In this guide, you will learn:
- Why you should know the difference between static and dynamic content
- What static content is, how to detect it, which tools to use to scrape it, and the challenges involved
- What dynamic content is, how to identify it, which tools are best suited for scraping it, and the obstacles you might encounter
- A static vs dynamic content comparison table in the context of web scraping
Let’s dive in!
An Introduction to Static vs Dynamic Content in Web Scraping
When it comes to web scraping, there is a significant difference in approach depending on whether the content you want to extract is static or dynamic. This distinction greatly affects how you handle data parsing, processing, and extraction.
As a rule of thumb, sections or pages optimized for SEO tend to be static. Instead, highly interactive sections or those requiring live updates are generally dynamic. However, in most cases, the reality is more complex than that.
Modern web pages are often hybrids, meaning they include both static content and dynamic content. Therefore, labeling an entire page as simply “static” or “dynamic” is usually inaccurate. It is more precise to say that specific content within the page is either static or dynamic.
To complicate matters further, even if one page on a site is static, another page on the same site might be dynamic. Just as a single web page can contain both types of content, a website can be a collection of both static and dynamic pages.
So, with that in mind, get ready to dig into the following static vs dynamic content comparison!
Static Content
Let’s go over everything you need to know about static content in web pages and how to scrape it.
What Is Static Content?
Static content refers to all elements on a web page that are embedded directly into the HTML document returned by the server. In other words, it does not require client-side rendering or additional data retrieval by the browser. Thus, everything is already present in the initial HTML response.
This typically includes UI elements, text, images, and other content that does not change unless the server-side source code is updated. Even if the server dynamically fetches data from databases or APIs before generating the HTML document to send to the client, the content is still considered static from the client’s perspective. The reason is that no further processing is needed in the browser.
How to Tell If a Web Page Uses Static Content
As mentioned in the introduction, it is rare for modern websites to be 100% static. After all, most web pages include some level of client-side interactivity. So the real question is not whether a page is entirely static or dynamic, but rather which parts of the page use static content.
To determine if a piece of content is static, you need to inspect the raw HTML document returned by the server. Note that this is not the same as what you see in your browser. The browser shows the rendered DOM, which may be modified by JavaScript after the page loads.
There are two simple ways to check whether a page uses static content and to identify which elements are static:
- View page source
- Use an HTTP Client
To apply the first approach, right-click on a blank area of the page and select the “View page source” option:

The result will be the original HTML returned by the server:

For example, in this case, you can tell that the quote elements are already present in this HTML. Therefore, you can safely assume they are static.
The second approach involves performing a simple GET request to the page URL using an HTTP client:

Again, this shows the raw HTML returned by the server. Since HTTP clients cannot run JavaScript, you do not have to worry about DOM changes. Still—as we will cover soon—your request might be blocked by the server due to anti-bot protections. Therefore, using the “View page source” method is the recommended approach.
Tools for Scraping Static Content
Scraping static content is straightforward because it is embedded directly in the HTML source of the page. Below is a basic overview of the process:
- Retrieve the HTML document by performing a GET request to the page’s URL using a simple HTTP client.
- Parse the response using an HTML parser.
- Extract the desired elements using CSS selectors, XPath, or similar strategies provided by the HTML parser.
If you are looking for tools to use for content scraping, check out our detailed guides on:
You can find a complete example related to the “Quotes to Scrape” site—whose HTML was shown in an earlier section—in our tutorial on web scraping with Python.
Some popular scraping stacks for retrieving static content include:
- Python: Requests + Beautiful Soup, HTTPX + Beautiful Soup, AIOHTTP + Beautiful Soup
- JavaScript: Axios + Cheerio, Node Fetch + Cheerio, Fetch API + Cheerio
- PHP: cURL + DomCrawler, Guzzle + DomCrawler, cURL + Simple HTML DOM Parser
- C#: HttpClient + HtmlAgilityPack, HttpClient + AngleSharp
“BeautifulSoup is faster and uses less memory than Selenium. It doesn’t execute JavaScript, or do anything other than parse HTML and work with its DOM.” – Discussion on Reddit
Challenges in Static Content Scraping
The main challenge in scraping static content lies in making the right HTTP request to retrieve the HTML document. Many servers are configured to serve content only to real browsers, so they may block your request if it lacks certain headers or fails TLS fingerprinting checks.
To avoid those issues, you should manually set proper HTTP headers for web scraping. Alternatively, use an advanced HTTP client that can simulate browser behavior, such as cURL Impersonate.
Otherwise, for a professional solution that does not rely on awkward tricks or workarounds in your code, consider using the Web Unlocker. This is an endpoint that returns the HTML of any web page, regardless of the defense mechanisms implemented by the server.
Additionally, if you send too many requests from the same IP address, you might trigger rate limiting or even an IP ban. To prevent that, integrate rotating proxies to distribute your requests across multiple IPs. See our guide on how to avoid IP bans with proxies.
