

In this managed vs API-based web scraping blog post, you will see:
- An overview of managed web scraping services and API-based web scraping solutions.
- What managed web scraping is, how it works, its main use cases, and when it is the best choice.
- What web scraping APIs are, how they function, their core use cases, and when they achieve the most value.
- A final, side-by-side comparison to help you decide which approach best fits your web data collection needs.
Let’s dive in!
Introduction to Managed Web Scraping Services and Web Scraping APIs
Managed web scraping and API-based web scraping are two of the most common approaches to collecting web data. In both cases, the main challenges of web scraping (e.g., browser fingerprinting, JavaScript rendering, TLS fingerprints, rate limits, CAPTCHAs, and similar obstacles) are outsourced to a third-party provider.
With managed services, the entire scraping process is completely outsourced. The provider works with you to understand your needs and delivers the required data, often enriched with insights and custom analysis. Essentially, it is an end-to-end, turnkey solution.
On the other hand, API-based web scraping involves building custom scripts, AI agents, or pipelines that connect to scraping APIs. These endpoints gather structured web data from known domains while taking care of anti-scraping bypass, scalability, and infrastructure. However, you are still responsible for integration, data storage, and other technical aspects.
In both approaches, choosing a reliable provider is pivotal. Bright Data is a leading provider of web scraping solutions, covering both approaches:
- Managed data acquisition: Access data and insights without development or maintenance effort through a fully managed, enterprise-grade service.
- Web Scraping APIs: A rich set of scraping endpoints for 120+ popular platforms. They support automatic proxy rotation, anti-bot bypass, JavaScript rendering, and more.
What sets Bright Data apart is its enterprise-ready infrastructure, supporting over 20,000 companies worldwide with 99.99% uptime and success rate, 24/7 expert support, compliant and ethically sourced data, and access to 400M+ real-user IPs across 195 countries—one of the largest proxy networks in the world.
Managed Web Scraping: A Deep Dive
Let’s start this managed vs API-based scraping article by focusing on managed web data acquisition services and understanding what they are best suited for.
What It Is
Managed web scraping is an end-to-end data collection service where a provider handles everything for you.
That includes sourcing web pages, bypassing anti-bot systems, parsing data from the identified pages, validating and cleaning results, scaling the infrastructure, and delivering structured, reliable, compliant data that meets your requirements.
Instead of building and maintaining scraping bots and managing the entire infrastructure, you simply describe your desires to the provider. In return, the provider delivers ready-to-use datasets, dashboards, or insights that meet your needs.
The goal of managed web scraping is to save time, reduce engineering effort, and lower operational costs while still giving you access to the data you want.
How It Works
When opting for a managed web data acquisition solution, the entire data journey is handled for you. From the initial setup to final delivery, the provider takes care of every step required to give the data you want in the desired format or presentation.
The process usually includes the following stages:
- Project kickoff: You start by selecting a managed data collection service. You then work closely with the provider’s experts to define data sources, required fields, insights, and KPIs that align with your business goals.
- Data collection: The managed scraping provider leads the full data collection process. Its team builds, automates, and scales the extraction solution based on your requirements and runs it continuously, while your project manager oversees execution.
You now have access to the data you requested. Still, with the best providers, the process does not stop there and includes two additional steps:
- Data validation and enrichment: The provider refines the data using automated deduplication, cross-referencing, and ongoing quality monitoring. The goal is to supply accurate, consistent, enriched, and high-quality data.
- Reports and insights: Once the data is collected and polished, the provider can also deliver insights through dashboards, real-time tracking, and expert guidance to support better business decisions.
As you can see, this approach truly goes from end to end. It ensures that the entire process of retrieving, processing, and finalizing data is fully managed for you, from raw data to actionable knowledge.
Requirements
Managed web scraping services require virtually no technical skills on your side. The reason is that the entire data scraping process is outsourced. Thus, you do not need technical expertise to build scrapers, manage proxies, or manage the underlying infrastructure.
The main requirement is having a clear understanding of your data needs, including aspects like the target sources, data fields, number of records, and update frequency. Obviously, you also need the ability to understand and take advantage of the delivered output.
Use Cases
Managed web scraping can support practically all industries. Providers can even aggregate data from multiple sources at once, such as combining information from several e-commerce platforms together with social media data for sentiment analysis.
