

In this tutorial, we will learn how to scrape Amazon using Bright Data and a production-ready scraping project.
We will cover:
- How to use the Amazon Scraper API
- Setting up a project and configuring Amazon scrape targets
- Fetching and rendering Amazon pages
- Extracting product data from search and product pages
- Scraping Amazon using Bright Data’s Web MCP with Claude Desktop
Why Scrape Amazon?
Amazon is the world’s largest product marketplace and one of the richest sources of real-time commerce data on the internet. From pricing trends to customer sentiment, the platform reflects market behavior at a scale few other websites can match.
Scraping Amazon allows teams to move beyond manual research and static datasets, enabling automated, data-driven decision-making at scale.
Common Amazon Scraping Use Cases
Some of the most common reasons companies and developers scrape Amazon include:
- Price monitoring & competitive intelligence: Track product prices, discounts, and stock availability across categories and sellers in near real time.
- Market & product research: Analyze product listings, categories, and best-seller rankings to identify demand trends and new opportunities.
- Review & sentiment analysis: Collect customer reviews and ratings to understand buyer sentiment, product performance, and feature gaps.
- AI-powered applications: Feed live Amazon data into LLMs and AI agents for tasks like shopping assistants, dynamic pricing models, and automated market analysis.
With the use cases clear, we can now get practical and walk through the ways for scraping Amazon with Bright Data.
Scraping Amazon with the Bright Data Amazon Scraper API
In addition to building custom scrapers or using MCP with Claude, Bright Data also offers a managed Amazon Scraper API. You’ll need your API key for authentication.
Choosing an Amazon scraper
Start by opening the Bright Data Scraper Library.
From the list of available scrapers, select the Amazon scraper that matches your use case, such as:
- Product details by ASIN
- Search results
- Reviews
Each scraper is designed for a specific type of Amazon data.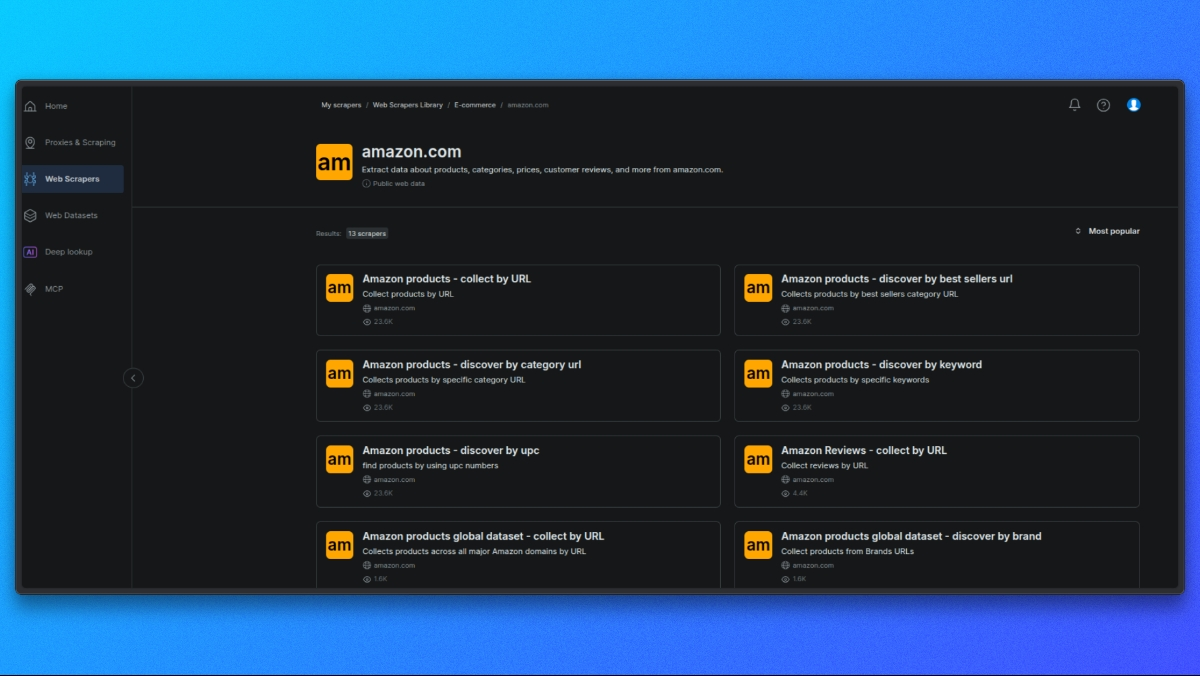
Select the Scraper Endpoint
Each scraper offers different endpoints depending on the data you want (e.g., product details, search results, reviews).
Click on the endpoint that fits your use case.
