
In this tutorial, you will see:
- What OpenAI Codex CLI is and what it can do.
- How Codex can become even more effective with web interaction and data scraping capabilities.
- How to connect Codex CLI with the Bright Data MCP server to build a next-level AI coding agent.
Let’s dive in!
What Is the OpenAI Codex CLI?
The OpenAI Codex CLI, simply known as Codex or Codex CLI, is an open-source command-line interface tool developed by OpenAI. Its goal is to bring the power of their LLMs directly to your terminal.
Below are some of the main tasks it can help developers with:
- Code generation and modification: Understands natural language instructions to generate valid code and apply changes within your project.
- Code comprehension and explanation: Helps to understand unfamiliar codebases or explains specific code segments clearly.
- Debugging and testing: Assists in identifying and fixing bugs, writing tests, and even running those tests locally.
- Repository management: Integrates with version control systems like Git to manage files, set up migrations, update imports, and more.
- Shell command execution: Runs shell commands for tasks such as installing dependencies or running tests.
As you cal tell, Codex CLI acts as a lightweight, local coding assistant. The library is built in Rust and available as an open-source Node.js package.
Although it was released only in mid-May 2026, it has already gained over 34k stars on GitHub. That is a strong indicator of its adoption and popularity in the IT community.
Why Extend Codex CLI with Web Interaction and Data Retrieval Capabilities?
No matter how advanced the OpenAI models integrated into the Codex CLI may be, they still share the common limitations inherent to all large language models.
OpenAI LLMs generate responses based on the static datasets they were trained on, which is essentially a snapshot frozen in time. This is especially problematic given how rapidly development technologies evolve.
Now, imagine improving your Codex CLI coding assistant with the capability to access up-to-date tutorials, documentation pages, and guides—and learn from them. On top of that, picture it browsing dynamic websites as effortlessly as it can explore your local file system. This major boost in functionality becomes achievable through its integration with the Bright Data MCP server.
The Bright Data MCP server offers over 60 AI-ready tools designed for real-time web data extraction and interaction. Those tools are all powered by Bright Data’s rich AI data infrastructure.
Below are some examples of what you can accomplish by merging the OpenAI CLI with Bright Data MCP:
- Automatically fetch search engine results pages to embed relevant contextual links in your text documents.
- Gather the latest tutorials or documentation, absorb the information, and generate working code or create projects from scratch.
- Extract live data from websites and store it locally for use in testing, mocking, or analysis.
For the complete list of tools available in the Bright Data MCP server, check out the documentation.
See the Bright Data MCP server in action within Codex CLI!
How to Connect the OpenAI Codex CLI to the Bright Data Web MCP Server
Learn how to install the OpenAI Codex CLI and configure it to interact with the Bright Data MCP server. In detail, we will use the resulting enhanced coding CLI agent to perform a task that:
- Scrapes structured data from an Amazon product page.
- Stores the data in a local file.
- Defines a Node.js script to load the data and process it.
Follow the steps below!
Prerequisites
To follow along with this tutorial, make sure you have:
- Node.js 20+ installed locally (we recommend the latest LTS version).
- An OpenAI API key.
- A Bright Data account with an API key ready.
The steps below will walk you through setting up both the OpenAI and Bright Data keys when needed.
The system requirements for the OpenAI Codex CLI are:
- macOS 12+, or
- Ubuntu 20.04+/Debian 10+, or
- Windows 11 via WSL 2 (note that version 2 of the Windows Subsystem for Linux is required).
Then, optional but helpful background knowledge to better understand this guide is:
- A general understanding of how MCP works.
- Familiarity with the Bright Data MCP server and its available tools.
Step #1: Install the OpenAI Codex CLI
First, retrieve your OpenAI API key by following the official guide. If you already have one, you can skip this step.
Once you have your OpenAI API key, open your terminal and set it as an environment variable:
export OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"Replace the <YOUR_OPENAI_API_KEY> API key with your actual OpenAI API key. Keep in mind that the above command will only set the key for your current terminal session. Alternatively, you can also authorize via your ChatGPT plan by logging in from the terminal.
