume you are retrieving data from an e-commerce site. In particular, focus on this product web page:
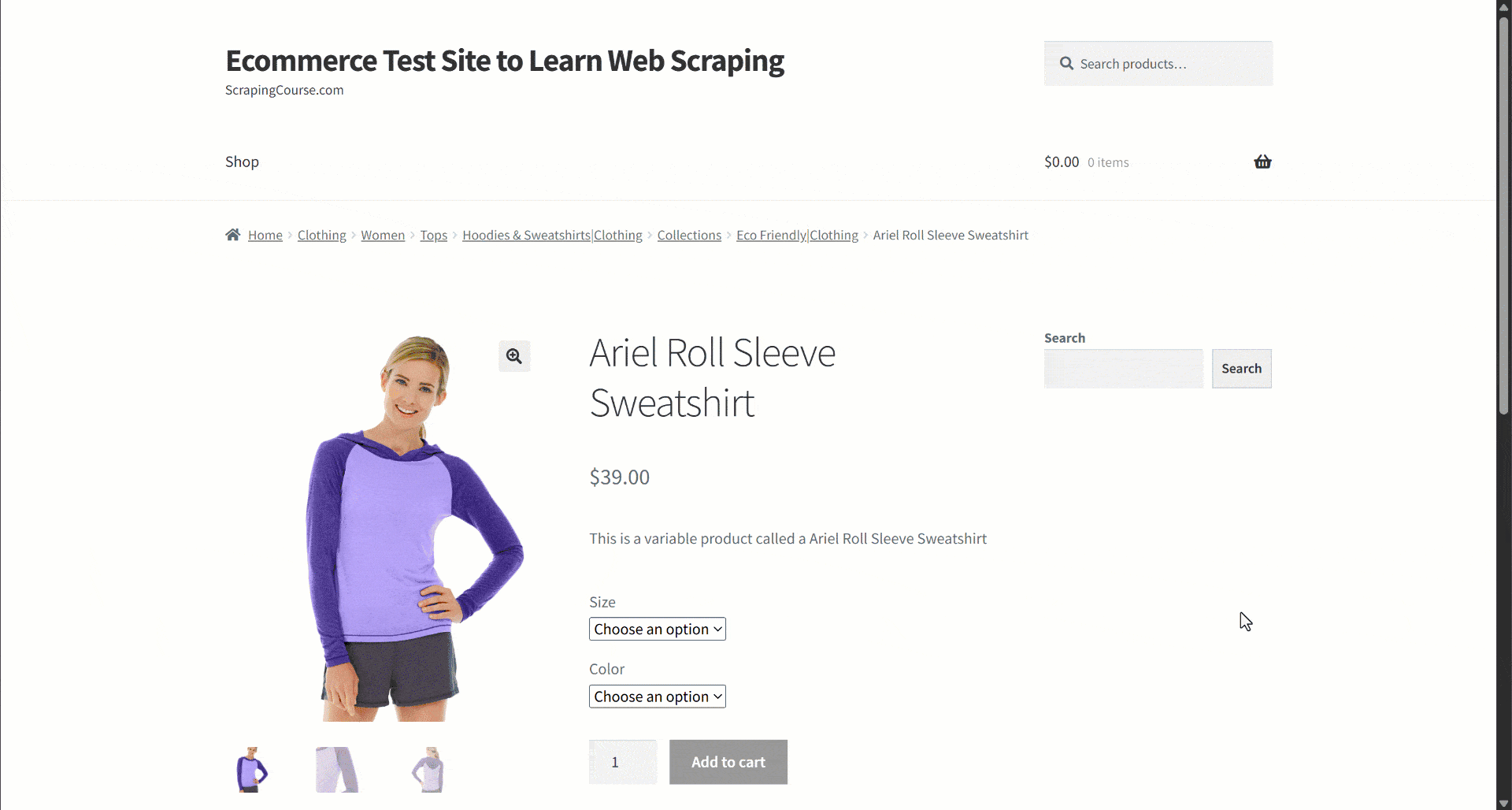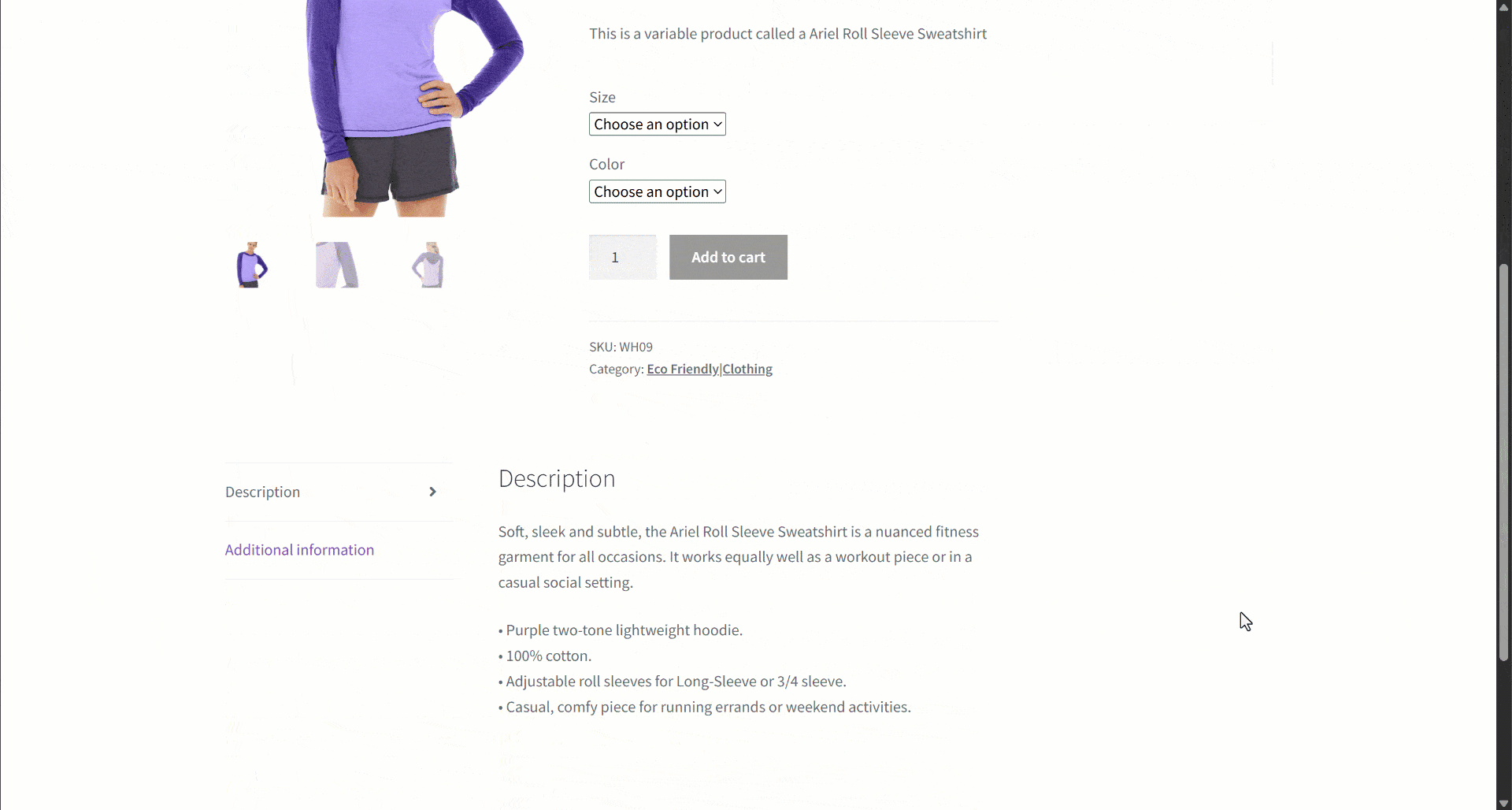