
A global financial institution needs to combine live market data from the web with confidential in-house analytics. Their data is split between an on-premises warehouse (for sensitive client data) and Azure Data Lake (for scalable analytics). This guide teaches you how to connect both through Bright Data’s APIs for secure, near real-time integration.
You will learn:
- Why financial organizations need hybrid data setups
- How to collect compliant web data with Bright Data
- How to set up secure two‑way sync between Azure Data Lake and an on‑premises warehouse
- How to validate end‑to‑end data sync
- How to run unified analytics without moving sensitive data
- Where to find the sample configurations and scripts in GitHub
What Is Hybrid Data Integration and Why Finance Needs It
Financial organizations operate under strict regulations like GDPR, SOC 2, MiFID II, and Basel III that control where data can reside. Public web data fuels real-time market intelligence, while existing in-house datasets support long-term modeling and compliance. Traditional ETL systems rarely unify both securely.
The Challenge: How do you combine external market data with internal analytics without compromising security or compliance?
The Solution: Bright Data provides structured, compliant web data through APIs, while Azure’s hybrid infrastructure keeps sensitive data on-premises.
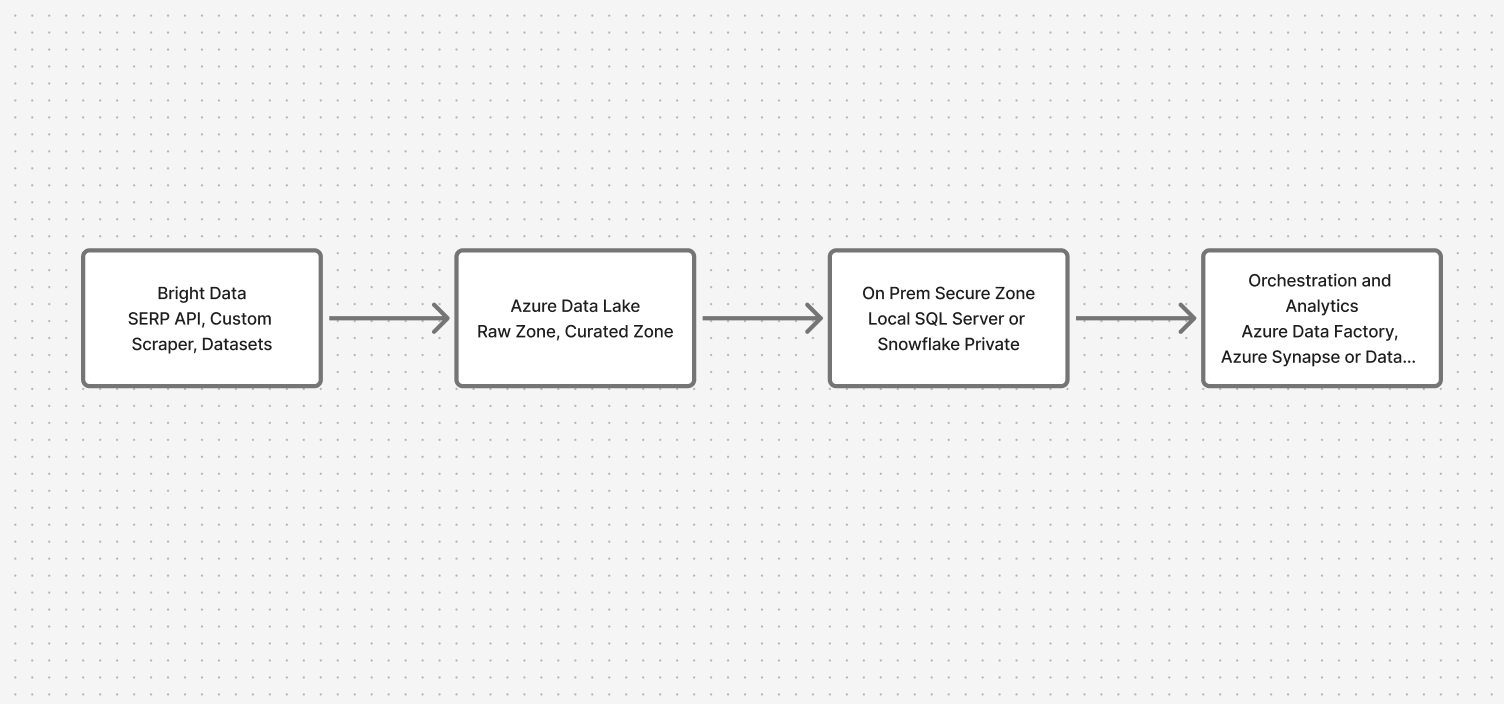
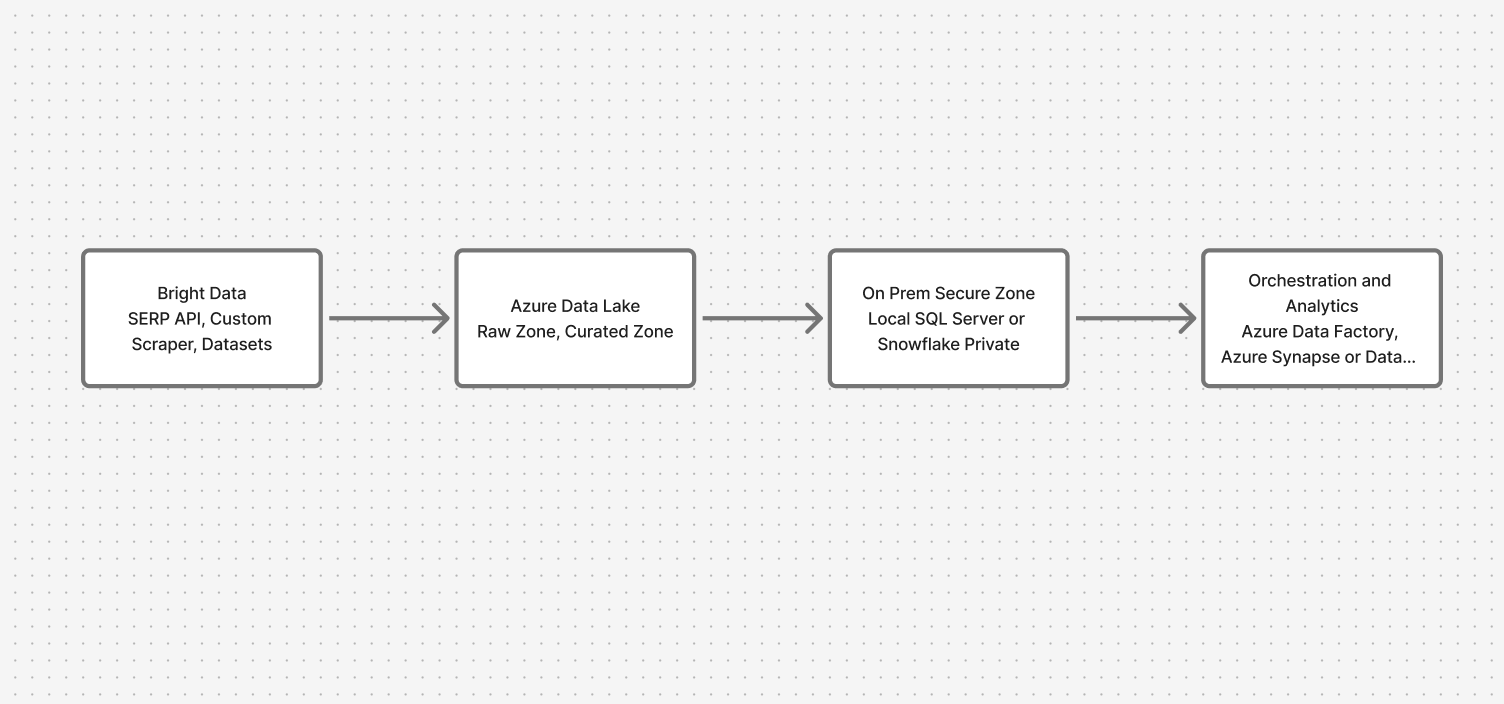
Architecture Overview: Bridging Cloud and On-Prem Safely
The system moves through four key layers:
- Data Collection: Bright Data APIs (SERP, Custom Scraper, Datasets)
- Cloud Landing Zone: Azure Data Lake (raw and curated zones)
- On-Premises Secure Zone: Local SQL Server or Snowflake
- Orchestration & Analytics: Azure Data Factory with private endpoints, Synapse/Databricks for federated queries
This ensures web data flows in while sensitive data stays put.