Thun, run the following command to install OpenAI Codex CLI globally via the official @openai/codex package:
npm install -g @openai/codexIn the same terminal session where you set the OPENAI_API_KEY, navigate to the folder you want to work in. Launch Codex CLI with:
codexYou will be prompted for permission to operate on the current directory:
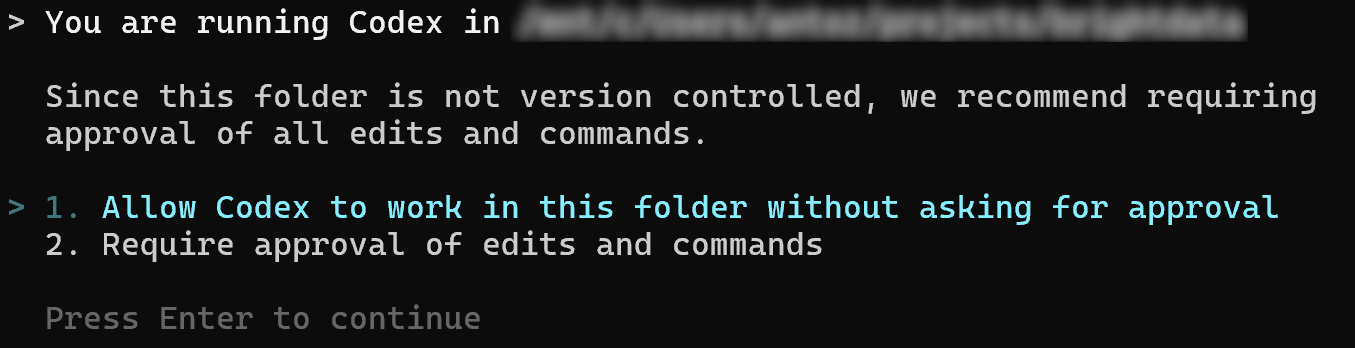
Since this is just a simple test, you can select Option 1. For better security, choose Option 2.
After pressing Enter, you should see:
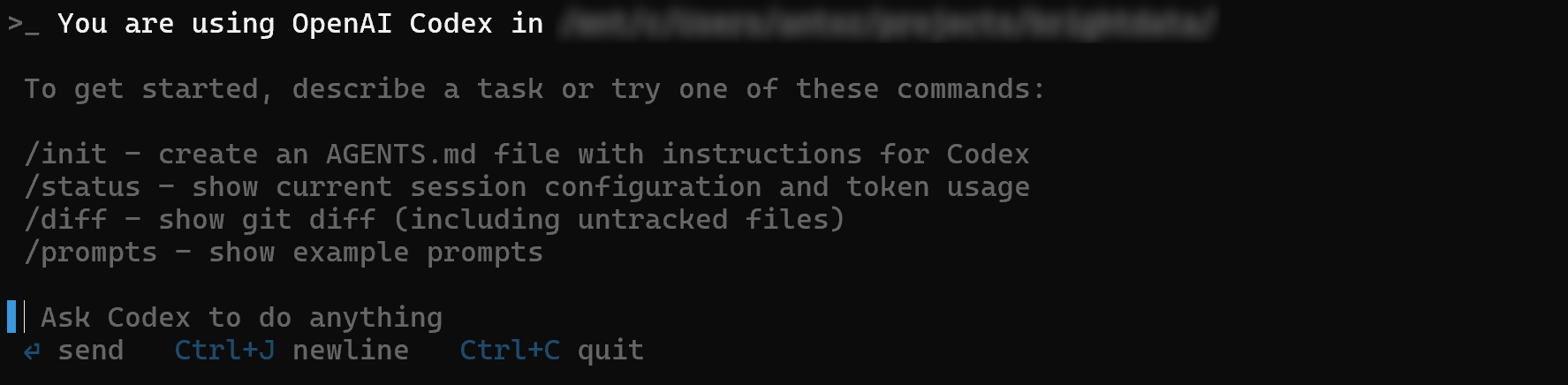
In the “Ask Codex to do anything” section, you can now type your prompt. By default, Codex will rely on a GPT-5 model. To change the underlying LLM, refer to the official documentation.
Done! The OpenAI Codex CLI is now installed and ready to use.
Step #2: Test the Bright Data Web MCP Server
If you do not have a Bright Data account yet, sign up for Bright Data. If you already have one, simply log in.
Next, follow the official Bright Data documentation to retrieve your API token. For this guide, we will assume you are using a token with Admin permissions.
Install the Bright Data MCP server globally through the @brightdata/mcp official package:
npm install -g @brightdata/mcpTest the installation with the following command:
API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" npx -y @brightdata/mcpReplace the <YOUR_BRIGHT_DATA_API_KEY> placeholder with the actual API token you generated earlier. The above command sets the required API_TOKEN environment variable and then starts the Bright Data MCP server locally.
