

In this article, you will discover:
- Which products Bright Data provides on Databricks.
- How to set up a Databricks account and retrieve all the required credentials for programmatic data retrieval and exploration.
- How to query a Bright Data dataset using Databricks’s:
- REST API
- CLI
- SQL Connector
Let’s dive in!
Bright Data’s Data Products on Databricks
Databricks is an open analytics platform for building, deploying, sharing, and maintaining enterprise-grade data, analytics, and AI solutions at scale. On the website, you can find data products from multiple providers, which is why it is considered one of the best data marketplaces.
Bright Data has recently joined Databricks as a data products provider, already offering over 40 products:
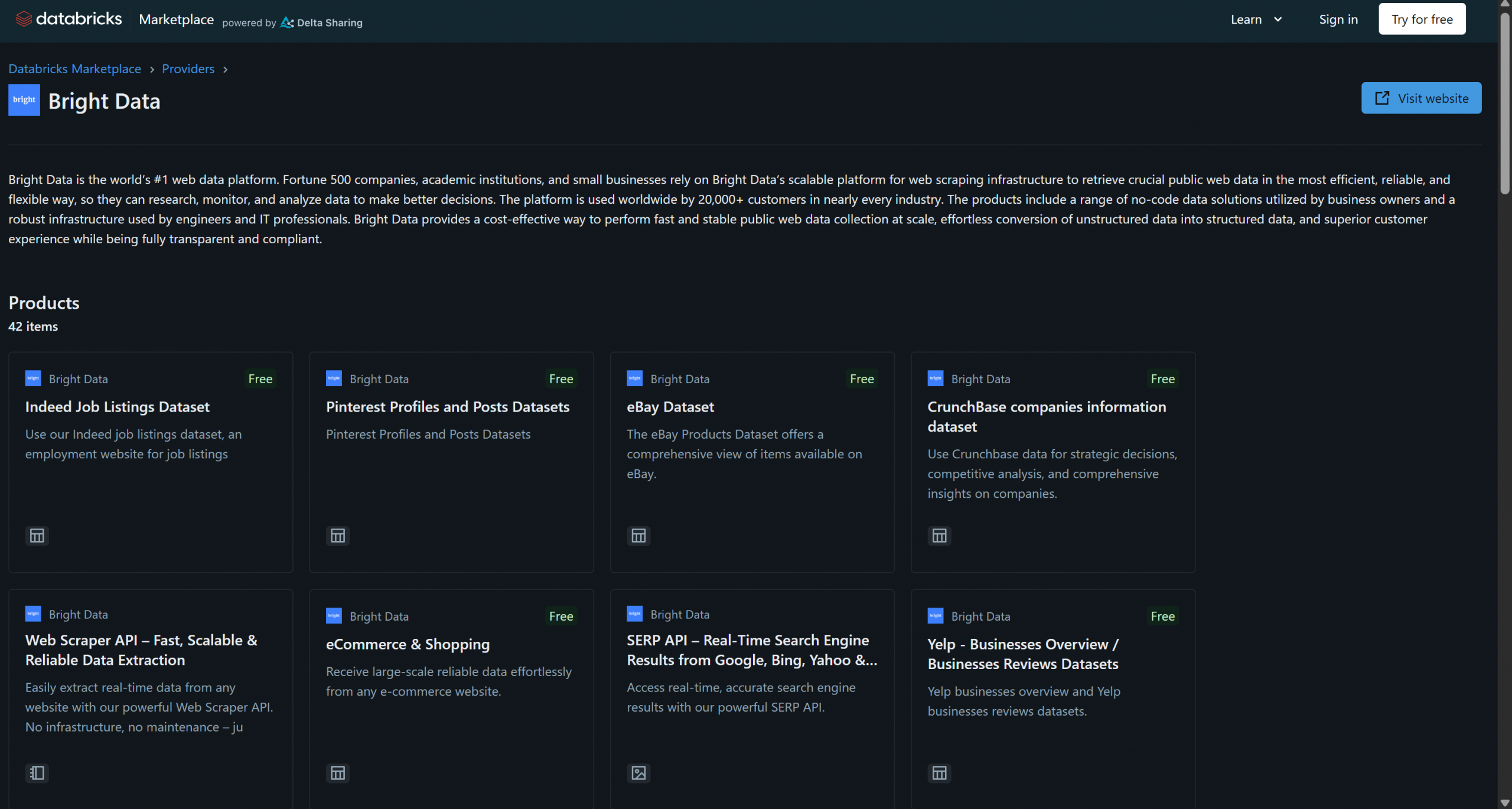
These solutions include B2B datasets, company datasets, financial datasets, real estate datasets, and many others. On top of that, you also have access to more general web data retrieval and web scraping solutions through Bright Data’s infrastructure, such as Scraping Browser and the Web Scraper API.
In this tutorial, you will learn how to programmatically query data from one of these Bright Data datasets using the Databricks API, CLI, and dedicated SQL Connector library. Let’s jump into it!
Getting Started with Databricks
To query Bright Data datasets from Databricks via API or CLI, you first need to set up a few things. Follow the steps below to configure your Databricks account and retrieve all the required credentials for Bright Data dataset access and integration.
At the end of this section, you will have:
- A configured Databricks account
- A Databricks access token
- A Databricks warehouse ID
- A Databricks host string
- Access to one or more Bright Data datasets in your Databricks account
Prerequisites
First, make sure you have a Databricks account (a free account is enough). If you do not have one, create an account. Otherwise, simply log in.
Configure Your Databricks Access Token
To authorize access to Databricks resources, you need an access token. Follow the instructions below to set one up.