Best For
Going for managed web scraping is ideal whenever you lack the skills, infrastructure, or capacity to handle a data collection project.
The reason is that building a reliable data pipeline fueled by web scraping is far from easy. You must choose the right scraping tools, integrate proxies, and implement anti-scraping bypass solutions to make your scripts effective in real-world scenarios.
On top of that, you have to monitor websites for structural changes, check that your custom software runs consistently, and manage the scalability of your infrastructure. And these are just some of the aspects involved in creating and handling a production-ready web scraping process…
All of that leads to significant time and cost invested in staff, servers, and third-party solutions. By embracing a managed service instead of building in-house, you eliminate those needs. That means a more streamlined workflow that can save a substantial amount of money, especially if your team has little or no prior experience with web scraping.
For example, consider the estimated ROI of choosing Bright Data’s managed web scraping services instead of implementing and managing the process yourself: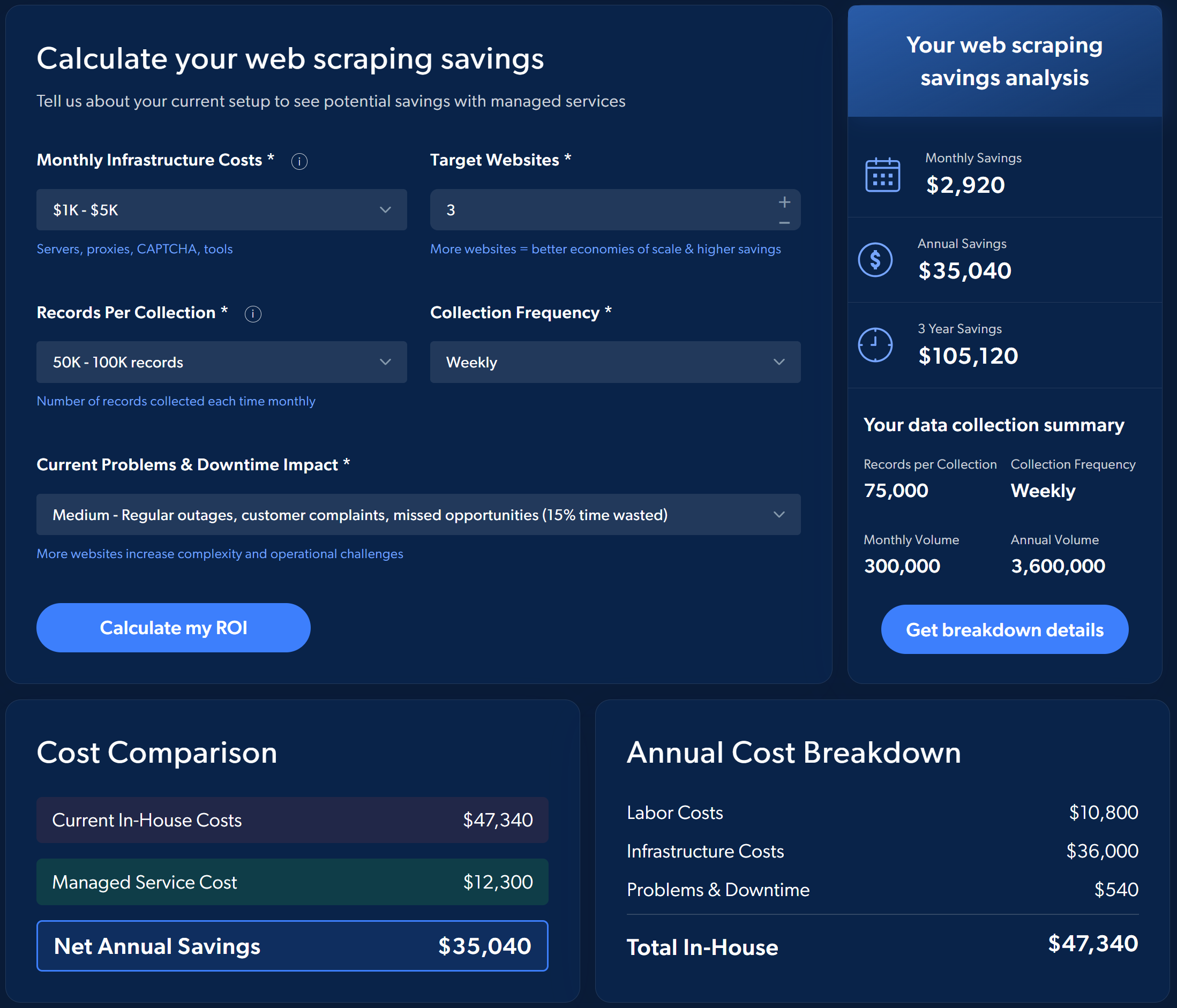
To get an idea of the potential savings, run a simple simulation directly on Bright Data’s managed data collection service page.
