
In this blog post, you will see:
- What social listening is and why it is valuable.
- Why agentic AI is the best approach for performing it.
- The main obstacles to using AI for social media listening, especially via agents.
- How to overcome them with dedicated, agent-ready social media scraping tools.
- A step-by-step guide to building an agentic social listening workflow in LangChain, powered by Bright Data social media scraping tools.
- What you need to turn this example into a production-ready agentic workflow.
- Examples of real-world agentic workflows for social listening.
Let’s dive in!
Social Listening: What It Is, How It Works, and Examples
Social listening is the process of monitoring and analyzing digital conversations to understand what people are saying about a brand, product, announcement, industry, or specific topic.
It goes beyond simply tracking mentions. Social listening helps uncover trends, measure sentiment, and understand how the external public truly feels. Its ultimate goal is to generate insights that inform marketing, product decisions, and customer support.
At a high level, social listening generally follows a two-step process:
- Monitoring: Tracking social media platforms for mentions, comments, and conversations related to a target topic (e.g., competitors, your brand, relevant keywords, etc.).
- Analysis: Interpreting that data to understand what is happening, identify patterns, and take action to improve outcomes or gain deeper intelligence.
For instance, a company could study unfiltered discussions on Reddit in niche communities to discover pain points or feature requests. Similarly, a brand may analyze Instagram comments and hashtags to gauge engagement and brand perception.
Why an AI Agentic Workflow Is Ideal for Social Listening
Traditional social listening workflows are usually static, built on a series of components that feed data from input to output in a fixed pipeline.
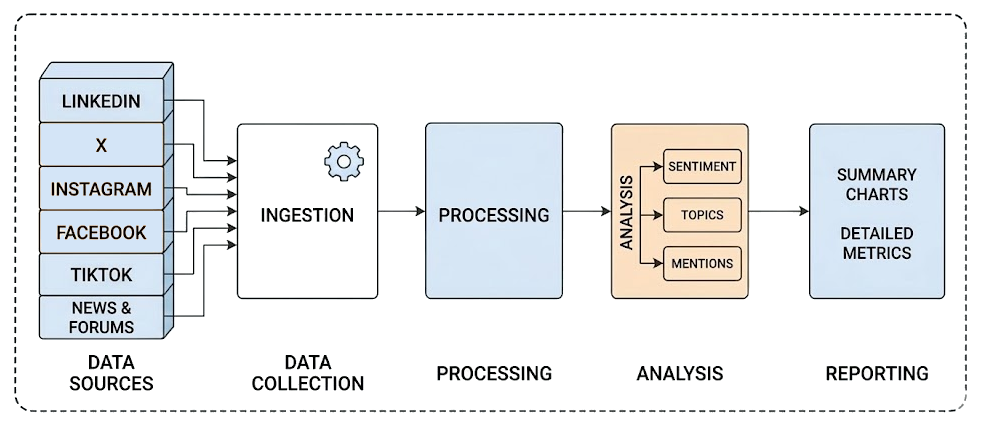
That approach works well for many data analysis processes, but it struggles with social media data. The reason is that interpreting context and adapting continuously to new conversations is extremely challenging. This is where AI, especially through agentic workflows, becomes a strong fit!
An agentic social listening workflow transforms that passive data stream into an active intelligence engine. After all, unlike static pipelines, AI agents can engage in autonomous behavior.
For example, if an agent detects an unusual spike in sentiment on Reddit, it can proactively investigate related threads on X or Threads to find the root cause. Also, it can conduct deeper research on Reddit itself (or, potentially, even Google) to understand what is going on.
In particular, the main advantages of an agentic social listening workflow are:
- Deep sentiment analysis: Beyond simply assigning “positive/neutral/negative” labels, AI understands sarcasm and cultural context. This provides a high-fidelity view of the input data, particularly in terms of sentiment and engagement.
- Autonomous research: Agents can proactively hunt for emerging trends or dive deeper into ongoing conversations without requiring constant manual intervention.
- Cross-platform integration: Agentic workflows can monitor multiple networks simultaneously, aggregating insights in a single, actionable view.
By moving from fixed pipelines to agentic reasoning, you can start truly listening to social media. This shift leads to a dynamic system that evolves as quickly as the conversation itself, without requiring changes to the elements in the pipeline.
Challenges in Social Media Listening with AI
There is no doubt that AI has made social listening significantly easier, particularly when it comes to understanding the “why.” Advanced AI/ML models can analyze sentiment, predict possible trends, and even interpret nuance. However, a major challenge remains: how to collect social media data reliably and at scale?
The main idea is to connect your agentic workflow directly to social platform APIs (if available). Yet, official APIs can be expensive, subject to rate limits, and may include restrictions on how you can process the retrieved data. Additionally, API responses can change over time or be incomplete. For these reasons, APIs are often not a practical option, and many teams rely on web scraping instead.
Still, social media scraping is inherently difficult for several reasons:
- Platform complexity and change: Social media websites constantly evolve, with complex and highly dynamic interactive and navigation patterns. That turns data parsing into a difficult task.
- Anti-bot measures: CAPTCHAs, human verification checks, and rate limits require sophisticated strategies for IP rotation, fingerprint management, and more.
- Data fragmentation: Data is spread across multiple platforms (X, Instagram, Threads, TikTok, Reddit, LinkedIn, YouTube, Facebook, etc.), making it hard to create a unified social media dataset.
