

In this guide, you will see:
- Why ChatGPT is an ideal choice for AI-powered web scraping.
- How to use ChatGPT to scrape website data with Python.
- The main limitations of this approach, and how to work around them.
Let’s dive in!
Can ChatGPT Scrape Websites?
Yes. ChatGPT can scrape websites in two ways: using its built-in Web Search feature to directly extract data from URLs (quick, but limited to small scale), or by generating Python scraping code you run yourself (scalable, production-ready, and what this tutorial covers).
The key limitation of both approaches is anti-bot protection: CAPTCHAs, IP blocking, and JavaScript rendering that basic scripts can’t handle. This tutorial covers how to solve that too.
Why Use ChatGPT for Web Scraping?
ChatGPT (or more precisely, GPT models) introduces a powerful new way to approach web scraping.
Instead of writing complex parsing logic to extract data from raw HTML, you can let the model handle the process. OpenAI’s APIs even offer dedicated endpoints for data parsing, making GPT models especially well-suited for web scraping tasks.
The biggest advantage is that you no longer need to write manual data parsing logic. Forget about dealing with brittle CSS selectors or XPath expressions. All you need is a solid prompt for data extraction. With just a few lines of code, you instruct AI to extract structured data from HTML pages.
Altogether, this AI-powered approach makes web scraping faster, more flexible, and much easier to maintain. For more details, refer to our guide on using AI for web scraping.
Scraping Scenarios
Some practical scenarios where ChatGPT can improve or replace traditional scrapers are:
- E-commerce sites with dynamic layouts: Automatically extract product details (price, description, images) even when pages vary in structure. This is for price monitoring and/or retrieving data from sites like Amazon or scraping Shopify-based stores.
- Content aggregation: Scrape blog posts, reviews, or news articles from multiple sources and summarize or standardize the output using GPT.
- AI-assisted web crawling: Combine GPT with a crawler to not only fetch pages but also determine which links are worth visiting or what content to prioritize scraping.
- Social media and fast-changing platforms: Extract relevant information from platforms with frequently updated content or difficult-to-parse UIs.
Supported Workflows
Below are some advanced workflows where ChatGPT scraping really shines:
- Retrieval-Augmented Generation (RAG): Add scraped web data directly to the ChatGPT context to generate smarter, more accurate, context-aware answers. See our guide on building a RAG chatbot powered by SERP data.
- Real-time data enrichment: Optimize internal tools, dashboards, or AI agents with scraped product, pricing, or trend data gathered on-the-fly.
- Rapid prototyping for market research: Use ChatGPT to quickly gather data from multiple platforms, without having to manually build custom scraping bots.
How to Perform Web Scraping with ChatGPT in Python
In this guided section, you will see how to build a ChtGPT scraping script. The target will be a specific product page from “Ecommerce Test Site to Learn Web Scraping”:
This page is an ideal target for testing because e-commerce product pages often vary in structure. They display different types of data depending on the product. That variability is what makes e-commerce web scraping so challenging, and where AI can make a real difference.
The scraper will use ChatGPT (GPT models) to extract these product details from the page without writing any manual parsing logic:
- SKU
- Name
- Images
- Price
- Description
- Sizes
- Colors
- Category
Note: The following example is written in Python for simplicity and because the OpenAI Python SDK is widely used. Still, you can achieve the same results using the JavaScript OpenAI SDK or any other supported language. We also suggest going over the Python web scraping guide.
Follow the steps below to learn how to scrape web data using ChatGPT!
Prerequisites
Before getting started, make sure you have the following:
- Python 3.8 or higher installed on your machine.
- An OpenAI API key to access GPT models.
Follow the official guide to retrieve your OpenAI API key.
Step #1: Create Your Python Project
Run the following command in your terminal to create a new folder for your web scraping project:
mkdir chatgpt-scraperThis chatgpt-scraper directory will serve as the project folder for web scraping with ChatGPT.
Navigate to the folder and create a Python virtual environment inside it:
cd chatgpt-scraper
python -m venv venvOpen the project folder in your favorite Python IDE. Visual Studio Code with the Python extension or PyCharm Community Edition are both excellent options.
In the project folder, create a scraper.py file:
chatgpt-scraper
├─── venv/
└─── scraper.py # <------------Right now, scraper.py is just an empty Python script. This will soon contain the logic for LLM web scraping via ChatGPT.
Next, activate the virtual environment in your terminal. On Linux or macOS, run:
source venv/bin/activateEquivalently, on Windows, execute:
venv/Scripts/activateGreat! Your Python environment is now set up for web scraping with ChatGPT.
