In this article, you will learn:
- What an Amazon price tracker is and why it is useful
- How to build one with a step-by-step tutorial in Python
- The limitations of this approach and how to overcome them
Let’s dive in!
What Is an Amazon Price Tracker?
An Amazon price tracker is a tool, service, or script to monitor the price of one or more Amazon products over time. It provides periodic updates on price changes, enabling you to identify price drops, discounts, or fluctuations.
Why Track an Amazon Item Price?
Tracking Amazon prices helps you:
- Save money by purchasing products at their lowest prices
- Time purchases during sales or promotions
- Set competitive pricing for your products, if you are a seller
In addition, Amazon price tracking is essential for monitoring seasonal trends and understanding market dynamics.
Creating an Amazon Price Tracker: Step-By-Step Guide
In this tutorial section, you will learn how to build an Amazon price tracker using Python. Follow the steps below to create a scraping bot that:
- Connects to the Amazon pages of specified products
- Scrapes price data from those pages
- Tracks price changes over time
If you are also interested in other data, refer to our guide on how to scrape Amazon product data.
Time to implement an Amazon price tracking script!
Step #1: Project Setup
Before getting started, make sure that you have Python 3+ installed on your machine. If not, download it from the official site and follow the installation instructions.
Then, create a directory for your Amazon price tracking project with this command:
mkdir amazon-price-tracker
Navigate into that directory and set up a virtual environment inside it:
cd amazon-price-tracker
python -m venv venv
Open the project folder in your preferred Python IDE. Visual Studio Code with the Python extension or PyCharm Community Edition are both good choices.
Create a scraper.py file in the project folder, which should now contain this file structure:

scraper.py will contain the Amazon price tracking logic.
In your IDE’s terminal, activate the virtual environment. On Linux or macOS, use:
./venv/bin/activate
Equivalently, on Windows, run:
venv/Scripts/activate
Great! You are now set up and ready to go.
Step #2: Configure the Scraping Libraries
As discussed in our guide on scraping e-commerce sites, scraping Amazon requires a browser automation tool. This is not because the site is particularly dynamic, but because Amazon employs anti-bot measures to detect and block automated requests.
In simple terms, you need a browser automation tool like Selenium to retrieve data from Amazon. To get started, install Selenium as follows:
pip install selenium
If you are not familiar with this library, refer to our tutorial on Selenium web scraping.
Import the Selenium library into your scraper.py script:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
Next, create a ChromeDriver object to control a Chrome browser instance:
# Initialize the WebDriver to control Chrome
driver = webdriver.Chrome(service=Service())
# Scraping logic...
# Release the driver resources
driver.quit()
driver will be used to interact with the Amazon product page for price tracking.
Remember that Amazon adopts anti-scraping measures, which may block headless browsers. To avoid issues, keep your Selenium-controlled browser in headed mode.
Awesome! Time to automate your Amazon scraping logic.