Prerequisites
Before starting:
- Active Bright Data account with API access
- Azure subscription with Data Lake, Data Factory, and Synapse or Databricks
- On‑prem database reachable via private network (ODBC or JDBC)
- Secure private link (ExpressRoute, Site‑to‑Site VPN, or Private Endpoint)
- GitHub account to clone the sample repo
💡 Tip: Run all steps in a non‑production workspace first.
Step-by-Step Implementation
1. Collect Financial Web Data with Bright Data
We’ll configure Bright Data’s Custom Scraper to extract stock prices, regulatory filings, and financial news. The scraper outputs structured JSON that’s ready for analysis.
Here’s what the data looks like:
[
{
"symbol": "AAPL",
"price": 230.66,
"currency": "USD",
"timestamp": "2026-11-10T20:15:36Z",
"source": "https://finance.yahoo.com/quote/AAPL",
"sector": "Technology",
"scraped_at": "2026-11-10T20:16:10Z"
},
{
...
}
]
Configuration Made Simple: The scraper_config.yaml defines what to scrape and how often. It targets financial sites, extracts specific data points, and schedules hourly collection with webhook notifications.
This approach ensures you get clean, structured data without manual intervention.
# scraper_config.yaml
name: financial_data_aggregator
description: >
Collects real-time stock prices, SEC filings, and financial news headlines
for hybrid cloud integration.
targets:
- https://finance.yahoo.com/quote/AAPL
- https://finance.yahoo.com/quote/MSFT
- https://www.sec.gov/edgar/search/
selectors:
- name: symbol
type: text
selector: "h1[data-testid='quote-header'] span"
- name: price
type: text
selector: "fin-streamer[data-field='regularMarketPrice']"
- name: headline
type: text
selector: "article h3 a"
- name: filing_type
type: text
selector: "td[class*='filetype']"
- name: filing_date
type: text
selector: "td[class*='filedate']"
- name: filing_url
type: link
selector: "td[class*='filedesc'] a"
pagination:
type: next-link
selector: "a[aria-label='Next']"
output:
format: json
file_name: financial_data.json
schedule:
frequency: hourly
timezone: UTC
webhook: "https://<your-webhook-endpoint>/brightdata/ingest"
notifications:
email_on_success: [email protected]
email_on_failure: [email protected]2. Ingest Data Securely into Azure Data Lake
Now we route the collected data to Azure Data Lake using an Azure Function. This function acts as a secure gateway:
- Receives JSON data via HTTPS POST from Bright Data
- Authenticates using Managed Identity (no secrets to manage)
- Organizes files by source and timestamp for easy tracking
- Adds metadata tags for compliance tracking
The Result: Your market data lands in partitioned folders making it easy to manage and query.
azure_ingest.py
# azure_function_ingest.py
import azure.functions as func
import json
import os
from datetime import datetime
from azure.identity import ManagedIdentityCredential
from azure.storage.blob import BlobServiceClient, ContentSettings
# Environment variables
STORAGE_ACCOUNT_URL = os.getenv("STORAGE_ACCOUNT_URL") # e.g., "https://myaccount.blob.core.windows.net"
CONTAINER_NAME = os.getenv("CONTAINER_NAME", "brightdata-market")
# Initialize blob client with managed identity
credential = ManagedIdentityCredential()
blob_service_client = BlobServiceClient(account_url=STORAGE_ACCOUNT_URL, credential=credential)
def main(req: func.HttpRequest) -> func.HttpResponse:
try:
# Parse incoming JSON from Bright Data
payload = req.get_json()
source = detect_source(payload)
now = datetime.utcnow()
date_str = now.strftime("%Y-%m-%d")
# Prepare target path
blob_path = f"raw/source={source}/date={date_str}/financial_data_{now.strftime('%H%M%S')}.json"
# Upload JSON file
blob_client = blob_service_client.get_blob_client(container=CONTAINER_NAME, blob=blob_path)
data_bytes = json.dumps(payload, indent=2).encode("utf-8")
blob_client.upload_blob(
data_bytes,
overwrite=True,
content_settings=ContentSettings(content_type="application/json"),
metadata={
"classification": "public",
"data_category": "market_data",
"source": source,
"ingested_at": now.isoformat(),
},
)
return func.HttpResponse(
f"Data from {source} saved to {blob_path}",
status_code=200
)
except Exception as ex:
return func.HttpResponse(str(ex), status_code=500)
def detect_source(payload: dict) -> str:
"""Simple helper to identify source name."""
