

Airbnb is one of the most requested data sources in travel and real estate, and one of the hardest to collect: the pages sit behind an anti-bot layer and change often, and in 2026 that data increasingly feeds dynamic-pricing models and AI agents that need it fresh and structured. This guide shows four ways to get it, from a plain Python request to a fully managed dataset, with real, tested code and live output for each.
What this guide covers
- The four ways to pull Airbnb data in 2026, and when to use each
- A manual Python scraper, and exactly where it breaks
- Web Unlocker for custom pages, with parsing code you control
- The Airbnb Scraper API for clean, structured JSON at any volume
- The ready-made Airbnb dataset for bulk and historical data
- Feeding Airbnb data to an AI agent over the Web MCP
Ready to skip the build? Pull live listings now with the Airbnb Scraper API, download a ready-made Airbnb dataset, or start free with 5,000 records a month and no credit card.
What Airbnb data is worth collecting
A single Airbnb listing exposes far more than a nightly price. The fields that matter for most projects are:
- Pricing: nightly rate, total before taxes, discounts, and cleaning fees
- Availability: the booking calendar and minimum-night requirements
- Reviews and ratings: overall score, review count, and category breakdowns
- Host signals: superhost status, response rate, and history
- Property details: capacity, amenities, coordinates, and images
Each of these maps to a specific element on the live listing page. The red boxes below show where the structured fields come from:
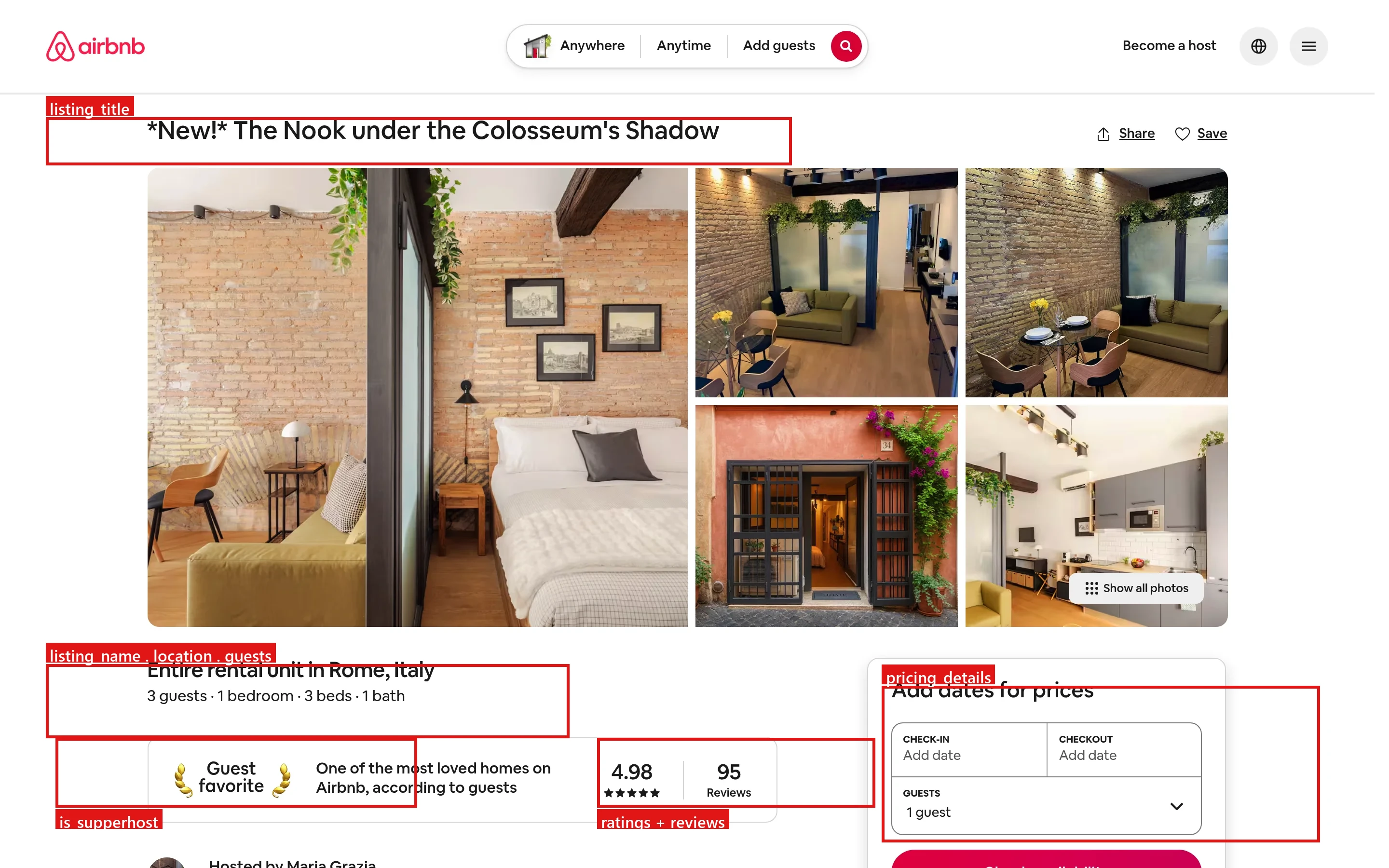
Common use cases: short-term-rental investment screening, dynamic pricing against local competition, occupancy and market-trend analysis, and supplying clean location data to AI and analytics pipelines.
