

In this guide, you will learn:
- What the
browser-uselibrary for development AI agents is - Why its capabilities are limited by the browser it controls
- How to overcome those limitations using a scraping browser
- How to build an AI agent that operates in the browser and avoids blocks thanks to integration with Scraping Browser
Let’s dive in!
What Is Browser Use?
Browser Use is an open-source Python project that makes websites accessible to AI agents. It identifies all interactive elements on a webpage, enabling agents to perform meaningful interactions with them. In short, the browser-use library allows AI to control and interact with your browser programmatically.
In detail, the main features it offers are:
- Powerful browser automation: Combines advanced AI with robust browser automation to simplify web interactions for AI agents.
- Vision + HTML extraction: Integrates visual understanding and HTML structure extraction for more effective navigation and decision-making.
- Multi-tab management: Can deal with multiple browser tabs, opening the door to complex workflows and parallel tasks.
- Element tracking: Tracks clicked elements using XPath and can repeat the exact actions taken by an LLM, ensuring consistency.
- Custom actions: Supports the definition of custom actions like saving to files, writing to databases, sending notifications, or handling human input.
- Self-correcting mechanism: Comes with a built-in error handling and automatic recovery system for a more reliable automation pipeline.
- Support for Any LLM: Is compatible with all major LLMs via LangChain, including GPT-4, Claude 3, and Llama 2.
Limitations of Browser Use in AI Agent Development
Browser Use is a groundbreaking technology that has made an unprecedented impact in the IT community. It is no surprise that the project reached over 60,000 GitHub stars in just a few months:

On top of that, the team behind it secured over $17 million in seed funding, which speaks volumes about the potential and promise of this project.
However, it is important to recognize that the browser control capabilities offered by Browser Use are not based on magic. Instead, the library combines visual input with AI control to automate browsers via Playwright—a feature-rich browser automation framework that does come with certain limitations.
As we pointed out in our previous articles on Playwright web scraping, the limitations do not stem from the automation framework itself. Quite the opposite, they come from the browsers it controls. Specifically, tools like Playwright launch browsers with special configurations and instrumentation that enable automation. The problem is that those settings can also expose them to anti-bot detection systems.
This becomes a major issue, especially when building AI agents that need to interact with well-protected sites. For example, assume you want to utilize Browser Use to build an AI agent that adds specific items to a shopping cart on Amazon for you. This is the result you will likely get:

As you can see, the Amazon anti-bot system can detect and stop your AI automation. In particular, the e-commerce platform may show the challenging Amazon CAPTCHA or respond with the “Sorry, something went wrong on our end” error page:

In such cases, it is “game over” for your AI agent. So, while Browser Use is an amazing and powerful tool, achieving its full potential requires thoughtful adjustments. The ultimate goal is to avoid triggering anti-bot systems so that your AI automation can operate as desired.
Why a Scraping Browser Is the Solution
Now, you might be thinking: “Why not just tweak the browser that browser-use controls via Playwright, using special flags to reduce the chances of detection?” That is indeed possible, and it is part of the strategy used by libraries like Playwright Stealth.
However, bypassing anti-bot detection is far more complex than flipping a few flags…
It involves factors like IP reputation, rate limiting, browser fingerprinting, and other advanced aspects. You cannot simply outsmart sophisticated anti-bot systems with a couple of manual tricks. What you really need is a solution built from the ground up to be undetectable to anti-bot and anti-scraping defenses. And that is where a scraping browser comes in!
Scraping browser solutions offer incredibly effective anti-detection features. So, what is the best anti-detect browser on the market? Bright Data’s Scraping Browser!
In particular, Scraping Browser is a next-generation, cloud-based web browser that offers:
- Reliable TLS fingerprints to blend in with real users
- Unlimited scalability for high-volume scraping
- Automatic IP rotation, backed by a 400M+ IP proxy network
- Built-in retry logic for handling failed requests gracefully
- CAPTCHA-solving capabilities, ready out of the box
- A comprehensive anti-bot bypass toolkit
Scraping Browser integrates with all major browser automation libraries—including Playwright, Puppeteer, and Selenium. So, it is fully compatible with browser-use as this library builds on top of Playwright.
