In this guide, you will learn:
- The definition of a JavaScript web scraping library
- The elements to consider when comparing these scraping libraries
- The best JavaScript scraping libraries
- A summary comparison table of all the analyzed tools
Let’s dive in!
What Is a JavaScript Web Scraping Library
A JavaScript web scraping library is a tool designed to help extract data from online pages. It can send HTTP requests, parse HTML pages, and render JavaScript-based content—or perform all of these actions.
JavaScript scraping libraries offer features for communicating with web servers, navigating the DOM tree, and/or interacting with web pages. Popular types of libraries include HTTP clients, all-in-one frameworks, and headless browser tools. Some are focused on static pages, while others can handle dynamic websites.
For a general introduction, read our guide on JavaScript web scraping.
Aspect to Consider When Evaluating the Best Scraping Libraries for JavaScript
These are the main elements to analyze when comparing the best JavaScript scraping libraries:
- Goal: The primary objective of the JavaScript scraping library.
- Features: Core capabilities and functionalities offered by the tool.
- Type: The category the library belongs to (e.g., browser automation, HTTP client, etc.).
- GitHub stars: The number of stars the project has on GitHub.
- Weekly downloads: The number of weekly downloads the project receives on npm.
- Release schedule: How frequently the library is typically updated or released.
- Pros: The key benefits of using the JavaScript library for web scraping.
- Cons: The potential drawbacks or limitations of the library.
Top 6 JavaScript Web Scraping Libraries
Time to dig into the best open-source JavaScript scraping libraries in the npm ecosystem.
For a complete list, explore our JavaScript scraping library GitHub repository.
1. Playwright

Currently, Playwright is considered one of the best headless browser libraries in the industry. It is a powerful JavaScript web scraping library that enables automated testing with several advanced capabilities. At the same time, it also supports the scraping of dynamic websites.
Playwright provides everything you need to interact with pages in real-time, including executing custom JavaScript code. It supports multiple browsers, including Chrome, Firefox, and WebKit—which Puppeteer does not support.
Additionally, Playwright offers advanced features like screen capturing and automatic waits for page elements to load. This makes it a comprehensive tool for web scraping in JavaScript.
For a complete tutorial, read our article on web scraping with Playwright.
🎯 Goal: Provide a high-level API for multi-browser end-to-end automation for modern web apps
🛠️ Features:
- Cross-browser support (Chromium, WebKit, Firefox)
- Cross-platform testing (Windows, Linux, macOS, headless or headed)
- Native mobile web emulation (Google Chrome for Android, Mobile Safari)
- Auto-waiting for elements to be actionable, eliminating flaky tests
- Stealth plugin support via Playwright Extra
- Web-first assertions with automatic retries until conditions are met
- Supports multiple tabs, origins, users, and contexts in one test
- Trusted events that replicate real browser input
- Ability to test frames and pierce Shadow DOM
- Full test isolation with browser contexts
- Code generation by recording actions, supporting various languages
- Playwright Inspector for test step-through, selector generation, and execution logs
- Trace Viewer for test failure investigation, including DOM snapshots and screencasts
⚙️ Type: Browser automation library
⭐ GitHub stars: ~68.3k
📥 Weekly downloads: ~8.7M
🗓️ Release schedule: Around once a month
👍 Pros:
- Support for multiple browsers
- Support for many powerful features, like automatic selector generator
- Advanced automation API
👎 Cons:
- Disk- and memory-heavy library
- Steep learning curve for mastering all features
- Requires browser installation
2. Cheerio

Cheerio is a fast, flexible, and lightweight JavaScript library used for parsing and manipulating HTML and XML. Commonly used in web scraping, it is based on an intuitive jQuery-like API. This exposes the methods you need for traversing and manipulating the DOM (Document Object Model).
In other words, Cheerio allows you to efficiently query HTML elements, select them, and easily extract text, attributes, and more. No surprise, Cheerio also appears on the list of the best HTML parsers for web scraping.
Keep in mind that it does not come with a built-in HTTP client. So, you must integrate it with libraries like Axios or node-curl-impersonate for HTML page retrieval. Also, as a static HTML parser, it cannot render JavaScript.
