

In this hands-on tutorial, you’ll learn how to scrape data from Glassdoor using Playwright Python. You will also learn about the anti-scraping techniques employed by Glassdoor and how Bright Data can help. You’ll also learn about the Bright Data solution that makes scraping Glassdoor much faster.
Skip Scraping, Get the Data
Want to skip the scraping process and access data directly? Consider taking a look at our Glassdoor dataset.
The Glassdoor dataset offers a complete company overview with reviews and FAQs that provide insights about jobs and companies. You can use our Glassdoor dataset to find market trends and business information on companies and how current and past employees perceive and rate them. Based on your requirements, you have the option to purchase the entire dataset or a customized subset.
The dataset is available in formats such as JSON, NDJSON, JSON Lines, CSV, or Parquet, and can also be optionally compressed into .gz files.
Is It Legal to Scrape Glassdoor?
Yes, it is legal to scrape data from Glassdoor, but it must be done ethically and in compliance with Glassdoor’s terms of service, robots.txt file, and privacy policies. One of the biggest myths is that scraping public data like company reviews and job listings is not legal. However, this is not true. It should be done within legal and ethical limits.
How to Scrape Glassdoor Data
Glassdoor uses JavaScript to render its content, which can make scraping more complex. To handle this, you need a tool that can execute JavaScript and interact with the webpage like a browser. Some popular choices are Playwright, Puppeteer, and Selenium. For this tutorial, we will use Playwright Python.
Let’s start building the Glassdoor scraper from scratch! Whether you’re new to Playwright or already familiar with it, this tutorial is here to help you build a web scraper using Playwright Python.
Setting Up Working Environment
Before you begin, make sure you have the following set up on your machine:
- official website
- Visual Studio Code
Next, open a terminal and create a new folder for your Python project, then navigate to it:
mkdir glassdoor-scraper
cd glassdoor-scraper
Create and activate a virtual environment:
python -m venv glassdoorenv
glassdoorenvScriptsactivate
Install Playwright:
pip install playwright
Then, install the browser binaries:
playwright install
This installation may take some time, so please be patient.
Here’s what the complete setup process looks like:
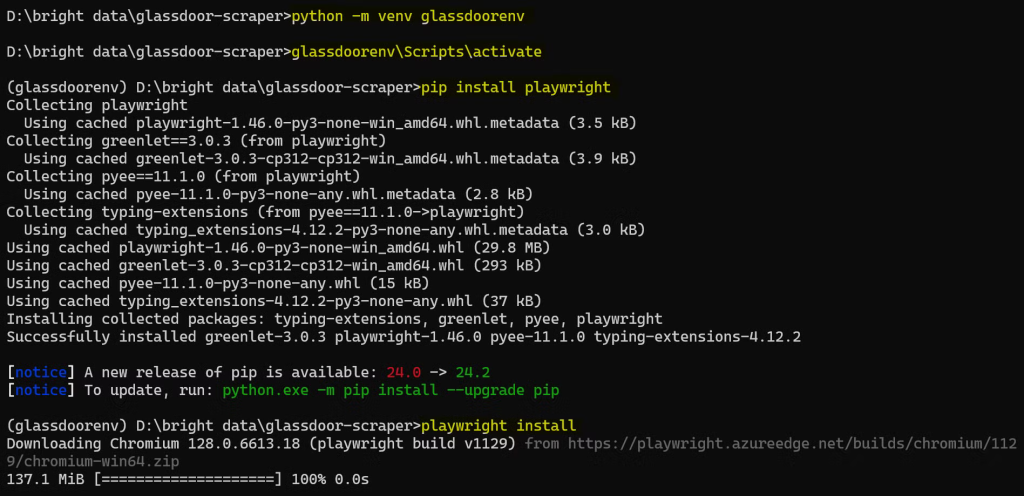
You’re now set up and ready to start writing your Glassdoor scraper code!
Understanding Glassdoor Website Structure
Before you start scraping Glassdoor, it’s important to understand its structure. For this tutorial, we’ll focus on scraping companies in a specific location that have particular roles.