By integrating Scraping Browser into Browser Use, you can bypass the Amazon blocks you encountered earlier—or avoid similar blocks on any other site.
How to Integrate Browser Use With a Scraping Browser
In this tutorial section, you will learn how to integrate Browser Use with Bright Data’s Scraping Browser. We will build an OpenAI-powered AI agent that can add items to the Amazon cart.
This is just one example to demonstrate the power of AI-driven browser automation. Note that the AI agent can interact with other sites, according to your needs and target goals. What matters is that it allows you to save significant time and effort by performing tedious operations for you.
In detail, the Amazon AI agent we are about to build will be able to:
- Connect to Amazon using a remote Scraping Browser instance to avoid detection and blocks.
- Read a list of items from the prompt.
- Search, select the correct products, and add them to your cart automatically.
- Visit the cart and provide a summary of the entire order.
Follow the steps below to see how to utilize Browser Use with Scraping Browser!
Prerequisites
To follow along with this tutorial, make sure you have the following:
- A Bright Data account.
- An API key from a supported AI provider such as OpenAI, Anthropic, Gemini, DeepSeek, Grok, or Novita.
- Basic knowledge of Python async programming and browser automation.
If you do not yet have a Bright Data or AI provider account, do not worry. We will walk you through how to create them in the steps below.
Step #1: Project Setup
Before we begin, make sure you have Python 3 installed on your system. Otherwise, download it from the official site and follow the installation instructions.
Open your terminal and create a new folder for your AI agent project:
mkdir browser-use-amazon-agentThe browser-use-amazon-agent folder will contain all the code for your Python-based AI agent.
Navigate into the project folder and set up a virtual environment inside it:
cd browser-use-amazon-agent
python -m venv venvNow open the project folder in your favorite Python IDE. Visual Studio Code with the Python extension or PyCharm Community Edition are both valid choices.
In the browser-use-amazon-agent folder, create a new Python file named agent.py. Your project structure should now look like this:
At this point, agent.py is just an empty script but it will soon contain your complete AI browser automation logic.
In your IDE’s terminal, activate the virtual environment. On Linux/macOS, run:
source venv/bin/activateEquivalently, on Windows, execute:
venv/Scripts/activateYou are all set! Your Python environment is now ready for building an AI agent with Browser Use and Scraping Browser.
Step #2: Set Up Environment Variables Reading
Your project will integrate with third-party services like Bright Data and your chosen AI provider. Instead of hardcoding API keys and connection secrets directly in your Python code, it is best practice to load them from environment variables.
To simplify that task, we will use the python-dotenv library. In the activated virtual environment, install it with:
pip install python-dotenvIn your agent.py file, import the library and load the environment variables with load_dotenv():
from dotenv import load_dotenv
load_dotenv()You will now be able to read variables from a local .env file. Add it to your project:

You can now access these environment variables in your code with this line of code:
env_value = os.getenv("<ENV_NAME>")Do not forget to import os from the Python standard library:
import osGreat! You are now ready to securely read secrets for integrating with third-party services from the envs.
Step #3: Get Started With browser-use
With your virtual environment activated, install browser-use:
pip install browser-useSince the library relies on several dependencies, this may take a few minutes. So, be patient.
Since browser-use uses Playwright under the hood, you might also need to install Playwright’s browser dependencies. To do so, run the following command:
python -m playwright installThis downloads the necessary browser binaries and sets up everything Playwright needs to function correctly.
Now, import the required classes from browser-use:
from browser_use import Agent, Browser, BrowserConfigWe will use these classes to build the AI agent’s browser automation logic shortly.
Since browser-use provides an async API, you need to initialize your agent.py with an asynchronous entry point:
# other imports..
import asyncio
async def main():
# AI agent logic...
if __name__ == "__main__":
asyncio.run(main())The above snippet uses Python’s asyncio library to run asynchronous tasks, which is required for working with browser-use.