The four approaches at a glance
| Approach | Effort | Scale | Maintenance | Best for |
|---|---|---|---|---|
| Manual Python | High | Low | High | Learning, tiny one-off pulls |
| Web Unlocker | Medium | Medium | Medium | Custom parsing, pages with no pre-built scraper |
| Airbnb Scraper API | Low | High | None | Structured listing data at any volume |
| Airbnb Dataset | None | Bulk | None | Historical or market-wide data, no code |
The honest summary: manual scraping is the cheapest way to learn and the most expensive way to operate. The other three move the hard parts, unblocking, parsing, and maintenance, onto managed infrastructure.
Approach 1: Manual scraping, and where it breaks
Start with the obvious: fetch the search page with requests and parse it. Here is the whole attempt.
import requests
url = "https://www.airbnb.com/s/Rome, Italy/homes"
resp = requests.get(url, headers={"User-Agent": "Mozilla/5.0"}, timeout=30)
print("status:", resp.status_code)
print("DataDome anti-bot active:", "datadome" in resp.text.lower())Running it shows what you are actually up against:
status: 200
DataDome anti-bot active: TrueThe request returns 200, but every response is wrapped in DataDome’s bot-detection layer. On some attempts you get a challenge page with no listings, and on others a single request slips through. That inconsistency is the real problem: as soon as you add pagination, more cities, or any real request volume, DataDome flags the traffic and you hit CAPTCHAs, rate limits, and IP bans. Making it dependable means rotating residential proxies, a real browser fingerprint, automated CAPTCHA solving, and a parser that survives Airbnb’s frequent markup changes. That is a maintenance project, not a script. If you do want the DIY route, our Python web scraping guide covers the fundamentals. The next three approaches remove that burden.
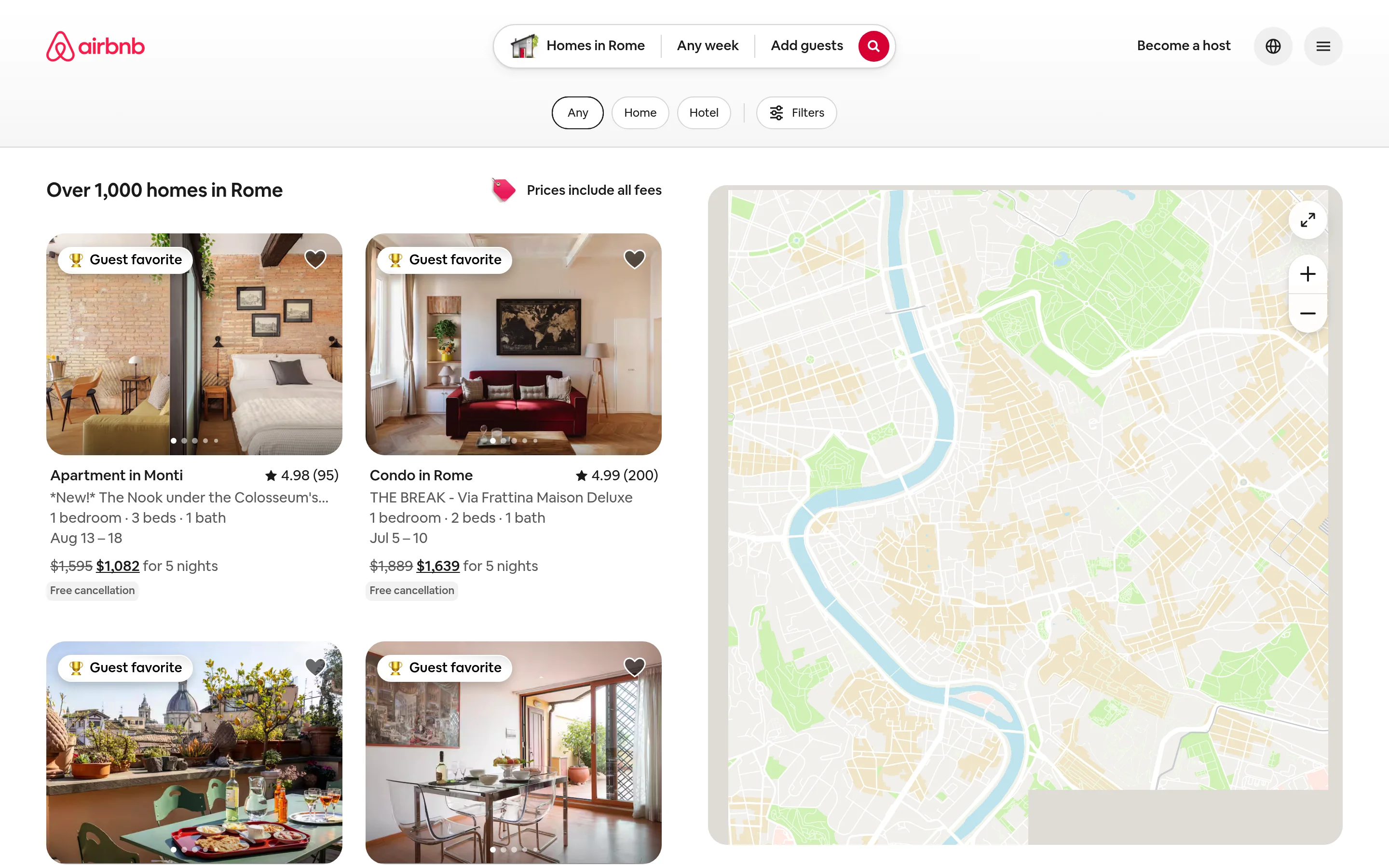
Approach 2: Web Unlocker for custom pages
When you need the raw page (for example, a page type that has no pre-built scraper), Web Unlocker handles the unblocking and hands back the fully rendered HTML. You still parse the data yourself, which is the right tradeoff when you want full control over extraction.
