

In this article, you will learn:
- Whether synthetic data is truly the future of AI and ML training.
- What real-world web data is, its primary types, and how to collect it at scale.
- What synthetic data is, how it can be categorized, and how it is generated successfully.
- The impact of synthetic vs real data in terms of cost, privacy, robustness, and distribution quality.
- How data choice affects the AI training pipeline and model performance.
- Why a hybrid approach combining both data types is often the most effective strategy.
- The pros and cons of each approach.
Let’s dive in.
Is Synthetic Data the Future of AI/ML, or Does Web Data Still Matter?
The AI scaling laws show that performance tends to improve as models are trained on more parameters, more compute, and, critically, more data. In other words, larger models require exponentially larger datasets to sustain performance gains.
Historically, real web data has served as the foundation of modern AI training, but high-quality web data is finite. Famously, Elon Musk stated that AI companies have run out of training data and have “exhausted” the sum of human knowledge available for model training.
On top of that, web data is increasingly duplicated and expensive to collect, clean, and legally vet. This also highlights the importance of selecting web dataset providers that deliver AI-optimized, regularly updated, and privacy-compliant datasets.
These pressures are accelerating interest in alternative data sources, particularly synthetic data. According to Gartner, by 2030, synthetic data is expected to overshadow real-world data in AI model training. The firm attributes this shift to stricter privacy requirements, real-world data scarcity, and organizations seeking lower-cost alternatives that reduce legal and compliance risks.
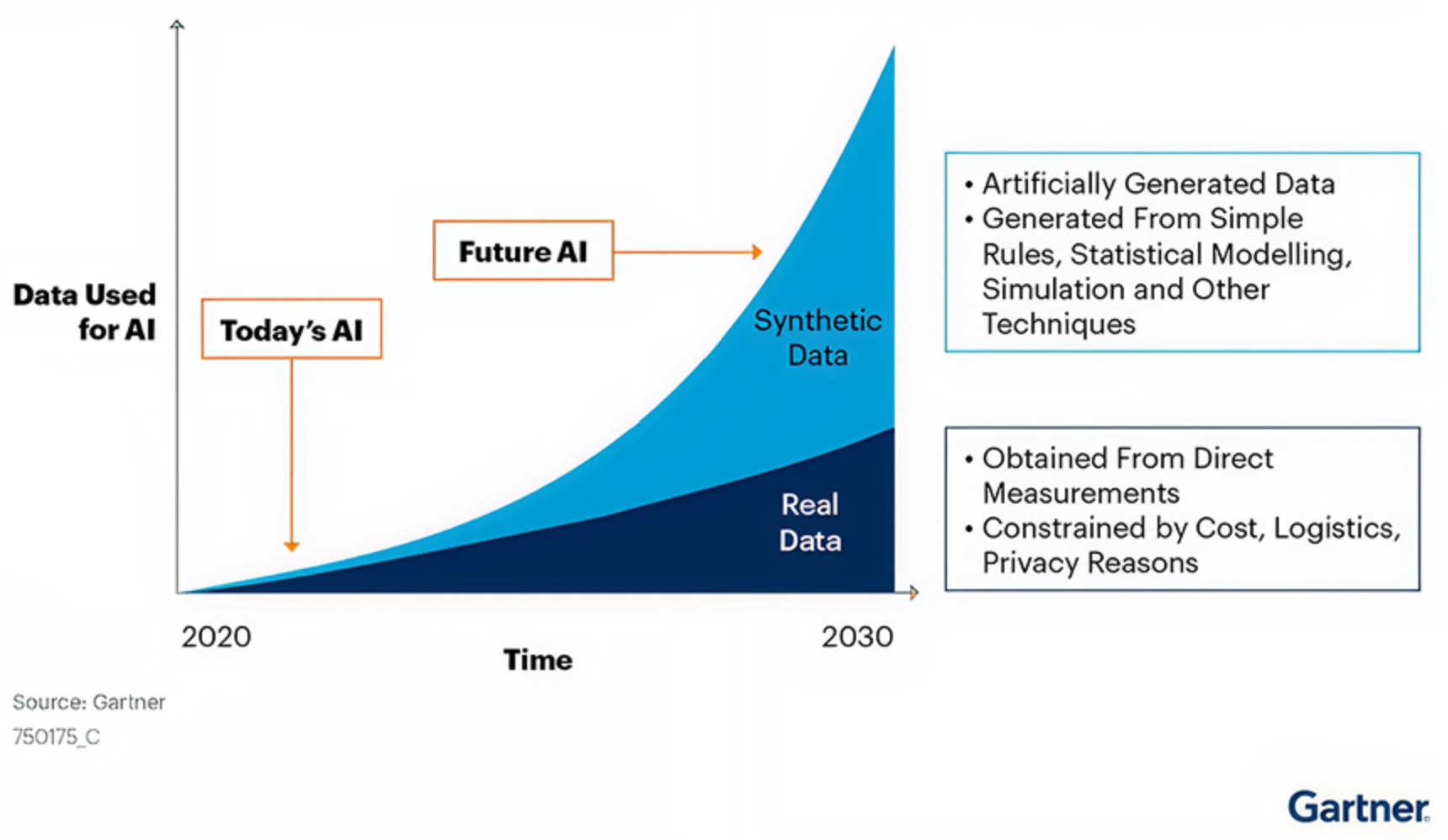
At the same time, this prediction should be viewed as an estimate rather than an inevitability. The internet continues to generate enormous volumes of content, with approximately 402 million terabytes of web data created every day!
