

In this tutorial, you will learn:
- What an AWS Bedrock AI agent is and what it can do.
- Why giving agents access to web search results via an AI-ready tool like Bright Data’s SERP API improves accuracy and context.
- How to build an AWS Bedrock agent integrated with the SERP API step by step in the AWS console.
- How it is possible to achieve the same using code with AWS CDK.
Let’s dive in!
What Is an AWS Bedrock AI Agent?
In AWS Bedrock, an AI agent is a service that uses LLMs to automate multi-step tasks by breaking them down into logical steps. More in detail, an Amazon Bedrock AI agent is a system that takes advantage of foundation models, APIs, and data to understand user requests, gather relevant information, and complete tasks automatically.
AWS Bedrock agents support memory for task continuity, built-in security via Bedrock Guardrails, and can collaborate with other agents for complex workflows. Thanks to the AWS infrastructure, they are managed, scalable, and serverless, simplifying the process of building and deploying AI-powered applications.
Why AI Agents in Amazon Bedrock Benefit from Dynamic Web Search Context
LLMs are trained on large datasets that represent the knowledge available up to a specific point in time. This means that when an LLM is released, it only knows what was included in its training data, which quickly becomes outdated.
That is why AI models lack real-time awareness of current events and emerging knowledge. As a result, they may produce outdated, incorrect, or even hallucinated responses, which is a huge problem in AI agents.
This limitation can be overcome by giving your AI agent the ability to fetch fresh, trustworthy information in a RAG (Retrieval-Augmented Generation) setup. The idea is to equip your agent with a reliable tool that can perform web searches and retrieve verifiable data to support its reasoning, expand its knowledge, and ultimately deliver more accurate results.
One option would be to build a custom AWS Lambda function that scrapes SERPs (Search Engine Results Pages) and prepares the data for LLM ingestion. However, this approach is technically complex. It requires handling JavaScript rendering, CAPTCHA solving, and constantly changing site structures. Moreover, it is not easily scalable, as search engines like Google can quickly block your IPs after a few automated requests.
A much better solution is to use a top-rated SERP and web search API, such as Bright Data’s SERP API. This service returns search engine data while automatically managing proxies, unblocking, data parsing, and all other challenges.
By integrating Bright Data’s SERP API into AWS Bedrock via a Lambda function, your AI agent gains access to web search information—without any of the operational burden. Let’s see how!
How to Integrate Bright Data SERP API into Your AWS Bedrock AI Agent for Search-Contextualized Use Cases
In this step-by-step section, you’ll learn how to give your AWS Bedrock AI agent the ability to fetch real-time data from search engines using the Bright Data SERP API.
This integration enables your agent to deliver more contextual and up-to-date answers, including relevant links for further reading. The setup will be done visually in the AWS Bedrock console, with only a small amount of code required.
Follow the steps below to build an AWS Bedrock AI agent supercharged through SERP API!
Prerequisites
To follow along with this tutorial, you need:
- An active AWS account (a free trial works fine).
- The prerequisites for Amazon Bedrock Agents set up. (Note: Amazon Bedrock Agents are currently available only in select AWS Regions. Check the latest list of supported regions and make sure you’re using one of them.)
- A Bright Data account with an API key ready.
- Basic Python programming skills.
Do not worry if you have not created a Bright Data account yet. You will be guided through that process later in the guide.
Step #1: Create an AWS Bedrock Agent
To create an AWS Bedrock AI agent, log in to your AWS account and open the Amazon Bedrock console by searching for the service in the search bar:
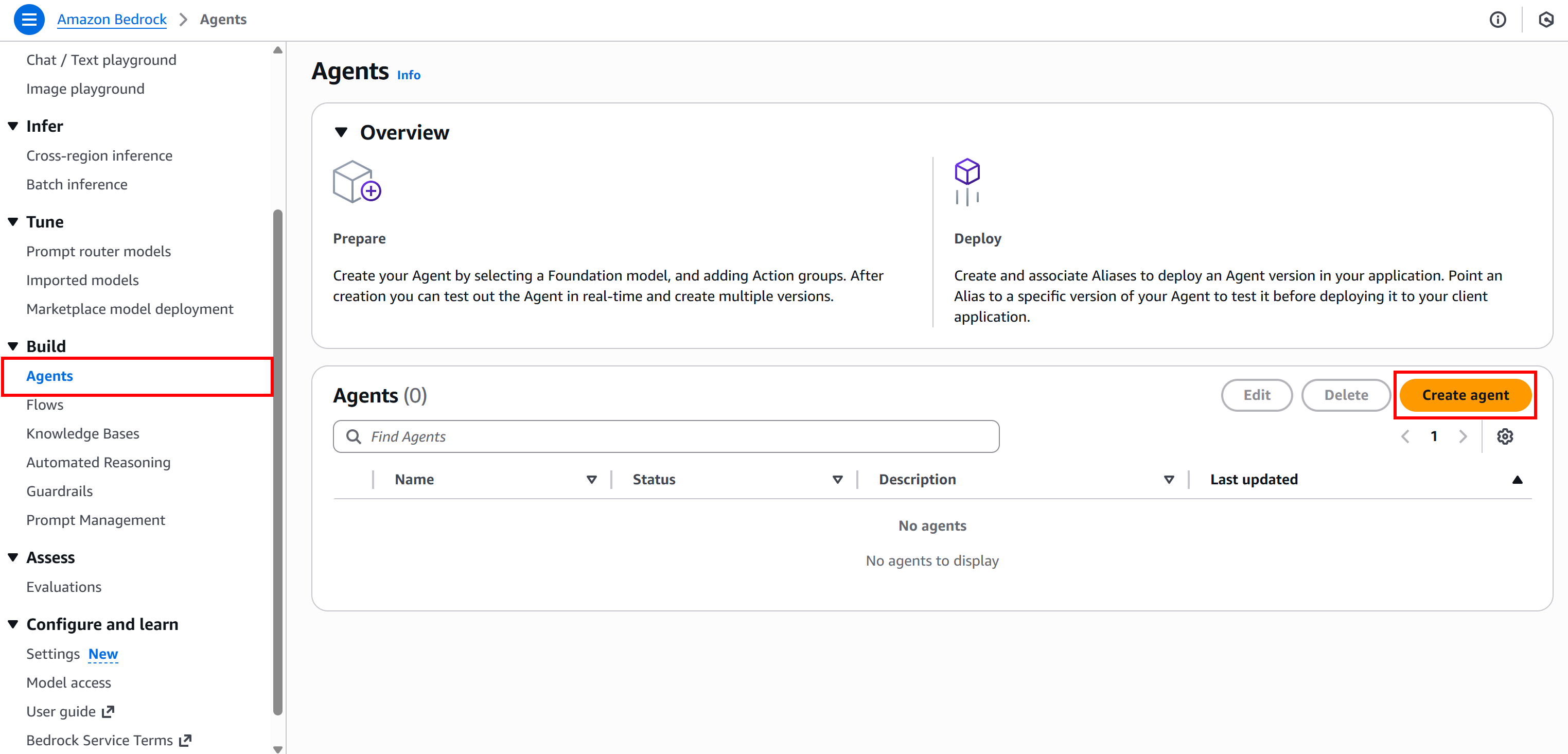
Next, in the Bedrock console, select “Agents” from the left-hand menu, then click the “Create agent” button:
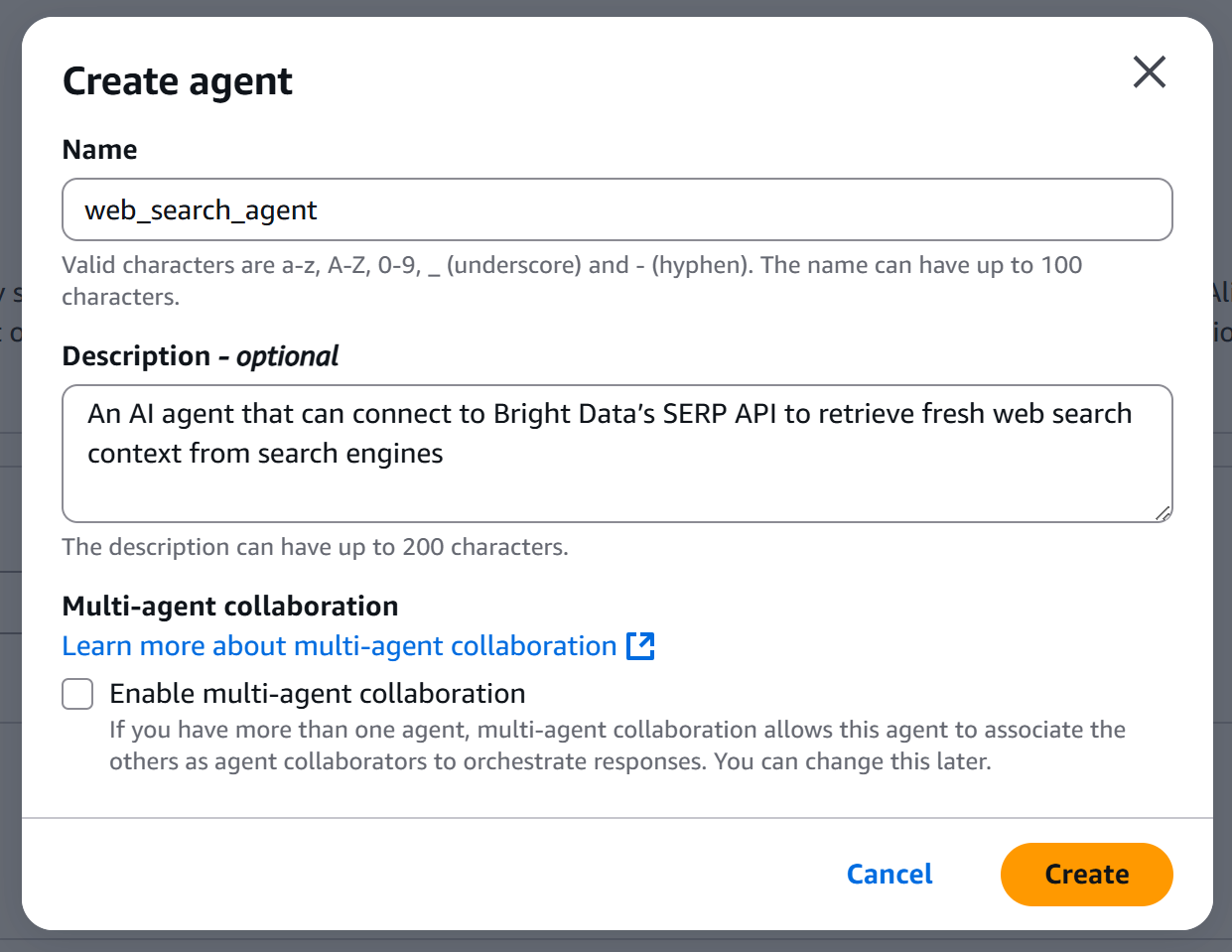
Give your agent a name and description, for example:
- Name:
web_search_agent - Description: “An AI agent that can connect to Bright Data’s SERP API to retrieve fresh web search context from search engines.”
Important: If you plan to use Amazon LLMs, you must use underscores (_) instead of hyphens (-) in the agent name, functions, etc. Using hyphens can cause a “Dependency resource: received model timeout/error exception from Bedrock. If this happens, try the request again.” error.
Click “Create” to finalize your AI agent. You should now be redirected to the “Agent builder” page:
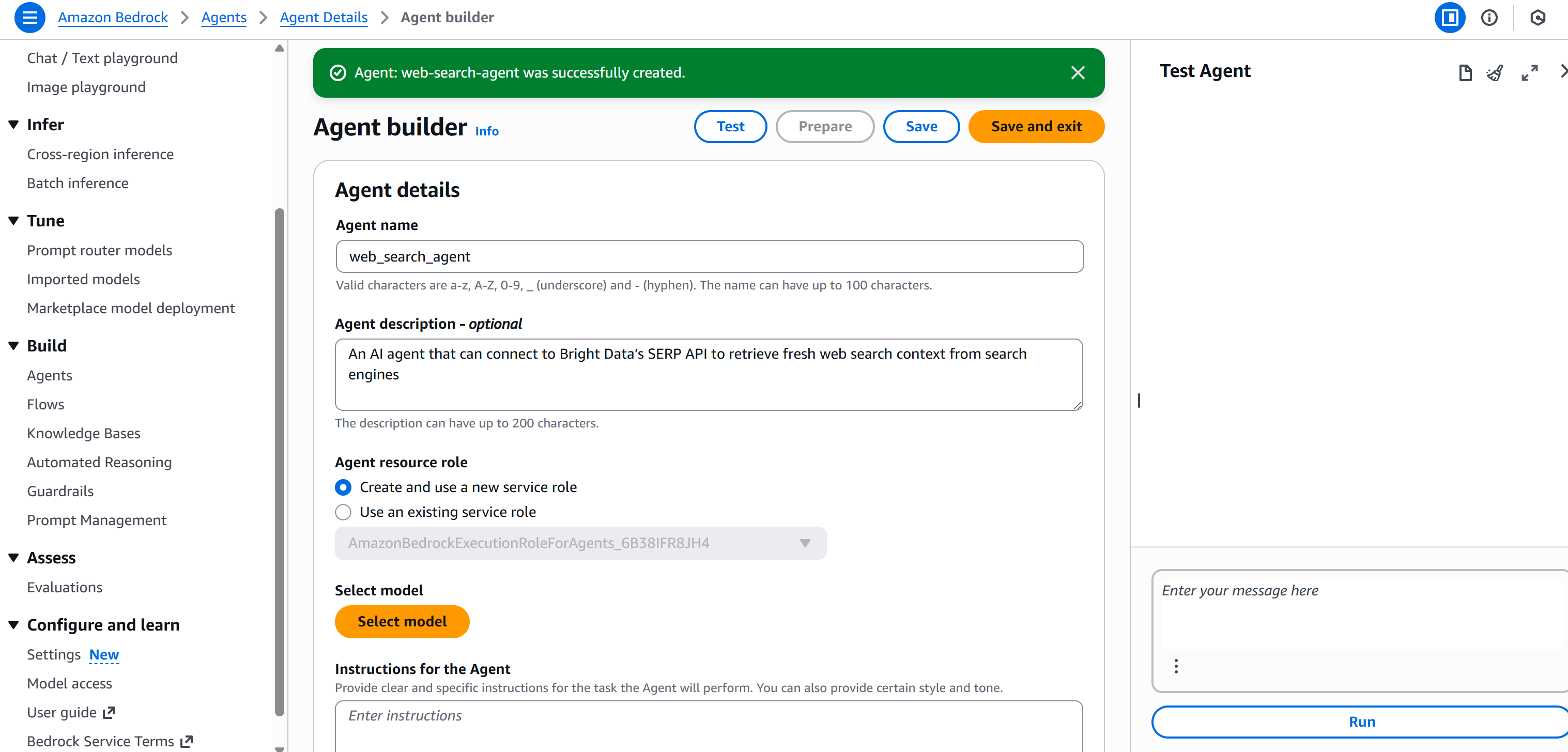
Great! You have successfully created an AI agent in AWS Bedrock.