Dynamic Content
Let’s continue this static vs dynamic content guide by exploring how dynamic content is loaded or rendered by web pages and how to scrape it.
What Is Dynamic Content?
In web pages, dynamic content refers to any content that is loaded or rendered on the client side—either during initial page load or after user interaction. This includes data fetched via technologies like AJAX and WebSockets, as well as content embedded within JavaScript and rendered at runtime in the browser.
In particular, dynamic content is not part of the original HTML document returned by the server. That is because it is added to the page after JavaScript execution. That means it will not be visible unless the page is rendered in a browser—which is the only kind of tool that can run JavaScript.
How to Tell If a Web Page Uses Dynamic Content
The simplest way to tell whether a page is dynamic or not is by following the opposite approach used to detect static content. If the HTML document returned by the server does not contain the content you see on the page, then there is some mechanism in place to retrieve or render that content dynamically in the client.
The other way around does not necessarily work. If some content is present in the HTML returned by the server, that does not mean the page is entirely static. That content may be stale, and the client could dynamically update it either once or periodically after the page loads. This is often the case for pages that display live updates, for example.
In general, to see if a page includes dynamic content, you can reload the page or repeat the user action that causes the content to appear while inspecting the “Network” section in your browser’s DevTools:
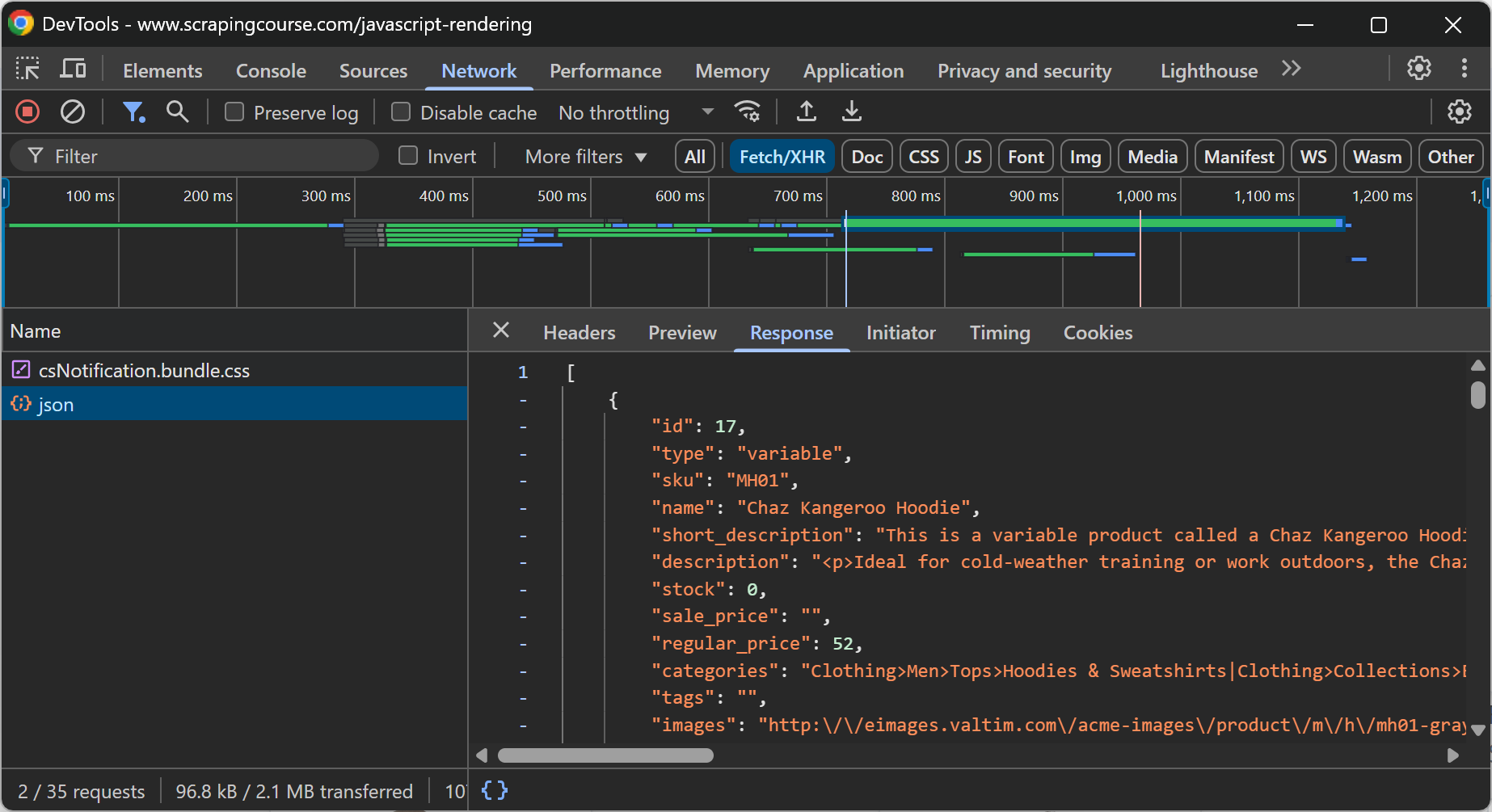
For example, on the above web page, it is clear that the e-commerce data is retrieved dynamically in the client through an API call performed via AJAX.