To put it into perspective, GPT-3 was trained on roughly 45 terabytes of raw text before filtering. This comparison suggests that web-scale human-generated data remains vast and highly relevant for AI training.
As a result, the future of AI training is unlikely to depend exclusively on synthetic data. Instead, many machine learning experts expect a hybrid approach, a topic we will examine later in this article.
Synthetic Data vs Real Web Data: Comparing the Two Data Paradigms
In the following chapters, you will learn what synthetic data and real web data are, what they offer, and how they compare across multiple aspects of AI model training. We will begin with real web data, as it is more natural to grasp, and then move on to synthetic data.
For an immediate high-level comparison, take a look at the synthetic data vs real web data table below:
| Real Web Data | Synthetic Data | |
|---|---|---|
| Definition | Data collected from real web sources | Artificially generated data that mimics real-world distributions using models or rules |
| Examples | Web pages, forums, news articles, product pages, PDFs, etc. | LLM-generated text, GAN images, simulated robotics environments, rule-based datasets, etc. |
| Primary goal | Capture real-world complexity and natural behavior | Increase scale, coverage, and controllability |
| Data types | Unstructured (text, images), semi-structured (JSON, XML) | Structured, semi-structured, unstructured (text, image, audio, video) |
| How it is obtained | Mainly web scraping | LLM generation, GANs, VAEs, rule-based systems, simulation engines |
| Privacy risk | Higher (PII, compliance required) | Low (no real user data if properly generated) |
| Data quality | Noisy, inconsistent, but authentic | Clean, structured, but may include artifacts or hallucinations |
| Distribution | Natural, real-world distribution | Controlled but may introduce synthetic bias or shift |
| Robustness | Strong generalization to real-world inputs | Strong for targeted scenarios, weaker generalization |
| Long-tail coverage | Naturally present but sparse | Can be explicitly generated and oversampled |
| Bias risk | Reflects real-world bias | Can amplify or introduce new bias |
| Typical pipeline role | Pretraining, fine-tuning, evaluation | Pretraining, augmentation, edge-case generation |
| Risks | Data scarcity, compliance constraints, noise | Synthetic-to-real gap, model collapse, hallucinated patterns |
Now, it is time to dive into the two core data paradigms shaping modern AI training!
Exploring the World of Real Web Data
Here, we will cover everything you need to know about real web data for AI model training.
What Is Web Data?
Web data is information collected from web pages and other public web sources, mostly via web scraping. It includes unstructured content such as text, images, code, metadata, and documents (e.g., PDFs), as well as semi-structured data like JSON and XML.
Types of Web Data
There are many possible categories of web data. Still, at a high level, especially in the context of AI, it is useful to distinguish between two main types:
- Historical web data: Typically collected through web scraping pipelines, then cleaned, enriched, deduplicated, and aggregated into structured datasets in formats like CSV, JSON, and Parquet. These datasets are used for model pretraining and fine-tuning.
- Live web data: Retrieved in real time from web pages through scraping or APIs. It reflects the most up-to-date information available on the internet. This makes it particularly useful for grounding AI responses and for RAG systems, where freshness and factual accuracy are pivotal.
Together, these two forms of web data serve complementary roles in modern AI systems.
How to Get Web Data
To source web data for AI/ML training, you need a scalable web scraping pipeline. Building that in-house requires significant engineering expertise.
It involves handling a wide range of anti-scraping challenges like IP blocking, CAPTCHA solving, and rate limiters. Plus, it entails strong data engineering capabilities for cleaning, deduplication, and normalization. As a result, companies prefer to rely on dedicated web data platforms, such as Bright Data.