Step #2: Configure the AI Agent
Now that you have created an agent, you need to complete its setup by configuring a few options.
For the “Agent resource role” info, leave the default “Create and use a new service role” option. This automatically creates an AWS Identity and Access Management (IAM) role that the agent will assume:
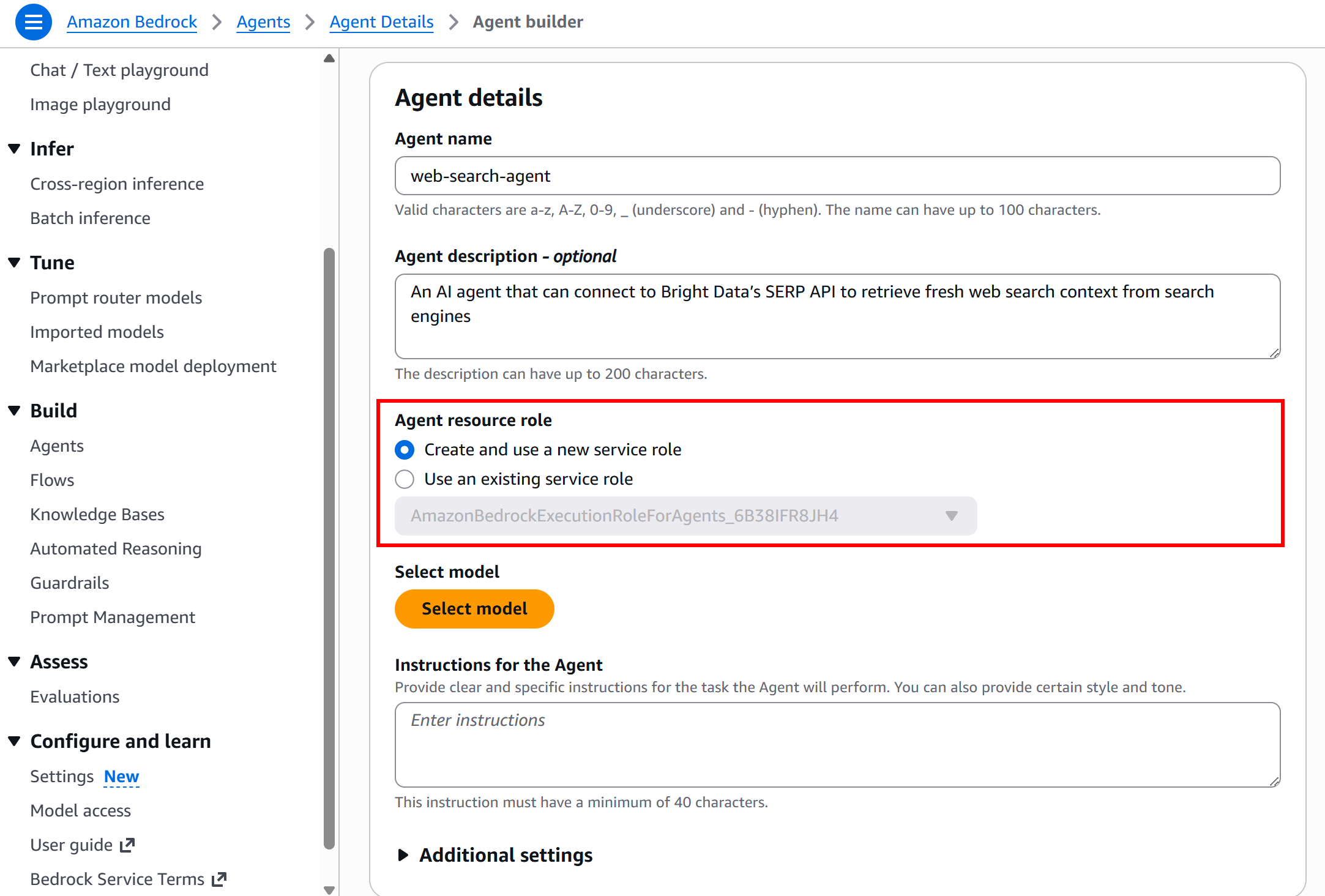
Next, click “Select model” and choose the LLM model to power your agent. In this example, we will use the “Nova Lite” model from Amazon (but any other model will do):
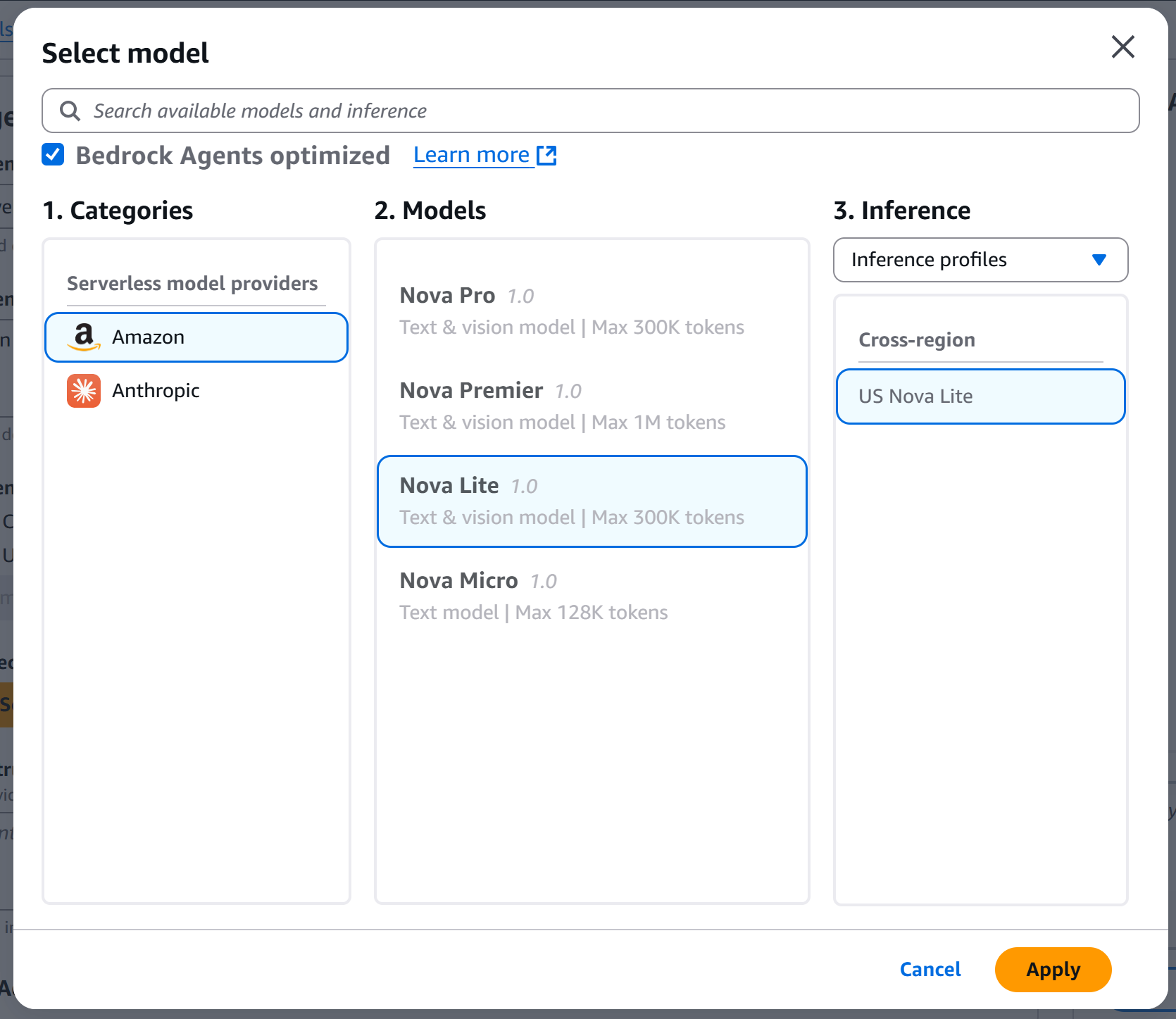
After selecting the model, click “Apply” to confirm.
In the “Instructions for the Agent” section, provide clear and specific instructions that tell the agent what it should do. For this web search agent, you can enter something like:
You are an agent designed to handle use cases that require retrieving and processing up-to-date information. You can access current data, including news and search engine results, through web searches powered by Bright Data’s SERP API.After completing the instructions, the final agent details section should look like this:
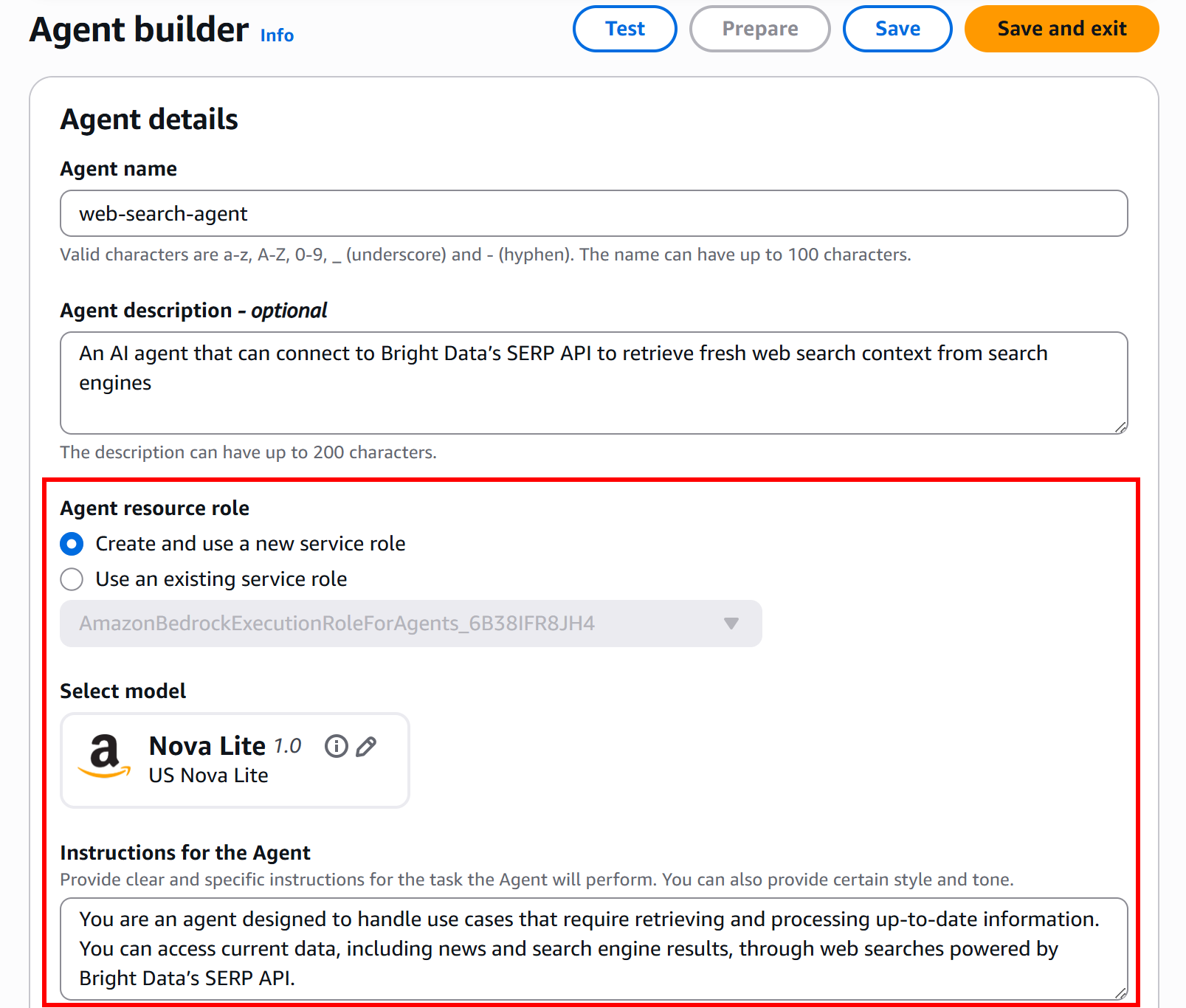
Complete the configuration of the agent details by clicking “Save” in the top bar to save all agent details.
Note: AWS Bedrock offers many other configuration options. Explore them to adapt your agents to your specific use cases.
Step #3: Add the SERP API Action Group
Action groups allow agents to interact with external systems or APIs to gather information or perform actions. You will need to define one to integrate with Bright Data’s SERP API.