🎯 Goal: Offer a jQuery-like syntax for DOM exploration from HTML and XML documents
🛠️ Features:
- Works with both HTML and XML documents
- Implements a subset of jQuery’s API for server-side use in web scraping
- Support for traversing, manipulating, and modifying DOM structures
- Lightweight and minimal dependencies for fast performance
- Compatible with Node.js and browser environments
⚙️ Type: HTML parser
⭐ GitHub stars: ~28.9k
📥 Weekly downloads: ~6.9M
🗓️ Release schedule: Less than once a year
👍 Pros:
- Simple jQuery-like syntax most JavaScript developers are already familiar with
- Support for both HTML and XML parsing
- Fast HTML parsing capabilities
👎 Cons:
- Slow development process
- jQuery syntax may feel old
- Some breaking changes in the latest version
3. Axios

Axios is the most popular and widely used JavaScript library for making HTTP requests. That makes it commonly employed in web scraping tasks to retrieve HTML data from web pages.
It supports Promises, making it ideal for handling async programming in Node.js. Axios is lightweight, easy to use, and can send GET, POST, and other HTTP requests. It enables request customization and randomization to avoid getting blocked.
Note that Axios does not offer built-in HTML parsing or browser automation like other libraries. Thus, it must be paired with tools like Cheerio.
🎯 Goal: Make automated HTTP requests
🛠️ Features:
- Can make requests for all HTTP methods in Node.js and the browser
- Supports the
PromiseAPI - Support for request and response interception
- Can transform request and response data
- Support for request cancellation
- Support for custom timeouts
- Support for proxy integration
- Support for custom headers, cookies, and more
- Support for query parameters
- Automatically serialize request body to JSON, multipart/
FormData, and URL encoded form - Automatically handle JSON data from responses
- Support for bandwidth limits
⚙️ Type: HTTP client
⭐ GitHub stars: ~106k
📥 Weekly downloads: ~50M
🗓️ Release schedule: Around once a month
👍 Pros:
- The most used HTTP client in JavaScript
- Tons of online resources and tutorials
- Support for interceptors and advanced features
👎 Cons:
- No support for TLS fingerprint spoofing
- Requires an HTML parser for scraping
- Not a lightweight dependency
4. Puppeteer

Puppeteer is a JavaScript library for testing that can also be used for web scraping. That is possible thanks to its high-level API to interact with browsers. You can use it to automate browsing tasks and scrape content on dynamic pages that require JavaScript rendering or execution.
Puppeteer can click buttons, fill out forms, navigate through pages, and more. It also guarantees built-in support for proxy handling, headless operation, and request interception.
See our tutorial on web scraping with Puppeteer.
🎯 Goal: Provide a high-level API for automating and controlling headless Chrome and Firefox browsers for web scraping and testing
🛠️ Features:
- Works with Chromium-based browsers, Chrome, and Firefox
- Provides a high-level API for simulating user interaction on a web page
- Can capture screenshots and generate PDFs of web pages
- Support for form submission and other automations
- Anti-bot capabilities with Puppeteer Extra
- Can emulate mobile devices and custom user agents
- Support for network interception and request/response modification
- Highly customizable
- Support for custom user agents
- Support for both headless or headed modes
⚙️ Type: Browser automation library
⭐ GitHub stars: ~89.3k
📥 Weekly downloads: ~3.1M
🗓️ Release schedule: Around once a month
👍 Pros:
- Support for Chrome and Firefox for handling dynamic content pages
- CLI command to automatically download browsers
- Support for both WebDriver BiDi and Chrome DevTools Protocol
👎 Cons:
- No support for Safari
- Hard to deploy on Docker
- Limited automation API
5. Crawlee

Crawlee is a JavaScript web scraping library for advanced crawling needs. It comes with a high-level API for web scraping built on top of Puppeteer, Playwright, or Cheerio. Its purpose is to simplify the process of:
- Crawling sites
- Extracting data from web pages
- Dealing with JavaScript rendering and simulating user interaction
Crawlee can tackle common challenges such as pagination, rate-limiting, and proxy rotation. It supports both headless browsers and regular HTTP parsing. The library also integrates well with cloud platforms and offers built-in solutions for handling retries and error management.
For more details, follow our step-by-step guide on web scraping with Crawlee.