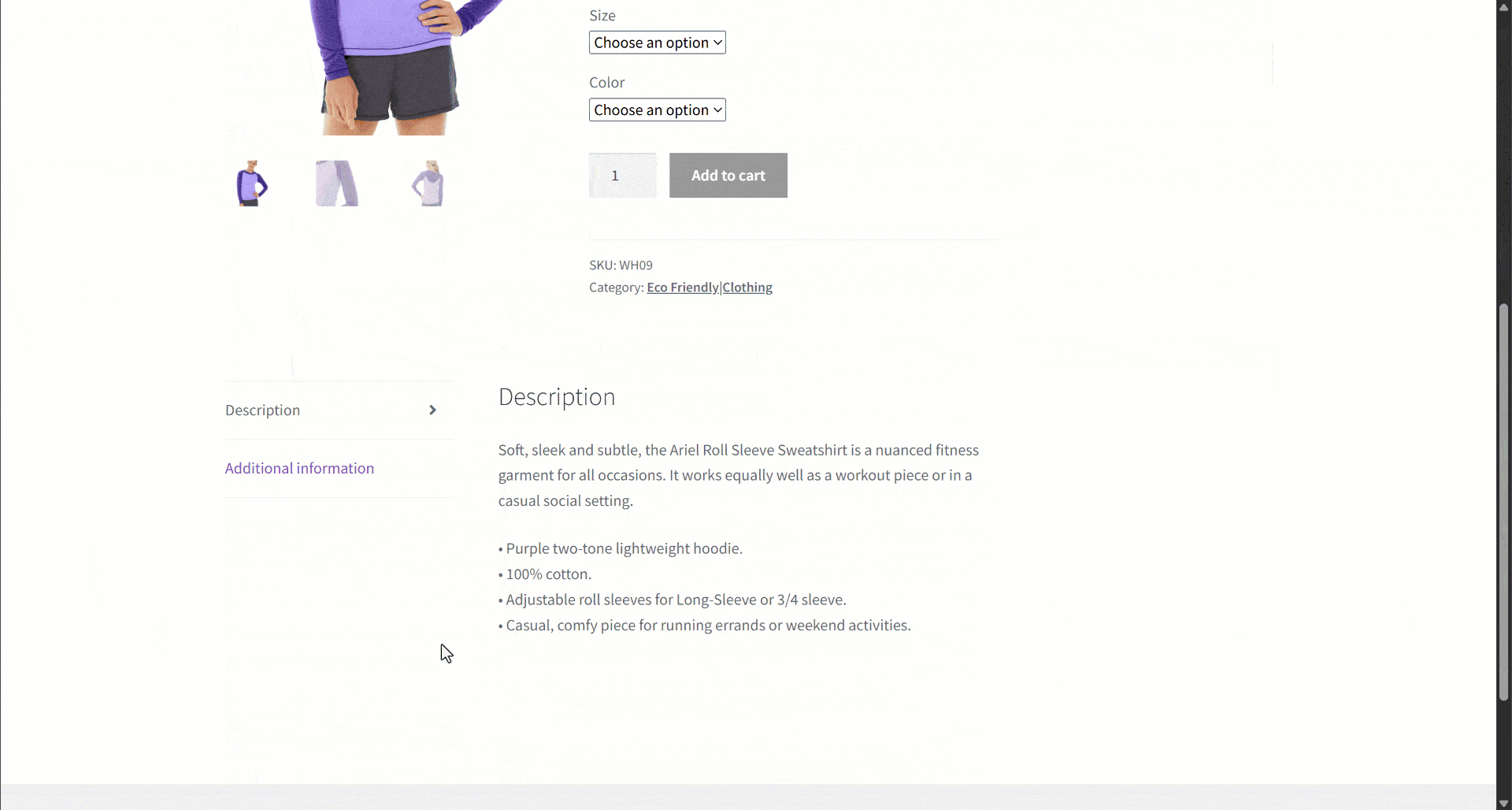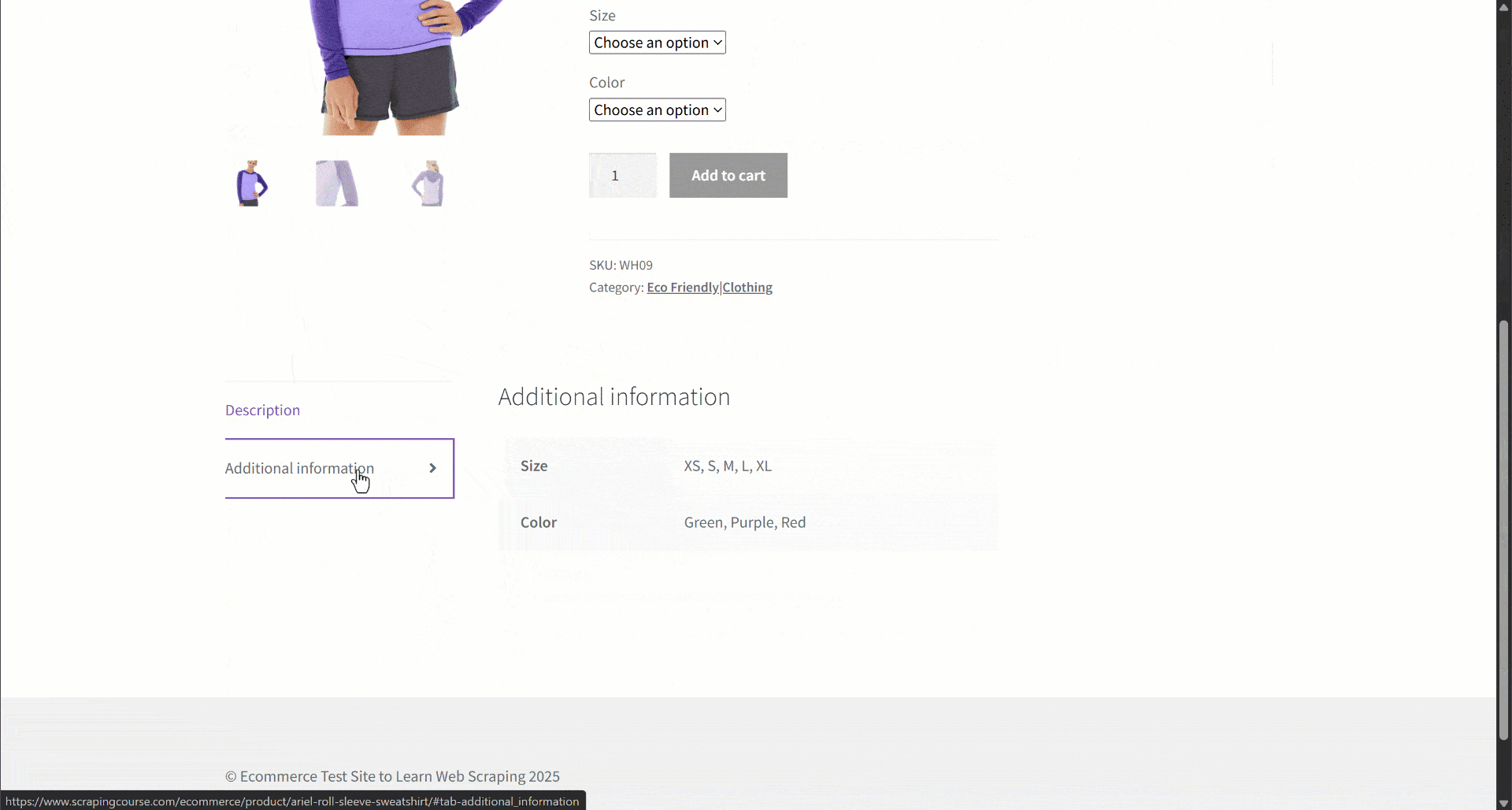
During data extraction, you provide the page content to an LLM for simplified data parsing. Now, LLMs can be imprecise, and they may produce made-up, unreliable, or incomplete data. That is why applying data validation is so pivotal.
