

The #1 blocker for the agentic web is still the “old web”- dynamic, JS-heavy, CAPTCHAs, paywalls, popups, throttling, and messy HTML that agents can’t reliably parse. That’s why we built the Web MCP: so that agents can access and interact with that old web. That’s also why we decided to take the extra step and make the core capabilities available for free.
As the lead developer and maintainer of Bright Data’s Web MCP, we knew early on this wasn’t a “regular” MCP. Most MCP servers wrap a single SaaS/API (like Gmail, HubSpot, GitHub), which is a tidy, structured problem: one schema and auth model, predictable inputs and outputs, and repeatable actions with documented errors.
But the Web MCP wraps the entire internet.
It integrates with the open web, where every site is its own shifting “API,” pages render client-side, infinite scroll appears, and CAPTCHAs or throttling can change behavior minute to minute. Web MCP absorbs that chaos with resilient navigation and fetching, managed sessions and region control, and extraction that cleans messy HTML into usable JSON/Markdown.
What is the Web MCP
Web MCP lets your agent browse the real web. It handles JS-rendered pages and CAPTCHAs, then returns clean text your model can use. Think of it as “internet access for agents,” packaged as MCP tools.
Why free? The Free plan gives you just what you need to start building and testing without cost friction (plus enough for your day-to-day uses). It includes 5,000 requests/month for Rapid mode, exposing the two everyday tools: search results and “scrape as Markdown.” That’s perfect for most agents to find pages and read them reliably.
You can upgrade to Pro later for when you’re ready for clicks, scrolling, screenshots, and structured JSON extraction (set PRO_MODE in the local version or add &pro=1 in the remote one).
Quick start & docs
Guided tutorials
Engineering a web-scale MCP server
While “regular” MCPs offer deterministic tools over fixed APIs, the Web MCP offers fault-tolerant tools over a chaotic internet so agents can still act reliably. Doing this right carries both big engineering challenges and real responsibility.
Shipping an MCP for the entire web meant we had to meet three strict standards:
- Be lightweight & smart—so you don’t burn tokens just by connecting
- Be scalable & performant—so it works at production load, not just demos
- Be secure & compliant—so teams can deploy with confidence
1) Be lightweight & smart (token efficiency without dumbing it down)
We originally shipped the MCP with 60+ tools, but early users taught us a valuable insight: ~90% of agent calls used only two—search and scrape-as-markdown.
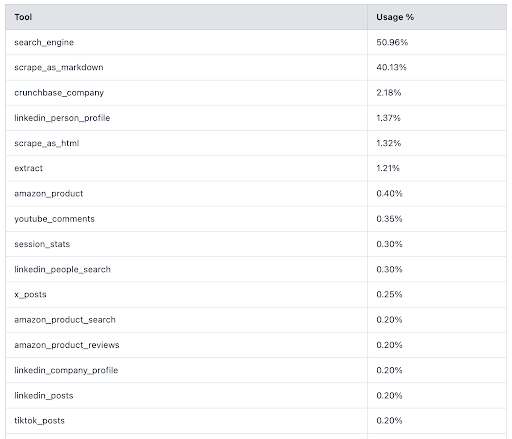
Yet typical MCPs enumerate dozens of tools up front. In MCP, the first step is /list/tools. With 60+ tools, that handshake alone cost ~17,000 tokens 🤯 before doing any real work. It also confused models and led to bad tool choices which made it slower and less consistent.
We learned that token costs during handshake scared users away far more than runtime latency, and that CAPTCHA handling was table stakes: without it, too many real-world pages simply failed.
Our answer: two modes.
Rapid mode (default)
Exactly two tools:
search_engine→ returns SERP resultsscrape_as_markdown→ fetches any URL as clean, LLM-friendly Markdown
Near-zero handshake: minimal tool metadata, minimal confusion
Covers the vast majority of search + extraction tasks
Fast and suits real-time use cases
Why scrape_as_markdown matters
Most “web” integrations stop at this point due to CAPTCHAs and blocks, which breaks on the modern web.scrape_as_markdown:
- Works on JS-heavy sites (full rendering)
- Auto-solves CAPTCHAs
- Returns clean Markdown that LLMs digest far better than raw HTML
When you need structured JSON (e.g., product data), switch to Pro and use the vertical scrapers.
Pro mode (opt-in)
- The full ~60-tool surface (e-commerce, social, news, real estate, finance, LinkedIn/HR, and more)
- Uses Bright Data’s Web Scraper API to return structured JSON when the workflow requires it
- You opt in when vertical structure justifies the token cost
Result: faster starts, fewer tokens, and happier agents that pick the right tool.
How to enable Pro
- Remote/hosted: append
&pro=1to your connection URL - STDIO/self-hosted: set
PRO_MODE = true
2) Be scalable & performant (built for real-world traffic)
We kept orchestration out of the hot path, so request time comes from the target site, not from Web MCP.
Architecture overview:
- Single MCP endpoint with a two-mode tool surface
- Headless browser orchestration for JS-heavy pages or if any interaction with the target site is needed
- Auto-solve CAPTCHAs and resilient session management
- Tunable concurrency and per-account isolation
In practice:
- Low handshake overhead (Rapid mode) → minimal startup time
- Robust scraping on real-world, JS-rich sites
- Operational headroom for batch jobs and high-QPS agents
3) Be secure & compliant (built on Bright Data’s GDPR program)
Web MCP is a thin wrapper over Bright Data’s APIs, so you inherit the platform’s privacy, security, and governance posture (GDPR/CCPA) instead of re-implementing controls in your agent. Read more in our Trust Center.
You’re running on Bright Data’s vetted infrastructure and policies—the same setup used by production customers—while the MCP layer stays minimal. The platform’s legal footing is proven, with victories in court cases with Meta and X Corp supporting responsible access to public web data.
What’s (intentionally) not inside Web MCP
Web MCP does not add its own isolation, residency, PII-redaction, or rate-limiting layers; those guardrails are handled by Bright Data’s APIs/policies and/or should be implemented in your agent/application according to your risk posture.
Easy Quick Start
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.prebuilt import create_react_agent
client = MultiServerMCPClient({
"brightdata": {
"url": "https://mcp.brightdata.com/sse?token=<API_TOKEN>", # add &pro=1 to opt into Pro
"transport": "sse",
}
})
tools = await client.get_tools() # Rapid mode returns the slim, high-value set
agent = create_react_agent("openai:gpt-4.1", tools)
# Your agent can now search and extract live sites reliably:
resp = await agent.ainvoke({"messages": "Find the latest guidance on US passport renewal fees and summarize the changes."})Free means “no excuses”
If your agent isn’t connected to the live web, it will be confidently wrong on time-sensitive tasks. With Web MCP’s free tier, you can fix that today.

AI Engineer
Meir is an AI Engineer at Bright Data, building agents that transform live web data into actionable answers using cutting-edge GenAI and automation.





