

In this tutorial, you will learn the following:
- What Cloudflare is.
- A deeper look at its WAF mechanism.
- How its anti-bot system works from a technical point of view.
- What happens when you target a Cloudflare-protected site using standard automation tools.
- High-level approaches to bypass Cloudflare.
- How to bypass the Cloudflare human check in Python.
- How to bypass Cloudflare at scale.
Let’s dive in!
What Is Cloudflare?
Cloudflare is a web infrastructure and security company that operates one of the largest networks on the Web. It offers a comprehensive suite of services designed to make websites faster and more secure.
At its core, Cloudflare functions primarily as a CDN (Content Delivery Network), caching site content on a global network to improve load times and reduce latency. On top of that, it provides features like DDoS (Distributed Denial-of-Service) protection, a WAF (Web Application Firewall), bot management, DNS services, and more.
By integrating with Cloudflare’s network, sites can quickly gain enhanced security and optimized performance. This has made Cloudflare the go-to solution for millions of websites worldwide.
Understanding Cloudflare’s Anti-Bot Mechanisms
One of the reasons why Cloudflare is so popular is its WAF (Web Application Firewall). This can be enabled on any web page served through its global network. In detail, it represents one of the most effective solutions against scrapers, undesired crawlers, and bots in general.
More specifically, the Cloudflare WAF sits in front of your web applications. It inspects and filters incoming requests in real time to stop attacks or unwanted traffic before they reach your servers or access your web pages.
As part of its multilayered defense strategy, the Cloudflare WAF uses proprietary algorithms to detect and block malicious bots. These algorithms analyze several characteristics of incoming traffic, including:
- TLS fingerprints: Inspects how the TLS handshake is performed by the HTTP client or browser. It looks at details like the cipher suites offered, the order of negotiation, and other low-level traits. Bots and non-standard clients often have unusual, non-browser-like TLS signatures that give them away.
- HTTP request details: Examines HTTP headers, cookies, user-agent strings, and other aspects. Bots often reuse default or suspicious configurations that differ from those used by real browsers.
- JavaScript fingerprints: Runs JavaScript in the client’s browser to gather detailed information about the environment. This includes the exact browser version, operating system, installed fonts or extensions, and even subtle hardware characteristics. These data points form a fingerprint that helps distinguish real users from automated scripts.
- Behavioral analysis: One of the strongest indicators of automated traffic is unnatural behavior. Cloudflare monitors patterns like rapid requests, lack of mouse movements, identical click paths, idle times, and more. It uses machine learning to determine whether the browsing behavior matches that of a human or a bot. This is one of the most complex anti-bot techniques.
Cloudflare generally provides two modes of human verification:
- Always show the human verification challenge
- Automated human verification challenge (only when suspicious activity is detected)
Explore both options below!
Mode #1: Always Show the Human Verification Challenge
The first mode is less common but offers stronger protection. The idea is to always require human verification on the first access to a site.