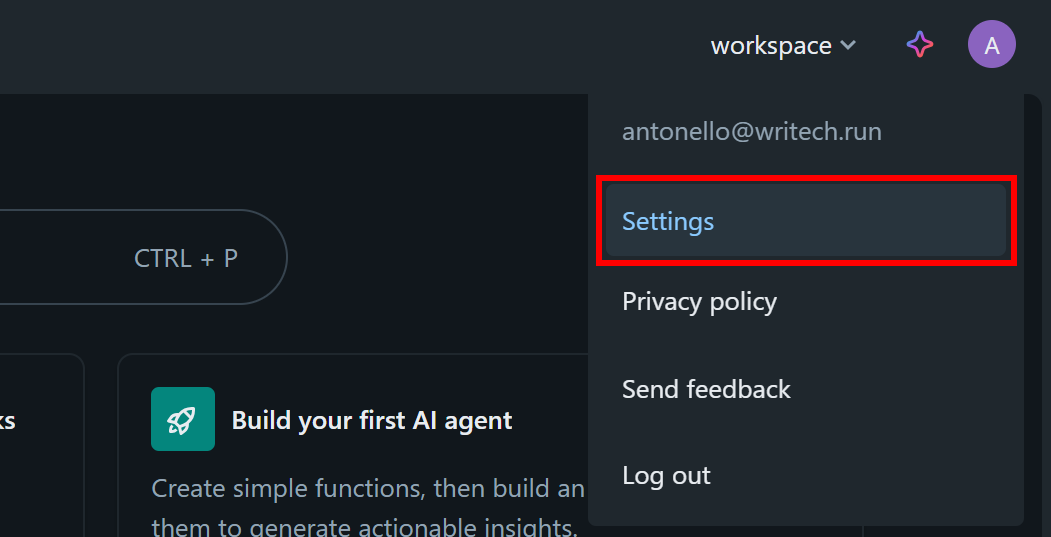
In your Databricks dashboard, click your profile image and select the “Settings” option:
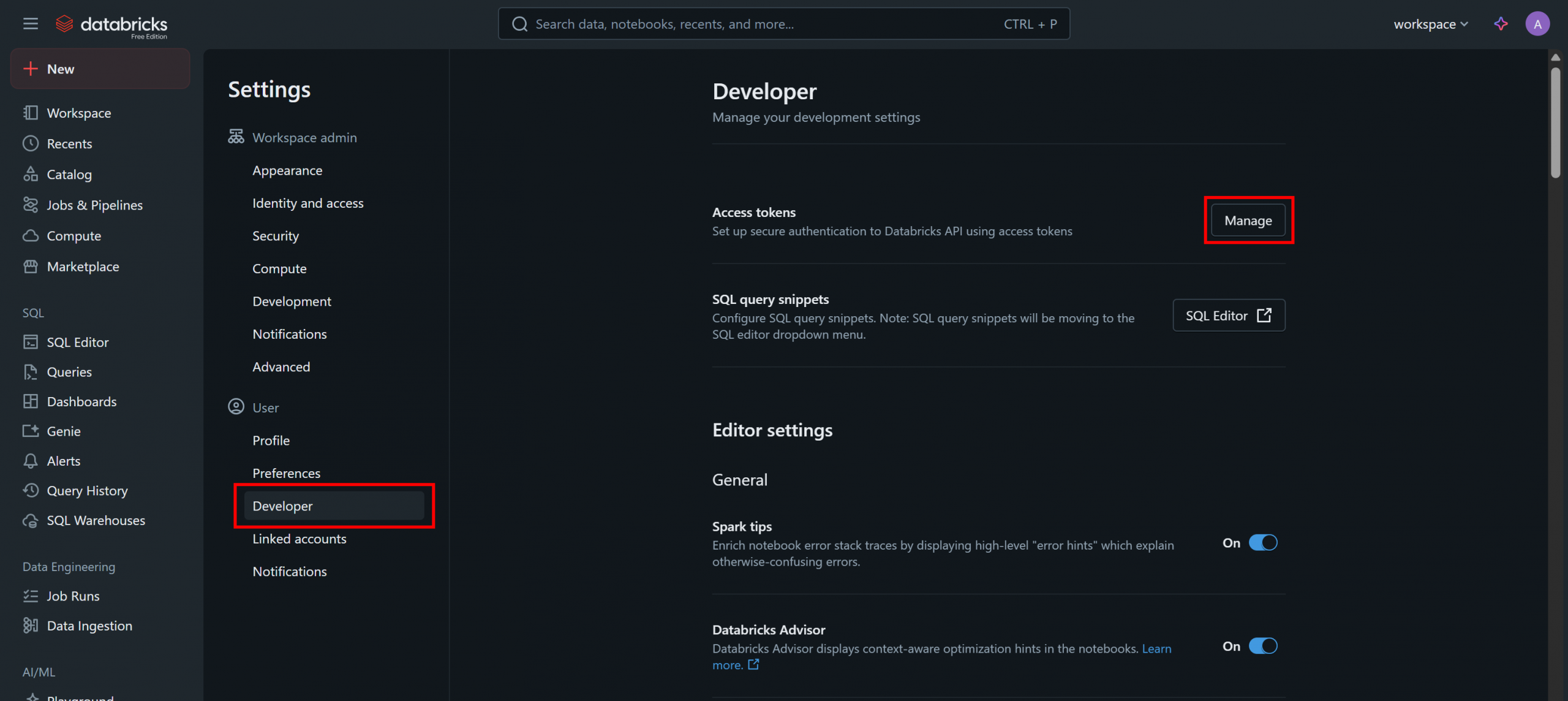
On the “Settings” page, select the “Developer” option, then click the “Manage” button in the “Access tokens” section:
On the “Access tokens” page, click “Generate New Token” and follow the instructions in the modal:
You will receive a Databricks API access token. Store it in a safe place, as you will need it soon.
Retrieve Your Databricks Warehouse ID
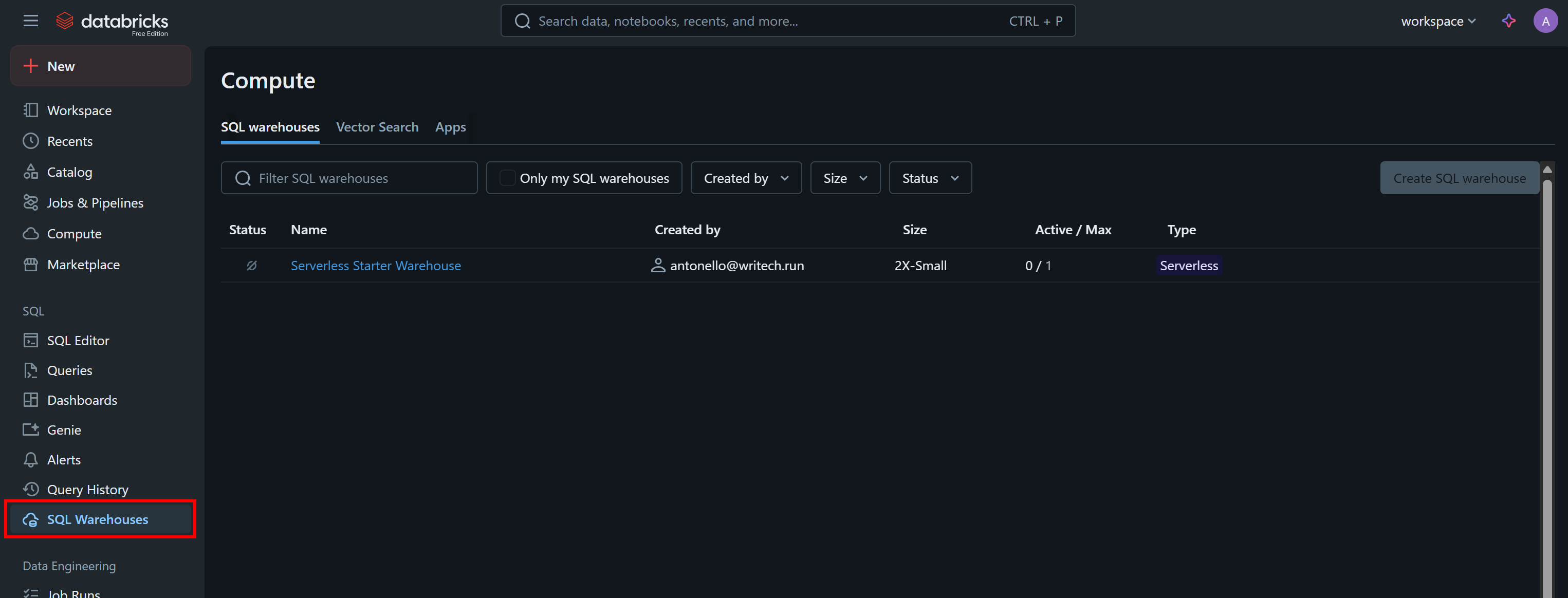
Another piece of information you need to programmatically call the API or query the datasets via CLI is your Databricks warehouse ID. To retrieve it, select the “SQL Warehouses” option in the menu:
Click the available warehouse (in this example, “Serverless Starter Warehouse”) and reach the “Overview” tab:
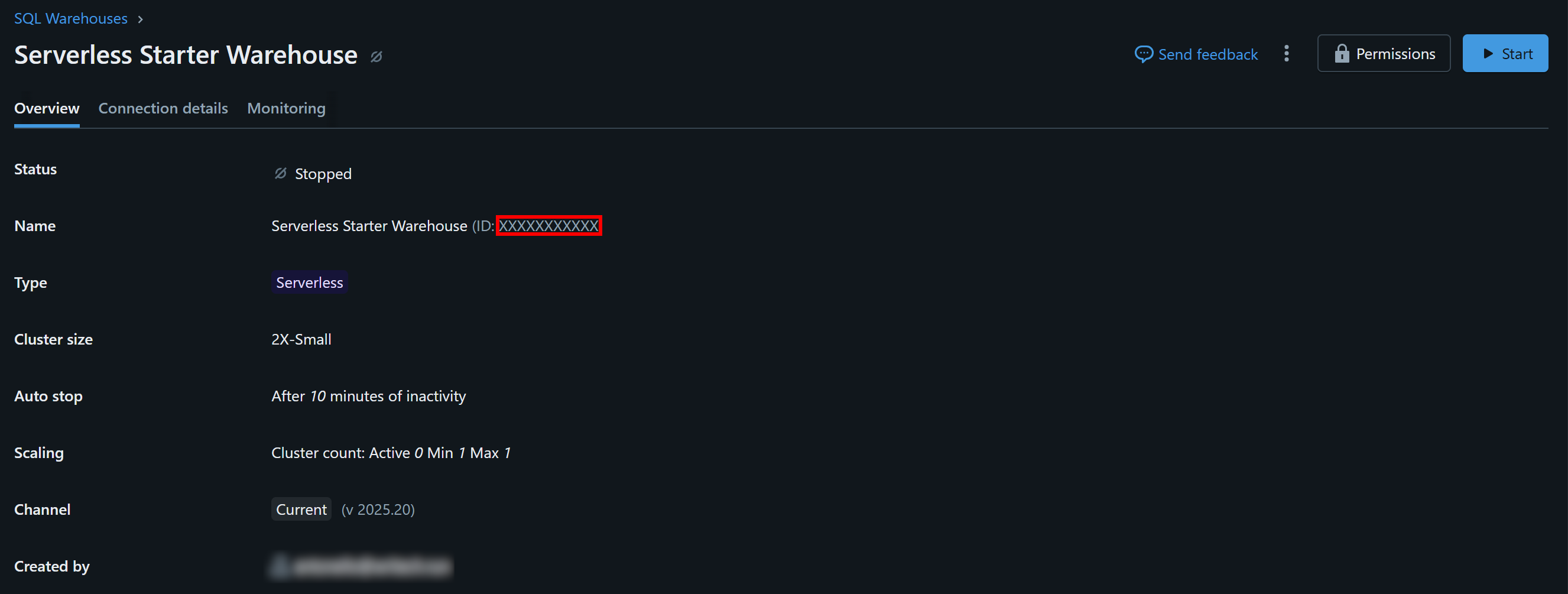