Airbnb embeds its listing data as JSON inside the page, so once you have the HTML you can pull fields directly without fragile CSS selectors.
import os
import re
import requests
API = "https://api.brightdata.com/request"
payload = {
"zone": os.environ["BRIGHTDATA_UNLOCKER_ZONE"],
"url": "https://www.airbnb.com/s/Rome, Italy/homes",
"format": "raw",
"country": "us", # geo-target for consistent currency and language
}
headers = {"Authorization": f"Bearer {os.environ['BRIGHTDATA_API_KEY']}"}
html = requests.post(API, json=payload, headers=headers, timeout=120).text
names = re.findall(r'"localizedStringWithTranslationPreference":"([^"]+)"', html)
prices = re.findall(r'"accessibilityLabel":"([^"]*?\$[\d,]+[^"]*?)"', html)
print(len(set(names)), "listings parsed")
for name, price in list(zip(names[::2], prices))[:4]:
print("-", name, "|", price)This returns real, parsed listings:
30 listings parsed
- *New!* The Nook under the Colosseum's Shadow | $1,082 for 5 nights, originally $1,595
- THE BREAK - Via Frattina Maison Deluxe | $1,639 for 5 nights, originally $1,889
- The Unique Home Pantheon | $1,064 for 5 nights, originally $1,481
- 360 penthouse overlooking central Rome | $3,010 for 5 nightsWeb Unlocker gets you past the wall, and you keep complete control of parsing. The cost is that you still own the extraction logic and have to update it when Airbnb changes its page structure. If all you want is clean listing data, the Scraper API removes that step entirely.
Approach 3: The Airbnb Scraper API
The Airbnb Scraper API is a pre-built scraper. You send listing or search URLs and receive structured JSON. No proxies, no parsing, no markup maintenance. It is part of Bright Data’s Web Scraper API, which covers 700+ sites.
The example below collects this exact listing, the one you can see live on Airbnb.
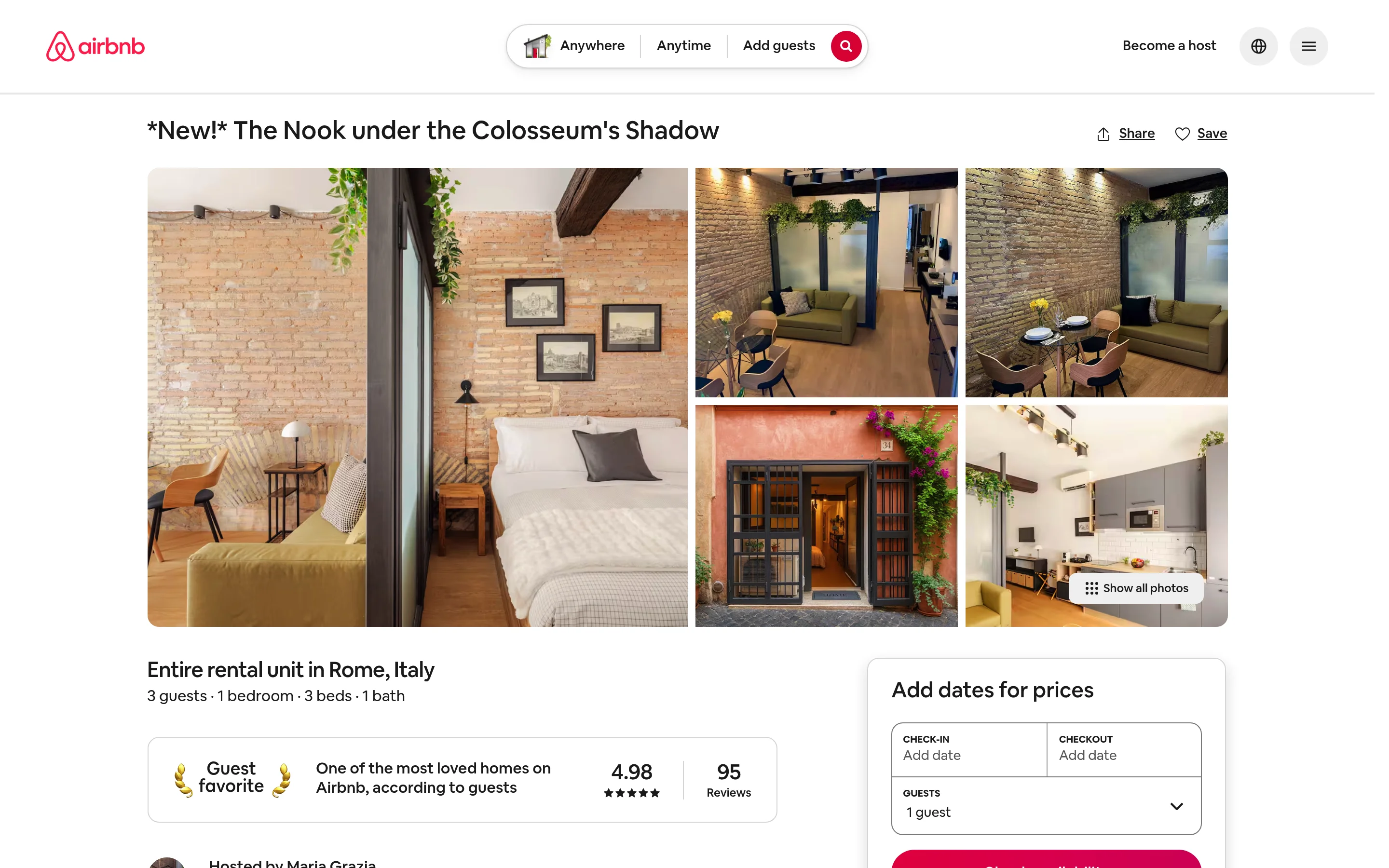
For up to 20 URLs, use the synchronous endpoint and get results back in one call.
import os
import requests
DATASET_ID = "gd_ld7ll037kqy322v05" # Airbnb Properties Information
TOKEN = os.environ["BRIGHTDATA_API_KEY"]
resp = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": DATASET_ID, "format": "json"},
headers={"Authorization": f"Bearer {TOKEN}", "Content-Type": "application/json"},
json={"input": [{"url": "https://www.airbnb.com/rooms/1409274854260723534"}]},