For example, this is how StackOverflow operates as of this writing. Try visiting it in incognito mode (to ensure a fresh session with no cookies), and you will see a CAPTCHA called Cloudflare Turnstile, even if you are a real human user:
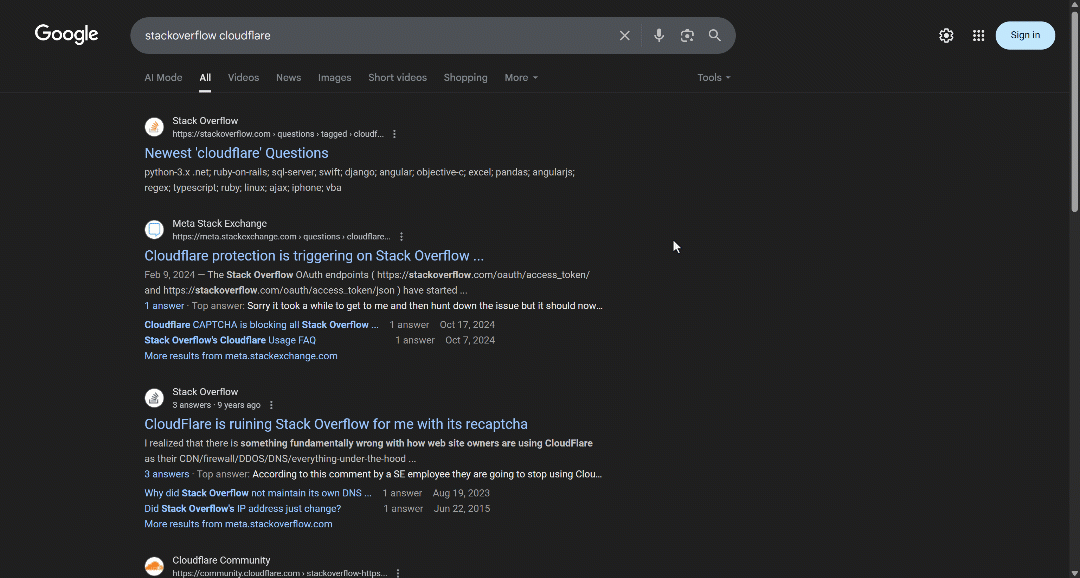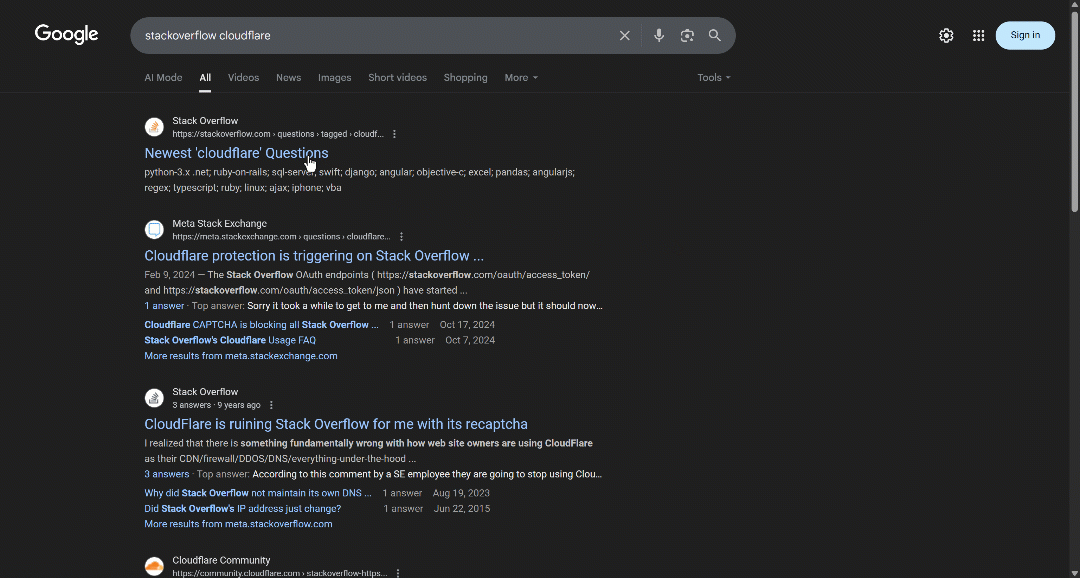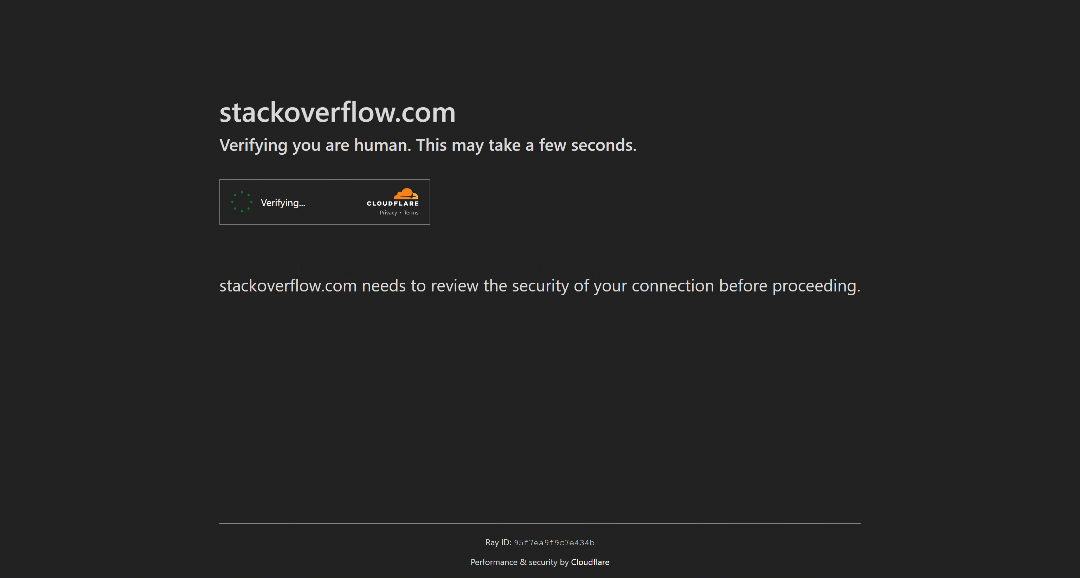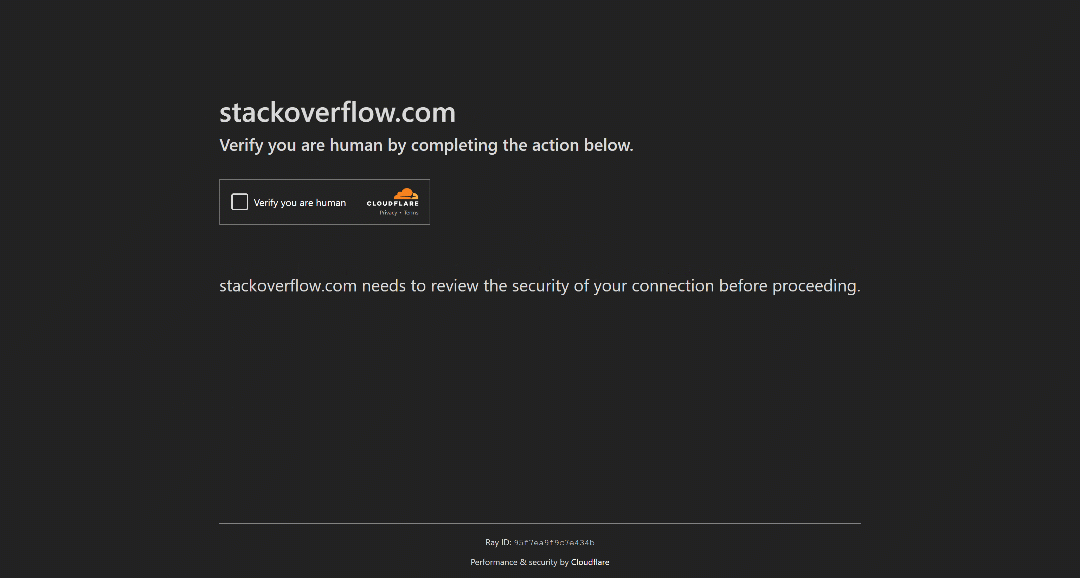
Note: By the time you read this article, StackOverflow’s bot protection may have changed or be working differently.
In this case, if you are building an automated script, the only option is to automate the Turnstile CAPTCHA interaction in a human-like way. Now, that is particularly challenging as Turnstile relies on behind-the-scenes behavioral analysis and other proprietary checks. That is how it manages to verify you are human with a single click.
Mode #2: Automated Human Verification Challenge
In this mode, Cloudflare only issues a challenge if it suspects a request might be from a bot. It does this by presenting a JavaScript challenge, which runs invisibly in the browser to verify that the client behaves like a legitimate user:
This process is seamless and usually completes automatically if you are a human using a regular browser. If you pass, you can continue navigating the site without interruption. Since this causes minimal disruption for regular users, it is by far the most common Cloudflare mode.
However, if the JavaScript challenge fails (meaning Cloudflare concludes the client is likely to be a bot), it will escalate to showing a Turnstile CAPTCHA for human verification:
Now, you are back to what you saw in the previous scenario. In this mode, using a bot that presents human-like fingerprints may be enough to pass the initial verification, avoiding the Turnstile CAPTCHA altogether. Still, if it does appear, you need a way to deal with it.
How Cloudflare Works in Detail from a Technical Point of View
Try opening the NopeCHA Cloudflare test page in incognito mode using your browser. This page is protected by the Cloudflare WAF, so the automated JavaScript-based verification process will immediately begin.
In the background, a series of POST requests are exchanged with Cloudflare’s endpoints, transmitting encrypted data within their payloads:
The exact contents of these payloads are not publicly documented. Yet, based on Cloudflare’s known detection strategies, it is reasonable to assume they include several types of browser and system fingerprints.
Since your browser and hardware configuration are legitimate, this challenge should pass automatically. Otherwise, perform the required user interaction (i.e., clicking the checkbox).
Once the verification succeeds, the Cloudflare server issues a cf_clearance cookie, which indicates that this specific user session is allowed to access the website:
In this case, the cookie is valid for 15 days. This means it could theoretically be reused by an automated bot for a couple of weeks to access the target site without having to solve the verification process again.
What Happens When You Try to Connect to a Cloudflare-Protected Site
Now, let’s take a look at what actually happens when an automated bot tries to visit a page protected by Cloudflare.
Note: The sample scripts below will be written in Python, but the same principles apply regardless of the programming language, HTTP client, or browser automation tool you choose.