If everything is working, you should see logs similar to this:

On the first launch, the MCP server will automatically create two default proxy zones in your Bright Data account:
mcp_unlocker: A zone for Web Unlocker.mcp_browser: A zone for Browser API.
These zones are required for the MCP server to power all of its tools.
To confirm that the zones were created, log in to your Bright Data dashboard. Reach the “Proxies & Scraping Infrastructure” page, and you should see both mcp_* zones listed:
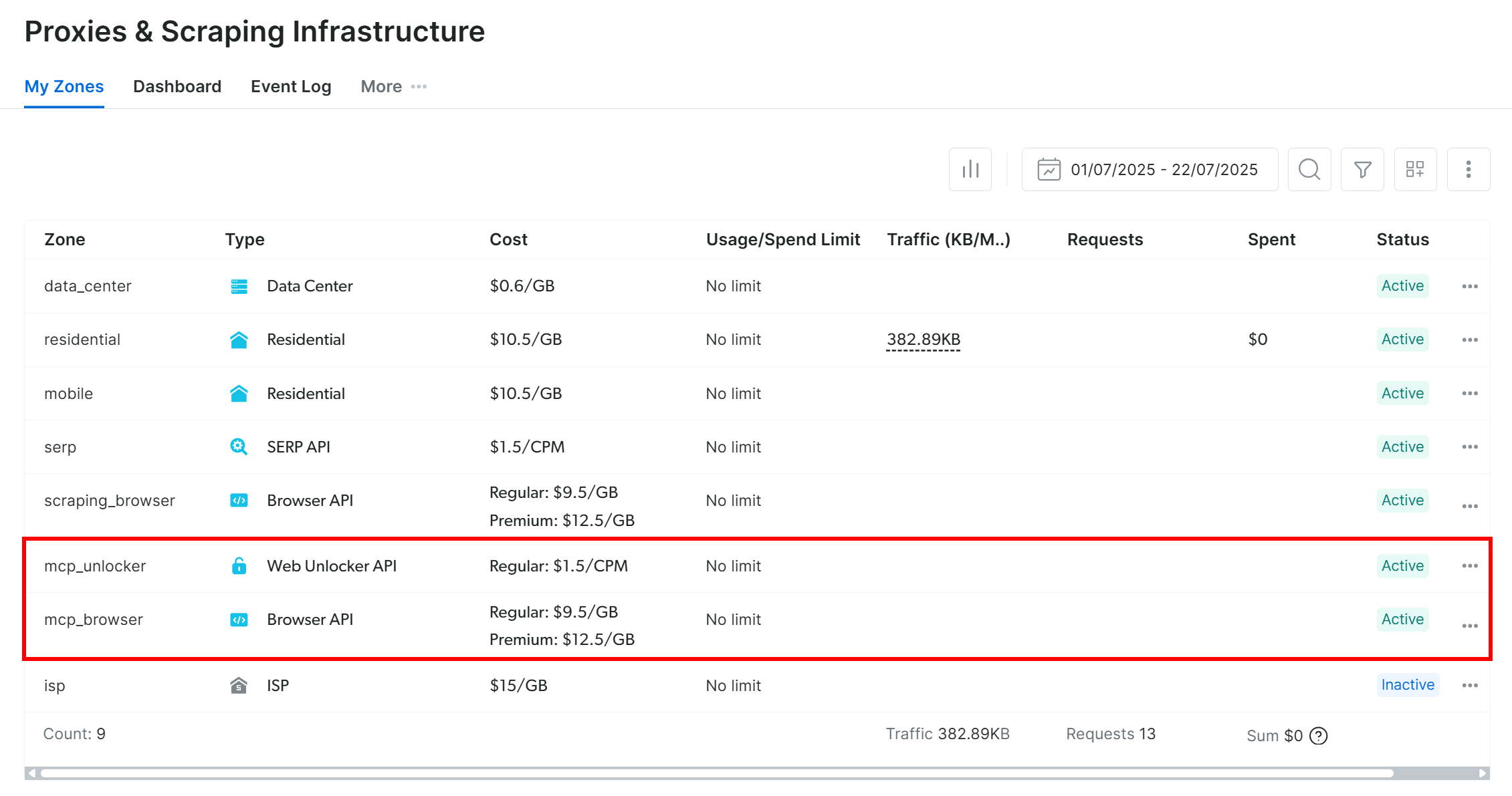
If your API token does not have Admin permissions, these zones will not be created automatically. You will need to create them manually and set their names via environment variables, as described in the official documentation.