In the “Agent builder” page, scroll down to the “Action groups” section and click “Add”:
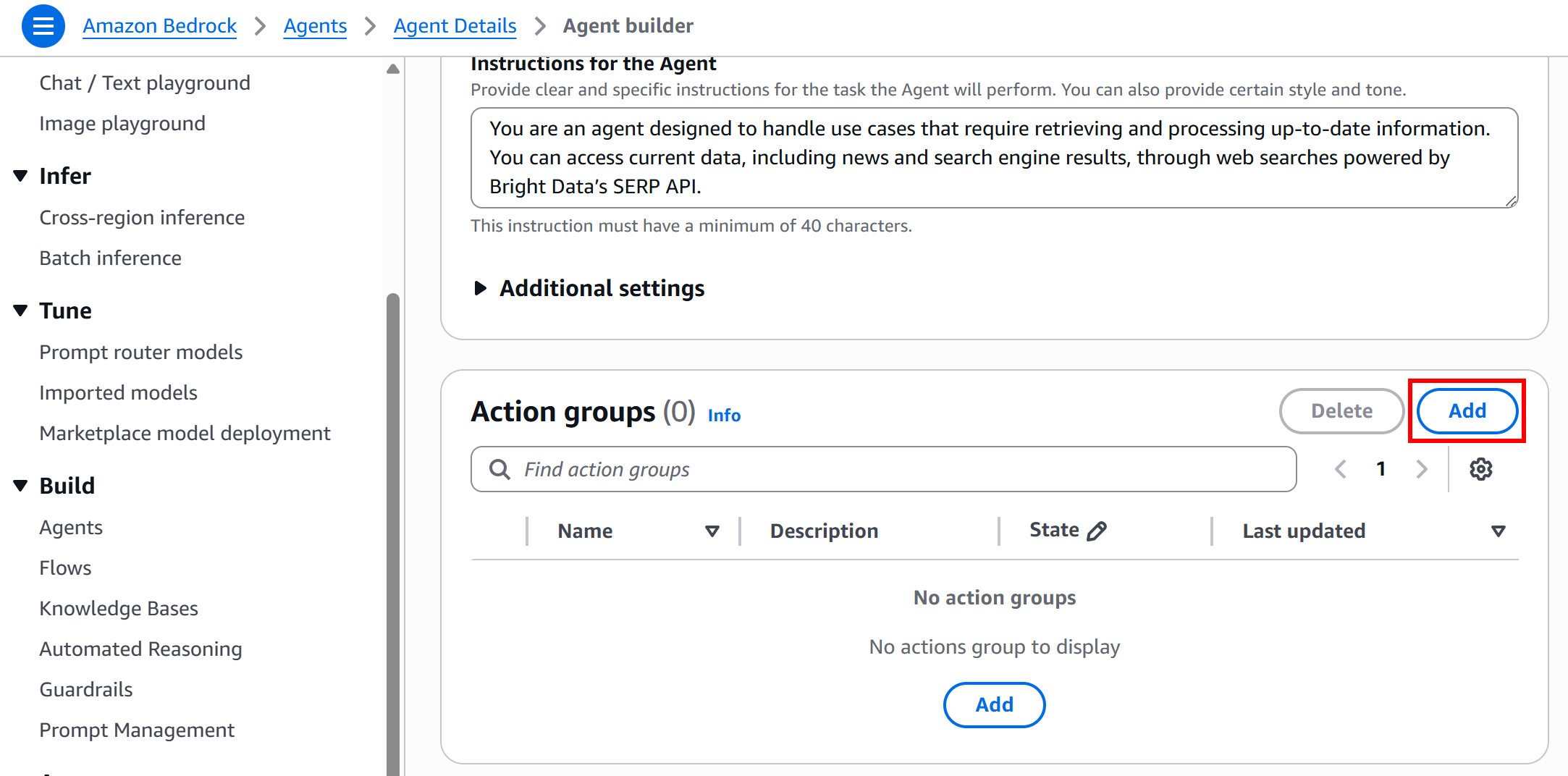
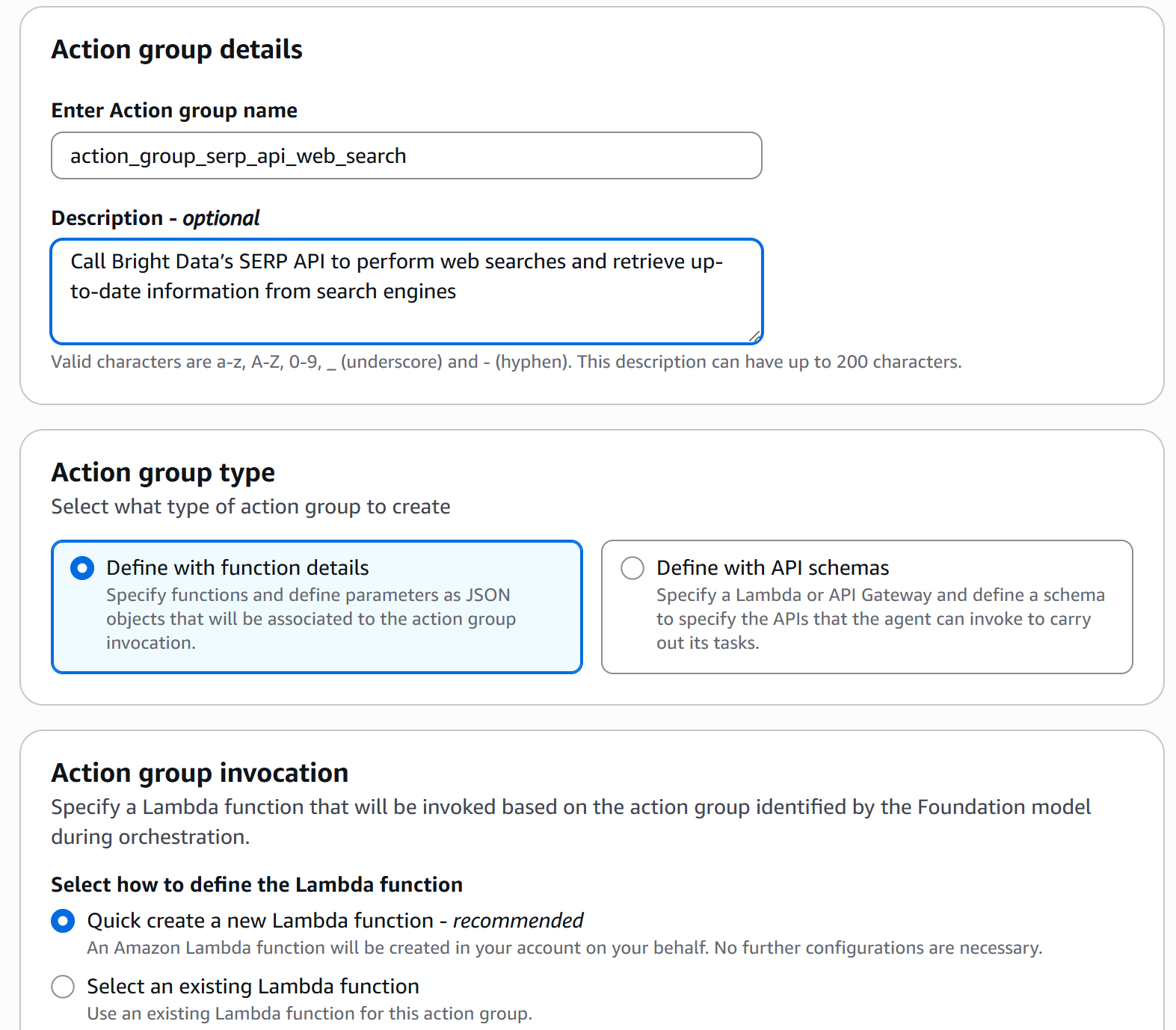
This will open a form to define the action group. Fill it out as follows:
- Enter Action group name:
action_group_web_search(again, use underscores_, not hyphens-) - Description: “Call Bright Data’s SERP API to perform web searches and retrieve up-to-date information from search engines.”
- Action group type: Select the “Define with function details” option.
- Action group invocation: Select the “Quick create a new Lambda function” option, which sets up a basic Lambda function that the agent can call. In this case, the function will handle the logic to call Bright Data’s SERP API.
Note: With the “Quick create a new Lambda function” option, Amazon Bedrock generates a Lambda function template for your agent. You can later modify this function in the Lambda console (we will do that in a later step).
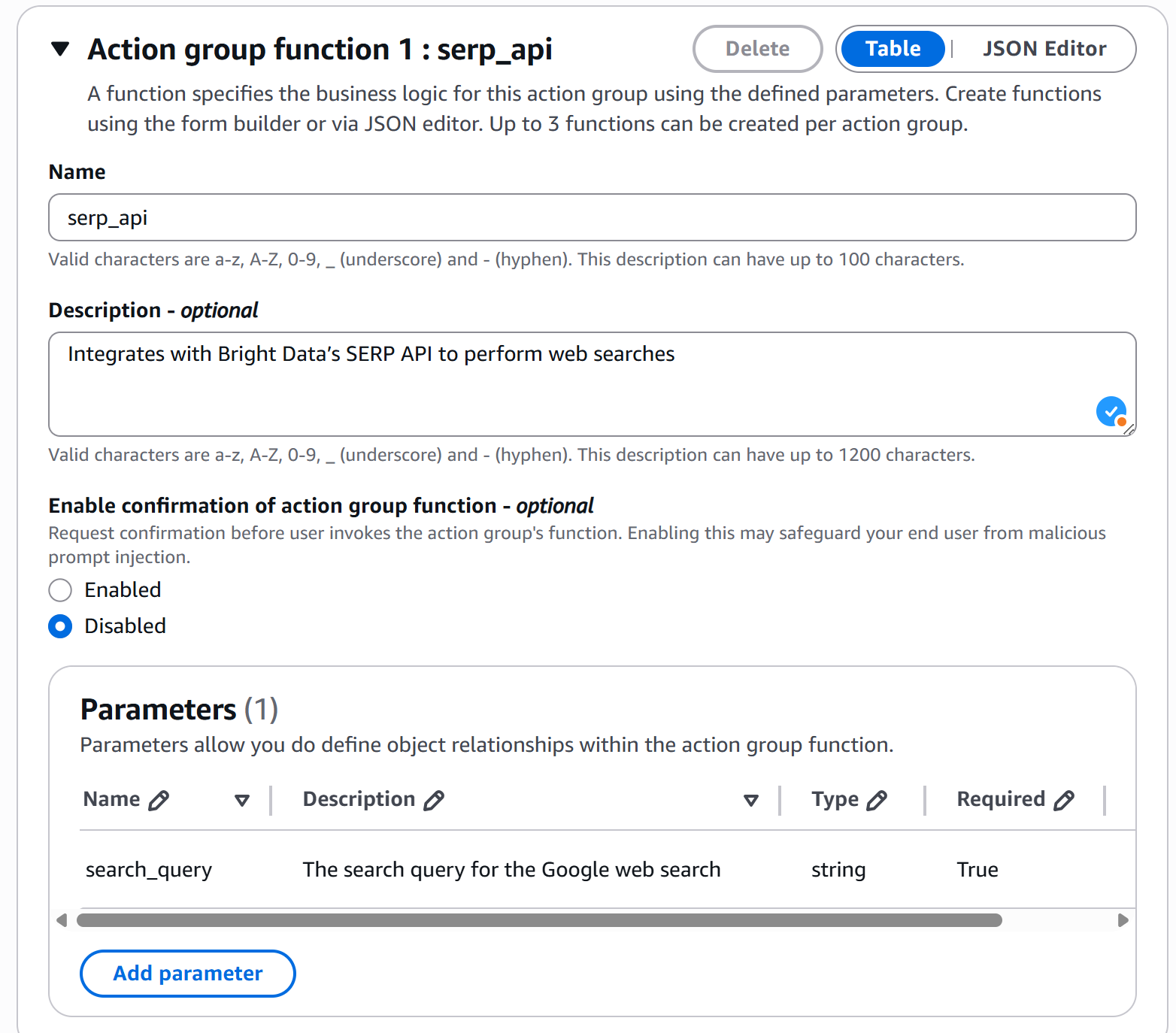
Now, configure the function in the group. Scroll down to the “Action group function 1: serp_api” section and fill it out as follows:
- Name:
serp_api(again, prefer underscores). - Description: “Integrates with Bright Data’s SERP API to perform web searches.”
- Parameters: Add a parameter named
search_queryof type string and mark it as required. This parameter will be passed to the Lambda function and represents the input for the Bright Data SERP API to retrieve web search context.
Finally, click “Create” to complete the action group setup:
Lastly, click “Save” to save your agent configuration. Well done!
Step #4: Set Up Your Bright Data Account
Now, it is time to set up your Bright Data account and configure the SERP API service. Notice that you can either follow the official Bright Data documentation or the steps below.