For simplicity, we will assume that you already have a Python project with a development environment set up.
Step #1: Define the Target Schema and Rules
Start by inspecting the target page and notice that the product page contains the following fields:
- Product URL: The URL of the product page.
- Product name: A string containing the product name.
- Images: A list of image URLs.
- Price: The price as a float number.
- Currency: A single character representing the currency.
- SKU: A string containing the product ID.
- Category: An array containing one or more categories.
- Description: A text field with the product description.
- Long description: A text field containing the full product description with all details.
- Additional Information: An object containing:
- Size options: An array of strings with the available sizes.
- Color options: An array of strings with the available colors.
Then, represent that in a Pydantic model as shown below:
# pip install pip install pydantic
from typing import List, Optional, Annotated
from pydantic import BaseModel, ConfigDict, HttpUrl, PositiveFloat, StringConstraints, model_validator
class AdditionalInformation(BaseModel):
size_options: Optional[List[str]] = None # nullable
color_options: Optional[List[str]] = None # nullable
class Product(BaseModel):
model_config = ConfigDict(strict=True, extra="forbid")
product_url: HttpUrl # required, must be a valid URL
product_name: str # required
images: Optional[List[HttpUrl]] = None # list of valid URLs, nullable
price: Optional[PositiveFloat] = None # nullable, must be >= 0
currency: Optional[Annotated[str, StringConstraints(min_length=1, max_length=1)]] = None # nullable, single character
sku: str # required
category: Optional[List[str]] = None # nullable
description: Optional[str] = None # nullable
long_description: Optional[str] = None # nullable
additional_information: Optional[AdditionalInformation] = None # nullable
@model_validator(mode="after")
# Custom validation rule to make sure that the price is always associated with a currency
def check_currency_if_price(cls, values):
price = values.price
currency = values.currency
if price is not None and not currency:
raise ValueError("currency must be provided if price is set")
return valuesNote that the Product model not only defines the fields and their types (e.g., str, HttpUrl, etc.) but also includes validation constraints (e.g., the currency must be a single character). Plus, it includes strict validation rules to ensure that the price is always associated with a currency, and any extra fields that do not directly match the model are forbidden.
Step #2: Collect the Data
Suppose you retrieve data via AI web scraping, as shown in one of the tutorials below:
- Web Scraping with ChatGPT: Step-By-Step Tutorial
- Web Scraping With Gemini: Complete Tutorial
- Web Scraping Using Perplexity: Step-By-Step Guide
- Web Scraping with Claude: AI-Powered Parsing in Python
You will end up with a product.json file containing the scraped data. Here, we will assume the LLM populated it like this:
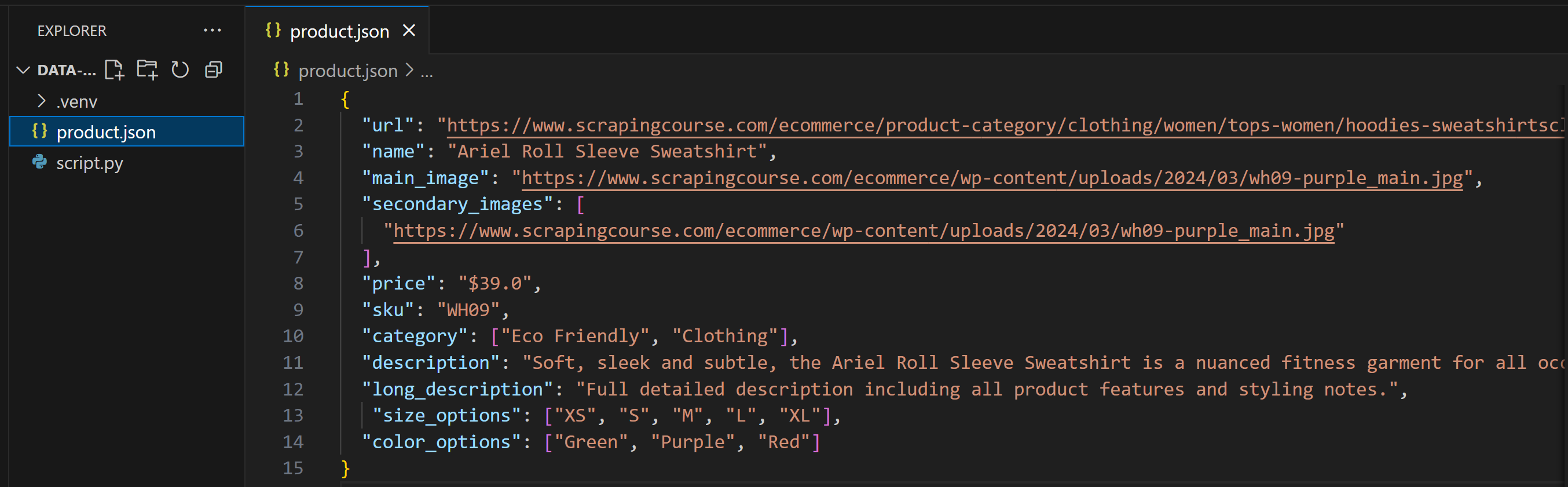
As you can tell, this output does not exactly match the Pydantic model. This is common if you do not explicitly specify an output structure in your prompt, or if the AI is configured with a temperature that is too high.