Even when you have access to trusted social media scraping tools, two additional hurdles remain:
- Tool compatibility: The scraping tool must be compatible with the AI library or agentic workflow you plan to use.
- Data usability: Scraped data must be structured, cleaned, and delivered in a format that AI can easily understand. Delays, inconsistent formatting, or missing data fields can reduce the effectiveness of agentic workflows and increase the risk of hallucinations. Discover the best data formats for agentic AI.
Thus, while AI transforms social listening, the real bottleneck lies in data acquisition.
AI-Ready Tools for Grounded, Scalable Agentic Social Listening
You know that allowing AI agents to access reliable social media data is the main obstacle in agentic social listening workflows. As a result, the solution is clear: agents need access to trusted and enterprise-ready tools for social media scraping.
When autonomously called by AI agents, these tools source AI-optimized data from selected social media platforms. The returned data forms the foundation for AI to analyze, reason over, and infer insights. The challenge is finding good tools, as without them, you will face the typical reliability and scalability issues associated with web scraping.
Thus, agent-ready social media scraping tools must:
- Be highly solid, with high success rates and minimal downtime.
- Support concurrent requests to handle large volumes of data.
- Return content in formats ideal for LLM ingestion, such as JSON or Markdown.
- Integrate seamlessly with the AI agent library of choice—whether LangChain, LlamaIndex, CrawlAI, Agno, Dify, or similar frameworks.
- Handle anti-bot measures, including rate limits, IP rotation, CAPTCHAs, and other protections.
- Support multiple social media platforms.
This is precisely what Bright Data provides through its Social Media Scraper service. Let’s explore it in more detail!
Bright Data’s AI-Ready Social Media Scraping Tools
Bright Data is the leading web data collection platform, also ranking first among the top social media data providers. Among its AI-ready scraping solutions, Social Media Scraper stands out for agentic workflows:
- Achieves 99.99% reliability and 99.95% success rates, ensuring continuous data flow for AI agents with minimal downtime.
- Built for scale, supporting high concurrency thanks to a proxy network of 150 million IPs across 195 countries.
- Enables bulk scraping of up to 5,000 social media pages simultaneously, letting agents deal with a large amount of data.
- Returns structured, LLM-ready formats like JSON and Markdown, optimized for fast ingestion, reasoning, and downstream AI processing.
- Offers official integrations with 70+ AI frameworks and solutions, plus native APIs for custom implementations.
- Automatically handles anti-bot and anti-scraping challenges for you.
- Supports major platforms such as Facebook, Instagram, LinkedIn, TikTok, X, Pinterest, Quora, YouTube, Threads, Reddit, Vimeo, and more.
- Pay-per-success model ensures cost efficiency, making large-scale AI-driven data collection predictable and economical.
Note: This solution is also available natively via Bright Data’s Web MCP server, enabling simplified integration into agentic workflows.
How to Build a Social Listening Agent Backed by Bright Data
In this guided section, you will see how to get started with a simple social listening agent. This will be built in LangChain and connected to Gemini, but any other AI agent framework and LLM provider will work.
Note: If you want practical instructions on how to use Bright Data’s solutions to build an AI-powered application for social listening, refer to the “Building an AI-Powered Social Listening App” webinar.
Follow the steps below!
Prerequisites
To follow this tutorial, make sure you have:
- Python 3.10 installed locally.
- A Bright Data account with an API key ready.
- A Gemini API key (or an API key from any other LLM provider supported by LangChain).
- A basic understanding of how LangChain agents work.
Take a look at the official guide to set up your Bright Data API key. Store it securely, as you will need it to connect your LangChain agent to Bright Data using the official LangChain–Bright Data tools.
For more information about integrating Bright Data with LangChain, refer to the blog posts below:
Step #1: Set Up Your LangChain Project
Create a new Python project for your social listening agent:
mkdir agentic-social-listening
cd agentic-social-listeningIn the project folder, create a virtual environment and activate it:
python -m venv .venv
source .venv/bin/activate # or on Windows: .venv\Scripts\activateAdd an agent.py file, which will contain your social listening agent logic. Your project structure should look like this:
agentic-social-listening/
├── .venv/
└── agent.pyIn the activated virtual environment, install the required libraries:
pip install langchain langchain-google-genai langchain-brightdataThese are:
langchain: Simplifies building AI agents.langchain-google-genai: Connects your agent to Gemini via theChatGoogleGenerativeAIintegration.langchain-brightdata: Connects your LangChain agent to Bright Data’s scraping solutions via the official integration, as explained in the docs.
Great! Load the project folder in your favorite Python IDE and prepare to develop an agentic social listening workflow.
Step #2: Define the Workflow of the Agent
Suppose you want to build a social listening agent that monitors sentiment and mentions across two posts (one on Instagram and one on TikTok) for the same announcement. While the posts differ, the underlying announcement is identical.
This is an interesting example because it shows how an agent can track engagement across multiple platforms for a single campaign, identify overlapping and platform-specific sentiment, and detect product mentions or promotional requests.