Well done! The next step is to configure the Scraping Browser and integrate it into your script.
Step #4: Get Started With Scraping Browser
For general integration instructions, refer to the official Scraping Browser documentation. Otherwise, follow the steps below.
To get started, if you have not already, create a Bright Data account. Log in, reach the user dashboard, and click the “Get proxy products” button:
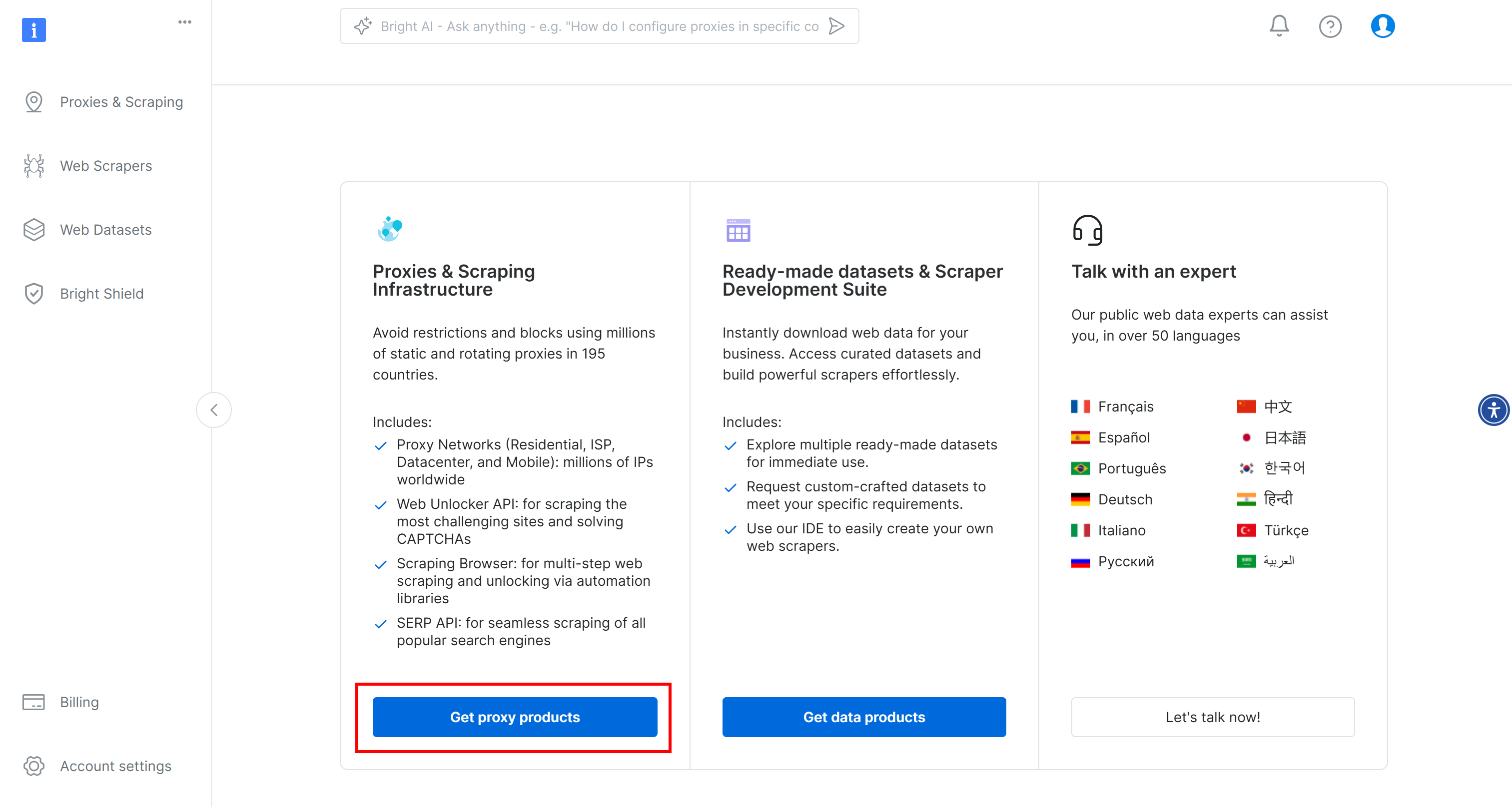
On the “Proxies & Scraping Infrastructure” page, look for the “My Zones” table and select the row referring to the “Scraping Browser” type:

If you do not see such a row, it means you have not configured the Scraping Browser zone yet. In that case, scroll down until you find the “Browser API” card and press the “Get Started” button:

Next, follow the guided setup to configure the Scraping Browser for the first time.