For this demonstration, we will use the Cloudflare challenge page from ScrapingCourse:
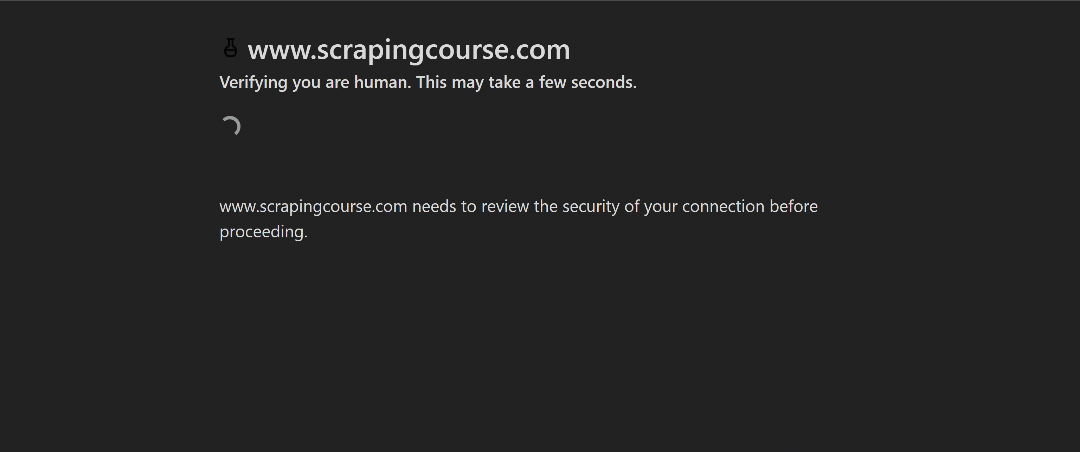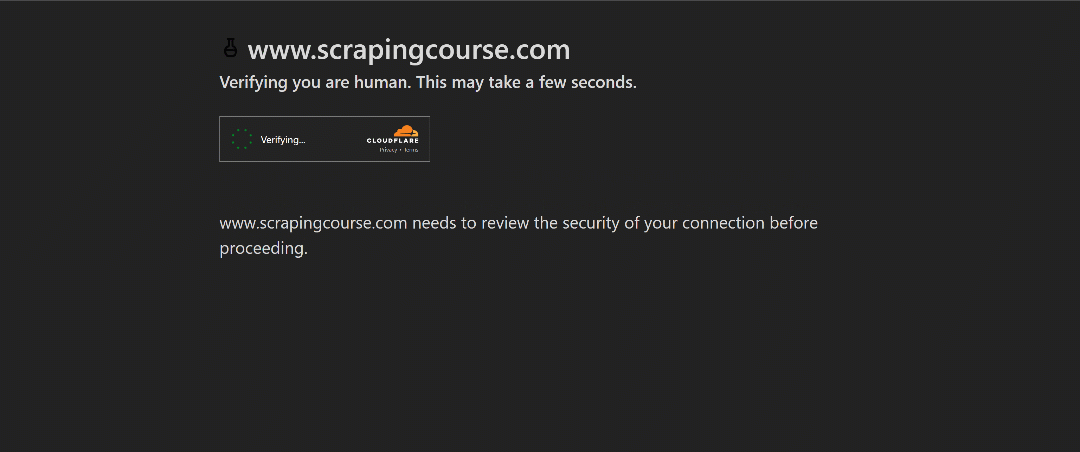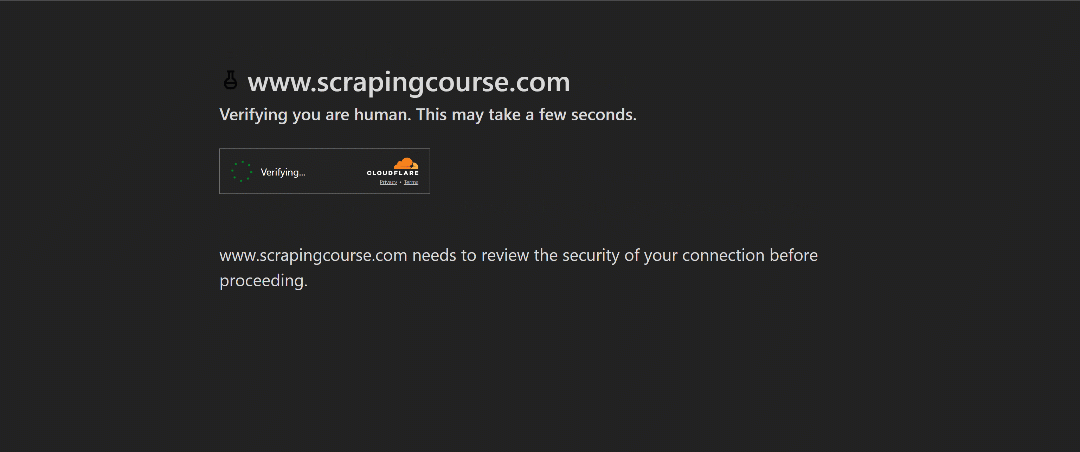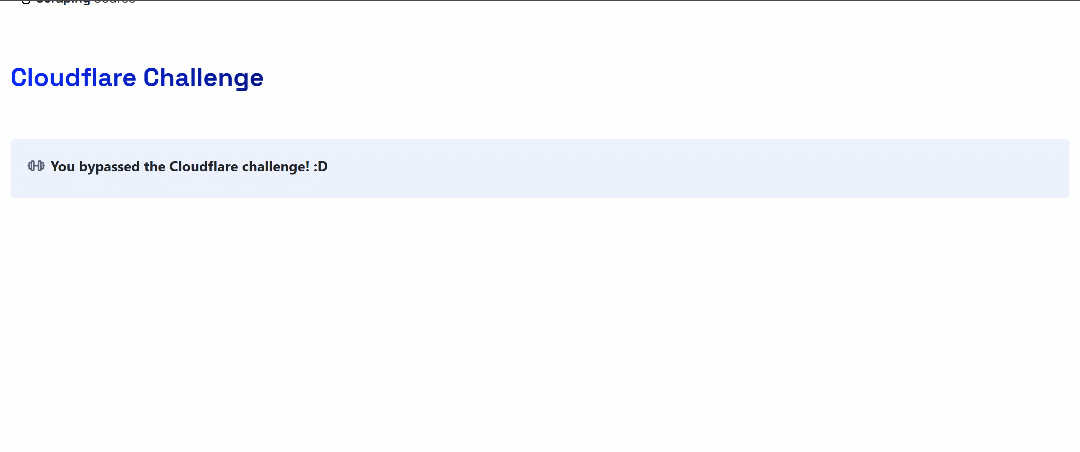
This is a site that requires passing Cloudflare’s verification. Once the challenge is successfully solved, it displays the following page:
In the following examples, we will specifically check whether the retrieved page content includes the string:
"You bypassed the Cloudflare challenge! :D"
This will confirm that the verification process was successfully completed.
As a basic test, we will see what occurs when visiting the Cloudflare-protected page above using two different approaches:
- With an HTTP client like Requests
- With a browser automation tool like Playwright
Targeting Cloudflare-Protected Pages with Requests
Check whether Requests can automatically bypass Cloudflare’s human verification with:
# pip install requests
import requests
# Connect to the target page
response = requests.get(
"https://www.scrapingcourse.com/cloudflare-challenge"
)
# Raise exceptions in case of HTTP error status codes
response.raise_for_status()
# Verify if you received the success page
html = response.text
print("Cloudflare Bypassed:", "You bypassed the Cloudflare challenge! :D" in html)
Note that the script will not even reach the final print() statement. Instead, it will fail with:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://www.scrapingcourse.com/cloudflare-challenge
As you can see, Cloudflare recognized the request as coming from an automated script and blocked it with a 403 Forbidden response.