In the “Name” section, you will see your Databricks warehouse ID (in parentheses, after ID:). Copy it and store it safely, as you will need it shortly.
Find Your Databricks Host
To connect to any Databricks compute resource, you need to specify your Databricks hostname. This corresponds to the base URL associated with your Databricks account and has a format like:
https://<random-string>.cloud.databricks.comYou can find this information directly by copying it from your Databricks dashboard URL:

Get Access to Bright Data Datasets
Now you need to add one or more Bright Data datasets to your Databricks account so that you can query them via API, CLI, or SQL Connector.
Go to the “Marketplace” page, click the settings button on the left, and select “Bright Data” as the only provider you are interested in:
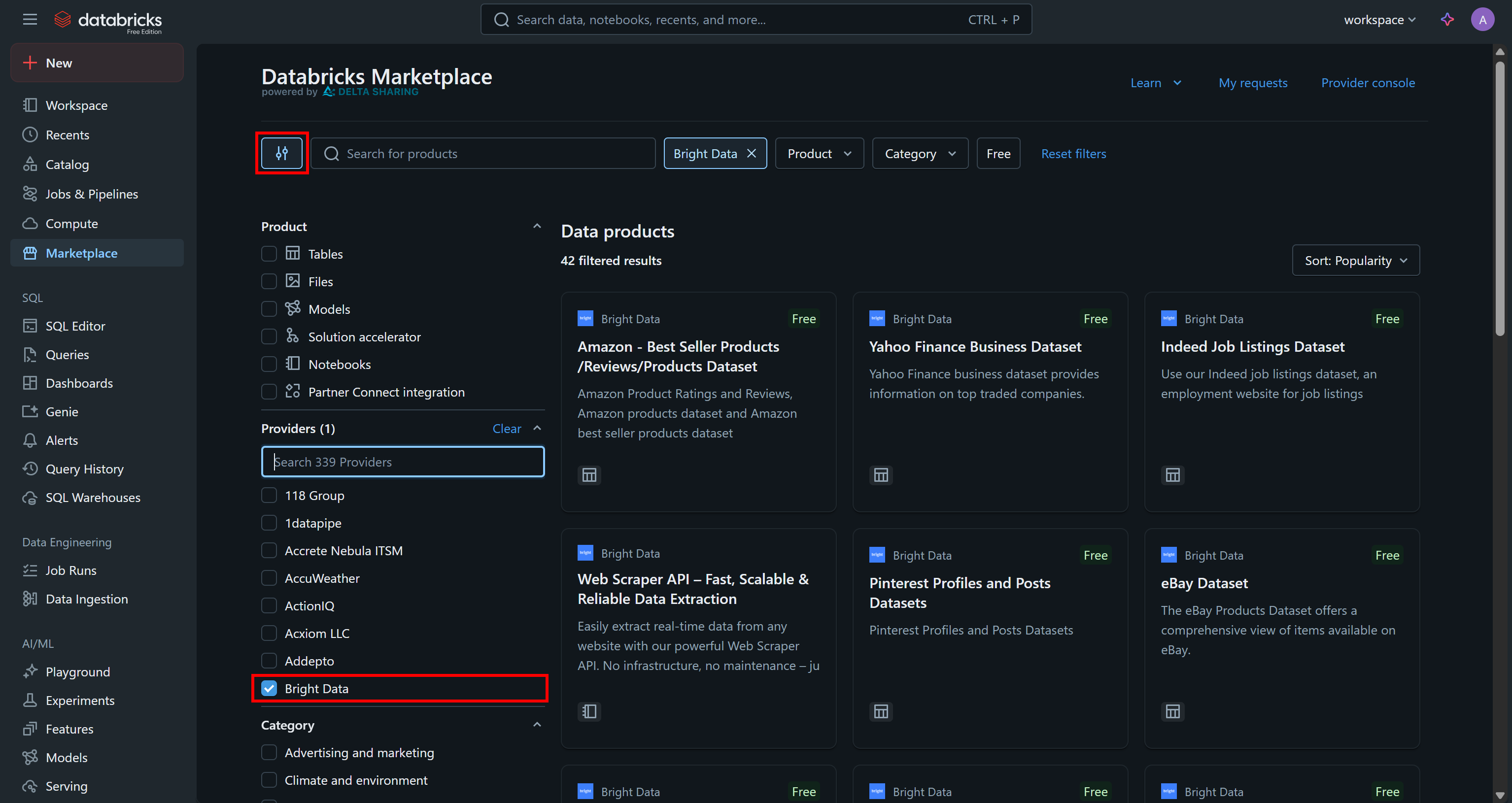
This will filter the available data products to only those provided by Bright Data and accessible via Databricks.
