

In this guide, you will learn:
- What Agno is and why it is an excellent choice for building agentic workflows.
- Why web scraping plays such a valuable role in AI agents.
- How to integrate Agno with its built-in Bright Data tools to create a web scraping agent.
Let’s dive in!
What Is Agno?
Agno is a full-stack Python framework for building multi-agent systems that leverage memory, knowledge, and advanced reasoning. It enables the creation of sophisticated AI agents for a wide range of use cases. These span from simple tool-using agents to collaborative agent teams with state and determinism.
Agno is model-agnostic, highly performant, and puts reasoning at the center of its design. It supports multi-modal inputs and outputs, complex multi-agent orchestration, built-in agentic search with vector databases, and complete memory/session handling.
As of this writing, Agno is one of the most popular open-source libraries for building AI agents, boasting over 29k stars on GitHub:
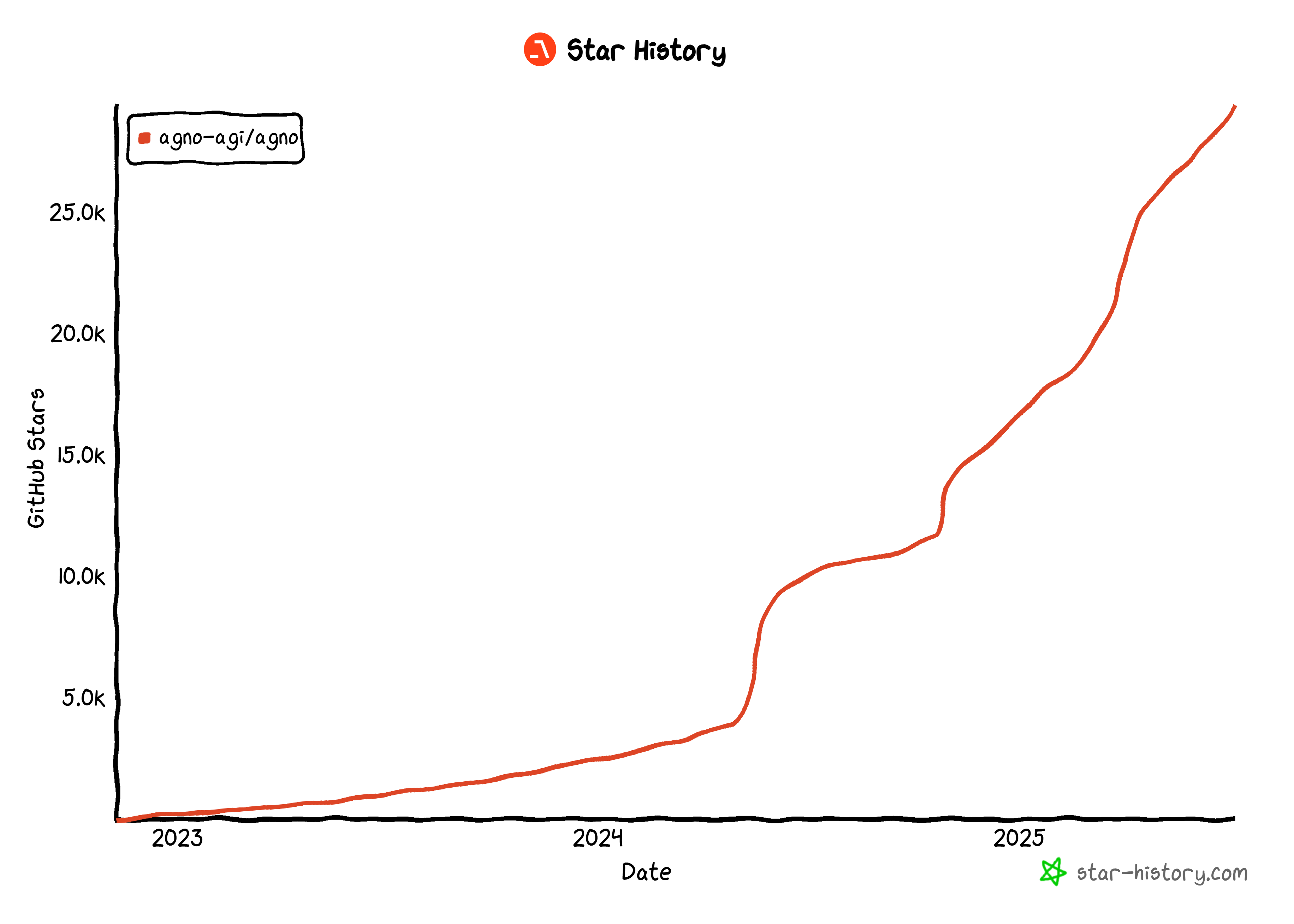
Its rapid rise highlights just how quickly Agno is gaining traction in the developer and AI community.
Why Agentic Web Scraping Is So Useful
Traditional web scraping relies on writing rigid data parsing rules to extract data from specific web pages. The problem? Sites frequently change their structure, which means you constantly have to update your scraping logic. That leads to high maintenance costs and fragile pipelines.
That is why AI web scraping is gaining support. Instead of crafting custom parsing scripts, you can use an AI model to extract data directly from the HTML of a web page with just a simple prompt. This approach is so popular that many AI scraping tools have emerged recently.
Still, AI web scraping becomes even more powerful when embedded into an agentic AI architecture. In particular, you can build a dedicated web scraping agent that other AI agents can connect to. That is possible in multi-agent workflows or via AI protocols like Google’s A2A.
Agno makes all of the above possible. It lets you build standalone AI scraping agents or complex multi-agent ecosystems. However, regular LLMs are not designed for proficient web scraping. They often fail to connect to sites with strong bot defenses—or worse, they might “hallucinate” and return fake data.
To address those limitations, Agno natively integrates with Bright Data via dedicated scraping tools. With these tools, your AI agent can scrape fresh, structured data from any website.
