

All data is valuable. Aggregate data is one of the most sought after types on the web. Google Finance contains tons of aggregate data for different financial markets. This data is useful for everything from trading bots to general reports.
Let’s start!
Prerequisites
If you’ve got the right skillset, you can extract data from Google Finance with relative ease. You’ll need the following in order to scrape Google Finance.
- Python: You really only need a basic understanding of Python. You should know how to deal with variables, functions, and loops.
- Python Requests: This is the standard Python HTTP client. It’s used to make GET, POST, PUT, and DELETE requests all over the web.
- BeautifulSoup: BeautifulSoup gives us access to an efficient HTML parser. This is what we use to extract our data.
If you don’t have them installed already, you can install Requests and BeautifulSoup with the following commands.
Install Requests
pip install requests
Install BeautifulSoup
pip install beautifulsoup4
What to Scrape from Google Finance
Here’s a shot of the Google Finance front page. It contains all small bits of information about different markets. We want detailed information about multiple markets, not just small bits.
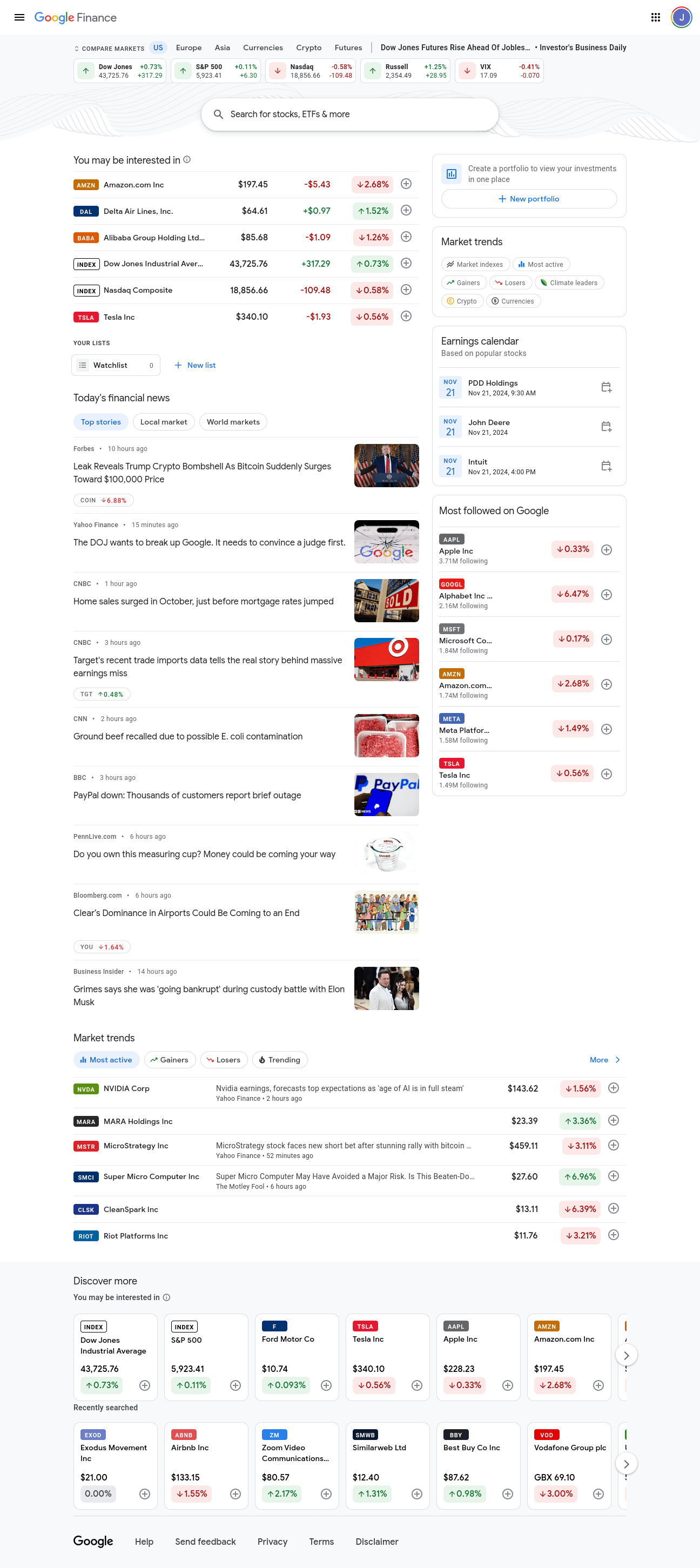
If you scroll down a little bit, you’ll see a section called Market trends on the right hand side of the page. Each bubble in this section links to detailed information about a specific market. We’re interested in the following markets: Gainers, Losers, Market indexes, Most active, and Crypto.