Note: In the following steps, you will be guided through installing all the required dependencies one by one. If you prefer to install them all at once, run the following command:
pip install requests openai markdownify beautifulsoup4Step #2: Configure OpenAI in Python
To connect to ChatGPT (i.e., GPT models) for web scraping, you need to use the OpenAI Python SDK. In your activated virtual environment, install the library via the openai package:
pip install openaiThen, import the OpenAI client in your code:
from openai import OpenAITo connect to ChatGPT for web scraping, create a client instance:
client = OpenAI()By default, the OpenAI() constructor will look for your API key in the OPENAI_API_KEY environment variable. This is the recommended way to configure authentication securely.
For development or testing purposes, you can alternatively add the key directly in the code:
python
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>"
client = OpenAI(api_key=OPENAI_API_KEY)Replace the <YOUR_OPENAI_API_KEY> placeholder with your actual OpenAI API key.
Amazing! Your OpenAI setup is now complete, and you are ready to use ChatGPT for web scraping.
Step #3: Retrieve the HTML of the Target Page
To scrape data from a web page, you first need to get its HTML. You can achieve that by making a GET request to the target web server with a popular Python HTTP client like Requests.
In an activated virtual environment, install Requests with:
pip install requestsNext, import the library in scraper.py:
import requestsUse the get() method to send a GET request to the target URL:
url = "https://www.scrapingcourse.com/ecommerce/product/mach-street-sweatshirt"
response = requests.get(url)The target server will respond with the HTML document associated with the web page.
If you print response.content, you will see the full HTML document of the page:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<link rel="profile" href="https://gmpg.org/xfn/11" />
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php" />
<!-- omitted for brevity... -->
<title>Mach Street Sweatshirt – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>You now have the HTML of the target page. Use ChatGPT to parse that and extract structured data from it!
Step #4: Convert the Page HTML to Markdown [Optional]
Note: This step is not technically required, but it can save you significant time and money. Thus, it is worth implementing.
Before diving into ChatGPT scraping, take a moment to examine how other AI web scraping tools handle raw HTML. You will notice that many of them convert HTML to Markdown before passing it to the LLM.
Why do they do that? Our Kaggle benchmarks highlight two major reasons:
- Cost efficiency: Markdown uses fewer tokens than HTML, which reduces API usage and cuts costs.
- Faster processing: Fewer tokens also lower compute overhead, which results in faster responses.
For more details, read our guide on why AI agents prefer markdown over HTML.
Time to implement the HTML-to-Markdown optimization!
Open the target webpage in incognito mode (to ensure a new session), then right-click anywhere on the page. Select “Inspect” to open the browser’s Developer Tools. Explore the DOM, and you will find that all relevant product information is inside an element with the CSS selector #main:
As a first approach, you might consider sending the raw HTML of the entire page to ChatGPT for data parsing. However, this would include a lot of irrelevant content (such as headers, footers, and navigation elements). That adds unnecessary noise and could open the door to hallucinations.
Instead, you should utilize only the content within the #main element. That guarantees you are sending only the most relevant part of the page to the LLM, reducing the risk of inaccurate results. So, even if you choose not to convert the HTML to Markdown, scoping the input to just the key HTML elements is a best practice when working with LLMs.
To consider only the #main element, you need a Python HTML parsing library like Beautiful Soup. With your activated Python virtual environment, install it using this command:
pip install beautifulsoup4If you are not familiar with its API, take a look at our tutorial on Beautiful Soup web scraping.
Then, import it in scraper.py:
from bs4 import BeautifulSoupUse Beautiful Soup to:
- Parse the raw HTML fetched with Requests.
- Select the
#mainelement. - Get its HTML content.