If you do not already have an account, sign up for Bright Data. Otherwise, log in to your existing account. Once logged in, reach the “My Zones” section in the “Proxies & Scraping” page and check for a “SERP API” row in the table:
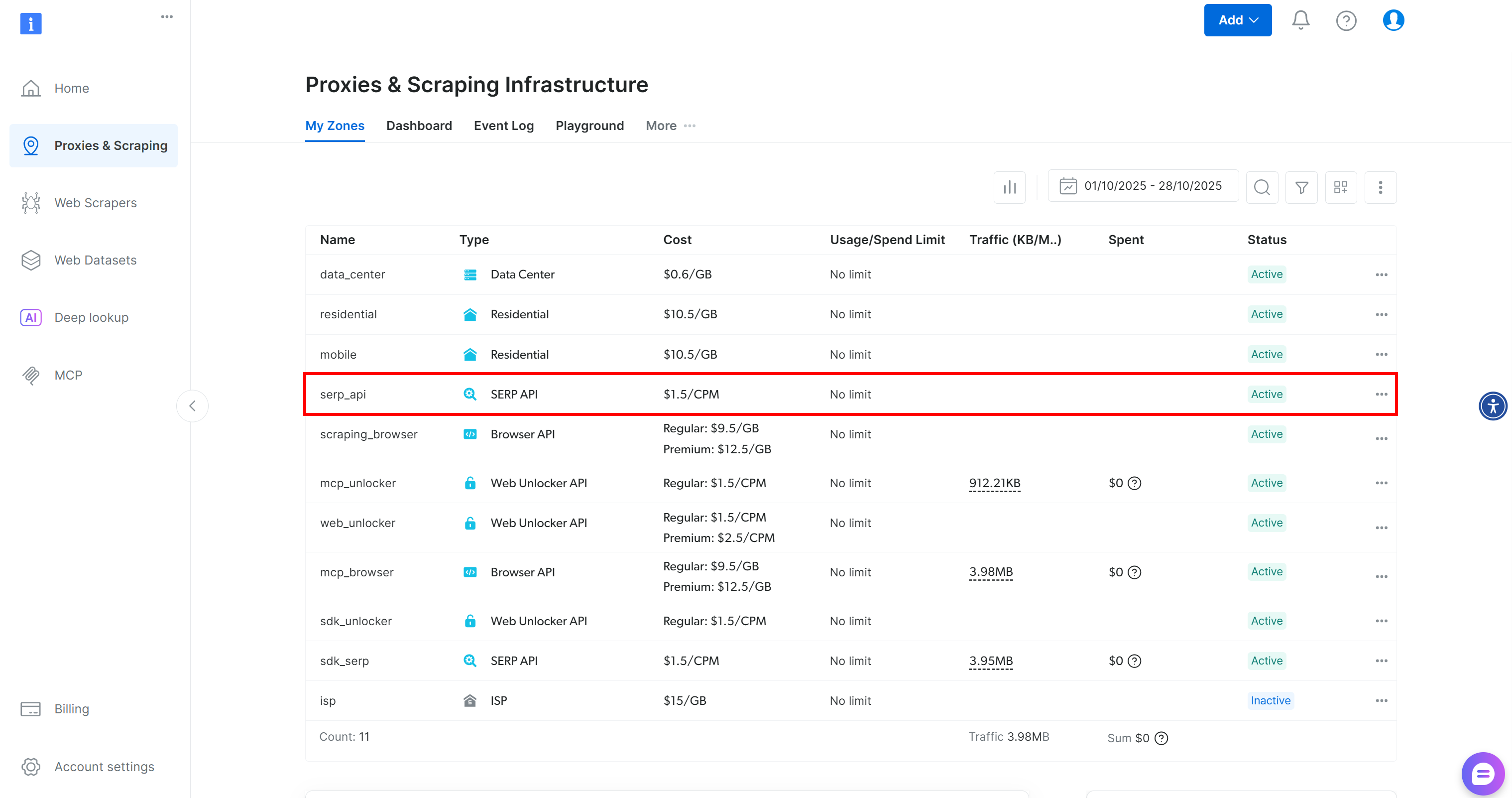
If you do not see a row for SERP API, it means you have not configured a zone yet. Scroll down and click “Create zone” under the “SERP API” section:
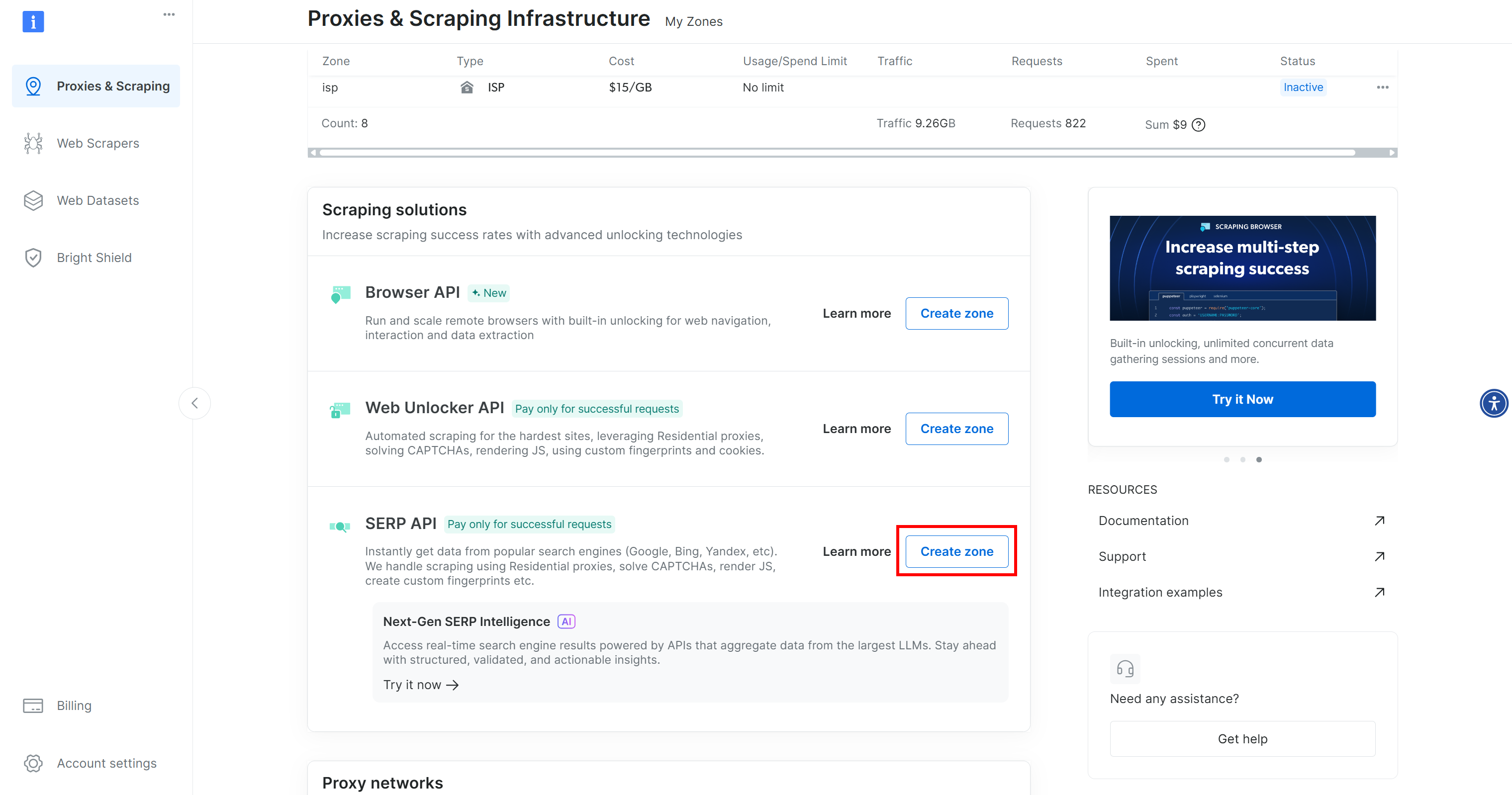
Create a SERP API zone, naming it something like serp_api (or any name you prefer). Keep track of the SERP API zone name, as you will require it to connect via API.
On the product page, toggle the “Activate” switch to enable the zone:
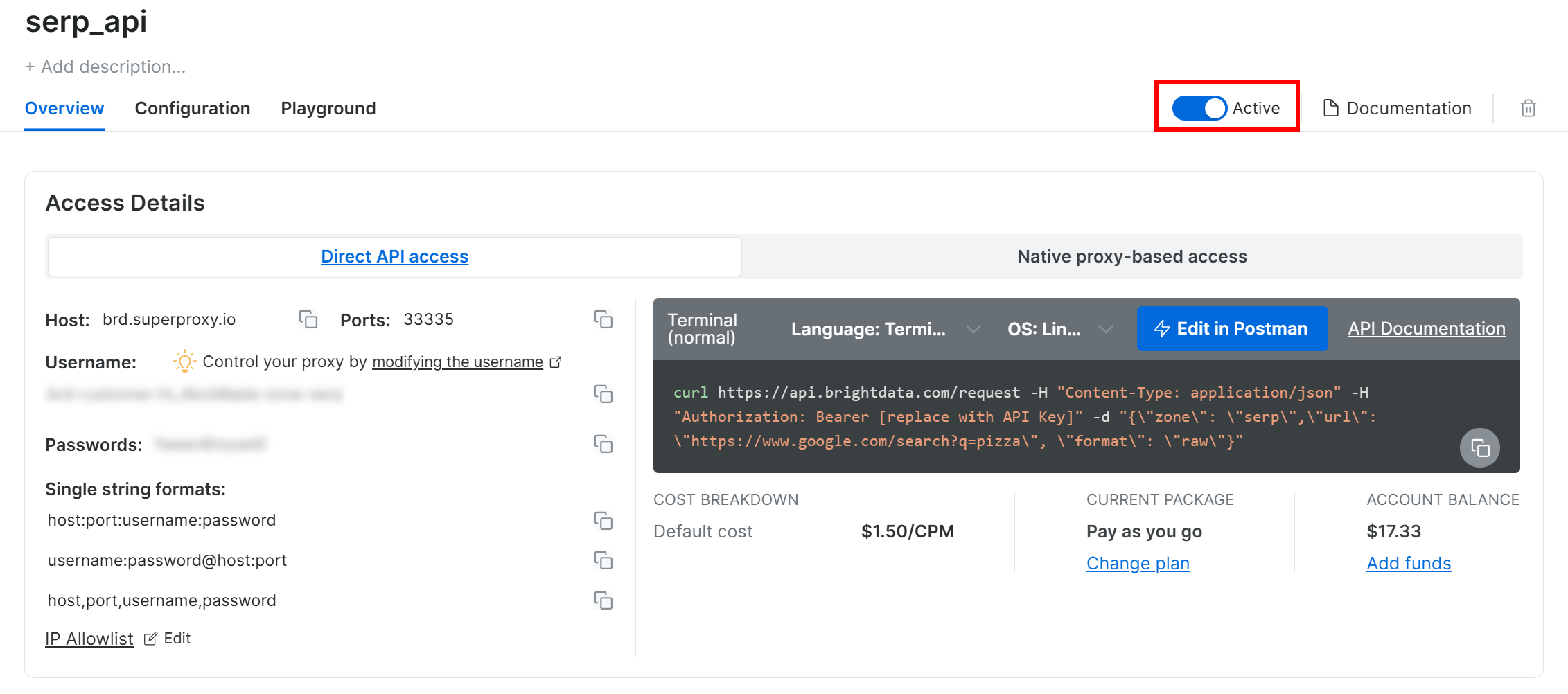
Lastly, follow the official guide to generate your Bright Data API key. Store it in a safe place, as you will need it shortly.
This is it! You now have everything you need to use Bright Data’s SERP API in your AWS Bedrock AI agent.
Step #5: Store Secrets in AWS
In the previous step, you obtained sensitive information, such as your Bright Data API key and your SERP API zone name. Instead of hardcoding these values in your Lambda function code, store them securely in AWS Secrets Manager.
Search for “Secrets Manager” in the AWS search bar and open the service:
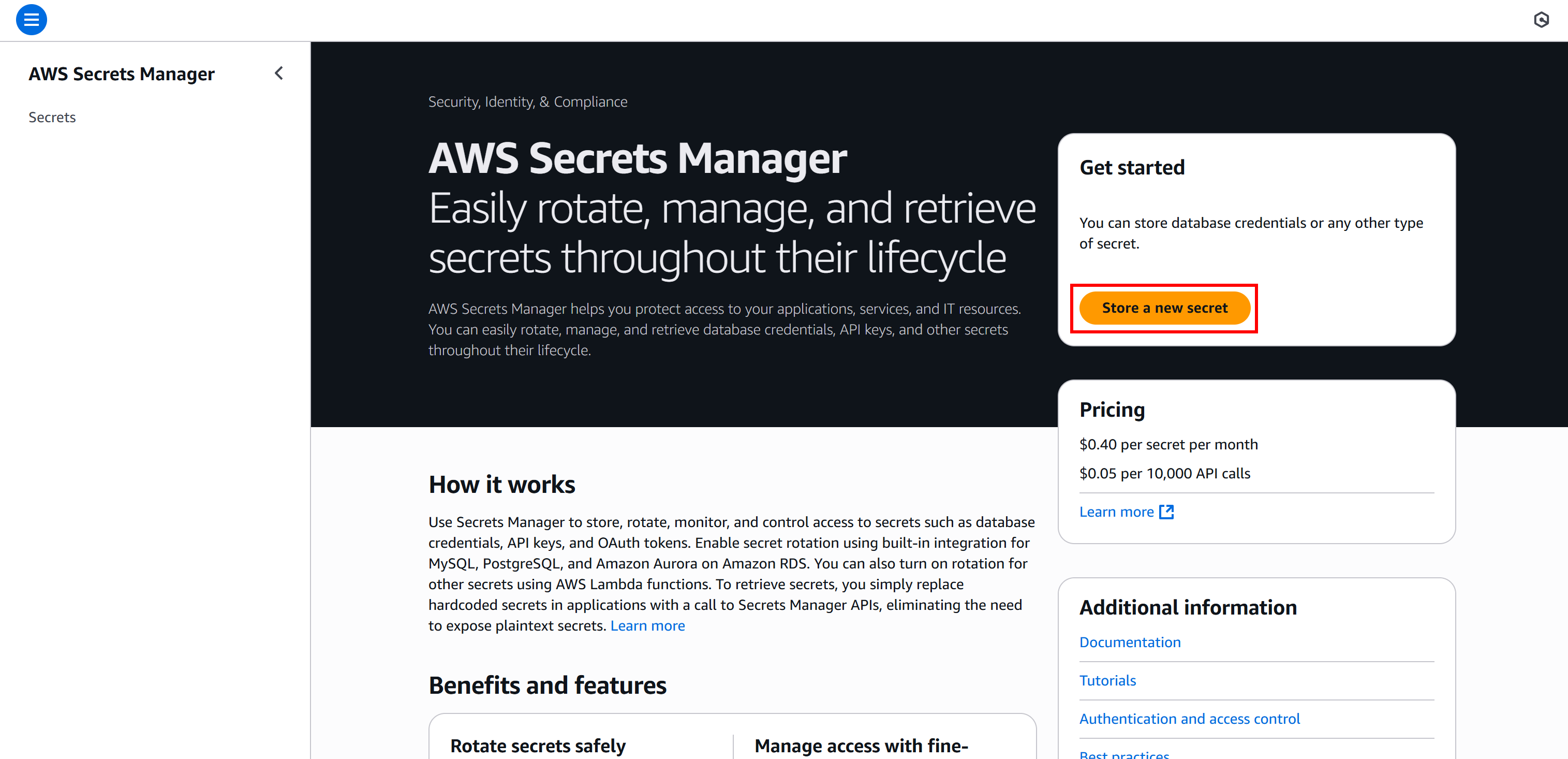
Click the “Store a new secret” button and select the “Other type of secret” option. In the “Key/value pairs” section, add the following key-value pairs:
BRIGHT_DATA_API_KEY: Enter your Bright Data API key obtained earlier.BRIGHT_DATA_SERP_API_ZONE: Enter your Bright Data SERP API zone name (e.g.,serp_api).