To avoid blocks and disruptions, Bright Data overcomes challenges like TLS fingerprinting, browser and device fingerprinting, CAPTCHAs, Cloudflare protections, and more for you. Once the data is retrieved, it is fed into the LLM for interpretation and analysis, following your original task instructions.
Explore how to integrate Bright Data tools into an Agno agent for next-level web scraping!
How to Integrate Bright Data Tools for Web Scraping in Agno
In this step-by-step section, you will see how to use Agno to build a web scraping AI agent. By integrating the Bright Data tools, you will give your Agno agent the ability to scrape data from any web page.
Follow the instructions below to create your Bright Data-powered scraping agent in Agno!
Prerequisites
To follow this tutorial, make sure you have the following:
- Python 3.7 or higher installed locally (we recommend using the latest version).
- A Bright Data API key.
- An API key for a supported LLM provider (here, we will use Gemini because it is free to use via API—but any supported LLM provider will do).
Do not worry if you do not have a Bright Data API key or Gemini API key yet. We will walk you through how to create them in the next steps.
Step #1: Project Setup
Open a terminal and create a new directory for your Agno AI agent project, which will use Bright Data for web scraping:
mkdir agno-web-scraperThe agno-web-scraper folder will hold all the Python code for your scraping Agno agent.
Next, navigate into the project directory and set up a virtual environment inside it:
cd agno-web-scraper
python -m venv venvNow, load the project in your favorite Python IDE. We recommend Visual Studio Code with the Python extension or PyCharm Community Edition.
Inside the project folder, create a new file named scraper.py. Your directory structure should look like this:
agno-web-scraper/
├── venv/
└── scraper.pyActivate the virtual environment in your terminal. In Linux or macOS, execute:
source venv/bin/activateEquivalently, on Windows, launch this command:
venv/Scripts/activateIn the next steps, you will be guided through installing the required Python packages. If you prefer to install everything now, in the activated virtual environment, run:
pip install agno python-dotenv google-genai requestsNote: We are installing google-genai because this tutorial uses Gemini as the LLM provider. If you plan to use a different LLM, be sure to install the appropriate library for that provider.