Note: By default, the MCP server only exposes the search_engine and scrape_as_markdown tools. To enable access to all other tools for browser automation and structured data extraction, you must execute the MCP server in Pro Mode. To do so, set the PRO_MODE=true environment variable before launching the server:
API_TOKEN="<YOUR_BRIGHT_DATA_API_KEY>" PRO_MODE="true" npx -y @brightdata/mcpAwesome! You successfully confirmed that the Bright Data MCP server works on your machine. Stop the server now, as we will configure the OpenAI Codex CLI to start it automatically in the next step.
Step #3: Configure the Bright Data Web MCP Server Connection in Codex
Codex supports MCP integration through a configuration file located at ~/.codex/config.toml (~ means your home directory). That file is not created during installation, so you have to create it first.
Start by adding the .codex folder:
mkdir ~/.codexThen create and edit the configuration file:
nano ~/.codex/config.tomlInside the nano editor, make sure the config.toml file contains the following mcp_servers entry:
[mcp_servers.brightData]
command = "npx"
args = ["-y", "@brightdata/mcp"]
env = { "API_TOKEN" = "<YOUR_BRIGHT_DATA_API_KEY>", "PRO_MODE" = "true" }Press CTRL + O and Enter to write the file, then CTRL + X to save and exit (Use ⌘ Command instead of CTRL on macOS).
Important: Replace the <YOUR_BRIGHT_DATA_API_KEY> placeholder with your actual Bright Data API token.
The [mcp_servers] section in the above config snippet tells Codex how to launch the Bright Data MCP servers. In particular, it specifies the arguments and environment variables to produce the same npx command you tested earlier. Remember that enabling PRO_MODE is optional but recommended.
Now, the OpenAI Codex CLI will be able to automatically launch the MCP server in the background with that configured command and connect to it.
Great! Time to test the integration.
Step #4: Confirm the MCP Server Connection
If the OpenAI Codex CLI is still running, exit it using the /quit command, then relaunch it with:
codexCodex CLI should now automatically connect to the Bright Data MCP server.
As of this writing, Codex does not provide a dedicated command to verify MCP server integration (unlike the Gemini CLI, which provides detailed MCP connection info).
However, if Codex fails to connect to the configured MCP server, it will display an error message like this:
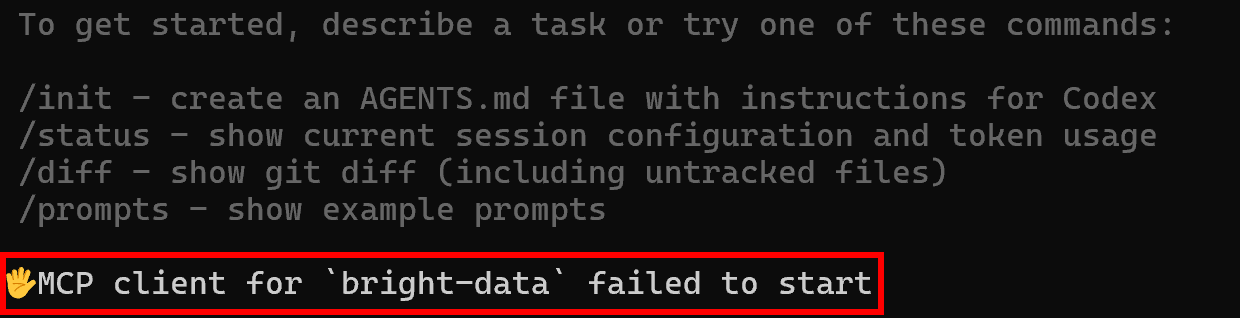
If you DO NOT see this error, you can assume the MCP integration is working correctly. Well done!
Step #5: Run a Task in Codex
Now that Codex is connected to the Bright Data MCP server, let’s put it to work with a real-world task. For example, try the following prompt in the OpenAI Codex CLI:
Extract data from the following Amazon page: "https://www.amazon.com/crocs-Unisex-Classic-Black-Women/dp/B0014BYHJE/". Save the resulting JSON into a local "product.json" file. Next, build a Node.js "index.js" script to read and log its contents in the console.This mimics the practical use case of collecting real-world data for analysis, mocking APIs, or other development tasks.