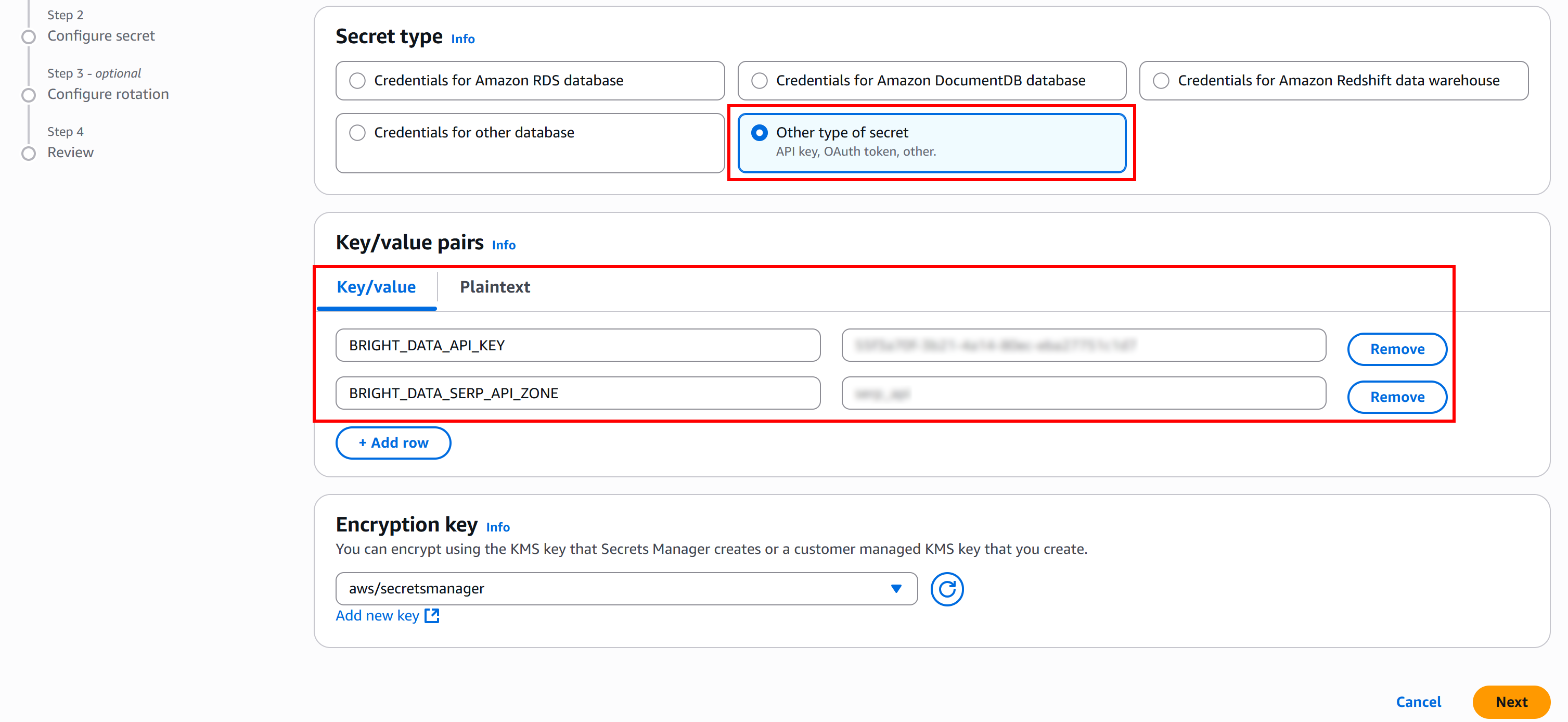
Then, click “Next” and provide a secret name. For example, call it BRIGHT_DATA:
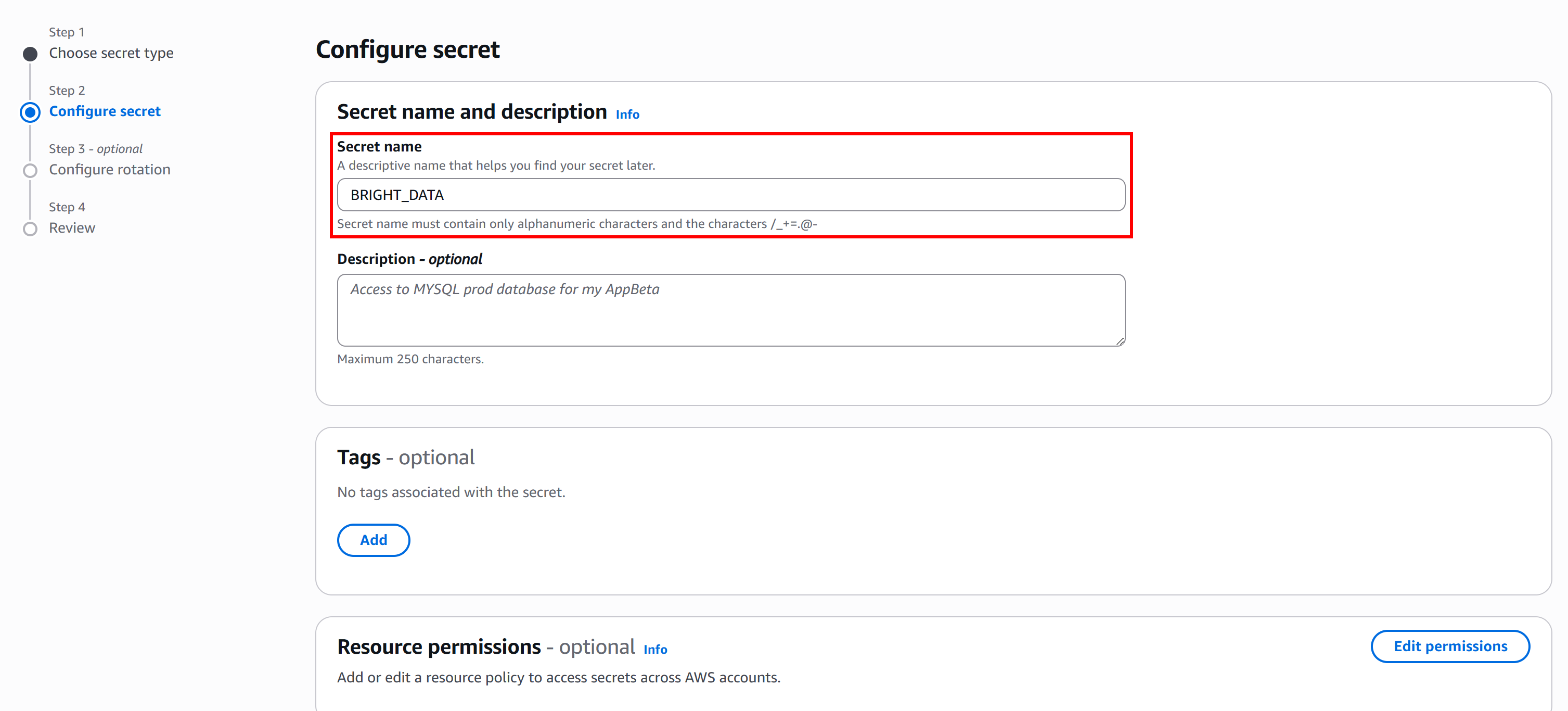
This secret will store a JSON object containing the fields BRIGHT_DATA_API_KEY and BRIGHT_DATA_SERP_API_ZONE.
Complete the secrets creation by following the remaining prompts to finish storing the secret. After completion, your secret will look like this:

Cool! You will access these secrets in your Python Lambda function to securely connect to the Bright Data SERP API, which you will set up in the next step.
Step #6: Create the Lambda Function to Call the SERP API
You have all the building blocks to define the Lambda function associated with the action group created in Step #3. That function will contain the Python code to Bright Data’s SERP API and retrieve web search data.
To create the Lambda, search for “Lambda” in the AWS search bar and open the Amazon Lambda console. You will notice that a function has already been created automatically in Step #3 by AWS Bedrock:
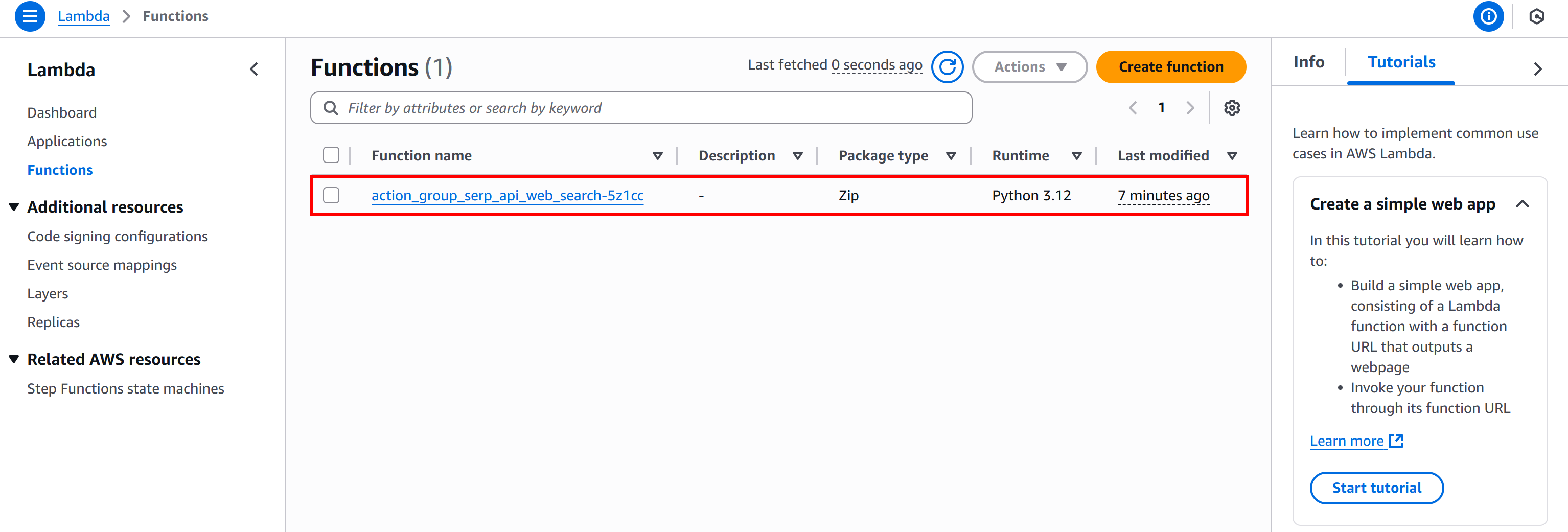
Click on the function named action_group_serp_api_web_search_XXXX to open its overview page:
On this page, scroll down to the Code tab, where you will find a built-in Visual Studio Code editor for editing your Lambda logic:
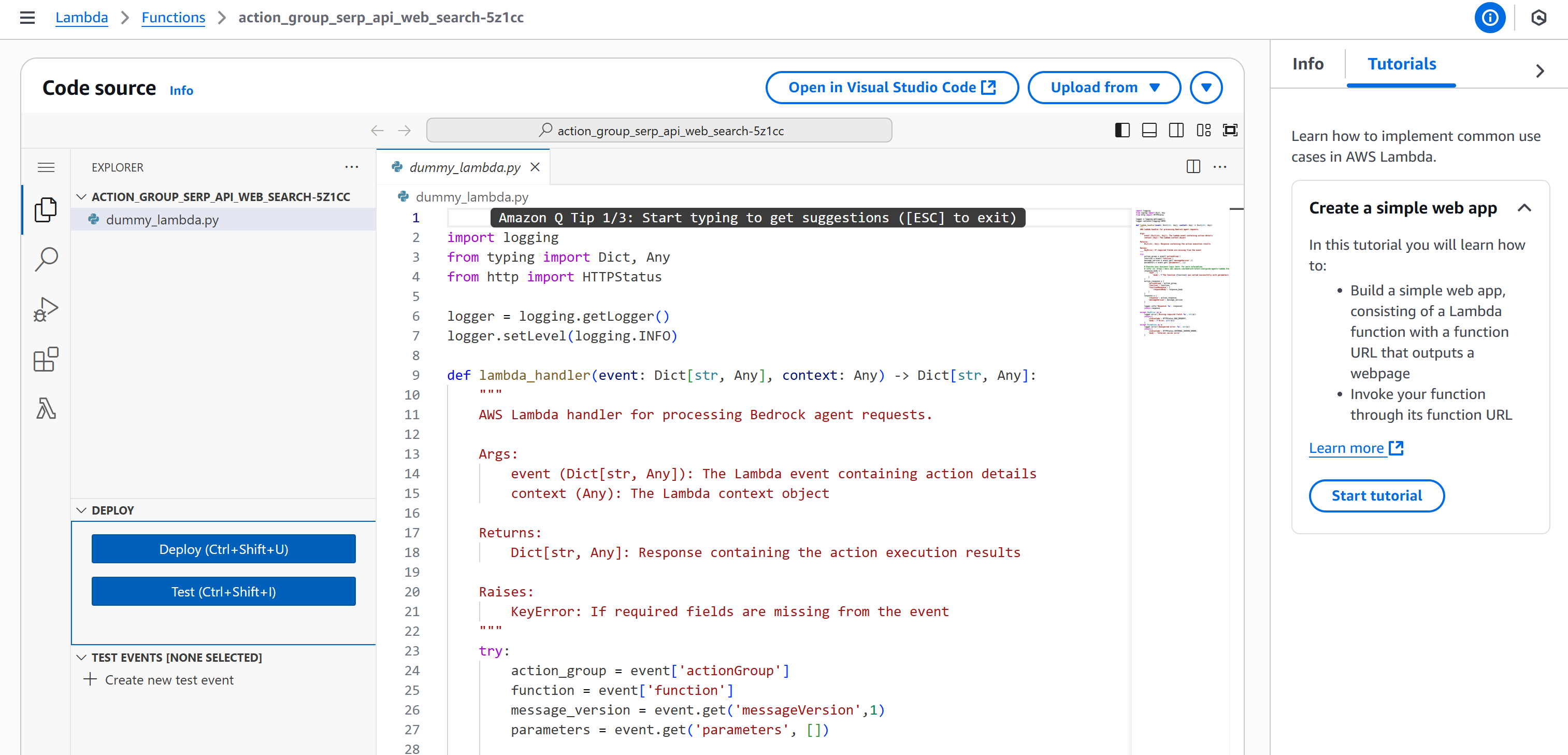
Replace the contents of the dummy_lambda.py file with the following code:
import json
import logging
import os
import urllib.parse
import urllib.request
import boto3
# ----------------------------
# Logging configuration
# ----------------------------
log_level = os.environ.get("LOG_LEVEL", "INFO").strip().upper()
logging.basicConfig(
format="[%(asctime)s] p%(process)s {%(filename)s:%(lineno)d} %(levelname)s - %(message)s"
)
logger = logging.getLogger(__name__)
logger.setLevel(log_level)
# ----------------------------
# AWS Region from environment
# ----------------------------
AWS_REGION = os.environ.get("AWS_REGION")
if not AWS_REGION:
logger.warning("AWS_REGION environment variable not set; boto3 will use default region")
# ----------------------------
# Retrieve the secret object from AWS Secrets Manager
# ----------------------------
def get_secret_object(key: str) -> str:
"""
Get a secret value from AWS Secrets Manager.
"""
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=AWS_REGION
)
try:
get_secret_value_response = client.get_secret_value(
SecretId=key
)
except Exception as e:
logger.error(f"Could not get secret '{key}' from Secrets Manager: {e}")
raise e
secret = json.loads(get_secret_value_response["SecretString"])
return secret
# Retrieve Bright Data credentials
bright_data_secret = get_secret_object("BRIGHT_DATA")
BRIGHT_DATA_API_KEY = bright_data_secret["BRIGHT_DATA_API_KEY"]
BRIGHT_DATA_SERP_API_ZONE = bright_data_secret["BRIGHT_DATA_SERP_API_ZONE"]
# ----------------------------
# SERP API Web Search
# ----------------------------
def serp_api_web_search(search_query: str) -> str:
"""
Calls Bright Data SERP API to retrieve Google search results.