For example, if you want to find companies in New York City with machine learning roles and an overall rating greater than 3.5, you’ll need to apply the appropriate filters to your search.
Take a look at the Glassdoor companies page:
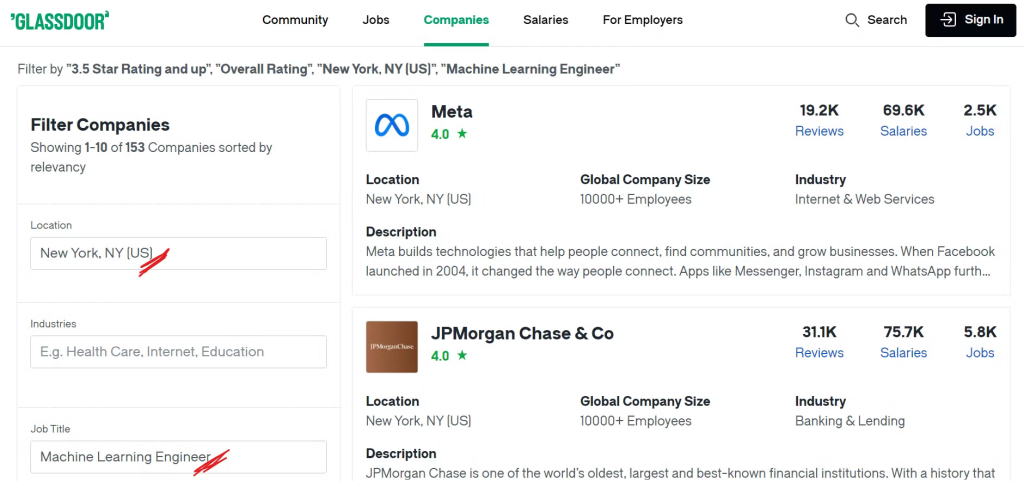
Now, you can see a lot of companies listed by applying our desired filters, and you might be wondering what specific data we’ll be scraping. Let’s see it next!
Identifying Key Data Points
To effectively collect the data from Glassdoor, you need to identify the content that you’re looking to scrape.
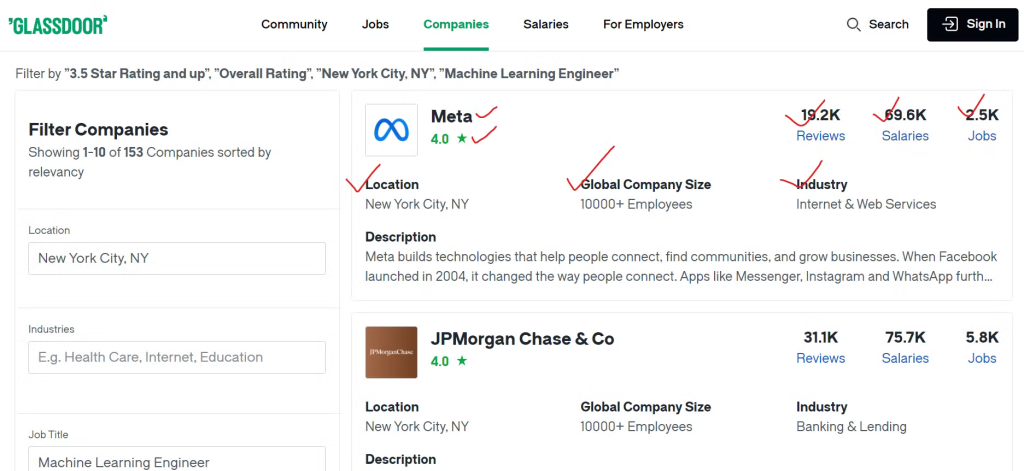
We will extract various details about each company, such as the company name, a link to its job listings, and the total number of job openings. Additionally, we’ll scrape the number of employee reviews, the count of reported salaries, and the industry in which the company operates. We will also extract the geographical location of the company and the total number of employees worldwide.
