

In this guide, you will discover:
- Why Perplexity is a good choice for AI-powered web scraping
- How to scrape a website in Python with a step-by-step tutorial
- The main limitation of this web scraping approach, and how to bypass it
Let’s get started!
Why Use Perplexity for Web Scraping?
Perplexity is an AI-powered search engine that utilizes large language models to generate detailed answers to user queries. It retrieves information in real time, summarizes it, and can respond with cited sources.
Utilizing Perplexity for web scraping reduces the process of data extraction from unstructured HTML content to a simple prompt. That eliminates the need for manual data parsing, making it significantly easier to extract relevant information.
On top of that, Perplexity is built for advanced web crawling scenarios, thanks to its capabilities for discovering and exploring web pages.
For more information, refer to our guide on using AI for web scraping.
Use Cases
Some examples of Perplexity-powered scraping use cases are:
- Pages that frequently change structure: It can adapt to dynamic pages where layouts and data elements change often, such as e-commerce sites like Amazon.
- Crawling large websites: It can assist in discovering and navigating pages or performing AI-driven searches that guide the scraping process.
- Extracting data from complex pages: For sites with hard-to-parse structures, Perplexity can automate data extraction without requiring extensive custom parsing logic.
Scenarios
Some examples where scraping with Perplexity comes in handy are:
- Retrieval-Augmented Generation (RAG): Enhancing AI insights by integrating real-time data scraping. For a practical example using a similar AI model, read our guide on creating a RAG chatbot with SERP data.
- Content aggregation: Gathering news, blog posts, or articles from multiple sources to generate summaries or analytics.
- Social media scraping: Extracting structured data from platforms with dynamic or frequently updated content.
How to Perform Web Scraping with Perplexity in Python
For this section, we will use a specific product page from the “Ecommerce Test Site to Learn Web Scraping” sandbox:

This page represents a great example target because e-commerce product pages often have different structures, displaying varying types of data. That is what makes e-commerce web scraping so challenging—and where AI can help.
In particular, the Perplexity-powered scraper will leverage AI to extract these product details from the page without needing manual parsing logic:
- SKU
- Name
- Images
- Price
- Description
- Sizes
- Colors
- Category
Note: The following example will be in Python for simplicity and because of the popularity of the SDKs involved. Still, you can get the same result using JavaScript or any other programming language.
Follow the steps below to learn how to scrape web data with Perplexity!
Step #1: Set Up Your Project
Before you begin, ensure that Python 3 is installed on your machine. If it is not, download it and follow the installation instructions.
Then, run the command below to initialize a folder for your scraping project:
mkdir perplexity-scraperThe perplexity-scraper directory will serve as the project folder for your project for web scraping using Perplexity.
Navigate to the folder in your terminal and create a Python virtual environment inside it:
cd perplexity-scraper
python -m venv venvOpen the project folder in your preferred Python IDE. Visual Studio Code with the Python extension or PyCharm Community Edition are both excellent options.
Create a scraper.py file in the project’s folder, which should now look like this:

At this point, scraper.py is just an empty Python script, but it will soon contain the logic for LLM web scraping.
Next, activate the virtual environment in your IDE’s terminal. On Linux or macOS, run:
source venv/bin/activateEquivalently, on Windows, use:
venv/Scripts/activateGreat! Your Python environment is now set up for web scraping with Perplexity.
Step #2: Retrieve Your Perplexity API Key
Like most AI providers, Perplexity exposes its models via APIs. To programmatically access them, you first need to redeem a Perplexity API key. You can refer to the official “Initial Setup” or follow the guided steps below.
If you do not have a Perplexity account yet, create one and log in. Then, navigate to the “API” page and click “Setup” to add a payment method if you have not done so already:

Note: You will not be charged at this step. Perplexity only stores your payment details for future API usage. You can use a credit/debit card, Google Pay, or any other supported payment method.
Once your payment method is set up, you will see the following section:

Purchase some credits by clicking on “+ Buy Credits” and wait for them to be added to your account. Once the credits are available, the “+ Generate” button under the API Keys section will become active. Press it to generate your Perplexity API key:

An API key will appear:

Copy the key and store it in a safe place. For simplicity, we will define it as a constant in scraper.py:
PERPLEXITY_API_KEY="<YOUR_PERPLEXITY_API_KEY>"Important: In production Perplexity scraping scripts, avoid storing API keys in plain text. Instead, store secrets like that in environment variables or a .env file managed with libraries like python-dotenv.
Wonderful! You are ready to use the OpenAI SDK to make API requests to Perplexity’s models in Python.
Step #3: Configure Perplexity in Python
The last sentence in the previous step does not contain a typo—even though it mentioned the OpenAI SDK. That is because Perplexity API is fully OpenAI-compatible. Actually, the recommended way to connect to the Perplexity API using Python is through the OpenAI SDK.
As a first step, install the OpenAI Python SDK. In an activated virtual environment, run:
pip install openaiNext, import it into your scraper.py script:
from openai import OpenAITo connect to Perplexity instead of OpenAI, configure the client as follows:
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")Great! The Perplexity Python setup is now complete, and you’re ready to make API requests to their models.
Step #4: Get the HTML of the Target Page
Now, you need to retrieve the HTML of the target page. You can achieve that with a powerful Python HTTP client like Requests.
In an activated virtual environment, install Requests with:
pip install requestsNext, import the library in scraper.py:
import requestsUse the get() method to send a GET request to the page URL:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)The target server will respond with the raw HTML of the page.
If you print response.content, you will see the full HTML document:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Ajax Full-Zip Sweatshirt – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>You now have the exact HTML of the target page in Python. Let’s parse it and extract the data we need from it!
Step #5: Convert the Page HTML to Markdown (Optional)
Warning: This step is not technically required, but it can save you significant time and money. So, it is definitely worth considering.
Take a moment to explore how other AI-powered web scraping technologies, like Crawl4AI and ScrapeGraphAI, handle raw HTML. You will notice that they both offer options to convert HTML to Markdown before passing the content to the configured LLM.
Why do they do that? There are two key reasons:
- Cost efficiency: Converting to Markdown reduces the number of tokens sent to the AI, helping you save money.
- Faster processing: Less input data means lower computational costs and quicker responses.
For more information, read our guide on why the new AI agents choose Markdown over HTML.
Time to replicate the HTML-to-Markdown conversion logic to reduce token usage!
Start by opening the target webpage in incognito mode (to make sure you are operating on a fresh session). Then, right-click anywhere on the page and select “Inspect” to open the developer tools.
Examine the page structure. You will see that all relevant data is contained within the HTML element identified by the CSS selector #main:

Technically, you could send the entire raw HTML to Perplexity for data parsing. However, that would include a lot of unnecessary information—such as headers and footers. Instead, using the content inside #main as the input raw data guarantees that you are dealing only with the most relevant data. This will reduce noise and limit AI hallucinations.
To extract only the #main element, you need a Python HTML parsing library like Beautiful Soup. In your activated Python virtual environment, install it with this command:
pip install beautifulsoup4If you are not familiar with its API, read our guide on Beautiful Soup web scraping.
Now, import it in scraper.py:
from bs4 import BeautifulSoupUse Beautiful Soup to:
- Parse the raw HTML fetched with Requests
- Select the
#mainelement - Get its HTML content
Achieve that with this snippet:
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)If you print main_html, you will see something like this:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<div class="woocommerce-notices-wrapper"
id="notices-wrapper"
data-testid="notices-wrapper"
data-sorting="notices">
</div>
<div id="product-309"
class="product type-product post-309 status-publish first outofstock
product_cat-hoodies-sweatshirts has-post-thumbnail
shipping-taxable purchasable product-type-variable">
<!-- omitted for brevity... -->
</div>
</main>Use OpenAI’s Tokenizer tool to check how many tokens the selected HTML corresponds to:

Next, estimate the cost of sending these tokens to Perplexity’s API using LLM API Pricing Calculator:

As you can see, this approach results in more than 20,000 tokens. That means from $0.21 to around $0.63 per request. On a large-scale project with thousands of pages, that is a lot!
To reduce token consumption, convert the extracted HTML into Markdown using a library like markdownify. Install it in your Perplexity-powered scraping project with:
pip install markdownifyImport markdownify in scraper.py:
from markdownify import markdownifyThen, use it to convert the HTML from #main to Markdown:
main_markdown = markdownify(main_html)The data conversion process will produce an output as below:

From the “size” element at the end of the two text areas, you can see that the Markdown version of the input data is much smaller than the original #main HTML. Additionally, upon inspection, you will notice how it still contains all the key data to scrape!
Use OpenAI’s Tokenizer again to check how many tokens the new Markdown input consumes:

With this simple trick, you reduced 20,658 tokens down to 950 tokens—a 95%+ reduction. This also translates into a huge reduction in Perplexity API costs per request:
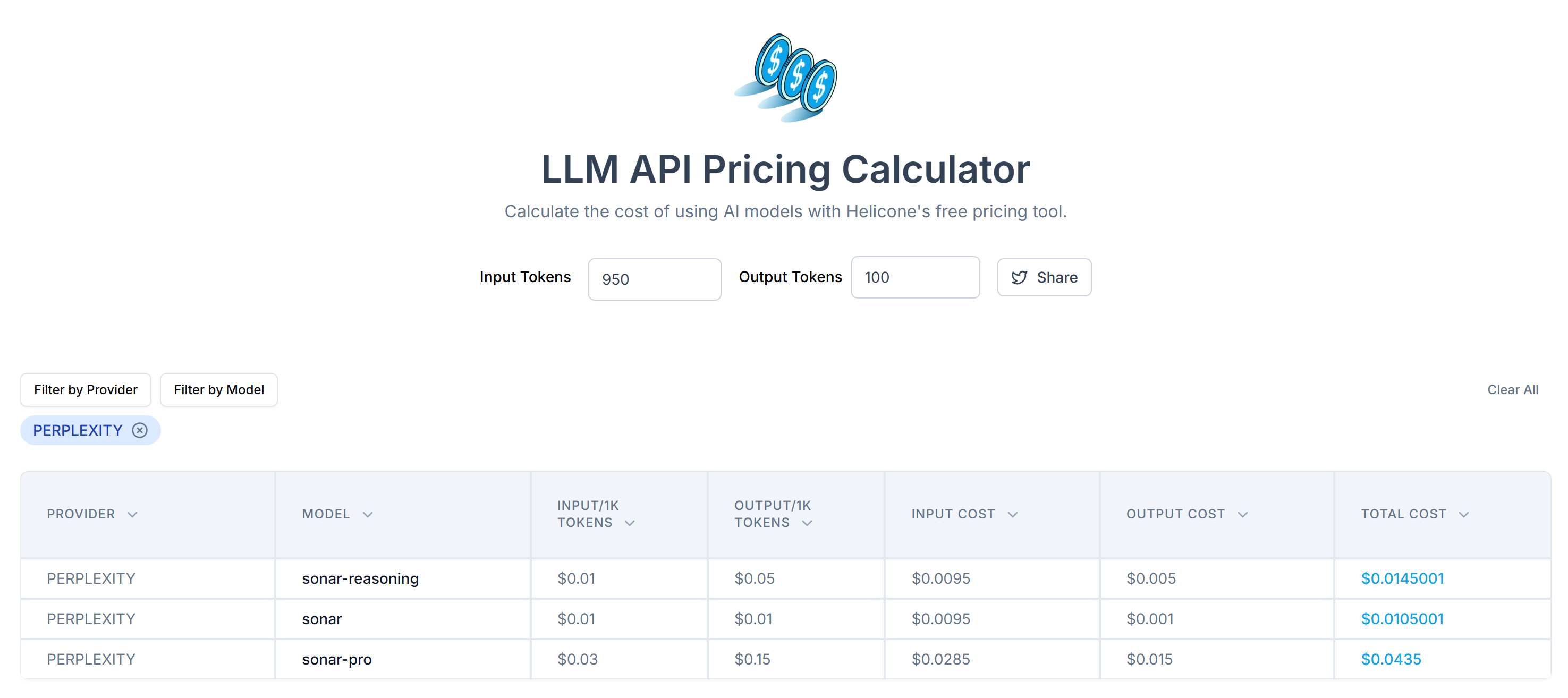
The cost drops from around $0.21-$0.63 per request to just $0.014-$0.04 per request!
Step #6: Use Perplexity for Data Parsing
Follow these steps to scrape data using Perplexity:
- Write a well-structured prompt to extract JSON data in the desired format from the Markdown input
- Send a request to Perplexity’s LLM model using the OpenAI Python SDK
- Parse the returned JSON
Implement the first two steps with the following code:
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.contentThe prompt variable instructs Perplexity to extract structured data from the main_markdown content. To improve results, it is recommended to define a clear prompt for the system so it knows how to behave and what to do.
Note: Perplexity still relies on the old OpenAI legacy syntax for making API calls. If you try to use the newer responses.create() syntax, you will encounter the following error:
httpx.HTTPStatusError: Client error '404 Not Found' for url 'https://api.perplexity.ai/responses'Now, product_raw_string should contain JSON data in the following format:
"```json
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "$69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.nnMint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": ["XS", "S", "M", "L", "XL"],
"colors": ["Blue", "Green", "Red"],
"category": "Hoodies & Sweatshirts"
}
```"As you can see, Perplexity returns the data in Markdown format.
To implement step 3 of the algorithm at the beginning of this section, you need to extract the raw JSON content using a regex. Then, you can parse the resulting JSON data to Python dictionary json.loads():
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)Do not forget to import json and re from the Python Standard Library:
import json
import reNote: If you are a Perplexity Tier-3 user, you can skip the regex parsing step by configuring the API to return data in a structured JSON format directly. Find more information on the Perplexity “Structured Outputs” guide.
Once you have parsed the product_data dictionary, you can access the fields for further data processing. For example:
price = product_data["price"]
price_eur = price * USD_EUR
# ...Fantastic! You have successfully utilized Perplexity for web scraping. It only remains to export the scraped data as needed.
Step #7: Export the Scraped Data
Currently, you have the scraped data stored in a Python dictionary. To save it as a JSON file, use the following code:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)This will generate a product.json file containing the scraped data in JSON format.
Well done! Your Perplexity-powered web scraper is now ready.
Step #8: Put It All Together
Here is the complete code of your scraping script using Perplexity for data parsing:
from openai import OpenAI
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import re
import json
# Your Perplexity API key
PERPLEXITY_API_KEY = "<YOUR_PERPLEXITY_API_KEY>" # replace with your API key
# Conffigure the OpenAI SDK to connect to Perplexity
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")
# Retrieve the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)
# Convert the #main HTML to Markdown
main_markdown = markdownify(main_html)
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.content
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Run the scraping script with:
python scraper.pyAt the end of the execution, a product.json file will be generated in your project folder. Open it, and you will find structured data like this:
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.n• Mint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Blue",