# Look for field 'source' in the first element of array
if isinstance(payload, list) and payload:
src_url = payload[0].get("source", "")
if "yahoo" in src_url:
return "finance_yahoo"
elif "sec" in src_url:
return "sec"
return "unknown"3. Sync Non-Sensitive Subsets to On-Premises
Not all data needs to travel between environments. We use Azure Data Factory to act as a smart filter, carefully selecting only the data subsets that are safe to sync with your on-premises warehouse.
Here’s how the process works in practice:
The pipeline begins by scanning for new files that have landed in your Data Lake. It then applies intelligent filtering to include only public, non-sensitive data—think market prices and stock symbols, not client information or proprietary analytics.
What makes this secure and reliable:
Private endpoints create a dedicated tunnel between Azure and your on-premises infrastructure, completely bypassing the public internet. This eliminates exposure to external threats while ensuring consistent performance.
Incremental loading with watermark tracking means the system only moves new or changed records. Combined with automatic schema validation, this prevents duplicates while keeping both environments perfectly aligned.
Now let’s look at how this translates into actual pipeline code:
{
"name": "Hybrid_Cloud_OnPrem_Sync",
"properties": {
"activities": [
{
"name": "Lookup_NewFiles",
"type": "Lookup",
"dependsOn": [],
"typeProperties": {
"source": {
"type": "JsonSource"
},
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"firstRowOnly": false
}
},
{
"name": "Get_Metadata",
"type": "GetMetadata",
"dependsOn": [
{
"activity": "Lookup_NewFiles",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"fieldList": ["childItems", "size", "lastModified"]
}
},
{
"name": "Filter_PublicData",
"type": "Filter",
"dependsOn": [
{
"activity": "Get_Metadata",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"items": {
"value": "@activity('Lookup_NewFiles').output.value",
"type": "Expression"
},
"condition": "@equals(item().metadata.classification, 'public')"
}
},
{
"name": "Copy_To_OnPrem_SQL",
"type": "Copy",
"dependsOn": [
{
"activity": "Filter_PublicData",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"source": {
"type": "JsonSource",
"treatEmptyAsNull": true
},
"sink": {
"type": "SqlSink",
"preCopyScript": "IF OBJECT_ID('stg_market_data') IS NULL CREATE TABLE stg_market_data (symbol NVARCHAR(50), price FLOAT, currency NVARCHAR(10), timestamp DATETIME2, source NVARCHAR(500));"
}
},
"inputs": [
{
"referenceName": "ADLS_PublicData_Dataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "OnPrem_SQL_Dataset",
"type": "DatasetReference"
}
]
},
{
"name": "Log_Load_Status",
"type": "StoredProcedure",
"dependsOn": [
{
"activity": "Copy_To_OnPrem_SQL",
"dependencyConditions": ["Succeeded", "Failed"]
}
],
"typeProperties": {
"storedProcedureName": "usp_Log_HybridLoad",
"storedProcedureParameters": {
"load_source": {
"value": "BrightData",
"type": "String"
},
"status_msg": {
"value": "@activity('Copy_To_OnPrem_SQL').output",
"type": "Expression"
}
}
},
"linkedServiceName": {
"referenceName": "OnPrem_SQL_LinkedService",
"type": "LinkedServiceReference"
}
}
],
"annotations": ["HybridIntegrationDemo"]
}
}Breaking down the key components:
- Lookup_NewFiles acts as your pipeline’s check it first identifies what new data has arrived in Data Lake that needs processing. This prevents the system from re-processing old files unnecessarily.
- Get_Metadata then examines these files closely, checking their size, modification dates, and structure. This step ensures we’re working with complete, valid files before proceeding further.
- Filter_PublicData is where the security magic happens. Using the classification metadata we embedded earlier, it automatically filters out any sensitive data, ensuring only public market information continues down the pipeline.
- Copy_To_OnPrem_SQL handles the actual transfer, but with smart safeguards. The preCopyScript ensures the destination table exists with the correct schema, while the private endpoint connection keeps everything within your secure network.