For this example, assume you are interested in the “Zillow Properties Information Dataset”:
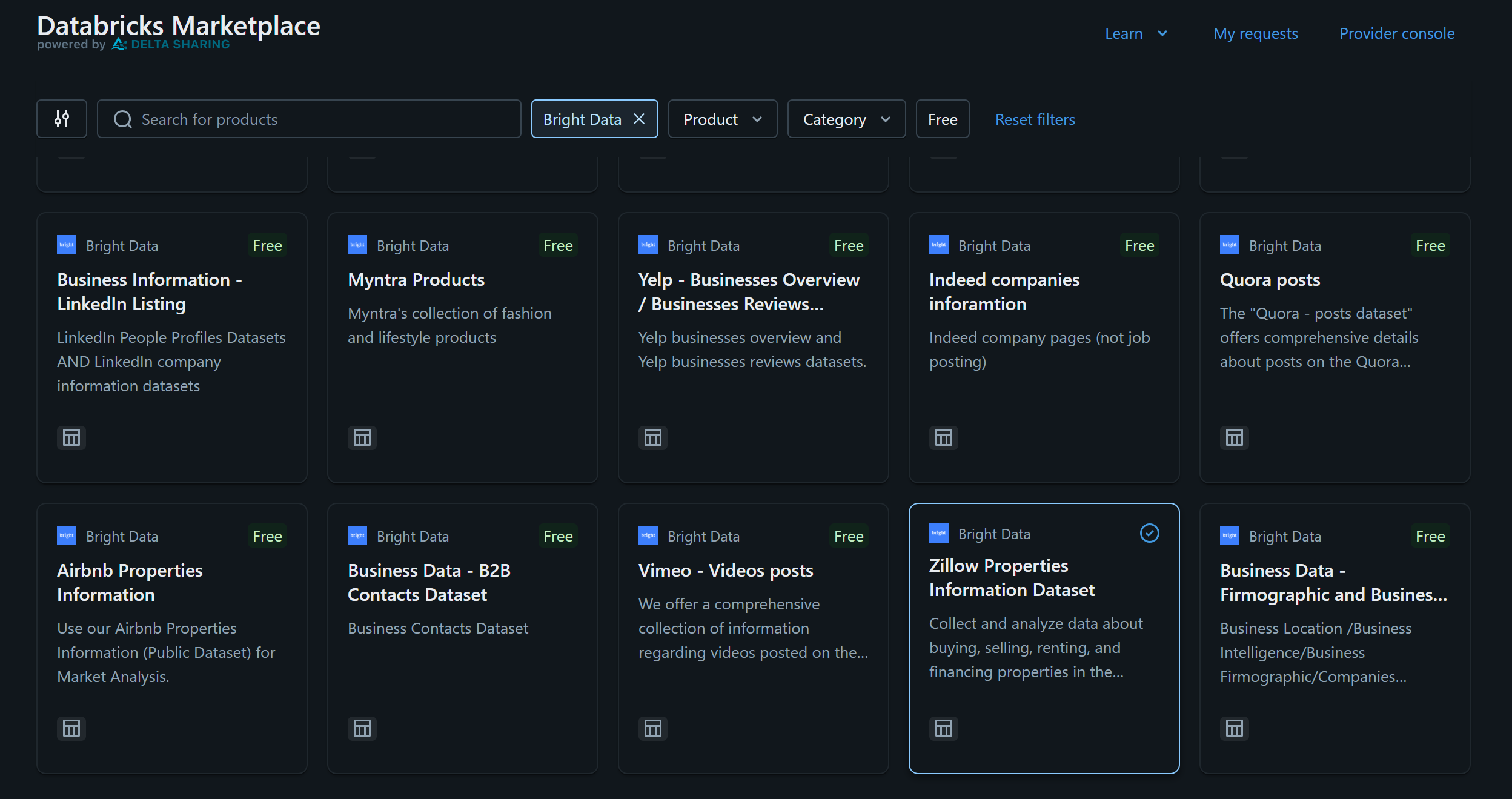
Click on the dataset card, and on the “Zillow Properties Information Dataset” page, press “Get Instances Access” to add it to your Databricks account:
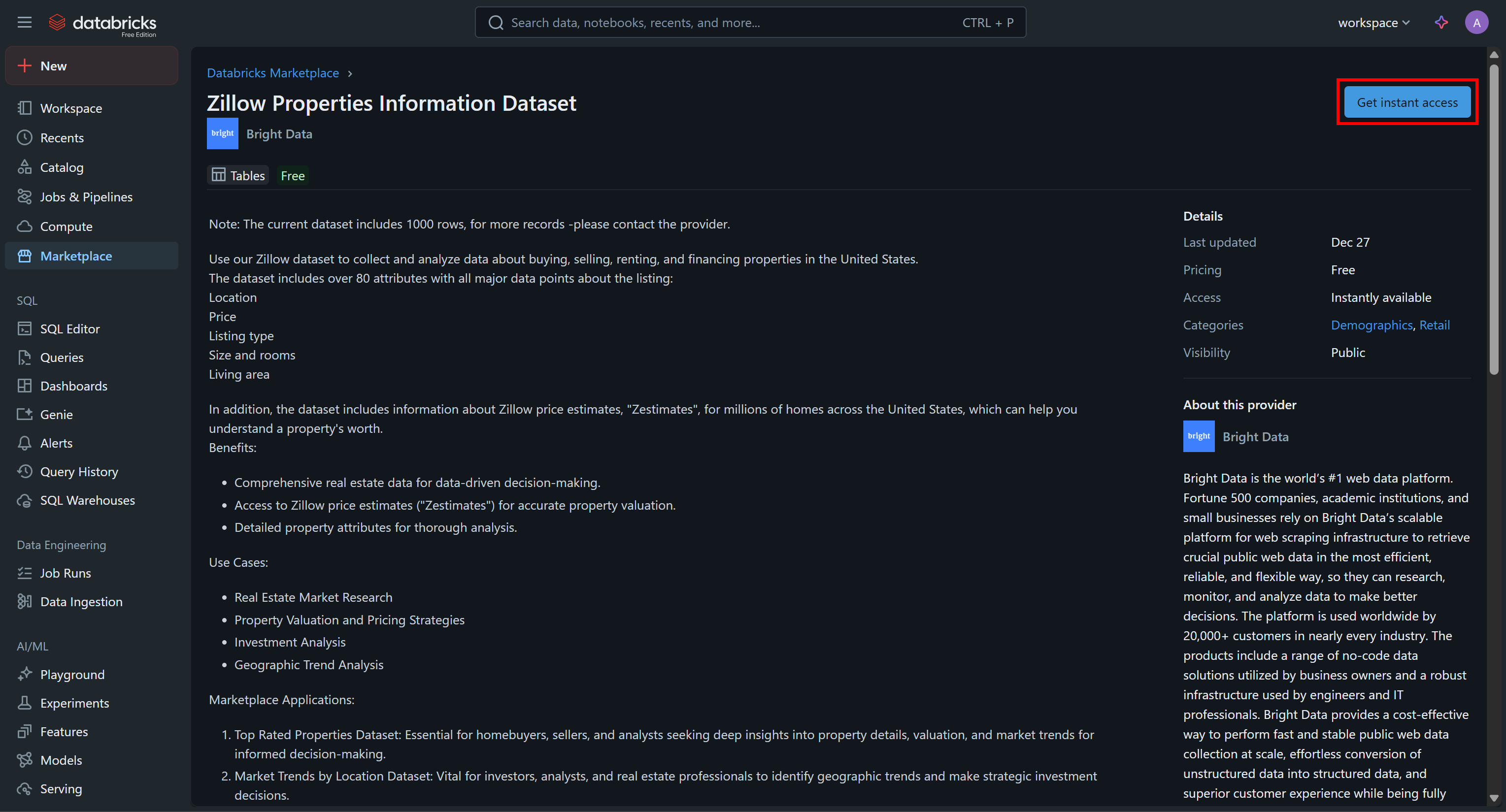
The dataset will be added to your account, and you will now be able to query it via Databricks SQL. If you are wondering where that data comes from, the answer is Bright Data’s Zillow Datasets.