Paste the prompt into the CLI and press Enter. The execution flow should look similar to this:
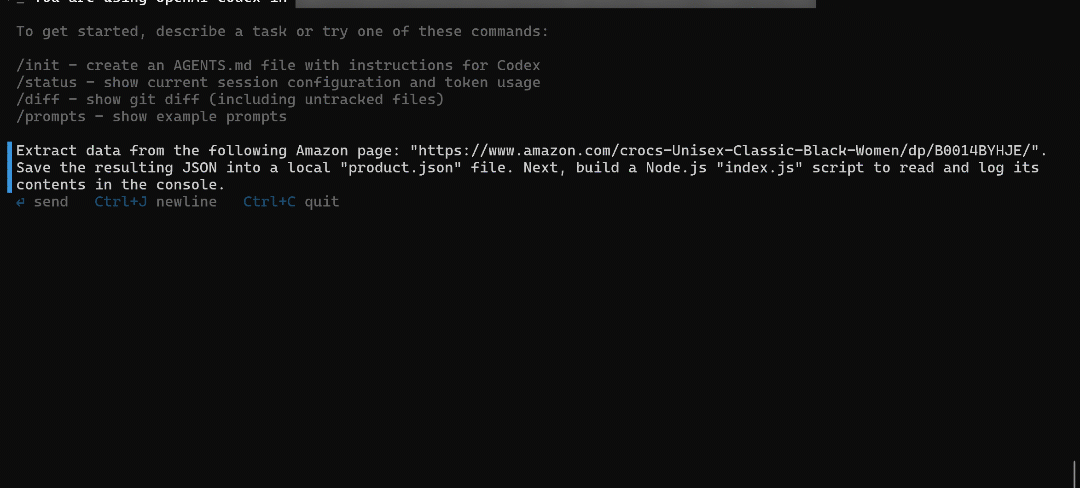
The above GIF has been sped up, but this is what should happen:
- The LLM selects the appropriate MCP tool (in this case,
web_data_amazon_product) and launches the Amazon scraping task through the MCP server. - The CLI periodically checks if the scraping task has finished and the data is ready.
- Once complete, the raw product data returned by the tool in JSON format is displayed.
- Codex validates the JSON to ensure it is properly structured.
- The data is saved to a local file named
product.json. - You are prompted to add more fields to the JSON. Answer “No.”
- Codex generates a Node.js script,
index.js, that loads and prints the JSON contents fromproduct.json.
