

In this article, you will learn:
- What the Anthropic web fetch tool is and its main limitations.
- How it works.
- How to use it in cURL and Python.
- What Bright Data offers to achieve similar goals.
- How the Anthropic web fetch tool and Bright Data web data tools compare.
- A summary table for a quick comparison.
Let’s dive in!
What Is the Anthropic Web Fetch Tool?
The Anthropic web fetch tool allows Claude models to retrieve content from web pages and PDF documents. This tool was introduced for free in the Claude beta release on 2026-09-10.
By including this tool in a Claude API request, the configured LLM can fetch and analyze the full text from specified web page or PDF URLs. This gives Claude access to up-to-date, source-based information for grounded responses.
Notes and Limitations
These are the main notes and limitations associated with the Anthropic web fetch tool:
- Available on the Claude API at no additional cost. You only pay the standard token fees for the fetched content that is included in your conversation context.
- Retrieves full content from specified web pages and PDF documents.
- Currently in beta and requires the beta header
web-fetch-2026-09-10. - Claude cannot dynamically construct URLs. You must explicitly provide complete URLs, or it can only use URLs obtained from previous web searches or fetch results.
- Can only fetch URLs that have already appeared in the conversation context. This includes URLs from user messages, client-side tool results, or previous web search and web fetch results.
- Only works with the following models: Claude Opus 4.1 (
claude-opus-4-1-20260805), Claude Opus 4 (claude-opus-4-20260514), Claude Sonnet 4.5 (claude-sonnet-4-5-20260929), Claude Sonnet 4 (claude-sonnet-4-20260514), Claude Sonnet 3.7 (claude-3-7-sonnet-20260219), Claude Sonnet 3.5 v2 (deprecated) (claude-3-5-sonnet-latest), and Claude Haiku 3.5 (claude-3-5-haiku-latest). - Does not support dynamically rendered JavaScript websites.
- Can include optional citations for fetched content.
- Works with prompt caching, so that cached results can be reused across conversation turns.
- Supports
max_uses,allowed_domains,blocked_domains, andmax_content_tokensparameters. - Common error codes includes:
invalid_input,url_too_long,url_not_allowed,url_not_accessible,too_many_requests,unsupported_content_type,max_uses_exceeded, andunavailable.
How Web Fetch Works in Claude Models
This is what happens behind the scenes when you add the Anthropic web fetch tool to your API request:
- Claude determines when to fetch content based on the prompt and the URLs provided.
- The API retrieves the full text content from the specified URL.
- For PDFs, automatic text extraction is performed.
- Claude analyzes the fetched content and generates a response, optionally including citations.
The resulting response is then returned to the user or added to the conversation context for further analysis.
How to Use the Anthropic Web Fetch Tool
The two main ways to use the web fetch tool are by enabling it in a request to one of the supported Claude models. This can be done in either of the following ways:
- Via a direct API call to the Anthropic API.
- Through one of the Claude client SDKs, such as the Anthropic Python API library.
See how in the following sections!
In both cases, we will demonstrate how to use the web fetch tool to scrape the Anthropic homepage, shown below:

Prerequisites
The main requirement for using the Anthropic web fetch tool is having access to an Anthropic API key. Here, we will assume you have an Anthropic account with an API key in place.
Through a Direct API Call
Utilize the web fetch tool by making a direct API call to the Anthropic API with one of the supported models, as shown below in a cURL POST request:
curl https://api.anthropic.com/v1/messages \
--header "x-api-key: <YOUR_ANTHROPIC_API_KEY>" \
--header "anthropic-version: 2023-06-01" \
--header "anthropic-beta: web-fetch-2026-09-10" \
--header "content-type: application/json" \
--data '{
"model": "claude-sonnet-4-5-20260929",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": "Scrape the content from 'https://www.anthropic.com/'"
}
],
"tools": [{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
}]
}'Note that claude-sonnet-4-5-20260929 is one of the models supported by the web fetch tool.
Also, notice that the two special headers, anthropic-version and anthropic-beta, are required.
To enable the web fetch tool in the configured model, you must add the following item to the tools array in the request body:
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
}The type and name fields are what matter, while max_uses is optional and defines how many times the tool can be called within a single iteration.