You are all set! You now have a Python development environment ready to build a scraping agentic workflow using Agno and Bright Data.
Step #2: Configure Environment Variables Reading
Your Agno scraping agent will connect to third-party services like Bright Data and Gemini through API integrations. To keep things secure, avoid hardcoding your API keys directly into your Python code. Instead, store them as environment variables.
To make loading environment variables easier, adopt the python-dotenv library. With your virtual environment activated, install it by running:
pip install python-dotenvNext, in your scraper.py file, import the library and call load_dotenv() to load your environment variables:
from dotenv import load_dotenv
load_dotenv()This function allows your script to read variables from a local .env file. Go ahead, and create a .env file in the root of your project directory:
agno-web-scraper/
├── venv/
├── .env # <-----------
└── scraper.pyWonderful! You are now set up to securely handle your integration secrets using environment variables.
Step #3: Set Up Bright Data
The Bright Data tools integrated into Agno give you access to several data collection solutions. In this tutorial, we will focus on integrating these two scraping-specific products:
- Web Unlocker API: An advanced scraping API that overcomes bot protections, providing access to any web page in Markdown format.
- Web Scraper APIs: Specialized endpoints for ethically extracting fresh, structured data from popular websites, such as LinkedIn, Amazon, and many others.
To use these tools, you need to:
- Set up the Web Unlocker solution in your Bright Data account.
- Get your Bright Data API token to authenticate requests to Web Unlocker and Web Scraper APIs.
Follow the instructions below to do this!
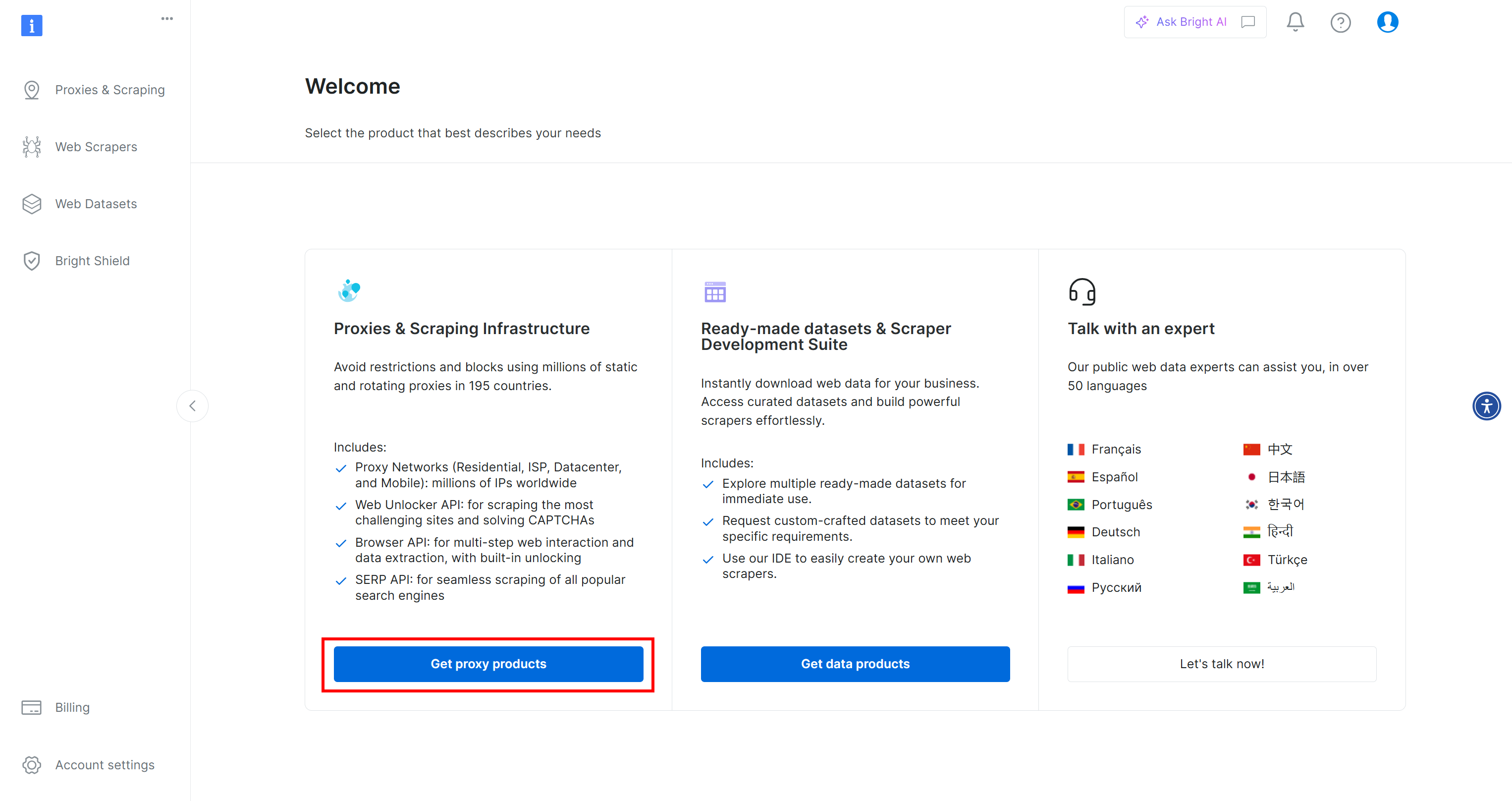
First, if you do not already have a Bright Data account, sign up for free. If you already do, log in and open your dashboard. Here, click the “Get proxy products” button:
You will be redirected to the “Proxies & Scraping Infrastructure” page:
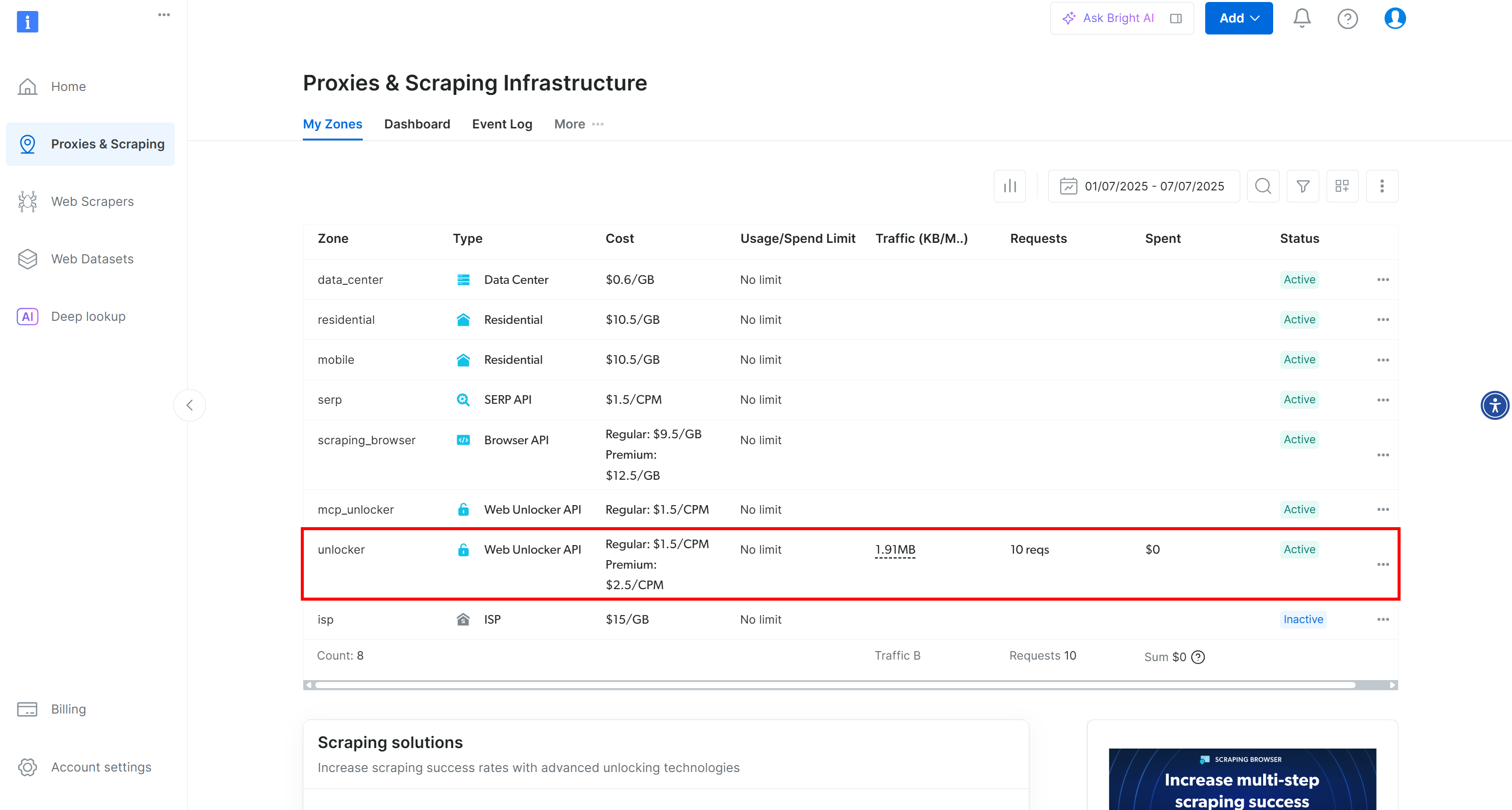
On this page, you will see already configured Bright Data solutions. In this example, a Web Unloker zone is activated. The name of that zone is “unblocker”(you will need this later when integrating it into your script).