timeout=180,
)
listing = resp.json()[0]
for field in ("listing_title", "ratings", "property_number_of_reviews",
"is_supperhost", "guests", "location", "lat", "long"):
print(f"{field}: {listing[field]}")
print("amenities:", len(listing["amenities"]), "| images:", len(listing["images"]),
"| available_dates:", len(listing["available_dates"]))The response is a single clean record with 51 fields. Real output for that listing:
listing_title: *New!* The Nook under the Colosseum's Shadow
ratings: 4.98
property_number_of_reviews: 95
is_supperhost: True
guests: 3
location: Rome, Lazio, Italy
lat: 41.8949
long: 12.4895
amenities: 12 | images: 66 | available_dates: 185No parsing logic, no proxy management, and the schema stays stable even when Airbnb changes its HTML. That is the difference between scraping a page and consuming a maintained data product.
For larger jobs, switch to the asynchronous endpoint. You trigger a collection, poll for completion, then download. This scales to thousands of URLs in one job.
import os
import time
import requests
DATASET_ID = "gd_ld7ll037kqy322v05"
TOKEN = os.environ["BRIGHTDATA_API_KEY"]
HEADERS = {"Authorization": f"Bearer {TOKEN}", "Content-Type": "application/json"}
# 1. Trigger
urls = [
"https://www.airbnb.com/rooms/1409274854260723534",
"https://www.airbnb.com/rooms/667303913003951222",
# ... hundreds more
]
trigger = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
params={"dataset_id": DATASET_ID, "format": "json"},
headers=HEADERS,
json={"input": [{"url": u} for u in urls]},
)
snapshot_id = trigger.json()["snapshot_id"]
# 2. Poll until ready
while True:
status = requests.get(
f"https://api.brightdata.com/datasets/v3/progress/{snapshot_id}",
headers=HEADERS,
).json()["status"]
if status == "ready":
break
if status == "failed":
raise RuntimeError("collection failed")
time.sleep(10)
# 3. Download
data = requests.get(
f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}",
params={"format": "json"},
headers=HEADERS,
).json()
print(len(data), "listings collected")You only pay for delivered records, the Web Scraper API starts from $0.70 per 1,000 records, and every new account gets 5,000 free records per month to test with, no credit card required. There is also a no-code version in the control panel if you would rather not write any of this.