- Log_Load_Status provides crucial visibility every sync operation is recorded in your on-premises database. This creates the audit trail that compliance teams require, while giving operations staff immediate visibility into pipeline health.
The real benefit: Your on-premises team gets the market context and real-time intelligence they need, while your sensitive client data and proprietary models remain securely where they belong. It’s the best of both worlds agility meets security.
4. Enable Bidirectional Sync Validation
Data consistency is essential for making reliable business decisions. You need confidence that your cloud analytics and on-premises reports show the same numbers. We built automated data validation checks that run continuously to provide this assurance.
Here is how the validation process works:
- Row count comparisons serve as your first alert system. This initial check quickly identifies major issues like failed transfers or incomplete data loads. If the counts do not match between cloud and on premises, you know immediately that something requires investigation.
- Hash checksums create digital fingerprints of your data. Instead of manually comparing thousands of records, we generate unique cryptographic hashes for each dataset. Even a single character change produces a completely different hash. This method makes data corruption or partial transfers instantly detectable.
- Near real-time synchronization means validations run every few minutes. You are not waiting for overnight batch jobs to discover problems. The system catches issues within minutes, not days, keeping your data current and reliable.
- Automated alerting turns data issues into immediate actions. When the system detects discrepancies, it sends notifications through Slack, email, or your existing monitoring tools. Your team can address problems before they affect business decisions.
Here is what this looks like in practice:
def validate_sync():
# Compare record counts between systems
cloud_count = get_cloud_record_count()
onprem_count = get_onprem_record_count()
if cloud_count != onprem_count:
alert_team(f"Record count mismatch: Cloud {cloud_count} vs On-prem {onprem_count}")
return False
# Generate checksums for data integrity validation
cloud_checksum = generate_data_checksum('cloud')
onprem_checksum = generate_data_checksum('onprem')
if cloud_checksum != onprem_checksum:
alert_team(f"Data integrity failure: Checksums don't match")
return False
# Verify sync timeliness
last_sync_time = get_last_sync_timestamp()
if is_sync_delayed(last_sync_time):
alert_team(f"Sync delay detected: Last sync {last_sync_time}")
return False
return True5. Build Unified Analytics Without Moving Sensitive Data
Here’s the powerful part: you can join cloud and on-premises data virtually without moving sensitive information.
Example Query:
SELECT c.symbol,
c.stock_price,
o.risk_score
FROM adls.market_data c
JOIN external.onprem_portfolio o
ON c.symbol = o.ticker
WHERE o.client_tier = 'premium';Azure Synapse creates external tables pointing to your on-premises warehouse, while Databricks uses JDBC connections with role-based access controls.
Compliance & Audit Trail Best Practices
Meeting audit and legal requirements requires a systematic approach to data tracking and security. Here’s how we build a compliant framework:
- Complete data movement logging ensures every transfer is recorded in Azure Monitor and your on-premises SIEM. This creates an immutable record of what data moved where and when, giving auditors full traceability.
- Clear data provenance uses Bright Data source IDs as digital fingerprints. These tags stay with your data throughout its lifecycle, letting you trace any analysis back to its original source collection.
- Automated lineage tracking with Azure Purview maps how data transforms through your pipelines. It automatically documents which raw feeds contribute to specific reports and what transformations were applied.
- Centralized access control synchronizes Azure AD with on-premises LDAP. This applies your existing security policies to both environments, ensuring consistent permission management across cloud and on-premises systems.
The result is automated compliance reporting, centralized security management, and a framework that protects data without slowing down your team.
Common Challenges & How Bright Data Helps
| Challenge | Bright Data Feature |
|---|---|
| IP blocks or rate limits | Residential and ISP Proxies (400M+ IPs) |
| CAPTCHAs or login barriers | Web Unlocker for automated solving |
| Heavy JavaScript websites | Scraping Browser (Playwright-based rendering) |
| Frequent site changes | Managed Data Services with AI auto-fix |
Conclusion & Next Steps
Financial organizations can safely merge public and private data by using Bright Data’s APIs together with Azure’s hybrid infrastructure.
The result is a compliant system that delivers both agility and control.
💡 If you prefer fully managed data access, use Bright Data’s Managed Data Services to handle scraping and delivery end‑to‑end.

Technical Writer
Amitesh Anand is a developer advocate and technical writer sharing content on AI, software, and devtools, with 10k followers and 400k+ views.





