

In this guide, you will learn:
- Everything you need to know to get started with Baidu web scraping.
- The most popular and effective approaches for scraping Baidu.
- How to build a custom Baidu scraper from scratch in Python.
- How to retrieve search engine results using the Bright Data SERP API.
- How to give your AI agents access to Baidu search data via the Web MCP.
Let’s dive in!
Getting Familiar with the Baidu SERP
Before taking any action, spend some time understanding how the Baidu SERP (Search Engine Results Page) is structured, which data it contains, how to access it, and so on.
Baidu SERP URLs and Bot Detection System
Open Baidu in your browser and start performing some searches. For example, search for “bright data”. You should get a URL like this:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=bright%20data&fenlei=256&oq=ai%2520model&rsv_pq=970a74b9001542b3&rsv_t=7f84gPOmZQIjrqRcld6qZUI%2FiqXxDExphd0Tz5ialqM87sc5Falk%2B%2F3hxDs&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=12&rsv_sug1=1&rsv_sug7=100&rsv_btype=t&inputT=1359&rsv_sug4=1358Among all these query parameters, the important ones are:
- Base URL:
https://www.baidu.com/s. - Search query parameter:
wd.
In other words, you can get the same results with a shorter URL:
https://www.baidu.com/s?wd=bright%20dataAlso, Baidu structures its URLs for pagination via the pn query parameter. In detail, the second page adds &pn=10, and then each subsequent page increments that value by 10. For example, if you want to scrape 3 pages with the keyword “bright data”, your SERP URLs would be:
https://www.baidu.com/s?wd=bright%20data -> page 1
https://www.baidu.com/s?wd=bright%20data&pn=10 -> page 2
https://www.baidu.com/s?wd=bright%20data&pn=20 -> page 3Now, if you try to access such a URL directly using a simple GET HTTP request in an HTTP client like Postman, you will likely see something like this:
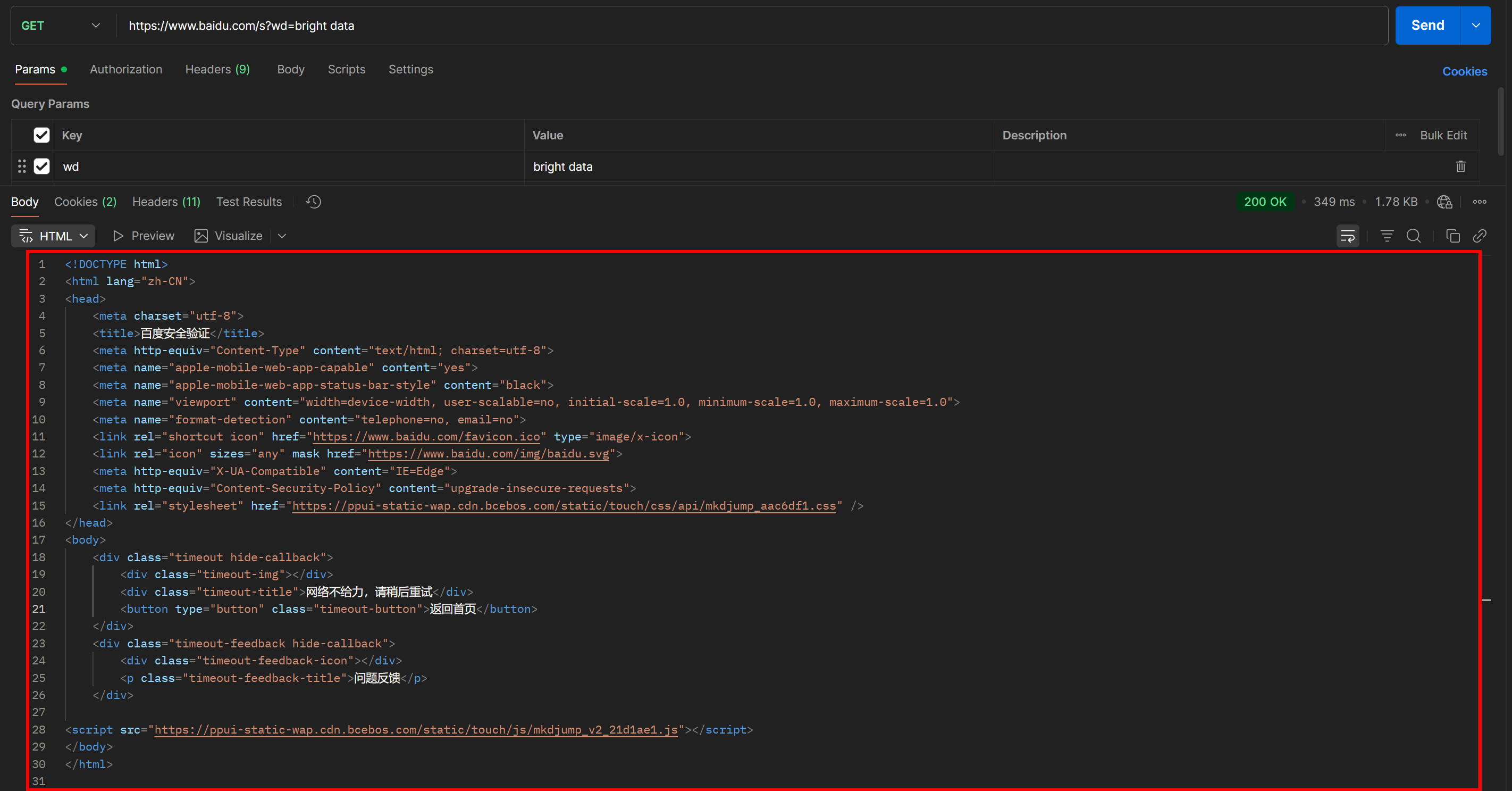
As you can tell, Baidu returns a page with the message “网络不给力,请稍后重试” (which translates to “The network is not working well, please try again later,” but is actually an anti-bot page).
This happens even if you include a User-Agent header, which is normally essential for web scraping tasks. In other words, Baidu detects that your request is automated and blocks it, requiring additional human verification.