Step #3: Apply the Validation Rules
Load the data from the product.json file:
import json
input_data_file_name = "product.json"
with open(input_data_file_name, "r", encoding="utf-8") as f:
product_data = json.load(f)Then, validate it with Pydantic as follows:
try:
# Validate the data through the Pydantic model
product = Product(**product_data)
print("Validation successful!")
except ValidationError as e:
print("Validation failed:")
print(e)Execute your script, and you will get an error output like this:
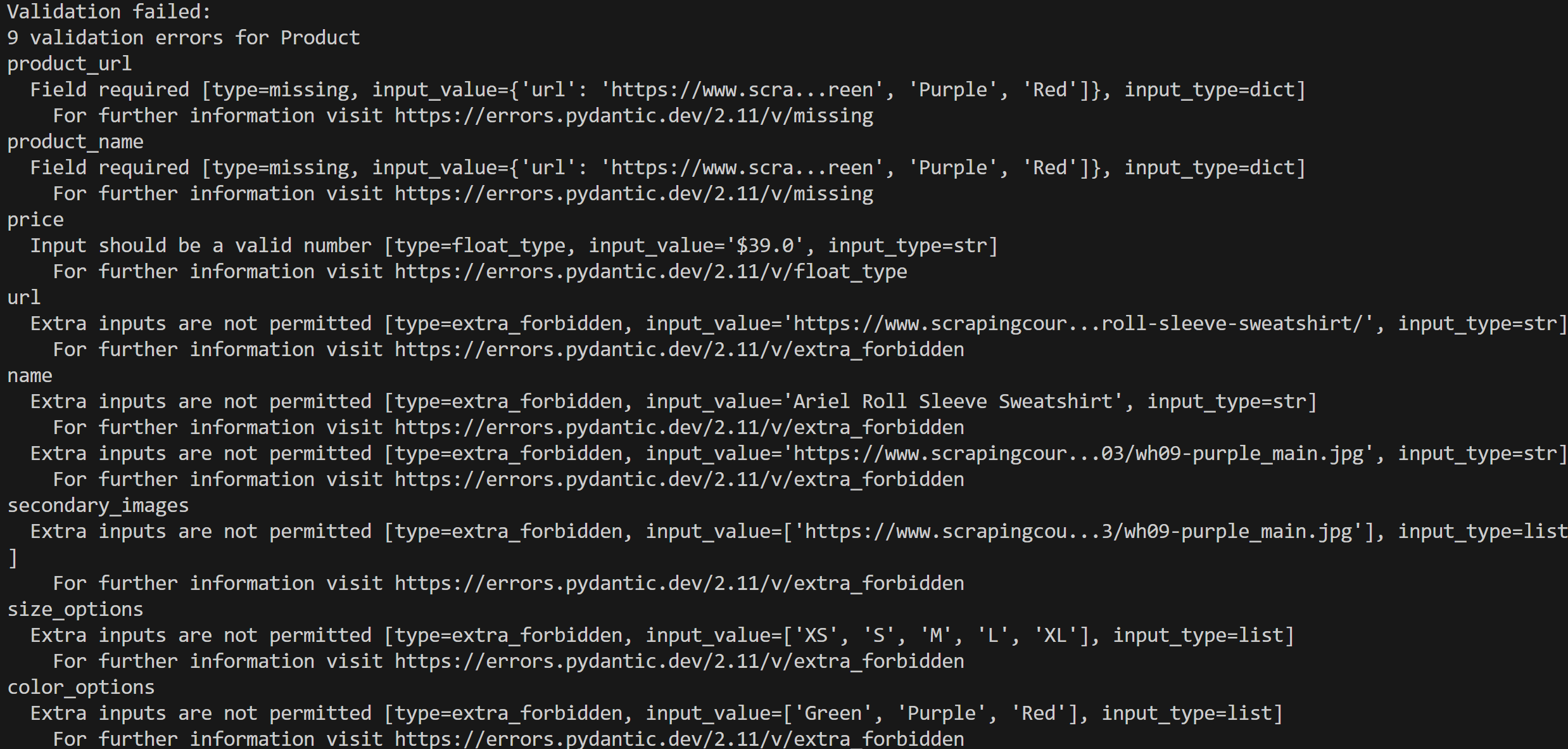
In this case, 9 validation errors were detected because the input data does not conform to the Product model.
Step #4: Fix the Errors
Now, there is no universal process to automatically fix data so that it passes the validation step. Every data pipeline or workflow is different, and you may need to intervene in different aspects of it.
In this case, the solution is as simple as clearly specifying the expected output format in the LLM prompt, a feature supported by most LLMs like OpenAI.
Tip: You can see that feature in action in our guide on visual web scraping with GPT Vision.
