

In this article, you will see:
- Why scraping LLMs is important and the scenarios it supports.
- Why relying on a dedicated LLM chat scraper is the best approach.
- The main factors to consider when comparing solutions to scrape LLMs.
- A list of the top LLM scrapers of the year.
Let’s dive in!
TL;DR: Summary Table of the Top LLM Scrapers
If you are in a hurry, compare the top LLM scrapers at a glance in the summary table below.
| LLM Scraper | Types | Supported LLMs | APIs | No‑code | Infrastructure | Concurrency | GDPR Compliance | Free Trial | Entry Pricing |
|---|---|---|---|---|---|---|---|---|---|
| Bright Data’s LLM Scraper | API scraper + no‑code + managed | ChatGPT, Perplexity, Gemini, Grok, Google AI Mode, Copilot | ✅ | ✅ | Enterprise proxy network (400M+ IPs) with automatic unblocking | Unlimited | ✅ | ✅ | $1.5/1k records |
| Scrapeless | API scraper | ChatGPT, Perplexity, Copilot, Gemini, Google AI Mode, Grok | ✅ | ❌ | Unified API + 80M+ proxy network | High | ✅ | ✅ | $49/mo |
| cloro | API scraper | ChatGPT, Perplexity, Copilot, Gemini, Grok, Google AI Mode | ✅ | ❌ | Unified API with geo‑targeting | Limited (10–100 concurrent jobs) | ✅ | ✅ | $100/mo |
| A‑Parser | Desktop scraper + API | ChatGPT, Perplexity, Google AI Mode, Copilot, DeepAI, Kimi | ✅ (for management) | ✅ | Local execution + management APIs | Limited (~100–200 queries/min) | — (Undisclosed) | ❌ | $179 one‑time |
| Infatica | API scraper | ChatGPT, Gemini, Perplexity | ✅ | ❌ | Scraping API with residential proxies | High | ✅ | ❌ | Custom |
| Apify | Ready‑made scrapers + API | ChatGPT, Gemini, Perplexity, Grok, others (Actor‑based) | ✅ | ✅ | Serverless scraping platform with proxy support | Limited (25–256 concurrent runs) | ✅ | ✅ | Actor‑dependent |
An Introduction to the World of Scraping LLMs
Before exploring the best LLM scrapers, it helps to build some background knowledge and context around scraping data from LLMs.
What Is an LLM Scraper?
An LLM scraper, also called an LLM chat scraper or a scraping LLM solution, is a tool specifically built to extract structured data from LLMs. In other words, it automatically sends prompts and collects the generated responses.
In most cases, it retrieves not only the direct replies but also additional outputs such as citations, links, and metadata. Target platforms include ChatGPT, Gemini, Perplexity, Grok, and similar services.
Why Scraping LLM Is So Important
The rise of Generative Engine Optimization (GEO) is reshaping how brands think about visibility — and why scraping LLMs has become a critical intelligence-gathering practice. Where SEO once meant chasing keyword rankings on Google, the new battleground is whether your brand is mentioned, cited, or recommended inside AI-generated answers on platforms like ChatGPT, Perplexity, Google AI Overviews, and Claude.
The scale of this shift is hard to overstate. ChatGPT alone now reaches over 800 million weekly active users, and AI Overviews appear in an estimated 16% of all Google searches, far more for high-intent, comparison-driven queries. Critically, users who arrive via AI search aren’t just browsing: Ahrefs found that AI search visitors convert 23x better than traditional organic visitors, making presence in AI answers a direct revenue signal.
This is where prompt tracking comes in. Prompt tracking is the systematic practice of testing a defined set of prompts across AI platforms and recording how your brand appears in the responses over time by monitoring brand mentions, citations, competitor references, and sentiment shifts. Unlike a Google rank position, AI answers are probabilistic and volatile: between 40–60% of cited sources change month to month, meaning brands that aren’t actively scraping and tracking LLM outputs are flying blind.
