

Wikipedia is an extensive and comprehensive source of information, containing millions of articles covering nearly every topic. For researchers, data scientists, and developers, this data opens up countless opportunities, from building machine learning datasets to conducting academic research. In this article, we’ll walk you through the process of scraping Wikipedia step by step.
Using Bright Data Wikipedia Scraper API
If you’re looking to efficiently extract data from Wikipedia, the Bright Data Wikipedia Scraper API is a great alternative to manual web scraping. This powerful API automates the process, making it much easier to gather large volumes of information.
Key Use Cases:
- Collect explanations on a wide range of topics
- Compare information from Wikipedia with other data sources
- Conduct research using large datasets
- Scrape images from Wikipedia Commons
You can get your data in formats like JSON, CSV, and .gz, and it supports various delivery options, including Amazon S3, Google Cloud Storage, and Microsoft Azure.
With just one API call, you can access a wealth of data quickly and easily!
How to Scrape Wikipedia Using Python
Follow this step-by-step tutorial to scrape Wikipedia using Python.
1. Setup and Prerequisites
Before you begin, ensure your development environment is properly configured:
- Install Python: Download and install the latest version of Python from the official Python website.
- Choose an IDE: Use an IDE like PyCharm, Visual Studio Code, or Jupyter Notebook for your development work.
- Basic Knowledge: Make sure you’re familiar with CSS selectors and comfortable using browser DevTools to inspect page elements.
If you’re new to Python, read this how to scrape with Python guide for detailed instructions.
Next, create a new project using Poetry, a dependency management tool that simplifies managing packages and virtual environments in Python.
poetry new wikipedia-scraper
This command will generate the following project structure:
wikipedia-scraper/
├── pyproject.toml
├── README.md
├── wikipedia_scraper/
│ └── __init__.py
└── tests/
└── __init__.py
Navigate into the project directory and install the necessary dependencies:
cd wikipedia-scraper
poetry add requests beautifulsoup4 pandas lxml
First, BeautifulSoup is used for parsing HTML and XML documents, making it easy to navigate and extract specific elements from web pages. The requests library handles sending HTTP requests and retrieving the content of web pages. Pandas is a powerful tool for manipulating and analyzing the scraped data, particularly useful when working with tables. Finally, lxml is used to speed up the parsing process, enhancing the performance of BeautifulSoup.
Next, activate the virtual environment and open the project folder in your preferred code editor (VS Code in this case):
poetry shell
code .
Open the pyproject.toml file to verify your project’s dependencies. It should look like this:
[tool.poetry.dependencies]
python = "^3.12"
requests = "^2.32.3"
beautifulsoup4 = "^4.12.3"
pandas = "^2.2.3"
lxml = "^5.3.0"
Finally, create a main.py file within the wikipedia_scraper folder where you’ll write your scraping logic. Your updated project structure should now look like this:
wikipedia-scraper/
├── pyproject.toml
├── README.md
├── wikipedia_scraper/
│ ├── __init__.py
│ └── main.py
└── tests/
└── __init__.py
Your environment is now set up, and you’re ready to start writing the Python code to scrape Wikipedia.
2. Connecting to the Target Wikipedia Page
To begin, connect to the desired Wikipedia page. In this example, we’ll scrape the following Wikipedia page.

Here’s a simple code snippet to connect to a Wikipedia page using Python:
import requests # For making HTTP requests
from bs4 import BeautifulSoup # For parsing HTML content
def connect_to_wikipedia(url):
response = requests.get(url) # Send a GET request to the URL
# Check if the request was successful
if response.status_code == 200:
return BeautifulSoup(response.text, "html.parser") # Parse and return the HTML
else:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
return None # Return None if the request fails
wikipedia_url = "<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>"
soup = connect_to_wikipedia(wikipedia_url) # Get the soup object for the specified
In the code, the Python requests library allows you to send an HTTP request to the URL, and with BeautifulSoup, you can parse the HTML content of the page.
3. Inspecting the Page
To scrape data effectively, you need to understand the structure of the webpage’s DOM (Document Object Model). For example, to extract all the links on the page, you can target the <a> tags, as shown below:

To scrape images, target the <img> tags and extract the src attribute to get the image URLs.

To extract data from tables, you can target the <table> tag with the class wikitable. This allows you to gather all the rows and columns of the table and extract the required data.

To extract paragraphs, simply target the <p> tags that contain the main textual content of the page.