Otherwise, if the structured output feature is not available, you can always ask the LLM to match the expected Pydantic model in the prompt by dumping it as a JSON string:
prompt = f"""
Extract data from the given page content and return it with the following structure:
{Product.model_json_schema()}
CONTENT:
<page content>
"""In both cases, the output of the LLM should match the expected format.
After making this change, product.json will contain:
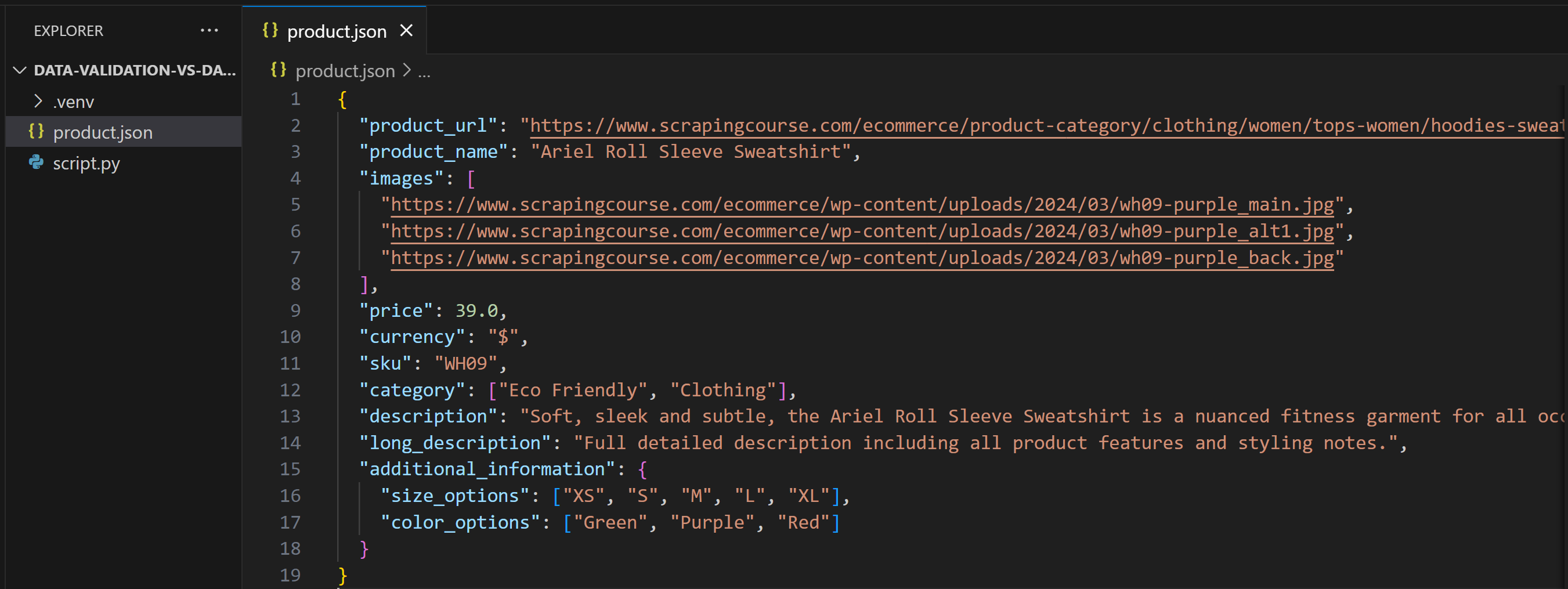
This time, when you run the script, it will produce:

Wonderful! Data validation passes successfully. Once the data has been validated, you can proceed with processing it, storing it in a database, or carrying out other operations.
Data Verification: The Essentials Explained
Let’s continue this data validation vs data verification guide by focusing on the second technique: data verification.
What Is Data Verification and Why Does It Matter?
Data verification is the process of checking that data is accurate and reflects real-world facts. This is done by comparing information against authoritative sources.
Unlike data validation, which only checks whether data meets predefined rules (e.g., an email address is correctly formatted), verification confirms that the data is truthful and corresponds to reality (e.g., the email actually exists and belongs to the intended person).
Verifying data is key to enforcing data quality, particularly when it comes to the meaning of the information. After all, even well-structured, seemingly clean data can contain wrong info. Relying on inaccurate data can result in costly mistakes, flawed decision-making, poor customer experiences, and operational inefficiencies.
Examples of Data Verification Checks
Data verification can be tricky, and the right approach depends heavily on the input data and the domain in which you are operating. Still, some common verification methods include:
- Automated verification: Using specialized software, third-party services, or agentic AI systems to cross-reference data against trusted sources.
- Proofreading: Manually review document, data, or data fields to make sure they contain precise information. This can be done manually by humans using their knowledge on a topic, or automatically by AI.
- Double-entry: Two separate systems (or autonomous AI agents) independently enter data on the same topic. The records are then compared, and any discrepancies are flagged for review or correction.
- Source data verification: Compare data stored in a database against the original source documents (e.g., patient medical records) to confirm they match.
When to Do It
Data verification should be done whenever you do not fully trust the source of the data. A common example is when using AI to generate or enrich data, which can produce plausible-looking but inaccurate information.
