In this guide, you will see:
- What it means to scrape a website to Markdown and why this is useful.
- The main approaches to converting the HTML of a web page to Markdown for static and dynamic sites.
- How to use Python to scrape a webpage to Markdown.
- The limitations of this solution and how to overcome them with Bright Data.
Let’s dive in!
What Does It Mean to “Scrape a Website to Markdown”?
To “Scrape a website to Markdown” means converting its content into Markdown.
More specifically, it refers to taking the HTML of a web page and transforming it into the Markdown data format.
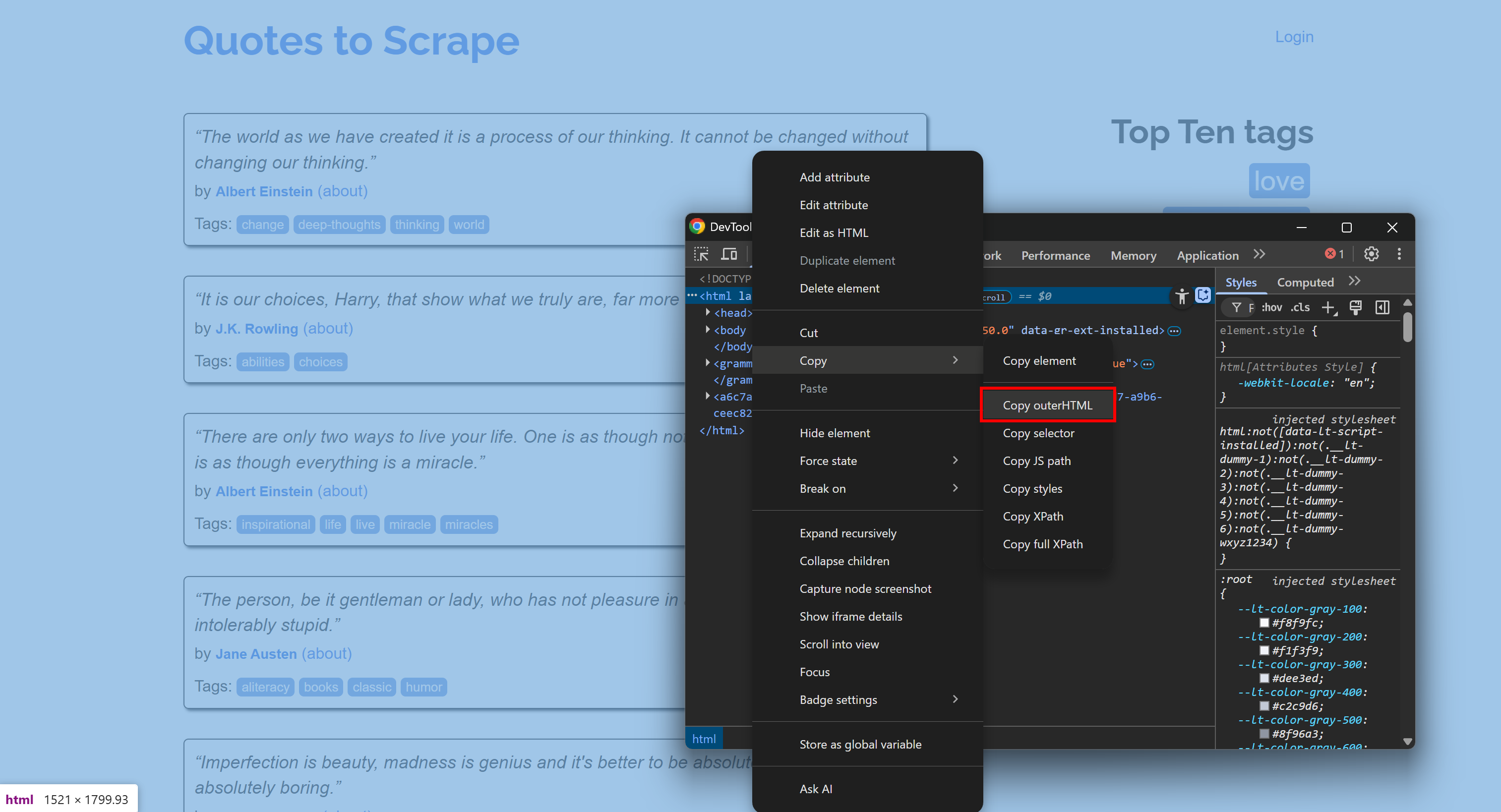
For example, connect to a site, open the DevTools, and copy its HTML:
Then paste it into an HTML-to-Markdown converter:
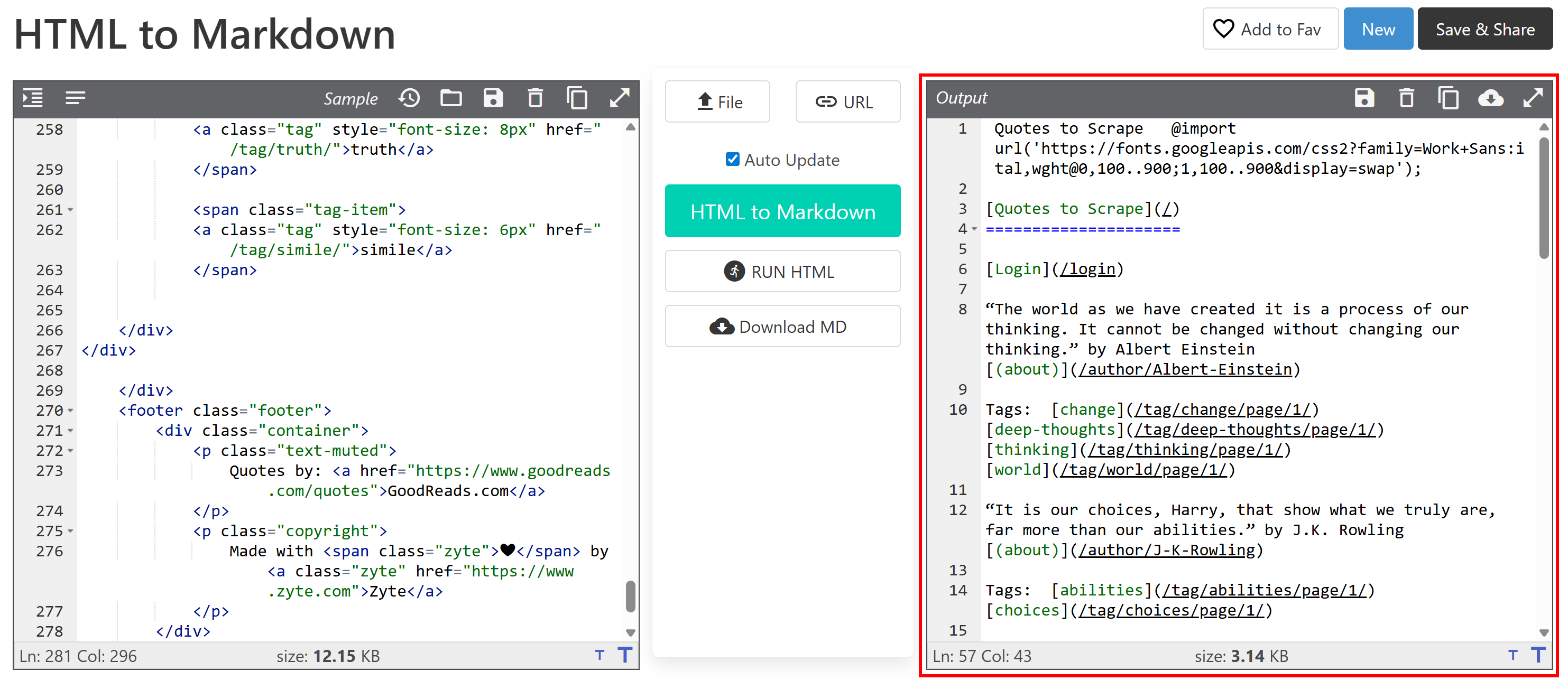
The output will look similar to the Markdown document you want to get via web scraping. Now the goal is to automate this process, which is exactly what this article is about!