Once reached the product page, enable it by toggling the on/off switch:

Now, go to the “Configuration” tab and ensure both “Premium domains” and “CAPTCHA Solver” are enabled for maximum effectiveness:

Switch to the “Overview” tab and copy the Playwright Scraping Browser connection string:

Add this connection string to your .env file:
SBR_CDP_URL="<YOUR_PLAYWRIGHT_SCRAPING_BROWSER_CONNECTION_STRING>"Replace <YOUR_PLAYWRIGHT_SCRAPING_BROWSER_CONNECTION_STRING> with the value you just copied.
Now, in your agent.py file, load the environment variable with:
SBR_CDP_URL = os.getenv("SBR_CDP_URL")Amazing! You can now use Scraping Browser inside browser-use. Before we dive into that, let’s complete the third-party integrations by adding OpenAI to your script.
Step #5: Get Started With OpenAI
Disclaimer: The following step focuses on integrating OpenAI, but you can easily adapt the instructions below for any other AI provider supported by Browser Use.
To enable AI capabilities in browser-use, you need a valid API key from an external AI provider. Here, we will use OpenAI. If you have not generated an API key yet, follow OpenAI’s official guide to create one.
Once you have your key, add it to your .env file:
OPENAI_API_KEY="<YOUR_OPENAI_KEY>"Make sure to replace <YOUR_OPENAI_KEY> with your actual API key.
Next, import the ChatOpenAI class from langchain_openai in agent.py:
from browser_use import ChatOpenAINote that Browser Use relies on LangChain to handle AI integrations. So even if you have not explicitly installed langchain_openai in your project, it is already available for use. For more guidance, read our tutorial on how to integrate Bright Data in LangChain workflows.
Set up the OpenAI integration using the gpt-4o model with:
llm = ChatOpenAI(model="gpt-4o")No additional configuration is required. That is because langchain_openai will automatically read the API key from the OPENAI_API_KEY environment variable.
For integration with other AI models or providers, refer to the official Browser Use documentation.
Step #6: Integrate Scraping Browser in browser-use
To connect to a remote browser in browser-use, you need to use the BrowserConfig object like this:
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(browser_profile=config)This configuration instructs Playwright to connect to the remote Bright Data Scraping Browser instance.
Step #7: Define the Task to Automate
It is now time to define the task you want your AI agent to perform in the browser using natural language.
Before doing so, make sure the goal is clearly defined in your mind. In this case, let’s assume you want the AI agent to:
- Connect to Amazon.com.
- Add the PlayStation 5 console and Astro Bot PS5 game to the cart.
- Reach the cart page and generate a summary of the current order.
If you give only those basic instructions to Browser Use, things might not go as expected. That is because some products have multiple versions, some pages may prompt you to purchase additional insurance, some items may be unavailable, etc.
Therefore, it makes sense to add extra notes to guide the AI agent’s decisions in these situations.
Also, to improve performance, it is helpful to clearly outline the most important steps in words.
With that in mind, the task your AI agent should perform in the browser can be described like this:
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""Note how this version is detailed enough to guide the AI agent through common scenarios and prevent it from getting stuck.