Build Your Request
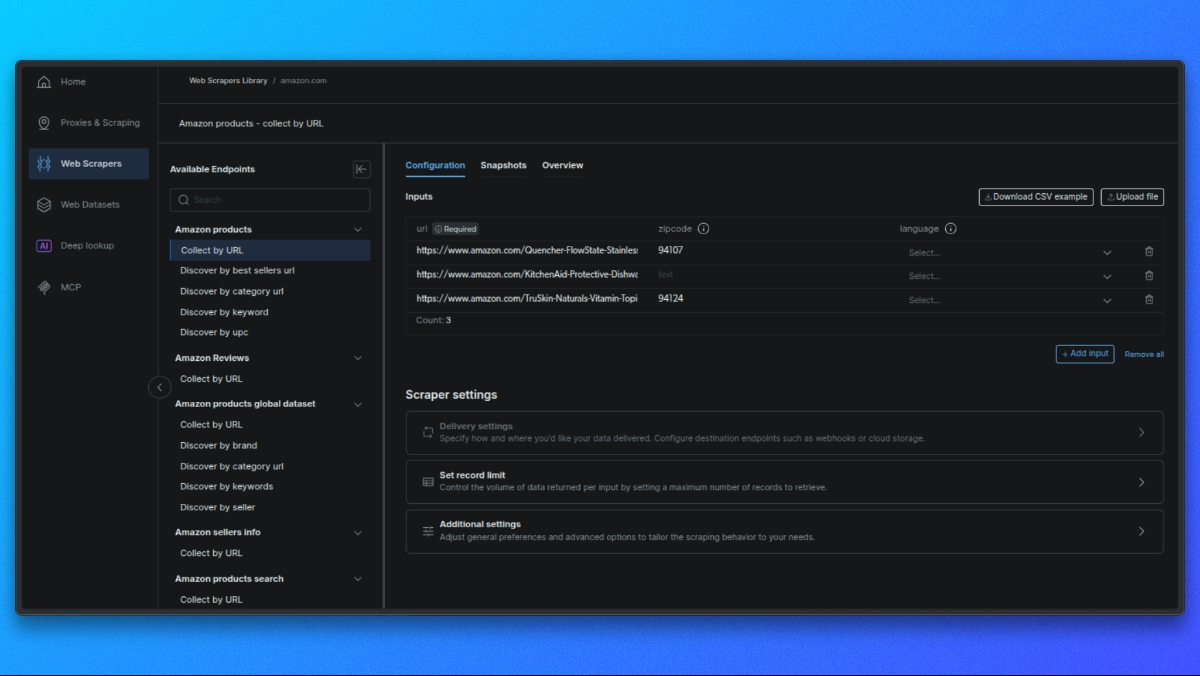
In the central panel, you’ll see a form to configure your request:
- Single Input: Paste a product URL, ASIN, or keyword.
- Bulk CSV: Upload a CSV file with multiple inputs for batch processing.
Optional Settings: - Output Schema: Select only the fields you need.
- External Storage: Set up S3, GCS, or Azure for direct delivery.
- Webhook URL: Set a webhook to receive results automatically.
Make the API Request
Here’s a basic example using curl for a product page:
curl -i --silent --compressed "https://api.brightdata.com/dca/trigger?customer=hl_ee3f47e5&zone=YOUR_ZONE_NAME" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"input": {
"url": "https://www.amazon.com/dp/B08L5TNJHG"
}
}'Replace YOUR_ZONE_NAME and YOUR_API_KEY with your actual zone and API key.
### Retrieve Your Results
- For real-time jobs (up to 20 URLs), you’ll get results directly.
- For batch jobs, you’ll receive a job ID to poll for results or get them via webhook/external storage.
Now, let’s see how to build a custom scraper with Bright Data’s residential proxies.
Project Setup
You can follow this tutorial using the project code available in the repository.
Before getting started, make sure you have the following prerequisites installed on your system.
Prerequisites
This project requires:
- Python 3.10+
- pip for dependency management
- Node.js 18+ (required by Vercel)
- Vercel CLI
In addition, you will need:
- A Bright Data account
- Access to Bright Data’s Web MCP
- Claude Desktop
Installing Dependencies
Install the required Python dependencies using the provided requirements.txt file:
pip install -r requirements.txtThis installs all libraries used for page fetching, browser automation, HTML parsing, and data extraction.
Bright Data CA Certificate
This project uses a Bright Data CA certificate for TLS verification when routing requests through the proxy.
Ensure the certificate file exists at the following path:
certs/brightdata-ca.crtThis file is passed to the HTTP client during requests. If it is missing or incorrectly referenced, Amazon requests will fail due to TLS verification errors.
Vercel Setup
This project is designed to run as a Vercel Serverless Function.
The api/search.py file serves as the API entry point and is executed by Vercel in response to incoming HTTP requests.