[Extra] Why Markdown?
Why Markdown instead of another format (like plain text)? Because, as shown in our data format benchmark, Markdown is one of the best formats for LLM ingestion. The top three reasons are:
- It preserves most of the page’s structure and information (e.g., links, images, headings, etc.).
- It is concise, leading to limited token usage and faster AI processing.
- LLMs tend to understand Markdown much better than plain HTML.
That is why the best AI scraping tools default to working with Markdown.
HTML to Markdown Approaches
You now know that scraping a site to Markdown simply means converting the HTML of its pages into Markdown. At a high level, the process looks like this:
- Connect to the site.
- Retrieve the HTML as a string.
- Use an HTML-to-Markdown library to generate the Markdown output.
The challenge is that not all web pages are delivered the same way. The first two steps can vary significantly depending on whether the target page is static or dynamic. Let’s explore how to handle both scenarios by expanding the required steps!
Step #1: Connect to a Site
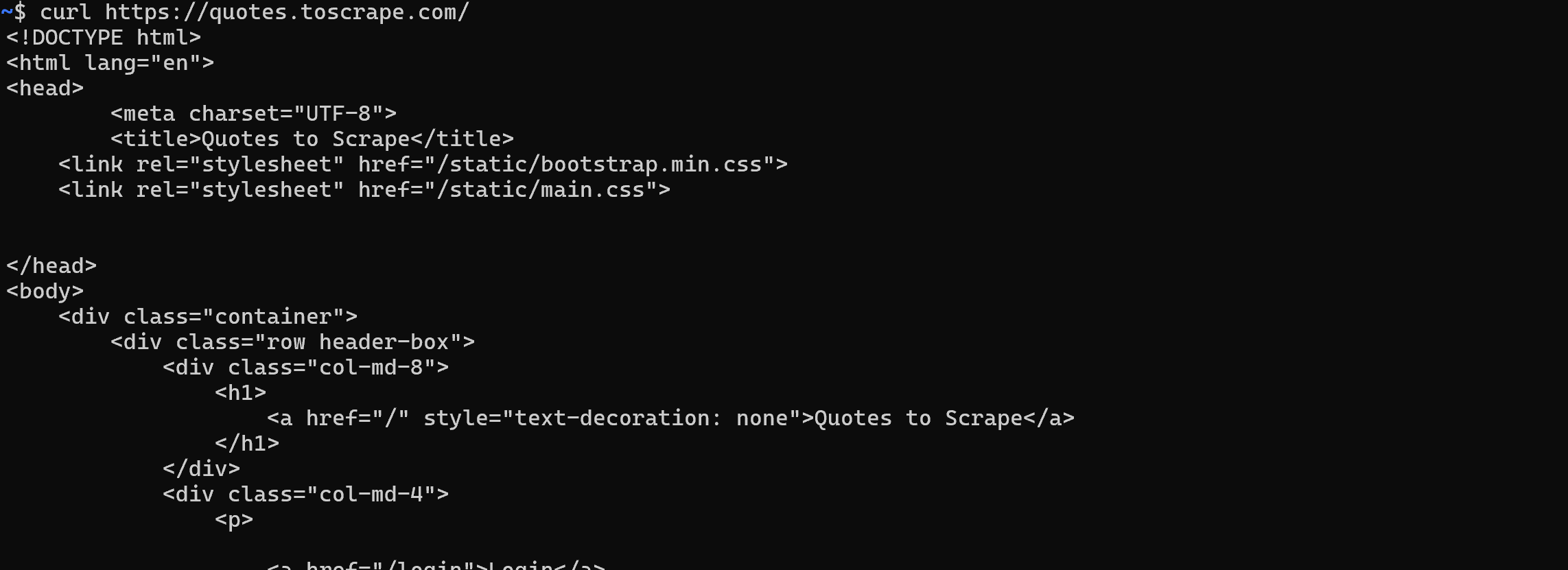
On a static web page, the HTML document returned by the server is exactly what you see in the browser. In other words, everything is fixed and embedded in the HTML produced by the server.
In this case, retrieving the HTML is simple. You just need to perform a GET HTTP request to the page’s URL with any HTTP client:
By contrast, on a dynamic website, most (or part) of the content is retrieved via AJAX and rendered in the browser via JavaScript. That means the initial HTML document returned by the web server only contains the bare minimum. Only after JavaScript executes on the client side, the page is populated with the full content:

In such cases, you cannot just fetch the HTML with a simple HTTP client. Instead, you need a tool that can actually render the page, such as a browser automation tool. Solutions like Playwright, Puppeteer, or Selenium enable you to programmatically control a browser to load the target page and get its fully rendered HTML.
Step #2: Retrieve the HTML as a String
For static web pages, this step is straightforward. The response from the web server to your GET request already contains the full HTML document as a string. Most HTTP clients, like Python’s Requests, provide a method or field to access that directly:
url = "https://quotes.toscrape.com/"
response = requests.get(url)
# Access the HTML content of the page as a string
html = response.textFor dynamic websites, things are much trickier. This time, you are not interested in the raw HTML document returned by the server. Instead, you need to wait until the browser renders the page, the DOM stabilizes, and then access the final HTML.