Beautiful! See how to launch this task.
Step #8: Launch the AI Task
Initialize a browser-use Agent object using your AI agent’s task definition:
agent = Agent(
task=task,
llm=llm,
browser=browser,
)You can now run the agent with:
await agent.run()Also, do not forget to close the Playwright-controlled browser when the task is complete to free up its resources:
await browser.close()Perfect! The Browser Use + Bright Data Scraping Browser integration is now fully set up. All that is left is to put everything together and run the complete code.
Step #9: Put It All Together
Your agent.py file should contain:
from dotenv import load_dotenv
import os
from browser_use.browser.config import BrowserConfig
import asyncio
from browser_use import ChatOpenAI
# Load the environment variables from the .env file
load_dotenv()
async def main():
# Read the remote URL of Scraping Browser from the envs
SBR_CDP_URL = os.getenv("SBR_CDP_URL")
# Set up the AI engine
llm = ChatOpenAI(model="gpt-4o")
# Configure the browser automation to connect to a remote Scraping Browser instance
config = BrowserConfig(
cdp_url=SBR_CDP_URL
)
browser = Browser(browser_profile=config)
# The task you want to automate in the browser
task="""
# Prompt for Your Amazon Agent
**Objective:**
Visit [Amazon](https://www.amazon.com/), search for the required items, add them to the cart, and show a summary of the current order.
**Important:**
- Click on a product's title to access its page. There, you can find the "Add to cart" button.
- If you are asked for extended warranty or similar after adding a product to the cart, decline the option.
- You can find the search bar to search for products at the top section of each Amazon page. If you cannot use it, go back to the Amazon home page before a search.
- If the product is unavailable, add the cheapest used option to the cart instead. If no used options are available, skip the product.
- If any modal/section occupying a part of the page appears, remember that you can close it by clicking the "X" button.
- Avoid refurbished items.
---
## Step 1: Navigate to the Target Website
- Open [Amazon](https://www.amazon.com/)
---
## Step 2: Add Items to the Cart
- Add the items you can find in the shopping list below to the Amazon cart:
- PlayStation 5 (Slim) console
- Astro Bot PS5 game
---
## Step 3: Output Summary
- Reach the cart page and use the info you can find on that page to generate a summary of the current order. For each item in the cart, include:
- **Name**
- **Quantity**
- **Cost**
- **Expected delivery time**
- At the end of the report, mention the total cost and any other useful additional info.
"""
# Initialize a new AI browser agent with the configured browser
agent = Agent(
task=task,
llm=llm,
browser=browser,
)
# Start the AI agent
await agent.run()
# Close the browser when the task is complete
await browser.close()
if __name__ == "__main__":
asyncio.run(main())Et voilà! In under 100 lines of code, you built a powerful AI agent that combines browser-use with Bright Data’s Scraping Browser.
To execute your AI agent, run:
python agent.pyOnce launched, browser-use will log everything it does. Since the Scraping Browser runs in the cloud and there is no visual interface, these logs are essential for understanding what the agent is doing.
Here is a short excerpt of what the logs might look like:
INFO [agent] 📍 Step 1
INFO [browser] 🔌 Connecting to remote browser via CDP wss://brd-customer-hl_4bcb8ada-zone-scraping_browser:[email protected]:9222
INFO [agent] 🤷 Eval: Unknown - Task has just started, beginning with navigating to Amazon.
INFO [agent] 🧠 Memory: Step 1: Navigate to Amazon's website. Open tab to Amazon's main page.
INFO [agent] 🎯 Next goal: Navigate to Amazon's website by opening the following URL: https://www.amazon.com/.
INFO [agent] 🛠️ Action 1/1: {"go_to_url":{"url":"https://www.amazon.com/"}}
INFO [controller] 🔗 Navigated to https://www.amazon.com/
INFO [agent] 📍 Step 2
INFO [agent] 👍 Eval: Success - Navigated to Amazon homepage. The search bar is available for input.