Building Glassdoor Scraper
Now that you’ve identified the data you want to scrape, it’s time to build the scraper using Playwright Python.
Start by inspecting the Glassdoor website to locate the elements for the company name and ratings, as shown in the image below:
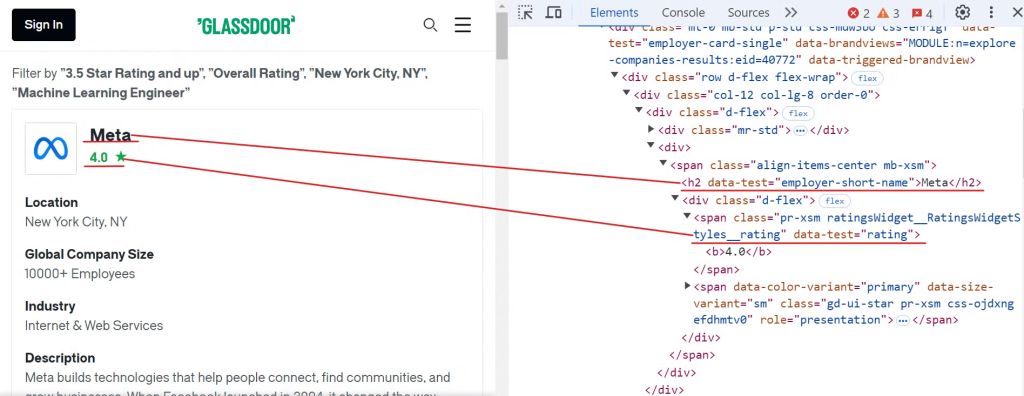
To extract this data, you can use the following CSS selectors:
[data-test="employer-short-name"]
[data-test="rating"]
Similarly, you can extract other relevant data by using simple CSS selectors as shown in the image below:
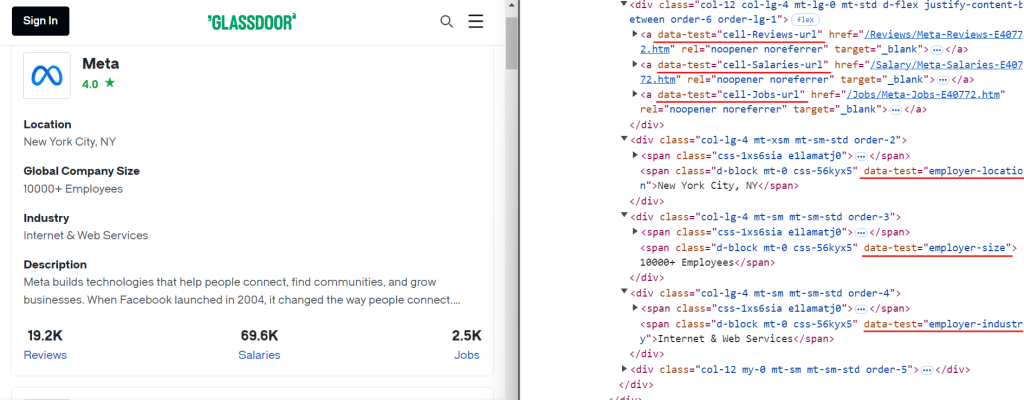
Here are the CSS selectors you can use for extracting additional data:
[data-test="employer-location"] /* Geographical location of the company */
[data-test="employer-size"] /* Number of employees worldwide */
[data-test="employer-industry"] /* Industry the company operates in */
[data-test="cell-Jobs-url"] /* Link to the company's job listings */
[data-test="cell-Jobs"] h3 /* Total number of job openings */
[data-test="cell-Reviews"] h3 /* Number of employee reviews */
[data-test="cell-Salaries"] h3 /* Count of reported salaries */
Next, create a new file named glassdoor.py and add the following code:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Launch a Chromium browser instance
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Define the base URL and query parameters for the Glassdoor search
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# Construct the full URL with query parameters and navigate to it
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Initialize a counter for the records extracted
record_count = 0
# Locate all company cards on the page and iterate through them to extract data
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extract relevant data from each company card
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# Construct the URL for job listings
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extract additional data about jobs, reviews, and salaries
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Print the extracted data
print({
"Company": company_name,
"Rating": rating,
"Jobs URL": jobs_url_path,
"Jobs Count": jobs_count,
"Reviews Count": reviews_count,
"Salaries Count": salaries_count,
"Industry": industry,
"Location": location,
"Global Company Size": global_company_size,
})
record_count += 1
except Exception as e:
print(f"Error extracting company data: {e}")
print(f"Total records extracted: {record_count}")
# Close the browser
await browser.close()
# Entry point for the script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
This code sets up a Playwright script to scrape company data by applying specific filters. For example, it applies filters such as location (New York, NY), rating (3.5+), and job title (Machine Learning Engineer).