"""
logger.info(f"Executing Bright Data SERP API search for search_query='{search_query}'")
# Encode the query for URL
encoded_query = urllib.parse.quote(search_query)
# Build the Google URL to scrape the SERP from
search_engine_url = f"https://www.google.com/search?q={encoded_query}"
# Bright Data API request (docs: https://docs.brightdata.com/scraping-automation/serp-api/send-your-first-request)
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"
}
data = {
"zone": BRIGHT_DATA_SERP_API_ZONE,
"url": search_engine_url,
"format": "raw",
"data_format": "markdown" # To get the SERP as an AI-ready Markdown document
}
payload = json.dumps(data).encode("utf-8")
request = urllib.request.Request(url, data=payload, headers=headers)
try:
response = urllib.request.urlopen(request)
response_data: str = response.read().decode("utf-8")
logger.debug(f"Response from SERP API: {response_data}")
return response_data
except urllib.error.HTTPError as e:
logger.error(f"Failed to call Bright Data SERP API. HTTP Error {e.code}: {e.reason}")
except urllib.error.URLError as e:
logger.error(f"Failed to call Bright Data SERP API. URL Error: {e.reason}")
return ""
# ----------------------------
# Lambda handler
# ----------------------------
def lambda_handler(event, _):
"""
AWS Lambda handler.
Expects event with actionGroup, function, and optional parameters including search_query.
"""
logger.debug(f"lambda_handler called with event: {event}")
action_group = event.get("actionGroup")
function = event.get("function")
parameters = event.get("parameters", [])
# Extract search_query from parameters
search_query = next(
(param["value"] for param in parameters if param.get("name") == "search_query"),
None,
)
logger.debug(f"Input search query: {search_query}")
serp_page = serp_api_web_search(search_query) if search_query else ""
logger.debug(f"Search query results: {serp_page}")
# Prepare the Lambda response
function_response_body = {"TEXT": {"body": serp_page}}
action_response = {
"actionGroup": action_group,
"function": function,
"functionResponse": {"responseBody": function_response_body},
}
response = {"response": action_response, "messageVersion": event.get("messageVersion")}
logger.debug(f"lambda_handler response: {response}")
return responseThis snippet retrieves Bright Data API credentials from AWS Secrets Manager, calls the SERP API with a Google search query, and returns the search results as Markdown text. For more information on how to call the SERP API, refer to the docs.
Paste the above code into the online IDE:
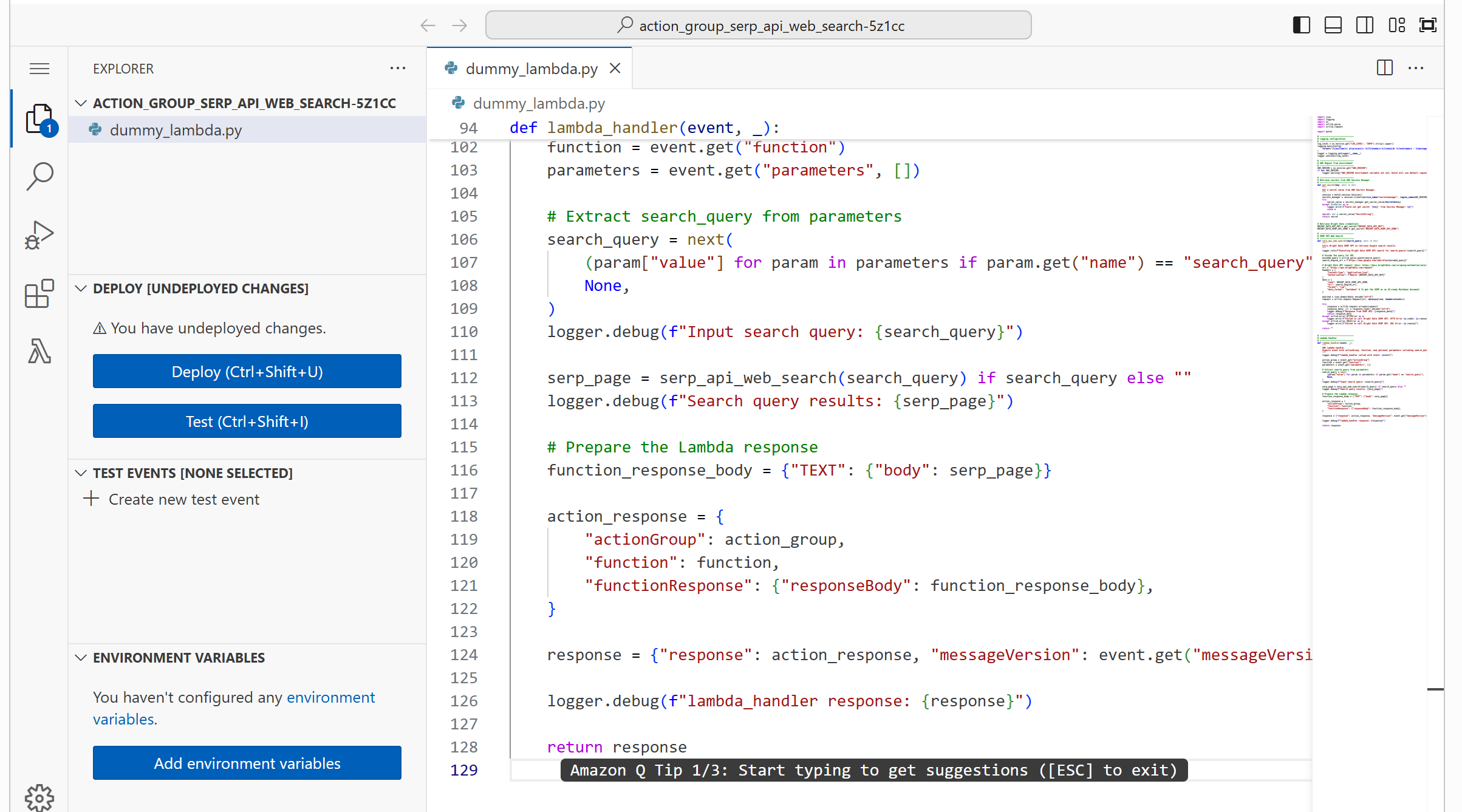
Then, press “Deploy” to update the Lambda function:
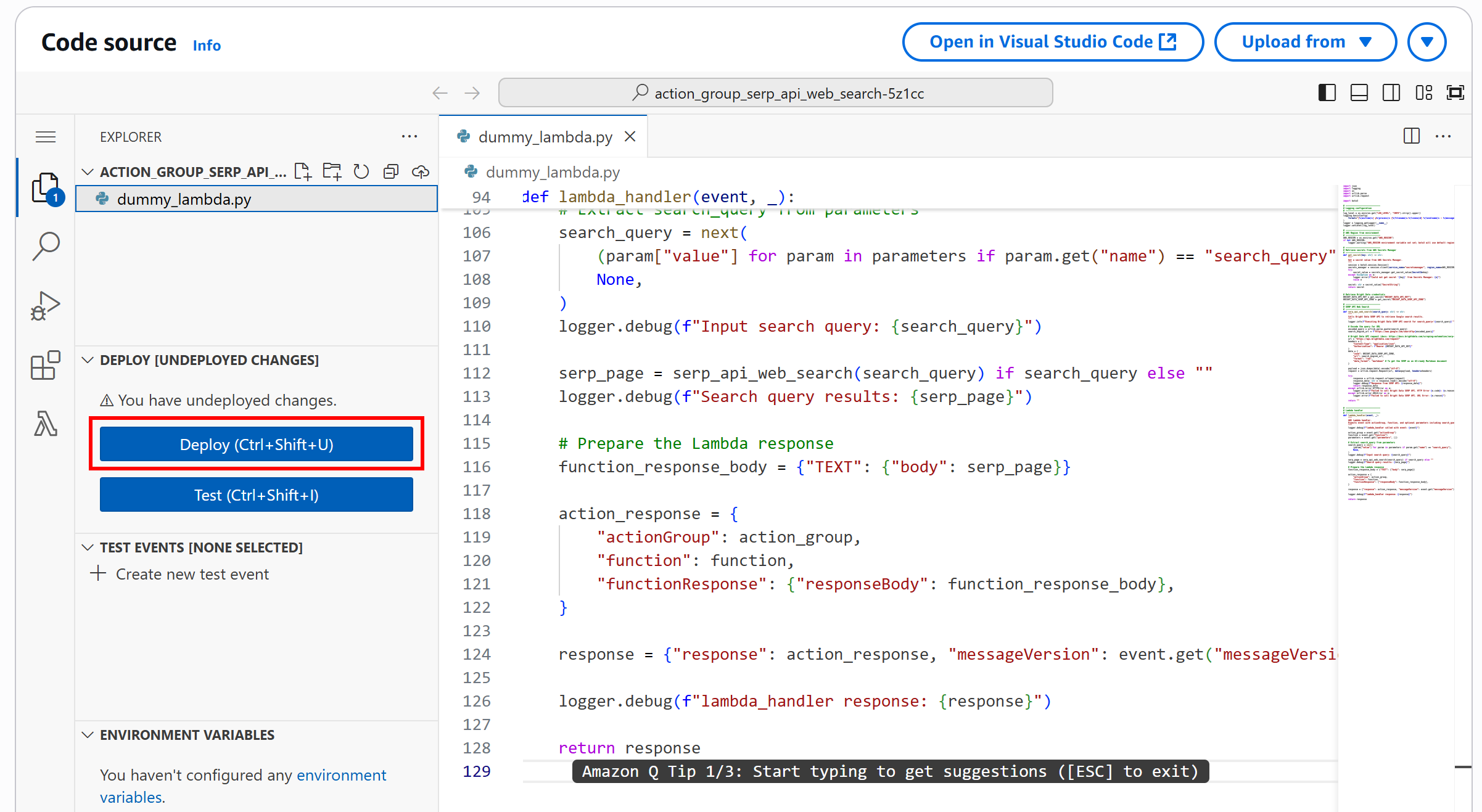
If everything goes as expected, you will receive a message like “Successfully updated the function action_group_serp_api_web_search_XXXX.”
Note: The Lambda function is automatically configured with a resource-based policy that allows Amazon Bedrock to invoke it. Since this was handled by the “Quick create a new Lambda function” option earlier, there is no need to manually modify the IAM role.
Perfect! Your AWS Lambda function for connecting to the Bright Data SERP API is now complete.
Step #7: Configure Lambda Permissions
While your Lambda function does not require custom IAM permissions to be invoked, it does need access to the API keys stored in AWS Secrets Manager.