Replace the <YOUR_ANTHROPIC_API_KEY> placeholder with your actual Anthropic API key. Then, execute the request and you should get something like this:
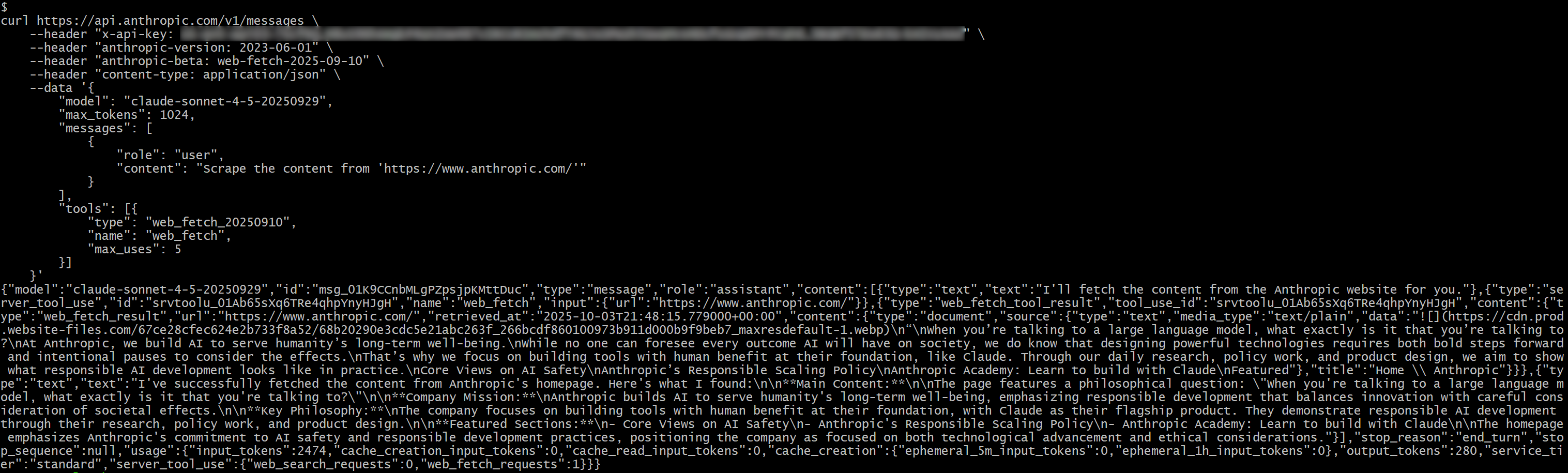
In the response, you should see:
{"type":"server_tool_use","id":"srvtoolu_01Ab65sXq6TRe4qhpYnyHJgH","name":"web_fetch","input":{"url":"https://www.anthropic.com/"}}This specifies that the LLM executed a call to the web_fetch tool.
Specifically, the result produced by the tool would be something like:

“When you’re talking to a large language model, what exactly is it that you’re talking to?
At Anthropic, we build AI to serve humanity’s long-term well-being.
While no one can foresee every outcome AI will have on society, we do know that designing powerful technologies requires both bold steps forward and intentional pauses to consider the effects.
That’s why we focus on building tools with human benefit at their foundation, like Claude. Through our daily research, policy work, and product design, we aim to show what responsible AI development looks like in practice.
Core Views on AI Safety
Anthropic’s Responsible Scaling Policy
Anthropic Academy: Learn to build with Claude
Featured
This represents a sort of Markdown-like version of the homepage of the specified input URL. It is “sort of” Markdown, as some links are omitted and—aside from the first image—the output mainly focuses on text, which is exactly what the web fetch tool is designed to return.
Note: Overall, the result is accurate, but it definitely misses some content, which may have been lost during processing by the tool. In fact, the original page contains more text than what was retrieved.