Here, we will use a Nike announcement. This is how it appears on Instagram: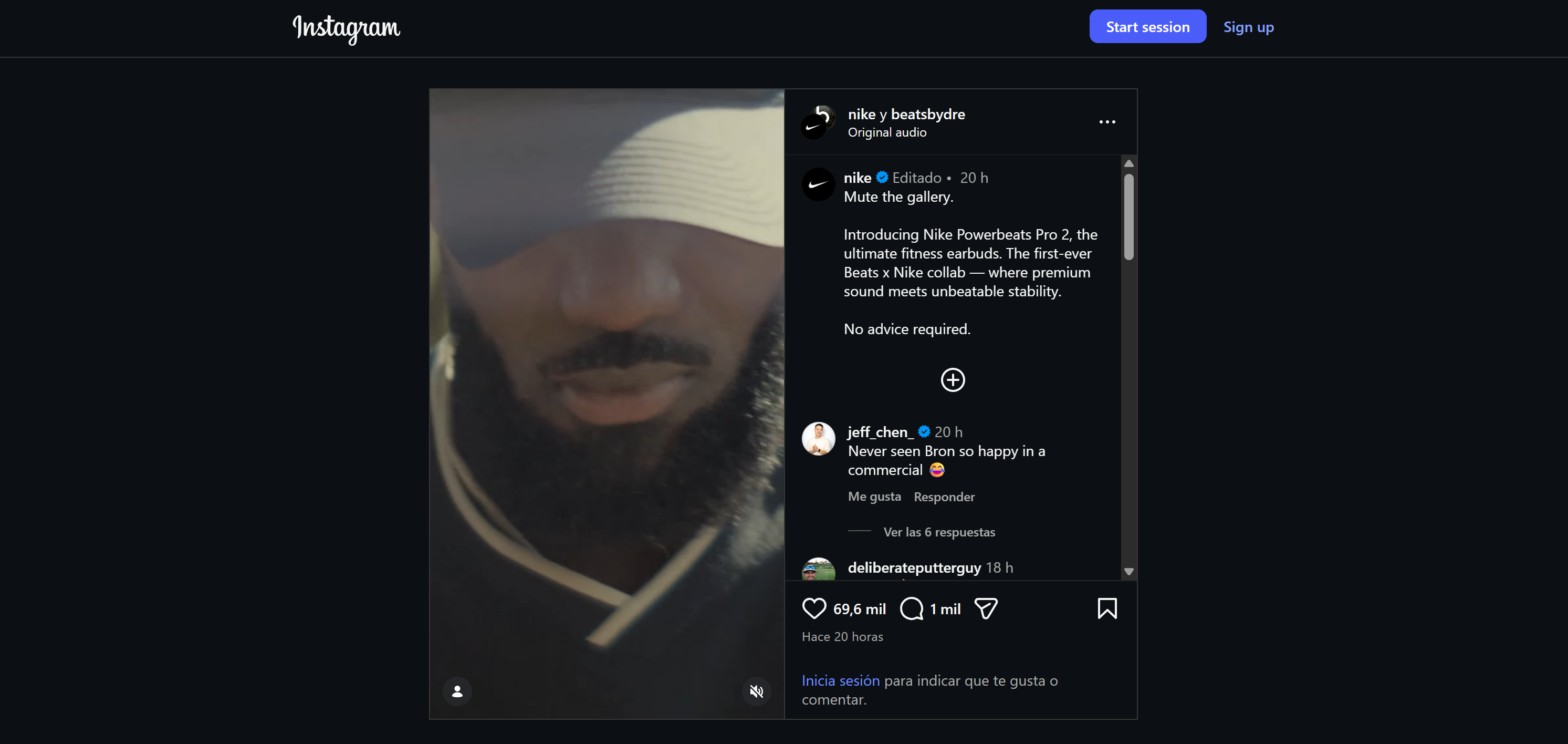
And this is how it appears on TikTok: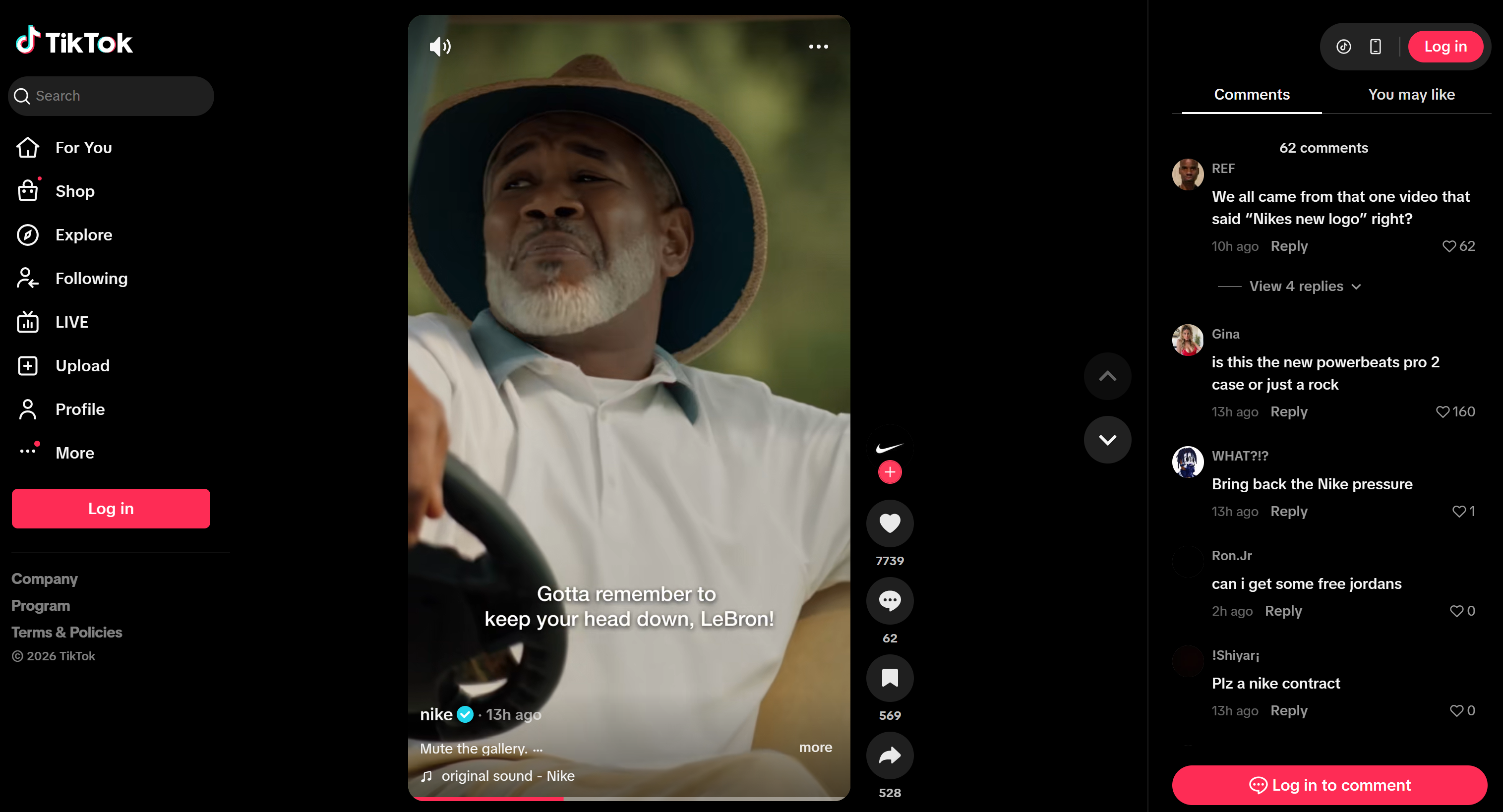
The idea is to let the AI agent use Bright Data’s Social Media Scraper API to fetch comments from both posts. Then, it will analyze and process that data via its Gemini-powered LLM brain. This completes a basic agentic social listening workflow.
Note: This is just an example, assuming you already have the target social posts. In a production-ready scenario, Bright Data tools can be used to search the web, track entire social media accounts, and handle multi-platform social listening at scale.
All clear! Time to develop the agent.
Step #3: Implement the Agent
To build the social listening agent presented earlier, add the following lines of code to agent.py:
# pip install langchain langchain-google-genai langchain-brightdata
from langchain_brightdata import BrightDataWebScraperAPI
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.agents import create_agent
# Replace with your actual API keys
GOOGLE_API_KEY = "<YOUR_GOOGLE_API_KEY>"
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>"
# Initialize the LLM engine
llm = ChatGoogleGenerativeAI(
model="gemini-3-flash-preview",
google_api_key=GOOGLE_API_KEY
)
# Initialize the Bright Data Web Scraper API tool
web_scraper_api_tool = BrightDataWebScraperAPI(
bright_data_api_key=BRIGHT_DATA_API_KEY
)