Another scenario where data verification is important is when data has been transferred or stored, such as during migrations or consolidations. After such tasks, you need to ensure that the resulting data remains accurate. Verifying data is also relevant as part of ongoing data quality maintenance.
Keep in mind that data verification generally follows data validation. If the structure of the data does not match the expected format, verification does not make sense, as the data may not be usable altogether. Only after the data passes validation does it make sense to proceed to verification.
Verifying data is surely more complex than validating it, as you cannot get deterministic results (as demonstrated earlier with a simple Python script). This is because it is very challenging to determine with absolute certainty whether the information is true.
Top Approaches to Data Verification
When dealing with user-submitted content, the best way to verify it is through human verification. Examples include:
- Email verification: After a user enters an email address during registration, an automated email with a confirmation link or code is sent to ensure the address is valid and accessible.
- Phone number verification: A one-time password (OTP) is sent via text message or phone call to confirm that the number is valid, active, and belongs to the user.
Similarly, you can ask users to submit documents or bills for identity or address verification. These documents can be processed with OCR systems to verify that the data entered by the user matches the information on the uploaded documents. While this approach can still be vulnerable to fraud, it is very useful for increasing data reliability.
The real challenge arises when retrieving public data from the web, the largest and most unstructured source of information. In this case, it is hard to determine whether the information is correct. The general approach is to prioritize trusted sources (e.g., documentation, official statements) and, given some input content, trace its origin, cross-check it online against reliable sources, and compare the results.
Doing that manually is extremely time-consuming, which is why many of these tasks are now automated using AI agents equipped with the tools for web data search and scraping.
How to Verify Data: Python Example
In this section, you will find a step-by-step example of how to build an AI agent for data verification. The agent will:
- Take a sample text as input.
- Pass the information to an LLM extended with web search and scraping tools.
- Ask the AI to identify the main topics in the source text and search Google for relevant, trusted pages to verify accuracy.
- Scrape information from those pages and compare it against the source text.
- Return a report indicating whether the data is accurate and, if not, suggest how to fix it.
This type of workflow would not be possible without an AI-ready infrastructure that supports web data retrieval, search, interaction, and more—such as the one provided by Bright Data’s AI infrastructure.
For an easier integration, we will use the Bright Data Web MCP, which offers over 60 tools. Specifically, its free tier includes these two tools:
search_engine: Retrieve search results from Google, Bing, or Yandex in JSON or Markdown.scrape_as_markdown: Scrape any webpage into clean Markdown format, bypassing bot detection and CAPTCHA.
Those two tools are sufficient to power the data verification agent and achieve the goal!
Scenario Description
Assume you have some input data in a summary.txt file that you want to verify for correctness. For example, this contains a short summary of Super Bowl LIX:

You will build a data verification agent using LangChain integrated with Web MCP. To follow along, you will need:
- Python installed locally.
- A LangChain project set up.
- A Bright Data API key to authenticate your connection to Web MCP.
- An OpenAI API key.
Before getting started, review our tutorial on using the LangChain MCP adapter for integration with Bright Data’s Web MCP. If you prefer to use other frameworks or tools, check out these guides:
- Building Web Scraping Agents with CrewAI & Bright Data’s Model Context Protocol (MCP)
- Building a CLI Chatbot with LlamaIndex and Bright Data’s MCP
- Integrating Claude Code with Bright Data’s Web MCP
- How To Create a RAG Chatbot With GPT-4o Using SERP Data
Build an AI Agent For Data Verification
This is how you can build the data verification agent using LangChain and Bright Data’s Web MCP:
# pip install langchain["openai"] langchain-mcp-adapters langgraph
import asyncio
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
from langchain_openai import ChatOpenAI
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
async def main():
# Load the input data to verify
input_file_name = "summary.txt"
with open(input_file_name, "r", encoding="utf-8") as f:
summary_data_to_verify = f.read()
# Initialize the LLM engine
llm = ChatOpenAI(
model="gpt-5-nano",
)
# Configuration to connect to a local Bright Data Web MCP server instance
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>", # Replace with your Bright Data API key
}
)
# Connect to the MCP server
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Initialize the MCP client session
await session.initialize()
# Get the MCP tools
tools = await load_mcp_tools(session)
# Create the ReAct agent
agent = create_react_agent(llm, tools)
# Agent task description
input_prompt = f"""
Given the input content below, perform the following steps:
1. Identify the main topic as a Google-like search query and use it to perform a web search to gather information about it.
2. From the search results, select the top 2/3 authoritative sources (e.g., trusted news sites, journals, official publications).
3. Scrape the content from the selected pages.
4. Compare the scraped information with the input content to determine whether it is accurate.
5. If not accurate, produce a report listing all errors found in the input content, along with the corrected information and links to the supporting sources.
Input content:
{summary_data_to_verify}
"""
# Stream the agent’s response
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()
if __name__ == "__main__":
asyncio.run(main())Focus on the prompt itself, as it is the most important part of the above script.