It then launches a Chromium browser instance, navigates to the Glassdoor URL that includes these filters, and extracts data from each company card on the page. After collecting the data, it prints the extracted information to the console.
And, here’s the output:

Nice job!
There’s still an issue. Currently, the code extracts only 10 records, whereas there are approximately 150 records available on the page. This shows that the script only captures data from the first page. To extract more records, we need to implement pagination handling, which is covered in the next section.
Handling Pagination
Each page on Glassdoor displays data for approximately 10 companies. To extract all available records, you need to handle pagination by navigating through each page until you reach the end. To handle pagination, you’ve to locate the “Next” button, check if it is enabled, and click it to proceed to the next page. Repeat this process until no more pages are available.
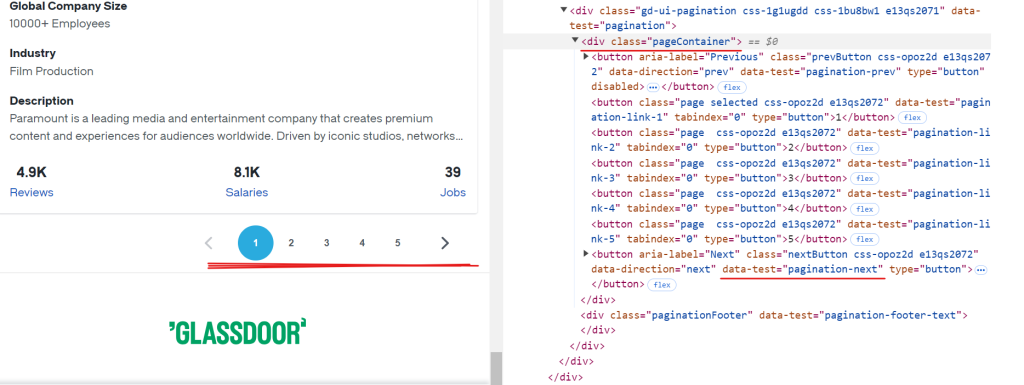
The CSS selector for the “Next” button is [data-test="pagination-next"], which is present within a <div> tag with the class pageContainer, as shown in the above image.
Here is a code snippet showing how to handle pagination:
while True:
# Ensure the pagination container is visible before proceeding
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identify the "next" button on the page
next_button = page.locator('[data-test="pagination-next"]')
# Determine if the "next" button is disabled, showing no further pages
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Stop if there are no more pages to navigate
# Navigate to the next page
await next_button.click()
await asyncio.sleep(3) # Allow time for the page to fully load
Here’s the modified code:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Launch a Chromium browser instance
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Define the base URL and query parameters for the Glassdoor search
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# Construct the full URL with query parameters and navigate to it
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Initialize a counter for the records extracted
record_count = 0
while True:
# Locate all company cards on the page and iterate through them to extract data
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extract relevant data from each company card
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# Construct the URL for job listings
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extract additional data about jobs, reviews, and salaries
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Print the extracted data
print({
"Company": company_name,
"Rating": rating,
"Jobs URL": jobs_url_path,
"Jobs Count": jobs_count,
"Reviews Count": reviews_count,
"Salaries Count": salaries_count,
"Industry": industry,
"Location": location,
"Global Company Size": global_company_size,
})
record_count += 1
except Exception as e:
print(f"Error extracting company data: {e}")
try:
# Ensure the pagination container is visible before proceeding
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identify the "next" button on the page
next_button = page.locator('[data-test="pagination-next"]')
# Determine if the "next" button is disabled, showing no further pages
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Stop if there are no more pages to navigate
# Navigate to the next page
await next_button.click()
await asyncio.sleep(3) # Allow time for the page to fully load
except Exception as e:
print(f"Error navigating to the next page: {e}")
break # Exit the loop on navigation error
print(f"Total records extracted: {record_count}")
# Close the browser
await browser.close()
# Entry point for the script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
The result is:

Great! You can now extract data from all available pages, not just the first one.