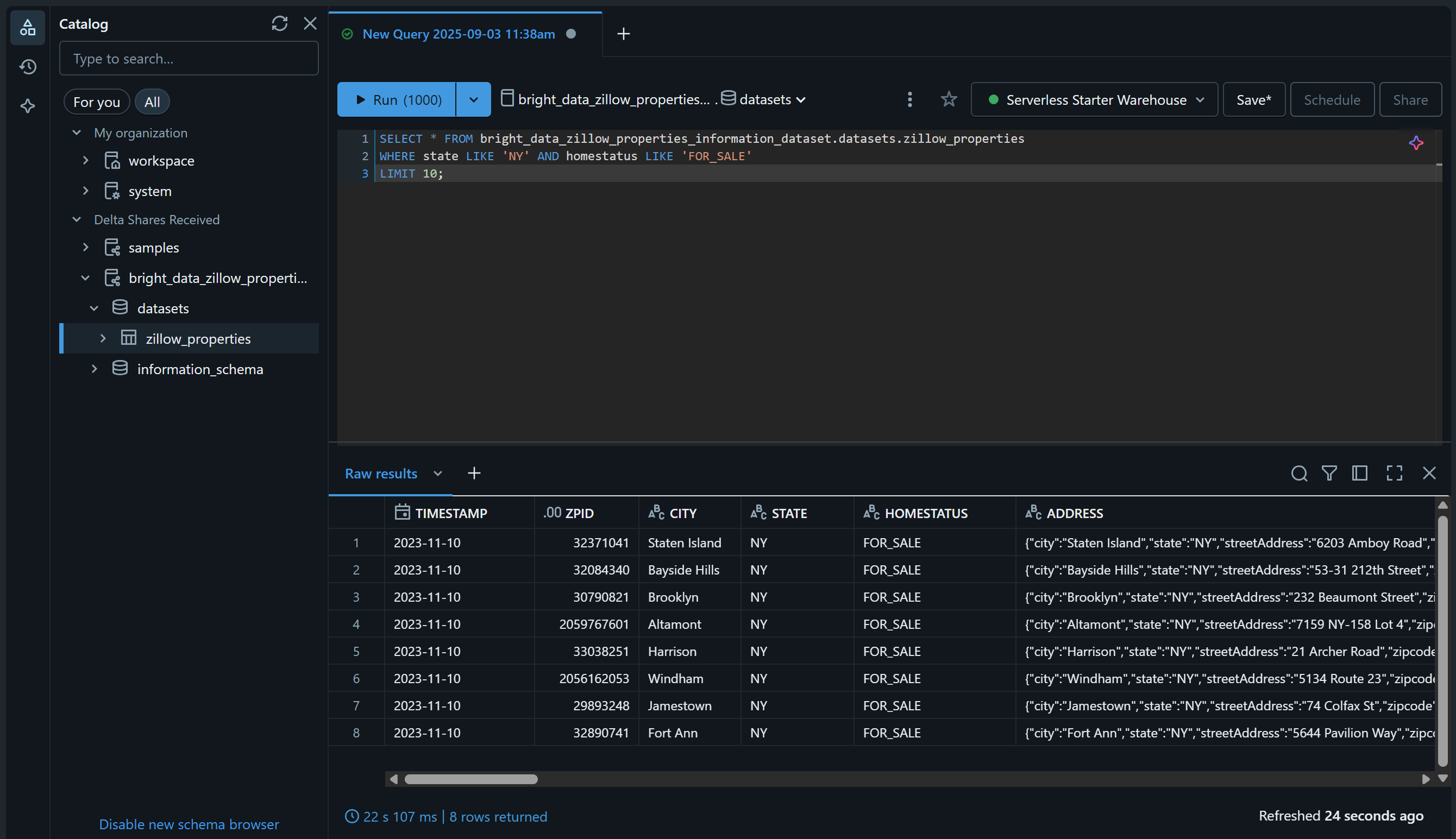
Verify that by reaching the “SQL Editor” page, and query the dataset using a SQL query like this:
SELECT * FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;The result should be something like:
Great! You have successfully added the chosen Bright Data dataset and made it queryable via Databricks. You can follow the same steps to add other Bright Data datasets.
In the next sections, you will learn how to query this dataset:
- Via the Databricks REST API
- With the Databricks SQL Connector for Python
- Through the Databricks CLI
How to Query a Bright Data Dataset via the Databricks REST API
Databricks exposes some of its features via a REST API, including the ability to query datasets available in your account. Follow the steps below to see how to programmatically query the “Zillow Properties Information Dataset” provided by Bright Data.
Note: The code below is written in Python, but it can be easily adapted to other programming languages or called directly in Bash via cURL.
Step #1: Install the Required Libraries
To run SQL queries on remote Databricks warehouses, the REST API endpoint to use is /api/2.0/sql/statements. You can call it via a POST request using any HTTP client. In this example, we will use the Python Requests library.
Install it with:
pip install requestsNext, import it in your script with:
import requestsLearn more about it in our dedicated guide on Python Requests.
Step #2: Prepare Your Databricks Credentials and Secrets
To call the Databricks REST API endpoint /api/2.0/sql/statements using an HTTP client, you need to specify:
- Your Databricks access token: For authentication.
- Your Databricks host: To build the complete API URL.
- Your Databricks warehouse ID: To query the correct table in the correct warehouse.
Add the secrets you retrieved earlier to your script like this:
databricks_access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
databricks_warehouse_id = "<YOUR_DATABRICKS_WAREHOUSE_ID>"
databricks_host = "<YOUR_DATABRICKS_HOST>"Tip: In production, avoid hard-coding these secrets in your script. Instead, consider storing those credentials in environment variables and loading them using python-dotenv for better security.
Step #3: Call the SQL Statement Execution API
Make a POST HTTP call to the /api/2.0/sql/statements endpoint with the appropriate headers and body using Requests:
# The parametrized SQL query to run on the given dataset
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# The parameter to populate the SQL query
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# Make the POST request and query the dataset
headers = {
"Authorization": f"Bearer {databricks_access_token}", # For authenticating in Databricks
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)As you can see, the snippet above relies on a prepared SQL statement. As stressed in the documentation, Databricks strongly recommends using parameterized queries as a best practice for your SQL statements.
In other words, running the script above is equivalent to executing the following query on the bright_data_zillow_properties_information_dataset.datasets.zillow_properties table, just as we did earlier:
SELECT * FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;Fantastic! It only remains to manage the output data
Step #4: Export the Query Results
Handle the response and export the retrieved data with this Python logic:
if response.status_code == 200:
# Access the output JSON data
result = response.json()
# Export the retrieved data to a JSON file
output_file = "zillow_properties.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=4)
print(f"Query successful! Results saved to '{output_file}'")
else:
print(f"Error {response.status_code}: {response.text}")If the request is successful, the snippet will create a zillow_properties.json file containing the query results.