Visiting Cloudflare-Protected Pages with Playwright
Let’s now try with a browser automation solution like Playwright:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Go to the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# Wait for the desired text to be on the page
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)
This script instructs a Chromium browser to visit the target page. It then uses a locator to check whether an element containing the required text appears on the page, automatically waiting for it (by default, Playwright waits up to 30 seconds).
Run the necessary installation commands and execute the script above. You will see the following output:
Cloudflare Bypassed: False
If you run it in headed mode (headless=False), you’ll notice that the script gets stuck on the Cloudflare verification page. This will show a Turnstile CAPTCHA and waits for it to be manually solved:
Note: If you tried to automate clicking the Turnstile checkbox, the verification would fail. That is because Cloudflare is smart enough to detect that it is automated and not a real human interaction.
High-Level Approaches to Bypassing Cloudflare
Explore three approaches you can use to bypass Cloudflare protection with your automated script.
Approach #1: Bypass Cloudflare Entirely
Do not forget that Cloudflare acts as a CDN, which means it caches and distributes site content across multiple geographically dispersed servers. So, sites distributed via Cloudflare are typically only accessible through servers in the CDN network.
Now, imagine if you managed to discover the IP address of the site server behind the CDN. The consequence would be that you could interact with the site while bypassing Cloudflare entirely. After all, Cloudflare can only evaluate requests that pass through its network.
That is possible by looking at DNS history lookup tools like SecurityTrails to identify any historical DNS records that reveal the original server’s IP address. Once you obtain the IP, you can attempt to send requests directly to the server, eluding Cloudflare.
The problem is that the server may have additional configurations in place to accept requests only from Cloudflare’s IP range. That would make it nearly impossible to connect to the site directly without being blocked. Additionally, successfully finding the original server IP is quite difficult and unlikely.
Approach #2: Rely on a Cloudflare Solver
Online, you can find several free and open-source libraries designed to bypass Cloudflare. Some of the most popular ones include:
- cloudscraper: A Python module that handles Cloudflare’s anti-bot challenges.
- Cfscrape: A lightweight PHP module to bypass Cloudflare’s anti-bot pages.
- Humanoid: A Node.js package to bypass Cloudflare’s anti-bot JavaScript challenges.
Not surprisingly, most of these projects have not received updates in years. The reason is that developers gave up due to the ongoing struggle to keep up with Cloudflare’s updates. So, these tools generally do not work for long.
Approach #3: Use an Automation Solution with Cloudflare Bypass Capabilities
In most cases, the best solution for scraping a Cloudflare-protected site is to use an all-in-one automation solution. To be effective, these libraries or online services need to offer at least the following features:
- JavaScript rendering, so that Cloudflare’s JavaScript challenges can be executed properly.
- TLS, HTTP header, and browser fingerprint spoofing to simulate real users and avoid detection.
- Turnstile CAPTCHA solving capabilities, to handle Cloudflare’s human verification when it appears.
- Simulated human-like interaction, such as moving the mouse along a B-spline curve to mimic natural user behavior.
Additionally, premium solutions often include an integrated proxy network to rotate IP addresses and reduce the risk of getting blocked.
In the following two chapters, you will see both open-source and primarily premium solutions in action!
How to Bypass Cloudflare Human Check in Python
Most open-source solutions that claim to bypass Cloudflare only manage to do so for a limited period of time. This is because it is essentially a cat-and-mouse game, and their open-source nature (where Cloudflare engineers can easily study their code) does not help.
So, it is no surprise that many tools that once worked (like Puppeteer Stealth) no longer achieve the goal. Still, at the time of writing, there are two solutions that actually manage to bypass Cloudflare’s protections:
- Camoufox: An open-source, anti-detect Python browser based on a customized Firefox build, designed to evade bot detection and enable web scraping.
- SeleniumBase: An open-source, professional-grade Python toolkit for advanced web automation.
Let’s see how both perform against the Cloudflare challenge page from ScrapingCourse!
Bypass Clouflare Turnstile with Camoufox
First, install Camoufox in your Python project with:
pip install camoufox[geoip]
Then, retrieve the required extra dependencies with:
python -m camoufox fetch
For more information, refer to the official installation guide.
The Camoufox Python library is built on top of Playwright, so its API is very similar. Visit the target site, wait for the Turnstile challenge to appear, and handle it (if it actually shows up) using the following logic:
# pip install camoufox[geoip]
# python -m camoufox fetch
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
with Camoufox(
headless=False,
humanize=True,
window=(1280, 720) # So that the Turnstile checkbox is on coordinate (210, 290)
) as browser:
page = browser.new_page()
# Visit the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
# Wait for the Cloudflare Turnstile to appear and load
page.wait_for_load_state(state="domcontentloaded")
page.wait_for_load_state("networkidle")
page.wait_for_timeout(5000) # 5 seconds
# Ckick the Turnstile checkbox (if it is present)
page.mouse.click(210, 290)
try:
# Wait for the desired text to appear
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
# The text did not appear
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)
Notice that the Turnstile handling logic is a bit tricky. It relies on the assumption that the Turnstile checkbox will appear at approximately the (210, 290) coordinate on a 1280×720 browser window.