During the run, you will notice a log entry like this:

This confirms that the CLI called the web_data_amazon_product tool from the Bright Data MCP server using the Amazon product URL read from the prompt. The JSON you see is the structured result returned by Bright Data’s Amazon Scraper, which was called by the tool behind the scenes.
After execution, your working directory should contain these two files:
├── product.json
└── index.jsOpen product.json in VS Code, and you will see:
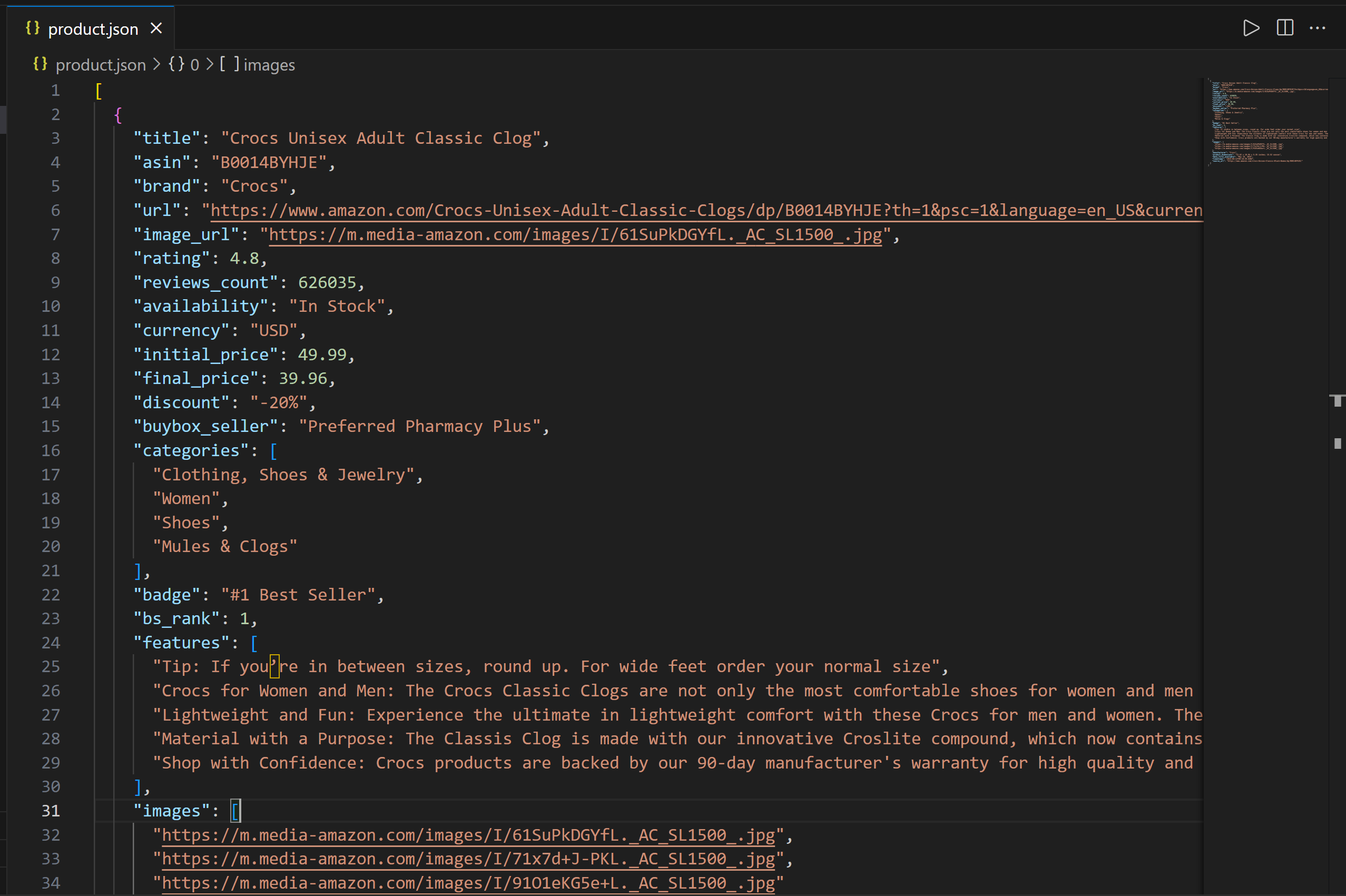
This file contains real product data extracted from Amazon via the Bright Data MCP integration.
Now, open index.js:
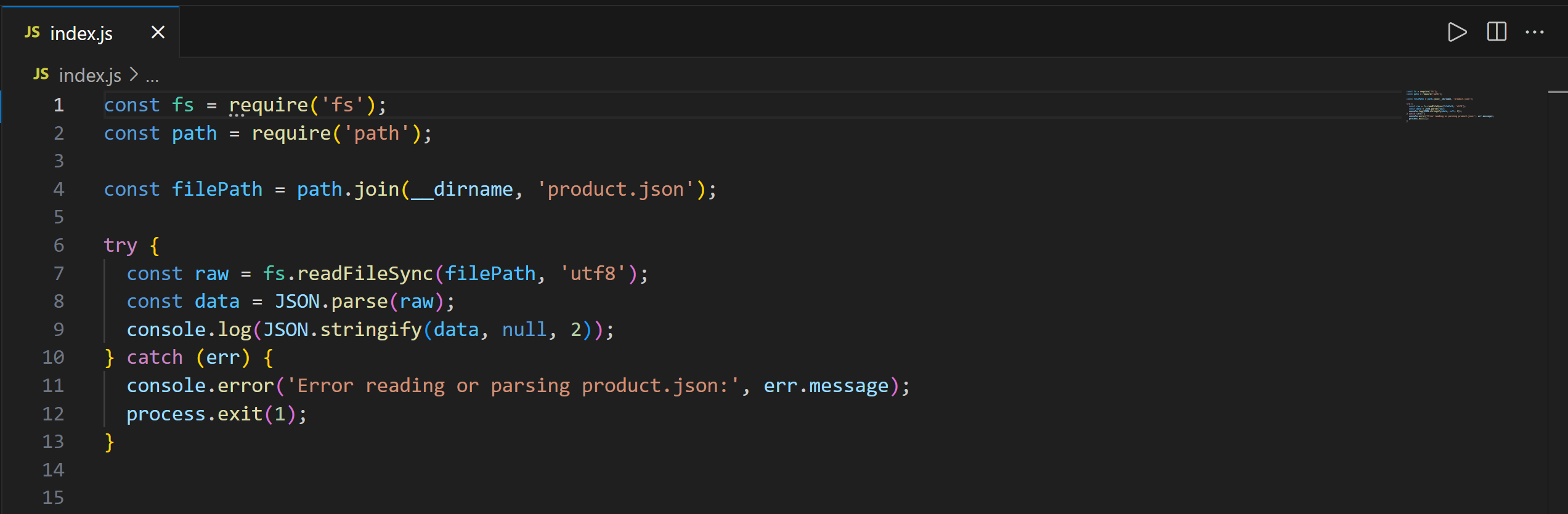
This script includes the JavaScript logic to load and print the contents of product.json in Node.js.