Step #5: Put It All Together
Your final script should contain:
import requests
import json
# Your Databricks credentials (replace them with the right values)
databricks_access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
databricks_warehouse_id = "<YOUR_DATABRICKS_WAREHOUSE_ID>"
databricks_host = "<YOUR_DATABRICKS_HOST>"
# The parametrized SQL query to run on the given dataset
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# The parameter to populate the SQL query
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# Make the POST request and query the dataset
headers = {
"Authorization": f"Bearer {databricks_access_token}", # For authenticating in Databricks
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)
# Handle the response
if response.status_code == 200:
# Access the output JSON data
result = response.json()
# Export the retrieved data to a JSON file
output_file = "zillow_properties.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=4)
print(f"Query successful! Results saved to '{output_file}'")
else:
print(f"Error {response.status_code}: {response.text}")Execute it, and it should produce a zillow_properties.json file in your project directory.
The output first contains the column structure to help you understand the available columns. Then, in the data_array field, you can see the resulting query data as a JSON string:
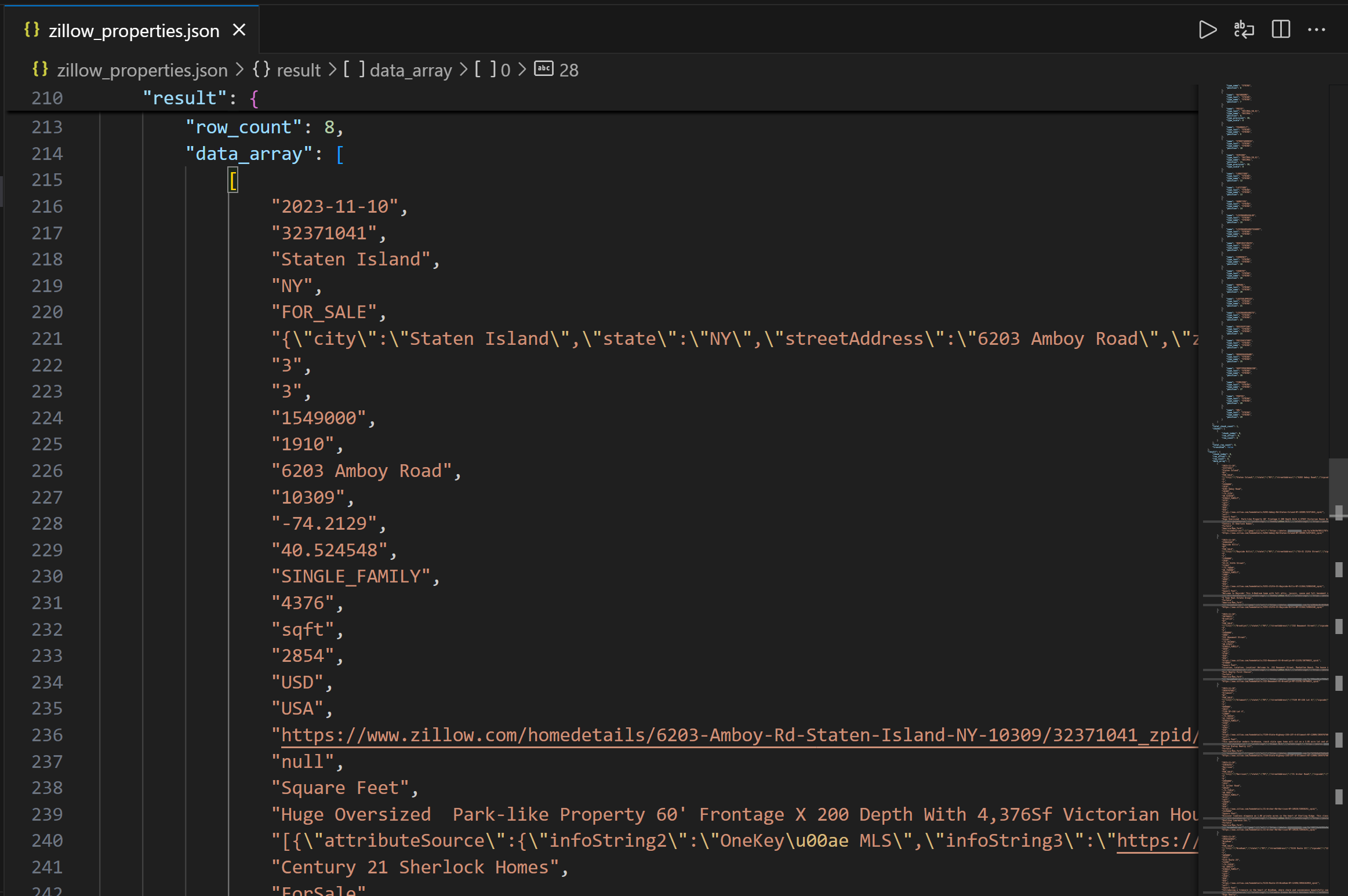
Mission complete! You just collected Zillow property data provided by Bright Data via the Databricks REST API.
How to Access Bright Data Datasets Using the Databricks CLI
Databricks also lets you query data in a warehouse through the Databricks CLI, which relies on the REST API under the hood. Learn how to use it!
Step #1: Install the Databricks CLI
The Databricks CLI is an open-source command-line tool that lets you interact with the Databricks platform directly from your terminal.
To install it, follow the installation guide for your operating system. If everything is set up correctly, running the databricks -v command should display something like this:

Perfect!
Step #2: Define a Configuration Profile for Authentication
Use the Databricks CLI to create a configuration profile named DEFAULT that authenticates you with your Databricks personal access token. To do so, run the command below:
databricks configure --profile DEFAULTYou will then be prompted to provide:
- Your Databricks host
- Your Databricks access token
Paste both values and press Enter to complete the configuration:

You will now be able to authenticate CLI api commands by specifying the --profile DEFAULT option.