This corresponds to what you would normally do manually by opening DevTools and copying the HTML from the <html> node:
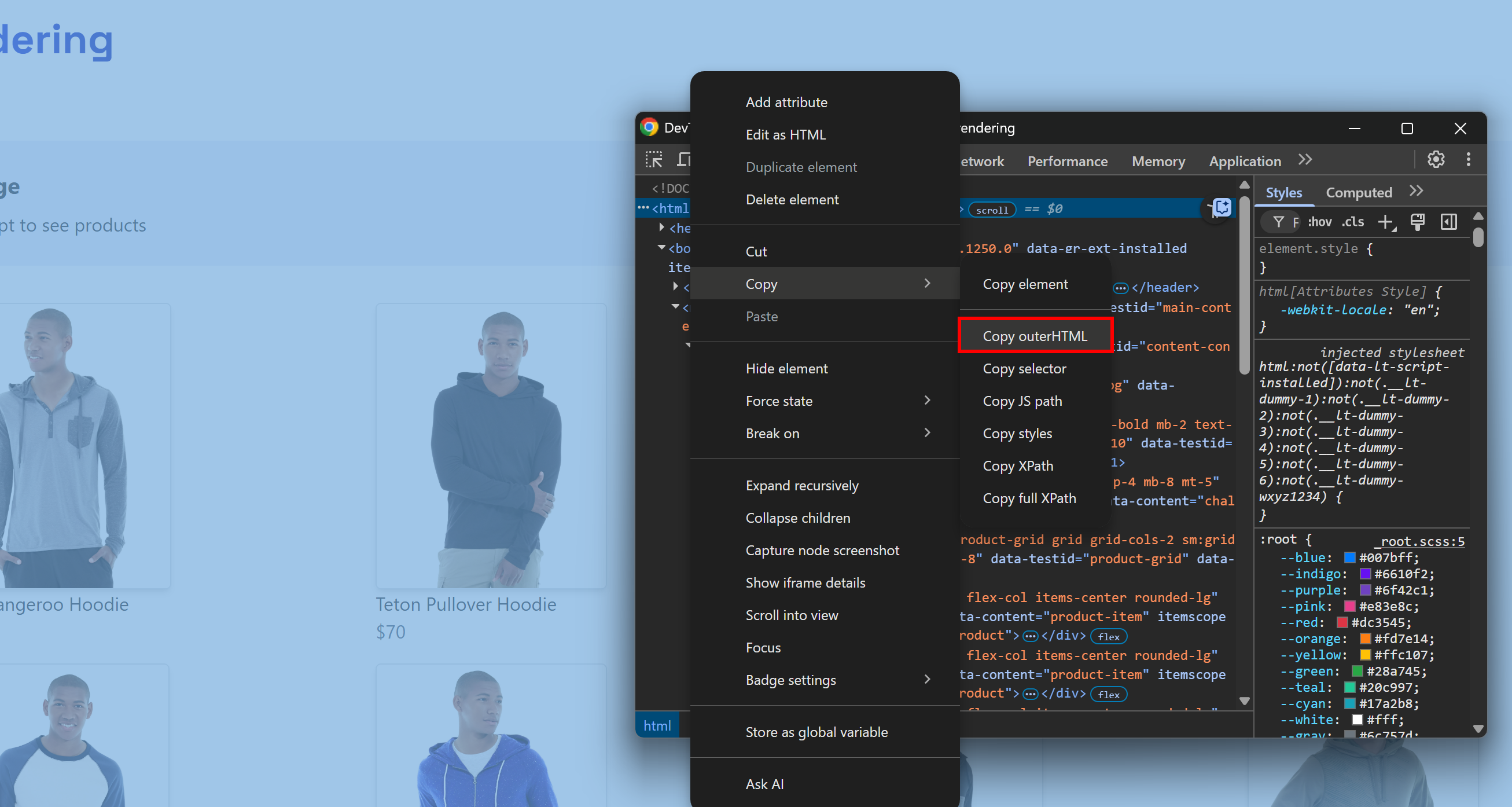
The challenge is knowing when the page has finished rendering. Common strategies include:
- Wait for the
DOMContentLoadedevent: Fires when the initial HTML is parsed and deferred<script>s are loaded and executed. Waiting for this event is the default Playwright behavior. - Wait for the
loadevent: Fires when the entire page has loaded, including stylesheets, scripts, iframes, and images (except lazily loaded ones). - Wait for the
networkidleevent: Considers rendering finished when there are no network requests for a given duration (e.g.,500msin Playwright). This is not reliable for sites with live-updating content, as it will never fire. - Wait for specific elements: Use custom waiting APIs provided by browser automation frameworks to wait until certain elements appear in the DOM.
Once the page is fully rendered, you can extract the HTML using the specific method/field provided by the browser automation tool. For example, in Playwright:
html = await page.content()Step #3: Use an HTML-to-Markdown Library to Generate the Markdown Output
Once you have retrieved the HTML as a string, you just have to feed it to one of the many HTML-to-Markdown libraries available. The most popular are:
| Library | Programming Language | GitHub Stars |
|---|---|---|
markdownify |
Python | 1.8k+ |
turndown |
JavaScript/Node.js | 10k+ |
Html2Markdown |
C# | 300+ |
commonmark-java |
Java | 2.5k+ |
html-to-markdown |
Go | 3k+ |
html-to-markdown |
PHP | 1.8k+ |