Step #3: Connect to the Target Page
Suppose you want to track the price of the PS5 on Amazon:
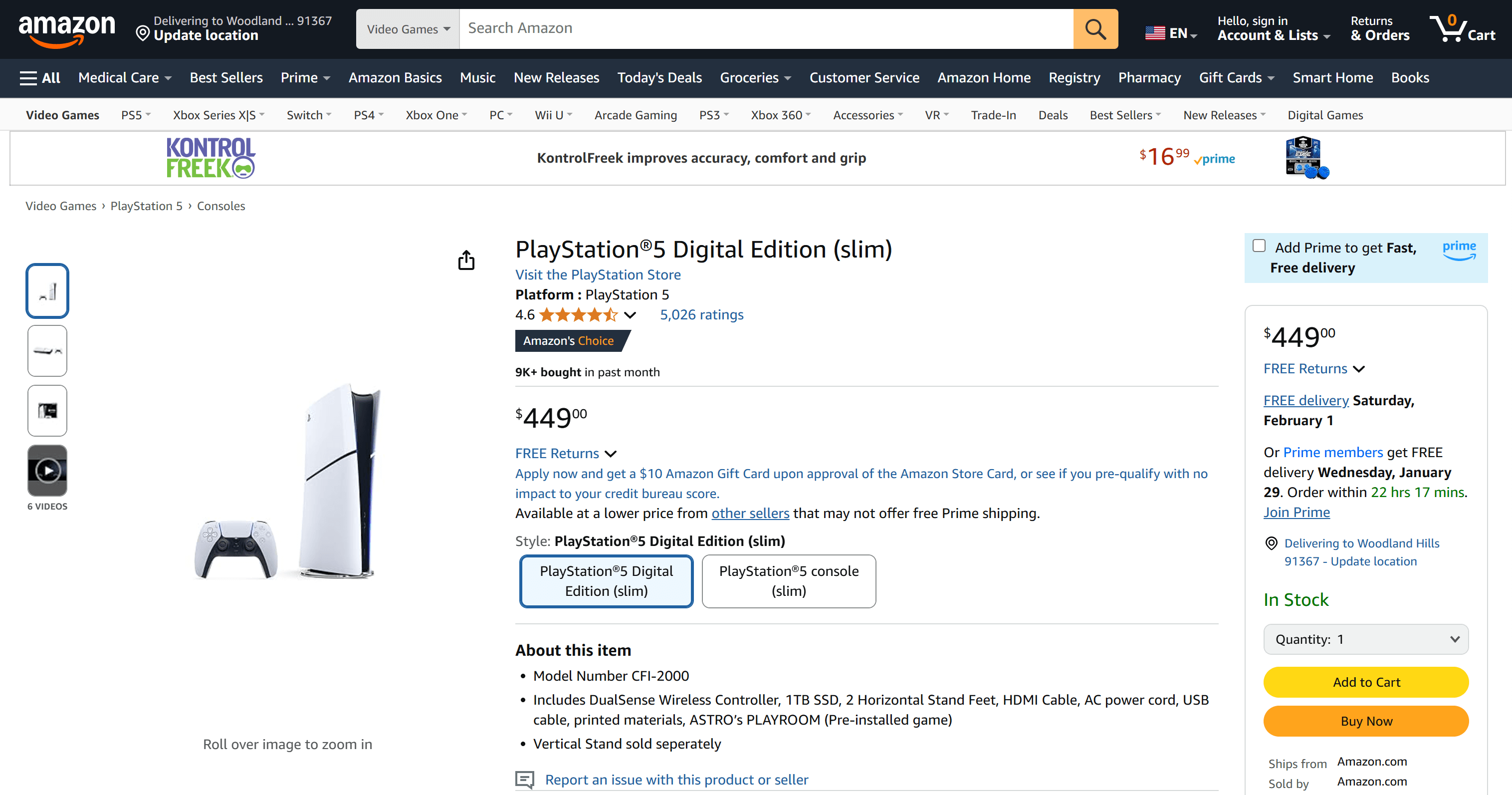
Here is the URL of the product page:
https://www.amazon.com/PlayStation%C2%AE5-Digital-slim-PlayStation-5/dp/B0CL5KNB9M/
The part after amazon.com is just a slug for readability, but the important part is the code after /dp/. This code is called the Amazon ASIN, a unique identifier for Amazon products.
In other words, you can access the same product page using the ASIN directly in the following format:
https://www.amazon.com/product/dp/<AMAZON_ASIN>
For this example, the ASIN for the PS5 is B0CL5KNB9M. Store this ASIN in a variable and use it to generate the Amazon product URL:
amazon_asin = "B0CL5KNB9M"
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
Next, use the get() method from Selenium to instruct the browser to navigate to the target page:
driver.get(amazon_url)
Set a breakpoint before the driver.quit() instruction, then run the script. You should now see the Amazon product page loaded in the browser:

The “Chrome is being controlled by automated software” message proves that Selenium is operating on the browser as desired.