Run the script above, and you will get the following result:
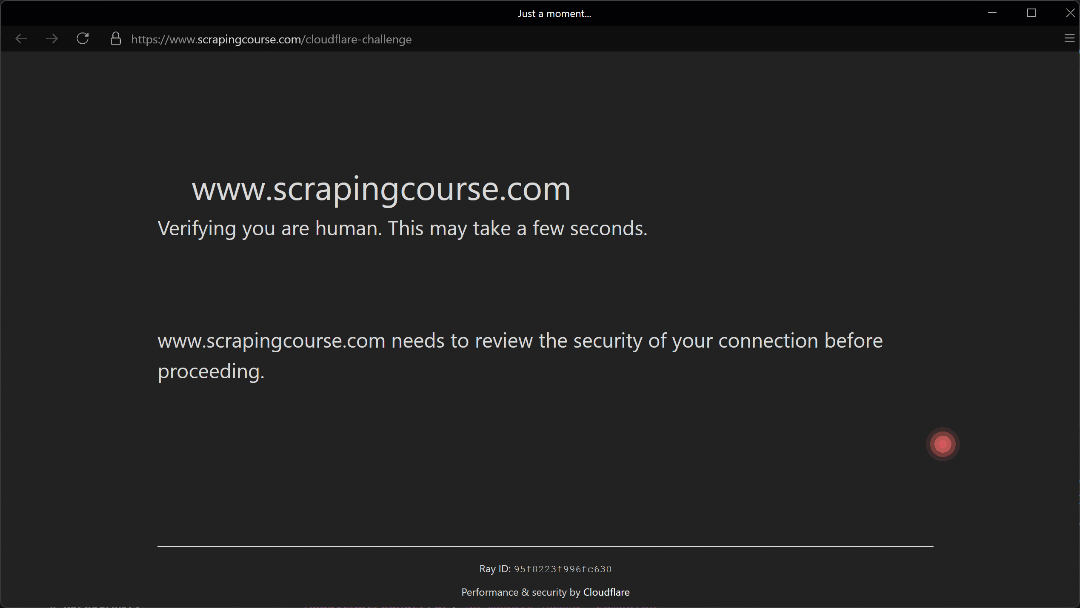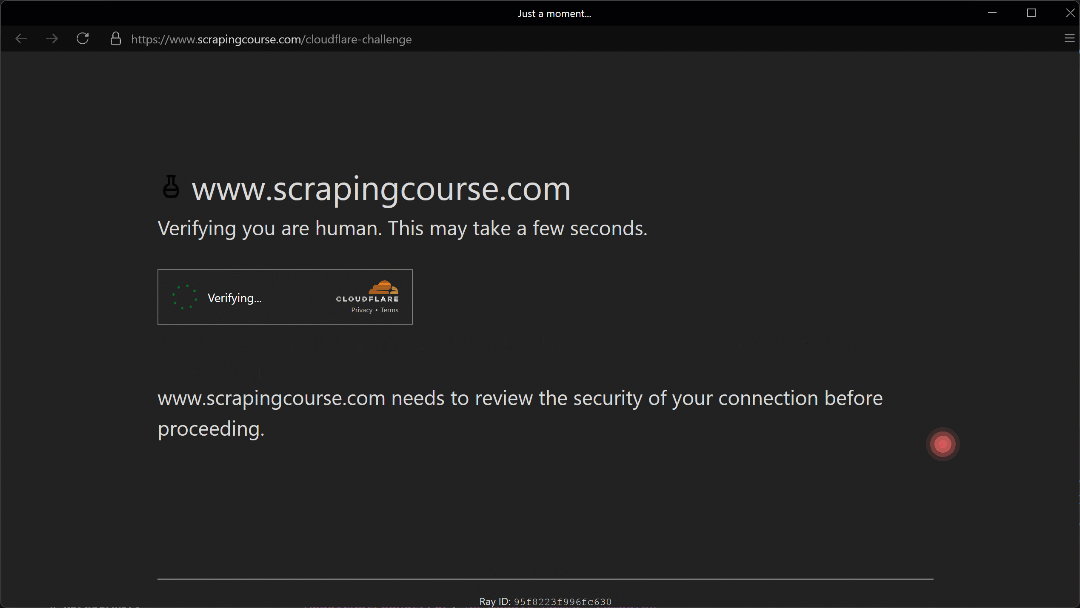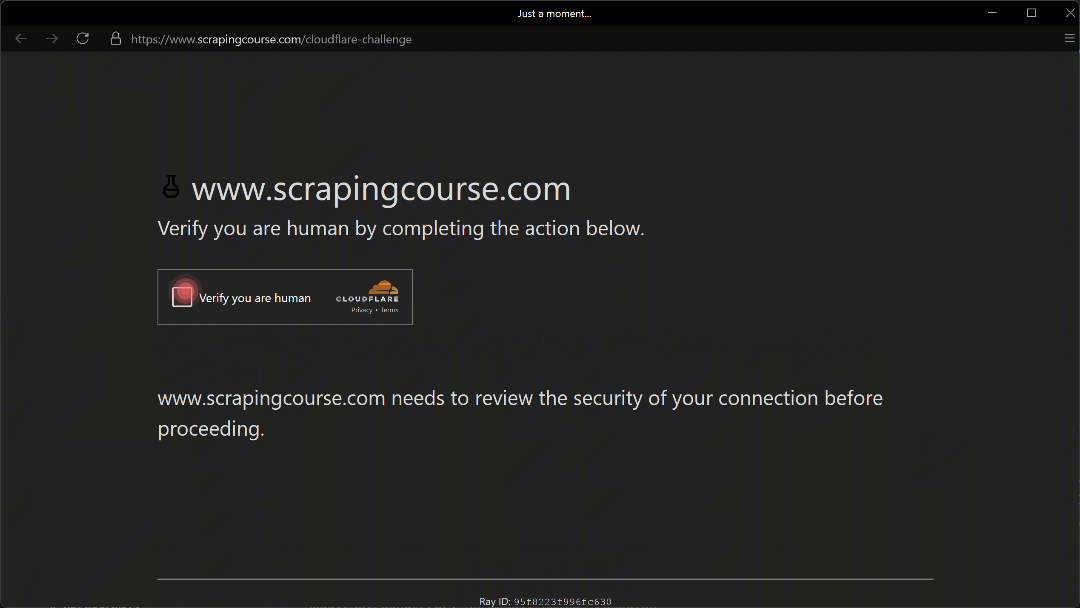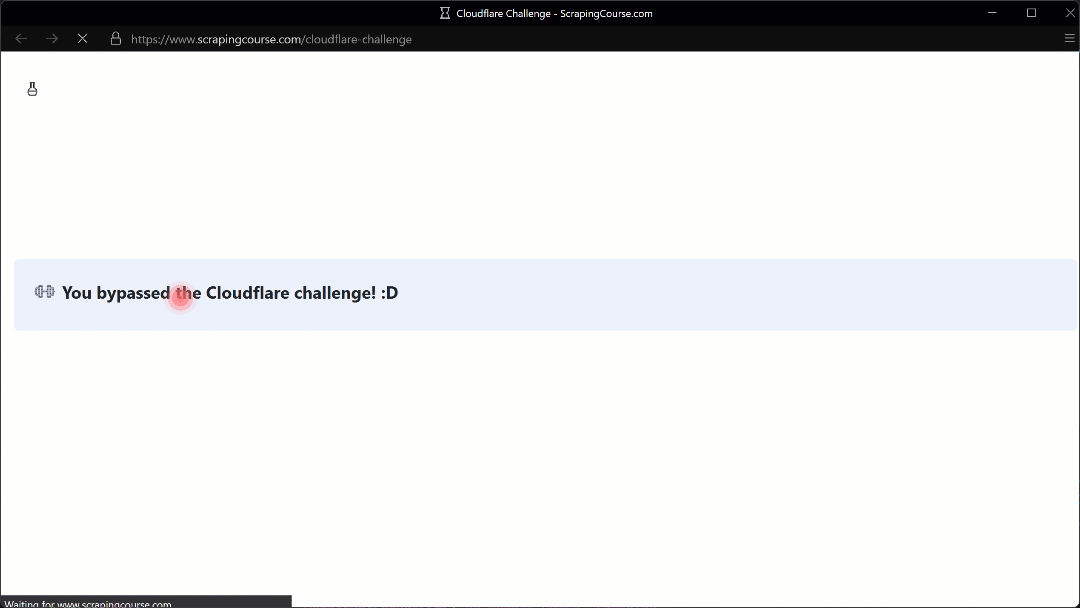
The automated mouse movement toward the (210, 290) coordinate appears realistic thanks to the Humanize=True parameter.