# Create a ReAct agent with access to the Bright Data Web Scraping APIs
agent = create_agent(llm, [web_scraper_api_tool])
# Define a simple social listening query
prompt = """
You are a social listening expert.
Targets:
- Instagram Reel: "https://www.instagram.com/nike/reel/DV_PTxKDueO/"
- TikTok Video: "https://www.tiktok.com/@nike/video/7618336096694406414"
Task:
1. Use Bright Data's Social Media Scraper API to collect all comments from the target posts.
2. Generate a Markdown report summarizing engagement and sentiment.
3. Highlight comments mentioning other Nike products, promotions, or interesting user requests for follow-up analysis.
"""
# Stream the agent's step-by-step output
for step in agent.stream(
{
"messages": prompt
},
stream_mode="values",
):
step["messages"][-1].pretty_print()This is what the code does:
- Reads the credentials for Gemini and Bright Data API access (in production, read them from the envs).
- Creates a Gemini-powered AI engine to process and analyze social media data.
- Connects the agent to Bright Data’s Scraping APIs (including the Social Media Scraper API) via the
BrightDataWebScraperAPILangChain tool. - Uses the
create_agent()function to define a ReAct agent that can call the Bright Data scraping tools dynamically. - Instructs the agent on targets (Instagram and TikTok posts) and tasks (comment collection, sentiment analysis, report generation, and flagging key mentions).
- Launches the agent and streams the result to the terminal.
Mission complete! You have now implemented a simple agentic workflow for social listening.
