

Business data is often incomplete, inconsistent, or lacking context, which limits its usefulness for strategic decisions. AI data enrichment improves raw data by incorporating trustworthy external sources, providing actionable, high-quality datasets that support better decision-making across different industries.
This guide explains what AI data enrichment is, how it enhances traditional methods, where it’s applied across sectors, and how to implement it effectively.
What is AI data enrichment?
AI data enrichment augments first-party records with trusted external attributes. It uses artificial intelligence (AI) for entity resolution (ER), deduplication, and schema standardization – reducing manual lookups.
For example, sales teams enrich company lists with leadership details (CEO, founders), funding updates, technographics, and verified contacts. Finance teams combine client profiles with credit bureau attributes and transaction patterns. That’s decision-ready intelligence for sharper segmentation, smarter routing, more reliable scoring in sales, and stronger risk assessment in finance.
By expanding coverage and improving feature quality, enrichment also strengthens downstream models – reducing classic “garbage-in, garbage-out” effects when sound data governance, bias checks, and ongoing monitoring are in place.
How AI enhances traditional data enrichment
Traditional data enrichment relied heavily on manual research, lookup tables, spreadsheet formulas, or basic ETL scripts, which were time-consuming, error-prone, and difficult to scale. While some automated tools offered partial scalability, they lacked adaptability for diverse data sources. AI transforms this process by leveraging advanced technologies to deliver faster, more accurate, and scalable enrichment:
- Pattern recognition and source ranking. Machine learning (ML) models identify patterns to impute missing fields (e.g., predicting job titles from similar records) and rank data sources by coverage, precision, and freshness. For example, ML can prioritize a verified LinkedIn profile over an outdated database.
- Unstructured text processing. Natural language processing (NLP) and named entity recognition (NER) extract entities (e.g., names, organizations), topics, sentiment, and buying signals from unstructured sources like social media or company websites.
- Document understanding. Optical character recognition (OCR) and layout analysis convert documents like invoices, contracts, and forms into structured fields. AI-driven intelligent document processing (IDP) identifies complex layouts, such as tables or multi-column formats.
- Synchronization and freshness. AI coordinates multiple APIs and datasets, using backoff mechanisms, deduplication, and validation to ensure real-time data freshness.
These techniques deliver faster, more accurate enrichment, normalize fields to a clean schema, and maintain real-time data freshness without fragile rule sets.
Note – modern enrichment pairs LLM-powered extraction with classic master data management / extract–load–transform (MDM/ELT). Teams source trusted external data (marketplaces + web scraping), turn it into structured fields with LLMs, resolve entities into a single golden record, enforce data-quality checks, and serve results via the data warehouse and a vector database + retrieval-augmented generation (RAG) – measured end-to-end with evaluation and observability.
Use cases across industries
AI data enrichment delivers value across nearly every sector. Here are key applications:
- Marketing and sales. Enrich customer profiles with demographic, firmographic, and behavioral data (e.g., job titles, purchase history, social media activity) to refine segmentation, improve lead scoring, and personalize recommendations.
- Financial services. Integrate transaction histories with external signals (e.g., news, public filings, alternative credit data) to enhance risk assessment, fraud detection, and AML models while tailoring responsible credit offers.
- Healthcare. Combine EHR data with de-identified population and lifestyle datasets to predict readmissions and personalize care.
- Retail and e-commerce. Merge POS and catalog data with external factors (e.g., weather, competitor pricing) to optimize demand forecasting, inventory management, and reduce stockouts.
Practical implementation – building an AI enrichment system
Here’s how to build a company data enrichment system that processes a list of company names (typed or uploaded as CSV) to deliver comprehensive business intelligence.
You’ll need 3 core components:
- Web interface. A simple front end using Streamlit for users to input company names or upload CSV files.
- Data collection. Bright Data’s Web Scraper API to collect real-time public data from the web.
- AI processing. A large language model (LLM) like Google Gemini to parse raw pages and extract structured fields (e.g., CEO, headquarters, recent news, funding rounds).
How it works
Here’s the flow:
- Input validation. Accept company names via text input or CSV upload in Streamlit.
- Data scraping. Use Bright Data’s Web Scraper API to collect public data for each company.
- AI extraction. Normalize page text, then prompt Gemini to return a strict JSON object that matches your schema.
- Data processing. Clean and validate JSON output.
- Export. Display results in Streamlit as an interactive table with options like sorting, filtering, and download.