INFO [agent] 🧠 Memory: On the Amazon homepage, ready to search for items. 0 out of 2 items added to cart.
INFO [agent] 🎯 Next goal: Search for the 'PlayStation 5 (Slim) console' in the search bar.
INFO [agent] 🛠️ Action 1/2: {"input_text":{"index":2,"text":"PlayStation 5 (Slim) console"}}
INFO [agent] 🛠️ Action 2/2: {"click_element_by_index":{"index":4}}
INFO [controller] ⌨️ Input PlayStation 5 (Slim) console into index 2
INFO [agent] Something new appeared after action 1 / 2
# Omitted for brevity...
INFO [agent] 📍 Step 14
INFO [agent] 👍 Eval: Success - Extracted the order summary from the cart page.
INFO [agent] 🧠 Memory: Amazon cart page shows both items: PlayStation 5 Slim and Astro Bot PS5 game added successfully. Extracted item names, quantities, costs, subtotal, and delivery details.
INFO [agent] 🎯 Next goal: Finalize the task by summarizing the order details.
INFO [agent] 🛠️ Action 1/1: {"done":{"text":"Order Summary:nnItems in Cart:n1. Name: Astro Bot PS5n Quantity: 11n Cost: $58.95nn2. Name: PlayStation®5 console (slim)n Quantity: 1n Cost: $499.00nnSubtotal: $557.95nDelivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.nnTotal Cost: $557.95","success":true}}
INFO [agent] 📄 Result: Order Summary:
Items in Cart:
1. Name: Astro Bot PS5
Quantity: 1
Cost: $58.95
2. Name: PlayStation®5 console (slim)
Quantity: 1
Cost: $499.00
Subtotal: $557.95
Delivery Details: Your order qualifies for FREE Shipping. Choose this option at checkout.As you can see, the AI agent successfully found the desired items, added them to the cart, and generated a clean summary. All that with no blocks or bans from Amazon, thanks to the Scraping Browser!
browser-use also includes features for recording the browser session for debugging purposes. While this does not yet work with the remote browser, if it did, you would see a mesmerizing playback of the AI agent in action:
Truly hypnotic—and an exciting glimpse into how far AI-powered browsing has come.
Step #10: Next Steps
The Amazon AI agent we built here is just a starting point—a proof of concept to showcase what is possible. To make it production-ready, below are several ideas for improvement:
- Connect to your Amazon account: Allow the agent to log in, so it can access personalized features like order history and recommendations.
- Implement a purchase workflow: Extend the agent to actually complete purchases. That includes selecting shipping options, applying promo codes or gift cards, and confirming payment.
- Send a confirmation or report via email: Before finalizing any payment transaction, the agent could email a detailed summary of the cart and intended actions for user approval. This keeps you in control and adds a layer of accountability.
- Read items from a wishlist or input list: Have the agent load items dynamically from a saved Amazon wishlist, a local file (e.g., JSON or CSV), or a remote API endpoint.
Conclusion
In this blog post, you learned how to use the popular browse-use library in combination with a scraping browser API to build a highly effective AI agent in Python.
As demonstrated, combining Browse Use with Bright Data’s Scraping Browser enables you to create AI agents that can reliably interact with virtually any website. This is just one example of how Bright Data’s tools and services can empower advanced AI-driven automation.
Explore our solutions for AI agent development:
- Autonomous AI agents: Search, access, and interact with any website in real-time using a powerful set of APIs.
- Vertical AI apps: Build reliable, custom data pipelines to extract web data from industry-specific sources.
- Foundation models: Access compliant, web-scale datasets to power pre-training, evaluation, and fine-tuning.
- Multimodal AI: Tap into the world’s largest repository of images, videos, and audio—optimized for AI.
- Data providers: Connect with trusted providers to source high-quality, AI-ready datasets at scale.
- Data packages: Get curated, ready-to-use, structured, enriched, and annotated datasets.
For more information, explore our AI hub.
Create a Bright Data account and try all our products and services for AI agent development!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