Step #4: Test the Agent
Execute the agent with:
python agent.pyYou will see the agent running the bright_data_web_scraper tool (as expected):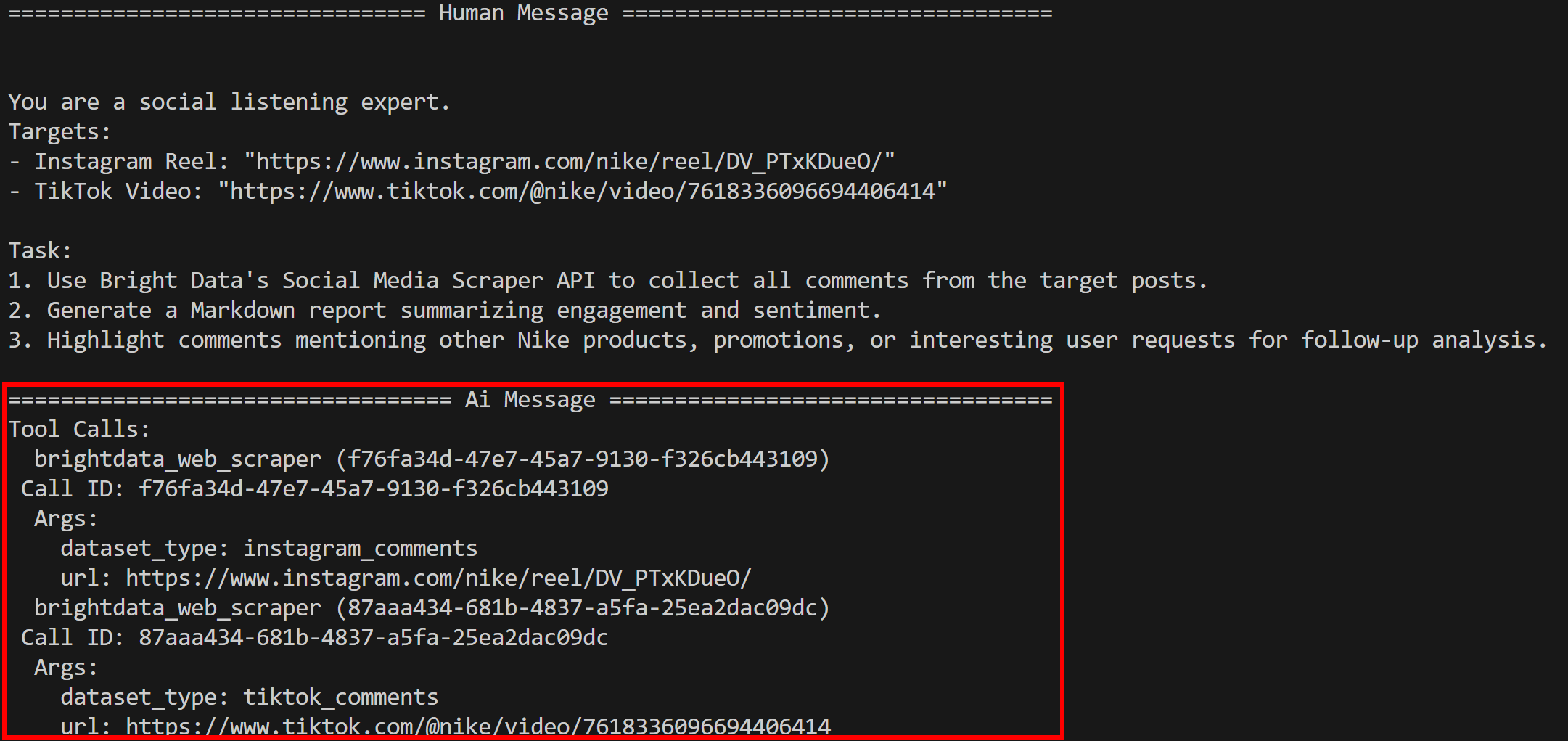
In particular, it calls the underlying instagram_comments and tiktok_comments tools. Under the hood, these rely on the Bright Data Instagram Comments Scraper and TikTok Comments Scraper.