This clearly shows that to scrape Baidu, you need a browser automation tool (such as Playwright or Puppeteer). A simple combination of an HTTP client and an HTML parser will not be enough, as it will consistently trigger anti-bot blocks.
Data Available in a Baidu SERP
Now, focus on the Baidu SERP for “bright data” rendered in your browser. You should see something like this:
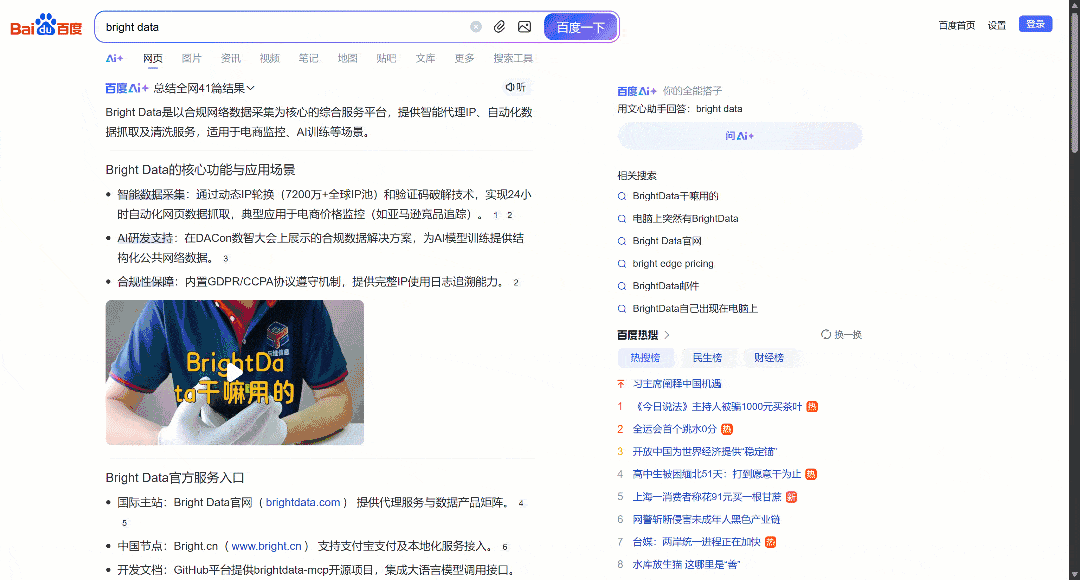
Each Baidu SERP page is divided into two columns. The left column contains an AI overview (see how to scrape AI overviews), followed by the search results. At the bottom of this column, there is the “相关搜索” (“Related Searches”) section, and below that, the pagination navigation elements.
The right column contains “百度热搜” (“Baidu Hot Searches”), which shows the trending or most popular topics on Baidu. (Note: These trending results are not necessarily related to your search terms.)
That covers all the main data you can scrape from a Baidu SERP. In this tutorial, we will focus only on the search results, which are generally the most important information!
Main Approaches to Scraping Baidu
There are several ways to get Baidu search results data. Compare the main ones in the summary table below:
| Approach | Integration Complexity | Requirements | Pricing | Risk of Blocks | Scalability |
|---|---|---|---|---|---|
| Build a custom scraper | Medium/High | Python programming skills + browser automation skills | Free (may require anti-bot browsers to avoid blocks) | Possible | Limited |
| Use Bright Data’s SERP API | Low | Any HTTP client | Paid | None | Unlimited |
| Integrate the Web MCP server | Low | AI agent framework or platform supporting MCP | Free tier available, then paid | None | Unlimited |
You will learn how to implement each approach as you go through the tutorial!
Note 1: Regardless of the method you choose, the target search query used throughout this guide will be “bright data.” That means you will see how to retrieve Baidu search results specifically for that query.
Note 2: We will assume you already have Python installed locally and are familiar with Python web scripting.
Approach #1: Build a Custom Scraper
Use a browser automation framework or an HTTP client combined with an HTML parser to build a Baidu scraper from scratch.
👍 Pros:
- Full control over the data parsing logic, with the possibility to extract exactly what you need.
- Flexible and customizable to your needs.
👎 Cons:
- Requires setup, coding, and maintenance effort.
- May face IP blocks, CAPTCHAs, rate limits, and other web scraping challenges when executing it at scale.
Approach #2: Use Bright Data’s SERP API
Leverage the Bright Data SERP API, a premium solution that lets you query Baidu (and other search engines) via an easy-to-call HTTP endpoint. It handles all anti-bot measures and scaling for you. Those and many other features make it one of the best SERP and search APIs on the market.
👍 Pros:
- Highly scalable and reliable, backed by a proxy network of 400M+ IPs.
- No IP bans or CAPTCHA issues.
- Works with any HTTP client (including visual tools like Postman or Insomnia).
👎 Cons:
- Paid service.
Approach #3: Integrate the Web MCP Server
Enable your AI agent to access Baidu search results for free through Bright Data’s Web MCP, which connects to the Bright Data SERP API and Web Unlocker under the hood.
👍 Pros:
- Integration in AI workflows and agents.
- Free tier available.
- No data parsing logic required (AI will take care of that).
👎 Cons:
- Limited control over the behavior of LLMs.
Approach #1: Build a Custom Baidu Scraper in Python Using Playwright
Follow the steps below to build a custom Baidu web scraping script in Python.
As mentioned earlier, scraping Baidu requires browser automation because simple HTTP requests will get blocked. In this tutorial section, we will use Playwright, one of the best libraries for browser automation in Python.
Step #1: Set Up Your Scraping Project
Start by opening your terminal and creating a new folder for your Baidu scraper project:
mkdir baidu-scraperThe baidu-scraper/ folder will contain all the files for your scraping project.
Next, navigate into the project directory and create a Python virtual environment inside it:
cd baidu-scraper
python -m venv .venvNow, open the project folder in your preferred Python IDE. We recommend Visual Studio Code with the Python extension or PyCharm Community Edition.