Achieve that with the following snippet:
# Parse the HTML of the page with Beautiful Soup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element and get its outer HTML
main_element = soup.select_one("#main")
main_html = str(main_element)If you print main_html, you should see:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<div class="woocommerce-notices-wrapper"
id="notices-wrapper"
data-testid="notices-wrapper"
data-sorting="notices">
</div>
<div id="product-267"
class="product type-product post-267 status-publish first outofstock
product_cat-hoodies-sweatshirts has-post-thumbnail
shipping-taxable purchasable product-type-variable">
<!-- omitted for brevity... -->
</div>
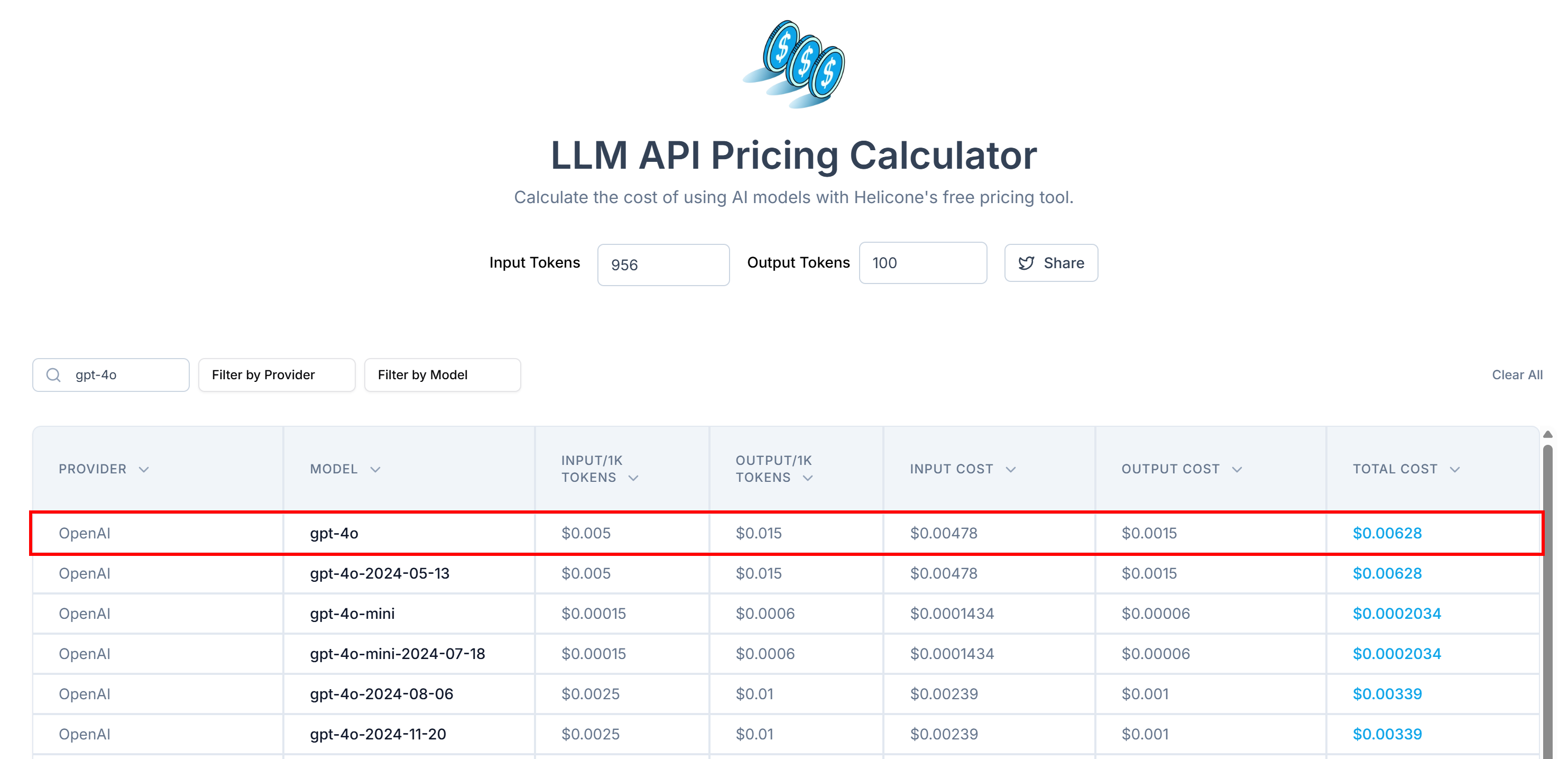
</main>Now, use the official OpenAI Tokenizer tool to check how many tokens the selected HTML string corresponds to:
Next, estimate the cost of sending these tokens to OpenAI using a tool like LLM API Pricing Calculator:
As you can see, this approach results in over 20,000 tokens, which translates to approximately $0.10 per request. That may not seem like much at first, but in a large-scale web scraping project involving thousands of pages, the costs can add up quickly.
To reduce token consumption, convert the extracted HTML into Markdown using a package like markdownify. Install it in your ChatGPT scraping project with:
pip install markdownifyDo not forget to import markdownify in scraper.py:
from markdownify import markdownifyThen, use it to convert the HTML from #main to Markdown with this line of code:
main_markdown = markdownify(main_html)You can simulate the output using any of the many HTML-to-Markdown converters available online. The conversion process will produce a result similar to this:
Looking at the “size” element near the end of the two text areas. You can notice that the Markdown version of the input is much more compact than the original #main HTML. Yet, if you inspect it, you will see that it preserves all the essential data needed for scraping.