That’s it! By targeting these specific elements, you can extract desired data from any Wikipedia page.
4. Extracting Links
Wikipedia articles contain internal and external links that direct users to related topics, references, or external resources. To extract all the links from a Wikipedia page, you can use the following code:
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True): # Find all anchor tags with href attribute
url = link["href"]
if not url.startswith("http"): # Check if the URL is relative
url = "<https://en.wikipedia.org>" + url # Convert relative links to absolute URLs
links.append(url)
return links # Return the list of extracted links
The soup.find_all('a', href=True) function retrieves all <a> tags on the page that contain an href attribute, which includes both internal and external links. The code also ensures relative URLs are properly formatted.
The result might look like:
<https://en.wikipedia.org#Early_life>
<https://en.wikipedia.org#Club_career>
<https://en.wikipedia.org/wiki/Real_Madrid>
<https://en.wikipedia.org/wiki/Portugal_national_football_team>
5. Extracting Paragraphs
To scrape textual content from a Wikipedia article, you can target the <p> tags, which hold the main body of text. Here’s how to extract paragraphs using BeautifulSoup:
def extract_paragraphs(soup):
paragraphs = [p.get_text(strip=True) for p in soup.find_all("p")] # Extract text from paragraph tags
return [p for p in paragraphs if p and len(p) > 10] # Return paragraphs longer than 10 characters
This function captures all paragraphs on the page, filtering out any empty or overly short ones to avoid irrelevant content like citations or single words.
An example result:
Cristiano Ronaldo dos Santos AveiroGOIHComM(Portuguese pronunciation:[kɾiʃˈtjɐnuʁɔˈnaldu]; born 5 February 1985) is a Portuguese professionalfootballerwho plays as aforwardfor andcaptainsbothSaudi Pro LeagueclubAl Nassrand thePortugal national team. Widely regarded as one of the greatest players of all time, Ronaldo has won fiveBallon d'Orawards,[note 3]a record threeUEFA Men's Player of the Year Awards, and fourEuropean Golden Shoes, the most by a European player. He has won33 trophies in his career, including seven league titles, fiveUEFA Champions Leagues, theUEFA European Championshipand theUEFA Nations League. Ronaldo holds the records for mostappearances(183),goals(140) andassists(42) in the Champions League,most appearances(30), assists (8),goals in the European Championship(14),international goals(133) andinternational appearances(215). He is one of the few players to have madeover 1,200 professional career appearances, the most by anoutfieldplayer, and has scoredover 900 official senior career goalsfor club and country, making him the top goalscorer of all time.
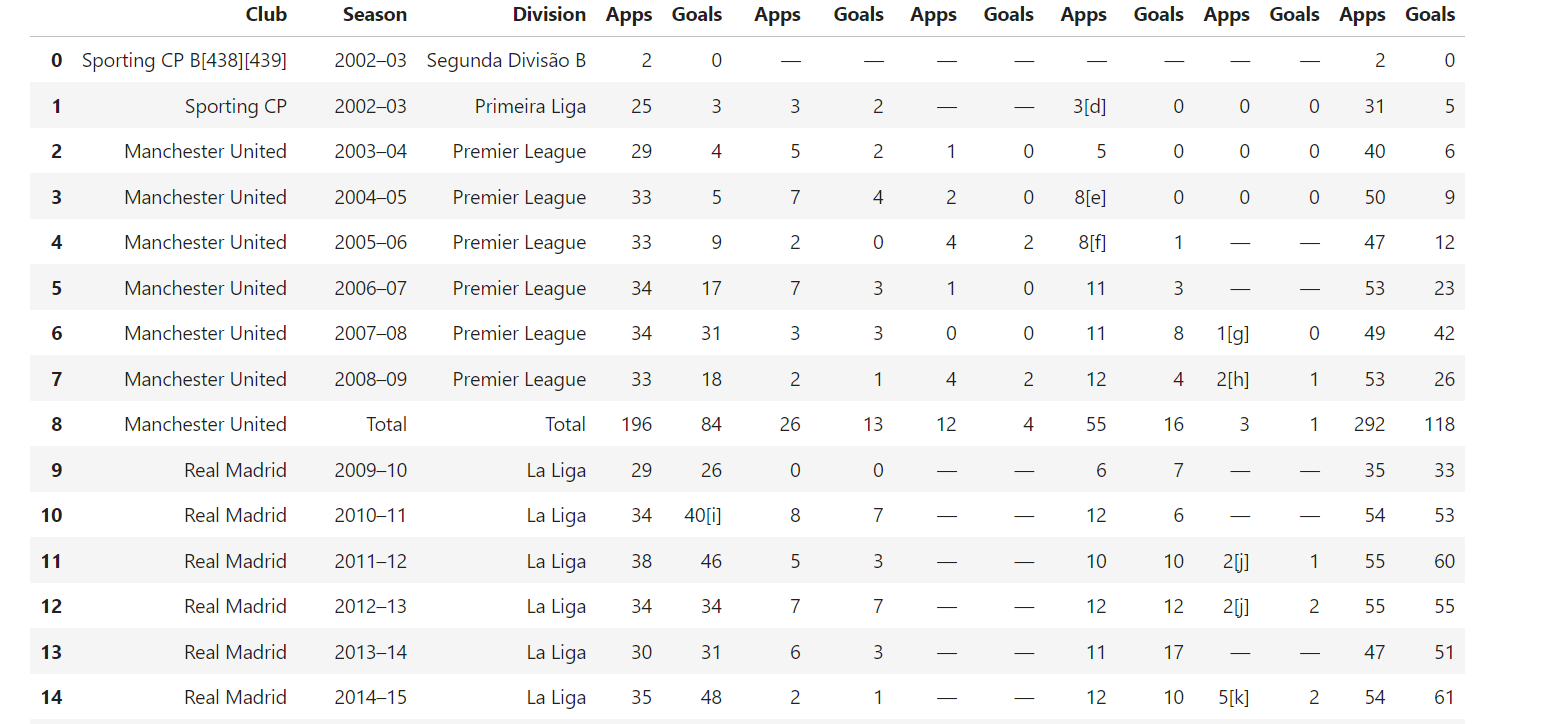
6. Extracting Tables
Wikipedia often includes tables with structured data. To extract these tables, use this code:
def extract_tables(soup):
tables = []
for table in soup.find_all("table", {"class": "wikitable"}): # Find tables with the 'wikitable' class
table_html = StringIO(str(table)) # Convert table HTML to string
df = pd.read_html(table_html)[0] # Read the HTML table into a DataFrame
tables.append(df)
return tables # Return list of DataFrames
This function finds all tables with the class wikitable and uses pandas.read_html() to convert them into DataFrames for further manipulation.
Example result:
7. Extracting Images
Images are another valuable resource that you can scrape from Wikipedia. The following function captures image URLs from the page:
def extract_images(soup):
images = []
for img in soup.find_all("img", src=True): # Find all image tags with src attribute
img_url = img["src"]
if not img_url.startswith("http"): # Prepend 'https:' for relative URLs
img_url = "https:" + img_url
if "static/images" not in img_url: # Exclude static or non-relevant images
images.append(img_url)
return images # Return the list of image URLs
This function finds all images (<img> tags) on the page, appends https: to relative URLs, and filters out non-content images, ensuring only relevant images are extracted.