Execute the index.js script with:
node index.jsThe result should be:
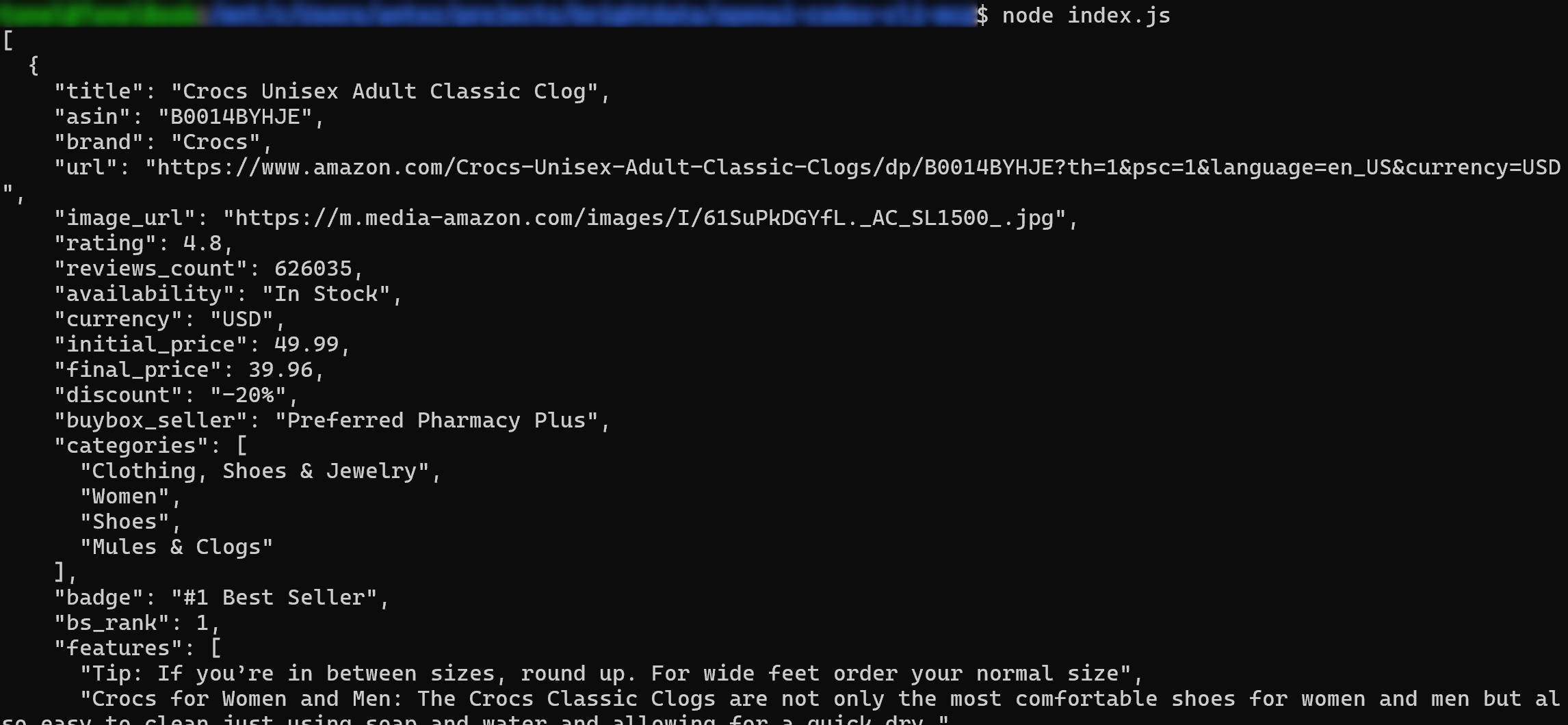
Et voilà! The workflow completed successfully.