Scraping a Website to Markdown: Practical Python Examples
In this section, you will see complete Python snippets to scrape a website to Markdown. The scripts below will implement the steps explained earlier. Note that you can easily convert the logic to JavaScript or any other programming language.
The input will be the URL of a web page, and the output will be the corresponding Markdown content!
Static Sites
In this example, we will use the following two libraries:
requests: To make the GET request and get the page HTML as a string.markdownify: To convert the HTML of the page into Markdown.
Install them both with:
pip install requests markdownifyThe target page will be the static “Quotes to Scrape” page. You can achieve the goal with the following snippet:
import requests
from markdownify import markdownify as md
# The URL of the page to scrape
url = "http://quotes.toscrape.com/"
# Retrieve the HTML content using requests
response = requests.get(url)
# Get the HTML as a string
html_content = response.text
# Convert the HTML content to Markdown
markdown_content = md(html_content)
# Print the Markdown output
print(markdown_content)Optionally, you can export the content to a .md file with:
with open("page.md", "w", encoding="utf-8") as f:
f.write(markdown_content)The result of the script will be:
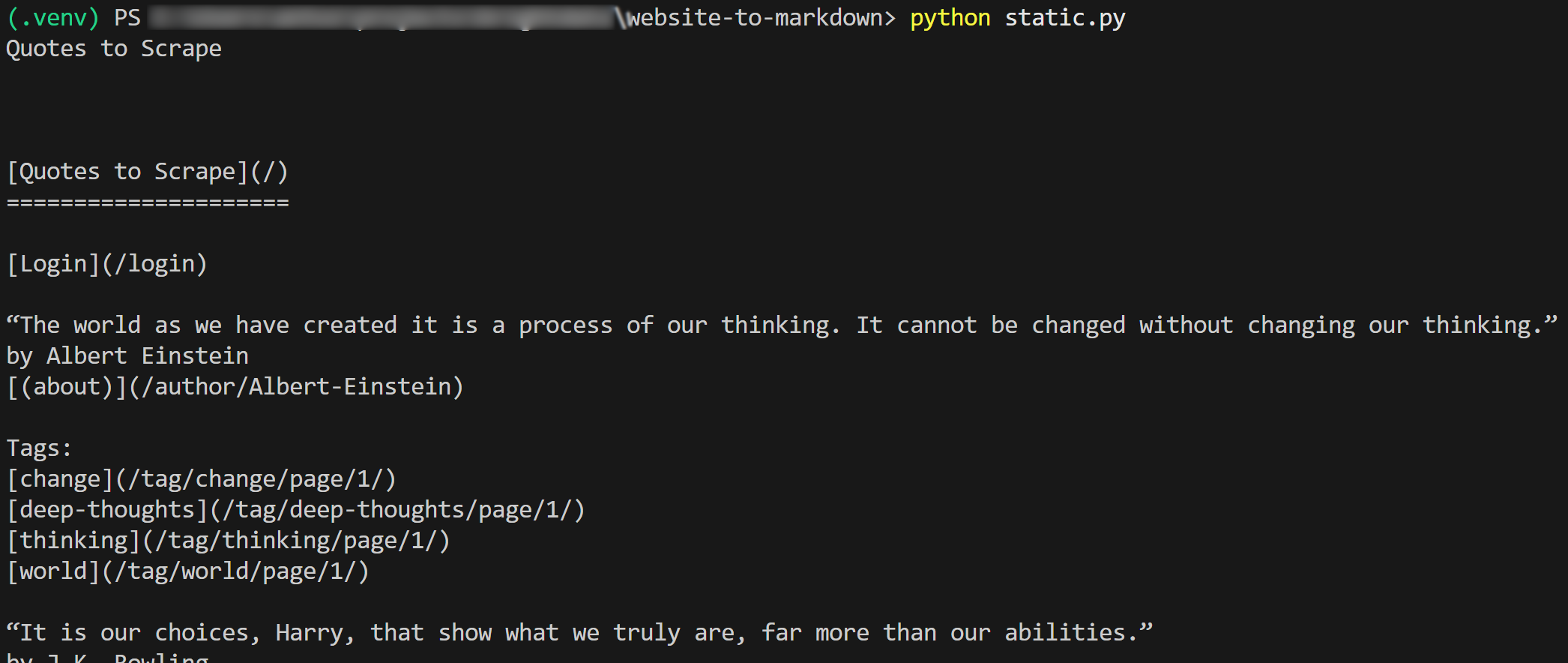
If you copy the output Markdown and paste it into a Markdown renderer, you will see:
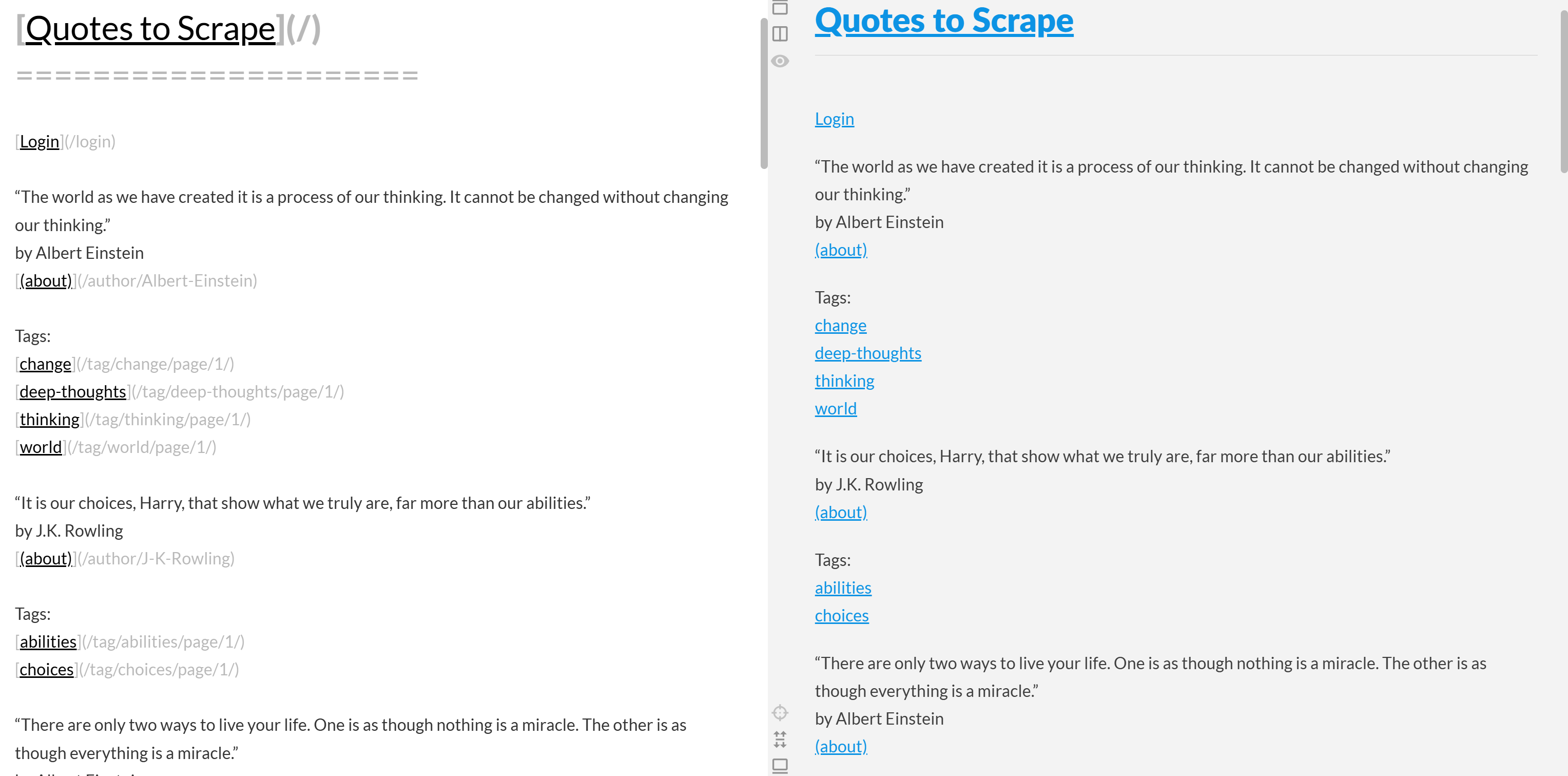
Notice how this looks like a simplified version of the original content from the “Quotes to Scrape” page:
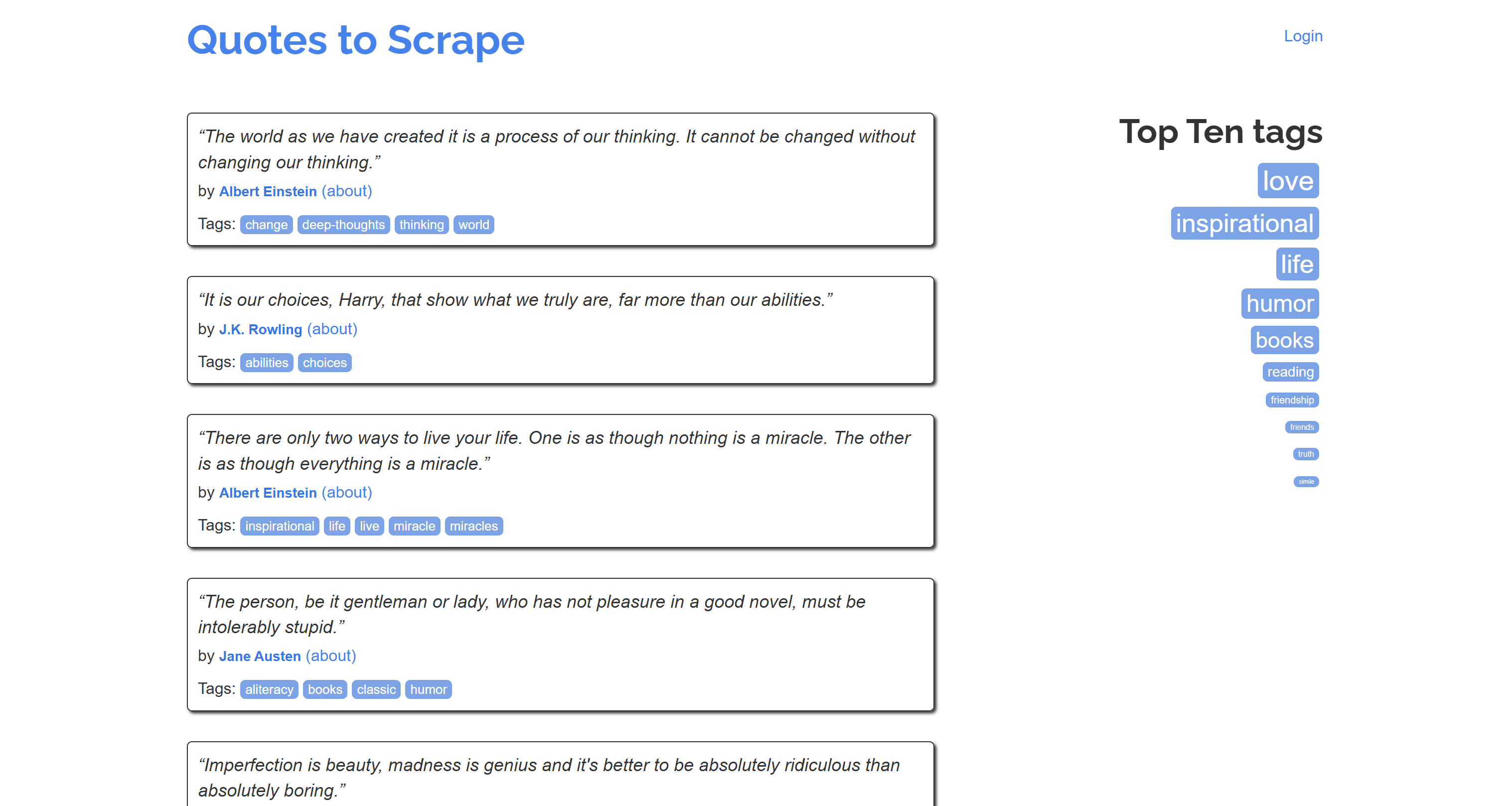
Mission complete!