To configure that, on the Lambda function details page, go to the “Configuration” tab, then select the “Permissions” option:
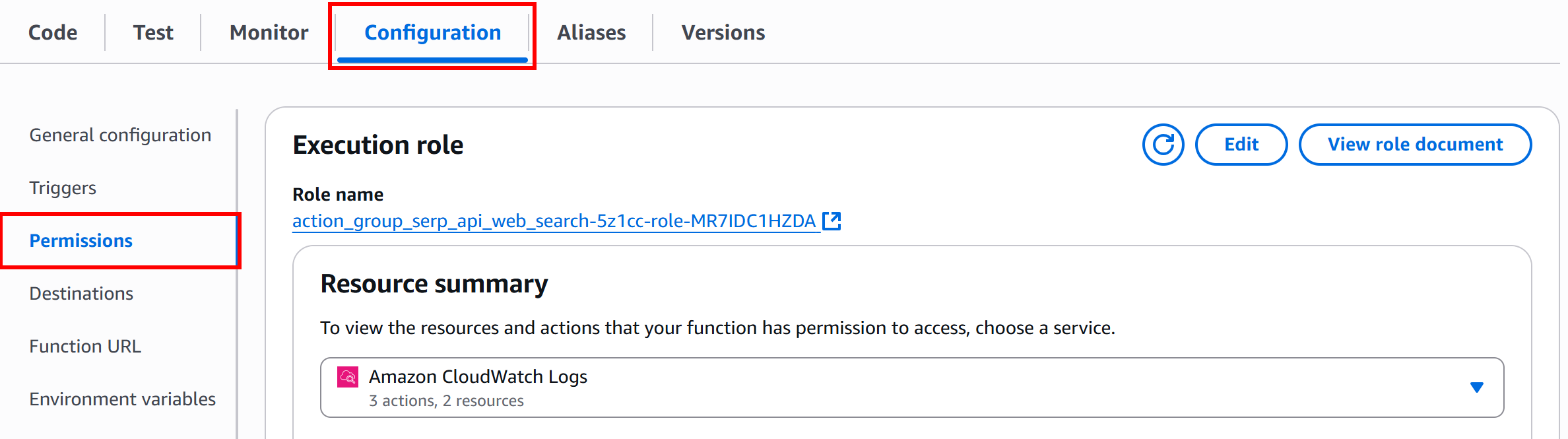
Under the “Execution role” section, click the “Role name” link to open the IAM console:
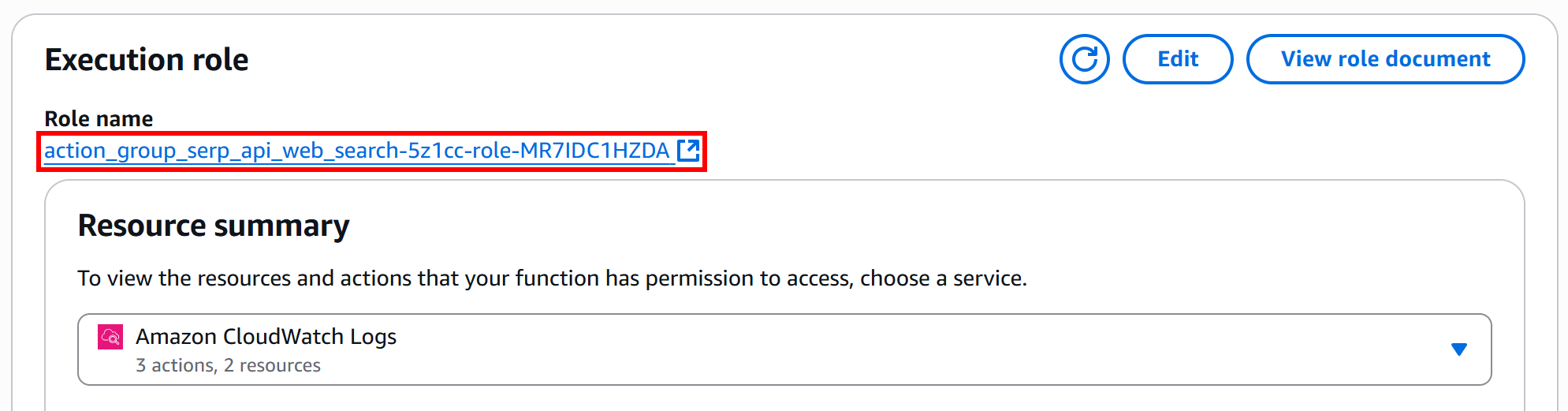
On the role page, locate and select the attached permission policy:
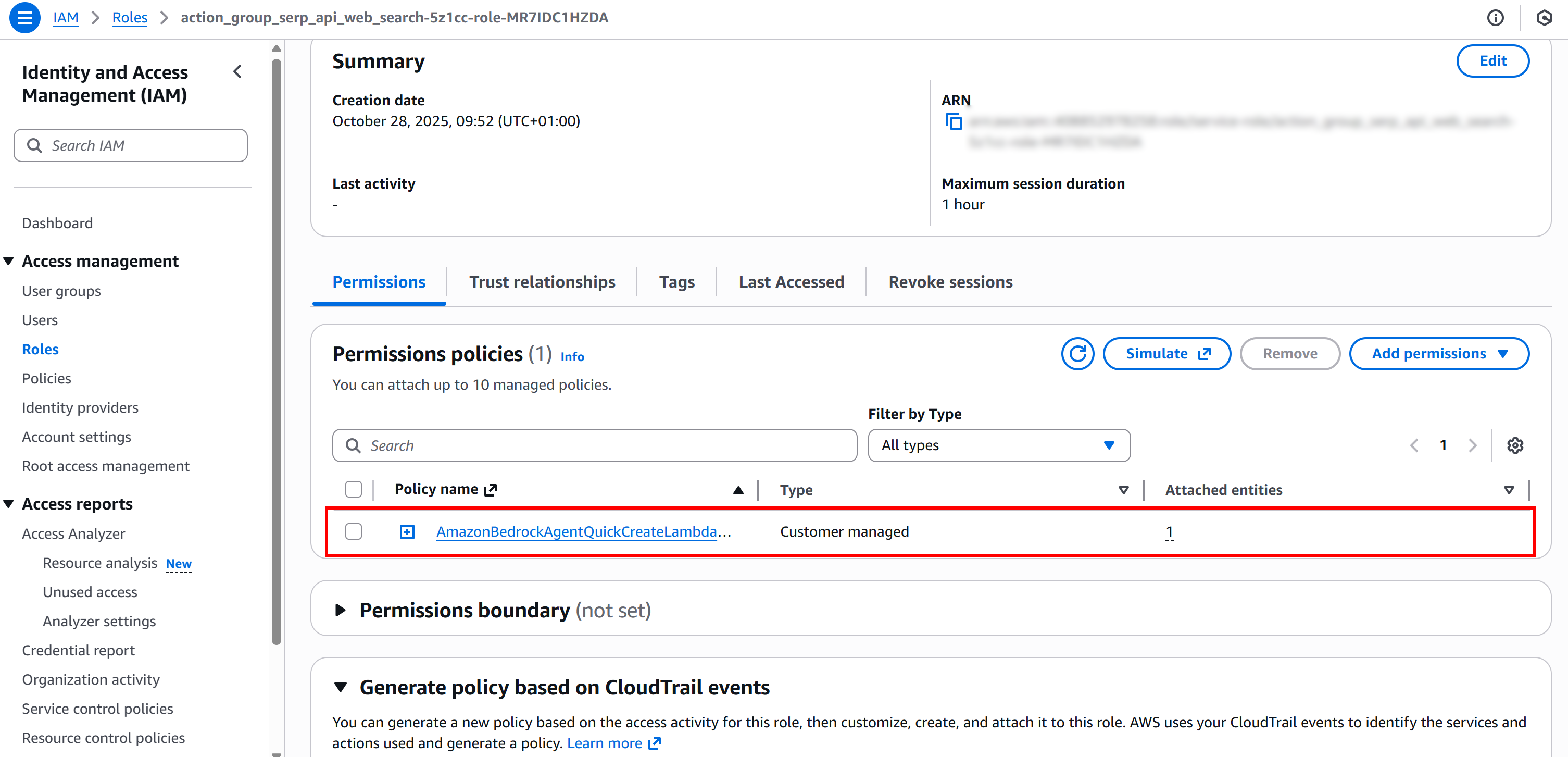
Open the “JSON” view and then click “Edit” to prepare to update the permission policy:
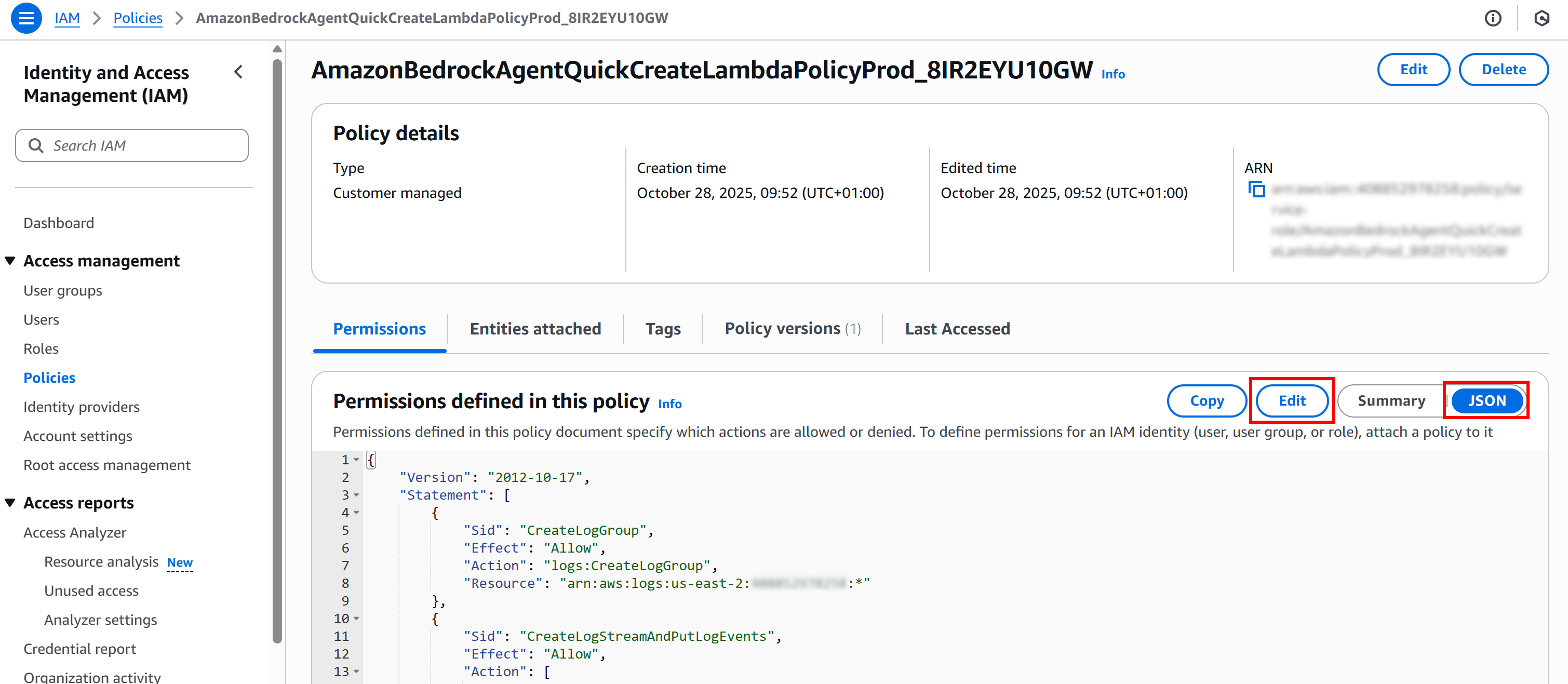
Make sure the Statement array includes the following block:
{
"Action": "secretsmanager:GetSecretValue",
"Resource": [
"arn:aws:secretsmanager:<YOUR_AWS_REGION>:<YOUR_AWS_ACCOUNT_ID>:secret:BRIGHT_DATA*"
],
"Effect": "Allow",
"Sid": "GetSecretsManagerSecret"
}Replace <YOUR_AWS_REGION> and <YOUR_AWS_ACCOUNT_ID> with the correct values for your setup. That block of JSON code will give the Lambda function the ability to access the BRIGHT_DATA secret from the Secrets Manager.
Then, click the “Next” button, and finally “Save changes.” As a result, you should see that your Lambda function also has Secrets Manager access permissions:
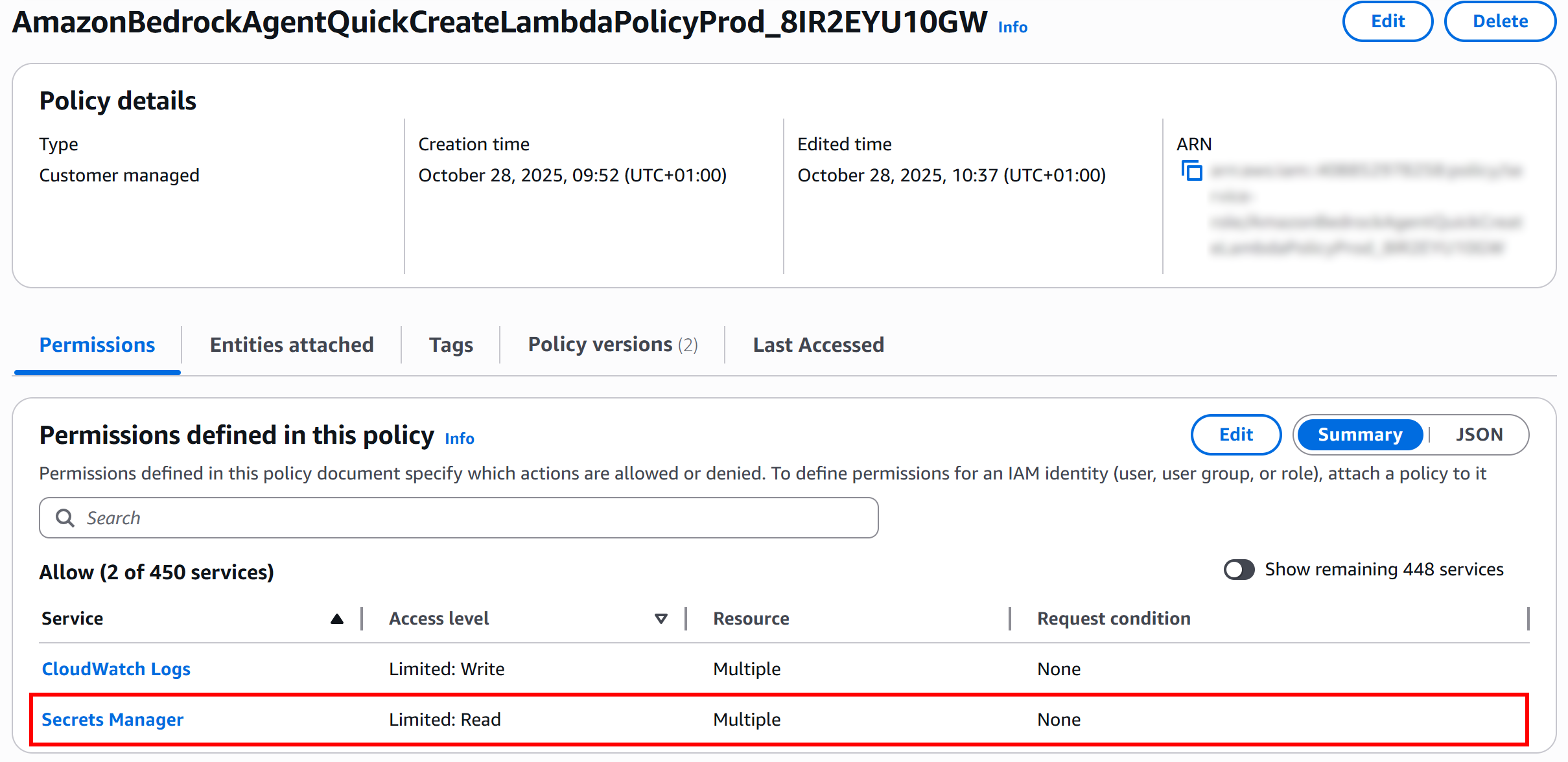
Fantastic! Your Lambda function is now properly configured and can be invoked by your AWS Bedrock AI agent with access to the Bright Data credentials stored in Secrets Manager.
Step #8: Finalize Your AI Agent
Go back to the “Agent builder” section and click “Save” one last time to apply all the changes you made earlier:
Next, click “Prepare” to ready your agent for testing with the latest configuration.

You should get a confirmation message like “Agent: web_search_agent was successfully prepared.”
Mission complete! Your Bright Data SERP API-powered AI agent is now fully implemented and ready to go.
Step #9: Test Your AI Agent
Your AWS Bedrock AI Agent has access to the serp_api group function, implemented by the lambda_handler Lambda function you defined in Step #6. In simpler terms, your agent can perform real-time web searches on Google (and potentially other search engines) via the Bright Data SERP API, retrieving and processing fresh online content dynamically.
To test this capability, let’s assume you want to fetch the latest news about Hurricane Melissa. Try prompting your agent with:
"Give me the top 3 latest news articles on Hurricane Melissa"(Remember: This is just an example, and you can test any other prompt involving real-time web search results.)