Add a new file named scraper.py to the root of your project directory. Your project’s structure should look like this:
baidu-scraper/
├── .venv/
└── scraper.pyThen, activate the virtual environment in the terminal. On Linux or macOS, execute:
source .venv/bin/activateEquivalently, on Windows, run:
.venv/Scripts/activateWith your virtual environment activated, install Playwright using pip via the playwright package:
pip install playwrightNext, install the required Playwright dependencies (e.g., the browser binaries):
python -m playwright installDone! Your Python environment is now ready to start building your Baidu web scraper.
Step #2: Initialize the Playwright Script
In scraper.py, import Playwright and use its synchronous API to start a controlled Chromium browser instance:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Initialize a Chromium instance in headless mode
browser = p.chromium.launch(headless=True) # set headless=False to see the browser for debugging
page = browser.new_page()
# Scraping logic...
# Close the browser and release its resources
browser.close()The above snippet forms the foundation of your Baidu scraper.
The parameter headless=True tells Playwright to launch Chromium without a visible GUI. Based on testing, this setting does not trigger Baidu’s bot detection. So, it works well for scraping. However, while developing or debugging your code, you might prefer to set headless=False so you can watch what is happening in the browser in real time.
Great! Now, connect to the Baidu SERP and start retrieving search results.
Step #3: Visit the Target SERP
As analyzed earlier, building a Baidu SERP URL is straightforward. Instead of instructing Playwright to simulate user interactions (like typing into the search box and submitting it), it is much easier to build the SERP URL programmatically and tell Playwright to navigate directly to it.
This is the logic to build a Baidu SERP URL for the search term “bright data”:
# The base URL of the Baidu search page
base_url = "https://www.baidu.com/s"
# The search keyword/keyphrase
search_query = "bright data"
params = {"wd": search_query}
# Build the URL of the Baidu SERP
url = f"{base_url}?{urlencode(params)}"Don’t forget to import the urlencode() function from the Python Standard Library:
from urllib.parse import urlencodeNow, instruct the Playwright-controlled browser to visit the generated URL via goto():
page.goto(url)If you run the script in headful mode (with headless=False) in the debugger, you will see a Chromium window load the Baidu SERP page:
Awesome! That is exactly the SERP you will be scraping next.
Step #4: Prepare to Scrape All SERP Results
Before diving into the scraping logic, you must study the structure of Baidu SERPs. First, as the page contains multiple search result elements, you will need a list to store the extracted data. Therefore, start by initializing an empty list:
serp_results = []Next, open the target Baidu SERP in an incognito window (to ensure a clean session) in your browser:
https://www.baidu.com/s?wd=bright%20dataRight-click on one of the search result elements and choose “Inspect” to open the browser’s DevTools:
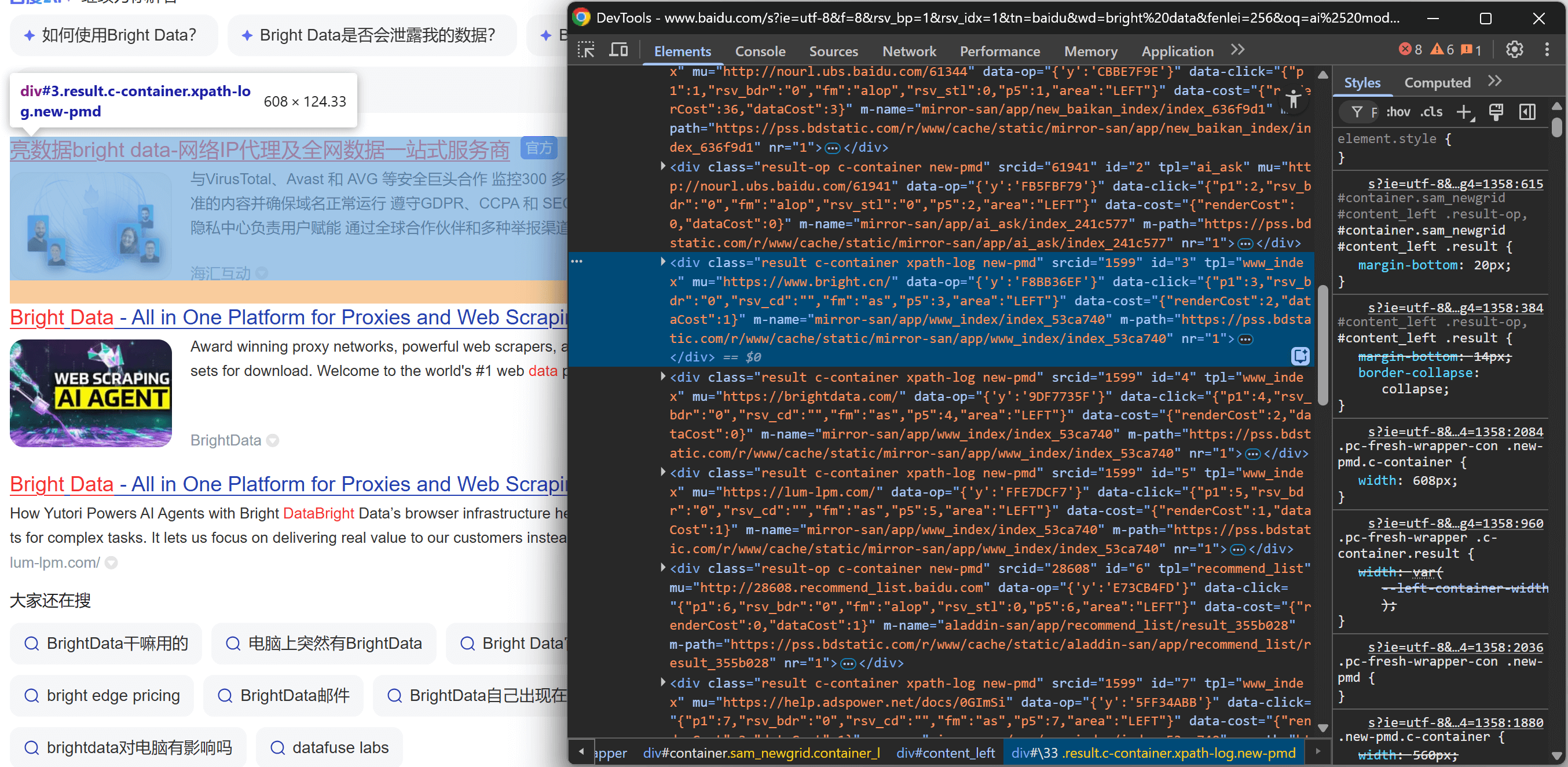
Looking at the DOM structure, you will notice that each search result item has the class result. This means you can select all search results on the page using the .result CSS selector.