Dynamic Sites
Here, we will utilize these two libraries:
playwright: To render the target page in a controlled browser instance.markdownify: To convert the rendered DOM of the page into Markdown.
Install the above two dependencies with:
pip install playwright markdownifyThen, complete the Playwright installation with:
python -m playwright installThe destination will be the dynamic “JavaScript Rendering” page on the ScrapingCourse.com site:
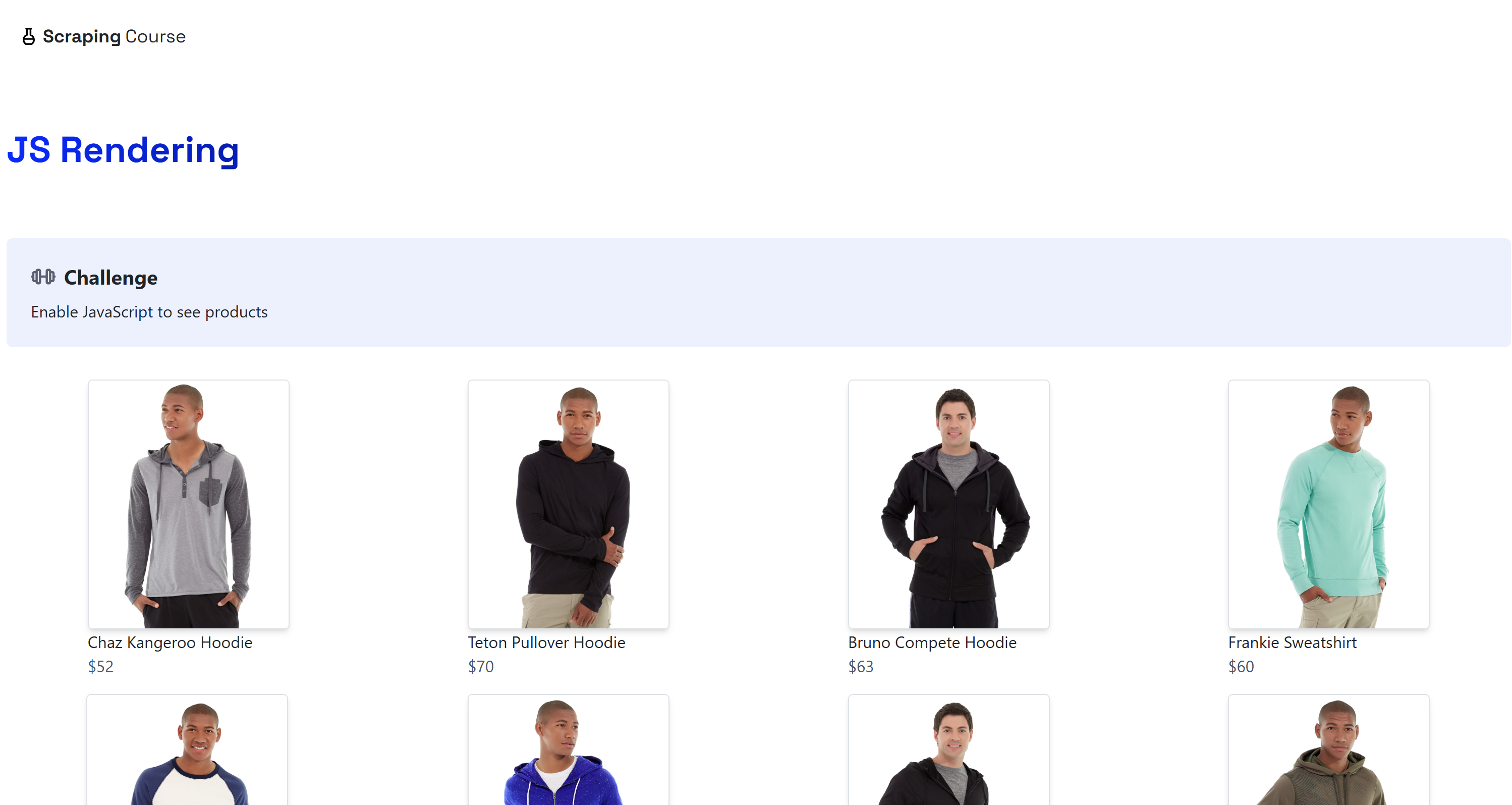
This page retrieves data on the client side via AJAX and renders it using JavaScript:
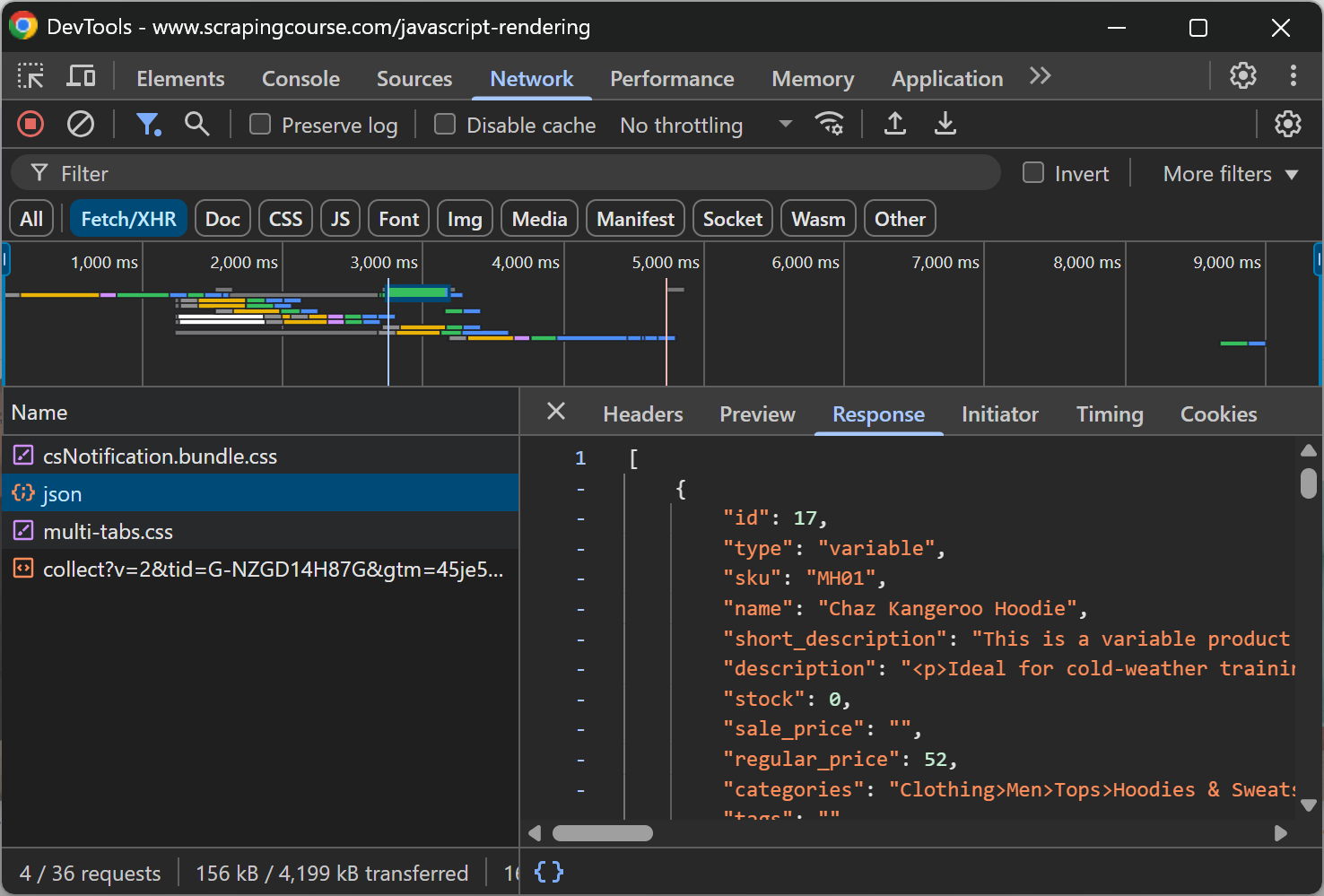
Scrape a dynamic website to Markdown as below:
from playwright.sync_api import sync_playwright
from markdownify import markdownify as md
with sync_playwright() as p:
# Launch a headless browser
browser = p.chromium.launch()
page = browser.new_page()
# URL of the dynamic page
url = "https://scrapingcourse.com/javascript-rendering"
# Navigate to the page
page.goto(url)
# Wait up to 5 seconds for the first product link element to be filled out
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)