The strategic stakes are clear. When a user asks ChatGPT “What’s the best project management tool for remote teams?” or “Which CRM is best for startups?”, the AI delivers a direct recommendation, not just a list of links to browse. If your brand isn’t in that answer, there is no “position 11” to optimize upward from: you are simply absent from the conversation. As one framework puts it, 2025 was the disruption year; 2026 is the selection year. AI systems are now consistently selecting certain brands and consistently ignoring others.
Scraping LLMs enables brands to act on this in several concrete ways: identifying which prompts trigger competitor mentions instead of their own, catching inaccurate or outdated brand representations before they shape buyer perception, and monitoring how brand sentiment shifts across different models over time. It supports the continuous, data-driven feedback loop that effective GEO strategy demands — turning raw AI responses into actionable content and positioning decisions.
Benefits of LLM Scraping
The main advantages and use cases that LLM scraping opens the door to are:
- Plain-English queries and results: Retrieve information through natural-language prompts, making data collection easier than traditional scraping based on data parsing.
- Dataset creation for model training: Collect prompt–response pairs to build datasets for fine-tuning, evaluation, benchmarking, or training custom AI models.
- Cross-model comparison: Compare responses from multiple LLM providers to identify differences, agreement, and model-specific behavior.
- Structured knowledge extraction: Extract structured data such as links, citations, entities, and metadata from otherwise unstructured model responses.
- GEO (Generative Engine Optimization) and AI search monitoring: Track how brands, products, or topics appear in AI-generated answers across different models over time.
- Change detection over time: Monitor how model responses evolve as models update or as information on the web changes.
Why You Should Rely on a Dedicated LLM Scraper
Retrieving data from LLMs is not inherently challenging, since you can directly send prompts to the models via API. The real difficulty is standardizing the process and running it at scale. Most LLM providers impose API rate limits based on pricing plans, and responses vary a lot across providers.
By choosing a specialized LLM scraper, you can avoid those challenges. What you get is a unified experience for scraping LLMs, usually via APIs or no-code tools. This helps standardize the process of retrieving data from AI models in a structured, stable, and consistent format.
LLm scrapers also support features like geolocation, bulk requests, and other capabilities that make data extraction easier than calling the APIs directly. In many cases, they can also be faster and more cost-effective thanks to large-scale infrastructure and caching mechanisms behind the scenes.
Aspects to Consider When Evaluating LLM Scrapers
Solutions for scraping web data via AI are super popular, but tools engineered for scraping data from LLMs are still relatively uncommon. Still, the market is growing quickly, with new players emerging regularly.
To avoid wasting time and focus on the most relevant tools, you need a comparison framework to evaluate them against consistent criteria, such as:
- Type: Whether the solution is an API, no-code platform, desktop application, or another type of tool.
- Covered LLMs: The LLM providers and platforms supported (e.g., ChatGPT, Gemini, Grok, etc.).
- Included data: The type of data you can retrieve from LLM responses, such as plain text, citations, hyperlinks, and more.
- Infrastructure: The provider’s ability to scale, maintain uptime, and handle large volumes of requests.
- Technical requirements: The skills or infrastructure needed to use and integrate the LLM scraping solution.
- Compliance: Adherence to privacy regulations (such as GDPR and CCPA) and security best practices.
- Pricing: The pricing structure, including free trials or credits for evaluation.
Best LLM Scrapers: Top Tools and Solutions
Given the criteria presented earlier, let’s explore the top six LLM scrapers.
1. Bright Data
Bright Data started as a proxy provider and has expanded its platform into the leading web data solution. Its rich offering includes specific tools to collect data from AI systems. These LLM scrapers extract structured responses and metadata from major AI models in a consistent and scalable way, either via API or through a no-code interface.
In detail, Bright Data’s main solutions for scraping LLMs include:
- ChatGPT Scraper: Collect structured responses, prompts, citations, links, rankings, and conversation metadata from ChatGPT queries in real time.
- Perplexity Scraper: Retrieve AI-generated answers along with sources, citations, and structured response data from Perplexity searches.
- Gemini Scraper: Extract prompts, generated answers, citations, links, and metadata from Gemini responses in a standardized format.
- Grok Scraper: Gather Grok-generated responses along with structured metadata such as citations, raw responses, and indexed outputs.