Step #3: Query Your Dataset
Use the following CLI command to run a parameterized query via the api post command:
databricks api post "/api/2.0/sql/statements" \
--profile DEFAULT \
--json '{
"warehouse_id": "<YOUR_DATABRICKS_WAREHOUSE_ID>",
"statement": "SELECT * FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties WHERE state LIKE :state AND homestatus LIKE :homestatus LIMIT :row_limit",
"parameters": [
{ "name": "state", "value": "NY", "type": "STRING" },
{ "name": "homestatus", "value": "FOR_SALE", "type": "STRING" },
{ "name": "row_limit", "value": "10", "type": "INT" }
]
}' \
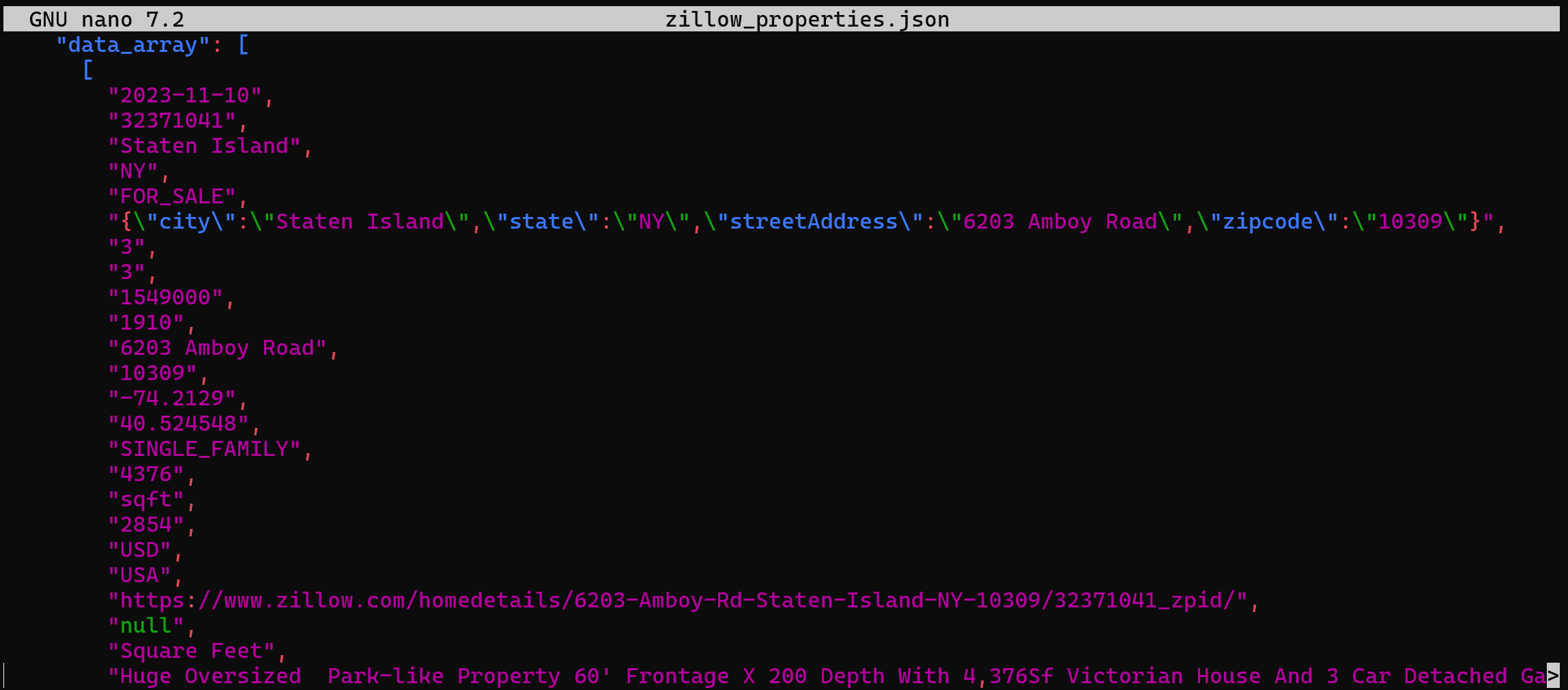
> zillow_properties.jsonReplace the <YOUR_DATABRICKS_WAREHOUSE_ID> placeholder with the actual ID of your Databricks SQL warehouse.
Behind the scenes, this does the same thing we did before in Python. More specifically, it makes a POST request to the Databricks REST SQL API. The result will be a zillow_properties.json file containing the same data as seen before:
How to Query a Dataset From Bright Data Through the Databricks SQL Connector
The Databricks SQL Connector is a Python library that lets you connect to Databricks clusters and SQL warehouses. In particular, it provides a simplified API for connecting to Databricks infrastructure and exploring your data.
In this guide section, you will learn how to use it to query the “Zillow Properties Information Dataset” from Bright Data.
Step #1: Install the Databricks SQL Connector for Python
The Databricks SQL Connector is available via the databricks-sql-connector Python library. Install it with:
pip install databricks-sql-connectorThen, import it in your script with:
from databricks import sqlStep #2: Get Started with the Databricks SQL Connector
The Databricks SQL Connector requires different credentials compared to the REST API and CLI. In detail, it needs:
server_hostname: Your Databricks host name (without thehttps://part).http_path: A special URL to connect to your warehouse.access_token: Your Databricks access token.
You can find the necessary authentication values, along with a sample starter snippet, in the “Connection Details” tab of your SQL warehouse:
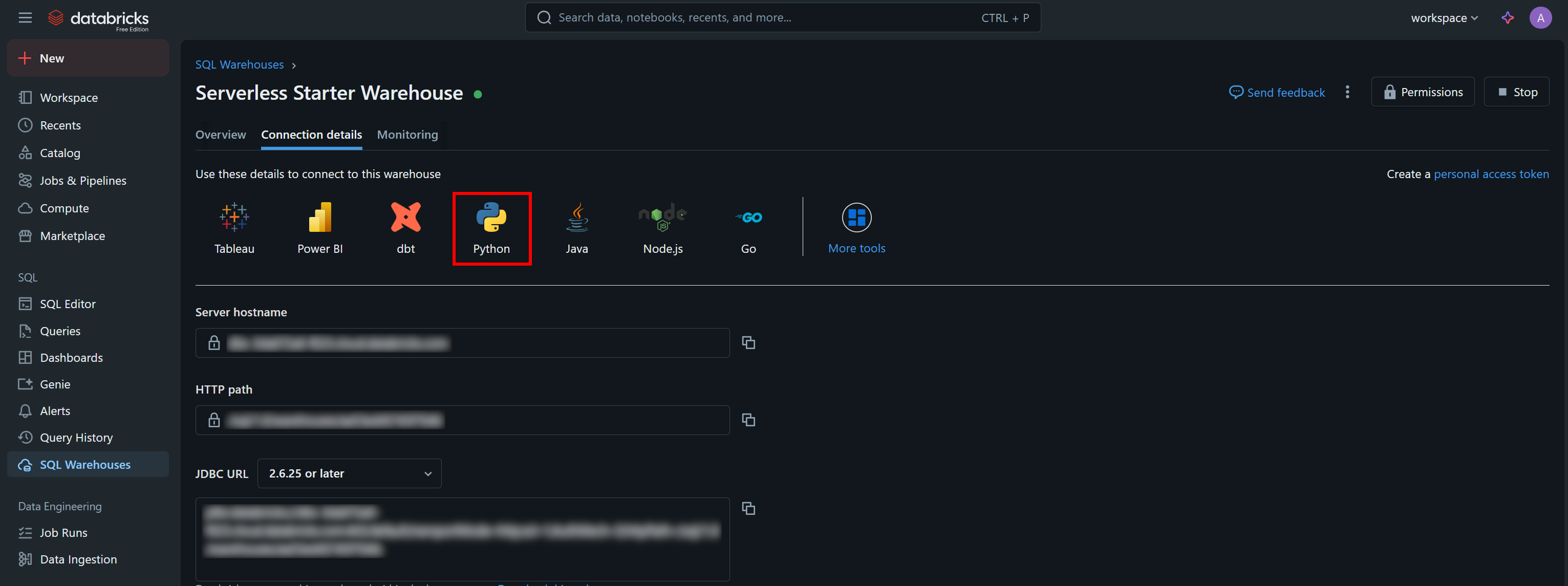
Press the “Python” button, and you will get:
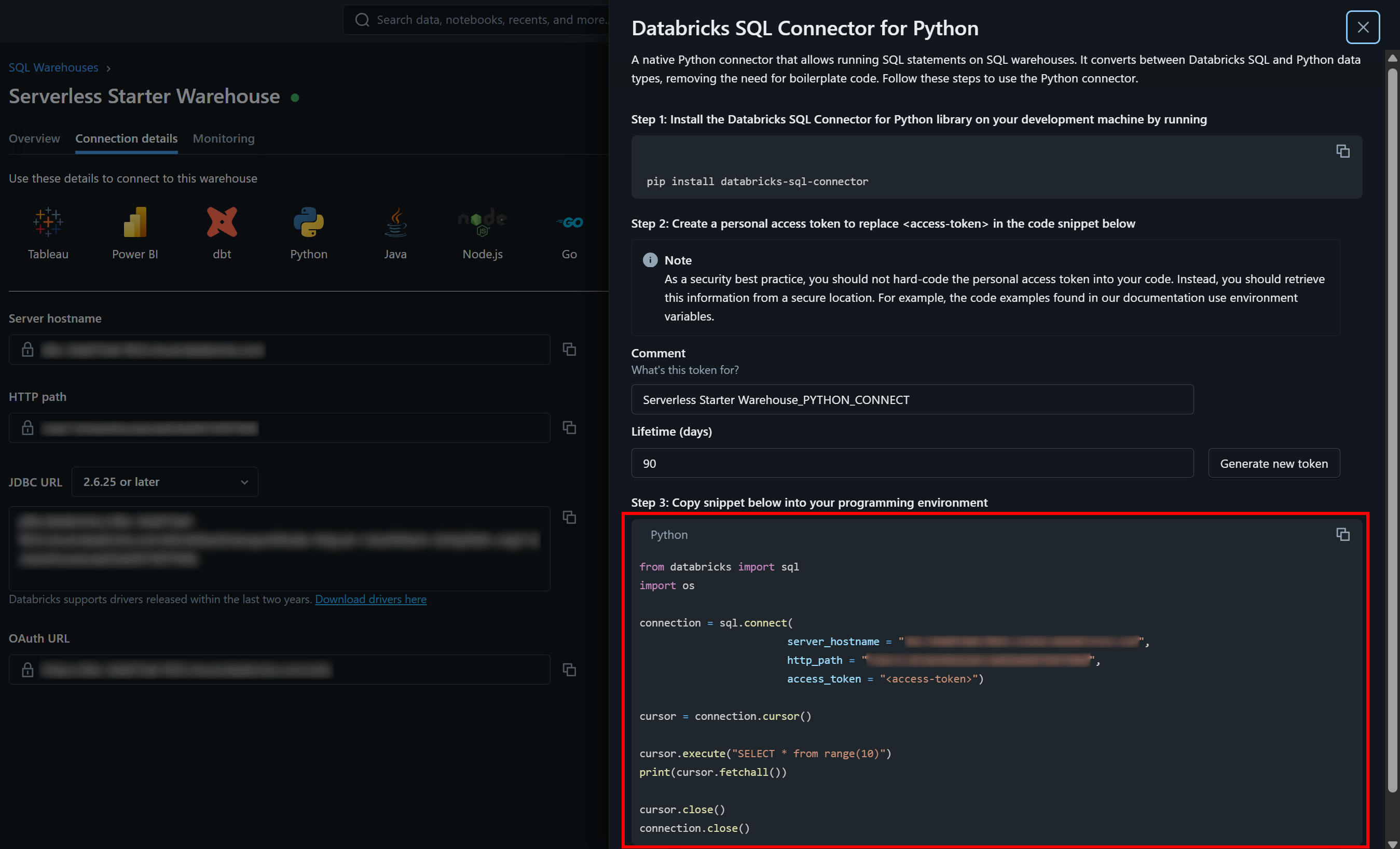