Run this prompt in the “Test Agent” section of your agent, and you should see an output similar to this:
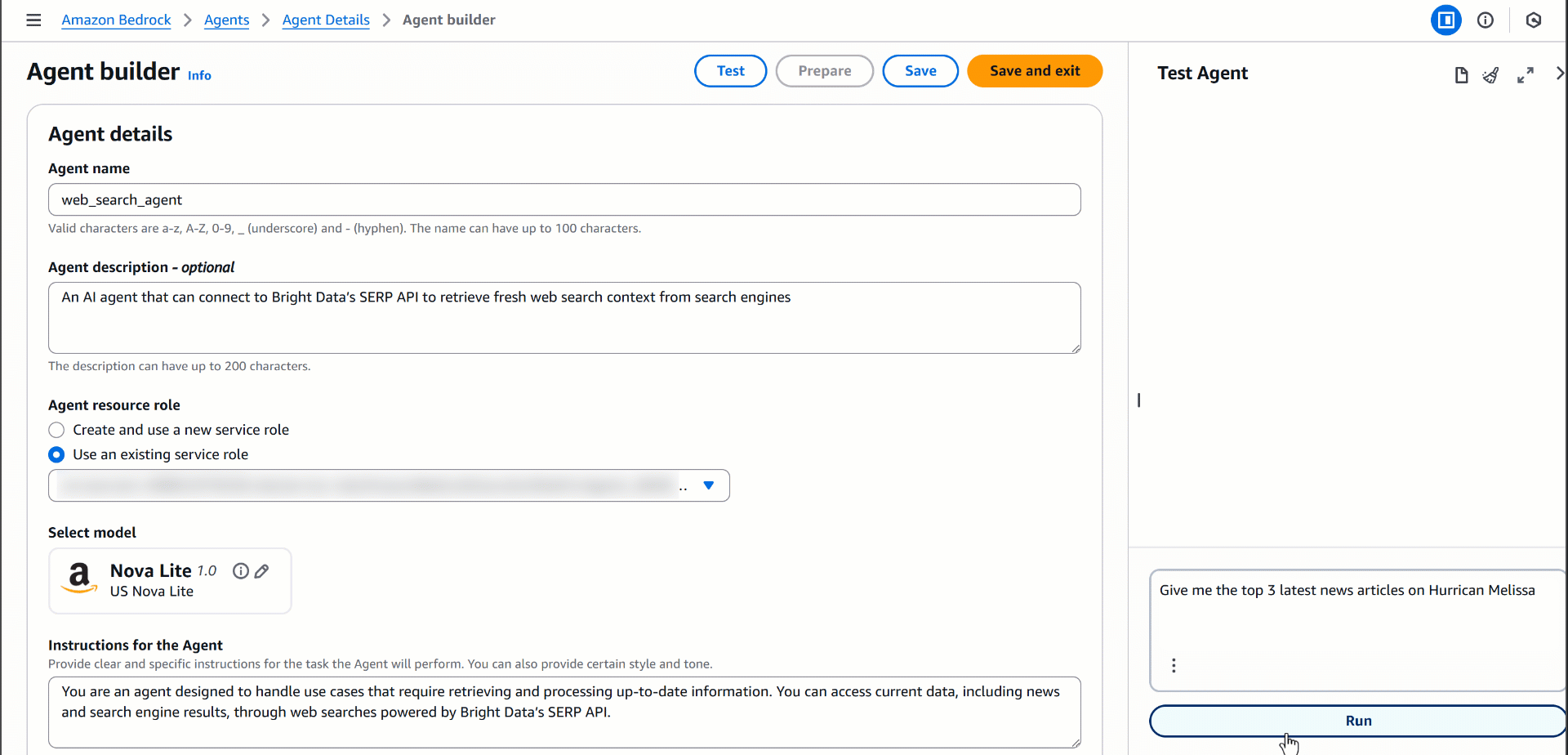
Behind the scenes, the agent invokes the SERP API Lambda, retrieves the latest Google Search results for “Hurricane Melissa,” and extracts the top relevant news items with their URLs. That is something any vanilla LLM, including Nova Lite, cannot achieve on its own!
This is the specific text response generated by the agent (with URLs omitted):
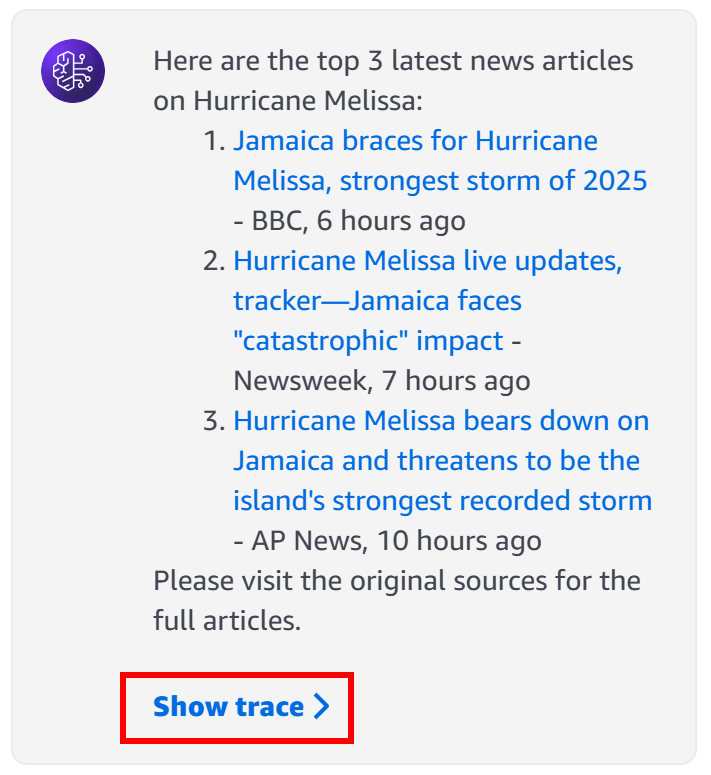
Here are the top 3 latest news articles on Hurricane Melissa:
1. Jamaica braces for Hurricane Melissa, strongest storm of 2026 - BBC, 6 hours ago
2. Hurricane Melissa live updates, tracker—Jamaica faces "catastrophic" impact - Newsweek, 7 hours ago
3. Hurricane Melissa bears down on Jamaica and threatens to be the island's strongest recorded storm - AP News, 10 hours ago
Please visit the original sources for the full articles.These results are not hallucinations! On the contrary, they match what you would find on Google when manually searching for “Hurricane Melissa” (as of the date the agent was tested):
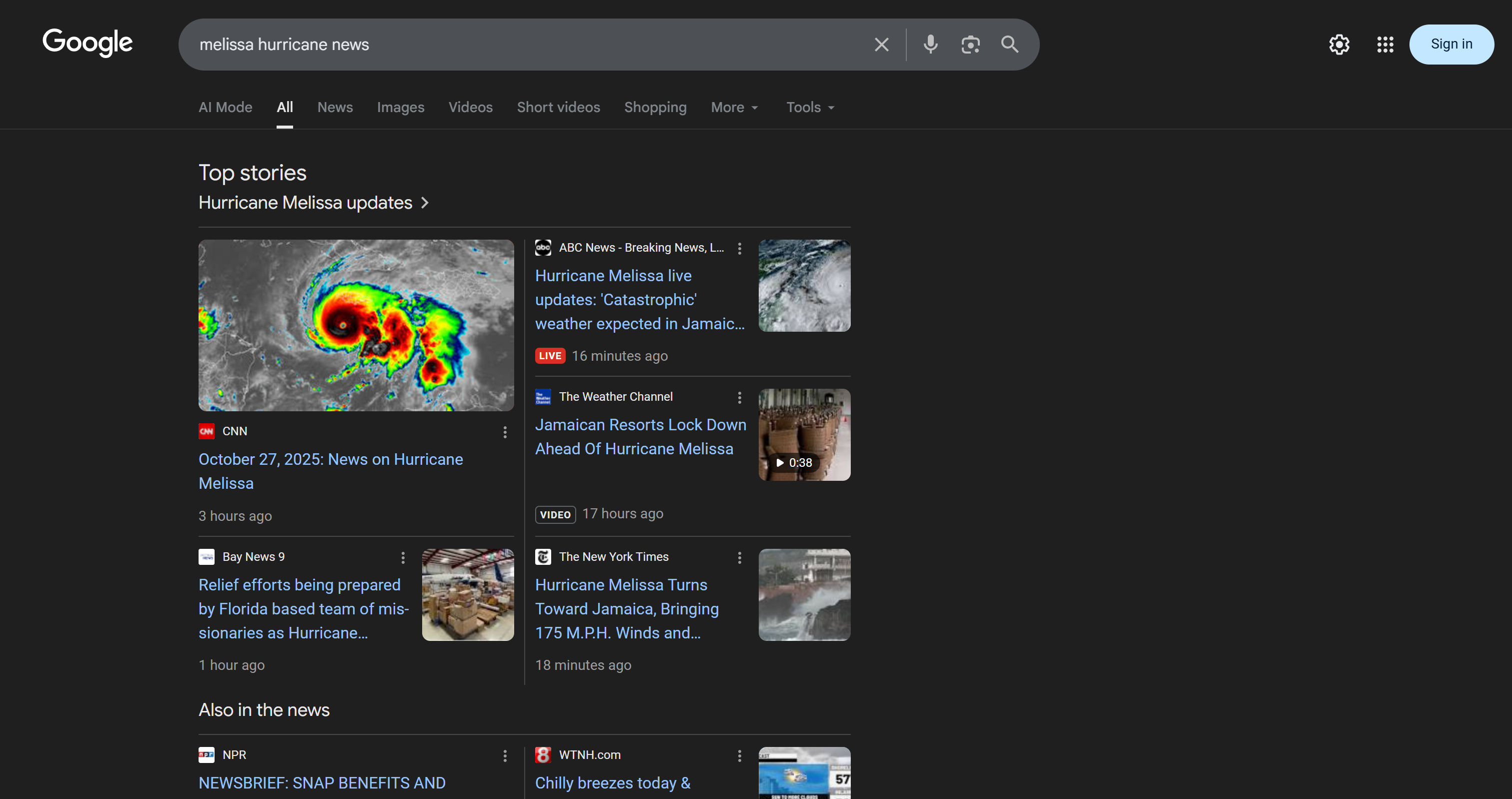
Now, if you have ever tried scraping Google search results, you know how difficult it can be due to bot detection, IP bans, JavaScript rendering, and many other challenges.
The Bright Data SERP API solves all of that efficiently, and its ability to return scraped SERPs in AI-optimized Markdown format (which is especially valuable for LLM ingestion).
To confirm that your agent actually called the SERP API Lambda, click “Show trace”:
In the “Trace step 1” section, scroll down to the group invocation log section to see the output from the function call:
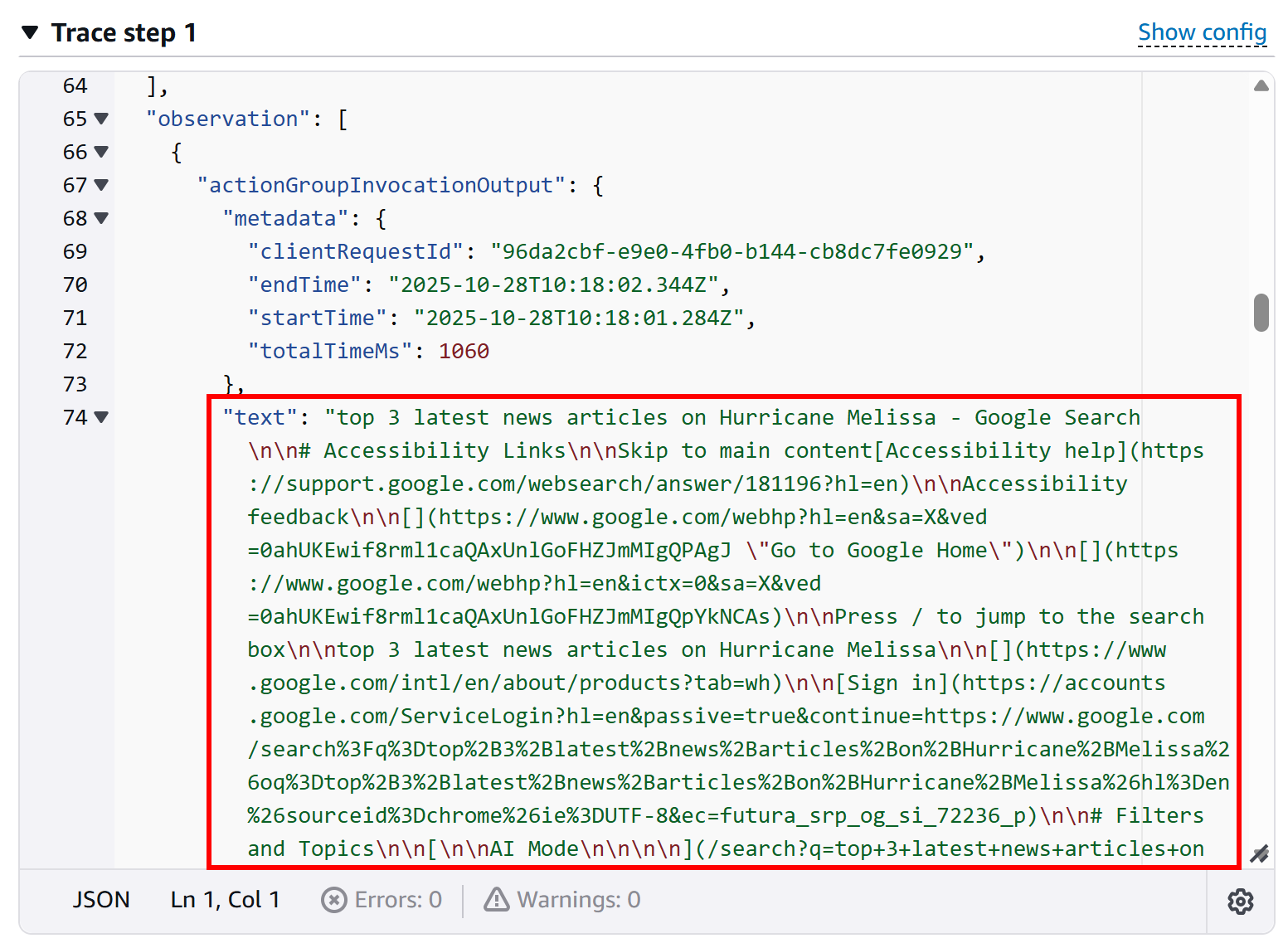
This confirms that the Lambda function successfully executed, and the agent interacted with the SERP API as intended. Similarly, verify that by checking the AWS CloudWatch logs for your Lambda.
Now to push your agent further! Try prompts related to fact-checking, brand monitoring, market trend analysis, or other scenarios. See how your agent performs in different use cases.
Et voilà! You just built an AWS Bedrock AI Agent integrated with Bright Data’s SERP API, capable of retrieving up-to-date, trusted, and contextual web search data on demand.
[Extra] Build an Amazon Bedrock Agent with Web Search Using AWS CDK
In the previous section, you learned how to define and implement an AI agent that integrates with the SERP API directly through the Amazon Bedrock console.
If you prefer a code-first approach, you can achieve the same result using the AWS Cloud Development Kit (AWS CDK). This method follows the same overall steps but manages everything locally within an AWS CDK project.
For detailed guidance, refer to the official AWS guide. You should also take a look at the GitHub repository supporting that tutorial. This codebase can be easily adapted to work with Bright Data’s SERP API.
Conclusion
In this blog post, you saw how to integrate Bright Data’s SERP API into an AWS Bedrock AI agent. This workflow is ideal for anyone looking to build more powerful, context-aware AI agents in AWS.
To create even more advanced AI workflows, explore Bright Data’s infrastructure for AI. You will find a suite of tools for retrieving, validating, and transforming live web data.
Sign up for a free Bright Data account today and start experimenting with our AI-ready web data solutions!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