- Google AI Mode Scraper: Capture AI-generated search responses from Google AI Mode, including prompts, answers, citations, links, and indexed results.
- Copilot Scraper: Fetch structured responses, sources, and answer sections from Copilot search results.
All these solutions run on Bright Data’s enterprise-grade infrastructure, powered by a global proxy network with over 400M+ IPs, automatic unblocking technologies, and 99.99% uptime. This infrastructure enables reliable, large-scale LLM data collection without the operational overhead.
Taken together, these aspects make Bright Data the most complete and scalable provider for LLM scraping.
🏆 Ideal for: Enterprise-grade, highly scalable, concurrent, multi-provider LLM scraping via no-code or API integrations.
Type:
- API-based LLM scraper.
- No-code LLM scraping options through a control panel.
- Fully managed LLM data collection option available.
Covered LLMs:
- ChatGPT
- Perplexity
- Gemini
- Grok
- Google AI Mode (AI Overviews)
- Copilot
Included data:
- Model responses in text, HTML, or Markdown formats.
- Structured output formats such as JSON, NDJSON, and CSV.
- Query prompts and URLs.
- Response content and full messages.
- Citations and sources.
- Attached links.
- Recommendations and rankings.
- Timestamps and metadata.
- Raw responses and parsed structured data (depending on the provider).
- Country-level metadata.
Infrastructure:
- Built-in proxy and unblocking infrastructure with automatic IP rotation and CAPTCHA solving.
- Access to 400M+ IPs across 195 countries.
- Supports bulk requests, with up to 5k requests at the same time.
- 99.95% success rate.
- Webhook-based or API-based data delivery.
- Results can be downloaded or delivered to storage services such as Amazon S3 and Google Cloud Storage.
- 99.99% uptime infrastructure.
- Designed for high-volume data collection and scalable workloads.
- Data parsing, validation, and structure detection features.
- Unlimited concurrency.
- Support for automated, scheduled runs.
- 27/4 support from a team of experts.
- 70+ AI integrations available.
Technical requirements:
- Basic programming skills required for connecting to the LLM scraping APIs.
- No-code interface available for non-technical users.
- Technical skills needed for integrations in AI/ML workflows, pipelines, and applications.
Compliance:
- Fully compliant with GDPR.
- CCPA-compliant.
- SEC-compliant.
- Certified to ISO 27001, SOC 2 Type II, and CSA STAR Level 1 standards.
Pricing:
- Free trial available with no credit card required.
- Pay-as-you-go pricing starting at $1.5 per 1K records with no commitment.
- Monthly plans available:
- 510K records for $499/mo ($0.98/1k records).
- 1M records for $999/mo ($0.83/1k records).
- 2.5M records for $1,999/mo ($0.75/1k records).
- Enterprise plans available with custom pricing.
2. Scrapeless
Scrapeless is a proxy and web scraping company specializing in automated public data extraction, even from LLMs. In particular, its LLM Chat Scraper service provides a unified API to retrieve real-time, structured insights from ChatGPT, Gemini, and others. By capturing citations and rankings, it enables precise monitoring of brand presence within generative search ecosystems.
🏆 Ideal for: Building AI-powered analytics dashboards with real-time LLM response data and citations.
Type:
- API-based LLM scraper.
Covered LLMs:
- ChatGPT
- Perplexity
- Copilot
- Gemini
- Google AI Mode (AI Overviews)
- Grok
Included data:
- Model responses in Markdown or text.
- Depending on the chosen provider and availability:
- Citations and content references.
- Extracted links and URLs.
- Related prompts and structured media data (e.g., maps, images, videos).
- Location data (coordinates, addresses, categories).
- Raw HTML (Google AI Mode).
Infrastructure:
- Unified API for scraping multiple AI models.
- Webhook support for automated result delivery.
- Supports country-level targeting across 195+ countries and 2,000+ cities through an 80M+ proxy network.
- 99.98% success-rate proxy network supporting the scraping API infrastructure.
- Results are temporarily stored for easier exploration.
Technical requirements:
- Basic programming skills needed to create tasks and retrieve results via API.
Compliance:
- Full GDPR compliance.
Pricing:
- Free trial available.