If you do not already have a Web Unlocker zone, scroll down to the “Web Unlocker API” card and click “Create zone”:
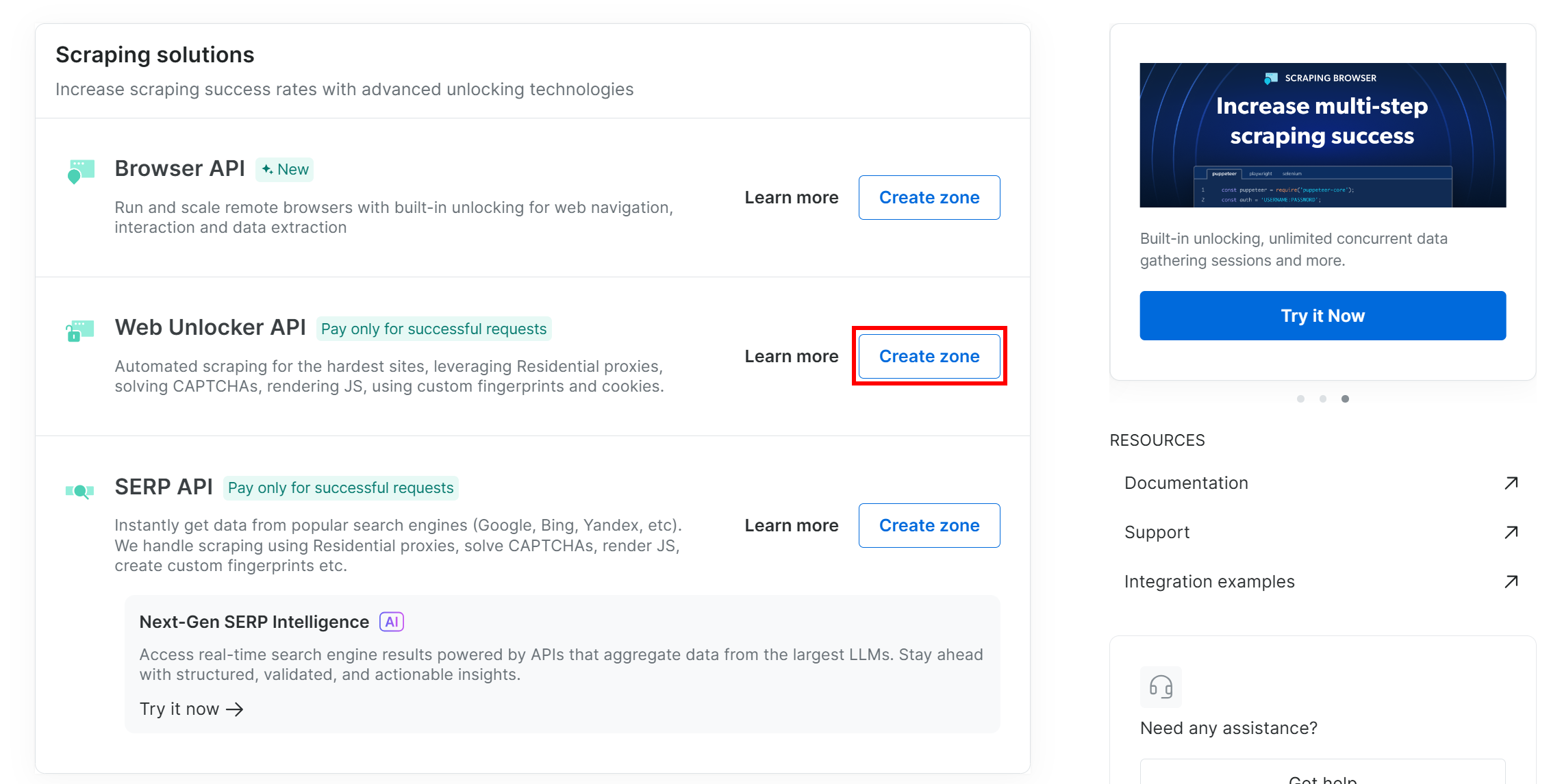
Give your zone a name (like “unlocker”), enable advanced features for best performance, and press the “Add” button:
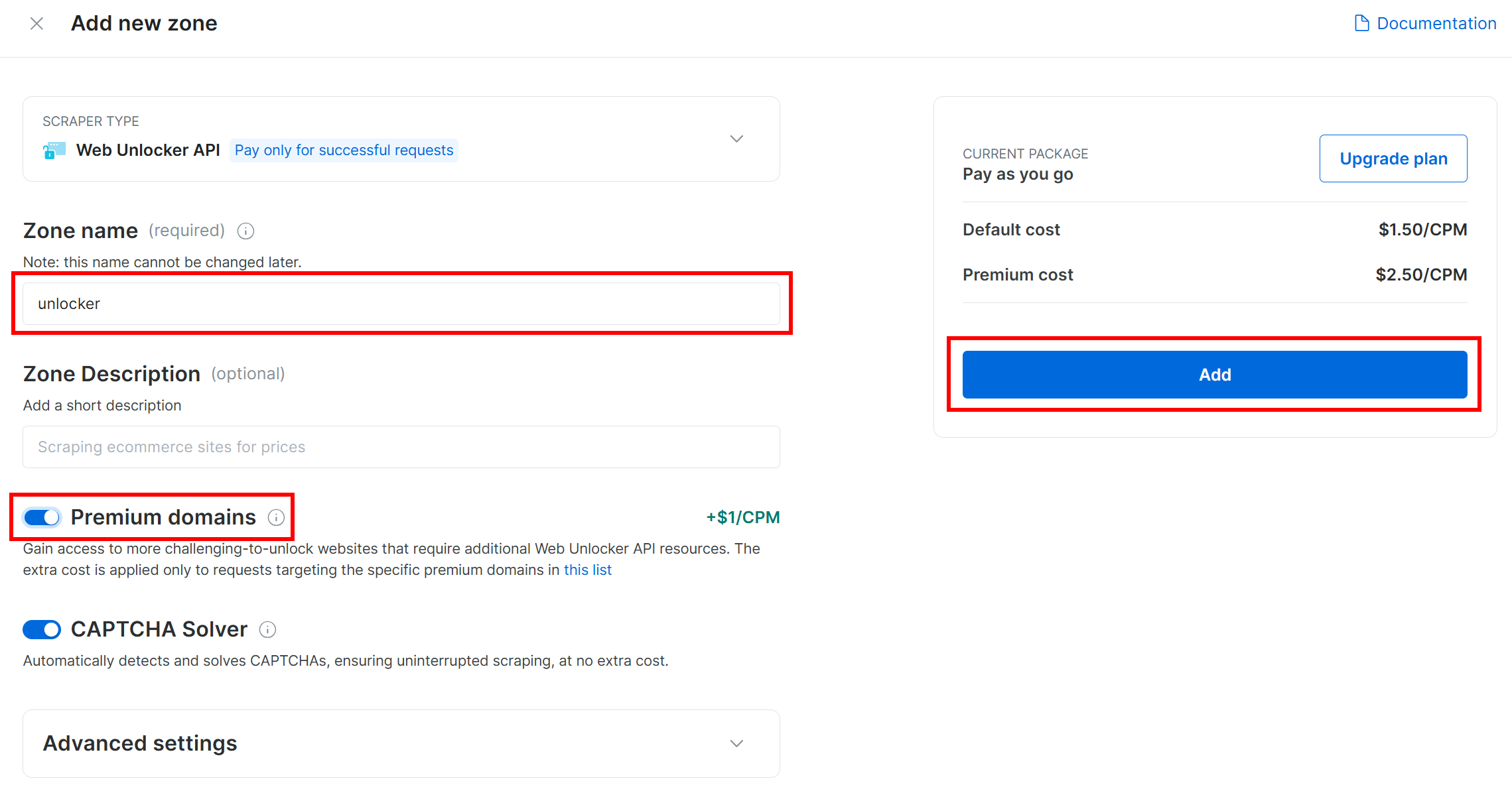
You will be taken to your new zone’s page. Make sure the toggle is set to the “Active” status, which confirms the product is ready to use:
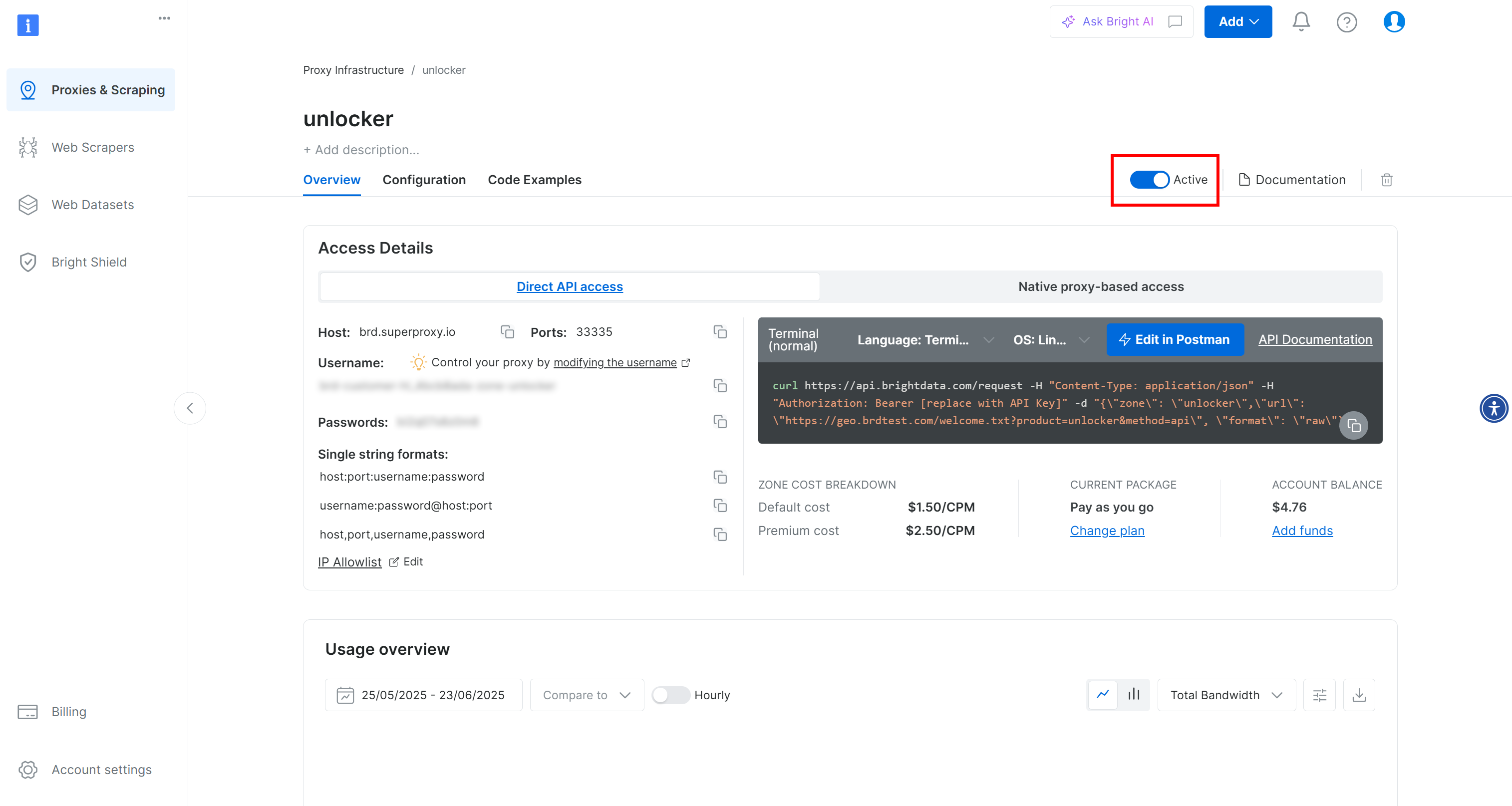
Now, follow the official Bright Data documentation to generate your API key. Once you have it, add it to your .env file like this:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Replace the <YOUR_BRIGHT_DATA_API_KEY> placeholder with your actual API key value.
Perfect! Time to integrate Bright Data tools into your Agno agent script for agentic web scraping.