Make sure the Vercel CLI is installed and authenticated:
vercel login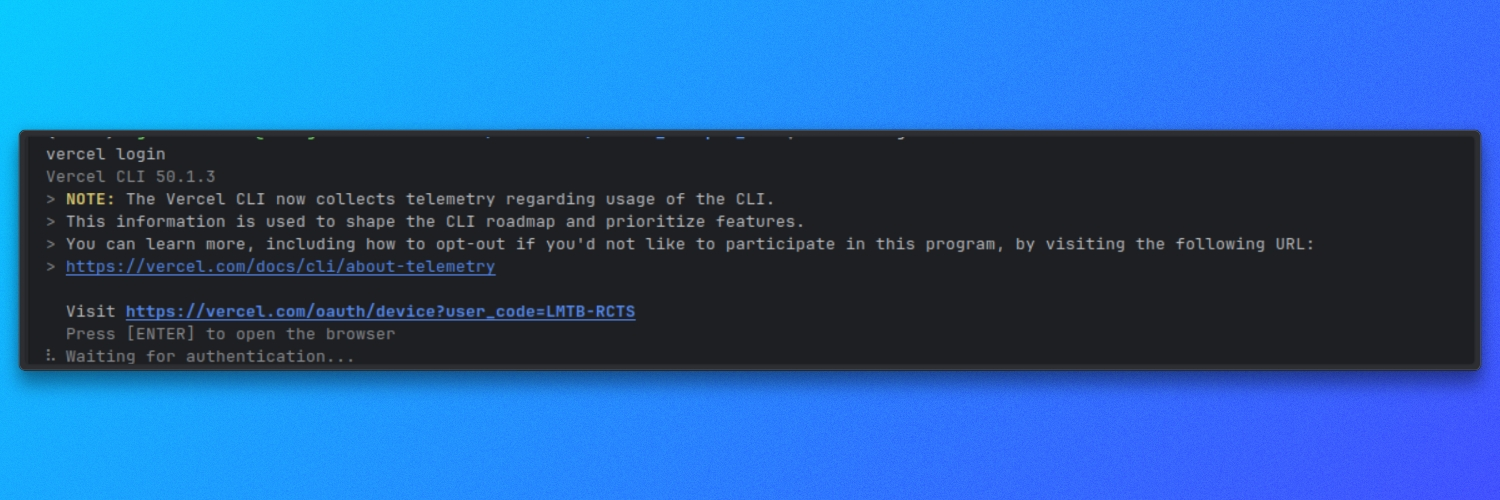
Environment Variables
The project uses environment-based configuration for runtime settings.
Create a .env file in the root of the project and define the required variables as specified in the repository. These values control how the scraper fetches, renders, and processes Amazon pages.
With the dependencies installed and environment variables configured, the project is ready to use.
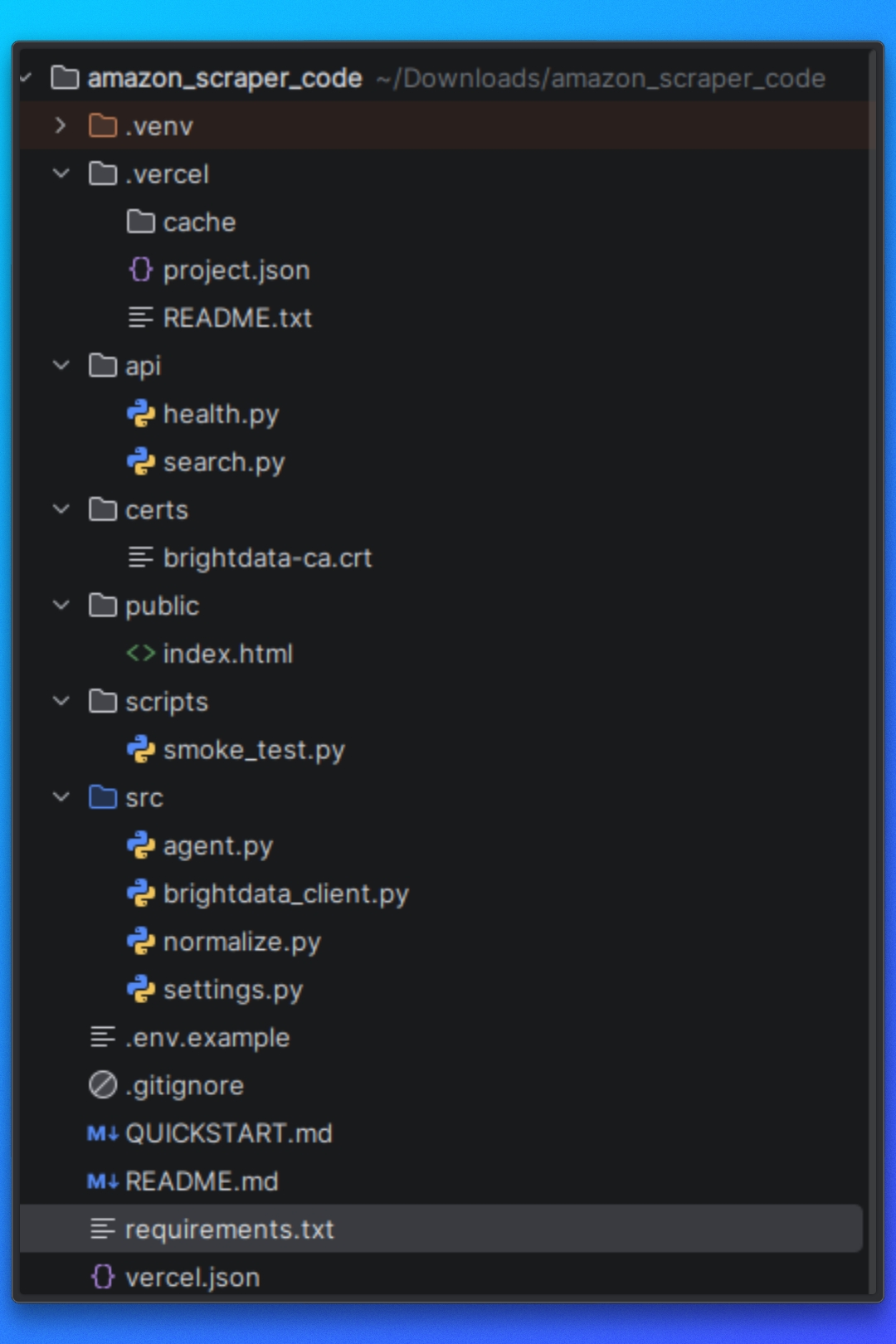
Understanding the Project Structure
Before running the scraper, we need to understand how the project is organized and how the scraping pipeline flows from start to finish.