Using the Anthropic Python API Library
Alternatively, you can call the web fetch tool using the Anthropic Python API library with:
# pip install anthropic
import anthropic
# Replace it with your Anthropic API key
ANTHROPIC_API_KEY = "<YOUR_ANTHROPIC_API_KEY>"
# Initialize the Anthropic API client
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
# Perform a request to Claude with the web fetch tool enabled
response = client.messages.create(
model="claude-sonnet-4-5-20260929",
max_tokens=1024,
messages=[
{
"role": "user",
"content": "Scrape the content from 'https://www.anthropic.com/'"
}
],
tools=[
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2026-09-10"
}
)
# Print the result produced by the AI in the terminal
print(response.content)
This time, the result will be:
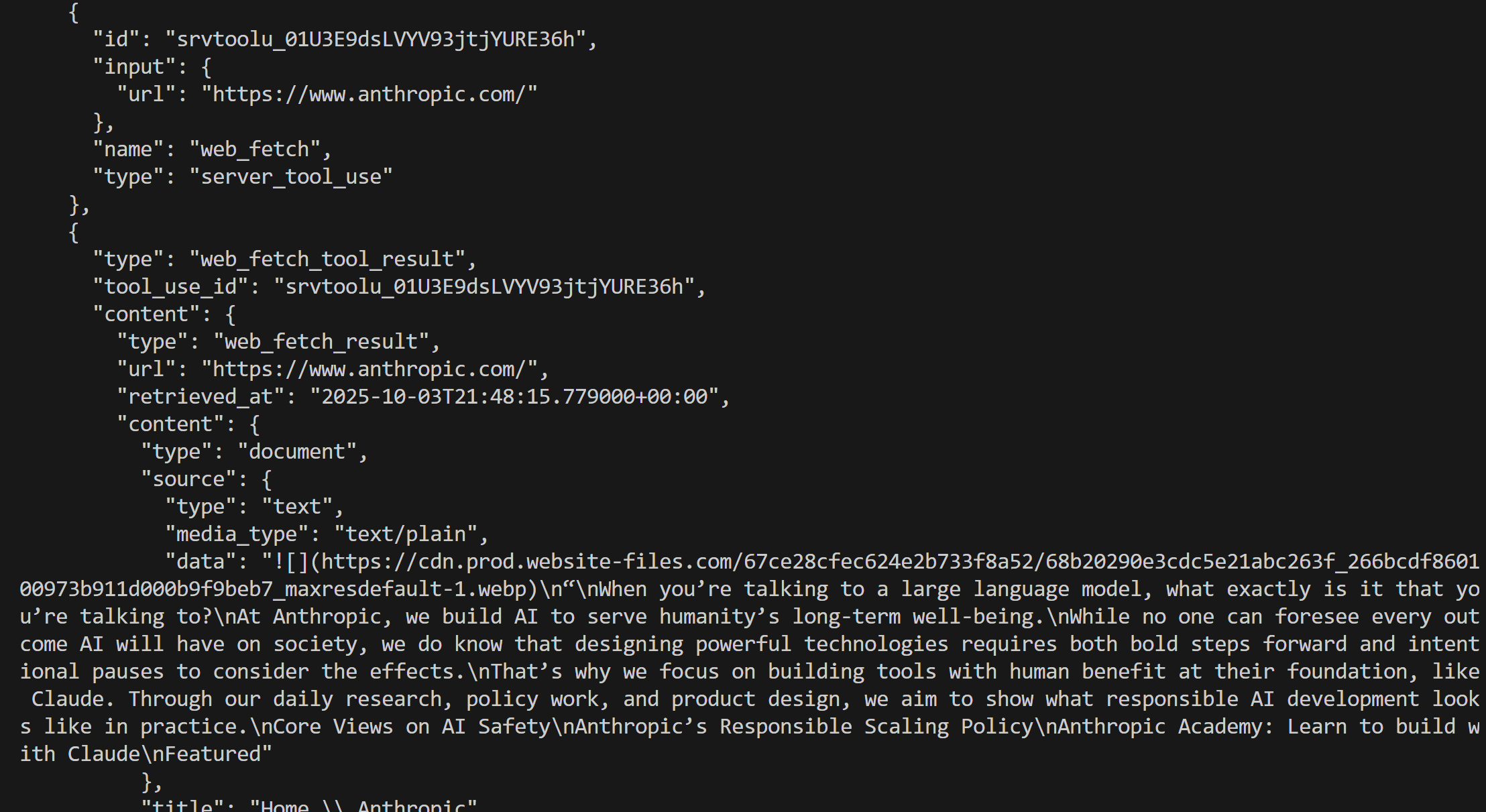
Great! This is equivalent to what we saw earlier.
An Introduction to Bright Data Web Data Tools
The Bright Data AI infrastructure offers a rich set of solutions to let your AI search, crawl, and navigate the web freely. This includes:
- Unlocker API: Reliably fetch content from any public URL, automatically bypassing blocks and solving CAPTCHAs.
- Crawl API: Effortlessly crawl and extract entire websites, with outputs in LLM-ready formats for effective inference and reasoning.
- SERP API: Gather real-time, geo-specific search engine results to discover relevant data sources for a specific query.
- Browser API: Enable your AI to interact with dynamic sites and automate agentic workflows at scale using remote stealth browsers.
Among the many tools, services, and products for web data retrieval in the Bright Data infrastructure, we will focus on Web MCP. This provides AI-integration-ready tools built on top of Bright Data products that are directly comparable to those offered by Anthropic. Note that Web MCP also functions as Claude MCP, fully integrating with any Anthropic models.