Now, we’ll click on each of these pages and examine them. We’ll start with Gainers. As you can see in our address bar, our url is: https://www.google.com/finance/markets/gainers. If you look at the developer console at the bottom, you should notice that the entire dataset is embedded in a ul, an unorganized list.

Now, we’ll look at the Losers. Our url is: https://www.google.com/finance/markets/losers. Once again, our dataset comes embedded in an unorganized list.

Here’s the same shot of the Market indexes page. This page is a bit special. This page contains multiple ul elements, so we’ll need to accomodate this in our code. The url is: https://www.google.com/finance/markets/indexes. Are you beginning to notice a trend?


The Most active page is shown below. Once again, all of our target data is embedded in a ul. Our url is: https://www.google.com/finance/markets/most-active.

Finally, let’s take a look at our Crypto page. As you probably expected by now, our data is inside of a ul. Our url is: https://www.google.com/finance/markets/cryptocurrencies.

On each of these pages, our target data comes embedded in an unorganized list. To extract our data, we’ll need to find these ul elements and extract the li (list item) elements from each of them. Take a look at our base url: https://www.google.com/finance/markets. Each page comes from the markets endpoint. Our url format is: https://www.google.com/finance/markets/{NAME_OF_MARKET}. We have 5 datasets and 5 urls all structured the same way. This makes it easy to scrape a ton of data using just a few variables.
Scrape Google Finance Manually With Python
If you can avoid getting blocked, you can scrape Google Finance with Python Requests and BeautifulSoup. We need to be able to scrape our data. We should also be able to store it. We have a variety of endpoints, but they all stem from the same base url: https://google.com/finance/markets/. Each time we fetch a page, we need to find the ul elements and extract all the li elements from each list.
Let’s go over the basic functions we’ll be using in our script. We call them write_to_csv() and scrape_page(). These names are pretty self explanatory.
Individual Functions
Take a look at write_to_csv().
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Successfully wrote {filename} to CSV...")
- Our function needs to write a list of
dictobjects to a CSV. If ourdatais not alist, we convert it withdata = [data]. - Each file we generate is from Google Finance, so we add that in when creating the file
filename = f"google-finance-{filename}.csv". - Our default
modeis"w"(write), but if the file exists, we change ourmodeto"a"(append). csv.DictWriter(file, fieldnames=data[0].keys())initializes our file writer.- If we’re in write mode, the file doesn’t exist yet, so we create its headers from the first
dictof thelist. - Once we’re done with setup, we add our data to the file with
writer.writerows(data).
Now let’s take a look at the actual scraping function, scrape_page(). This is where the magic really happens. We make our request to our formatted url. Then, we use BeautifulSoup to parse through the HTML that we receive back. We create an empty list called scraped_data to hold our extracted data. We find all the ul elements on the page. We then pull the li elements from each ul we found. There’s a catch though. The text from each list item is nested within multiple div elements. The actual array we scrape contains a bunch of repeats. To get around this, we pull items 3, 6, 8 and 11 and append() them to scraped_data.
Our scrape_page() function is in the snippet below.
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
for table in tables:
list_elements = table.find_all("li")
for list_element in list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] if endpoint != "cryptocurrencies" else "n/a",
"price": divs[8].text,
"change": divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
- We make our GET request to this endpoint:
requests.get(f"https://google.com/finance/markets/{endpoint}"). - We use BeuatifulSoup’s HTML parser on our
response:soup = BeautifulSoup(response.text, "html.parser"). - We find all of the tables on the page:
tables = soup.find_all("ul"). scraped_data = []gives us an array to hold our results.- We iterate through each of the tables we find and do the following:
- Find all the list items:
table.find_all("li"). - Iterate through each of the list items and find their
divelements. This returns a list calleddivs. - Pull the text from items 3, 6, 8, and 11 from
divsand make adictout of it. - Add the
dictto ourscraped_data. - Cryptocurrencies are priced by their trading pair, so if we’re on the cryptocurrencies endpoint, we reset our
currencyton/a.
- Find all the list items:
- Once we’re finished parsing the page, we save our
scrape_datato a CSV:write_to_csv(scraped_data, endpoint). We pass our endpoint in as a filename.
Scrape Google Finance Data
We can put our functions from above into a script to make everything work. In addition to those functions, we add a list of endpoints. We also add a main to hold our runtime. Feel free to copy and paste the code below and try it out!
import requests
from bs4 import BeautifulSoup
import csv
from pathlib import Path
endpoints = ["gainers", "losers", "indexes", "most-active", "cryptocurrencies"]
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Writing data to CSV File...")
with open(filename, mode) as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
if mode == "w":
writer.writeheader()
writer.writerows(data)
print(f"Successfully wrote {filename} to CSV...")
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
for table in tables:
list_elements = table.find_all("li")
for list_element in list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] if endpoint != "cryptocurrencies" else "n/a",
"price": divs[8].text,
"change": divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
if __name__ == "__main__":
for endpoint in endpoints:
print("---------------------")
scrape_page(endpoint)
When we run the code above, we get the following output.
---------------------
Writing to CSV...
Writing data to CSV File...
Successfully wrote google-finance-gainers.csv to CSV...
---------------------
Writing to CSV...
Writing data to CSV File...
Successfully wrote google-finance-losers.csv to CSV...
---------------------
Writing to CSV...
Writing data to CSV File...
Successfully wrote google-finance-indexes.csv to CSV...
---------------------
Writing to CSV...
Writing data to CSV File...
Successfully wrote google-finance-most-active.csv to CSV...
---------------------
Writing to CSV...
Writing data to CSV File...
Successfully wrote google-finance-cryptocurrencies.csv to CSV...
If you run the script using VSCode, you can actually see the CSV files pop up as the scraper completes its job. They’re highlighted in the screenshot below.