The project is structured around a clear separation of responsibilities.
Configuration
This part of the project defines Amazon targets, runtime options, and scraper behavior. These settings control what gets scraped and how the scraper operates.
Page Fetching and Rendering
This part of the project is responsible for loading Amazon pages and returning usable HTML. It handles navigation, page loading, and JavaScript execution so downstream logic works with fully rendered content.
Extraction Logic
Once HTML is available, the extraction layer parses the page and extracts structured data. This includes logic for both Amazon search result pages and individual product pages.
Execution Flow
The execution flow coordinates fetching, rendering, extraction, and output. It ensures each step runs in the correct order.
Output Handling
Scraped data is written to disk in a structured format, making it easy to inspect or consume in other workflows.
This structure keeps the scraper modular and makes it easier to reuse individual components, especially when integrating external fetching methods such as Bright Data’s Web MCP later in the tutorial.
With this overview in place, we can move on to configuring Amazon targets and defining what data the scraper should collect.
Configuring Amazon Targets
In this section, we will configure two things:
- The Amazon search keyword we want to scrape
- The Bright Data credentials we need to fetch Amazon pages successfully
1. Passing the Amazon search keyword
We send our Amazon keyword using a query parameter named q.
This is handled in api/search.py. The API reads q from the request URL and stops immediately if it is missing:
# api/search.py
query = query_params.get("q", [None])[0]
if not query:
self._send_json_response(400, {"error": "Missing required parameter: q"})
returnWhat this means:
We must call the endpoint with ?q=...
If we forget q, we get a 400 response and the scraper does not run
Setting how many products we want
We can also control how many products we return using the optional limit parameter.
Still in api/search.py, we parse limit, convert it to an integer, and clamp it to a safe range:
# api/search.py
limit_str = query_params.get("limit", [None])[0]
limit = DEFAULT_SEARCH_LIMIT
if limit_str:
try:
limit = int(limit_str)
limit = min(limit, MAX_SEARCH_LIMIT)
limit = max(1, limit)
except ValueError:
limit = DEFAULT_SEARCH_LIMITSo:
If we do not pass limit, we use the default.
If we pass something invalid, we fall back to the default.
If we pass a value higher than allowed, it is capped.
The default and max values are defined in src/settings.py:
# src/settings.py
DEFAULT_SEARCH_LIMIT = 10
MAX_SEARCH_LIMIT = 50If we ever want to change the default behavior, this is where we do it.
2. Mapping our query to Amazon’s search endpoint
Once we have q, we fetch Amazon search results through Bright Data using fetch_products(query, limit):
# api/search.py
raw_response = fetch_products(query, limit)The Amazon endpoint being scraped is defined in src/brightdata_client.py:
# src/brightdata_client.py
AMAZON_SEARCH_URL = "https://www.amazon.com/s"And when we fetch results, we pass our keyword to Amazon using the k parameter:
# src/brightdata_client.py
r = requests.get(
AMAZON_SEARCH_URL,
params={"k": query},
proxies=proxies,
headers=headers,
timeout=60,
verify=BRIGHTDATA_CA_CERT_PATH,
)That means:
- Our API parameter is
q - Amazon’s search parameter is
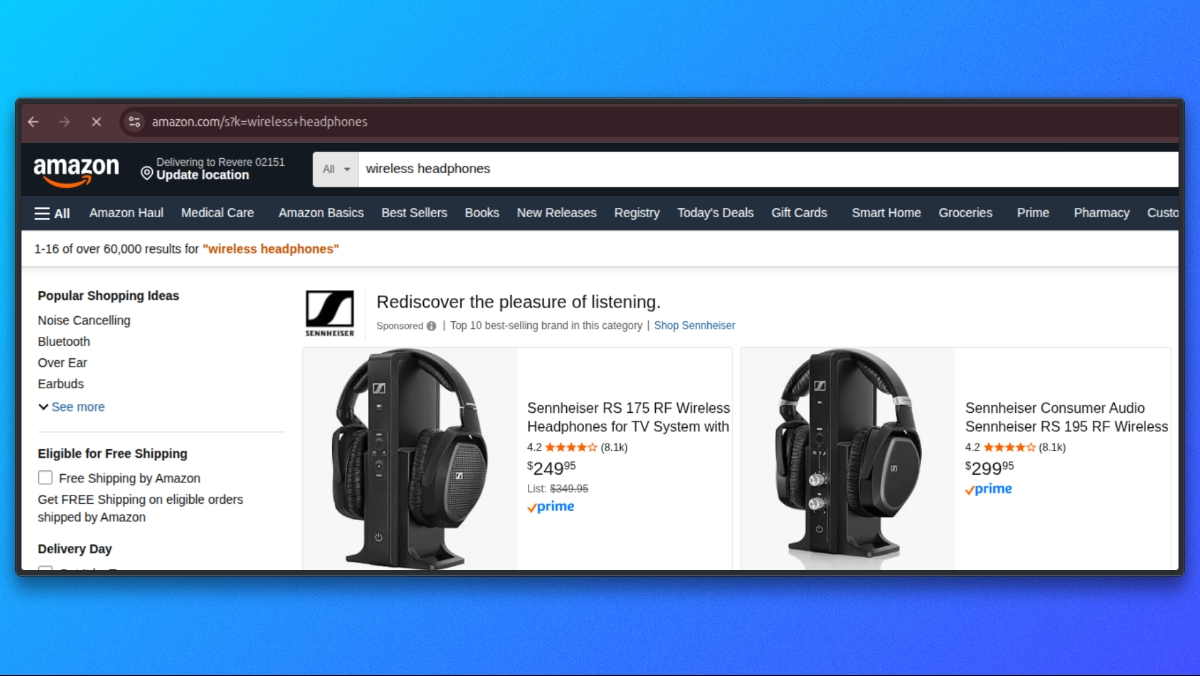
k - If we provide q=wireless headphones, the request goes to Amazon like
https://www.amazon.com/s?k=wireless+headphones
3. Configuring Bright Data credentials
To send requests through Bright Data, we need proxy credentials available as environment variables.