Step #4: Integrate the Agno Bright Data Tools for Web Scraping
In your project folder, with the virtual environment activated, install Agno by running:
pip install agnoKeep in mind that the agno package already includes built-in support for Bright Data tools. So, you do not need any extra integration-specific packages.
The only additional package required is the Python Requests library, which Bright Data tools use to call the products you configured earlier via API. Install requests with:
pip install requestsIn your scraper.py file, import the Bright Data scraping tools from agno:
from agno.tools.brightdata import BrightDataToolsThen, initialize the tools like this:
bright_data_tools = BrightDataTools(
web_unlocker_zone="unlocker", # Replace with your Web Unlocker API zone name
search_engine=False,
)Replace "unlocker" with the actual name of your Bright Data Web Unlocker zone.
Also note that search_engine is set to False since we are not using the SERP API tool in this example, which focuses purely on web scraping.
Tip: Instead of hardcoding zone names, you can load them from your .env file. To do so, add this line to your .env file:
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>"Replace the placeholder with your real Web Unlocker zone name. Then, you can remove the web_unlocker_zone argument from BrightDataTools. The class will automatically pick up the zone name from your environment.
Note: To connect to Bright Data, BrightDataTools looks for your API key in the BRIGHT_DATA_API_KEY environment variable. That is why we added it to your .env file in the previous step.
Amazing! Integrate Gemini to power your Agno web scraping agentic workflow.
Step #5: Configure the LLM Model from Gemini
Time to connect to Gemini, the LLM provider chosen in this tutorial. Start by installing the google-genai package:
pip install google-genaiThen, import the Gemini integration class from Agno:
from agno.models.google import GeminiNow, initialize your LLM model like this:
llm_model = Gemini(id="gemini-2.5-flash")In the above snippet, gemini-2.5-flash is the name of the Gemini model you want your agent to utilize. Feel free to replace it with any other supported Gemini model (just keep in mind that some of them are not free to use via API).
Under the hood, the google-genai library expects your Gemini API key to be stored in an environment variable named GOOGLE_API_KEY. To set it up, add the following line to your .env file:
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"Replace the <YOUR_GOOGLE_API_KEY> placeholder with your actual API key. If you do not have one yet, follow the official guide to generate a Gemini API key.
Note: If you would like to connect to a different LLM provider, check the official documentation for setup instructions.
Fantastic! You now have all the core components you need to build your Agno scraping agent.
Step #6: Define the Scraping Agent
In your scraper.py file, set up your Agno scraping agent like this:
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)This creates an Agno Agent object that uses your configured LLM to process prompts and leverages the Bright Data tools for web scraping.
Do not forget to add this import at the top of your file:
from agno.agent import AgentTerrific! All that is left is to send a query to your agent and export the scraped data.
Step #7: Query the Agno Scraping Agent
Read the prompt from the CLI and pass it to your Agno scraping agent for execution:
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)The first line uses Python’s built-in input() function to read a prompt typed by the user. The prompt should describe the scraping task or question you want your agent to handle. The second line [calls run()] on the agent to process the prompt and execute the task](https://docs.agno.com/agents/run#running-your-agent).
To display the response nicely formatted in your terminal, use:
pprint_run_response(response)Import this helper function from Agno like so:
from agno.utils.pprint import pprint_run_responsepprint_run_response prints the AI agent’s response. But you probably also want to extract and save the raw scraped data returned by the Bright Data tool. Let’s handle that in the next step!
Step #8: Export the Scraped Data
When running a scraping task, your Agno web scraping agent calls the configured Bright Data tools behind the scenes. Making sure your script also exports the raw data returned by these tools adds a lot of value to your workflow. The reason is that you can reuse that data for other scenarios (e.g., data analysis) or additional agentic use cases.
Currenly, your scraping agent has access to these two tool methods from BrightDataTools:
scrape_as_markdown(): Scrapes any web page and returns the content in Markdown format.web_data_feed(): Retrieves structured JSON data from popular sites like LinkedIn, Amazon, Instagram, and more.
Thus, depending on the task, the scraped data output can be either in Markdown or JSON format. To handle both cases, you can read the raw output from the tool result at response.tools[0].result. Then, attempt to parse it as JSON. If that fails, you will treat the scraped data as Markdown.
Implement the above logic with these lines of code:
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data) Do not forget to import json from the Python Standard Library:
import jsonGreat! Your Agno web scraping agent workflow is now complete.
Step #9: Put It All Together
This is the final code of your scraper.py file:
from dotenv import load_dotenv
from agno.tools.brightdata import BrightDataTools
from agno.models.google import Gemini
from agno.agent import Agent
from agno.utils.pprint import pprint_run_response
import json
# Load the environment variables from the .env file
load_dotenv()
# Configure the Bright Data tools for Agno integration
bright_data_tools = BrightDataTools(
web_unlocker_zone="web_unlocker", # Replace with your Web Unlocker API zone name
search_engine=False, # As the SERP API tool is not required in this use case
)
# The LLM that will be used by the AI scraping agent
llm_model = Gemini(id="gemini-2.5-flash")
# Define your Agno agent with Bright Data tools
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)
# Print the agent response in the terminal
pprint_run_response(response)
# Export the scraped data
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data)In under 50 lines of code, you have built an AI-driven scraping workflow that can pull data from any web page. That is the power of combining Bright Data with Agno for agent development!
Step #10: Run Your Agno Scraping Agent
In your terminal, launch your Agno web scraping agent by running:
python scraper.pyYou will be prompted to enter a request. Try something like:
Give me a short summary from "https://finance.yahoo.com/sectors/technology/article/why-starlink-is-so-important-to-spacexs-ipo-174446711.html"The output will include:
- The original prompt you submitted.
- A log showing which Bright Data tool was used for scraping. In this case, it confirms that
scrape_as_markdown()was invoked. - A Markdown-formatted summary generated by Gemini, highlighted by a blue rectangle.
If you look inside your project’s root folder, you will see a new file named output.md. Open it in any Markdown viewer, and you will get a Markdown version of the scraped page content.