These are all the instructions you need to get started with the databricks-sql-connector.
Step #3: Put It All Together
Adapt the code from the sample snippet in the “Databricks SQL Connector for Python” section to your warehouse in order to run the parameterized query of interest. You should end up with the a script like the following:
from databricks import sql
# Connect to your SQL warehouse in Databricks (replace the credentials with your values)
connection = sql.connect(
server_hostname = "<YOUR_DATABRICKS_HOST>",
http_path = "<YOUR_DATABRICKS_WAREHOUST_HTTP_PATH>",
access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
)
# Execute the SQL parametrized query and get the results in a cursor
cursor = connection.cursor()
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.datasets.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit
"""
params = {
"state": "NY",
"homestatus": "FOR_SALE",
"row_limit": 10
}
# Run the query
cursor.execute(sql_query, params)
result = cursor.fetchall()
# Printing all results a row at a time
for row in result[:2]:
print(row)
# Close the cursor and the SQL warehouse connection
cursor.close()
connection.close()Run the script, and it will generate an output like this:
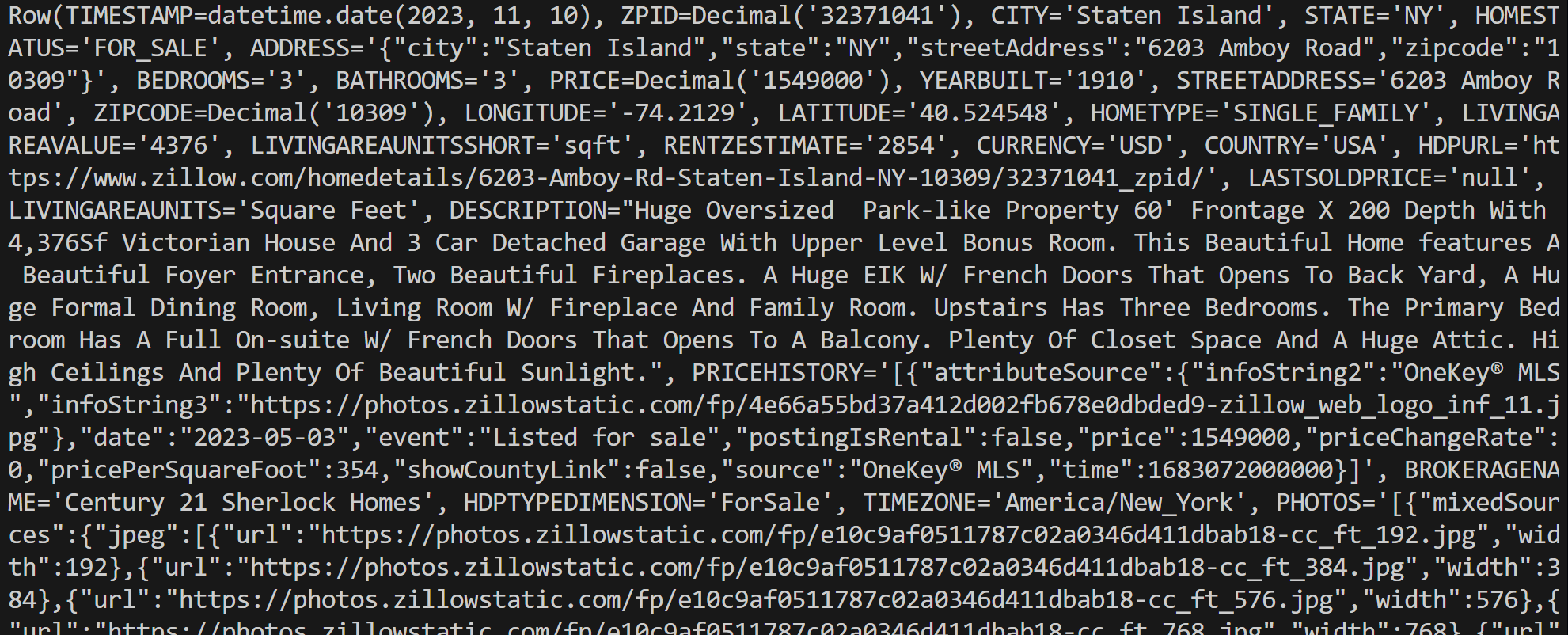
Notice that each row object is a Row instance, representing a single record from the query results. You can then process that data directly in your Python script.
Keep in mind that you can convert a Row instance into a Python dictionary with the asDict() method:
row_data = row.asDict()Et voilà! You now know how to interact with and query your Bright Data datasets in Databricks in multiple ways.
Conclusion
In this article, you learned how to query Bright Data’s datasets from Databricks using its REST API, CLI, or dedicated SQL Connector library. As demonstrated, Databricks provides multiple ways to interact with the products offered by their data providers, which now includes Bright Data.
With over 40 products available, you can explore the extensive richness of Bright Data’s datasets directly within Databricks and access their data in a variety of ways.
Create a Bright Data account for free and start experimenting with our data solutions today!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.