In src/settings.py, we load Bright Data settings like this:
# src/settings.py
BRIGHTDATA_USERNAME = os.getenv('BRIGHTDATA_USERNAME', '')
BRIGHTDATA_PASSWORD = os.getenv('BRIGHTDATA_PASSWORD', '')
BRIGHTDATA_PROXY_HOST = os.getenv('BRIGHTDATA_PROXY_HOST', 'brd.superproxy.io')
BRIGHTDATA_PROXY_PORT = os.getenv('BRIGHTDATA_PROXY_PORT', 'your_port)In your .env file, add the following credentials:
BRIGHTDATA_USERNAME=your_brightdata_username
BRIGHTDATA_PASSWORD=your_brightdata_password
BRIGHTDATA_PROXY_HOST=brd.superproxy.io
BRIGHTDATA_PROXY_PORT=your_portWhen we run the scraper, these values are used to build the Bright Data proxy URL inside src/brightdata_client.py:
# src/brightdata_client.py
proxy_url = (
f"http://{BRIGHTDATA_USERNAME}:{BRIGHTDATA_PASSWORD}"
f"@{BRIGHTDATA_PROXY_HOST}:{BRIGHTDATA_PROXY_PORT}"
)
proxies = {"http": proxy_url, "https": proxy_url}If we do not set BRIGHTDATA_USERNAME or BRIGHTDATA_PASSWORD, the scraper fails early with a clear error:
# src/brightdata_client.py
if not BRIGHTDATA_USERNAME or not BRIGHTDATA_PASSWORD:
raise ValueError(
"Bright Data proxy credentials not configured. "
"Set BRIGHTDATA_USERNAME and BRIGHTDATA_PASSWORD."
)With our keyword and Bright Data credentials configured, we are ready to fetch Amazon pages.
Fetching Amazon Pages
At this stage, we already have validated input and Bright Data configured. We now focus on where the Amazon request is executed and what minimal assumptions it makes.
All Amazon requests are sent from src/brightdata_client.py.
Amazon search endpoint
We define the Amazon search endpoint once and reuse it for all search requests:
# src/brightdata_client.py
AMAZON_SEARCH_URL = "https://www.amazon.com/s"Request headers
We send generic, browser-like headers to ensure Amazon returns the standard desktop HTML layout. These headers are not tied to the user’s operating system.
# src/brightdata_client.py
headers = {
"User-Agent": (
"Mozilla/5.0 "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0 Safari/537.36"
),
"Accept-Language": "en-US,en;q=0.9",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
}Sending the request
With the endpoint, headers, and proxy configuration already in place, we execute the Amazon request:
# src/brightdata_client.py
response = requests.get(
AMAZON_SEARCH_URL,
params={"k": query},
proxies=proxies,
headers=headers,
timeout=60,
verify=BRIGHTDATA_CA_CERT_PATH,
)
response.raise_for_status()
html = response.text or ""At the end of this call, html contains the raw Amazon search page content.
With the fetch phase complete, we can now move on to parsing the HTML and extracting product links and metadata from the Amazon search results page.
Extracting Search Results
Once the Amazon search page has been fetched, the next step is extracting product listings from the returned HTML. This entire step happens inside src/brightdata_client.py.
After the request completes, we pass the raw HTML into the internal parser:
products = _parse_amazon_search_html(html, limit=limit)
return {"products": products}All search-result extraction logic lives inside _parse_amazon_search_html.
Parsing the HTML
We begin by parsing the raw HTML into a DOM tree using BeautifulSoup. This allows us to query the page structure reliably.
soup = BeautifulSoup(html, "lxml")We also normalize the requested limit to ensure we always extract at least one item:
max_items = max(1, int(limit)) if isinstance(limit, int) else 10Locating search result containers
Amazon search pages include many elements that are not product listings. To isolate actual results, we first target Amazon’s primary search result container:
containers = soup.select('div[data-component-type="s-search-result"]')As a fallback, we also look for elements that contain a valid data-asin attribute:
fallback = soup.select('div[data-asin]:not([data-asin=""])')If the primary selector returns no results but the fallback does, we switch to the fallback:
if not containers and fallback:
containers = fallbackThis gives us resilience against minor layout variations while still keeping extraction scoped to real product entries.