Approach 4: The ready-made Airbnb dataset
If you need history or market-wide coverage rather than a specific list of URLs, skip collection entirely and buy the Airbnb dataset. It is the same structured schema, pre-collected and refreshed.
The marketplace dataset carries 6.5M+ records across 51 fields, priced from $0.0025 per record with a $250 minimum order, as a one-time download or a refreshing subscription. You filter by location, date, or other attributes and download in JSON, CSV, or Parquet. This is the buy-versus-build option: zero engineering, instant access, and a good fit for backtesting pricing models or analyzing a whole city at once. Bright Data publishes the same ready-to-use data for other marketplaces too, including the best Amazon data providers and best ecommerce data providers.
Bonus: feed Airbnb data straight to an AI agent (MCP)
The biggest shift of 2026 is that the consumer of this data is often an AI agent, not a dashboard. Agents need live web data on demand, and the Model Context Protocol (MCP) is how they call external tools. Bright Data’s Web MCP server gives any LLM, whether Claude, GPT, or Gemini, live search (SERP API) and scraping through the same unblocking infrastructure, so the agent never hits the DataDome wall from Approach 1.
Point your MCP client at the hosted server with one line, no install required:
https://mcp.brightdata.com/mcp?token=YOUR_API_TOKENOr run it locally with npx:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": { "API_TOKEN": "your-token-here" }
}
}
}Even faster, the Bright Data CLI wires the MCP into your agent with one command:
brightdata add mcp, agent claude-code,cursor,codexThe free Rapid mode exposes search_engine, scrape_as_markdown, and discover at one credit per request, drawing from the same 5,000 free monthly credits. An agent can then answer a prompt like “find available Airbnb listings in Rome under $200 a night and summarize the five cheapest” by searching and scraping live, with no scraping code in your application. Pro mode adds 60+ structured tools, including pre-built web data extractors and Scraping Browser automation, for production agents. For a full walkthrough, see the Web MCP scraping tutorial.
Before wiring it into an agent, you can try the exact same tools from your terminal with the Bright Data CLI, which draws from the same free credits. A quick search and scrape against Airbnb:
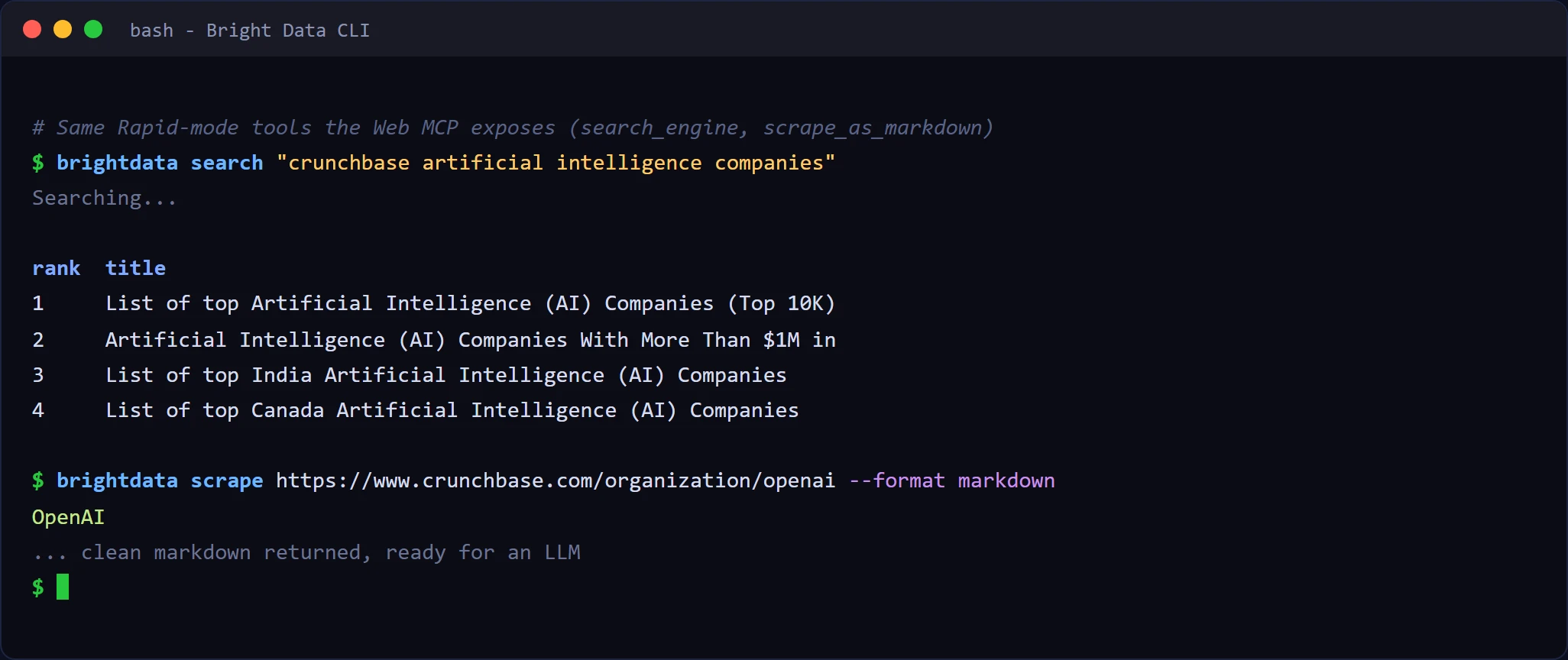
The CLI’s search and scrape map one to one to the MCP’s search_engine and scrape_as_markdown tools, so what returns in your terminal is exactly what the agent receives once it is connected.