Use OpenAI Tokenizer once again to see how many tokens the new Markdown input consumes:
With this simple trick, you reduced 21,504 tokens down to 956 tokens. That is a 95%+ token reduction!
This also translates into a huge reduction in OpenAI API costs per request:
The price dropped from around ~$0.10 per request to just ~$0.006 per request!
Step #5: Use ChatGPT for Data Parsing
The OpenAI SDK provides a specialized method called parse() for structured data extraction. That method accepts:
- The model to use for parsing (e.g.,
"gpt-4o"). - The output format, defined as a Pydantic model.
- A standard completions input (your system and user messages).
The parse() method will return an instance of the specified Pydantic class, or None if the model fails to produce a valid response.
Start by defining a Product class representing the structure of the product data you want to extract:
class Product(BaseModel):
sku: Optional[str] = None
name: Optional[str] = None
images: Optional[List[str]] = None
price: Optional[str] = None
description: Optional[str] = None
sizes: Optional[List[str]] = None
colors: Optional[List[str]] = None
category: Optional[str] = NoneThis Pydantic class maps the expected product structure found on the page. All fields are marked as optional, which is important because:
- Not all product pages may have all the data fields.
- If a required field is missing on the page, the model will not be forced to fill it out with potentially hallucinated data just to complete the structure.
Do not forget to add these two imports in scrape.py:
from pydantic import BaseModel
from typing import List, OptionalThen, define your scraping task with:
input = [
{
"role": "system",
"content": (
"You are a scraping agent that extracts structured product data in the specified format."
),
},
{
"role": "user",
"content": (
f"""
Extract product data from the given content.
CONTENT:\n
{main_markdown}
"""
),
},
]The above prompt instructs ChatGPT to extract structured data from the main_markdown content using the format defined in your Product class.
Tip: Test and refine the prompt in ChatGPT to ensure it returns the structure you expect before integrating it into your code.
Now call the parse() method with your configured parameters:
response = client.responses.parse(
model="gpt-4o",
input=input,
text_format=Product,
)You can now access the resulting parsed object using:
product = response.output_parsedproduct will be an instance of the Product class (or None, if the data parsing process fails).
Fantastic! You just relied on GPT models to extract structured product data from a webpage.
Step #6: Export the Scraped Data
At this point, the scraped data is stored in a Python object that is an instance of the Product class. Note that this object could also be None if the parsing failed.
To export that object to a JSON file, use the following code:
if product is not None:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product.model_dump(), json_file, indent=4)
else:
print("Extracted product was None!")This will create a product.json file containing the scraped data in structured JSON format.
Import json from the Python Standard Library:
import jsonWell done! Your ChatGPT-powered web scraper is now complete.
Step #7: Put It All Together
Below is the complete code for scraper.py, a script that uses ChatGPT for web scraping:
from openai import OpenAI
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
from pydantic import BaseModel
from typing import List, Optional
import json
# The Pydantic class representing the structure of the object to scrape
class Product(BaseModel):
sku: Optional[str] = None
name: Optional[str] = None
images: Optional[List[str]] = None
price: Optional[str] = None
description: Optional[str] = None
sizes: Optional[List[str]] = None
colors: Optional[List[str]] = None
category: Optional[str] = None
# Your OpenAI API key
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>"
# Initialize the OpenAI SDK client
client = OpenAI(api_key=OPENAI_API_KEY) # In production, read the OpenAI key from the envs
# Retrieve the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/mach-street-sweatshirt/"
response = requests.get(url)
# Parse the HTML of the page with Beautiful Soup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element, get its HTML, and convert it to Markdown
main_element = soup.select_one("#main")
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Define the input for the scraping task
input = [
{
"role": "system",
"content": (
"You are a scraping agent that extracts structured product data in the specified format."
),
},
{
"role": "user",
"content": (
f"""
Extract product data from the given content.
CONTENT:\n
{main_markdown}
"""
),
},
]
# Perform the scraping parsing request with OpenAI
response = client.responses.parse(
model="gpt-4o",
input=input,
text_format=Product,
)
# Get the parsed product data
product = response.output_parsed
# If OpenAI returned the desired content
if product is not None:
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product.model_dump(), json_file, indent=4)
else:
print("Extracted product was None!")Execute the script with the following command:
python scraper.pyThe scraper will take a while and then produce a product.json file in your project’s folder. Open it, and you should see:
{
"sku": "MH10",
"name": "Mach Street Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh10-blue_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh10-blue_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh10-blue_back.jpg"
],
"price": "$62.00",
"description": "From hard streets to asphalt track, the Mach Street Sweatshirt holds up to wear and wind and rain. An infusion of performance and stylish comfort, with moisture-wicking LumaTech\u2122 fabric, it\u2019s bound to become an everyday part of your active lifestyle.\n\n\u2022 Navy heather crewneck sweatshirt. \n\u2022 LumaTech\u2122 moisture-wicking fabric. \n\u2022 Antimicrobial, odor-resistant. \n\u2022 Zip hand pockets. \n\u2022 Chafe-resistant flatlock seams. \n\u2022 Rib-knit cuffs and hem.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Black",
"Blue",
"Red"
],
"category": "Hoodies & Sweatshirts"
}Et voilà! The ChatGPT scraper transformed unstructured data from an HTML page into a neatly organized JSON file.