Another possible source of dynamic content are web applications built as SPAs (Single-Page Applications). These are powered by frontend technologies like React that heavily rely on JavaScript rendering. So, if the DOM you see in DevTools is greatly different from the HTML returned by the server, then the page is dynamic.
Tools for Scraping Dynamic Content
Dynamic content requires JavaScript execution to be rendered or retrieved. Since only browsers can execute JavaScript, your options for scraping dynamic content are generally limited to browser automation tools like Playwright, Selenium, and Puppeteer.
These tools expose APIs that allow you to programmatically control a real browser. As a result, dynamic content web scraping requires these three steps:
- Instruct the browser to navigate to the target page.
- Wait for specific dynamic content to appear on the page.
- Select and extract that content using the node selection and data extraction APIs they provide.
For more guidance, read our article on how to scrape dynamic websites in Python.
Challenges in Dynamic Content Scraping
Scraping dynamic content is inherently much more challenging than scraping static content. First, because you may need to simulate user interactions in your code to replicate all the actions required to access the content. That can be a problem when dealing with sites that have complex navigation.
Second, because dynamic web pages often implement advanced anti-scraping and anti-bot measures like CAPTCHAs, JavaScript challenges, browser fingerprinting, and more.
Also, keep in mind that browser automation tools must instrument the browser in order to control it. Those changes in the browser settings can be enough for advanced anti-bot systems to detect you as a bot. That is particularly true when controlling the browser in headless mode to save resources.
An open-source workaround for these issues is to use browser automation libraries with built-in anti-bot evasion features, such as SeleniumBase, Undetected ChromeDriver, Playwright Stealth, or Puppeteer Stealth.
Still, those solutions only address the tip of the iceberg and are subject to all the issues highlighted in static content scraping—like IP bans, IP reputation problems, and more. Here is why the most effective approach is to use a solution like Bright Data’s Scraping Browser, which:
- Integrates with Puppeteer, Playwright, Selenium, and any other browser automation tool
- Runs in the cloud and scales infinitely
- Works with a proxy network of over 150 million IPs
- Operates in headful mode to avoid headless detection
- Comes with built-in CAPTCHA-solving capabilities
- Has top-notch anti-bot bypass features
Static vs Dynamic Content for Web Scraping: Comparison Table
This is a summary table comparing static vs dynamic content for web scraping:
| Aspect | Static Content | Dynamic Content |
|---|---|---|
| Definition | Content embedded directly in the initial HTML response from the server | Content loaded or rendered via JavaScript after the page has loaded |
| Visibility in HTML | Visible in the raw HTML document returned by the server | Not visible in the initial HTML document |
| Rendering location | Server-side rendering | Client-side rendering |
| Detection methods | – “View page source” option – Inspect HTML in an HTTP client |
– Check differences between source HTML and rendered DOM – Inspect the “Network” tab of DevTools |
| Common use cases | – SEO-oriented content – Simple info listings |
– Live updates – User-specific dashboards – SPA content |
| Scraping difficulty | Easy | From medium to hard |
| Scraping approach | HTTP client + HTML parser | Browser automation tools |
| Performance | Fast, as there is no need for JS rendering | Slow, as it involves rendering pages in the browser and waiting for elements to load |
| Main scraping challenges | – TLS fingerprinting – Rate limiting – IP bans |
– CAPTCHAs – Complex navigation/interaction flows – JS challenges |
| Recommended tools to avoid blocks | Proxies, Web Unlocker | Scraping Browser |
| Example stack | Requests + Beautiful Soup | Playwright, Selenium, or Puppeteer |
For a list of scraping tools in specific programming languages covering both scenarios, take a look at the guides below:
- Best JavaScript web scraping libraries
- Best Python web scraping libraries
- Top 7 PHP web scraping libraries
- Top 7 C# web scraping libraries
Conclusion
In this article, you understood the differences between static vs dynamic content on web pages, with a focus on web scraping. You learned what these two types of content are, how they differ, and how to handle both when parsing web data.
Regardless of whether you are dealing with static or dynamic content, things can get complicated due to anti-scraping and anti-bot measures. That is where Bright Data comes in, offering a comprehensive set of tools to cover all your scraping needs:
- Proxy services: Several types of proxies to bypass geo-restrictions, featuring 400M+ IPs [1].
- Scraping Browser: A Playright, Selenium-, Puppeter-compatible browser with built-in unlocking capabilities.
- Web Scraper APIs: Pre-configured APIs for extracting structured data from 100+ major domains.
- Web Unlocker: An all-in-one API that handles site unlocking on sites with anti-bot protections.
- SERP API: A specialized API that unlocks search engine results and extracts complete SERP data from all the major search engines [2].
Create a Bright Data account and test our scraping products with a free trial!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.