Save Data to CSV
Now that you’ve extracted the data, let’s save it in a CSV file for further processing. To do this, you can use the Python csv module. Below is the updated code that saves the scraped data to a CSV file:
import asyncio
import csv
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Launch a Chromium browser instance
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Define the base URL and query parameters for the Glassdoor search
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# Construct the full URL with query parameters and navigate to it
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Open CSV file to write the extracted data
with open("glassdoor_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow([
"Company", "Jobs URL", "Jobs Count", "Reviews Count", "Salaries Count",
"Industry", "Location", "Global Company Size", "Rating"
])
# Initialize a counter for the records extracted
record_count = 0
while True:
# Locate all company cards on the page and iterate through them to extract data
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extract relevant data from each company card
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# Construct the URL for job listings
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extract additional data about jobs, reviews, and salaries
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Write the extracted data to the CSV file
writer.writerow([
company_name, jobs_url_path, jobs_count, reviews_count, salaries_count,
industry, location, global_company_size, rating
])
record_count += 1
except Exception as e:
print(f"Error extracting company data: {e}")
try:
# Ensure the pagination container is visible before proceeding
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identify the "next" button on the page
next_button = page.locator('[data-test="pagination-next"]')
# Determine if the "next" button is disabled, showing no further pages
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Stop if there are no more pages to navigate
# Navigate to the next page
await next_button.click()
await asyncio.sleep(3) # Allow time for the page to fully load
except Exception as e:
print(f"Error navigating to the next page: {e}")
break # Exit the loop on navigation error
print(f"Total records extracted: {record_count}")
# Close the browser
await browser.close()
# Entry point for the script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
This code now saves the scraped data into a CSV file named glassdoor_data.csv.
The result is:
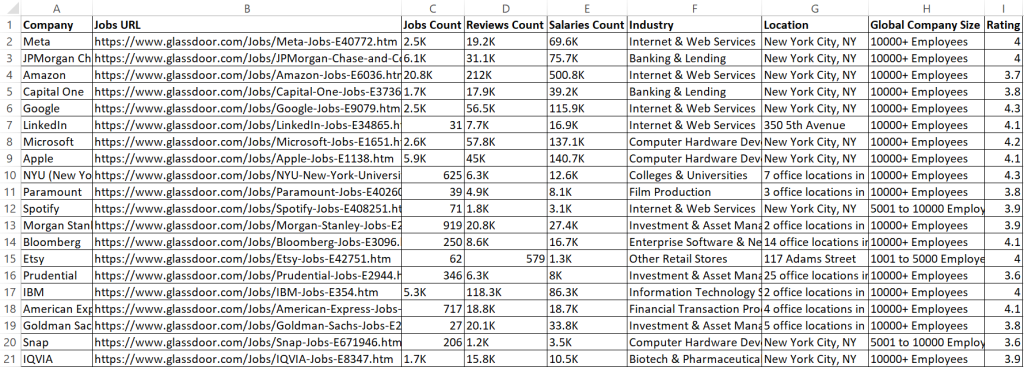
Awesome! Now, the data looks more clean and easy to read.