See it work inside the agent
Once connected, you ask in plain language and the agent decides which MCP tools to call. Prompts that work out of the box:
- “Find apartments for rent on Airbnb in Rome and recommend a few with ratings.”
- “Pull the key details for airbnb.com/rooms/ID: rating, superhost status, capacity.”
- “Compare nightly prices for two-bedroom Airbnbs in Rome versus Florence.”
- “Summarize the review sentiment for this listing in three bullet points.”
Here is the first prompt running in Claude Code. The agent calls search_engine and scrape_as_markdown on its own, then answers with live data and no scraping code in the project.
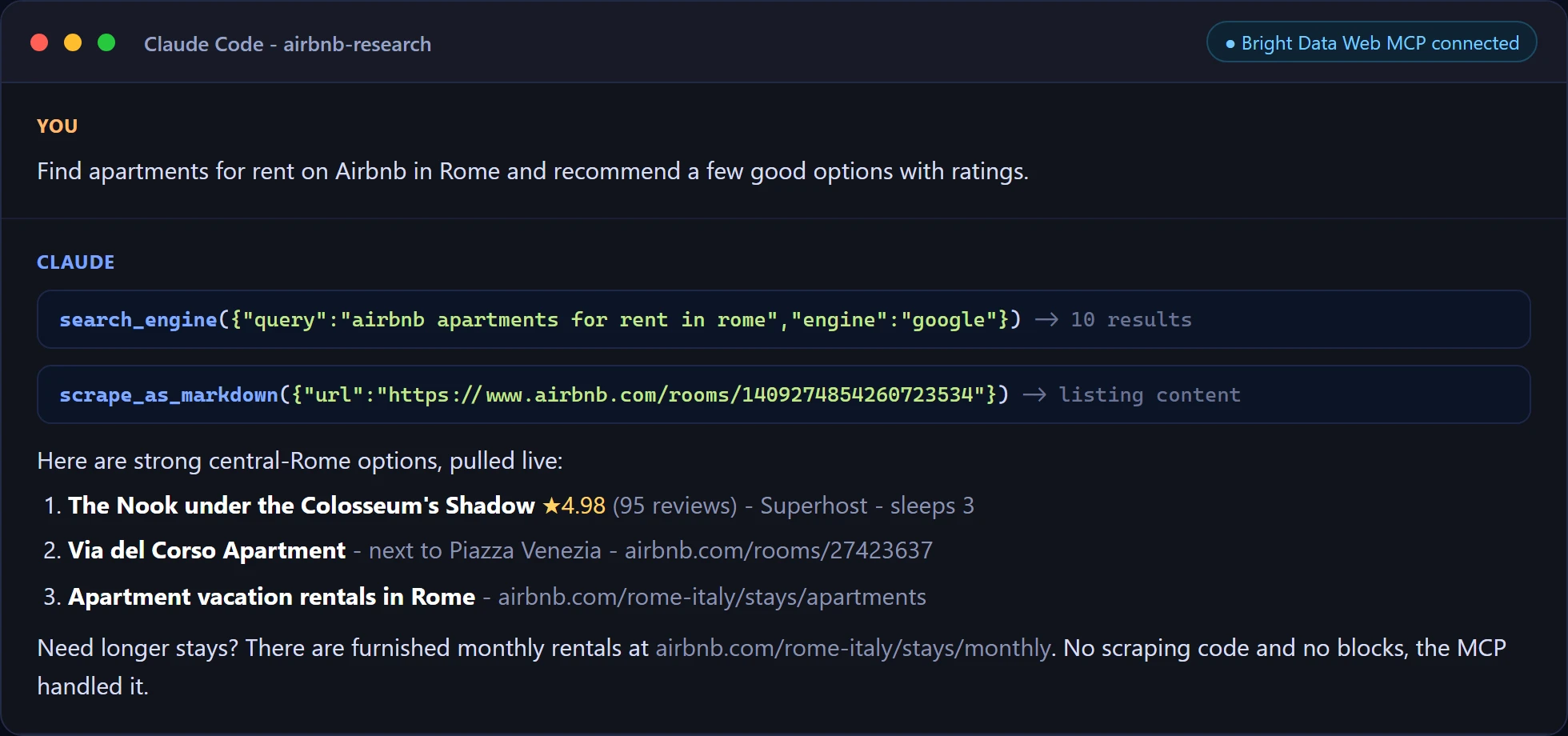
And a targeted extraction in Cursor, pulling one listing’s fields straight from the live page.