In short, managed services are ideal for businesses that want reliable, up-to-date, scalable, and validated data without investing in a dedicated team.
API-Based Web Scraping: An In-Depth Analysis
Continue this managed vs API-based web scraping blog post by exploring web data collection through scraping APIs, covering all the essential information you need to know.
What It Is
API-based web scraping involves connecting directly to a scraping API solution to gather web data. These APIs can be classified into three types:
- Official site APIs: Provide access to a predefined set of data directly from the website.
- General web unblocker APIs: Endpoints that bypass anti-bot protections on any web page.
- Specific web scraping APIs: Scrape particular domains and return structured data with a given schema.
Here, we will focus on the last two types of web scraping APIs. The reason is that official site APIs are often expensive, have strict rate limits, and give you little control, as the site can stop exposing data at any time. For more details, see our guide on web scraping vs API.
How It Works
API-based web scraping is a good middle ground between fully in-house and fully outsourced approaches.
The idea is to build simple scripts that connect to these APIs, which handle all the heavy lifting, including fetching pages, dealing with JavaScript rendering, bypassing anti-scraping protections, and potentially even returning already structured data.
You start by finding the right web scraping API provider for your needs. If scraping APIs that provide the data you want are available, you should use them directly. Otherwise, you can opt for a web unblocker API that delivers the unlocked HTML of the web pages of interest.
When using scraping APIs, you only need to build simple scripts that call the API, handle errors with retry logic in case of occasional failures, and store the retrieved data in a database, on local files, in the cloud, or using your preferred storage method.
If you choose a web unblocker API, you have to implement custom data parsing logic, either using CSS selectors/XPath expressions or artificial intelligence. Once the data is extracted from the unlocked HTML, it should be stored as mentioned earlier.
Finally, the data must be validated, cleaned, processed, and analyzed to extract insights.
Requirements
While API-based web scraping is much lighter than building a web scraper from scratch, it still requires some technical setup.
You require basic coding skills to write scripts that programmatically call the APIs in your preferred programming language. You should also know how to approach authentication, manage parallel HTTP requests, and deal with common errors.
Note: Top providers often offer no-code solutions, allowing you to use web scraping APIs without writing any code or needing technical skills.
To save the collected data, you also need to be familiar with data storage options. Plus, you must have data management skills to avoid duplicates and ensure regular updates with proper versioning.
If using a web unblocker API instead of a dedicated web scraping API, you need additional skills to parse HTML and structure the data according to your needs. Finally, data-related skills are necessary to prepare the data for processing, visualization, and analysis.
Use Cases
Web scraping APIs support a long list of use cases, such as:
- E-commerce: Retrieve product information, prices, reviews, and seller data from sites like Amazon, eBay, and Walmart.
- Finance: Access stock data, financial reports, and market trends from platforms such as Yahoo Finance or Nasdaq.
- Job market: Collect job postings and company data from LinkedIn, Indeed, and others.
- Travel: Track flights, hotel availability, and pricing from Expedia, Booking.com, and similar sites.
- B2B: Get company data from sources like Crunchbase or ZoomInfo.
- Social media: Monitor posts, trends, and engagement from X, Instagram, and TikTok.
- Search engines: Perform programmatic searches on search engines like Google, Bing, Yandex, and others using specialized SERP and web search APIs.
With a web unblocker API, you can then access structured data from virtually any website, even those without a dedicated scraping API.
Best For
API-based scraping is best suited for situations where you need consistent, structured web data without totally outsourcing the process. It strikes a balance between in-house development and managed services, enabling you to retain control over data collection while the API takes care of the main challenges.