Execute the Agent
Launch your agent, and you will see that it correctly identifies the main topic as “Super Bowl LIX.” Then, it will execute a Google search using the search_engine tool from Web MCP:

From the resulting SERP, it identifies ESPN and CBS Sports articles as the primary sources and scrapes them using the scrape_as_markdown tool:
After extracting the content from the three news sources, it produces the following Markdown report:
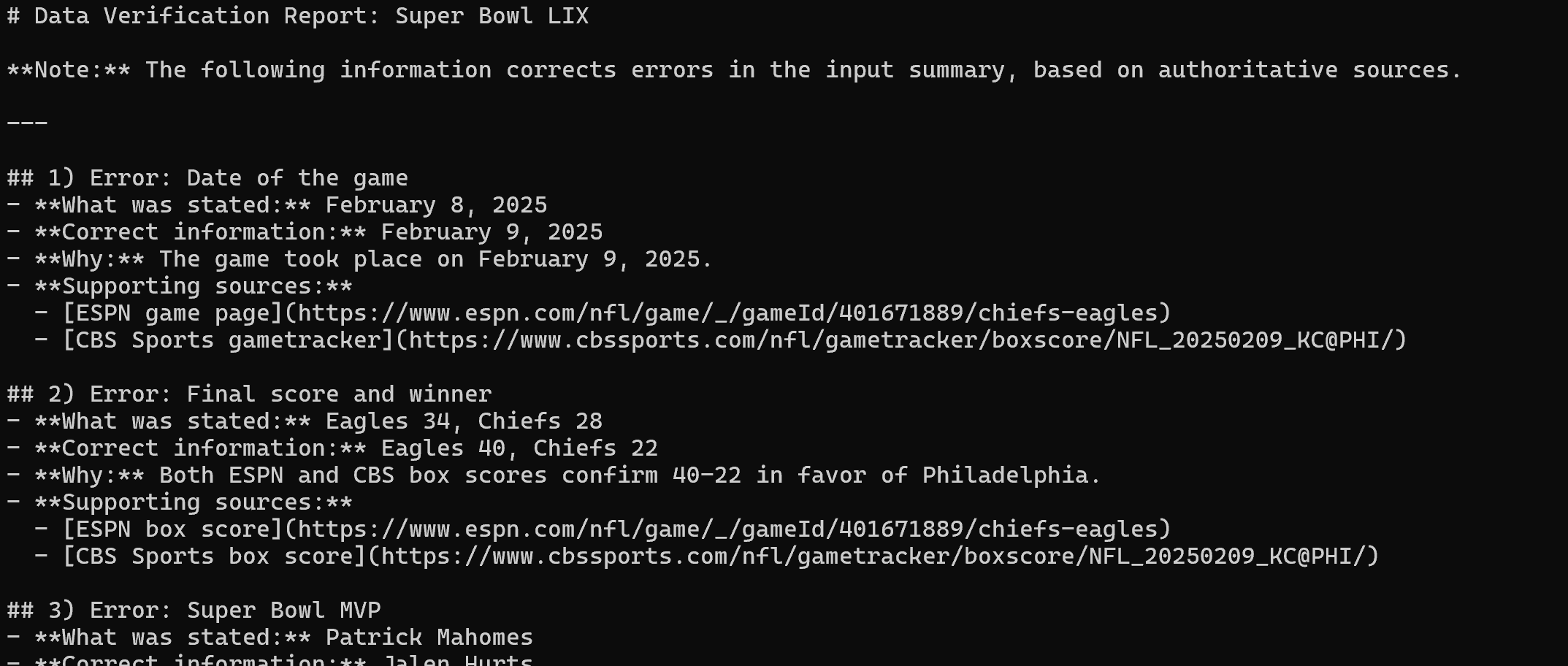
Render it in Visual Studio Code, and you will see the final report.
As you can tell, thanks to the web search and scraping capabilities from Web MCP, the LangChain agent was able to identify all errors in the original incorrect text. Mission complete!
Data Validation vs Data Verification: Summary Table
Compare the two techniques in the data validation vs data verification summary table below:
| Aspect | Data Validation | Data Verification |
|---|---|---|
| Definition | Checks the accuracy, quality, and integrity of data against predefined rules and standards before use or storage. | Confirms that data accurately reflects real-world facts by comparing it against authoritative sources. |
| Purpose | Ensures data conforms to expected formats, types, ranges, and rules; prevents bad data from entering systems. | Ensures data is truthful, accurate, and trustworthy for decision-making. |
| Timing | Performed at the point of entry, after extraction, after transformation, or periodically. | Performed after validation, or whenever data source reliability is uncertain; typically after data collection or transfer. |
| Complexity | Relatively straightforward; deterministic checks based on defined rules. | More complex; may involve uncertainty, external sources, and manual review; non-deterministic results possible. |
| Example | price must be ≥ 0 |
Verify that the price matches the official store listing |
Final Comment
As you learned in this data validation vs data verification blog post, data validation and data verification address two different but complementary tasks. In particular, both contribute to achieving high data quality. Another similar point is that overlooking either can cause significant problems across data-driven processes, which support most business operations.
That is why it is truly indispensable to choose a trusted, reliable data provider that offers multiple solutions to ensure proper data validation and provides the tools to build an effective data verification system.
Bright Data is an excellent example. It offers a wide range of products, including ready-to-use, validated datasets and a comprehensive selection of AI-ready web scraping solutions to gather accurate information from the web, supporting both validation and verification workflows.
Sign up for a free Bright Data account today and explore our data services!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.




