

In this guide, you will learn:
- The definition of a dataset
- The best ways to create datasets
- How to create a dataset in Python
- How to create a dataset in R
Let’s dive in!
What Is a Dataset?
A dataset, or data set, is a collection of data associated related to a specific theme, topic, or industry. Datasets can encompass various types of information—including numbers, text, images, videos, and audio—and can be stored in formats like CSV, JSON, XLS, XLSX, or SQL.
Essentially, a dataset comprises structured data geared toward a particular purpose.
Top 5 Strategies to Create a Dataset
Explore the 5 best strategies for creating datasets, analyzing how they work and their pros and cons.
Strategy #1: Outsource the Task
Establishing and managing a business unit for dataset creation may not be feasible or practical. That is especially true if you lack the internal resources or time. In such a scenario, an effective strategy for dataset creation is to outsource the task.
Outsourcing involves delegating the dataset creation process to external experts or specialized agencies, rather than handling it in-house. This approach allows you to leverage the skills of professionals or organizations experienced in data collection, cleaning, and formatting.
Who should you outsource dataset creation to? Well, many companies offer ready-to-use datasets or custom data collection services. For more details, refer to our guide on the best dataset websites.
These providers use advanced techniques to ensure that the retrieved data is accurate and formatted according to your specifications. While outsourcing enables you to focus on other important aspects of your business, it is essential to select a reliable partner who meets your quality expectations.
Pros:
- You do not have to worry about anything
- Datasets from any site in any format
- Historical or fresh data
Cons:
- You do not have full control over the data retrieval process
- Potential data compliance issues with GDPR and CCPA
- May not be the most cost-effective solution
Strategy #2: Retrieve Data From Public APIs
Many platforms, from social media networks to e-commerce sites, offer public APIs that expose a wealth of data. For example, X’s API gives access to information about public accounts, posts, and replies.
Retrieving data from public APIs is an effective technique to create datasets. The reason is that those endpoints return data in a structured format, making it easier to generate a dataset out of their responses. No surprise, APIs are one of the best strategies for data sourcing.
By leveraging these APIs, you can quickly collect large volumes of credible data directly from established platforms. The main downside is that you need to respect API’s usage limits and terms of service.
Pros:
- Access to official data
- Simple integration in any programming language
- Get structured data directly from the source
Cons:
- Not all platforms have public APIs
- You must comply with the limitations imposed by the API provider
- Data returned by these APIs may change over time
Strategy #3: Look for Open Data
Open data refers to datasets that are openly shared with the public for free. This data is mainly utilized in research and scientific papers, but it can also serve business needs, such as market analysis.
Open data is trustworthy, as it is provided by reputable sources such as governments, non-profits, and academic institutions. These organizations offer open data repositories covering a wide range of topics, including social trends, health statistics, economic indicators, environmental data, and more.
Popular sites where you can retrieve open data include:
- Data.gov: A comprehensive repository of U.S. federal data.
- European Union Open Data Portal: Offers datasets from across Europe.
- World Bank Open Data: Provides global economic and development data.
- UN Data: Features a variety of datasets on global social and economic indicators.
- Registry of Open Data on AWS: A platform to discover and share datasets that are available via AWS resources.
Open data is a popular way to create datasets, as it eliminates the need for data collection by providing freely available data. Still, you must review the data’s quality, completeness, and licensing terms to ensure it meets your project’s requirements.
Pros:
- Free data
- Ready-to-use, large, complete datasets
- Datasets backed by trusted sources like government agencies
Cons:
- Usually provides access only to historical data
- Require some work to get useful insights for your business
- You might not be able to find the data you are interested in
Strategy #4: Download Datasets from GitHub
GitHub hosts numerous repositories containing datasets for various purposes, ranging from machine learning and data science to software development and research. These datasets are shared by individuals and organizations to receive feedback and contribute to the community.
In some cases, these GitHub repositories also include code for processing, analyzing, and exploring the data.
Some notable repositories to get repositories from include:
- Awesome Public Datasets: A curated collection of high-quality datasets across various domains, including finance, climate, and sports. It serves as a hub for finding datasets related to specific topics or industries.
- Kaggle datasets: Kaggle, a prominent platform for data science competitions, hosts some of its datasets on GitHub. Users can create Kaggle datasets by starting from GitHub repositories with just a few clicks.
- Other open data repositories: Several organizations and research groups use GitHub to host open datasets.