- User-based pricing:
- Growth: $49/mo.
- Scale: $199/mo.
- Business: $399/mo.
- Custom: Custom pricing.
- Enterprise-based pricing:
- Enterprise: $699/mo.
- Enterprise Plus: $999/mo.
- Custom: Custom pricing.
3. cloro
cloro is an API-driven platform for monitoring SEO and AI search ecosystems. Its LLM scraping solution collects structured responses directly from AI interfaces such as ChatGPT, Gemini, and Perplexity through a unified API. It returns text, citations, and structured objects while supporting geographic targeting.
🏆 Ideal for: SEO and GEO teams analyzing AI search visibility across multiple LLM providers and search engines.
Type:
- API-based LLM scraping solution.
Covered LLMs:
- ChatGPT
- Perplexity
- Copilot
- Gemini
- Grok
- Google AI Mode
- Google AI Overview
Included data:
- Model responses in text, HTML, or Markdown format.
- Depending on the target LLM and available information:
- Structured sources and citations.
- Extracted entities and structured objects.
- Search queries and query expansions.
- Shopping-related structured data (e.g., product cards).
- Source URLs and metadata.
Infrastructure:
- Unified API for structured data extraction across multiple AI models.
- Supports 300M+ monthly API calls.
- 99.99% uptime.
- Supports geographic targeting by country.
- Supports concurrent scraping jobs, from 10 to 100, depending on the pricing plan.
Technical requirements:
- Requires API integration via HTTP requests.
- Basic programming skills needed for prompt submission and response handling.
Compliance:
- GDPR compliant for European users.
Pricing:
- Free trial available with 500 credits.
- Credit-based pricing model with monthly plans:
- Hobby: $100/mo for 250,000 credits.
- Starter: $250/mo for 694,444 credits.
- Growth: $500/mo for 1,562,500 credits.
- Business: $1,000/mo for 3,333,333 credits.
- Enterprise: Custom pricing.
4. A-Parser
A-Parser is a web-based and desktop application for web scraping and automation. It equips you with dozens of built-in parsers for retrieving data from various platforms. In detail, it covers services such as ChatGPT, Perplexity, Google, and other AI systems.
🏆 Ideal for: A desktop-based LLM scraping experience.
Type:
- Desktop scraping software available on Windows, Linux, and macOS (via Docker) + a web interface.
- Supports automation via API.
Covered LLMs:
- ChatGPT
- Perplexity
- Google AI (Gemini-based AI Mode)
- Copilot
- DeepAI
- Kimi
Included data:
- Model responses in Markdown/text.
- Depending on the response and the target LLM provider:
- Source links, anchors, and snippets.
- Images and image metadata (when present).
- Structured exports (e.g., JSON, CSV, SQL).
Infrastructure:
- Supports 100/200 queries per minute, depending on the target LLM provider.
- Task queue and automation via API.
- Third-party Proxy support (HTTP, SOCKS4/5).
- Thrid-party CAPTCHA solving service integration support.
Technical requirements:
- Installation and local setup required for the no-code desktop software.
- Programming skills needed for management via API.
Compliance:
- Undisclosed.
Pricing:
- One-time license pricing:
- Lite: $179
- Pro: $299
- Enterprise: $479
- Paid updates available separately.