Iterating through results
We iterate through the selected containers and stop once we reach the requested limit:
products = []
for c in containers:
if len(products) >= max_items:
breakFor each container, we extract the core fields. If a product card does not contain both a title and a URL, we skip it.
title = _extract_title(c)
url = _extract_url(c)
if not title or not url:
continueExtracting product fields
Each product card is parsed using small helper functions, all defined in the same file.
image = _extract_image(c)
rating = _extract_rating(c)
reviews = _extract_reviews_count(c)
price = _extract_price(c)We then assemble a structured product object:
products.append(
{
"title": title,
"price": price,
"rating": rating,
"reviews": reviews,
"url": url,
"image": image,
}
)Field extraction helpers
Each helper focuses on one field and handles missing or partial markup safely.
Title extraction
def _extract_title(container) -> str:
a = container.select_one('a.a-link-normal[href*="/dp/"]')
if a:
t = a.get_text(" ", strip=True)
if t:
return t
img = container.select_one("img.s-image")
alt = img.get("alt") if img else ""
return alt.strip() if isinstance(alt, str) else ""Product URL
def _extract_url(container) -> str:
a = container.select_one('a.a-link-normal[href*="/dp/"]')
href = a.get("href") if a else ""
if isinstance(href, str) and href:
return "https://www.amazon.com" + href if href.startswith("/") else href
return ""Image
def _extract_image(container) -> Optional[str]:
img = container.select_one("img.s-image")
src = img.get("src") if img else None
return src if isinstance(src, str) and src else NoneRating
def _extract_rating(container) -> Optional[float]:
el = container.select_one("span.a-icon-alt")
text = el.get_text(" ", strip=True) if el else ""
if not text:
el = container.select_one('span:contains("out of 5 stars")')
text = el.get_text(" ", strip=True) if el else ""
if not text:
return None
m = re.search(r"(\d+(?:\.\d+)?)", text)
return float(m.group(1)) if m else NoneReview count
def _extract_reviews_count(container) -> Optional[int]:
el = container.select_one("span.s-underline-text")
text = el.get_text(" ", strip=True) if el else ""
m = re.search(r"(\d[\d,]*)", text)
return int(m.group(1).replace(",", "")) if m else NonePrice
def _extract_price(container) -> str:
whole = container.select_one("span.a-price-whole")
frac = container.select_one("span.a-price-fraction")
whole_text = whole.get_text(strip=True).replace(",", "") if whole else ""
frac_text = frac.get_text(strip=True) if frac else ""
if not whole_text:
return ""
return f"${whole_text}.{frac_text}" if frac_text else f"${whole_text}"At the end of this step, we have a list of structured product entries extracted directly from Amazon search results.
Each item includes:
- title
- price
- rating
- reviews
- product URL
- image URL
With search result extraction complete, we move to normalizing and returning the response, which is handled in src/normalize.py.
Normalizing the Response
At this point, our search extraction returns product objects, but the fields are not yet standardized. For example, price is still a string (like “$129.99”), review counts may include commas, and some fields may be missing depending on the card.
To make the API response consistent, we normalize everything inside src/normalize.py.
In api/search.py, normalization happens right after we fetch the raw results:
# api/search.py
normalized = normalize_response(raw_response, query)That single call converts the raw Bright Data output into a clean response shape that always looks like:
items: a list of normalized product objectscount: how many items we returned
Normalizing a dict response
normalize_response supports multiple input types. In our API flow, we pass a dict like {"products": [...]} from fetch_products(...).
Here is the dict branch:
# src/normalize.py
if isinstance(raw_response, dict):
products = raw_response.get("products", []) or raw_response.get("items", [])
normalized_items = [normalize_product(p) for p in products if isinstance(p, dict)]
return {"items": normalized_items[:limit], "count": len(normalized_items[:limit])}What this does:
- Reads products from products (or items if present)
- Normalizes each product using normalize_product
- Returns a consistent
{"items": [...], "count": N}payload
Normalizing a single product
Each product is normalized by normalize_product(...).
Price is parsed into a numeric value and a currency code using parse_price(...):
# src/normalize.py
price_str = raw_product.get("price", "")
price, currency = parse_price(price_str)Rating is coerced into a float if possible:
# src/normalize.py
rating = raw_product.get("rating")
if rating is not None:
try:
rating = float(rating)
except (ValueError, TypeError):
rating = None
else:
rating = NoneReview counts are normalized into an integer, supporting both reviews and reviews_count keys:
# src/normalize.py
reviews_count = raw_product.get("reviews") or raw_product.get("reviews_count")
if reviews_count is not None:
try:
reviews_count = int(str(reviews_count).replace(",", ""))
except (ValueError, TypeError):
reviews_count = None
else:
reviews_count = NoneFinally, we return a standardized product object:
# src/normalize.py
return {
"title": raw_product.get("title", ""),
"price": price,
"currency": currency,
"rating": rating,
"reviews_count": reviews_count,
"url": raw_product.get("url", ""),
"image": raw_product.get("image"),
"source": "brightdata",
}With normalization complete, we now have a consistent items list that is safe to return from the API and easy for clients to consume.