Anti-scraping Techniques Employed by Glassdoor
Glassdoor monitors the number of requests coming from an IP address within a certain period. If the requests exceed a set limit, Glassdoor may temporarily or permanently block the IP address. Additionally, if unusual activity is detected, Glassdoor might present a CAPTCHA challenge, as I experienced.
The method discussed above is suitable for scraping a few hundred companies. However, if you need to scrape thousands, there is a higher risk that Glassdoor’s anti-bot mechanisms may flag your automated scraping script, as I encountered when scraping larger volumes of data.
Scraping data from Glassdoor can be difficult because of its anti-scraping mechanisms. Bypassing these anti-bot mechanisms can be frustrating and resource-intensive. However, there are strategies to help your scraper mimic human behaviour and reduce the likelihood of being blocked. Some common techniques include rotating proxies, setting real request headers, randomizing request rates, and more. While these techniques can improve your chances of successful scraping, they do not guarantee 100% success.
So, the best approach to scrape Glassdoor, despite its anti-bot measures, is to use a Glassdoor Scraper API 🚀
A Better Alternative: Glassdoor Scraper API
Bright Data offers a Glassdoor dataset that comes pre-collected and structured for analysis, as discussed earlier in the blog. If you don’t want to purchase a dataset and looking for a more efficient solution, consider using Bright Data’s Glassdoor Scraper API.
This powerful API is designed to scrape Glassdoor data seamlessly, handling dynamic content and bypassing anti-bot measures with ease. With this tool, you can save time, ensure data accuracy, and focus on extracting actionable insights from the data.
To get started with the Glassdoor Scraper API, follow these steps:
First, create an account. Visit the Bright Data website, click on Start Free Trial, and follow the sign-up instructions. Once logged in, you’ll be redirected to your dashboard, where you will get some free credits.
Now, go to the Web Scraper API section and select Glassdoor under the B2B data category. You’ll find various data collection options, such as collecting companies by URL or collecting job listings by URL.
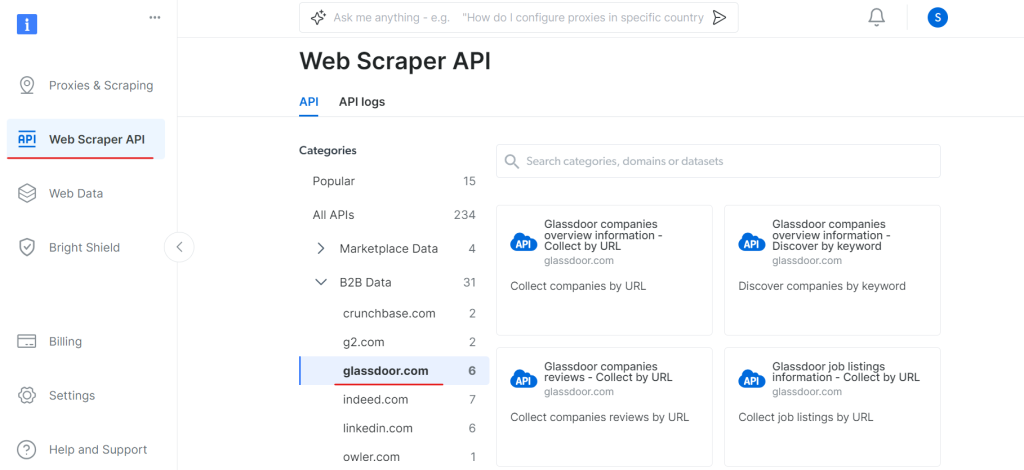
Under “Glassdoor companies overview information”, get your API token and copy your dataset ID (e.g., gd_l7j0bx501ockwldaqf).