5. Infatica
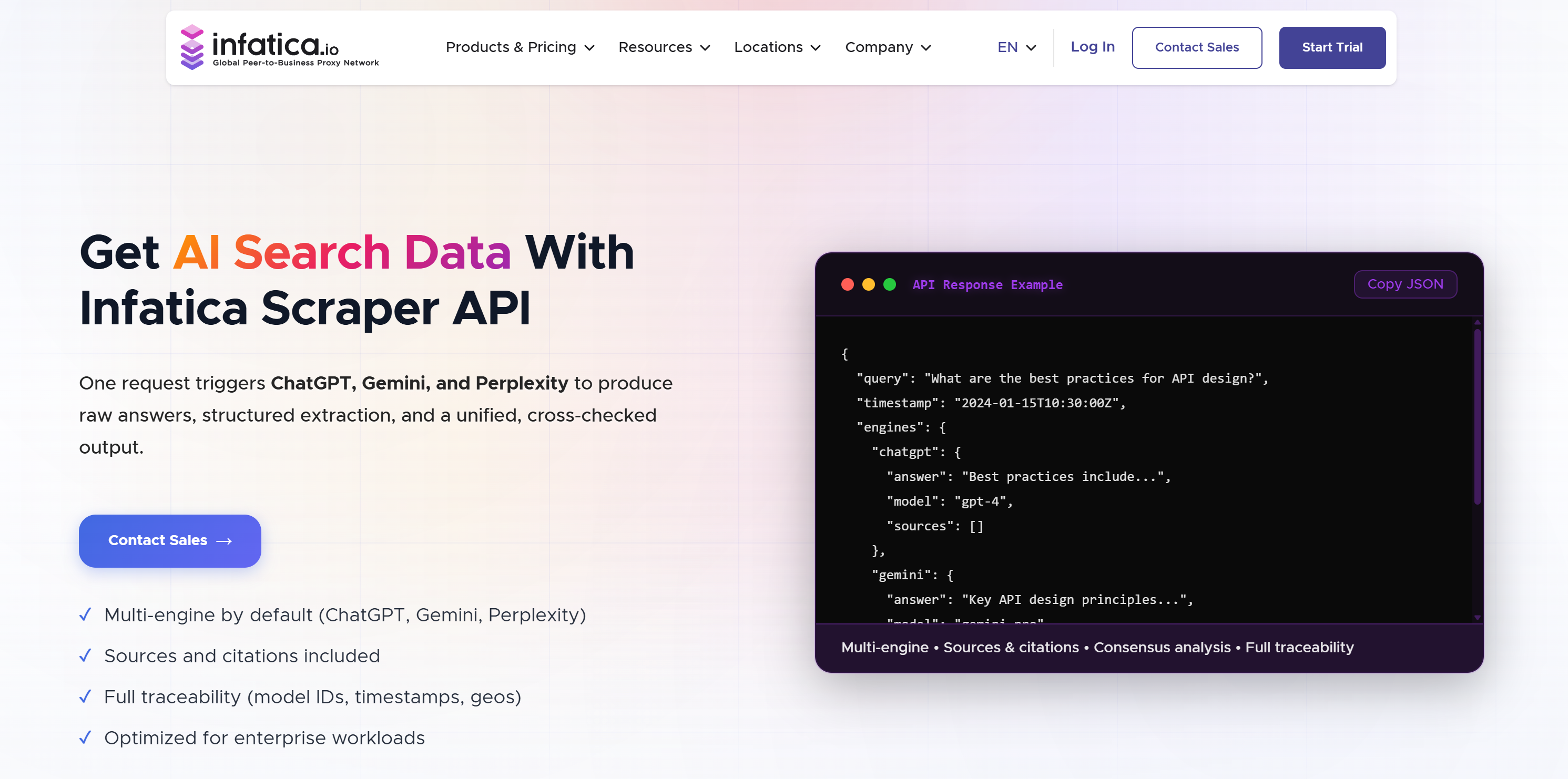
Infatica is a data collection provider offering proxy networks and scraping APIs. Among its many scraping APIs, there is also an AI Search Data API. This supports LLM scraping by querying multiple models in a single request. It returns normalized outputs with answers, sources, and metadata, enabling structured analysis and cross-model comparison. Learn more in the Infatica vs Bright Data comparison.
🏆 Ideal for: Comparing responses across multiple LLMs via normalized outputs and consensus analysis.
Type:
- API-based LLM scraper.
Covered LLMs:
- ChatGPT
- Gemini
- Perplexity
Included data:
- Raw model answers.
- Structured extraction in JSON or Markdown formats.
- Consensus analysis across models (agreement score and differences).
- Traceability metadata (e.g., model IDs, timestamps, geographic information, versions).
- When available, and based on the target model:
- Sources and citations.
- Links and referenced entities.
Infrastructure:
- Built over a scraping engine with browser automation and rendering.
- Can handle up to millions of requests.
- Supports batch jobs and continuous monitoring.
- Built-in residential proxy network integration with geographic targeting.