Bright Data provides an end-to-end ecosystem for web data collection and delivery. What makes it stand out is its 400M+ residential proxy network across 195 countries, which supports highly scalable and concurrent web data collection. This enterprise-grade infrastructure is also compliant with GDPR and CCPA, along with other privacy and security standards.
Bright Data’s offering for web data includes:
- Web data marketplace: A collection of 350+ ready-to-use datasets covering over 250 domains (including Reddit, Amazon, LinkedIn, Yahoo Finance, and many others). These datasets span over 17 petabytes of web data and are optimized for ML training and AI applications. They are delivered in multiple formats, such as JSON, CSV, and Parquet, via cloud delivery and other distribution methods.
- Web scraping products: A suite of API-based solutions for live web data extraction:
– Web Unlocker API: Bypasses blocks and CAPTCHAs to ensure data access on any web page.
– SERP API: Delivers structured, real-time search engine results from Google, Bing, Yandex, and others.
– Discover API: Returns a ranked, live set of URLs from the public web, ready for downstream processing.
– Crawl API: Performs scalable website crawling and structured data extraction.
– Scraper APIs: Cover 120+ websites for direct structured data extraction from popular domains.
Bright Data also offers managed services for turnkey data acquisition. These enable organizations to focus on model development rather than data engineering.
Entering the Realm of Synthetic Data
In this chapter, you will explore synthetic data usage for AI/ML model training.
What Is Synthetic Data?
Synthetic data is artificially generated information that replicates the statistical patterns and characteristics of real-world data. Instead of being collected from real events, it is produced artificially.
Types of Synthetic Data
Synthetic data can be categorized:
- By composition and privacy level:
– Fully synthetic: Generated entirely from scratch using machine learning models trained on real data. Because it contains no original data points, it offers the highest level of privacy protection.
– Partially synthetic: Takes an existing real dataset and replaces only the sensitive attributes (like names, addresses, or Social Security numbers) with artificial values. This preserves specific data trends while anonymizing PII.
– Hybrid: Blends real, anonymized records with artificially generated ones. This is commonly used to “upsample” or enrich datasets by artificially creating rare events (e.g., adding synthetic fraud records to a banking dataset).
- By data structure:
– Structured data: Highly organized, quantitative data presented in tabular formats.
– Unstructured data: Qualitative or media-heavy data formats. It includes synthetic text, artificially generated images, video, and audio.
How to Produce Synthetic Data
At a high level, synthetic data can be generated using three predominant approaches:
- Fully AI-generated: Created using models such as GANs (Generative Adversarial Networks), VAEs (Variational Autoencoders), or LLMs. These systems learn the underlying distribution of real datasets and then generate entirely new samples that resemble the original data without directly copying it.
- Rule-based generation: Where data is produced using predefined human-written rules, constraints, or business logic. This ensures strict consistency, structural correctness, and controlled behavior, making it useful for systems that require predictable outputs.
- Simulated or mock data: Generated through physical or behavioral simulations. This is commonly used in environments such as autonomous driving or robotics, where digital twins and physics engines create realistic “what-if” scenarios.
Impact of Synthetic Data vs Real Web Data on AI/ML Model Training
Let’s now compare several aspects to understand the consequences of using synthetic vs real web data for AI training.
Data Distribution and Realism
Web data closely approximates a natural data distribution. It captures the inherent complexity of human language and behavior as it appears in the real world. This brings important benefits, including natural correlations between features, authentic edge cases, diverse linguistic styles, and realistic noise such as human mistakes, ambiguity, and inconsistencies.
However, real-world web data is also inherently messy. It is often imbalanced, duplicated, difficult to curate at scale, and may contain low-quality or spammy content that requires extensive filtering.
In contrast, synthetic data represents a controlled distribution. It is intentionally designed and generated, allowing practitioners to shape dataset properties in a precise way. This enables balanced class distributions, targeted coverage of specific scenarios, rare event generation, and structured curriculum learning.
At the same time, synthetic data introduces important risks, including distribution shift, unrealistic artifacts, mode collapse, and over-regularization when the generator is too constrained.
Important: A central machine learning concept in this regard is the synthetic-to-real gap, similar to the sim-to-real problem in robotics. Models trained heavily on synthetic data may underperform on realistic inputs because the generated distribution does not fully match reality.
Long-Tail Coverage
Real web data naturally includes a wide range of knowledge. This includes obscure facts, rare events, and unexpected edge cases that emerge organically from human activity. Yet, these long-tail examples are inherently sparse. By definition, rare events appear infrequently, which makes it difficult for models to learn robust patterns from them during training.
On the other hand, you can use synthetic data to explicitly generate rare or underrepresented scenarios. That way, you can target specific gaps in a dataset and improve coverage where real data is insufficient. Examples include rare coding bugs and low-resource languages.