Apply that selector in your Playwright script:
search_result_elements = page.locator(".result")Note: If you are not familiar with this syntax, read our guide on Playwright web scraping.
Finally, iterate over each selected element:
for search_result_element in search_result_elements.all():
# Data parsing logic...Prepare to apply the data parsing logic to extract Baidu search results and populate the serp_results list:
Perfect! You are now close to wrapping up your Baidu scraping workflow.
Step #5: Scrape Search Results Data
Inspect the HTML structure of a SERP element on the Baidu results page. This time, focus on its nested elements to identify the data you want to extract.
Start by exploring the title section:
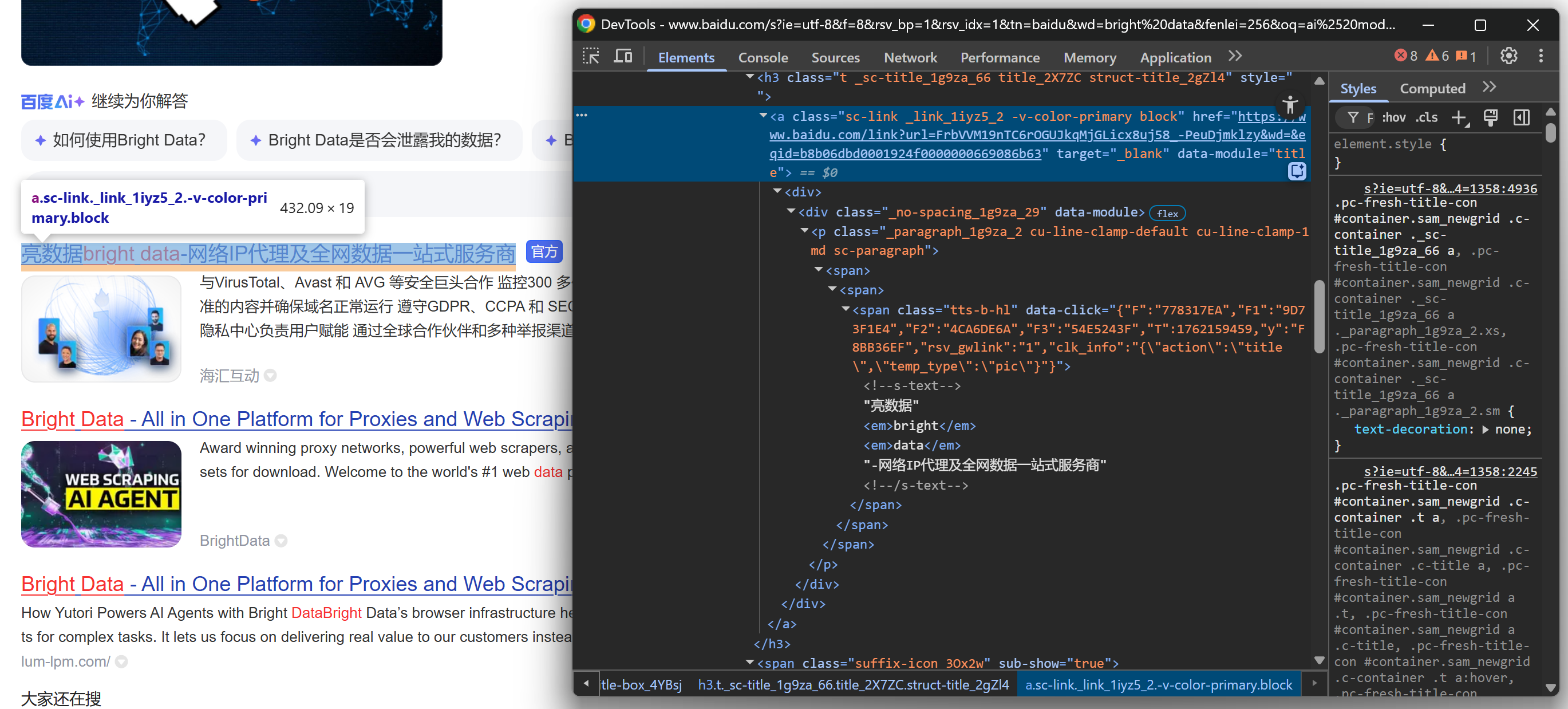
Continue by noticing that some results display a “官方” (“Official”) label:
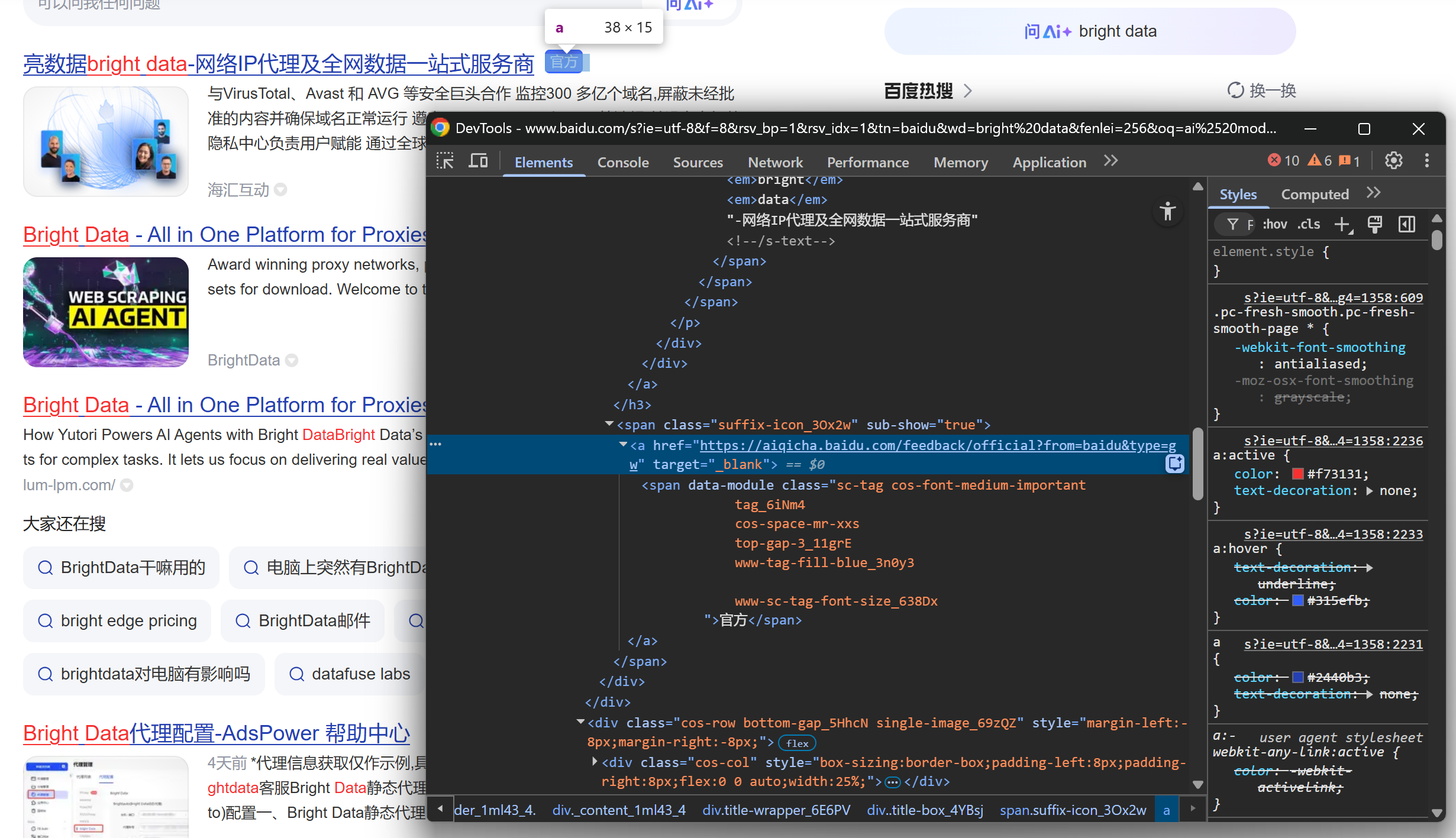
And then focus on the SERP result image:
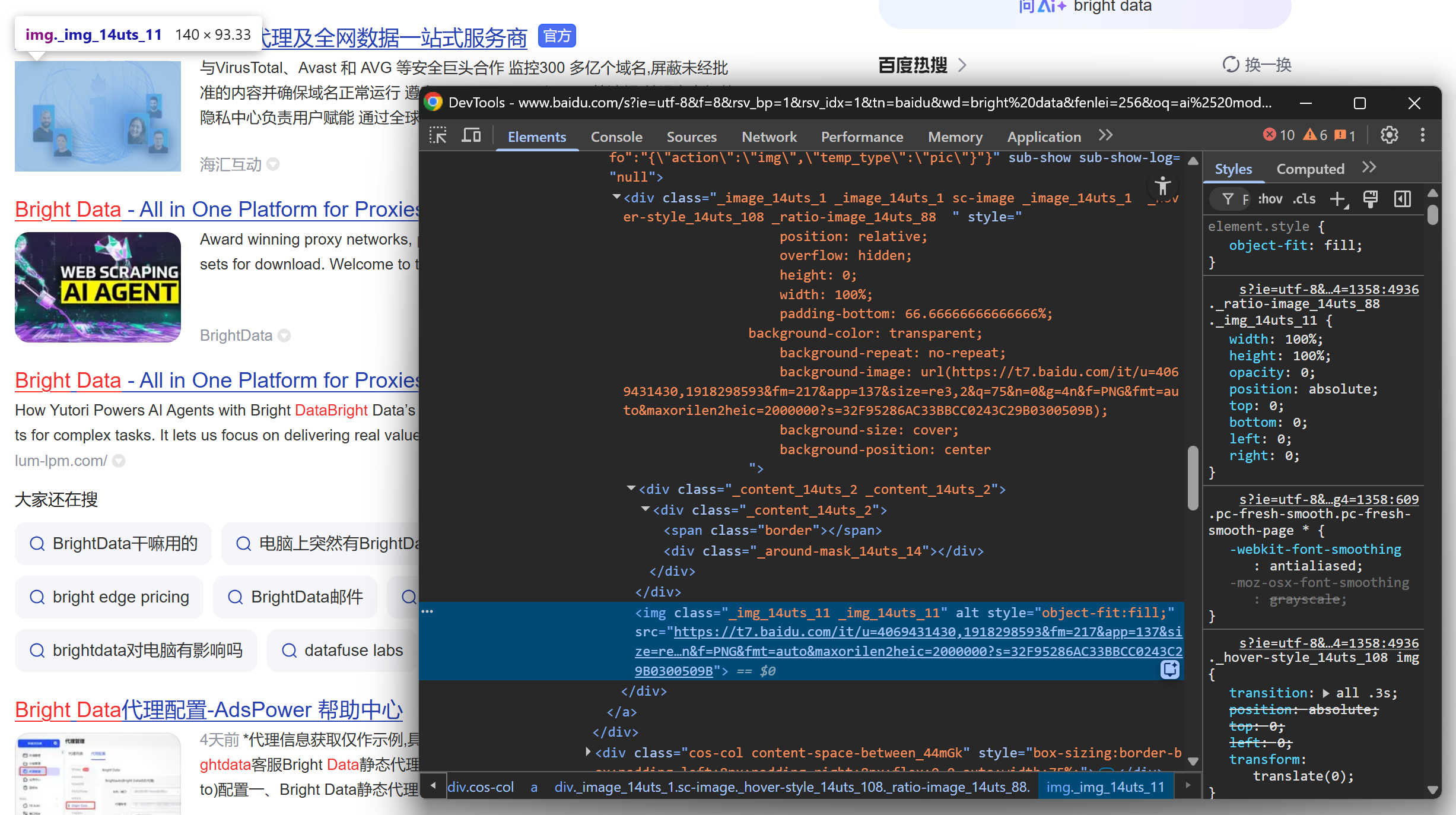
And conclude by looking at the description/abstract:
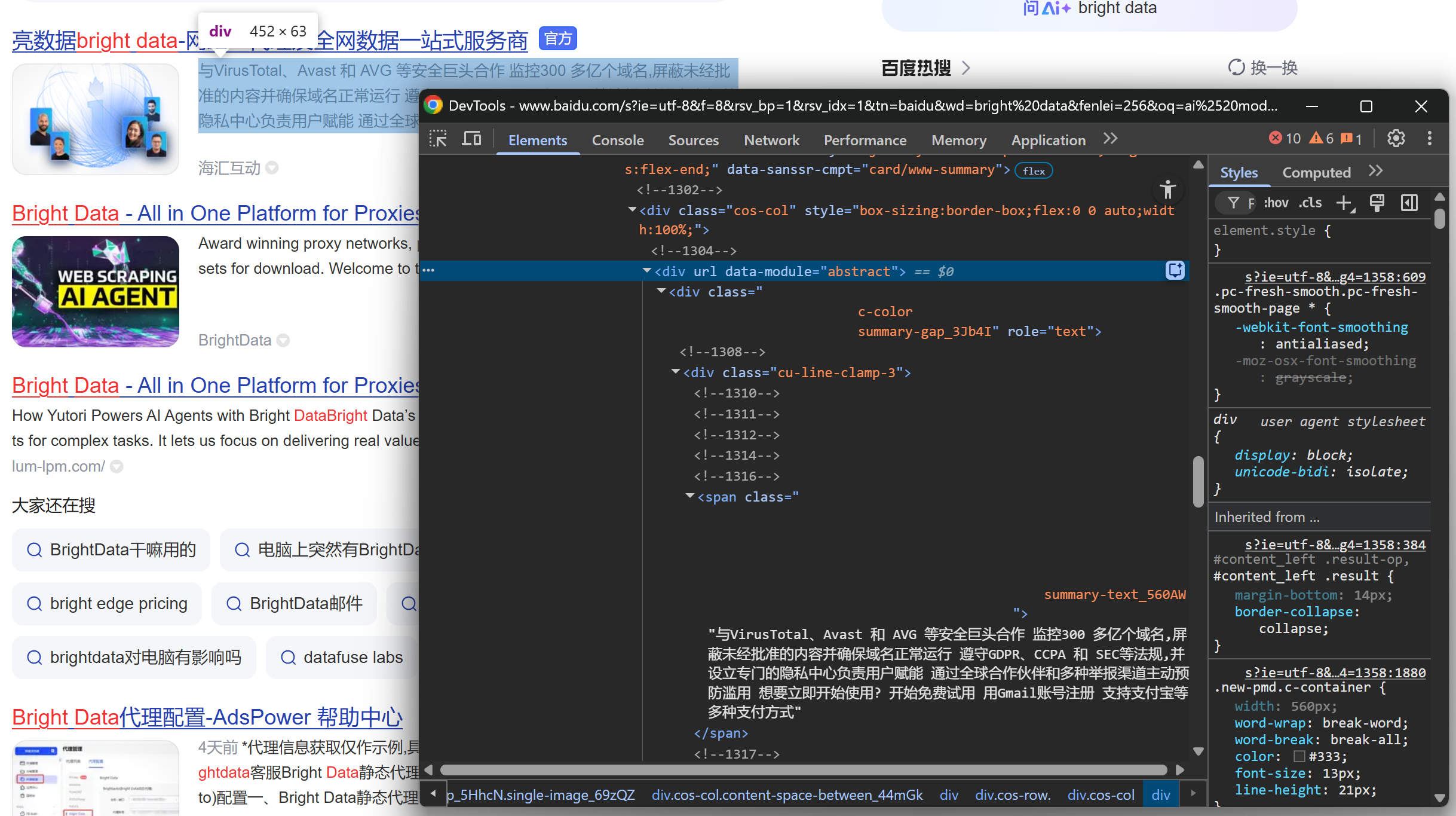
From these nested elements, you can extract the following data:
- Result URL from the
.sc-linkelement’shrefattribute. - Result title from the text of the
.sc-linkelement. - Result description/abstract from the
[data-module='abstract']text. - Result image from the
srcattribute of theimginside.sc-image. - Result snippet from the
.result__snippettext. - Official label, in an
<a>element whosehrefstarts withhttps://aiqicha.baidu.com/feedback/official(if present).
Use Playwright’s locator API to select elements and extract the desired data:
link_element = search_result_element.locator(".sc-link")
link = link_element.get_attribute("href")
title = link_element.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else None
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0Keep in mind that not all SERP items are the same. To prevent errors, always check that the element exists (.count() > 0) before accessing its attributes or text.
Terrific! You just define the Baidu SERP data parsing logic.
Step #6: Collect the Scraped Search Results Data
Conclude the for loop by creating a dictionary for each search result and appending it to the serp_results list:
serp_result = {
"title": title.strip(),
"href": link.strip(),
"description": description.strip(),
"image": image.strip() if image else "",
"official": official
}
serp_results.append(serp_result)Wonderful! Your Baidu web scraping logic is now complete. The final step is to export the scraped data for further use.