Managed vs API-Based Web Scraping: Head-to-Head Comparison
Now that you understand both methodologies for obtaining web data, it is time to compare them in a managed vs API-based scraping section.
How to Choose the Right Scraping Approach
Compare managed web scraping with API-based web scraping in the summary table below:
| Managed web scraping | API-based web scraping | |
|---|---|---|
| Description | You describe your requirements to the provider, which extracts and delivers data from the selected sources. | You connect to APIs to retrieve web data. The API handles page fetching, anti-bot bypass, proxy integration, etc. |
| Who It is for | Businesses needing a hands-off solution without in-house skills or infrastructure. | Teams with in-house engineers or technical resources who want control over data collection while outsourcing the heavy lifting. |
| Setup and maintenance | Fully managed end-to-end by the provider. No technical setup required on your side. | Requires basic programming skills and setup of scripts, error handling, and storage. |
| Anti-Bot handling | Fully handled by the provider. | Fully handled by the provider. |
| Infrastructure | Fully managed by the provider. | Managed by the API provider, but deployment and integration of your scripts is your responsibility. |
| Delivery | Data is delivered in your desired format and way. | Data is returned by the scraping API in HTML, JSON, or Markdown format. |
| Data cleaning and QA | Automated validation, deduplication, enrichment, and ongoing quality checks handled by the provider. | You are responsible for further validation, cleaning, and processing. |
| Insights and dashboards | Provider can deliver custom dashboards, reports, analytics, and actionable insights. | Not included. |
| Consulting and strategy | Expert recommendations and guidance included to optimize data collection and usage. | Not included. |
| Support | Dedicated support team, including data concierge for troubleshooting and project management. | Limited to API documentation and basic technical assistance. |
Managed Web Scraping
👍 Pros:
- Access to ready-to-use structured data, dashboards, or insights.
- End-to-end service covering data collection, validation, enrichment, and delivery, with no technical skills required.
- Reduces operational costs and engineering effort.
- Applicable to virtually any use case, industry, or scenario.
- Support and recommendations from a multi-area team of experts.
👎 Cons:
- Less control over the scraping process.
- Full dependency on a specific third-party provider.
API-Based Web Scraping
👍 Pros:
- Easy integration into existing systems.
- High speed and concurrency, supporting many simultaneous requests.
- No need to worry about blocks or anti-bot restrictions.
- No infrastructure management or maintenance required.
- Well-suited for building custom scraping tools for AI agents or automated workflows.
👎 Cons:
- Requires technical skills.
- You are responsible for validating, cleaning, and structuring the data.
Final Comment
Managed web services and web scraping APIs both aim to deliver web data, but they tackle the problem differently.
Web scraping APIs are endpoints for simplified data retrieval, letting developers integrate them directly into scripts, pipelines, or even AI agents and workflows. They are ideal when you need specific data points, like product prices, reviews, or search results, without having to manage the underlying infrastructure. However, they still require some setup and technical skills.
Conversely, managed web scraping acquisition services handle the entire data lifecycle—from extraction to validation, enrichment, and delivery—without requiring in-house engineering or maintenance.
In particular, Bright Data’s Managed Data Acquisition solution exemplifies that approach. It provides enterprise-grade pipelines, automated quality checks, compliance with privacy laws, and dashboards for real-time insights. You just need to define your targets and KPIs, and Bright Data takes care of scaling, monitoring, and delivering ready-to-use structured data to help you maximize your return on investment.
In conclusion, think of it this way: APIs give you the tools; managed services hand you the finished product!
Conclusion
In this guide, you examined the nuances of the two most popular approaches to web scraping: managed services and API-based solutions.
You learned that managed web scraping is ideal when you want a fully hands-off experience. It gives you not only the data but also validated datasets and interesting insights. All that without dealing with technical complexity. In contrast, web scraping APIs offer greater flexibility and control, but may require coding experience.
Whichever approach you choose, Bright Data has you covered. It offers industry-leading web scraping APIs such as the Unlocker API and domain-specific Scraper APIs, as well as enterprise-grade managed data acquisition services.
Sign up for Bright Data for free and explore our web scraping solutions today!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.