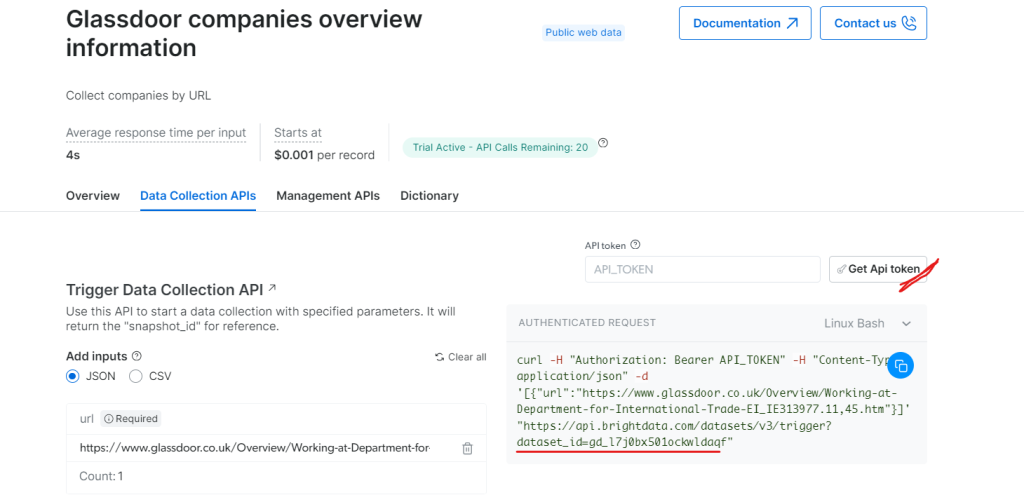
Now, here is the simple code snippet that shows how to extract company data by providing the URL, API token, and dataset ID.
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
Triggers a dataset using the BrightData API.
Args:
api_token (str): The API token for authentication.
dataset_id (str): The dataset ID to trigger.
company_url (str): The URL of the company page to analyze.
Returns:
dict: The JSON response from the API.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "COMPANY_PAGE_URL"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)
Upon running the code, you will receive a snapshot ID as shown below:

Use the snapshot ID to retrieve the actual data of the company. Run the following command in your terminal. For Windows, use:
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/datasets/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
For Linux:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/datasets/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
After running the command, you’ll get the desired data.
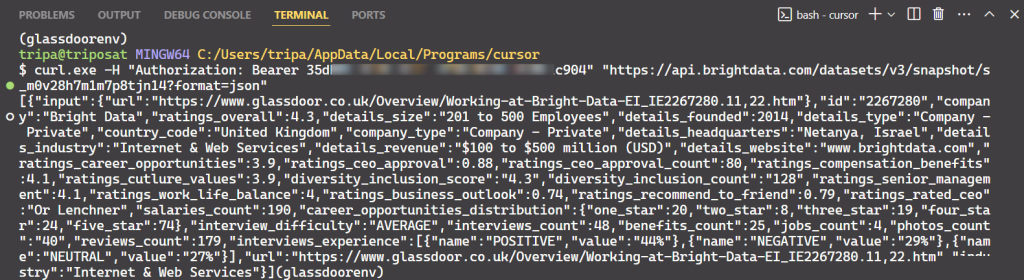
That’s all it takes!
Similarly, you can extract various types of data from Glassdoor by modifying the code. I’ve explained one method, but there are five other ways to do it. So, I recommend exploring these options to scrape the data you want. Each method is tailored to specific data needs and helps you get the exact data you need.
Conclusion
In this tutorial, you learned how to scrape Glassdoor using Playwright Python. You also learned about the anti-scraping techniques employed by Glassdoor and how to bypass them. To address these issues, the Bright Data Glassdoor Scraper API was introduced, which helps you overcome Glassdoor’s anti-scraping measures and extract the data you need seamlessly.
You can also try Scraping Browser, which is a next-generation browser that can be integrated with any other browser automation tool. Scraping Browser can easily bypass anti-bot technologies while avoiding browser fingerprinting. It relies on features like user-agent rotation, IP rotation, and CAPTCHA solving.
Sign up now and experiment with Bright Data’s products for free.

Technical Writer
Satyam Tripathi helps SaaS and data startups turn complex tech into actionable content, boosting developer adoption and user understanding.





