

Google Flights is a widely used flight booking service that provides a wealth of data, including flight prices, schedules, and airline details. Unfortunately, Google does not offer a public API to access this data. However, web scraping can be a great alternative to extracting this data.
In this article, I’ll show you how to build a robust Google Flights scraper using Python. We’ll go through each step to make sure everything is clear.
Why Scrape Google Flights?
Scraping Google Flights provides several advantages, including:
- Tracking flight prices over time
- Analyzing price trends
- Identifying the best times to book flights
- Comparing prices across different dates and airlines
For travelers, this leads to finding the best deals and saving money. For businesses, It helps in market analysis, competitive intelligence, and developing effective pricing strategies.
Building the Google Flights Scraper
The scraper we build will allow you to input details such as the departure airport, destination, travel date, and ticket type (either one-way or round-trip). If you are booking a round trip, you will also need to provide a return date. The scraper will take care of the rest: it loads all available flights, scrapes the data, and saves the results in a JSON file for further analysis.
If you’re new to web scraping with Python, check out this tutorial to get started.
1. What Data Can You Extract from Google Flights?
Google Flights provide lots of data, including airline names, departure and arrival times, total duration, number of stops, ticket prices, and environmental impact data (e.g., CO2 emissions).

Here’s an example of the data you can scrape:
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
}
2. Setting Up the Environment
First, let’s set up the environment in your system to run the scraper.
# Create a virtual environment (optional)
python -m venv flight-scraper-env
# Activate the virtual environment
# On Windows:
.flight-scraper-envScriptsactivate
# On macOS/Linux:
source flight-scraper-env/bin/activate
# Install required packages
pip install playwright tenacity asyncio
# Install Playwright browsers
playwright install chromium
Playwright is ideal for automating browsers and interacting with dynamic web pages, such as Google Flights. We use Tenacity to implement a retry mechanism.
If you’re new to Playwright, make sure to check out the guide on Web Scraping with Playwright.
3. Defining Data Classes
Using Python’s dataclass, you can neatly structure the search parameters and flight data.
from dataclasses import dataclass
from typing import Optional
@dataclass
class SearchParameters:
departure: str
destination: str
departure_date: str
return_date: Optional[str] = None
ticket_type: str = "One way"
@dataclass
class FlightData:
airline: str
departure_time: str
arrival_time: str
duration: str
stops: str
price: str
co2_emissions: str
emissions_variation: str
Here, the SearchParameters class stores flight search details such as departure, destination, dates, and ticket type, while the FlightData class stores data about each flight, including airline, price, CO2 emissions, and other relevant details.
4. Scraper Logic in the FlightScraper Class
The main scraping logic is encapsulated in the FlightScraper class. Here’s a detailed breakdown:
4.1 Defining CSS Selectors
You need to locate specific elements on the Google Flights page to extract data. This is done using CSS selectors. Here’s how the selectors are defined in the FlightScraper class:
class FlightScraper:
SELECTORS = {
"airline": "div.sSHqwe.tPgKwe.ogfYpf",
"departure_time": 'span[aria-label^="Departure time"]',
"arrival_time": 'span[aria-label^="Arrival time"]',
"duration": 'div[aria-label^="Total duration"]',
"stops": "div.hF6lYb span.rGRiKd",
"price": "div.FpEdX span",
"co2_emissions": "div.O7CXue",
"emissions_variation": "div.N6PNV",
}
These selectors target the airline name, flight timings, duration, stops, price, and emissions data.
Airline Name:

Departure Time:
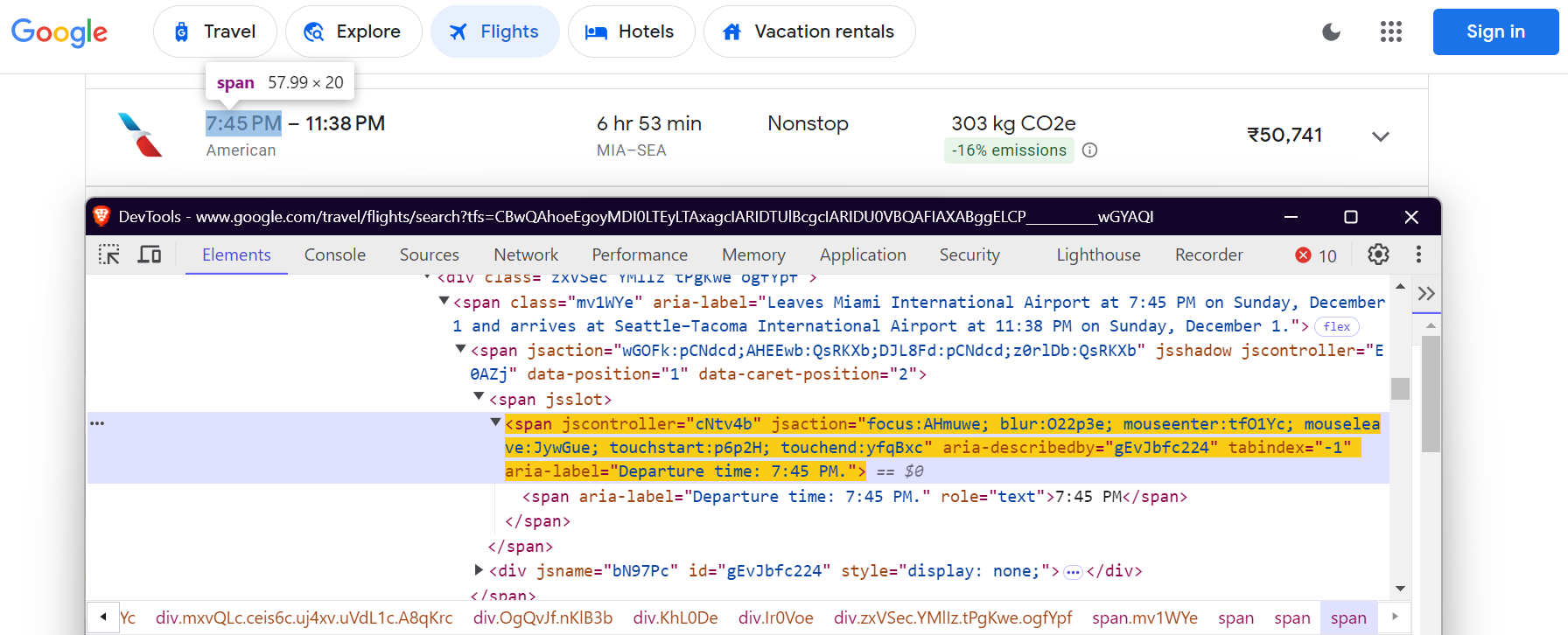
Arrival Time:

Flight Duration:

Number of Stops:

Price:

CO2e:

CO2 Emissions Variation:

4.2 Filling the Search Form
The _fill_search_form method simulates filling out the search form with departure, destination, and date details:
async def _fill_search_form(self, page, params: SearchParameters) -> None:
# First, let's pick our ticket type
ticket_type_div = page.locator("div.VfPpkd-TkwUic[jsname='oYxtQd']").first
await ticket_type_div.click()
await page.wait_for_selector("ul[aria-label='Select your ticket type.']")
await page.locator("li").filter(has_text=params.ticket_type).nth(0).click()
# Now, let's fill in our departure and destination
from_input = page.locator("input[aria-label='Where from?']")
await from_input.click()
await from_input.fill("")
await page.keyboard.type(params.departure)
# ... rest of the form filling code
4.3 Loading All Results
Google Flights uses pagination to load flights. You need to click the “Show more flights” button to load all available flights:
async def _load_all_flights(self, page) -> None:
while True:
try:
more_button = await page.wait_for_selector(
'button[aria-label*="more flights"]', timeout=5000
)
if more_button:
await more_button.click()
await page.wait_for_timeout(2000)
else:
break
except:
break
4.4 Extracting Flight Data
Once the flights are loaded, you can scrape the flight details:
async def _extract_flight_data(self, page) -> List[FlightData]:
await page.wait_for_selector("li.pIav2d", timeout=30000)
await self._load_all_flights(page)
flights = await page.query_selector_all("li.pIav2d")
flights_data = []
for flight in flights:
flight_info = {}
for key, selector in self.SELECTORS.items():
element = await flight.query_selector(selector)
flight_info[key] = await self._extract_text(element)
flights_data.append(FlightData(**flight_info))
return flights_data
5. Adding a Retry Mechanism
To make our scraper more reliable, add retry logic using the tenacity library:
@retry(stop=stop_after_attempt(3), wait=wait_fixed(5))
async def search_flights(self, params: SearchParameters) -> List[FlightData]:
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) ..."
)
# ... rest of the search implementation
6. Saving Scraped Results
Save the scraped flight data into a JSON file for future analysis.
def save_results(self, flights: List[FlightData], params: SearchParameters) -> str:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = (
f"flight_results_{params.departure}_{params.destination}_{timestamp}.json"
)
output_data = {
"search_parameters": {
"departure": params.departure,
"destination": params.destination,
"departure_date": params.departure_date,
"return_date": params.return_date,
"search_timestamp": timestamp,
},
"flights": [vars(flight) for flight in flights],
}
filepath = os.path.join(self.results_dir, filename)
with open(filepath, "w", encoding="utf-8") as f:
json.dump(output_data, f, indent=2, ensure_ascii=False)
return filepath
7. Running the Scraper
Here’s how to run the Google Flights scraper:
async def main():
scraper = FlightScraper()
params = SearchParameters(
departure="MIA",
destination="SEA",
departure_date="2024-12-01",
# return_date="2024-12-30",
ticket_type="One way",
)
try:
flights = await scraper.search_flights(params)
print(f"Successfully found {len(flights)} flights")
except Exception as e:
print(f"Error during flight search: {str(e)}")
if __name__ == "__main__":
asyncio.run(main())
Final Results
After running the scraper, your flight data will be saved in a JSON file that looks like this:
{
"search_parameters": {
"departure": "MIA",
"destination": "SEA",
"departure_date": "2024-12-01",
"return_date": null,
"search_timestamp": "20241027_172017"
},
"flights": [
{
"airline": "American",
"departure_time": "7:45 PM",
"arrival_time": "11:38 PM",
"duration": "6 hr 53 min",
"stops": "Nonstop",
"price": "₹50,755",
"co2_emissions": "303 kg CO2e",
"emissions_variation": "-16% emissions"
},
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
},
{
"airline": "Alaska",
"departure_time": "9:00 AM",
"arrival_time": "12:40 PM",
"duration": "6 hr 40 min",
"stops": "Nonstop",
"price": "₹62,917",
"co2_emissions": "325 kg CO2e",
"emissions_variation": "-10% emissions"
}
]
}
You can find the complete code in my GitHub Gist.
Common Challenges When Scaling Google Flights Scraping
When scaling Google Flights data scraping, challenges like IP blocking and CAPTCHAs are common. For example, if you send too many requests in a short time using a scraper, websites may block your IP address. To avoid this, you can use manual IP rotation or opt for one of the top proxy services. If you’re unsure about which proxy type is best for your use case, check out our guide on the best proxies for web scraping.
Another challenge is dealing with CAPTCHAs. Websites often use these when they suspect bot traffic, blocking your scraper until the CAPTCHA is solved. Handling this manually is time-consuming and complex.
So, what’s the solution? Let’s dive into that next!
The Solution: Bright Data Web Scraping Tools
Bright Data offers a range of solutions designed to simplify and scale your web scraping efforts efficiently. Let’s explore how Bright Data can help you overcome these common challenges.
1. Residential Proxies
Bright Data’s residential proxies give you the ability to access and scrape sophisticated target websites. Residential proxies allow you to route web scraping requests through legitimate residential connections. Your requests will appear to the target websites as coming from genuine users in a specific region or area. As a result, they are an effective solution to access pages protected by IP-based anti-scraping measures.
2. Web Unlocker
Bright Data’s Web Unlocker is perfect for scraping projects that face CAPTCHAs or restrictions. Instead of manually dealing with these issues, Web Unlocker handles them automatically, adapting to changing site blocks with a high success rate (typically 100%). You simply send one request, and Web Unlocker takes care of the rest.
3. Scraping Browser
Bright Data’s Scraping Browser is another powerful tool for developers who use headless browsers like Puppeteer or Playwright. Unlike traditional headless browsers, Scraping Browser handles CAPTCHA solving, browser fingerprinting, retries, and more — all automatically — so you can focus on collecting data without worrying about site restrictions.
Conclusion
This article discussed how to scrape Google Flights data using Python and Playwright. While manual scraping can be effective, it often comes with challenges like IP bans and the need for ongoing script maintenance. To simplify and enhance your data collection efforts, consider leveraging Bright Data’s solutions, such as residential proxies, Web Unlocker, and Scraping Browser.
Sign up for a free trial with Bright Data today!
Additionally, explore our guides on scraping other Google services such as Google Search Result Data, Google Trends, Google Scholar, Google Finance, and Google Maps.

Technical Writer
Satyam Tripathi helps SaaS and data startups turn complex tech into actionable content, boosting developer adoption and user understanding.