These repositories offer pre-existing datasets that can be readily used or adapted to meet your needs. Accessing them requires a single git clone command or a click on the “Download” button.
Pros:
- Off-the-shelf datasets
- Code to analyze and interact with the data
- Many different categories of data to choose from
Cons:
- Potential licensing issues
- Most of these repositories are not up-to-date
- Generic data, not tailored to your need
Strategy #5: Create Your Own Dataset with Web Scraping
Web scraping is the process of extracting data from web pages and converting it into a usable format.
Creating datasets through web scraping is a popular approach for several reasons:
- Access to tons of data: The Web is the largest source of data in the world. Scraping enables you to tap into this extensive resource, gathering information that may not be available through other means.
- Flexibility: You can choose what data to retrieve, the format in which to produce the dataset, and control how frequently to update the data.
- Customization: Tailor your data extraction to meet specific needs, such as extracting data from niche markets or specialized topics not covered by public datasets.
Here is how web scraping typically works:
- Identify the target site
- Inspect its web pages to devise a data extraction strategy
- Create a script to connect to the target pages.
- Parse the HTML content of the pages
- Select the DOM elements containing the data of interest
- Extract data from these elements
- Export the collected data to the desired format, such as JSON, CSV, or XLSX
Note that the script to do web scraping can be written in virtually any programming language, such as Python, JavaScript, or Ruby. Learn more in our article on the best languages for web scraping. Also, take a look at the best tools for web scraping.
Since most companies know how valuable their data is, even if publicly accessible on their site, they protect it with anti-bot technologies. These solutions can block the automated requests made by your scripts. See how to bypass these measures in our tutorial on how to perform web scraping without getting blocked.
Additionally, if you are curious about how web scraping differs from obtaining data from public APIs, check out our article on web scraping vs API.
Pros:
- Public data from any site
- You have control over the data extraction process
- Cost-effective solution that works with most programming languages
Cons:
- Anti-bot and anti-scraping solutions might stop you
- Requires some maintenance
- May necessitate custom data aggregation logic
How To Create Datasets in Python
Python is a leading language for data science and is therefore a popular choice for creating datasets. As you are about to see, creating a dataset in Python takes only a few lines of code.
Here, we will focus on scraping information about all datasets available from the Bright Data Dataset Marketplace:

Follow the guided tutorial to achieve the goal!
For a more detailed how-to, explore our Python web scraping guide.
Step 1: Installation and Set Up
We will assume that you have Python 3+ installed on your machine and that you have a Python project set up.
First, you need to install the required libraries for this project:
- requests: For sending HTTP requests and retrieving the HTML documents associated with web pages.
- Beautiful Soup: For parsing HTML and XML documents and extracting data from web pages.
- pandas: For manipulating data and exporting it to CSV datasets.
Open the terminal in the activated virtual environment in your project’s folder and run:
pip install requests beautifulsoup4 pandasOnce installed, you can import these libraries into your Python script:
import requests
from bs4 import BeautifulSoup
import pandas as pdStep 2: Connect to the Target Site
Retrieve the HTML of the page you want to extract data from. Use the requests library to send an HTTP request to the target site and retrieve its HTML content:
url = 'https://brightdata.com/products/datasets'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)For more details, refer to our guide on how to set a user agent in Python requests.
Step 3: Implement Scraping Logic
With the HTML content in hand, parse it using BeautifulSoup, and extract the data you need from it. Select the HTML elements that contain the data of interest and get data from them:
# parse the retrieved HTML
soup = BeautifulSoup(response.text, 'html.parser')
# where to store the scraped data
data = []
# scraping logic
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})Step 4: Export to CSV
Use pandas to convert the scraped data into a DataFrame and export it to a CSV file.