# Get the fully rendered HTML
rendered_html = page.content()
# Convert HTML to Markdown
markdown_content = md(rendered_html)
# Print the resulting Markdown
print(markdown_content)
# Close the browser and release its resources
browser.close()In the above snippet, we opted for option 4 (“Wait for specific elements”) because it is the most reliable. In detail, take a look at this line of code:
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)This waits up to 5000 milliseconds (5 seconds) for the .product-link element (an <a> tag) to have a non-empty href attribute. This is enough to indicate that the first product element on the page has been rendered, meaning the data has been retrieved and the DOM is now stable.
The result will be:
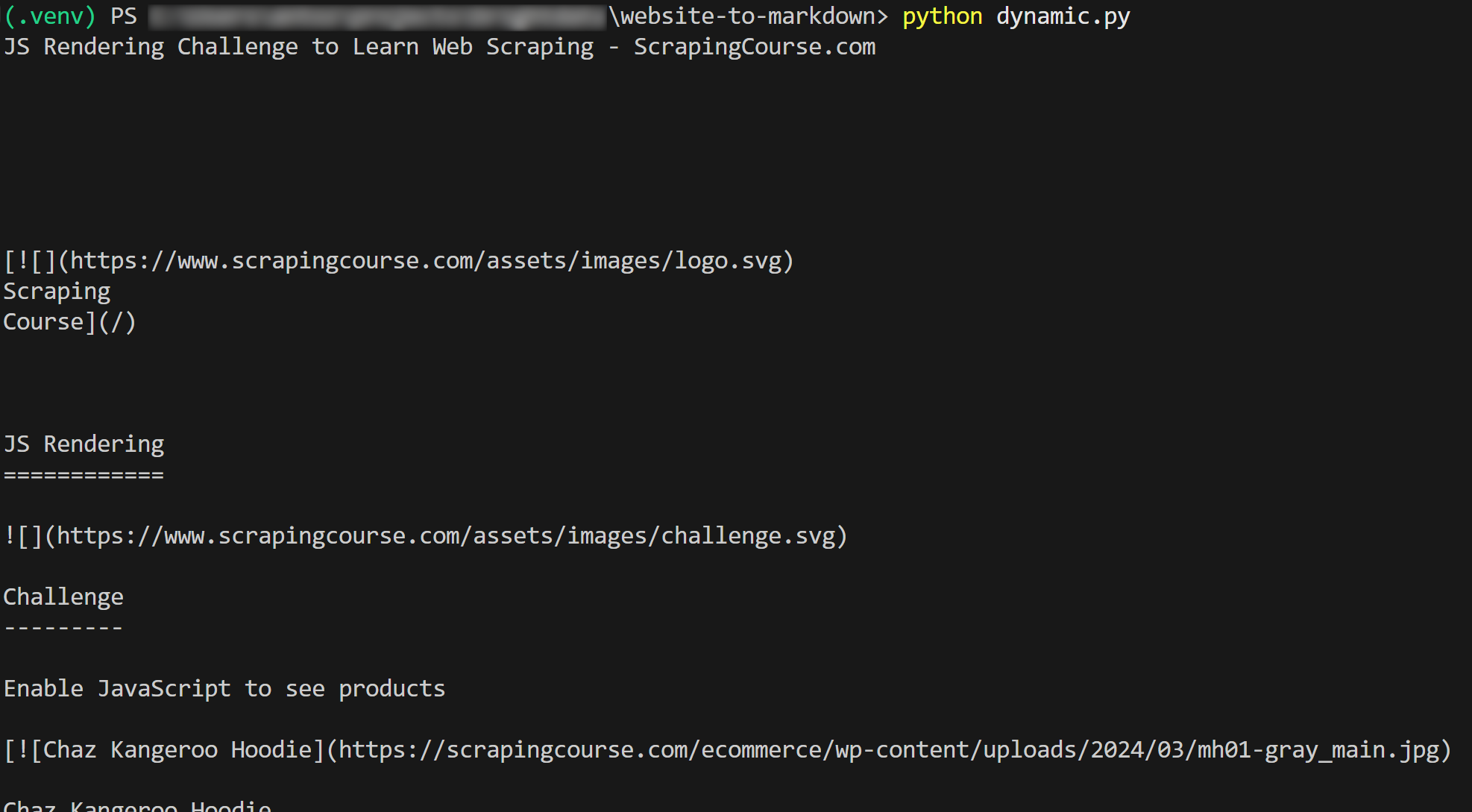
Et voilà! You just learned how to scrape a website to Markdown.
Limitations of These Approaches and the Solution
All the examples in this blog post have a fundamental aspect in common: they refer to pages that were designed to be easy to scrape!