As shown here, Camoufox successfully manages to click the checkbox. As a result, in the terminal, you will see this output:
Cloudflare Bypassed: True
Mission complete!
Avoid Clouflare with SeleniumBase
Install SeleniumBase with:
pip install seleniumbase
Then, use it to handle Cloudflare with:
# pip install seleniumbase
from seleniumbase import Driver
from seleniumbase.common.exceptions import TextNotVisibleException
# Launch in undetected-chromedriver mode
driver = Driver(uc=True)
# Visit the target page
url = "https://www.scrapingcourse.com/cloudflare-challenge"
driver.uc_open_with_reconnect(url, 4)
# Click the Turnstile (if it is present) and reload the page
driver.uc_gui_click_captcha()
try:
# Wait for the desired text to appear
driver.wait_for_text("You bypassed the Cloudflare challenge! :D", "main")
challenge_bypassed = True
except TextNotVisibleException:
# The text did not appear
challenge_bypassed = False
# Close the browser and release its resources
driver.quit()
print("Cloudflare Bypassed:", challenge_bypassed)
In uc=True mode (which uses undetected-chromedriver under the hood), SeleniumBase can take advantage of the dedicated uc_gui_click_captcha() method to handle the Turnstile CAPTCHA—if it appears. This means there is no need for custom click logic this time.
Run the script and you should see:
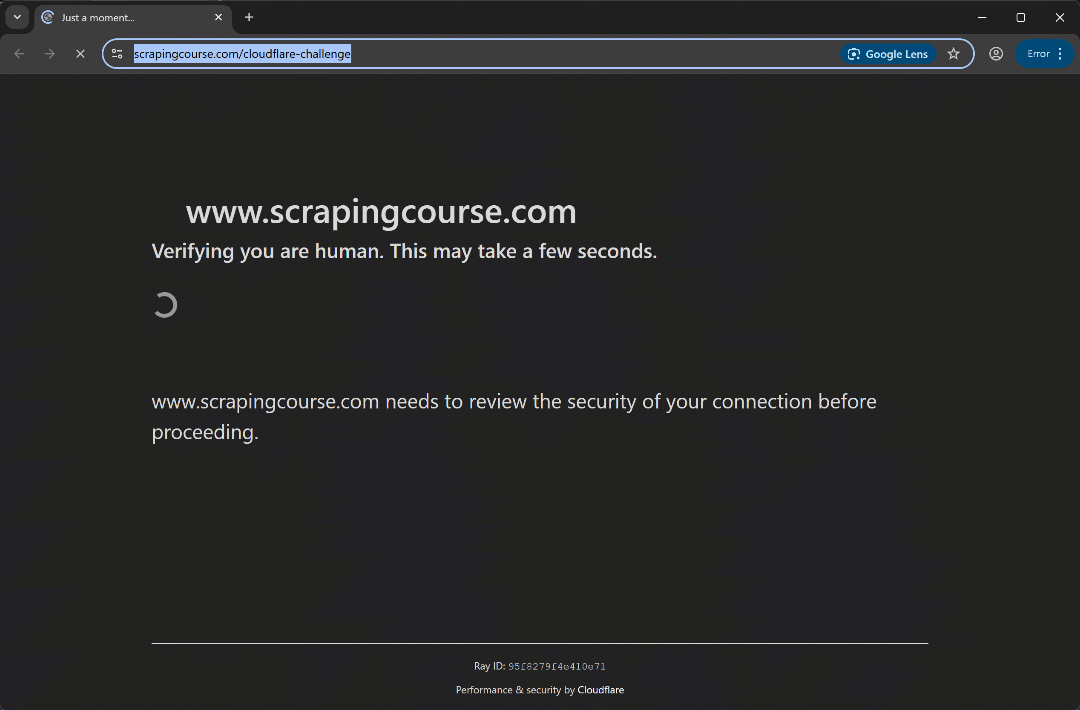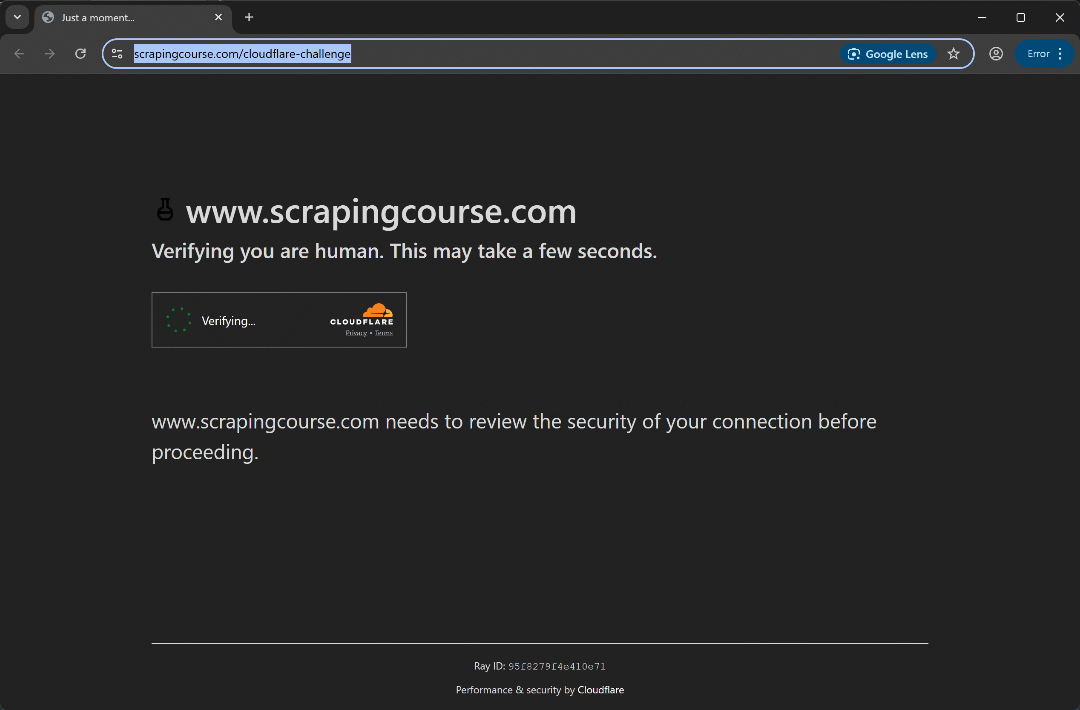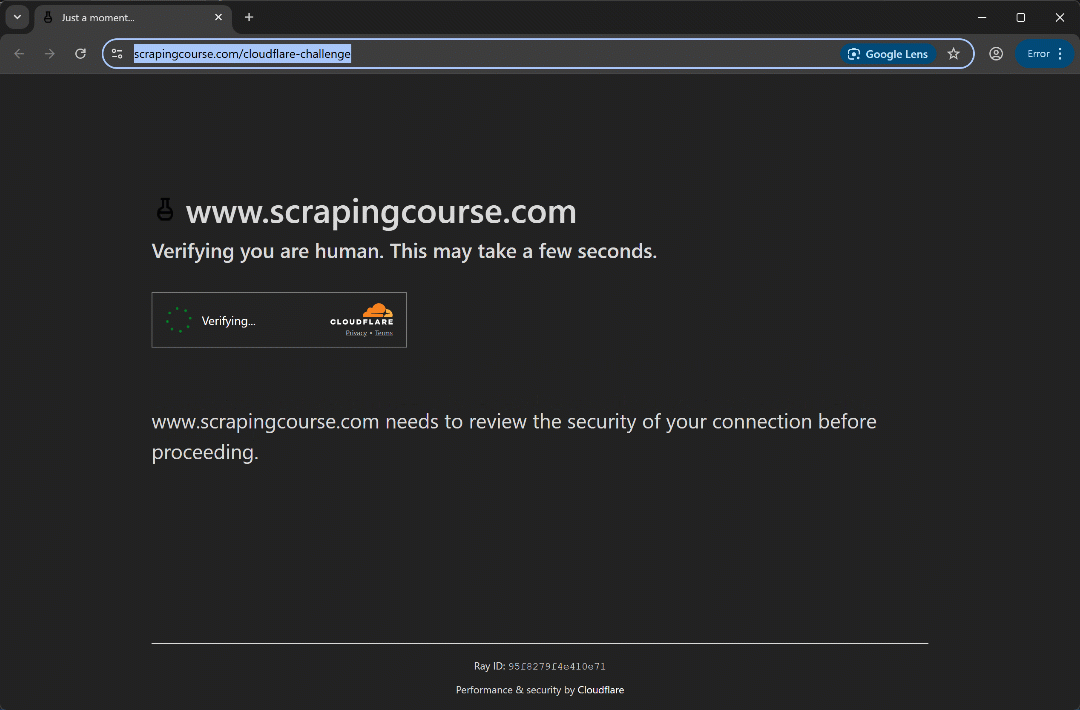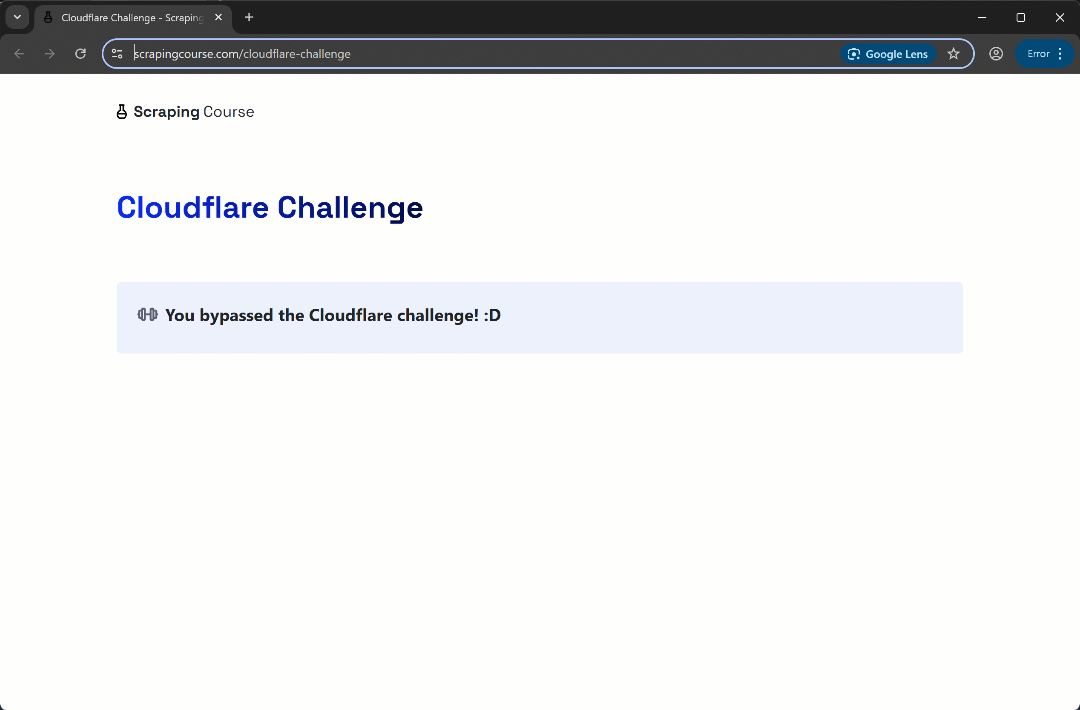
This time, the automation script bypasses the initial verification phase without even triggering the Turnstile CAPTCHA. Either way, the uc_gui_click_captcha() method would have been able to handle it successfully. This is possible thanks to UC mode, which you can learn more about in our SeleniumBase scraping guide.
Et voilà! Cloudflare bypassed once again.