The tool results are returned in JSON-structured data, containing all scraped comments from the two posts: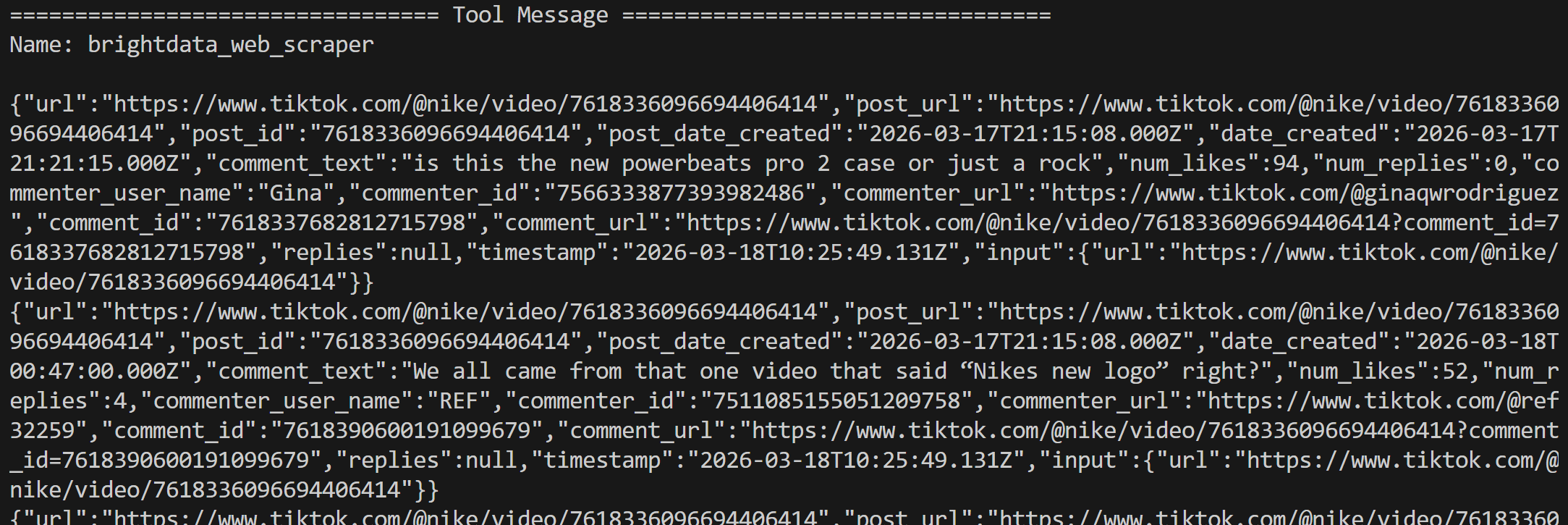
Next, the agent processes the comments for social listening as instructed and generates a Markdown report: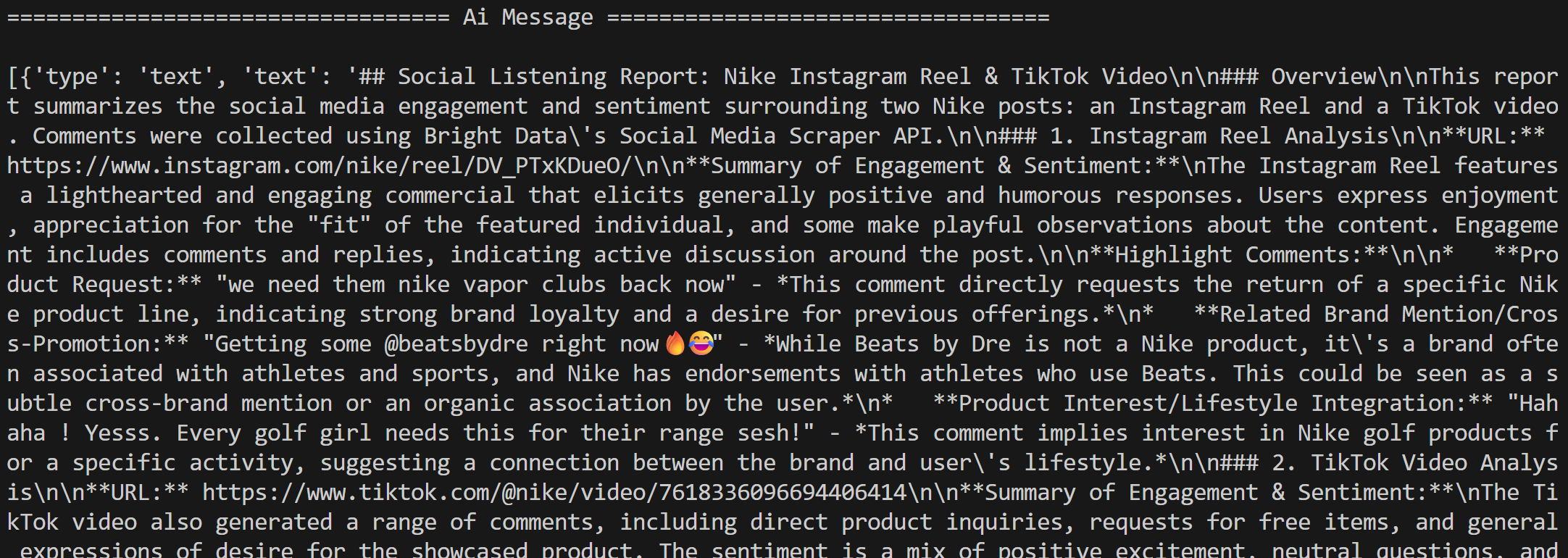
When viewed in a Markdown renderer, the report appears like