Unfortunately, most real-world web pages are not so open to web scraping bots. Quite the contrary, many sites implement anti-scraping protections such as CAPTCHAs, IP bans, browser fingerprinting, and more.
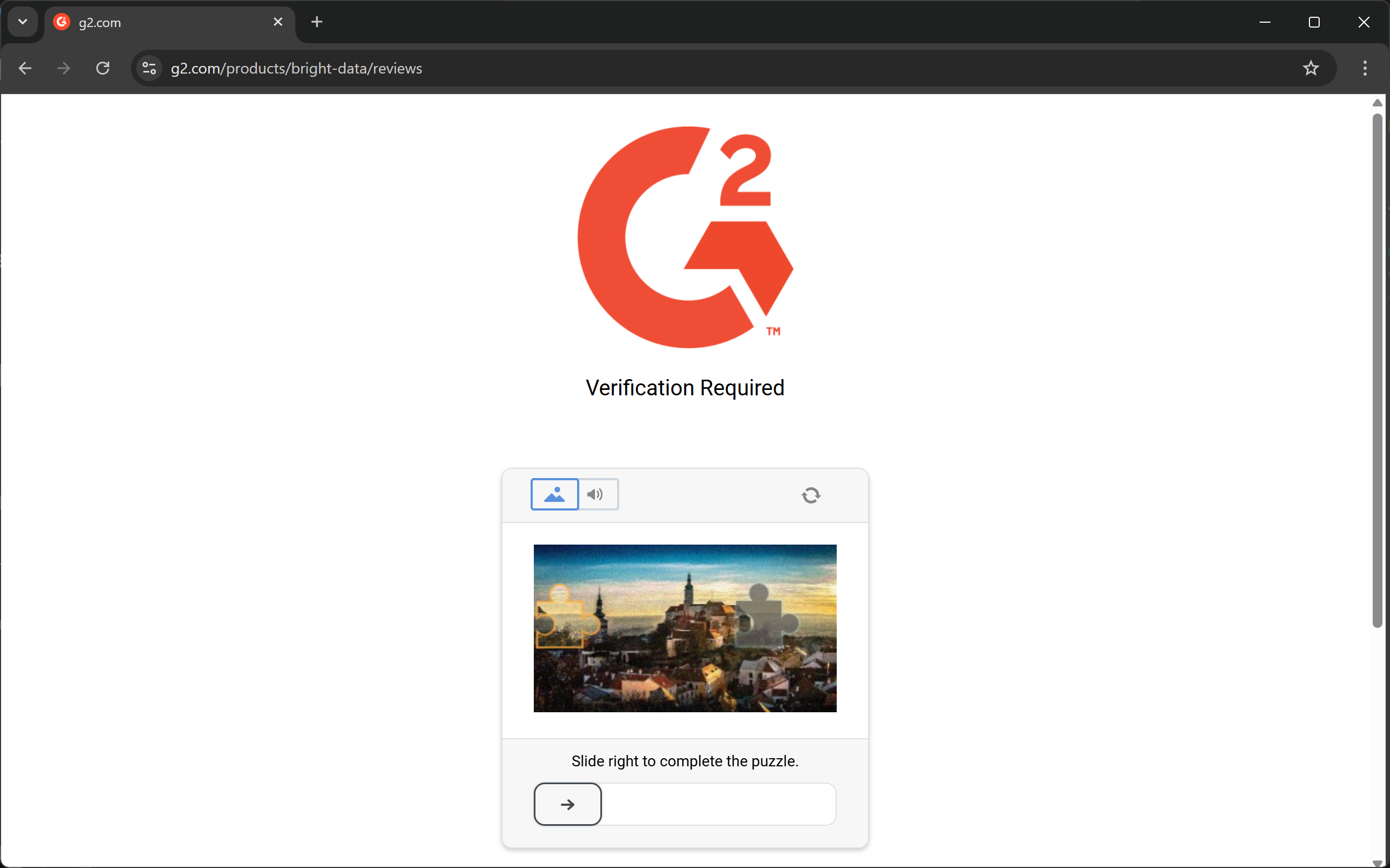
In other words, you cannot expect a simple HTTP request or a Playwright goto() instruction to work as intended. When targeting most real-world websites, you may encounter 403 Forbidden errors:

Or error / human verification pages:
Another key aspect to consider is that most HTML-to-Markdown libraries perform a raw data conversion. This can lead to undesired results. For example, if a page contains <style> or <script> elements embedded directly in the HTML, their content (i.e., CSS and JavaScript code, respectively) will be included in the Markdown output:
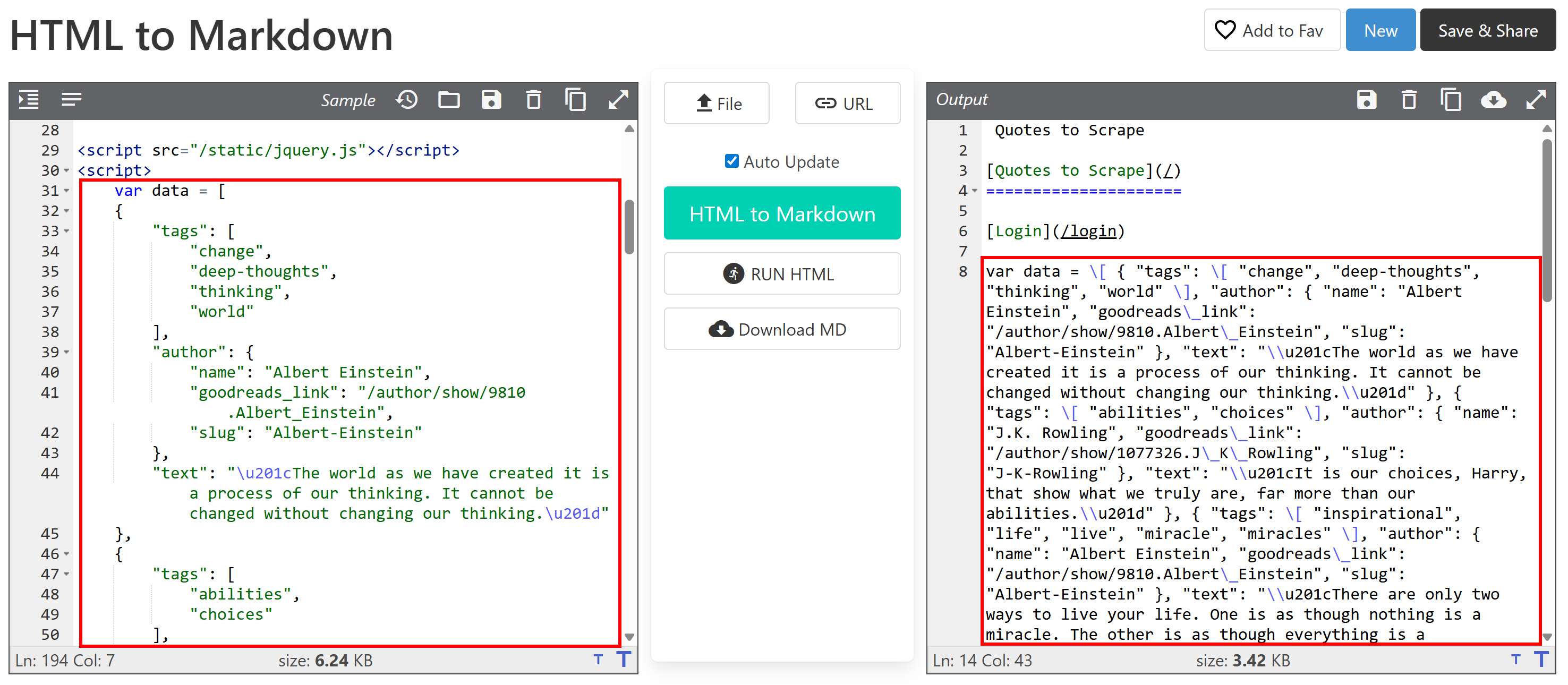
This is generally unwanted, especially if you plan to feed the Markdown to an LLM for data processing. After all, those text elements just add noise.