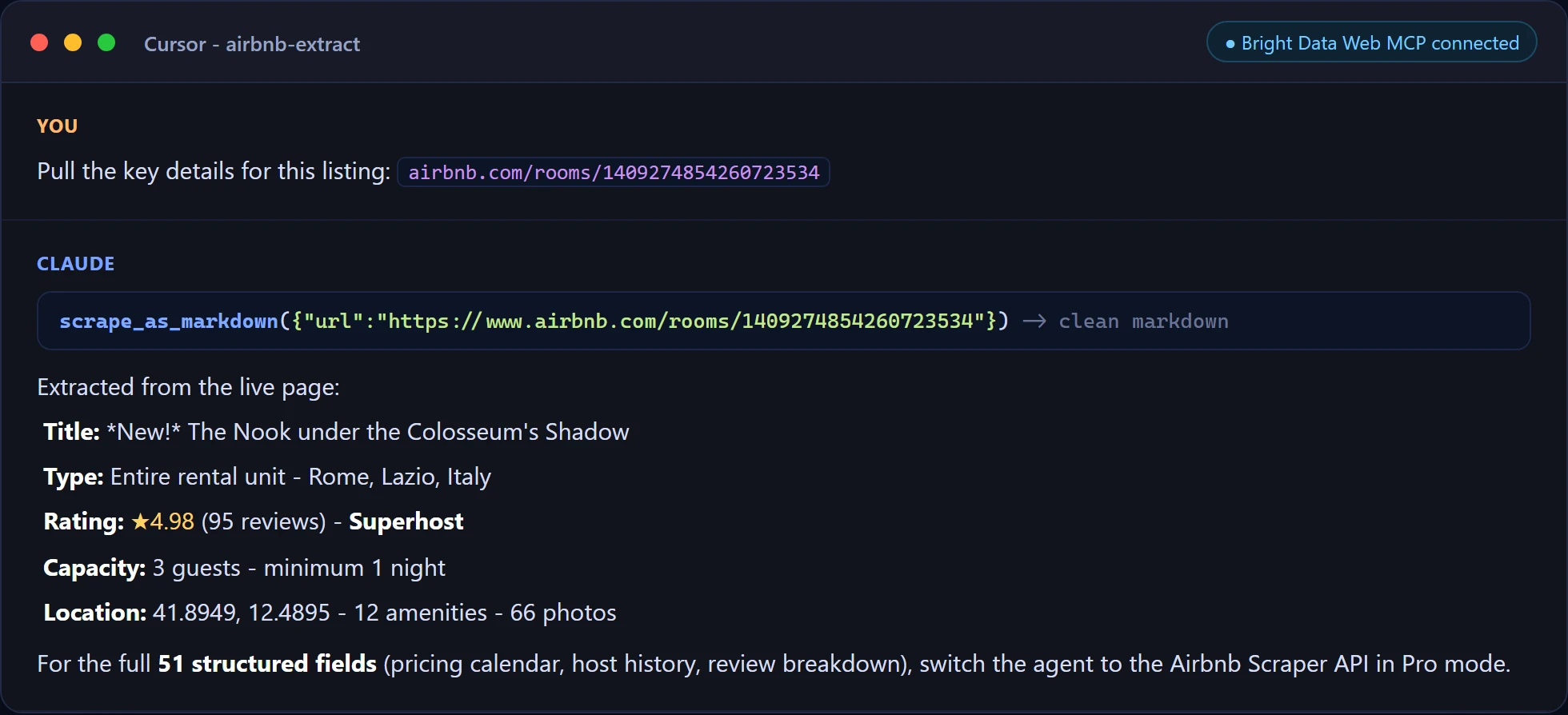
For production agents that need every field, enable Pro mode and the agent gains 60+ structured web data tools to call alongside the Airbnb Scraper API from Approach 3.
Turn the data into insight
Once you have listings, analysis is quick. Using the prices parsed in Approach 2, a short snippet summarizes the local market.
import statistics
prices = [1082, 1639, 1064, 3010, 904, 1115, 2008, 1398] # USD, 5-night totals
print("listings:", len(prices))
print("median:", statistics.median(prices))
print("range:", min(prices), "to", max(prices))Plotting the full sample shows the spread across central Rome at a glance.