Step #7: Export the Scraped Search Results to CSV
At this stage, your Baidu search results are stored in a Python list. To make the data usable by other teams or tools, export it to a CSV file using Python’s built-in csv library:
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile:
# Dynamically read field names from the first item
fieldnames = list(serp_results[0].keys())
# Initialize the CSV writer
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Write the header and populate the output CSV file
writer.writeheader()
writer.writerows(serp_results)Do not forget to import csv:
import csvThis way, your Baidu scraper will generate an output file named baidu_serp_results.csv, containing all the scraped results in CSV format. Mission accomplished
Step #8: Put It All Together
The final code contained in scraper.py is:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from urllib.parse import urlencode
import csv
# Where to store the scraped data
serp_results = []
with sync_playwright() as p:
# Initialize a Chromium instance in headless mode
browser = p.chromium.launch(headless=True) # set headless=False to see the browser for debugging
page = browser.new_page()
# The base URL of the Baidu search page
base_url = "https://www.baidu.com/s"
# The search keyword/keyphrase
search_query = "bright data"
params = {"wd": search_query}
# Build the URL of the Baidu SERP
url = f"{base_url}?{urlencode(params)}"
# Visit the target page in the browser
page.goto(url)
# Select all the search result elements
search_result_elements = page.locator(".result")
for search_result_element in search_result_elements.all():
# Data parsing logic
link_element = search_result_element.locator(".sc-link")
link = link_element.get_attribute("href")
title = link_element.inner_text()
description_element = search_result_element.locator("[data-module='abstract']")
description = description_element.inner_text() if description_element.count() > 0 else ""
image_element = search_result_element.locator(".sc-image img")
image = image_element.get_attribute("src") if image_element.count() > 0 else None
official_element = search_result_element.locator("a[href^='https://aiqicha.baidu.com/feedback/official']")
official = official_element.count() > 0
# Populate a new search result object with the scraped data
serp_result = {
"title": title.strip(),
"href": link.strip(),
"description": description.strip(),
"image": image.strip() if image else "",
"official": official
}
# Append the scraped Baidu SERP result to the list
serp_results.append(serp_result)
# Close the browser and release its resources
browser.close()
with open("baidu_serp_results.csv", mode="w", newline="", encoding="utf-8") as csvfile:
# Dynamically read field names from the first item
fieldnames = list(serp_results[0].keys())
# Initialize the CSV writer
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# Write the header and populate the output CSV file
writer.writeheader()
writer.writerows(serp_results)Wow! In just around 70 lines of code, you’ve built a Baidu data scraping script.
Test the script with:
python scraper.pyThe output will be a baidu_serp_results.csv file in your project folder. Open it to see the structured data extracted from Baidu search results:

Note: To scrape additional results, repeat the process using the pn query parameter to handle pagination.
Et voilà! You successfully transformed unstructured Baidu search results into a structured CSV file.
[Extra] Use a Remote Browser Service to Avoid Blocks
The scraper shown above works fine for small runs, but it will not scale well. Baidu will begin blocking requests when it sees too much traffic from the same IP, returning error pages or challenges. Running many local Chromium instances is also resource‑heavy (lots of RAM) and hard to coordinate.
A more scalable and easy-to-manage solution is to connect your Playwright instance to a remote browser-as-a-service scraping solution like Bright Data’s Browser API. This provides automatic proxy rotation, CAPTCHA handling and anti‑bot bypass, real browser instances to avoid fingerprinting issues, and unlimited scaling.
Follow the Bright Data Browser API setup guide, and you will end up with a WSS connection string that looks like this:
wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222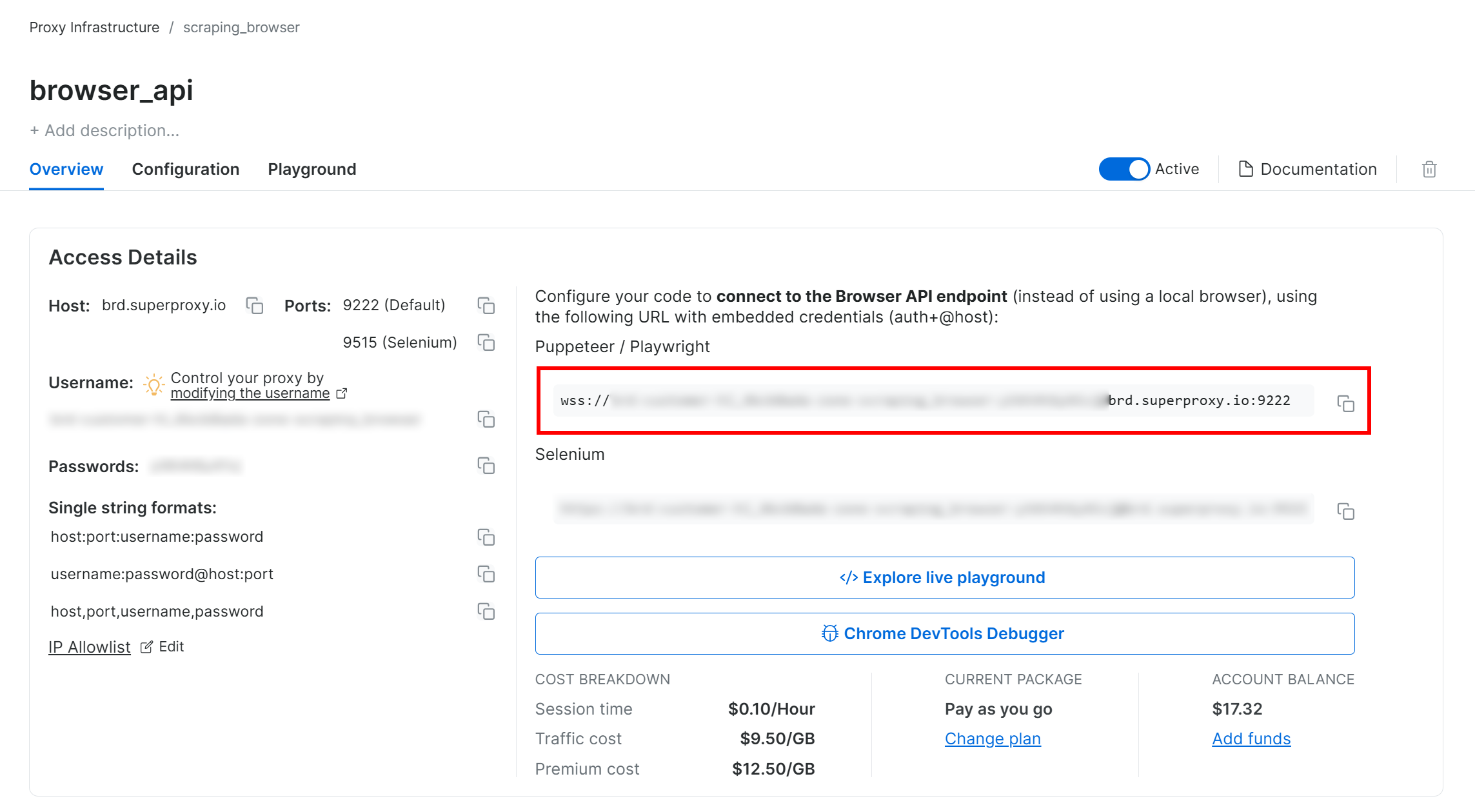
Use that WSS URL to connect Playwright to the remote browser instances over the CDP (Chrome DevTools Protocol):
wss_url = "wss://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:9222"
browser = playwright.chromium.connect_over_cdp(wss_url)
page = browser.new_page()
# ...Now your Playwright requests to Baidu will be routed through Bright Data’s Browser API remote infrastructure, which is backed by a 150‑million‑IP residential proxy network and real browser instances. That ensures a fresh IP for each session and realistic browser fingerprinting.
