

In this blog post, you will learn:
- What an OpenSea scraper is
- The types of data you can automatically extract from OpenSea
- How to create an OpenSea scraping script using Python
- When and why a more advanced solution may be needed
Let’s dive in!
What Is an OpenSea Scraper?
An OpenSea scraper is a tool designed to data from OpenSea, the world’s largest NFT marketplace. The primary goal of this tool is to automate the collection of various NFT-related information. Typically, it uses automated browser solutions to retrieve real-time OpenSea data without the need for manual effort.
Data to Scrape from OpenSea
Here are some of the key data points you can scrape from OpenSea:
- NFT collection name: The title or name of the NFT collection.
- Collection rank: The rank or position of the collection based on its performance.
- NFT image: The image associated with the NFT collection or item.
- Floor price: The minimum price listed for an item in the collection.
- Volume: The total trading volume of the NFT collection.
- Percentage change: The price change or percentage change in the collection’s performance over a specified period.
- Token ID: The unique identifier for each NFT in the collection.
- Last sale price: The most recent sale price of an NFT in the collection.
- Sale history: The transaction history for each NFT item, including previous prices and buyers.
- Offers: Active offers made for an NFT in the collection.
- Creator information: Details about the creator of the NFT, such as their username or profile.
- Traits/Attributes: Specific traits or properties of the NFT items (e.g., rarity, color, etc.).
- Item description: A short description or information about the NFT item.
How to Scrape OpenSea: Step-By-Step Guide
In this guided section, you will learn how to build an OpenSea scraper. The goal is to develop a Python script that automatically gathers data on NFT collections from the “Top” section of the ”Gaming” page:

Follow the steps below and see how to scrape OpenSea!
Step #1: Project Setup
Before getting started, verify that you have Python 3 installed on your machine. Otherwise, download it and follow the installation instructions.
Use the command below to create a folder for your project:
mkdir opensea-scraper
The opensea-scraper directory represents the project folder of your Python OpenSea scraper.
Navigate to it in the terminal, and initialize a virtual environment inside it:
cd opensea-scraper
python -m venv venv
Load the project folder in your favorite Python IDE. Visual Studio Code with the Python extension or PyCharm Community Edition will do.
Create a scraper.py file in the project’s folder, which should now contain this file structure:

Right now, scraper.py is a blank Python script but it will soon contain the desired scraping logic.
In the IDE’s terminal, activate the virtual environment. In Linux or macOS, launch this command:
./env/bin/activate
Equivalently, on Windows, execute:
env/Scripts/activate
Amazing, you now have a Python environment for web scraping!
Step #2: Choose the Scraping Library
Before jumping into coding, you need to determine the best scraping tools for extracting the required data. To do that, you should first conduct a preliminary test to analyze how the target site behaves as follows:
- Open the target page in incognito mode to prevent pre-stored cookies and preferences from affecting your analysis.
- Right-click anywhere on the page and select “Inspect” to open the browser’s developer tools.
- Navigate to the “Network” tab.
- Reload the page and interact with it—for example, by clicking on the “1h” and “6h” buttons.
- Monitor the activity in the “Fetch/XHR” tab.
This will give you insight into whether the webpage loads and renders data dynamically:

In this section, you can see all the AJAX requests the page makes in real time. By inspecting these requests, you will notice that OpenSea dynamically fetches data from the server. Additionally, further analysis reveals that some button interactions trigger JavaScript rendering to dynamically update the page content.
This indicates that scraping OpenSea requires a browser automation tool like Selenium!
Selenium allows you to control a web browser programmatically, mimicking real user interactions to extract data effectively. Now, let’s install it and get started.
Step #3: Install and Set Up Selenium
You can get Selenium via the selenium pip package. In an activate your virtual environment, run the command below to install Selenium:
pip install -U selenium
For guidance on how to use the browser automation tool, read our guide on web scraping with Selenium.