"Green",
"Red"
],
"category": "Hoodies & Sweatshirts"
}Et voilà! The script transformed unstructured data from an HTML page into a neatly organized JSON file, all thanks to Perplexity-powered web scraping.
Next Steps
To take your Perplexity-powered scraper to the next level, consider these improvements:
- Make it reusable: Modify the script to accept the prompt and target URL as command-line arguments. This will make the scraper more flexible and adaptable for different use cases and projects.
- Secure API credentials: Store your Perplexity API key in a .env file and use python-dotenv to safely load it. This approach avoids hardcoding sensitive credentials in the script, improving security by keeping the secrets private and separated from the codebase.
- Implement web crawling: Leverage Perplexity’s AI-powered search and crawling capabilities for intelligent, optimized crawling. Configure the scraper to navigate through linked pages, extracting structured data from various sources.
Breaking Through the Biggest Limitation of This Web Scraping Method
What is the biggest limitation of this AI-powered approach to web scraping? The HTTP request made by requests!
While the example above worked perfectly, that is because the target site is essentially a web scraping playground. In reality, companies and website owners understand the value of their data, even when it is publicly accessible. To protect it, they implement anti-scraping measures that can easily block your automated HTTP requests.
In such cases, the script will fail with 403 Forbidden errors, like:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: <YOUR_TARGET_URL>
Additionally, this approach does not work on dynamic web pages that rely on JavaScript for rendering or to fetch data asynchronously. Thus, websites do not even need advanced anti-bot defenses to block your LLM-powered scraper.
So, what’s the solution to all these problems? A Web Unlocking API!
Bright Data’s Web Unlocker API is a scraping endpoint you can call from any HTTP client. It returns the fully unlocked HTML of any URL you pass to it—bypassing anti-scraping blocks for you. No matter how many protections a target site has, a simple request to the Web Unlocker will retrieve the page’s HTML for you.
To get started, follow the official Web Unlocker documentation to retrieve your API key. Then, replace your existing request code from “Step #4” with these lines:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
And just like that—no more blocks, no more limitations! You can now scrape the Web using Perplexity without worrying about getting stopped.
Conclusion
In this tutorial, you learned how to use Perplexity in combination with Requests and other tools to create an AI-powered scraper. One of the biggest challenges in web scraping is the risk of getting blocked, but this was addressed using Bright Data’s Web Unlocker API.
As discussed, by integrating Perplexity with the Web Unlocker API, you can extract data from any site without the need for custom parsing logic. This is just one of the many use cases supported by Bright Data’s products and services, enabling you to implement efficient AI-driven web scraping.
Explore our other web scraping tools:
- Proxy Services: Four types of proxies to bypass location restrictions, including access to 400M+ monthly residential IPs.
- Web Scraper APIs: Dedicated endpoints for extracting fresh, structured web data from over 100 popular domains.
- SERP API: API for managing ongoing unlocking for SERPs and extracting individual pages.
- Scraping Browser: A cloud browser compatible with Puppeteer, Selenium, and Playwright, featuring built-in unlocking capabilities.
Sign up now to Bright Data and test our proxy services and scraping products for free!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