Out of all the 60+ available tools, the scrape_as_markdown tool is the perfect match for comparison. It allows you to scrape a single webpage URL with advanced options for content extraction and returns results in Markdown format. This tool can access any webpage, even those using bot detection or CAPTCHA.
Importantly, that tool is available on Web MCP even in the free tier, meaning you can use it at no cost. So, it achieves web data retriaval functionality similar to Anthropic’s web fetch tool, making Web MCP ideal for a direct comparison.
Anthropic Web Fetch Tool vs Bright Data Web Data Tools
In this section, we will build a process to compare the Anthropic web fetch tool with Bright Data’s Web Data Tools. In detail, we will:
- Use the web fetch tool through the Anthropic Python API library.
- Connect to Bright Data’s Web MCP using LangChain MCP adapters (but any other supported integration is fine).
We will run both approaches using the same prompt and Claude model across the following four input URLs:
"https://www.anthropic.com/""https://www.g2.com/products/bright-data/reviews""https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/""https://it.linkedin.com/in/antonello-zanini"
These represent a good mix of real-world pages that you might want an AI to automatically fetch content from: a website homepage, a G2 product page, an Amazon product page, and a public LinkedIn profile. Note that G2 is notoriously challenging to scrape due to Cloudflare protection, which is why it was intentionally included in the comparison.
Let’s see how the two tools perform!
Prerequisites
Before following this section, you should have:
- Python installed locally.
- An Anthropic API key.
- A Bright Data account with an API key.
To set up a Bright Data account and generate your API key, follow the official guide. It is also recommended to review the official Web MCP documentation.
Additionally, knowledge of how LangChain integration works and familiarity with the tools provided by Web MCP will be helpful.
Web Fetch Tool Integration Script
To run the Anthropic web fetch tool through the selected input URLs, you can write Python logic like this:
# pip install anthropic
import anthropic
Replace it with your Anthropic API key
ANTHROPIC_API_KEY = ""
Initialize the Anthropic API client
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
def scrape_content_with_anthropic_web_fetch_tool(url):
return client.messages.create( model="claude-sonnet-4-5-20260929",
max_tokens=1024,
messages=[
{
"role": "user",
"content": f"Scrape the content from '{url}'"
}
],
tools=[
{
"type": "web_fetch_20260910",
"name": "web_fetch",
"max_uses": 5
},
],
extra_headers={
"anthropic-beta": "web-fetch-2026-09-10"
}
)
Next, you can call this function on an input URL like this:
scrape_content_with_anthropic_web_fetch_tool("https://www.anthropic.com/")
Bright Data Web Data Tools Integration Script
Web MCP can be integrated with a wide range of technologies, as described on our blog. Here, we will demonstrate integration with LangChain, as it is one of the easiest and most popular options.
Before getting started, it is recommended to check out the guide: “LangChain MCP Adapters with Bright Data’s Web MCP.”
In this case, you should end up with a Python snippet like this:
# pip install "langchain[anthropic]" langchain-mcp-adapters langgraph
import asyncio
from langchain_anthropic import ChatAnthropic
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
import json
# Replace with your API keys
ANTHROPIC_API_KEY = "<YOUR_ANTHROPIC_API_KEY>"
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>"
async def scrape_content_with_bright_data_web_mcp_tools(agent, url):
# Agent task description
input_prompt = f"Scrape the content from '{url}'"
# Execute the request in the agent, stream the response, and return it as a string
output = []
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
content = step["messages"][-1].content
if isinstance(content, list):
output.append(json.dumps(content))
else:
output.append(content)
return "".join(output)
async def main():
# Initialize the LLM engine
llm = ChatAnthropic(
model="claude-sonnet-4-5-20260929",
api_key=ANTHROPIC_API_KEY
)
# Configuration to connect to a local Bright Data Web MCP server instance
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "false" # Optionally set to "true" for Pro mode
}
)
# Connect to the MCP server
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Initialize the MCP client session
await session.initialize()
# Get the Web MCP tools
tools = await load_mcp_tools(session)
# Create the ReAct agent with Web MCP integration
agent = create_react_agent(llm, tools)
# scrape_content_with_bright_data_web_mcp_tools(agent, "https://www.anthropic.com/")
if __name__ == "__main__":
asyncio.run(main())
This defines a ReAct agent that has access to the Web MCP tools.
Remember: Web MCP offers a Pro mode, which provides access to premium tools. Using Pro mode is not strictly required in this case. Thus, you can rely only on the tools available in the free tier. The free tools include scrape_as_markdown, which is sufficient for this benchmark.