The solution? Rely on a dedicated Web Unlocker API that can access any site, regardless of its protections, and produce LLM-ready Markdown. This ensures that the extracted content is clean, structured, and ready for downstream AI tasks.
Scraping to Markdown with Web Unlocker
Bright Data’s Web Unlocker is a cloud-based web scraping API that can return the HTML of any web page. That is true regardless of the anti-scraping or anti-bot protections in place, and whether the page is static or dynamic.
The API is backed by a proxy network of over 150 million IPs, allowing you to focus on your data collection while Bright Data handles the full unblocking infrastructure, JavaScript rendering, CAPTCHA solving, scaling, and maintenance updates.
Using it is simple. Make a POST HTTP request to Web Unlocker with the correct arguments, and you will get back the fully unlocked web page. You can also configure the API to return content in LLM-optimized Markdown format.
Follow the initial setup guide, and then use Web Unlocker to scrape a website to Markdown with just a few lines of code:
# pip install requests
import requests
# Replace these with the right values from your Bright Data account
BRIGHT_DATA_API_KEY= "<YOUR_BRIGHT_DATA_API_KEY>"
WEB_UNLOCKER_ZONE = "<YOUR_WEB_UNLOCKER_ZONE_NAME>"
# Replace with your target URL
url_to_scrape = "https://www.g2.com/products/bright-data/reviews"
# Prepare the required headers
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", # For authentication
"Content-Type": "application/json"
}
# Prepare the Web Unlocker POST payload
payload = {
"url": url_to_scrape,
"zone": WEB_UNLOCKER_ZONE,
"format": "raw",
"data_format": "markdown" # To get the response as Markdown content
}
# Make a POST request to Bright Data Web Unlocker API
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
# Get the Markdown response and print it
markdown_content = response.text
print(markdown_content)Execute the script and you will get:
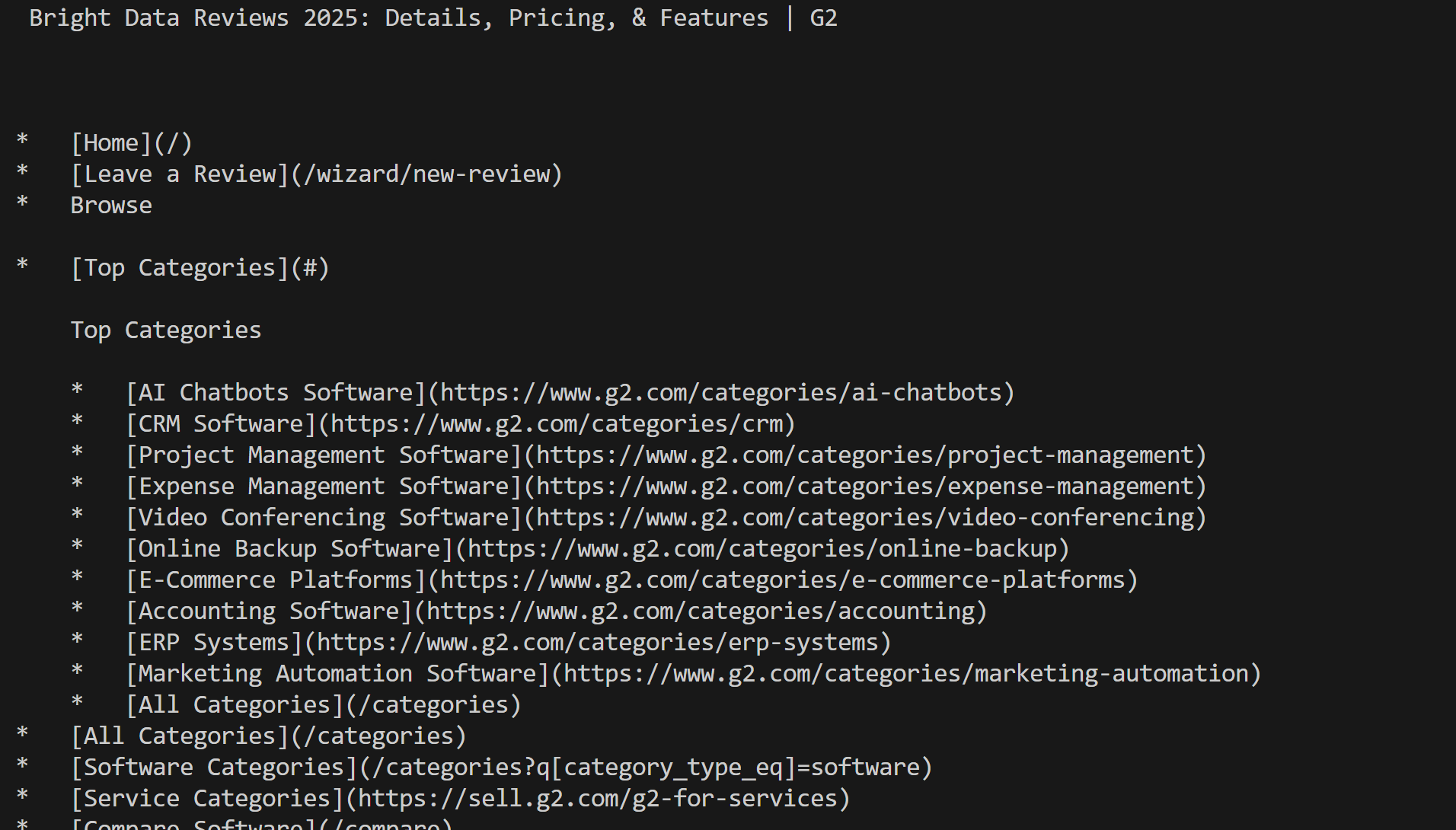
Note how, this time, you were not blocked by G2. Instead, you got the actual Mardkwon content, as desired.
Perfect! Converting a website to Markdown has never been easier.
Note: This solution is available through 75+ integrations with AI agent tools such as CrawlAI, Agno, LlamaIndex, and LangChain. Additionally, it can be used directly via the scrape_as_markdown tool on the Bright Data Web MCP server.
Conclusion
In this blog post, you explored why and how to convert a webpage to Markdown. As discussed, converting HTML to Markdown is not always straightforward due to challenges like anti-scraping protections and suboptimal Markdown results.
Bright Data has you covered with Web Unlocker, a cloud-based web scraping API capable of converting any webpage into LLM-optimized Markdown. You can call this API manually or integrate it directly into AI agent-building solutions or via the Web MCP integration.
Remember, Web Unlocker is just one of many web data and scraping tools available in Bright Data’s AI infrastructure.
Sign up for a free Bright Data account today and start exploring our AI-ready web data solutions!



Technical Writer
 5.5 years experience
5.5 years experience
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.