As you can tell, the Markdown output from Bright Data accurately captures the content of the original web page.
Now, try launching your scraping agent again with a different, more specific request:
Summarize the main features of the product on this Amazon page: "https://www.amazon.com/PlayStation%C2%AE5-console-slim-PlayStation-5/dp/B0CL61F39H/" This time, your output might look like this:
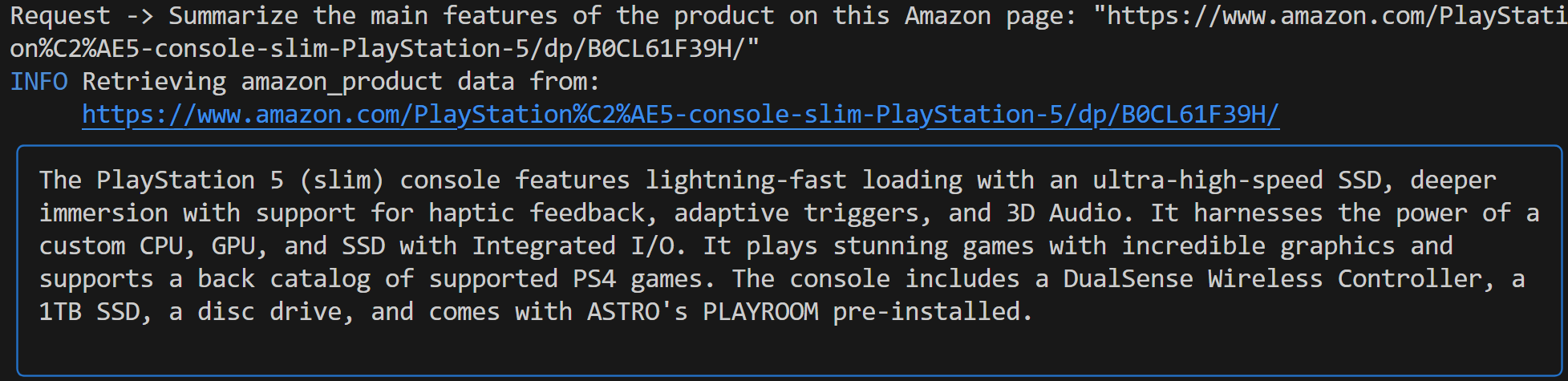
Notice how the Gemini-powered Agno agent automatically chose the web_data_feed tool, which is correctly configured for structured scraping of Amazon product pages.
As a result, you will now find an output.json file in your project folder. Open it and paste its contents into any JSON viewer:
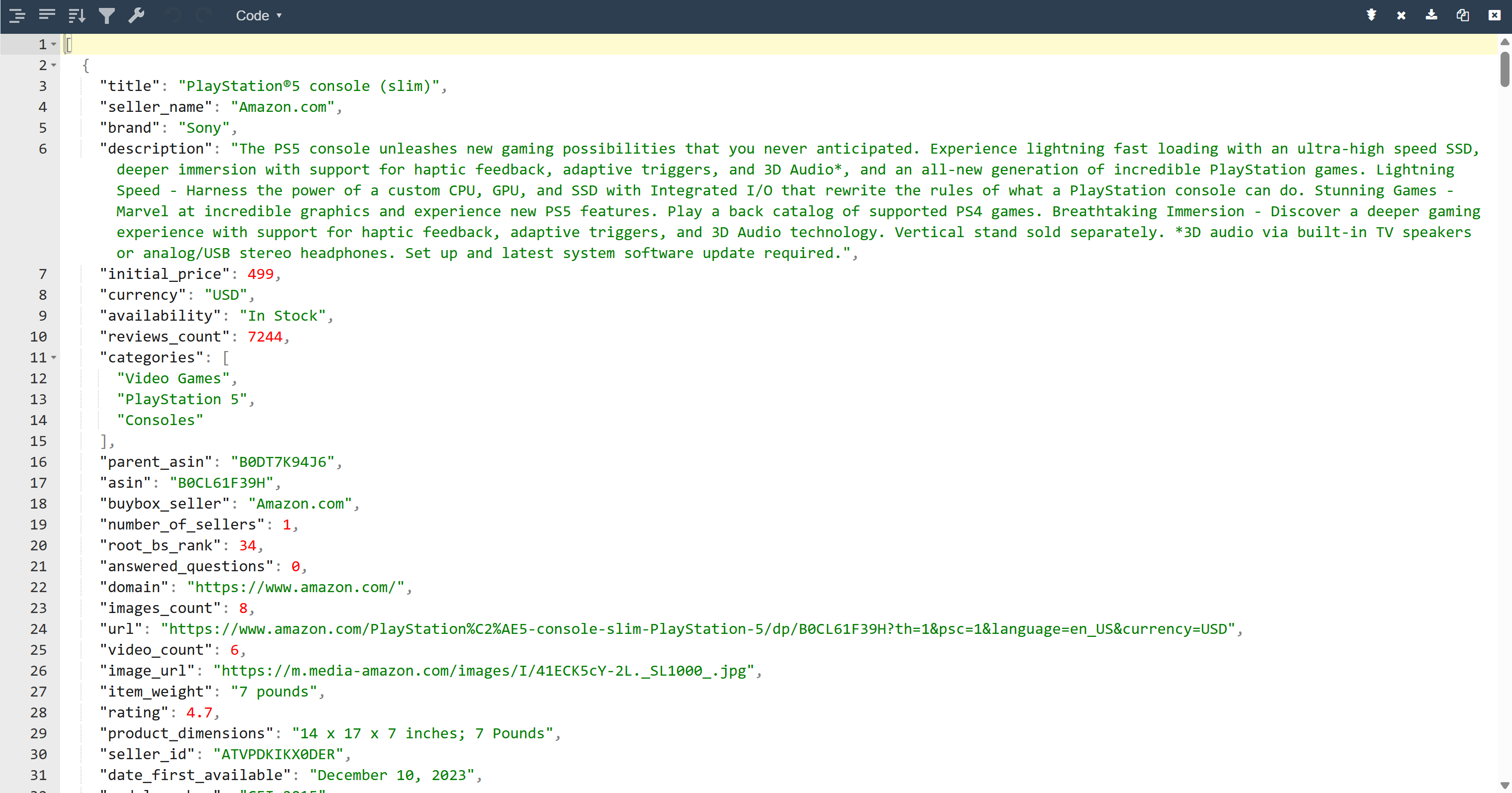
Look at how neatly the Bright Data tool extracted structured JSON data from this Amazon page:
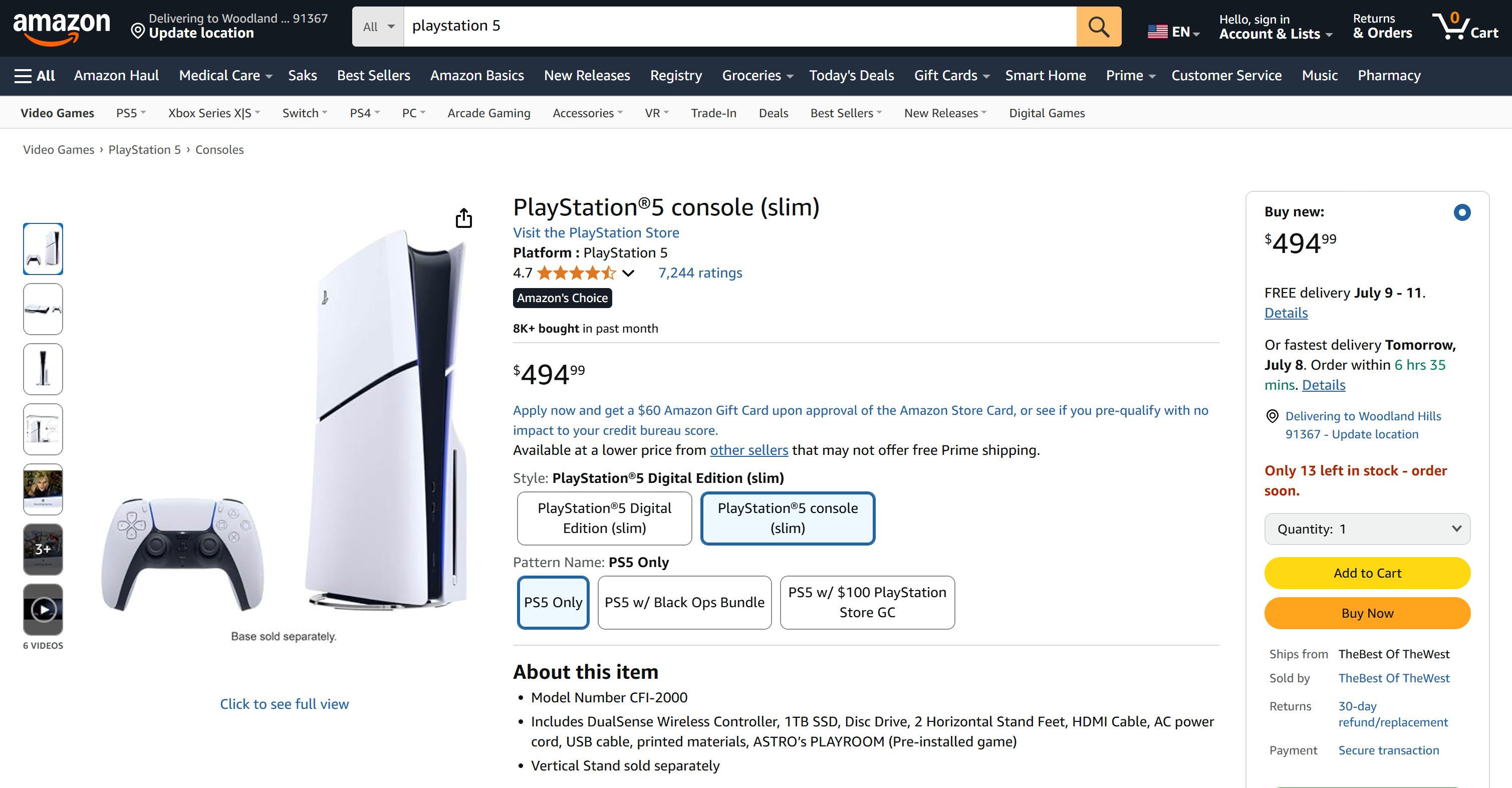
Both of these examples show how your agent can now retrieve data from virtually any web page. That is true even for complex sites like Amazon that are famous for their tough anti-scraping defenses (such as the notorious Amazon CAPTCHA).
Et voilà! You have just experienced seamless web scraping in your AI agent, powered by Bright Data tools and Agno.
Next Steps
The web scraping agent you just built with Agno is only the beginning. From here, you can explore several ways to expand and enhance your project:
- Incorporate a memory layer: Use Agno’s native vector database to store the data your agent collects through Bright Data. This gives your agent long-term memory, paving the way for advanced use cases like agentic RAG.
- Create a user-friendly interface: Build a simple web or desktop UI so users can chat with your agent in a natural, conversational way (similar to interacting with ChatGPT or Gemini). This makes your scraping tool far more accessible.
- Explore richer integrations: Agno offers a variety of tools and capabilities that can extend your agent’s skills well beyond scraping. Dive into the Agno documentation for inspiration on how to connect more data sources, use different LLMs, or orchestrate multi-step agent workflows.
Conclusion
In this article, you learned how to use Agno to build an AI agent for web scraping. This was made possible by Agno’s built-in integration with Bright Data tools. These equip the chosen LLM with the power to extract data from any website.
Keep in mind that this was just a straightforward example. If you want to develop more advanced agents, you will need solutions for fetching, validating, and transforming live web data. That is specifically what you can find in the Bright Data AI infrastructure.
Create a free Bright Data account and start experimenting with our AI-ready scraping tools!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