Keep in mind that Amazon uses anti-bot measures, which may result in CAPTCHA challenges or blocked requests. Do not worry as we will discuss strategies to handle these issues later in this article.
Learn more about Bright Data’s Amazon ASIN Scraper here.
Step #4: Scrape the Price Information
Open the target product page in incognito in your browser. Then, right-click on the price displayed on the page and select the “Inspect” option:

In the DevTools section, take a look at the HTML of the price element. Note that the price is inside an .a-price element.
Select the element with a CSS selector and extract data from it:
price_element = driver.find_element(By.CLASS_NAME, "a-price")
price = price_element.text.replace("n", ".")
The replace() function is used to clean the price from newline characters.
Do not forget to import By:
from selenium.webdriver.common.by import By
Terrific! You successfully implemented the key feature of your Amazon Price Tracker—scraping the price.
Step #5: Store the Pricing
The killer feature of an Amazon price tracker is the ability to track price history, so that you can evaluate changes and fluctuations over time. To achieve that, you need to store the price data somewhere, such as a database or a file.
For simplicity, we will use a JSON file as a database. The file will store the product’s ASIN and a list of historical prices.
First, ensure the JSON file exists with the following structure:
{
"asin": "<AMAZON_ASIN>",
"prices": []
}
This is how to initialize such a file in Python if it does not exist:
# JSON db file name and initial data
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# Write the JSON db file if it does not exist
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Selenium logic...
To work, the above snippet requires the following two imports:
import os
import json
Before the scraping logic, load the JSON file to access its current data:
# Open the JSON file for reading and writing
with open(file_name, "r+") as file:
# Load the current price data
price_data = json.load(file)
# Scraping logic...
After scraping the price, add the new price along with a timestamp to the prices list:
price = price_element.text.replace("n", "")
# Current timestamp
timestamp = datetime.now().isoformat()
# Add a new price info point
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
Add the following import:
from datetime import datetime
Finally, update the JSON file:
# Move the file pointer to the beginning
file.seek(0)
# Override the scraped data
json.dump(price_data, file, indent=4)
# Truncate the file so if new content is shorter than the original, the extra data would be cleared
file.truncate()
Fantastic! The price tracking logic has been implemented.
Step #6: Schedule the Price Tracking Logic
Currently, you need to manually run the script whenever you want to scrape and track Amazon prices. That might work for occasional use. Still, automating the script to run at regular intervals makes it much more effective.
Achieve that by using the Python schedule library. This provides an intuitive API for scheduling tasks in Python.
Install the library by running the following command in your activated virtual environment:
pip install schedule
Then, encapsulate your entire Amazon price-tracking logic into a function that accepts the ASIN as a parameter:
def track_price(amazon_asin):
# Entire Amazon price tracking logic...
You now have a Python job you can schedule to run every 12 hours:
# Run immediately
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# Then, schedule the job to run every 12 hours
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
The while loop ensures the script remains active to process scheduled tasks.
Do not forget the following two imports:
import schedule
import time
Perfect! You just automated the entire process, turning your script into a hands-free Amazon price tracker.
Step #7: Put It All Together
This is what your Python Amazon price tracker should now look like:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
import os
from datetime import datetime
import schedule
import time
def track_price(amazon_asin):
# Initialize the WebDriver to control Chrome
driver = webdriver.Chrome(service=Service())
# Amazon product URL generation
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
# JSON db file name and initial data
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# Write the JSON db file if it does not exist
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Open the JSON file for reading and writing
with open(file_name, "r+") as file:
# Load the current price data
price_data = json.load(file)
# Navigate to the target page
driver.get(amazon_url)
# Scrape the price
price_element = driver.find_element(By.CSS_SELECTOR, ".a-price")
price = price_element.text.replace("n", ".")