Import Selenium in scraper.py and initialize a WebDriver object to control Chrome:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
The snippet above sets up a WebDriver instance to interact with Chrome. Keep in mind that OpenSea employs anti-scraping measures that detect headless browsers and block them. Specifically, the server returns an “Access Denied” page.
That means you cannot use the --headless flag for this scraper. As an alternative approach, consider exploring Playwright Stealth or SeleniumBase.
Since OpenSea adapts its layout based on window size, maximize the browser window to ensure the desktop version is rendered:
driver.maximize_window()
Finally, always ensure you properly close the WebDriver to free up resources:
driver.quit()
Wonderful! You are now fully configured to start scraping OpenSea.
Step #4: Visit the Target Page
Use the get() method from Selenium WebDriver to tell the browser to get to the desired page:
driver.get("https://opensea.io/category/gaming")
Your scraper.py file should now contain these lines:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Scraping logic...
# close the browser and release its resources
driver.quit()
Place a debugging breakpoint on the final line of the script and run it. Here is what you should be seeing:

The “Chrome is being controlled by automated test software.” message certifies that Selenium is controlling Chrome as expected. Well done!
Step #5: Interact With the Webpage
By default, the “Gaming” page shows the “Trending” NFT collections:
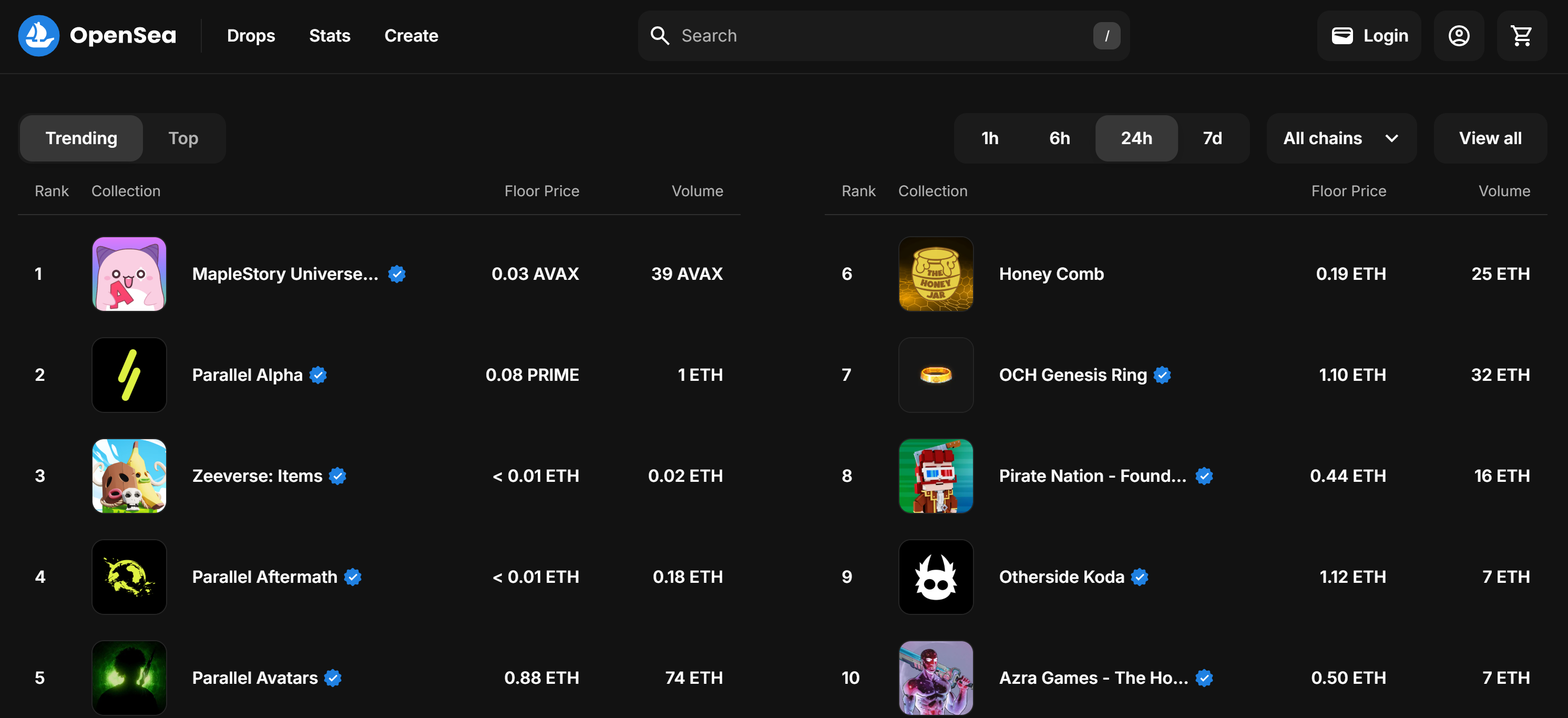
Remember that you are interested in the “Top” NFT collection. In other words, you want to instruct your OpenSea scraper to click the “Top” button as below:
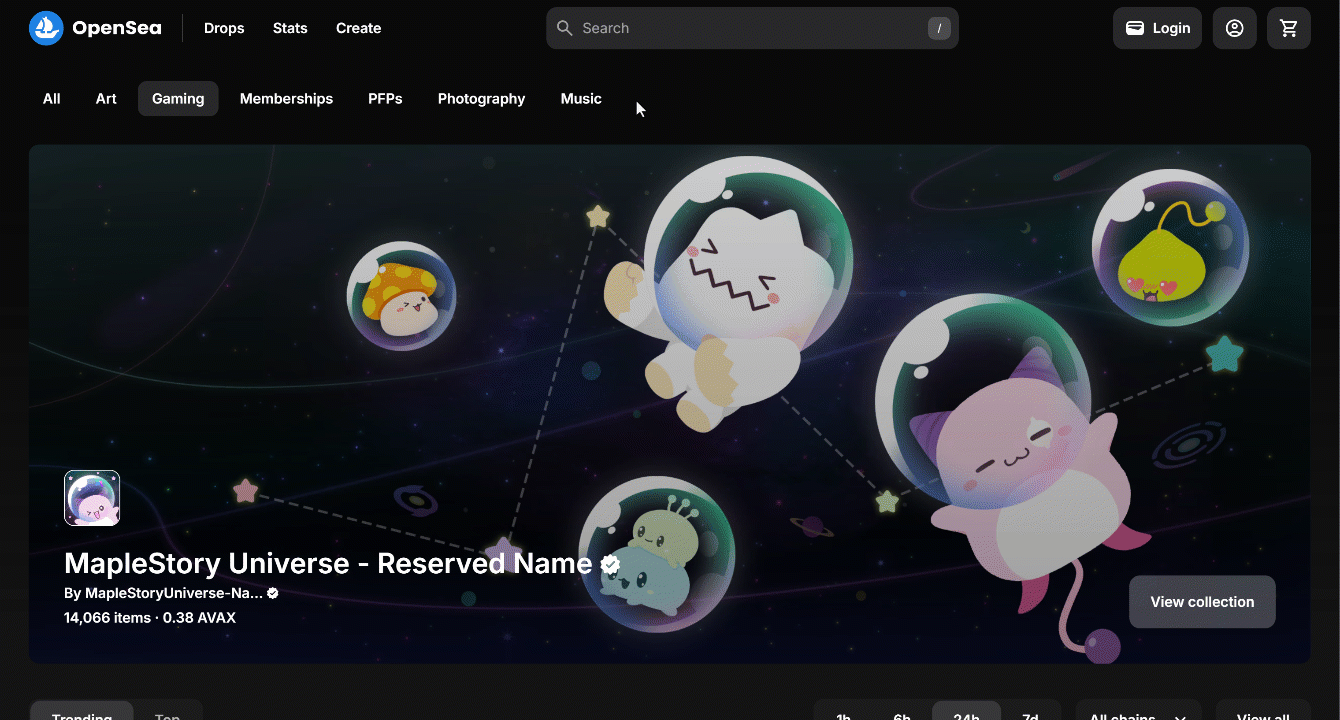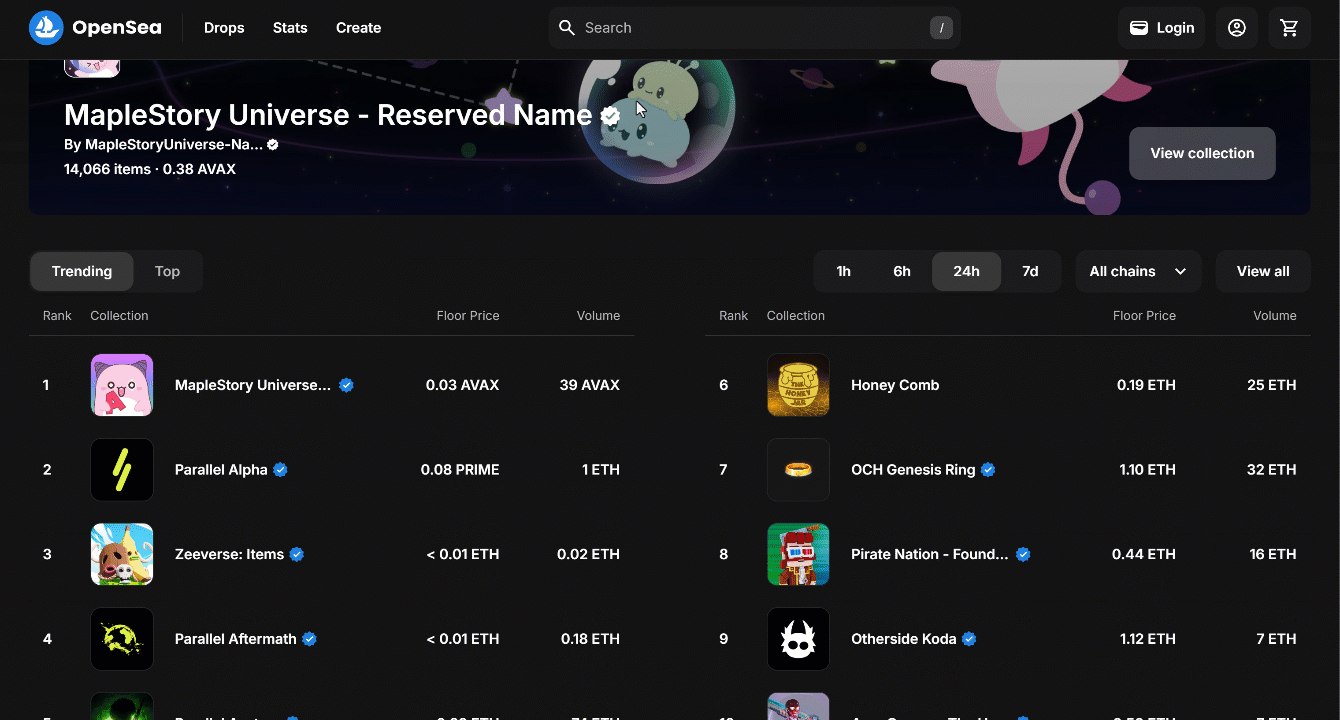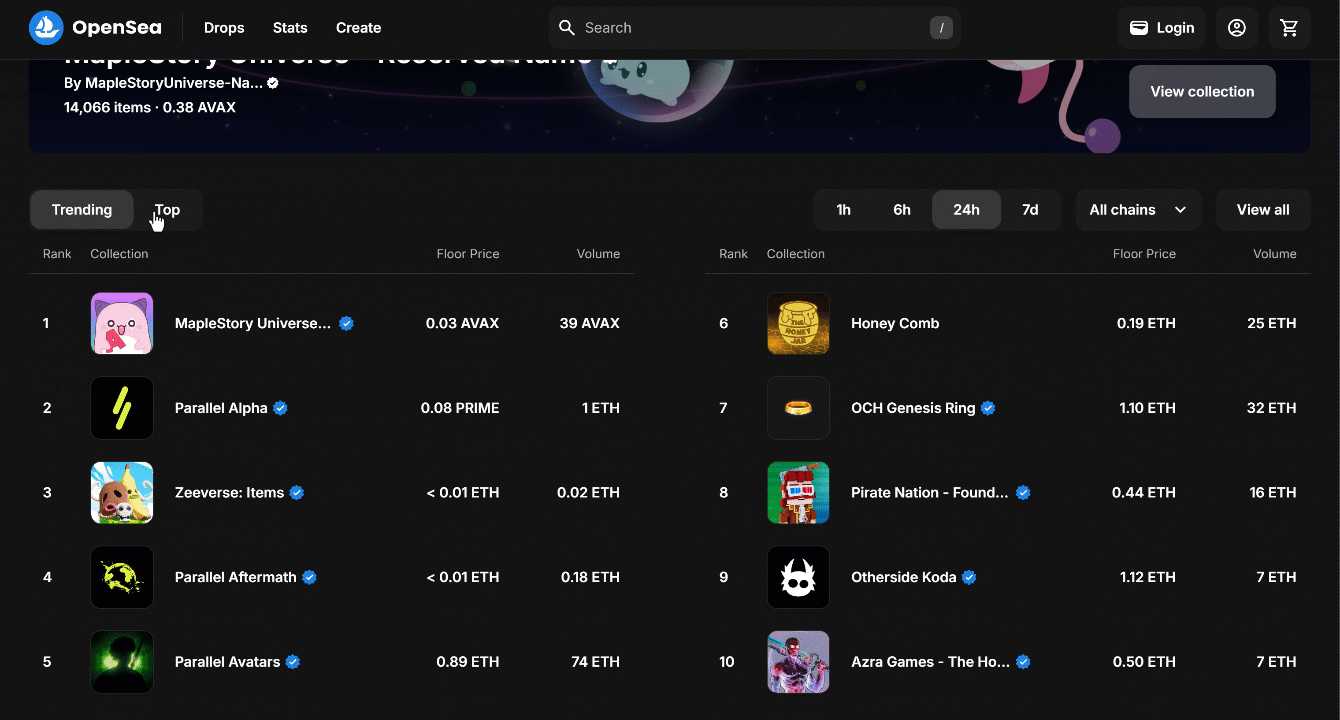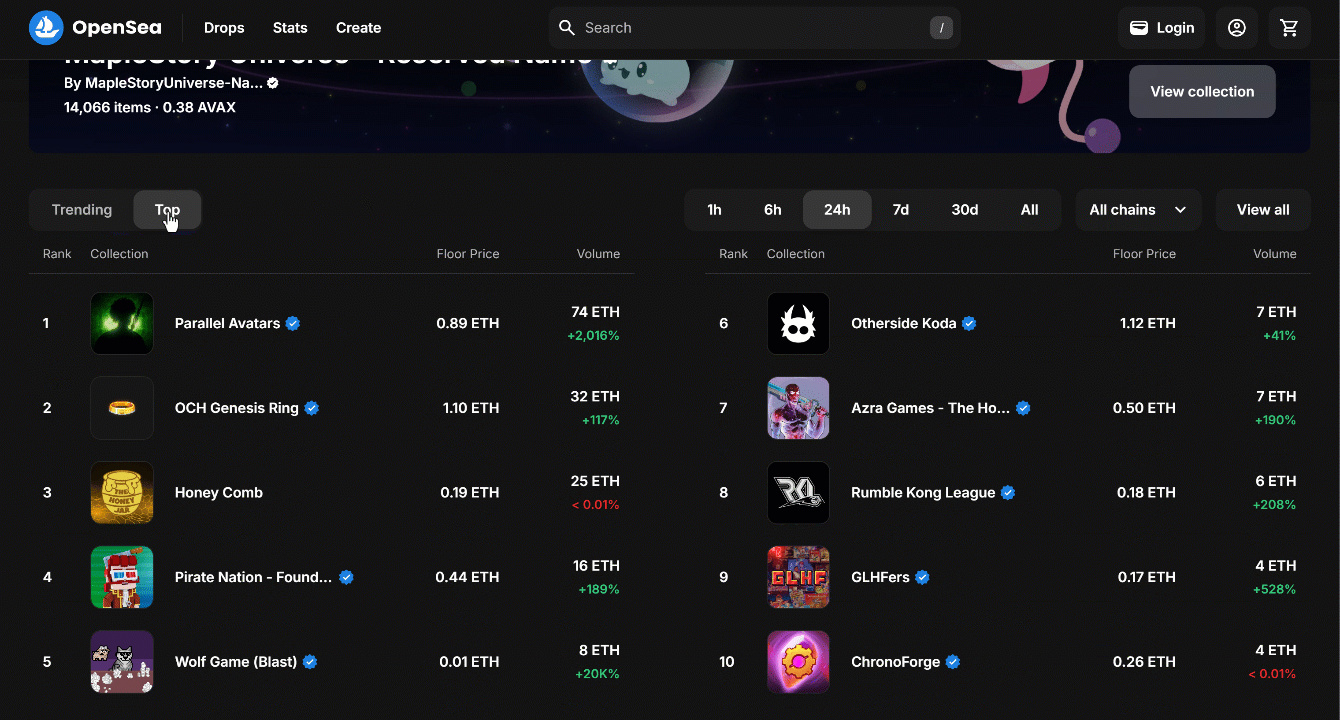
As a first step, inspect the “Top” button by right-clicking on it and selecting the “Inspect” option:

Note that you can select it by using the [value="top"] CSS selector. Use find_element() from Selenium to apply that CSS selector on the page. Then, once you selected the element, click on it with click():
top_element = driver.find_element(By.CSS_SELECTOR, "[value="top"]")
top_element.click()
To make the above code work, do not forget to add the By import:
from selenium.webdriver.common.by import By
Great! These lines of code will simulate the desired interaction.
Step #6: Prepare to Scrape the NFT Collections
The target page displays the top 10 NFT collections for the selected category. Since that is a list, initialize an empty array to store the scraped information:
nft_collections = []
Next, inspect an NFT collection entry HTML element:

Note that you can select all NFT collection entries using the a[data-id="Item"] CSS selector. Since some class names in the elements appear to be randomly generated, avoid targeting them directly. Instead, focus on data-* attributes, as these are typically used for testing and remain consistent over time.
Retrieve all NFT collection entry elements using find_elements():
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id="Item"]")
Next, iterate through the elements and prepare to extract data from each one:
for item_element in item_elements:
# Scraping logic...
Terrific! You are ready to start scraping data from OpenSea NFT elements.
Step #7: Scrape the NFT Collection Elements
Inspect an NFT collection entry:

The HTML structure is quite intricate, but you can extract the following details:
- The collection image from
img[alt="Collection Image"] - The collection rank from
[data-id="TextBody"] - The collection name from
[tabindex="-1"]
Unfortunately, these elements lack unique or stable attributes, so you will need to rely on potentially flaky selectors. Start by implementing the scraping logic for these first three attributes:
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt="Collection Image"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id="TextBody"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
name = name_element.text
The .text property retrieves the text content of the selected element. Since rank will later be used for sorting the scraped data, it is converted to an integer. Meanwhile, .get_attribute("src") fetches the value of the src attribute, extracting the image URL.