How to Bypass Cloudflare at Scale
The two libraries presented earlier work well for simple automation scripts but have three major drawbacks:
- To achieve a high percentage of effective results, they need to run browsers in headed mode. This consumes a lot system resources and makes scalability more challenging.
- They are inconsistent and may stop working temporarily if Cloudflare updates its detection logic. Since these solutions are community-maintained, updates can take days or even weeks to be released.
- There is no official support. You must rely on online resources and community help.
For these reasons, open-source libraries with Cloudflare bypass capabilities are not recommended for production projects. For more scalable, consistent results—and the backing of a dedicated 24/7 support team—you need premium products like those provided by Bright Data.
Specifically, here, we will focus on the following two solutions:
- Web Unlocker: An all-in-one scraping endpoint that includes all anti-bot bypass capabilities to retrieve HTML from any site.
- Browser API: An infinitely scalable cloud browser built to support any automation workflow. It integrates with Puppeteer, Selenium, Playwright, and any other browser automation tool. It includes advanced fingerprint management, built-in CAPTCHA solving, and automated proxy rotation.
See how to integrate these tools in Python (though they support any programming language) in your automation scripts!
Bypassing Cloudflare With Web Unlocker
Before getting started, follow the official guide to set up Web Unlocker for free in your Bright Data account. You will also need to generate a Bright Data API key for authenticating your requests to the Web Unlocker endpoint.
Here, we will assume that the name of your Web Unlocker zone is web_unlocker.