# Current timestamp
timestamp = datetime.now().isoformat()
# Add a new price info point
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
# Move the file pointer to the beginning
file.seek(0)
# Override the scraped data
json.dump(price_data, file, indent=4)
# Truncate the file so if new content is shorter than the original, the extra data would be cleared
file.truncate()
# Release the driver resources
driver.quit()
# Run immediately
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# Then, schedule the job to run every 12 hours
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
Launch it as below:
python3 scraper.py
Or, on Windoes:
python scraper.py
Let the script run for several hours. The script will generate a price_history.json file similar to the following:
{
"asin": "B0CL5KNB9M",
"prices": [
{
"price": "$449.00",
"timestamp": "2026-01-27T08:02:20.333369"
},
{
"price": "$449.00",
"timestamp": "2026-01-27T20:02:20.935339"
},
{
"price": "$449.00",
"timestamp": "2026-01-28T08:02:21.109284"
},
{
"price": "$449.00",
"timestamp": "2026-01-28T20:02:21.385681"
},
{
"price": "$449.00",
"timestamp": "2026-01-29T08:02:22.123612"
}
]
}
Notice how each entry in the prices array is recorded exactly 12 hours after the previous one.
Mission complete!
Step #8: Next Steps
You just built a functional Amazon price tracker, but there is room for improvement to take it to the next level. Possible enhancements are:
- Add logging: Like any unattended process, it is key to understanding what is happening. To do so, add some logging to track the script’s actions.
- Use a database: Replace the JSON file with a database to store data. This makes it easier to share and access the price history from multiple devices or applications.
- Implement error handling: Add robust error handling to manage anti-bot measures, network timeouts, and unexpected failures. Ensure the script retries or skips gracefully when errors occur.
- Read options from the CLI: Allow the script to accept inputs from the command line, such as the ASIN and scheduling options. That will make it more flexible.
- Notification system: Integrate alerts via email or messaging apps to notify you of significant price changes.
Limitations of This Approach and How to Overcome Them
The Amazon price tracking script built in the previous chapter is just a basic example. You cannot rely on such a simple script for long-term use unless you implement the next steps. While these steps will enhance the script, they will also make it more complex and harder to manage.
However, no matter how sophisticated your script becomes, Amazon can still stop it with CAPTCHAs:

Actually, chances are your current Selenium-based Amazon scraping script is already being blocked by CAPTCHAs. As a first step, consider following our guide on how to bypass CAPTCHAs in Python.
Still, you may face 429 Too Many Requests errors due to strict rate limiting. In such cases, integrating a proxy into Selenium to rotate your exit IP is a good strategy.
These challenges highlight how scraping sites like Amazon can become frustrating without the right tools. Additionally, not being able to use browser automation tools makes your script slow and resource-intensive.
So, should you give up? Not at all! The real solution is to rely on a service like Bright Insights, which provides actionable, AI-driven eCommerce insights to help you:
- Save lost revenues: Identify and address revenue loss from delisting, out-of-stock events, or visibility issues.
- Track sales and market share: Discover white space opportunities, track competitor sales, and spot trends early.
- Optimize pricing: Monitor competitors’ pricing in real time to stay competitive.
- Maximize retail media: Use analytics to optimize advertising, maximize ROI, and ensure growing results.
- Optimize product assortment: Improve your product assortment by tracking competitors and maximizing revenue.
- Cross-channel optimization: Leverage cross-channel intelligence to manage product sales and win across all platforms.
Bright Insights gives you all the eCommerce data you need, including Amazon price tracking capabilities.
Conclusion
In this blog post, you learned what an Amazon price tracker is and the advantages it offers. You also saw how to build one using Python and Selenium for web scraping.
The challenge is that Amazon employs strict anti-bot measures, such as CAPTCHAs, browser fingerprinting, and IP bans, to block automated scripts. But with our Amazon price tracker, you can forget about these challenges and get Amazon prices.
If web scraping is your thing and you are interested in different types of Amazon data, also consider our Amazon Scraper API!
Create a free Bright Data account today and explore our services.

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.