this: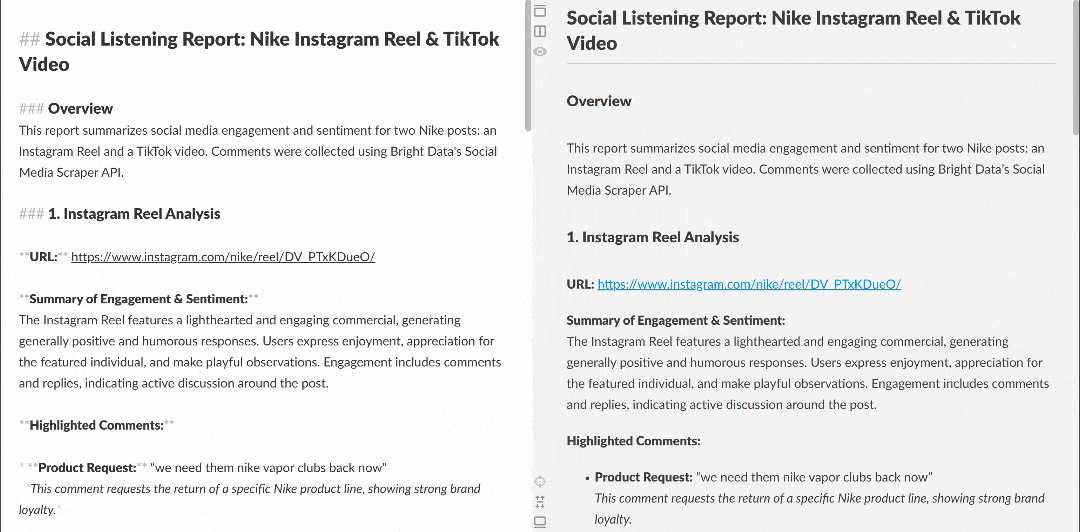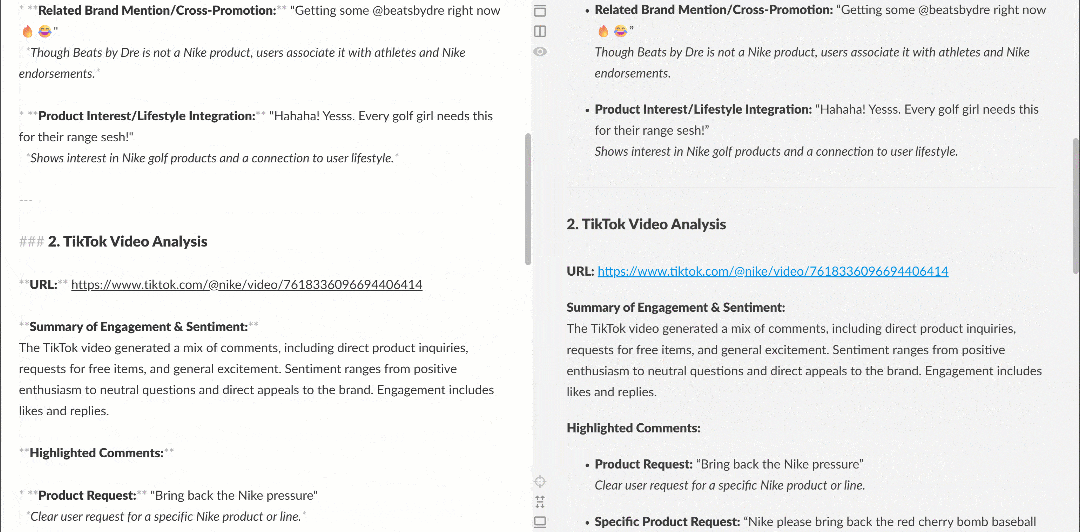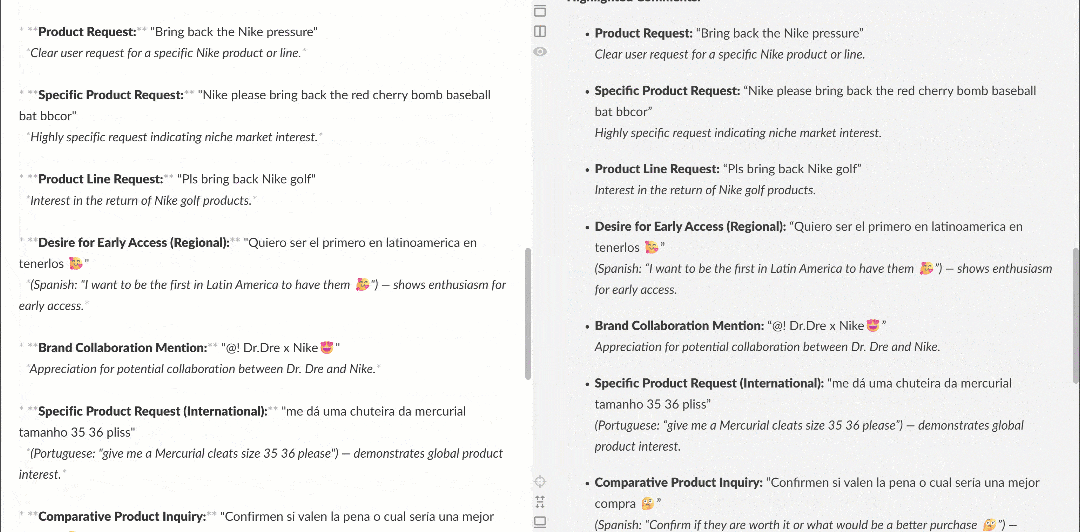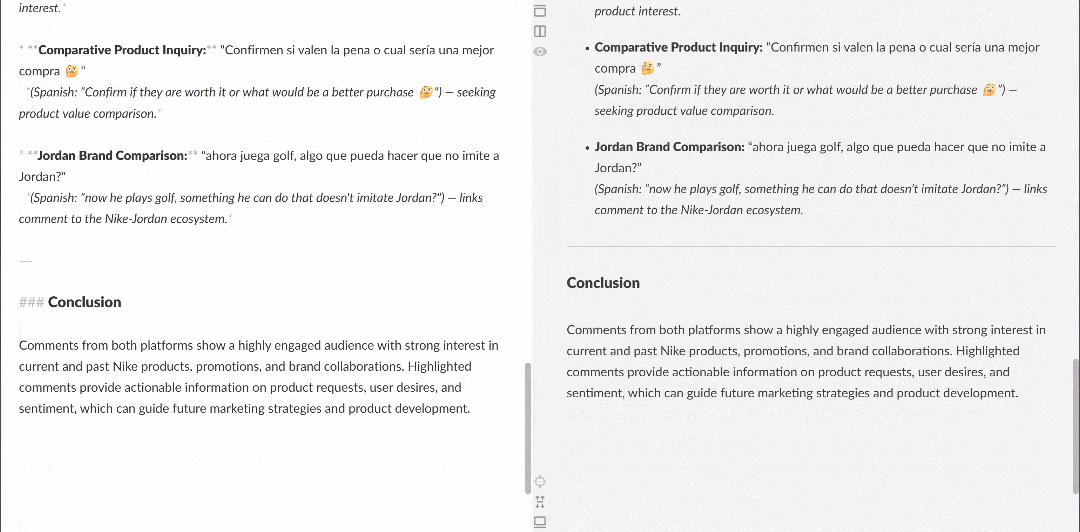
Note how it contains interesting insights, such as multiple users asking Nike to bring back Nike Golf or focus more on golf products. These are details that a basic sentiment analysis workflow might have missed.