- Supports webhooks and batch pipelines.
- Structured output normalization across models.
Technical requirements:
- Requires programming skills to send requests and process results via API.
- SDKs available in Python and Node.js for simplified integration.
Compliance:
- GDPR-compliant.
- ISO-certified
- Supports BYOK mode for improved compliance and monitoring.
Pricing:
- Custom pricing (you must contact sales).
6. Apify
Apify is a full-stack platform for web scraping, browser automation, and AI integrations. It features thousands of ready-made serverless applications, built by both the community and the company, called Actors. When it comes to scraping LLMs, there are special Actors for AI platforms such as ChatGPT, Gemini, and others. See how Apify compares with Bright Data.
🏆 Ideal for: Teams looking for many ready-made LLM scraping options with optional API integration.
Type:
- Ready-made LLM scraper with both no-code and API interfaces.
Covered LLMs:
- ChatGPT
- Gemini
- Perplexity
- Grok
- Others, depending on the chosen Actor
Included data:
- Depends on the selected Actor, ranging from plain responses to responses enriched with metadata.
Infrastructure:
- Scalable infrastructure supporting multiple concurrent requests (from 25 to 256).
- Support for built-in and third-party proxy integrations.
- Built-in storage solutions for different data types.
Technical requirements:
- Technical skills required to integrate Actors into custom scripts.
- Basic programming skills necessary to call Actors via API.
- No technical skills needed to manage and launch LLM scraping Actors through the web interface.
Compliance:
- SOC 2 Type II compliant.
- Fully aligned with GDPR and CCPA regulations.
Pricing:
- Depends on the chosen Actor.
Conclusion
In this article, you learned what LLM scrapers are and how they enable you to retrieve data from popular AI models. You also explored the growing importance of synthetic data and LLM data extraction for model training, monitoring, GEO, and many other use cases.
Among the top LLM scrapers available, Bright Data stands out as a leading option. Its enterprise-grade data collection infrastructure is backed by a proxy network of over 400M+ IPs, delivers 99.99% uptime, and achieves a 99.99% success rate.
Bright Data supports several dedicated LLM scraping APIs, including:
- ChatGPT Scraper
- Perplexity Scraper
- Gemini Scraper
- Grok Scraper
- Google AI Mode Scraper
- Copilot Scraper
Sign up for Bright Data for free today and start integrating our solutions for scraping LLMs!
FAQ
What is the difference between an LLM scraper and an LLM-powered scraper?
An LLM scraper collects answers or data directly from LLM providers using prompts. Instead, an LLM-powered scraper relies on LLMs to extract structured data from webpages or documents. In short, LLM scrapers target AI services, while LLM-powered scrapers employ AI to improve traditional web scraping.
Which LLM providers do scrapers usually target?
LLM scrapers target widely used AI platforms that generate structured answers. The most commonly supported providers include ChatGPT, Gemini, Perplexity, and Copilot. Some tools also support Grok and AI search features, such as Google AI Overviews.
What is the llm-scraper library?
llm-scraper is an open-source TypeScript library that uses LLMs to extract structured data from webpages. Instead of writing custom parsing logic, you define a schema and the LLM fills it by analyzing page content. So, rather than a scraping tool for collecting data from LLMs, it is an AI-powered web scraping solution for extracting data from webpages using LLMs. See it in action in our dedicated llm-scraper guide.
How does AI scraping differ from traditional SERP scraping?
In this context, AI scraping refers to collecting structured answers directly from LLM providers. You send a prompt to the scraper and receive a response that may include citations and enriched content. In contrast, traditional SERP scraping involves extracting raw HTML from search result pages based on a query. AI scraping focuses on retrieving model-generated insights, while SERP scraping relies on manually parsing search engine listings. Learn more about the two approaches.
How to use LLMs for web scraping?
If you prefer using LLMs to extract and process data from websites, rather than scraping LLMs themselves, follow these tutorials:
- Web Scraping with ChatGPT: Step-By-Step Tutorial
- Web Scraping Using Perplexity: Step-By-Step Guide
- How to Scrape Google AI Mode: Complete Guide
- How to Scrape Google AI Overviews

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.