In simpler terms, from a cost perspective, using Web MCP in free mode will not cost more than the token usage for the Claude model itself (which is the same in both scenarios). Essentially, the cost structure for this setup is the same as when connecting directly to Claude via the API.
Benchmark Results
Now, execute the two functions representing the two methods for AI web data retrieval using logic like this:
# Where to store the benchmark results
benchmark_results = []
# The input URLs to test the two approaches against
urls = [
"https://www.anthropic.com/",
"https://www.g2.com/products/bright-data/reviews",
"https://www.amazon.com/Owala-FreeSip-Insulated-Stainless-BPA-Free/dp/B0BZYCJK89/",
"https://it.linkedin.com/in/antonello-zanini"
]
# Test each URL
for url in urls:
print(f"Testing the two approaches on the following URL: {url}")
anthropic_start_time = time.time()
anthropic_response = scrape_content_with_anthropic_web_fetch_tool(url)
anthropic_end_time = time.time()
bright_data_start_time = time.time()
bright_data_response = await scrape_content_with_bright_data_web_mcp_tools(agent, url)
bright_data_end_time = time.time()
benchmark_entry = {
"url": url,
"anthropic": {
"execution_time": anthropic_end_time - anthropic_start_time,
"output": anthropic_response.to_json()
},
"bright_data": {
"execution_time": bright_data_end_time - bright_data_start_time,
"output": bright_data_response
}
}
benchmark_results.append(benchmark_entry)
# Export the benchmark data
with open("benchmark_results.json", "w", encoding="utf-8") as f:
json.dump(benchmark_results, f, ensure_ascii=False, indent=4)
The results can be summarized in the following table:
| Anthropic Web Fetch Tool | Bright Data Web Data Tools | |
|---|---|---|
| Anthropic homepage | ✔️ (partial text information) | ✔️ (full information in Markdown) |
| G2 review page | ❌ (tool failed after ~10 seconds) | ✔️ (full Markdown version of the page) |
| Amazon product page | ✔️ (partial text information) | ✔️ (full Markdown version of the page or structured JSON product data in Pro mode) |
| LinkedIn profile page | ❌ (tool failed immediately) | ✔️ (full Markdown version of the page or structured JSON profile data in Pro mode) |
As you can see, not only is the Anthropic web fetch tool less effective than Bright Data web data tools, but even when it works, it produces less complete results.
The Anthropic tool primarily focuses on text, whereas Web MCP tools like scrape_as_markdown return the full Markdown version of a page. Additionally, with Pro tools such as web_data_amazon_product, you can obtain structured data feeds from popular sites like Amazon.
Overall, Bright Data web data tools are the clear winner in terms of both accuracy and execution time!
Summary: Comparison Table
| Anthropic Web Fetch Tool | Bright Data Web Data Tools | |
|---|---|---|
| Content Types | Web pages, PDFs | Web pages |
| Capabilities | Text extraction | Content extraction, web scraping, web crawling, and more |
| Output | Mainly plain text | Markdown, JSON, and other LLM-ready formats |
| Model Integration | Only works with specific Claude models | Fully integrates with any LLM and over 70 technologies |
| Support for JavaScript-Rendered Sites | ❌ | ✔️ |
| Anti-Bot Bypass/CAPTCHA Handling | ❌ | ✔️ |
| Robustness | Beta | Production-ready |
| Support for Batch Requests | ✔️ | ✔️ |
| Agent Integration | Only in Claude solutions | ✔️ (in any AI agent building solution supporting MCP or official Bright Data tools) |
| Reliability and Completeness | Partial content; may fail on complex pages | Full content extraction; handles complex sites and pages with bot protection |
| Cost | Only standard token usage | Only standard token usage in free mode; additional costs in Pro mode |
For integrating Web MCP with Anthropic technologies and Claude models, refer to the following guides:
- Integrating Claude Code with Bright Data’s Web MCP
- Web Scraping with Claude: AI-Powered Parsing in Python
- How to Use Bright Data with Pica MCP in Claude Desktop
Conclusion
In this comparison blog post, you saw how the Anthropic web fetch tool stacks up against the web data retrieval and interaction capabilities offered by Bright Data. In particular, you learned how to use the Anthropic tool in real-world examples, followed by a benchmark comparison using an equivalent LangChain agent interacting with Bright Data’s Web MCP.
The clear winner was Bright Data’s tools, which include a range of AI-ready products and services capable of supporting a wide variety of use cases and scenarios.
Create a Bright Data account for free today and start exploring our AI-ready web data tools!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