🎯 Goal: Cover your end-to-end crawling and scraping needs, helping you build reliable scrapers
🛠️ Features:
- Unified Interface for both HTTP requests and headless browser crawling
- Persistent URL queue supporting both breadth-first and depth-first crawling
- Pluggable storage for tabular data and file storage
- Automatic scaling optimized for available system resources
- Built-in proxy rotation and session management
- Customizable lifecycles with hooks for enhanced control
- CLI tools to quickly bootstrap new projects
- Configurable routing, error handling, and retries
- Ready-to-deploy dockerfiles for seamless deployment
- TypeScript support with generics for type safety
- Support for JavaScript rendering integration
⚙️ Type: Scraping and crawling framework
⭐ GitHub stars: ~16.5k
📥 Weekly downloads: ~15k
🗓️ Release schedule: Once a month
👍 Pros:
- One of the few all-in-one JavaScript scraping libraries
- Proxy, JavaScript rendering, and CLI native integration
- Easy to deploy
👎 Cons:
- Steep learning curve for beginners
- May be hard to adapt to highly specific scenarios due to its pre-built nature
- Limited community support
6. node-curl-impersonate
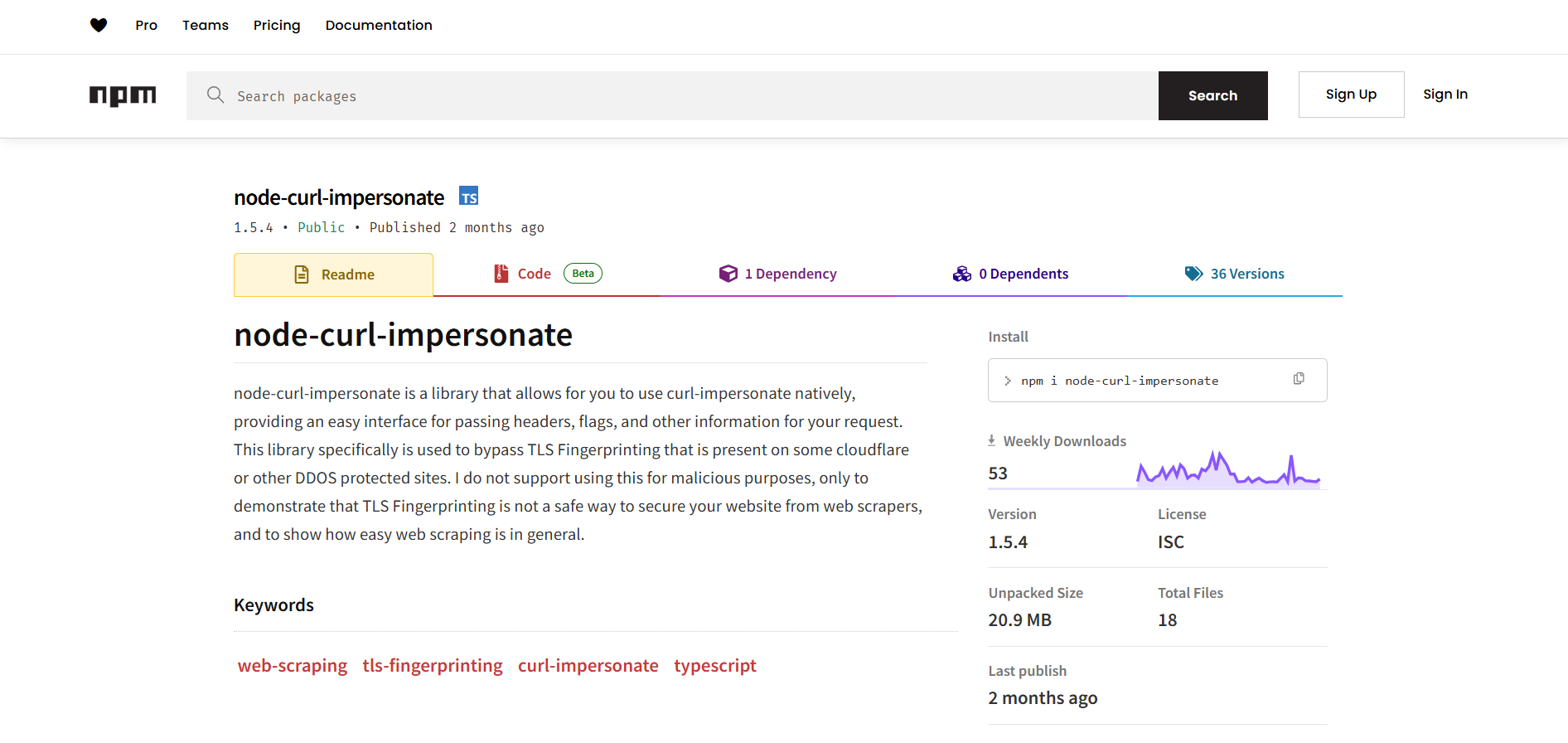
node-curl-impersonate is a Node.js HTTP client library based on cURL Impersonate. If you are not familiar with that technology, cURL Impersonate is a special version of cURL built for web scraping tasks. It relies on the TLS libraries used by browsers and other configurations to bypass most anti-bot systems.