Running the Scraper on Vercel
This scraper runs as a Vercel Serverless Function. Locally, we run it using the Vercel development server so the api/ routes behave the same way they will in production.
Run locally with Vercel
From the root of the repository, start the dev server:
vercel dev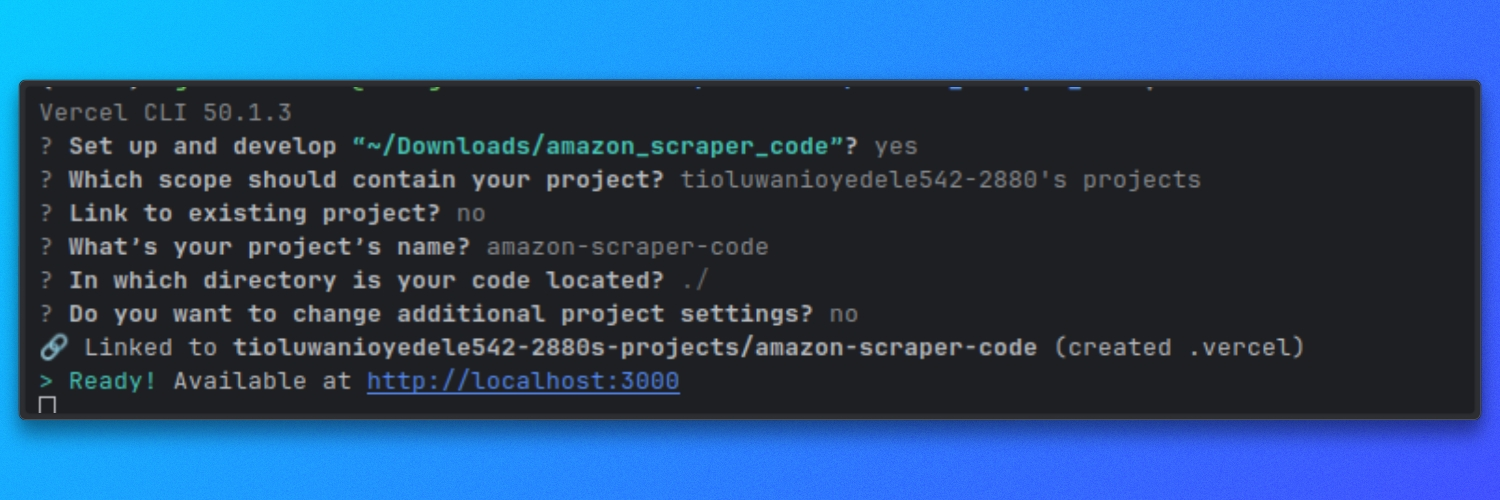
By default, this starts the server at:
http://localhost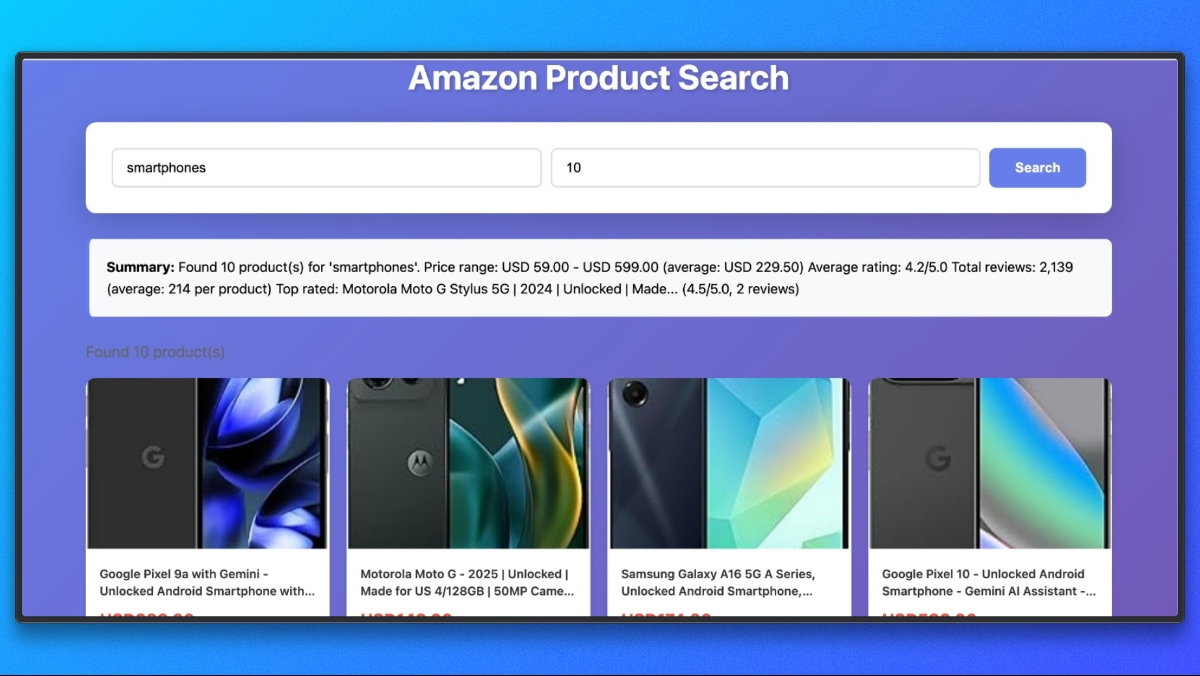
Now we have our full scraper project in place. You can run and try scraping different Amazon products.