Important: What you see is actual scraped data, not information made up or hallucinated by AI. Specifically, the content in product.json matches the data you can see in the original Amazon product page:
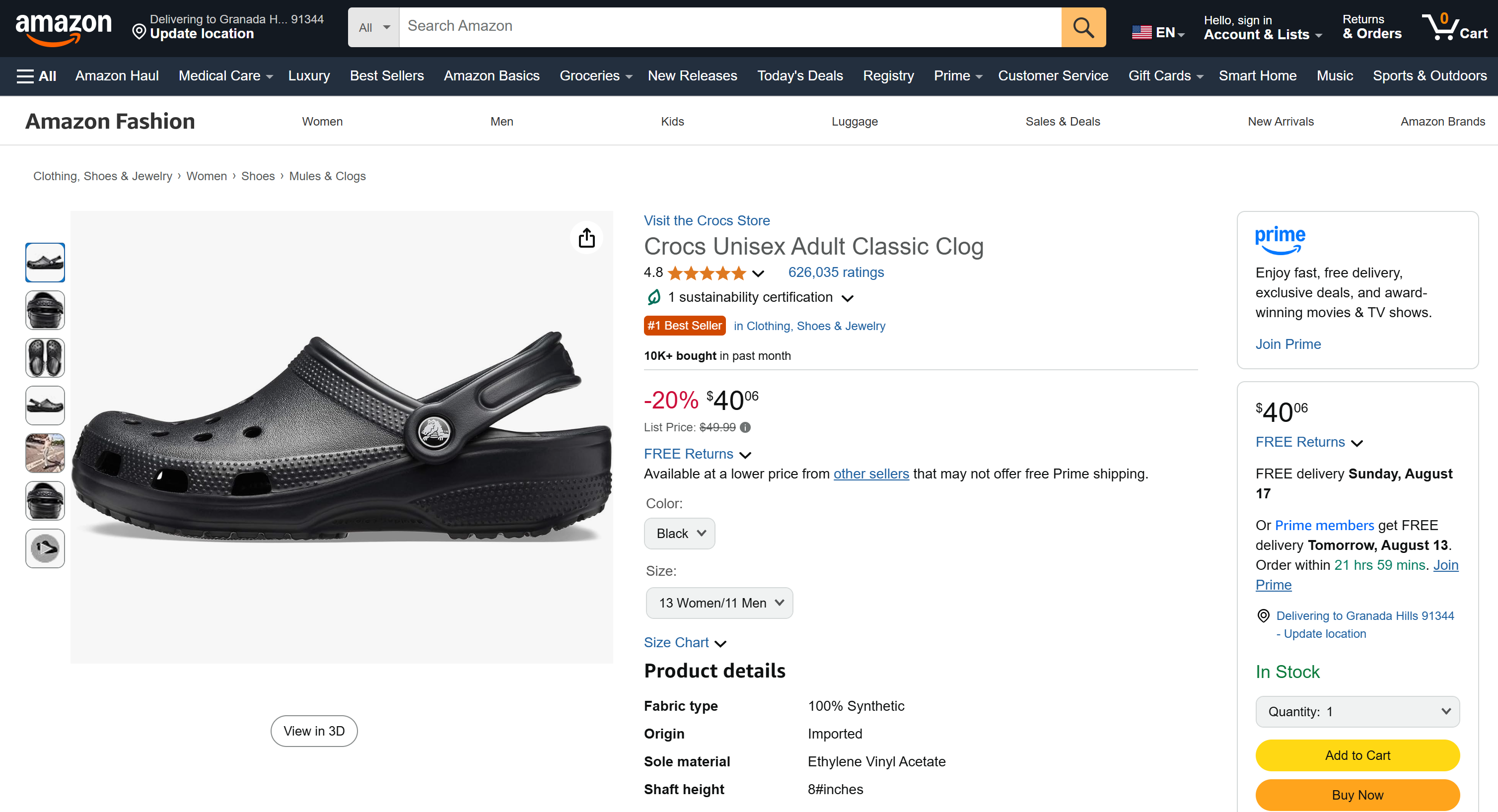
Remember that scraping Amazon is notoriously challenging because of its anti-bot protections (such as the Amazon CAPTCHA). Thus, a regular LLM cannot just access data from Amazon. That was possible thanks to the Bright Data capabilities the LLM has now access via MCP.
So, this example shows the power of combining the OpenAI Codex CLI with Bright Data’s MCP server. Now, try more prompts and discover more advanced LLM-driven data workflows!
Conclusion
In this article, you learned how to integrate the OpenAI Codex CLI with the Web MCP server. The result is a powerful AI coding agent capable of accessing the web and interacting with it.
To develop more complex AI agents, explore the full range of services, products, and capabilities available in the Bright Data AI infrastructure. Those solutions can support a long list of agentic scenarios.
Create a Bright Data account and start experimenting with Web MCP with 5,000 free monthly requests!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.