Check out the complete code in the AI Company Enrichment repo – follow the setup steps to run it locally. Here’s a sample interface:
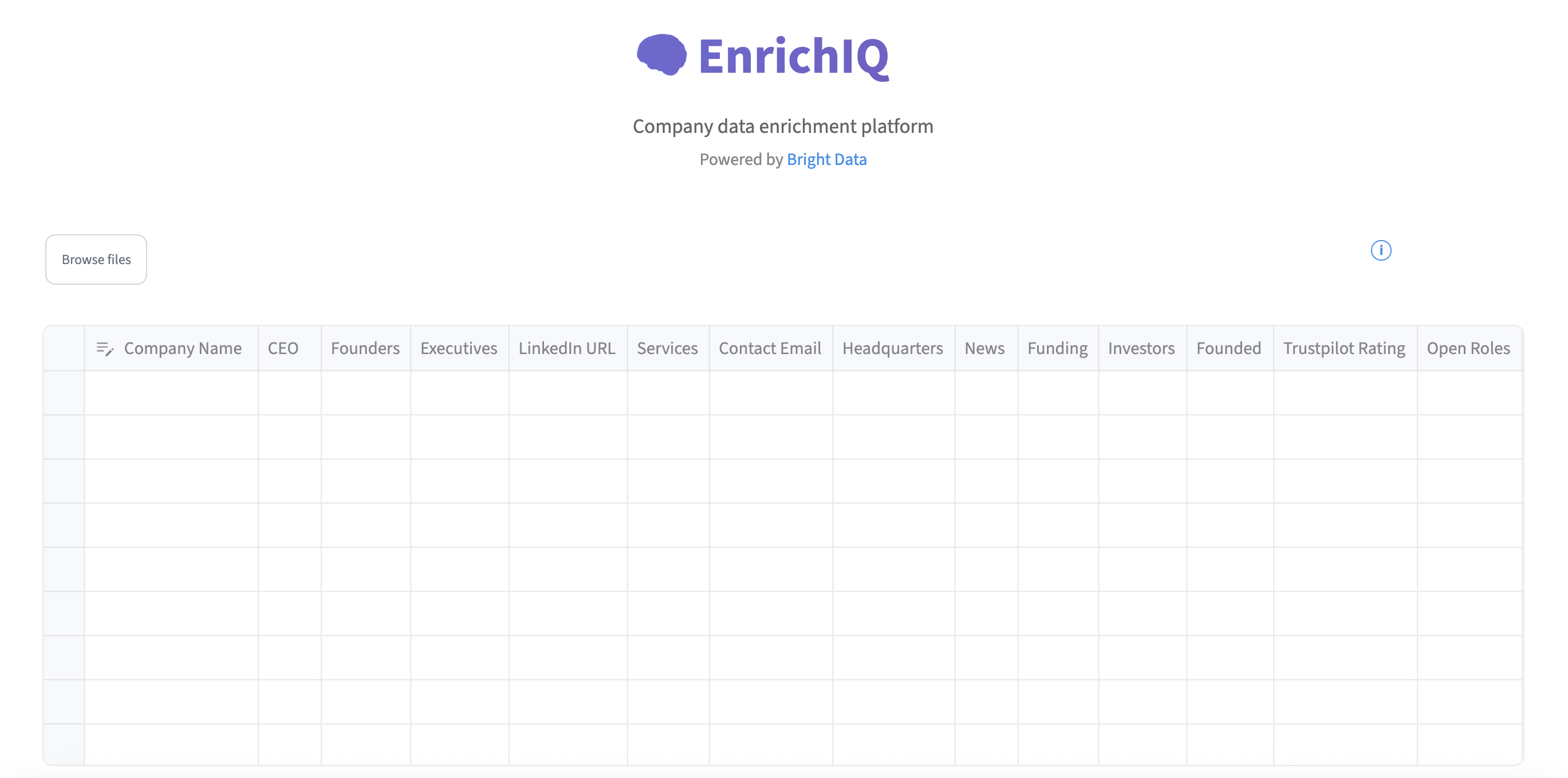
You’re ready to go!
Challenges and best practices
Effective AI data enrichment requires careful planning to address key challenges:
- Data quality issues. Inconsistent, incomplete, or biased data can undermine AI models, leading to unreliable predictions. Poor governance exacerbates these risks. Pre-enrichment data cleaning and validation are critical to ensure accuracy and fairness.
- Integration challenges. Many AI projects fail due to difficulties integrating enriched data with existing systems, often caused by incompatible formats or siloed infrastructure. Seamless workflows require robust tools and planning.
- Compliance requirements. Regulations like GDPR demand a lawful basis, purpose limitation, and defined storage periods, while CCPA/CPRA emphasize data minimization and transparency. Non-compliance risks fines and reputational damage.
- Infrastructure reliability. Data pipelines must maintain high uptime and manage usage limits to support uninterrupted AI workflows. Downtime or bottlenecks can disrupt model training and deployment. Bright Data’s platform offers 99.99% network uptime for uninterrupted data flows.
Best practices
- Choose Reliable, Compliant Infrastructure. Select platforms with proven uptime (ideally 99.9% or higher) and compliance with regulations like GDPR and CCPA. Evaluate multiple providers based on your use case, such as data volume or specific AI needs, and verify their ethical data sourcing practices.
- Implement validation and anomaly detection. Use automated tools to check for inconsistencies, duplicates, or outliers before enrichment. This ensures high-quality inputs and reduces downstream errors in AI models.
- Maintain detailed documentation. Document data sources, purposes, and retention policies to ensure traceability and compliance. This is essential for audits and building trust in AI systems.
- Leverage diverse data sources. Explore reputable data marketplaces or ready-made datasets to simplify enrichment. Compare providers for quality, cost, and relevance to your AI goals, and consider custom data collection if pre-built options don’t meet needs.
Conclusion
AI data enrichment transforms raw data into a competitive edge, driving smarter decisions, enhanced customer experiences, and revenue growth. By addressing challenges like data quality, integration, compliance, and infrastructure, organizations unlock AI’s full potential. Bright Data supports this journey with reliable infrastructure and high-quality datasets, enabling you to focus on insights.
Next steps
To master AI data enrichment, leverage Bright Data’s powerful tools and support:
- Power your AI models with advanced Web Access APIs for seamless data access.
- Explore the ultimate MCP tool to connect your AI to the web and enjoy 5,000 MCP requests every month for free.
- Use pre-collected datasets with billions of records for high-quality data.
- Integrate with AI platforms like n8n and CrewAI to connect and build AI agents.
- Learn more about AI data solutions in Bright Data’s blogs page.
For expert guidance, contact Bright Data’s support team.

Technical Writer
Satyam Tripathi helps SaaS and data startups turn complex tech into actionable content, boosting developer adoption and user understanding.