Additionally, you can also scrape using the Bright `Data MCP with an AI agent, let’s see how you can do this briefly.
Connecting Claude Desktop to Bright Data’s Web MCP
Claude Desktop must be configured to start the Bright Data’s Web MCP server.
Open the Claude Desktop configuration file.
You can navigate to Settings, click the Developer icon, and select Edit Config. This opens the configuration file used by Claude Desktop.

Add the following configuration and replace YOUR_TOKEN_HERE with your Bright Data API token:
{
"mcpServers": {
"brightdata": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "YOUR_TOKEN_HERE"
}
}
}
}Save the file and restart Claude Desktop.
Once Claude restarts, Bright Data’s Web MCP will be available as a tool.
Extracting Amazon Product Listings with Claude
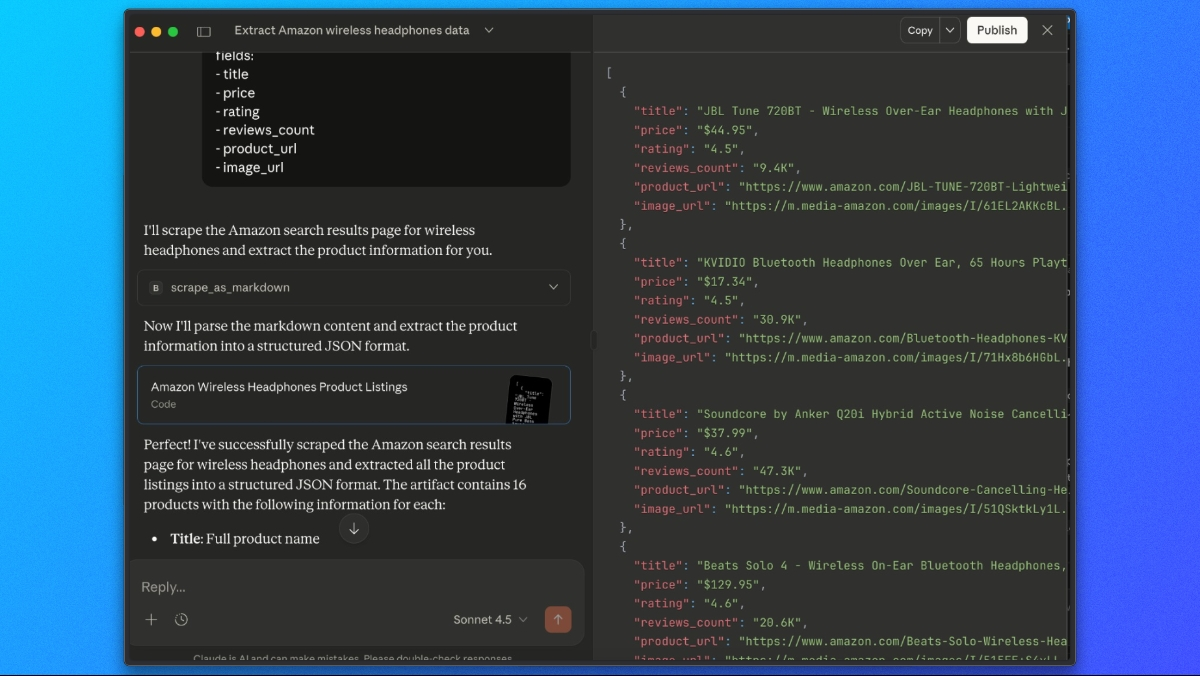
With Bright Data’s Web MCP connected, we can ask Claude to fetch and extract Amazon search results in a single step.
Use a prompt like this:
Please use the scrape_as_markdown tool to go to:
https://www.amazon.com/s?k=wireless+headphones
Then, look at the markdown output and extract all product listings into a JSON list with the following fields:
- title
- price
- rating
- reviews_count
- product_url
- image_urlClaude will fetch the page through Bright Data’s Web MCP, analyze the rendered content, and return a structured JSON response containing the extracted Amazon product data.
Closing Thoughts
In this tutorial, we explored three ways to scrape Amazon using Bright Data:
- Amazon Scraper API – The fastest way to get started. Use pre-built endpoints for product details, search results, and reviews without writing any scraping code.
- Custom scraper with Bright Data proxies – Build a production-ready scraper as a Vercel Serverless Function with full control over fetching, extraction, and normalization.
- Claude Desktop with Web MCP – Scrape Amazon interactively using AI-powered extraction without writing code.
Skip the scraping entirely
If you need large-scale, production-ready Amazon data without building infrastructure, consider Bright Data’s Amazon datasets. Get access to:
- Pre-collected product listings, prices, and reviews
- Historical data for trend analysis
- Ready-to-use datasets updated regularly
- Coverage across multiple Amazon marketplaces
Whether you need real-time scraping or ready-made datasets, Bright Data provides the infrastructure to access Amazon data reliably and at scale.

Technical Writer
Arindam Majumder is a developer advocate, YouTuber, and technical writer who simplifies LLMs, agent workflows, and AI content for 5,000+ followers.