Next, focus on the .w-1/5 columns:

Here is how the data is structured:
- The first
.w-1/5column contains the floor price. - The second
.w-1/5column contains the volume and percentage change, each in separate elements.
Extract these values with the following logic:
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1\/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1\/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
Note that you cannot use .w-1/5 directly but you need to escape / with \.
Here we go! The OpenSea scraping logic for getting NFT collections is complete.
Step #8: Collect the Scraped Data
You currently have the scraped data spread across several variables. Populate a new nft_collection object with that data:
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
Then, do not forget to add it to the nft_collections array:
nft_collections.append(nft_collection)
Outside the for loop, sort the scraped data in ascending order:
nft_collections.sort(key=lambda x: x["rank"])
Fantastic! It only remains to export this information to a human-readable file like CSV.
Step #9: Export the Scraped Data to CSV
Python has built-in support for exporting data to formats like CSV. Achieve that with these lines of code:
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
This snippets exports the scraped data from the nft_collections list to a CSV file named nft_collections.csv. It uses Python’s csv module to create a writer object that writes the data in a structured format. Each entry is stored as a row with column headers corresponding to the dictionary keys in the nft_collections list.
Import csv from the Python Standard Library with:
imprort csv
Step #10: Put It All Together
This is the final code of your OpenSea scraper:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Select the "Top" NFTs
top_element = driver.find_element(By.CSS_SELECTOR, "[value="top"]")
top_element.click()
# Where to store the scraped data
nft_collections = []
# Select all NFT collection HTML elements
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id="Item"]")
# Iterate over them and scrape data from them
for item_element in item_elements:
# Scraping logic
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt="Collection Image"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id="TextBody"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
name = name_element.text
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1\/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1\/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
# Populate a new NFT collection object with the scraped data
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
# Add it to the list
nft_collections.append(nft_collection)
# Sort the collections by rank in ascending order
nft_collections.sort(key=lambda x: x["rank"])
# Save to CSV
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
# close the browser and release its resources
driver.quit()
Et voilà! In less than 100 lines of code, you can build a simple Python OpenSea scraping script.
Launch it with the following command in the terminal:
python scraper.py
After a while, this nft_collections.csv file will appear in the project’s folder:

Congratulations! You just scraped OpenSea as planned.
Unlocking OpenSea Data with Ease
OpenSea offers much more than just NFT collection rankings. It also provides detailed pages for each NFT collection and the individual items within them. As NFT prices fluctuate frequently, your scraping script needs to run automatically and frequently to capture fresh data. However, most OpenSea pages are protected by strict anti-scraping measures, making data retrieval challenging.
As we observed earlier, using headless browsers is not an option, which means you will be wasting resources to keep the browser instance open. Additionally, when trying to interact with other elements on the page, you might encounter issues:

For example, the data loading can get stuck, and the AJAX requests in the browser may be blocked, resulting in a 403 Forbidden error:

This happens due to the advanced anti-bot measures implemented by OpenSea to block scraping bots.
These issues make scraping OpenSea without the right tools a frustrating experience. The solution? Use Bright Data’s dedicated OpenSea Scraper, which allows you to retrieve data from the site via simple API calls or no-code without the risk of being blocked!
Conclusion
In this step-by-step tutorial, you learned what an OpenSea scraper is and the types of data it can collect. You also built a Python script to scrape OpenSea NFT data, all with less than 100 lines of code.
The challenge lies in OpenSea’s strict anti-bot measures, which block automated browser interactions. Bypass those issues with our OpenSea Scraper, a tool you can easily integrate with either API or no-code to retrieve public NFT data, including the name, description, token ID, current price, last sale price, history, offers, and much more.
Create a free Bright Data account today and start using our scraper APIs!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.