Next Steps
To improve your ChatGPT scraper, consider the following enhancements:
- Make it reusable: Refactor the script to accept the target URL and model name as command-line arguments. This adds flexibility to your scraping logic.
- Secure your API key: Instead of hardcoding your OpenAI API key in the script, store it in a
.envfile and usepython-dotenvto load it safely. Alternatively, set it as a global environment variable namedOPENAI_API_KEY. Both approaches improve security by keeping sensitive credentials out of your codebase.
For integration of OpenAI models in other AI scraping tools, refer to the following guides:
- LLM Web Scraping with ScrapeGraphAI
- AI-Powered Web Scraping with
llm-scraper` - AI-Powered Web Scraping in Dify via a No-Code Workflow
Overcoming the Biggest Limitation of This AI-Powered Scraping Approach
The main bottleneck is the HTTP request made by requests. The above example works because the target site welcomes web scraping (remember that the name of the target site is “Ecommerce Test Site to Learn Web Scraping”). In the real world, things are different. Most sites protect their content with anti-scraping measures that can block your automated requests.
When this happens, your script will fail with a 403 Forbidden error (or similar) like:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: <YOUR_TARGET_URL>Additionally, the scraping method presented here does not work on websites that rely heavily on JavaScript. If you are targeting a dynamic site, requests is not enough, and you need a browser automation solution like Playwright or Selenium. So, even without strong anti-bot protection, many sites can break your ChatGPT scraper.
The best way to overcome these problems is by using a dedicated Web Unlocking API!
Bright Data’s Web Unlocker API is a powerful scraping endpoint that you can call from any HTTP client. It returns the fully unlocked HTML of any URL, which means it automatically bypasses anti-scraping blocks for you.
This is possible because it is supported by:
- A proxy network of over 150 million IPs.
- Fingerprint spoofing.
- CAPTCHA-solving capabilities.
- Many other advanced features.
Even better, Web Unlocker can return AI-optimized Markdown instead of raw HTML. This lets you skip the HTML-to-Markdown conversion step entirely (Step #5). That way, you can build an effective AI-powered scraper for any website with just a few lines of code.
To get started, follow the official Web Unlocker documentation and retrieve your API key. Then, replace the code from “Step #4” and “Step #5” with these lines:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/", # Replace with your target URL
"format": "raw",
"data_format": "markdown" # To get a response in Markdown"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)And just like that, no more blocks, no more limitations. You now have a fully functional AI web scraper powered by ChatGPT and Web Unlocker.
See the OpenAI SDK and Web Unlocker working together in a more complex scraping scenario.
Conclusion
In this tutorial, you learned how to combine ChatGPT (GPT models) with Requests and other tools to build an AI-powered web scraper. Getting blocked, which is one of the biggest challenges, was solved by using Bright Data’s Web Unlocker API.
As discussed, integrating ChatGPT with the Web Unlocker API lets you extract prompt-ready data from any site. All that without writing custom parsing code. This is just one of the many scenarios covered by Bright Data’s AI products and services.
Sign up now to Bright Data for free and experiment with our scraping solutions!
Web Scraping with ChatGPT FAQs
Yes. ChatGPT can scrape websites using its built-in Web Search for small-scale extraction, or by generating Python scraping code for scalable, production-ready scraping. Most real-world sites require handling anti-bot protection (covered in the Web Unlocker section above).
GPT-4o is currently the best balance of speed, accuracy, and cost for web scraping tasks. It handles structured data extraction reliably and supports Pydantic-based output formatting via the OpenAI API.
The ChatGPT-generated scraping code itself won’t get you blocked, your HTTP requests will. Use rotating proxies, set realistic request headers, and consider a dedicated solution like Bright Data’s Web Unlocker API to bypass CAPTCHAs and anti-bot measures automatically.
Not with requests alone. For JavaScript-heavy sites you need a headless browser like Playwright or Selenium, or a browser-based scraping API that handles JS rendering for you.

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.