node-curl-impersonate provides a Node.js API that wraps cURL Impersonate. That API allows you to send HTTP requests while impersonating common browsers, such as Chrome and Firefox. This helps prevent CAPTCHA prompts, as it gives you a trustable TLS fingerprint.
🎯 Goal: Perform automated HTTP requests as if they were made from a browser, but without using a headless browser
🛠️ Features:
- HTTP client with browser impersonation
- Support for Chome and Firefox impersonations
- Customizable user-agent and headers
- Built-in TLS fingerprinting matching
⚙️ Type: HTTP client
⭐ GitHub stars: —
📥 Weekly downloads: ~50
🗓️ Release schedule: Around once every few months
👍 Pros:
- HTTP client with browser impersonation
- Low resource usage with browser capabilities
- Support for multiple browser impersonations
👎 Cons:
- Limited online tutorials and resources
- Infrequent updates
- Depends on older browser versions
Best JavaScript Web Scraping Library
For a quick comparison, take a look at the JavaScript web scraping library summary table below:
| Library | Type | HTTP Requesting | HTML Parsing | JavaScript Rendering | Anti-detection | Learning Curve | GitHub Stars | Downloads |
|---|---|---|---|---|---|---|---|---|
| Playwright | Browser automation | ✔️ | ✔️ | ✔️ | High with the Stealth plugin | Steep | ~68.3k | ~8.7M |
| Cheerio | HTML parser | ❌ | ✔️ | ❌ | — | Gentle | ~28.9k | ~6.9M |
| Axios | HTTP client | ✔️ | ❌ | ❌ | Limited | Gentle | ~106k | ~50M |
| Puppeteer | Browser automation | ✔️ | ✔️ | ✔️ | High with the Stealth plugin | Steep | ~89.3k | ~3.1M |
| Crawlee | Scraping framework | ✔️ | ✔️ | ✔️ | Configurable | Steep | ~16.5k | ~15k |
| node-curl-impersonate | HTTP client | ✔️ | ❌ | ❌ | High | Medium | — | ~50 |
Conclusion
In this blog post, you discovered the best JavaScript scraping libraries and why they made the list. We compared some of the most used HTTP clients, browser automation tools, and crawling libraries in the npm ecosystem.
These libraries help with web scraping in Node.js. Still, there are many challenges they cannot address, such as:
- IP blocks
- Advanced anti-bot solutions
- CAPTCHAs
- Easy deployment in the cloud and server maintenance
These are just a few examples of the challenges scraping developers have to face. Forget about the hassle with Bright Data solutions:
- Proxy Services: 4 types of proxies to bypass location restrictions, including 400M+ monthly residential IPs
- Web Scraper APIs: Dedicated endpoints for extracting fresh, structured web data from over 100 popular domains.
- Web Unlocker: API to handle all ongoing site unlocking management for you, and extract one URL
- SERP API: API to handle all ongoing unlocking management for SERP and extract one page
- Scraping Browser: Puppeteer, Selenium, and Playwright-compatible browser with built-in unlocking activities
- Scraping Functions: IDE to build JavaScript scrapers on Bright Data infrastructure, with built-in unlocking & browsers
All the above scraping tools, solutions and services integrate with JavaScript—and any other programming language.
Create a Bright Data account and test these scraping services with a free trial!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.