Example result:
<https://upload.wikimedia.org/wikipedia/commons/d/d7/Cristiano_Ronaldo_2018.jpg>
<https://upload.wikimedia.org/wikipedia/commons/7/76/Cristiano_Ronaldo_Signature.svgb>
8. Saving the Scraped Data
Once you’ve extracted the data, the next step is to save it for later use. Let’s save the data into separate files for links, images, paragraphs, and tables.
def store_data(links, images, tables, paragraphs):
# Save links to a text file
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}\n")
# Save images to a JSON file
with open("wikipedia_images.json", "w", encoding="utf-8") as f:
json.dump(images, f, indent=4)
# Save paragraphs to a text file
with open("wikipedia_paragraphs.txt", "w", encoding="utf-8") as f:
for para in paragraphs:
f.write(f"{para}\n\n")
# Save each table as a separate CSV file
for i, table in enumerate(tables):
table.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
The store_data function organizes the scraped data:
- Links are saved in a text file.
- Image URLs are saved in a JSON file.
- Paragraphs are stored in another text file.
- Tables are saved in CSV files.
This organization makes it easy to access and work with the data later on.
Check out our guide to learn more about how to parse and serialize data to JSON in Python.
Putting It All Together
Now, let’s combine all the functions to create a complete scraper that extracts and saves data from a Wikipedia page:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from io import StringIO
import json
# Extract all links from the page
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True):
url = link["href"]
if not url.startswith("http"):
url = "<https://en.wikipedia.org>" + url
links.append(url)
return links
# Extract image URLs from the page
def extract_images(soup):
images = []
for img in soup.find_all("img", src=True):
img_url = img["src"]
if not img_url.startswith("http"):
img_url = "https:" + img_url
if "static/images" not in img_url: # Exclude unwanted static images
images.append(img_url)
return images
# Extract all tables from the page
def extract_tables(soup):
tables = []
for table in soup.find_all("table", {"class": "wikitable"}):
table_html = StringIO(str(table))
df = pd.read_html(table_html)[0] # Convert HTML table to DataFrame
tables.append(df)
return tables
# Extract paragraphs from the page
def extract_paragraphs(soup):
paragraphs = [p.get_text(strip=True) for p in soup.find_all("p")]
return [p for p in paragraphs if p and len(p) > 10] # Filter out empty or short paragraphs
# Store the extracted data into separate files
def store_data(links, images, tables, paragraphs):
# Save links to a text file
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}\n")
# Save images to a JSON file
with open("wikipedia_images.json", "w", encoding="utf-8") as f:
json.dump(images, f, indent=4)
# Save paragraphs to a text file
with open("wikipedia_paragraphs.txt", "w", encoding="utf-8") as f:
for para in paragraphs:
f.write(f"{para}\n\n")
# Save each table as a CSV file
for i, table in enumerate(tables):
table.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
# Main function to scrape a Wikipedia page and save the extracted data
def scrape_wikipedia(url):
response = requests.get(url) # Fetch the page content
soup = BeautifulSoup(response.text, "html.parser") # Parse the content with BeautifulSoup
links = extract_links(soup)
images = extract_images(soup)
tables = extract_tables(soup)
paragraphs = extract_paragraphs(soup)
# Save all extracted data into files
store_data(links, images, tables, paragraphs)
# Example usage: scrape Cristiano Ronaldo's Wikipedia page
if __name__ == "__main__":
scrape_wikipedia("<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>")
When you run the script, several files will be created in your directory:
wikipedia_images.jsoncontaining all the image URLs.wikipedia_links.txtwith all the links from the page.wikipedia_paragraphs.txtholding the extracted paragraphs.- CSV files for each table found on the page (e.g.,
wikipedia_table_1.csv,wikipedia_table_2.csv).
The result might look like:

That’s it! You’ve successfully scraped and stored data from Wikipedia into separate files.
Setting Up Bright Data Wikipedia Scraper API
Setting up and using Bright Data Wikipedia Scraper API is straightforward and can be done in just a few minutes. Follow these steps to quickly get started and begin collecting data from Wikipedia with ease.
Step 1: Create a Bright Data Account
Go to the Bright Data website and sign in to your account. If you don’t have an account yet, create one—it’s free to get started. Follow these steps:
- Go to the Bright Data website.
- Click on Start Free Trial and follow the prompts to create your account.
- Once you’re in your dashboard, locate the credit card icon in the left sidebar to access the Billing page.
- Add a valid payment method to activate your account.

Once your account is successfully activated, navigate to the Web Scraper API section in the dashboard. Here, you can search for any web scraper API you’d like to use. For our purposes, search for Wikipedia.

Click on the Wikipedia articles – Collect by URL option. It will allow you to collect Wikipedia articles simply by providing the URLs.
Step 2: Start Setting Up an API Call
Once you’ve clicked, you’ll be directed to a page where you can set up your API call.

Before proceeding, you need to create an API token to authenticate your API calls. Click on the Create Token button and copy the generated token. Keep this token safe, as you’ll need it later.

Step 3: Set Parameters and Generate the API Call
Now that you have your token, you’re ready to configure your API call. Provide the URLs of the Wikipedia pages you want to scrape, and on the right side, a cURL command will be generated based on your input.

Copy the cURL command, replace API_Token with your actual token, and run it in your terminal. This will generate a snapshot_id, which you’ll use to retrieve the scraped data.
Step 4: Retrieve the Data
Using the snapshot_id you generated, you can now retrieve the data. Simply paste this ID into the Snapshot ID field, and the API will automatically generate a new cURL command on the right side. You can use this command to pull the data. Additionally, you can choose the file format for the data, such as JSON, CSV, or other available options.

You also have the option to deliver the data to different storage services such as Amazon S3, Google Cloud Storage, or Microsoft Azure Storage.

Step 5: Run the Command
For this example, let’s assume you want to get the data in a JSON file. Choose JSON as the file format, and copy the generated cURL command. If you want to save the data directly to a file, simply add -o my_data.json to the end of the cURL command. If you prefer to store this data on your local machine, adding -o will automatically store the data in the specified file.
Run it in your terminal, and you’ll have all the extracted data in just a few seconds!
curl.exe -H "Authorization: Bearer 50xxx52c-xxxx-xxxx-xxxx-2748xxxxx487" "<https://api.brightdata.com/datasets/v3/snapshot/s_mxxg2xxxxx2g3nq?format=json>" -o my_data.json
Don’t want to handle Wikipedia web scraping yourself but still need the data? Consider purchasing a Wikipedia dataset instead.

Yes, It’s that simple!
Conclusion
This article covered everything you need to get started with scraping Wikipedia using Python. We’ve successfully extracted a variety of data, including image URLs, text content, tables, and internal and external links. However, for faster and more efficient data extraction, using Bright Data’s Wikipedia Scraper API is a straightforward solution.
Looking to scrape other websites? Register now and try our Web Scraper API. Start your free trial today!

Technical Writer
Satyam Tripathi helps SaaS and data startups turn complex tech into actionable content, boosting developer adoption and user understanding.