Also, if an error occurs, or if the agent determines that the retrieved data is insufficient to meet the goal, it will automatically fetch additional comments or repeat calls to the Bright Data tools. This makes the agent fully autonomous.
Et voilà! You just learned how to build a Bright Data–powered agentic social media listening workflow in LangChain.
Production-Ready Agentic Workflows for Social Listening
The previous chapter showed how to build a simple social listening agent. Still, a production-ready agentic workflow is far more complex. Let’s explore how to design it and the steps to implement it!
Architecture
In agentic social listening workflows, relying on multiple specialized AI agents tends to produce better results than using a single, monolithic agent. Each agent should focus on a distinct responsibility, and a possible agentic setup is:
- Data retrieval agent: Collects posts, comments, profiles, or engagement metrics from multiple social media platforms through tools like Bright Data’s Social Media Scraper.
- Analysis agent: Processes the collected data to extract trends, sentiment, and other actionable insights, transforming raw social content into meaningful intelligence.
- Reporting/Output Agent: Formats analyzed data into dashboards, summaries, or files (JSON, CSV) for easy consumption by humans or other AI systems.
- Coordination agent: Oversees the workflow, ensuring smooth handoffs, evaluating results for quality, and iterating processes automatically when improvements or additional data collection are needed.
Roadmap
Given the four agents, implement an agentic workflow for social listening as follows:
- Choose the AI agent stack: Pick based on the types of agents needed, tool integrations, and ease of workflow orchestration.
- Add the agents: Create four placeholder agents within your chosen AI agent framework.
- Integrate social media scraping tools: Give the data retrieval agent access to Bright Data’s Social Media Scraper or single, specific social media scrapers.
- Configure data retrieval tasks: Instruct the data retrieval agent to fetch the required social media data.
- Analyze collected data: Tell the analysis agent to process text, sentiment, trends, and engagement metrics.
- Generate structured reports: Instruct the reporting agent to produce the desired output based on the analyzed data.
- Coordinate and iterate: Implement the coordination agent to monitor results, trigger repeated cycles, etc.
- Design the agentic loop: Connect the four agents (Data retrieval → Analysis → Reporting → Coordination).
- Automate workflow scheduling: Set up recurring runs for continuous social listening.
Examples of Agentic Social Listening Workflows
Given the AI agent roadmap presented earlier, you can build several agentic social media listening workflows. Here are some examples!
Brand Sentiment Monitoring
AI agents continuously track mentions of your brand across social platforms. Utilizing Bright Data’s Social Media Scraper, agents collect posts, comments, and reactions, then analyze sentiment, detect emerging trends, and flag negative spikes, enabling proactive reputation management.
Competitor Analysis
AI agents monitor hashtags, keywords, and discussions across TikTok, X, Reddit, and YouTube comments. AI then detects content strategies, campaign performance, and audience engagement patterns, helping you adjust your own strategy in real time.
Trend Discovery and Forecasting
AI agents monitor hashtags, keywords, and discussions across TikTok, X, and Reddit. Bright Data’s scraper APIs provide structured, LLM-ready data for agents to detect rising trends, forecast popularity, and guide marketing or product decisions.
Crisis Detection and Response
Agents watch for sudden negative sentiment surges or viral posts across multiple networks. With Bright Data’s Social Media Scraper, AI can alert teams immediately, draft context-aware responses, or trigger automated escalation workflows.
Campaign Feedback Analysis
AI agents collect user reactions, comments, and post metrics from Facebook, Instagram, YouTube, or other platforms. Thanks to Bright Data’s scrapers, agents retrieve the data they need to track campaign success and optimize messaging strategies.
Conclusion
In this article, you learned what social media listening is, what it involves, and why agentic workflows are the best way to implement it. You also gained a clear understanding of the challenges involved and how to overcome them using AI-ready social media scraping tools.
Bright Data supports social listening through a dedicated, enterprise-level, and easy-to-integrate Social Media Scraper. This enables you to build scalable agentic workflows for social listening (and other social media marketing use cases) without losing reliability or performance.
Create a Bright Data account today for free and explore our AI-ready web data collection solutions!
FAQ
What is the difference between social listening and social monitoring?
Social monitoring tracks “what” happened by collecting notifications, likes, and metrics. Instead, social listening analyzes the “why” by looking at the sentiment and trends behind those conversations to guide long-term strategy.
What is the difference between sentiment analysis and social listening?
Sentiment analysis evaluates emotions or opinions in text, like positive, negative, or neutral. Social listening is broader: it monitors conversations across platforms to track trends, brand perception, and customer feedback, often using sentiment analysis as one of its tools.
Can an AI agent be used for social listening?
Yes, AI agents can be used for social listening. Actually, they are ideal for the task due to their ability to adapt to changing or unexpected scenarios, which is typical of the ever-evolving social media landscape.
Which tools does an AI need to access social listening?
AI agents for social listening require tools to collect social media data. By integrating with scrapers like Bright Data’s Social Media Scraper, agents can monitor multiple platforms at scale, delivering real-time, actionable intelligence.
Which social media platforms does it make sense to apply social listening to?
The most relevant social media platforms to scrape for agentic social listening are X, Reddit, Threads, Facebook, Instagram, LinkedIn, TikTok, Quora, Pinterest, YouTube, and Vimeo.

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