A major advantage of using synthetic data for long-tail coverage is the ability to oversample rare events. This can help reduce class imbalance and improve model performance on infrequent but important cases. Still, if rare scenarios are artificially overrepresented, the model’s learned priors may become distorted.
For example, if cybersecurity exploit cases are heavily oversampled in synthetic data, the model may start to overpredict their likelihood in real-world settings. As a result, careful calibration is fundamental to ensure that synthetic long-tail generation improves coverage without introducing unrealistic distributions.
Cost and Privacy Considerations
As mentioned earlier, companies rarely build their own web scraping and dataset infrastructure. Instead, they rely on third-party data providers such as Bright Data, which abstract away crawling, unblocking, cleaning, and delivery. This fundamentally shifts both the cost structure and the privacy tradeoffs of data acquisition.
Below is a simplified overview of Bright Data’s pricing model for web data collection:
| Price | Custom plans for enterprises | GDPR compliant | CCPA compliant | Compliant to SEC regulations | |
|---|---|---|---|---|---|
| Datasets | From $0.001 to $0.0025 per record | ✔️ | ✔️ | ✔️ | ✔️ |
| Web scraping APIs | $1-$1.5/1K results | ✔️ | ✔️ | ✔️ | ✔️ |
Bright Data also provides data annotation services, helping organizations further reduce reliance on in-house data engineering. Importantly, its data is aligned with privacy frameworks, which helps reduce legal and regulatory risk.
Without such web data providers, you would have to handle infrastructure development, ongoing maintenance, and the complex governance of PII, copyrighted material, and sensitive behavioral data internally.
With synthetic data, the primary costs come from inference compute and access to teacher models or APIs. From a privacy perspective, artificially generated data offers an inherent advantage. Because it is generated rather than collected from real individuals, synthetic data naturally eliminates exposure to personally identifiable information.
Now, the right choice between synthetic and real web data depends on quality requirements, scale, privacy constraints, and the target use case. Depending on these factors, either approach can be more cost-effective or more expensive than the other.
Data Quality Factors
Web data generally provides weak supervision. Models learn from naturally occurring signals such as next-token prediction, metadata, and human-generated content. The problem is that real data is noisy and can contain misinformation, contradictions, spam, biased opinions, and inconsistent formatting.
On the contrary, synthetic data offers greater control over quality and supervision. It can provide perfectly formatted labels, structured outputs, step-by-step reasoning, and automatically verified examples. For instance, synthetic datasets can include mathematically verified answers or code snippets validated through unit tests. This improves consistency and makes targeted training easier.
The major risk with synthetic data is that its quality is fundamentally bounded by the quality of the generating model, algorithm, or underlying approach. Generated hallucinations or factual errors can propagate into the final dataset, causing models to learn confidently incorrect patterns. Similarly, hidden biases present in generation systems may also be inherited by downstream models. On the bright side, synthetic data supports stronger alignment and safety tuning.
Generalization and Robustness
One of the most important questions in machine learning is how well a model generalizes to unseen inputs. In other terms, which data source leads to better robustness under distribution shift: real-world web data or synthetic data?
Web data tends to achieve strong robustness, as it reflects naturally occurring human behavior, language, and noise. This improves performance on out-of-distribution inputs and enhances domain transfer, particularly when models are deployed in unpredictable environments.
Instead, synthetic data is better suited for targeted optimization. It lets you precisely devise training examples for specific skills, edge cases, or rare scenarios.
Key Considerations When Training AI with Synthetic or Real Web Data
Now that you know the differences between synthetic and web data, you are ready to see the practical implications of using each approach in the AI model training.
Data Training Pipelines
When relying on web data, the pipeline typically follows these steps:
- Crawling: Collect raw data from websites using large-scale scraping systems or custom web scraping bots across multiple domains.
- Deduplication: Remove duplicate or near-duplicate content to reduce redundancy and improve dataset diversity and efficiency.
- Language detection: Identify the language of each sample and filter or segment the dataset based on target language requirements.
- Quality scoring: Evaluate and rank content using heuristics or models to filter out low-quality or irrelevant information.
- Toxicity filtering: Detect and remove harmful, unsafe, or inappropriate content to ensure training safety and compliance.
- PII removal and decontamination: Remove personally identifiable information and eliminate contamination from sensitive or unwanted sources.
When it comes to synthetic data pipelines, the steps are more generation-focused:
- Prompt generation: Design prompts or templates that define the structure, task, or scenario for synthetic data creation.
- Model sampling: Generate candidate outputs using generative models such as LLMs, GANs, or other systems.