Once you have completed the above steps, test Web Unlocker against the target page used in this article:
# pip install requests
import requests
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
data = {
"zone": "web_unlocker", # Replace with the name of your Web Unlocker zone
"url": "https://www.scrapingcourse.com/cloudflare-challenge",
"format": "raw"
}
# Perform a request to the Web Unlocker endpoint
response = requests.post(
"https://api.brightdata.com/request",
json=data,
headers=headers
)
# Get the response and check if Cloudflare was bypassed
html = response.text
print("Cloudflare Bypassed:", "You bypassed the Cloudflare challenge! :D" in html)
Web Unlocker will return the HTML content of the page behind the Cloudflare verification wall. In particular, the html variable will contain content like this:
<!doctype html>
<html lang="en"><head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Cloudflare Challenge - ScrapingCourse.com</title>
<!-- omitted for brevity ... -->
<main class="page-content py-4" id="main-content" data-testid="main-content" data-content="main">
<div class="container" id="content-container" data-testid="content-container" data-content="container">
<div class="cloudflareChallenge">
<h1 id="page-title" class="page-title text-4xl font-bold mb-2 text-left gradient-text highlight gradient-text leading-10" data-testid="page-title" data-content="title">
Cloudflare Challenge
</h1>
<div class="challenge-info bg-[#EDF1FD] rounded-md p-4 mb-8 mt-5" id="challenge-info" data-testid="challenge-info" data-content="challenge-info">
<div class="info-header flex items-center gap-2 pb-2" id="info-header" data-testid="info-header" data-content="info-header">
<img width="25" height="15" src="https://www.scrapingcourse.com/assets/images/challenge.svg" data-testid="challenge-image" data-content="challenge-image">
<h2 class="challenge-title text-xl font-bold" id="challenge-title" data-testid="challenge-title" data-content="challenge-title">
You bypassed the Cloudflare challenge! 😀
</h2>
</div>
</div>
</div>
</div>
</main>
<!-- omitted for brevity ... -->
</html>
This is exactly the HTML content of the page behind the Cloudflare human verification wall. Therefore, it is no surprise that the script’s output will be:
Cloudflare Bypassed: True
Note that you will only be charged for successful requests, and a free trial is available!
Automating Cloudflare with Browser API
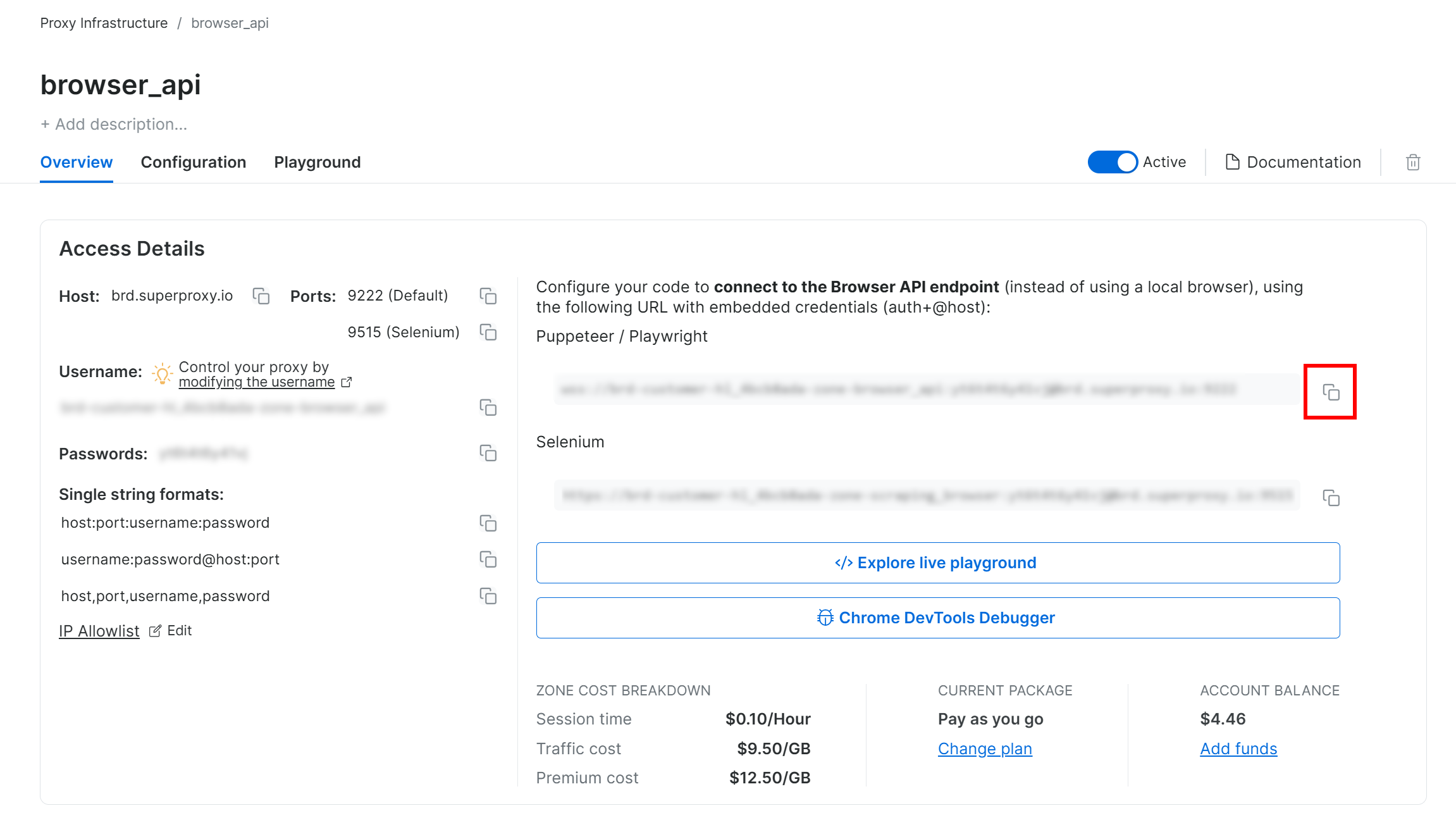
As a prerequisite, set up a Browser API product in your Bright Data account. On the zone page, copy the Playwright CDP connection URL:
This URL contains your credentials and allows you to instruct any browser automation solution that supports remote CDP (Chrome DevTools Protocol) to connect to the Bright Data Browser API. In other words, your automation tool will operate on a remotely hosted browser instance managed by Bright Data. That means scalability and browser maintenance are handled for you.
Extend the Playwright script shown earlier to connect to the Browser API via the CDP URL:
# pip install playwright
# python install -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
BRIGHT_DATA_API_CDP_URL = "<YOUR_BRIGHT_DATA_API_CDP_URL>" # Replace with your Browser API Playwright CDP URL
with sync_playwright() as p:
# Connect to the remote Browser API
browser = p.chromium.connect_over_cdp(BRIGHT_DATA_API_CDP_URL)
page = browser.new_page()
# Go to the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# Wait for the desired text to be on the page
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)
This time, the script will successfully bypass the Cloudflare verification thanks to the Browser API’s advanced capabilities. You will see the following output in the terminal:
Cloudflare Bypassed: True
Well done! Cloudflare bypass is no longer a problem.
Conclusion
In this article, you learned how Cloudflare works and explored practical solutions to bypass it in your automation workflows. As you have seen here, bypassing Cloudflare’s anti-scraping measures is challenging, but certainly possible.
No matter which approach you choose, everything becomes easier with professional, fast, and reliable solutions like:
- Web Unlocker: An endpoint that automatically bypasses rate limiting, fingerprinting, and other anti-bot restrictions for you.
- Browser API: A fully hosted browser that allows you to automate the interaction with any web page.
Sign up now for free and find out which of Bright Data’s solutions best suits your needs!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.