Approach #2: Use Bright Data’s SERP API
In this chapter, you will see how to use Bright Data’s all-in-one Baidu SERP API to programmatically retrieve search results.
Note: For the sake of simplicity, we assume you already have a Python project with the requests library installed.
Step #1: Set Up a SERP API Zone in Your Bright Data Account
Start by setting up up the SERP API product in Bright Data for scraping Baidu search results. First, create a Bright Data account—or log in if you already have one.
For a faster setup, you can refer to Bright Data’s official SERP API “Quick Start” guide. Otherwise, continue with the steps below.
Once logged in, navigate to “Proxies & Scraping” in your Bright Data account to reach the products page:
Take a look at the “My Zones” table, which lists your configured Bright Data products. If an active SERP API zone already exists, you are ready to go. Simply copy the zone name (e.g., serp_api), as you will need it later.
If no SERP API zone exists, scroll down to the “Scraping Solutions” section and click “Create Zone” on the “SERP API” card:
Give your zone a name (for example, serp-api) and click the “Add” button:
Next, go to the zone’s product page and make sure it is enabled by toggling the switch to “Active”:
Cool! Your Bright Data SERP API zone is now successfully configured and ready to use.
Step #2: Get Your Bright Data API Key
The recommended way to authenticate requests to the SERP API is by using your Bright Data API key. If you have not generated one yet, follow Bright Data’s official guide to create your API key.
When making a POST request to the SERP API, include your API key in the Authorization header as follows:
"Authorization: Bearer <YOUR_BRIGHT_DATA_API_KEY>"Amazing! You now have everything you need to call Bright Data’s SERP API from a Python script with requests—or any other Python HTTP client.
Now, let’s put everything together!
Step #3: Call the SERP API
Utilize the Bright Data SERP API in Python to retrieve Baidu search results for the keyword “bright data”:
# pip install requests
import requests
from urllib.parse import urlencode
# Bright Data credentials (TODO: replace with your values)
bright_data_api_key = "<YOUR_BRIGHT_DATA_API_KEY>"
bright_data_serp_api_zone_name = "<YOUR_SERP_API_ZONE_NAME>" # (e.g, "serp_api")
# Base URL of the Baidu search page
base_url = "https://www.baidu.com/s"
# Search keyword/keyphrase
search_query = "bright data"
params = {"wd": search_query}
# Build the Baidu SERP URL
url = f"{base_url}?{urlencode(params)}"
# Send a POST request to Bright Data's SERP API
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
},
json={
"zone": bright_data_serp_api_zone_name,
"url": url,
"format": "raw"
}
)
# Retrieve the fully rendered HTML
html = response.text
# Parsing logic goes here...For another example, check out the “Bright Data SERP API Python Project” on GitHub.
The Bright Data SERP API handles JavaScript rendering, integrates with a proxy network for automatic IP rotation, and manages anti-scraping measures like browser fingerprinting, CAPTCHAs, and others. This means you will not encounter the “网络不给力,请稍后重试” (“The network is not working well, please try again later.” ) error page that you would normally get when scraping Baidu with a basic HTTP client like requests.
In simpler terms, the html variable contains the fully rendered Baidu search results page. Verify that by printing the HTML with:
print(html)You will get an output like the one below:
From here, you can parse the HTML as shown in the first approach to extract the Baidu search data you need. As promised, the Bright Data SERP API prevents blocks and allows you to achieve unlimited scalability!
Approach #3: Integrate the Web MCP Server
Remember that the SERP API (and many other Bright Data products) is also accessible via the search_engine tool in the Bright Data Web MCP.
This open-source Web MCP server provides AI-friendly access to Bright Data’s web data retrieval solutions, including Baidu scraping. Specifically, the search_engine and scrape_as_markdown tools are available in the Web MCP free tier, giving you the opportunity to use them in AI agents or workflows at no cost.
To integrate the Web MCP into your AI solution, you only need Node.js installed locally and a configuration file like this:
{
"mcpServers": {
"Bright Data Web MCP": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>"
}
}
}
}For example, this setup works with Claude Desktop and Code (and many other AI libraries and solutions). Discover other integrations in the docs.
Alternatively, you can connect via the Bright Data remote server without any local prerequisites.
With this integration, your AI-powered workflows or agents will be able to autonomously fetch SERP data from Baidu (or other supported search engines) and process it on the fly.
Conclusion
In this tutorial, you explored three recommended methods for scraping Baidu:
- Using a custom scraper.
- Leveraging the Baidu SERP API.
- Through the Bright Data Web MCP.
As demonstrated, the most reliable way to scrape Baidu at scale while avoiding blocks is by using a structured scraping solution. This must be backed by advanced anti-bot bypass technology and a robust proxy network, such as Bright Data products.
Create a free Bright Data account and start exploring our scraping solutions today!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