We’ll show a screenshot of what each one looks like in ONLYOFFICE as well.
Most Active

Losers

Indexes

Gainers

Cryptocurrencies

Advanced Techniques
Handling Pagination
Traditionally, pagination is handled using numbers. For Google Finance, we actually use our endpoints array to handle our pagination. Each item of our endpoints list represents an individual page we wish to scrape. Take a look at this list again. Read more here about how to handle pagination while web scraping.
endpoints = ["gainers", "losers", "indexes", "most-active", "cryptocurrencies"]
Now, let’s look at how it gets used. With traditional pagination, you would have either an endpoint or a query param that you pass a number into. However, with this scraper, we pass the endpoint of each page into our base url instead.
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
Mitigate Blocking
During our testing, we didn’t run into any blocking issues. However, this world isn’t perfect and it’s possible you might run into them in the future. There are a variety of tactics you can use to get past any blocking that you may run into.
Fake User Agents
When you make a request to a website (with either a browser or Python Requests), your HTTP client sends a user-agent string to the site server. This is used to identify the application making the request. To set a fake user agent in Python, we create a user agent string. Then we add it to our headers.
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
headers = {
"User-Agent": USER_AGENT
}
response = requests.get(f"https://google.com/finance/markets/{endpoint}", headers=headers)
Timed Requests
Timing our requests can go a very long way. If something is requesting 200 pages per minute, it’s likely not human. To get past rate limiting and appear more human, we can tell our scraper to wait between requests. This our browsing activity appear much more normal. First, you need to import sleep from time.
from time import sleep
Next, sleep for some arbitrary amount of time between requests. This will slow down your scraper and make it appear more human.
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
sleep(5)
Consider Using Bright Data
Scraping the web can be a lot of work. Bright Data is one of the best dataset providers. With our datasets, the scraping is already done and you already have the reports. All you need to do is download them. We understand that web scraping isn’t for everybody, and that some people simply want to get their data and use it.
We don’t have a Google Finance dataset, but we do have a Yahoo Finance dataset. Yahoo Finance actually offers a broader range of financial data and can easily fill your Google Finance needs. We’ll show you how to purchase this dataset below.
Creating An Account
First, you need to create an account. Head on over to our registration page and create an account.

Downloading Bright Data Datasets
Next, go to our financial datasets page. Find the Yahoo Finance dataset. Click the View dataset button.

Once you’re viewing the dataset, you get a few options. You can download a sample dataset, or you can purchase the dataset. It costs $0.0025 per record with a minimum purchase of $500. If you want the dataset, click Proceed to purchase and go through the checkout process.

With our pre-made datasets, the scraping is already done for you. You just get your data and get on with the day!
Conclusion
You’ve done it! Aggregate data is a very valuable tool for people all over the world. Now you know how to scrape it from Google Finance, and you also know how to get it from our Yahoo Finance Dataset! By now, you should know how to create a basic scraper using Python Requests and BeautifulSoup. You should know how to use the find_all() method when parsing page objects with BeautifulSoup.
We’ve also gone over some of the more advanced methods, such as handling pagination with endpoints and mitigating blocking techniques. Take this knowledge and go build a scraper or save some time and work by downloading one of our ready-to-go datasets.
Sign up now and start your free trial today, including free dataset samples.

Technical Writer
Jacob Nulty is a Detroit-based software developer and technical writer exploring AI and human philosophy, with experience in Python, Rust, and blockchain.