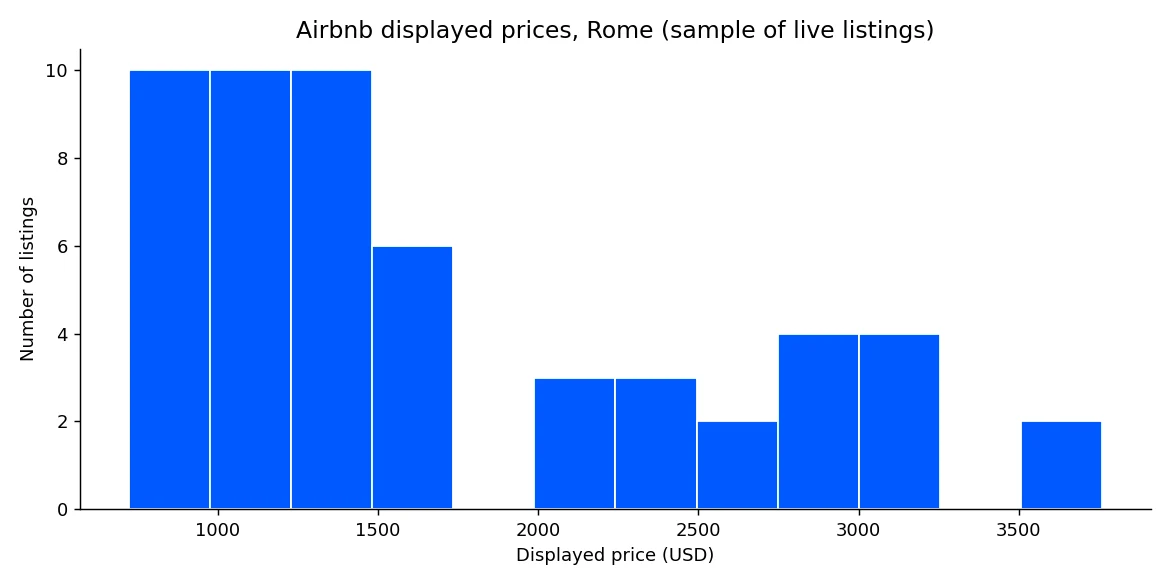
That distribution is the foundation for competitive pricing, outlier detection, and occupancy modeling.
How to choose
- Just exploring or learning? Manual scraping teaches you how the page is built. Do not run it in production.
- Need a page with no pre-built scraper, and want to own parsing? Use Web Unlocker.
- Need clean, structured listing data at any volume? Use the Airbnb Scraper API. This is the default for most projects.
- Need historical or market-wide data with no code? Use the Airbnb dataset.
For head-to-head comparisons of dedicated tools, see our roundups of the best Airbnb scrapers and the best Airbnb data providers.
The pattern that holds across all of them: let managed infrastructure handle unblocking and structure so your team spends its time on analysis, not on babysitting scrapers. Bright Data’s network is built for exactly this, with GDPR and CCPA aligned, ISO 27001 certified, ethically sourced infrastructure behind every request.
Conclusion
Scraping Airbnb in 2026 is less about clever parsing and more about choosing the right level of abstraction. Manual code is fine for learning but breaks under Airbnb’s anti-bot layer. Web Unlocker gives you the page when you need custom control. The Airbnb Scraper API gives you structured records with zero maintenance. The dataset gives you the whole market with zero code. Start with the 5k requests on the Scraper API, point it at the listings you care about, and build from there.
Frequently Asked Questions
Can I scrape Airbnb with plain Python requests?
Not reliably. Airbnb fronts its pages with DataDome bot detection. A default request often returns a challenge page, and even when one slips through, it breaks at scale with CAPTCHAs, rate limits, and IP bans. You need managed unblocking, a real browser fingerprint, and proxies, which is why most teams use Web Unlocker or the Airbnb Scraper API.
What data can the Airbnb Scraper API return?
A single record includes 51 fields: listing title and type, nightly and total pricing, availability calendar, ratings and review counts, host and superhost signals, amenities, coordinates, images, and more. You receive it as clean JSON with no parsing required.
Should I use the Scraper API or the ready-made dataset?
Use the Scraper API when you have specific listing or search URLs and want fresh data on demand. Use the dataset when you need historical or market-wide coverage without supplying URLs. The dataset carries 6.5M+ records and starts at $0.0025 per record.
How much does it cost to start?
Every new Bright Data account includes 5,000 free records per month across the Web Scraper API, Web Unlocker, and SERP API, with no credit card required. Beyond that, the Web Scraper API starts from $0.70 per 1,000 records and you only pay for delivered data.
Can an AI agent collect Airbnb data through MCP?
Yes. Bright Data’s Web MCP server connects any MCP-compatible LLM (Claude, GPT, Gemini) to live web data. In the free Rapid mode the agent gets search_engine and scrape_as_markdown at one credit per request, so it can pull current Airbnb listings on demand without any scraping code in your app. Pro mode adds 60+ structured data tools for production agents.
How do I handle large Airbnb scraping jobs?
Use the asynchronous endpoint: trigger a collection with your list of URLs, poll the progress endpoint until the snapshot is ready, then download in JSON, CSV, or NDJSON. A single job handles thousands of URLs, and snapshots are available for 30 days.

Web Data & AI Expert
Daniel Shashko is a Senior SEO/GEO at Bright Data, specializing in B2B marketing, international SEO, and building AI-powered agents, apps, and web tools.