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)Step 5: Execute the Script
Your final Python script will contain these lines of code:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# make a GET request to the target site with a custom user agent
url = 'https://brightdata.com/products/datasets'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)
# parse the retrieved HTML
soup = BeautifulSoup(response.text, 'html.parser')
# where to store the scraped data
data = []
# scraping logic
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})
# export to CSV
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)Launch it, and the following dataset.csv file will appear in your project’s folder:
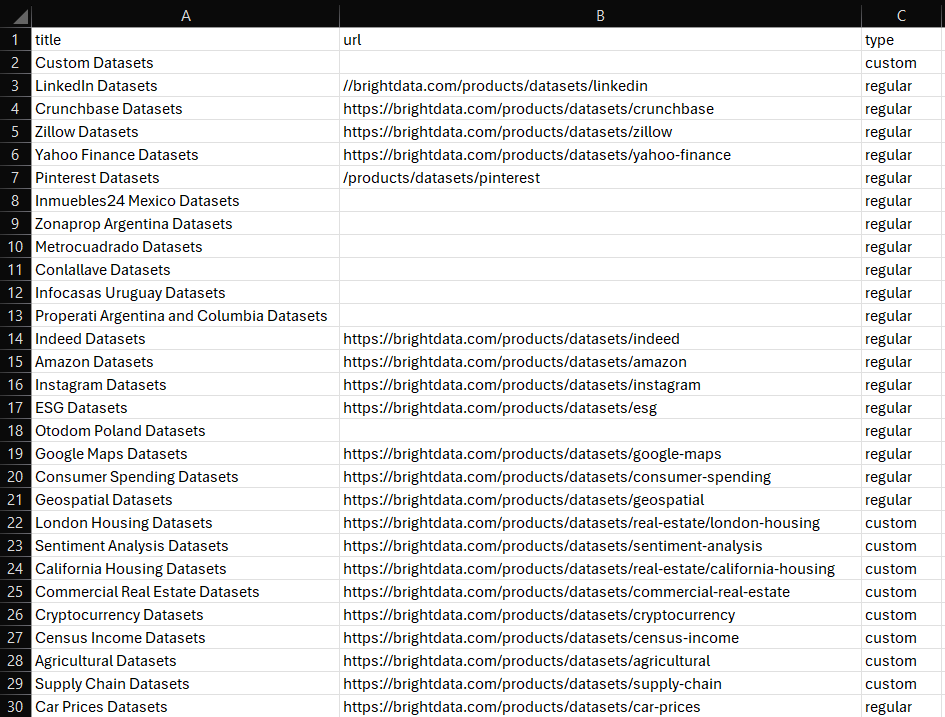
Et voilà! You now know how to create datasets in Python.
How To Create a Dataset in R
R is another widely adopted language by researchers and data scientists. Below is the equivalent script—according to what we saw before in Python—to create a dataset in R:
library(httr)
library(rvest)
library(dplyr)
library(readr)
# make a GET request to the target site with a custom user agent
url <- "https://brightdata.com/products/datasets"
headers <- add_headers(`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
response <- GET(url, headers)
# parse the retrieved HTML
page <- read_html(response)
# where to store the scraped data
data <- tibble()
# scraping logic
dataset_elements <- page %>%
html_nodes(".datasets__loop .datasets__item--wrapper")
for (dataset_element in dataset_elements) {
title <- dataset_element %>%
html_node(".datasets__item .datasets__item--title") %>%
html_text(trim = TRUE)
url_item <- dataset_element %>%
html_node(".datasets__item .datasets__item--title a")
url <- if (!is.null(url_item)) {
html_attr(url_item, "href")
} else {
""
}
type <- dataset_element %>%
html_attr("aria-label", "regular") %>%
tolower()
data <- bind_rows(data, tibble(
title = title,
url = url,
type = type
))
}
# export to CSV
write_csv(data, "dataset.csv")For more guidance, follow our tutorial on web scraping with R.
Conclusion
In this blog post, you learned about how to create datasets. You understood what a dataset is and explored different strategies for creating one. You also saw how to apply the web scraping strategy in Python and R.
Bright Data operates a large, fast, and reliable proxy network, serving by many Fortune 500 companies and over 20,000 customers. That is used to ethically retrieve data from the Web and offer them in a vast dataset marketplace, which includes:
- Business Datasets: Data from key sources like LinkedIn, CrunchBase, Owler, and Indeed.
- Ecommerce Datasets: Data from Amazon, Walmart, Target, Zara, Zalando, Asos, and many more.
- Real Estate Datasets: Data from websites such as Zillow, MLS, and more.
- Social Media Datasets: Data from Facebook, Instagram, YouTube, and Reddit.
- Financial Datasets: Data from Yahoo Finance, Market Watch, Investopedia, and more.
If these pre-made options do not meet your needs, consider our custom data collection services.
On top of that, Bright Data offers a wide range of powerful scraping tools, including Web Scraper APIs and Scraping Browser.
Sign up now and see which of Bright Data’s products and services best suits your needs.

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