- Verification: Validate outputs using automated checks, rules, or external tools to ensure correctness and consistency.
- Filtering: Remove low-quality, inconsistent, or hallucinated samples that do not meet predefined standards.
- Reward scoring: Assign quality or preference scores to rank and select the best synthetic examples.
- Iterative refinement: Improve data quality through repeated cycles of generation, filtering, and re-sampling to enhance robustness.
As you can tell, real web data pipelines focus on cleaning noisy real-world inputs. Instead, synthetic pipelines are more about controlling and validating generated outputs. Finally, once the training dataset has been produced, you can then proceed with training the AI model.
Performance Comparison
The final question is whether synthetic data can outperform real-world web data.
A recent paper in AI for Requirements Engineering (AI4RE) suggests that LLM-generated datasets can be a strong alternative when real data is scarce or difficult to access. Empirical results show that models trained exclusively on synthetic data can outperform those trained solely on human-authored datasets. In detail, improvements of up to +37% in precision and +30% in recall were observed compared to real-data-only baselines.
That said, this is not a binary or absolute conclusion. The evidence does not suggest that synthetic data should fully replace real data, but rather that the best performance is often achieved through a hybrid approach. Learn more about it!
Synthetic Data + Real-World Web Data: Why a Hybrid Approach Works Best
The debate between synthetic and real-world web data is no longer about choosing one over the other, but about how to combine them.
Recent evidence shows that hybrid configurations combining synthetic and real data achieve gains of up to +85% in precision and a doubling of recall compared to using only real-world web data.
At the same time, multiple studies and industry reports highlight that naïvely mixing synthetic and real samples can actually degrade performance due to distribution mismatch, redundancy, or bias amplification. This makes it clear that performance gains depend on careful dataset design rather than simple data accumulation.
A key open question is the optimal ratio between synthetic and real data. There is no universal answer. Some practitioners adopt a Pareto-style 80/20 split (mostly real data with synthetic augmentation), while others prefer more balanced mixes such as 60/40, depending on task complexity, domain risk, and data availability.
Similarly, the placement of synthetic data in the pipeline matters. Industry practice guides a staged strategy: synthetic-heavy pre-training for coverage, followed by real-data fine-tuning for grounding and evaluation.
Ultimately, hybrid pipelines work best because they combine complementary strengths. Synthetic data provides scale and edge-case coverage, while real web data ensures fidelity, realism, and reliable evaluation in production environments.
Real Web Data vs Synthetic Data: Pros and Cons
As a summary section, see the advantages and disadvantages of the two data paradigms.
Real Web Data
👍 Pros:
- Captures authentic real-world patterns and noise
- Strong benchmark for evaluation and validation
- Reduces risk of synthetic bias or artifacts
👎 Cons:
- Expensive and time-consuming to collect and label
- Can be limited by privacy and regulatory constraints
- Can be imbalanced or incomplete
Synthetic Data
👍 Pros:
- Highly scalable and fast to generate
- Can simulate rare events and edge cases
- Supports privacy-preserving training pipelines
👎 Cons:
- Risk of domain gap vs real-world data
- Requires careful validation and quality control
- May lack diversity compared to real data, leading to overfitting on synthetic artifacts
Real Web Data + Synthetic Data
👍 Pros:
- Combines scale (synthetic) with realism (real data)
- Often achieves best performance in practice
- Stronger robustness across edge cases and normal cases
👎 Cons:
- Requires careful balancing and tuning of ratios
- Risk of performance degradation if mixed poorly
- More complex pipeline design and maintenance
Conclusion
In this synthetic data vs real web data blog post, you learned the impact of using real-world or artificially generated data for AI/ML model training. As is always the case in these situations, there is no single winner. The right approach depends on your specific budget, technical skills, and performance goals.
No matter the setup, web data still plays a central role in AI model training, whether for pre-training or final fine-tuning. Its broad coverage and real-world grounding make it essential. However, some companies prefer to opt for more synthetic-heavy approaches. The main reason is the complexity of building and maintaining web data retrieval pipelines in-house.
This is where Bright Data can help. With enterprise-grade, highly scalable, and compliant infrastructure, it provides:
- Web datasets: 350+ ready-made datasets with billions of records, already collected, curated, and optimized for AI training use cases.
- Web scraping products: API-based solutions to access fresh web data from many sites at scale.
In addition, Bright Data offers data annotation services. It provides scalable, accurate, and customizable labeling solutions for NLP, computer vision, and speech recognition use cases.
Discover all Bright Data solutions for AI!
Create a Bright Data account for free and explore our web data solutions!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



