

Bright Data is the most complete web scraping platform on the market. It pairs the largest commercial proxy network with structured scraper APIs and ready-made datasets. It also adds a Scraping Browser, SERP APIs, and AI-agent integration. Zyte is the older, Scrapy-native alternative, built around a single managed scraping API.
Zyte (formerly Scrapinghub) created Scrapy, the open-source Python framework. It now sells three products: Zyte API, Zyte Data, and Scrapy Cloud. We tested both platforms and reviewed independent benchmark data. We compared them on success rate, pricing, product depth, and real-world usability. Bright Data wins on every axis except one narrow pricing case.
TL;DR: Bright Data vs. Zyte
Bottom line: Bright Data is the better choice for most teams. It scores higher on protected sites, offers far more products, and prices predictably. Zyte fits Scrapy-native teams scraping simple, unprotected sites. Benchmark figures below come from Scrape.do’s independent 2026 test.
| Feature | Bright Data | Zyte |
|---|---|---|
| Success rate | 98.87% | 91.43% |
| Product scope | Web Scraper APIs, Web Unlocker, Scraping Browser, SERP API, proxies, datasets, MCP | Zyte API, Zyte Data, Scrapy Cloud |
| Proxy access | Direct: residential, datacenter, ISP in 195 countries | None: managed internally by Zyte API |
| Pre-built datasets | Yes, 100+ domains | No |
| AI agent integration | MCP server | None |
| Pricing model | Flat: $1.5/1K records | Tiered by site difficulty: $0.06 to $16.08/1K |
| Free tier | 5,000 records/month, no card | $5 credit, card required |
| Best for | Reliability at scale, datasets, proxy control, AI agents | Scrapy-native teams on simple sites |
Success Rate: The Benchmark Data
Reliability is the first thing that matters in scraping. Scrape.do’s 2026 benchmark tested both against seven hard targets. These included Amazon, Indeed, Zillow, Google, and X. Bright Data scored 98.87%, the highest of any provider tested. Zyte scored 91.43%.
That 7-point gap compounds at scale. Across 100,000 requests, it is the difference between 1,130 and 8,570 failures. Each failure means wasted compute and a re-crawl. On protected sites, Bright Data is simply more reliable.
Response times were close in the test, around 10 to 11 seconds each. Speed is not the differentiator here. Reliability on hard targets is.
Pricing: Flat Rate vs. Difficulty Tiers
This is where the platforms differ most in philosophy. Bright Data charges one flat rate. Zyte charges by how hard the target site is.
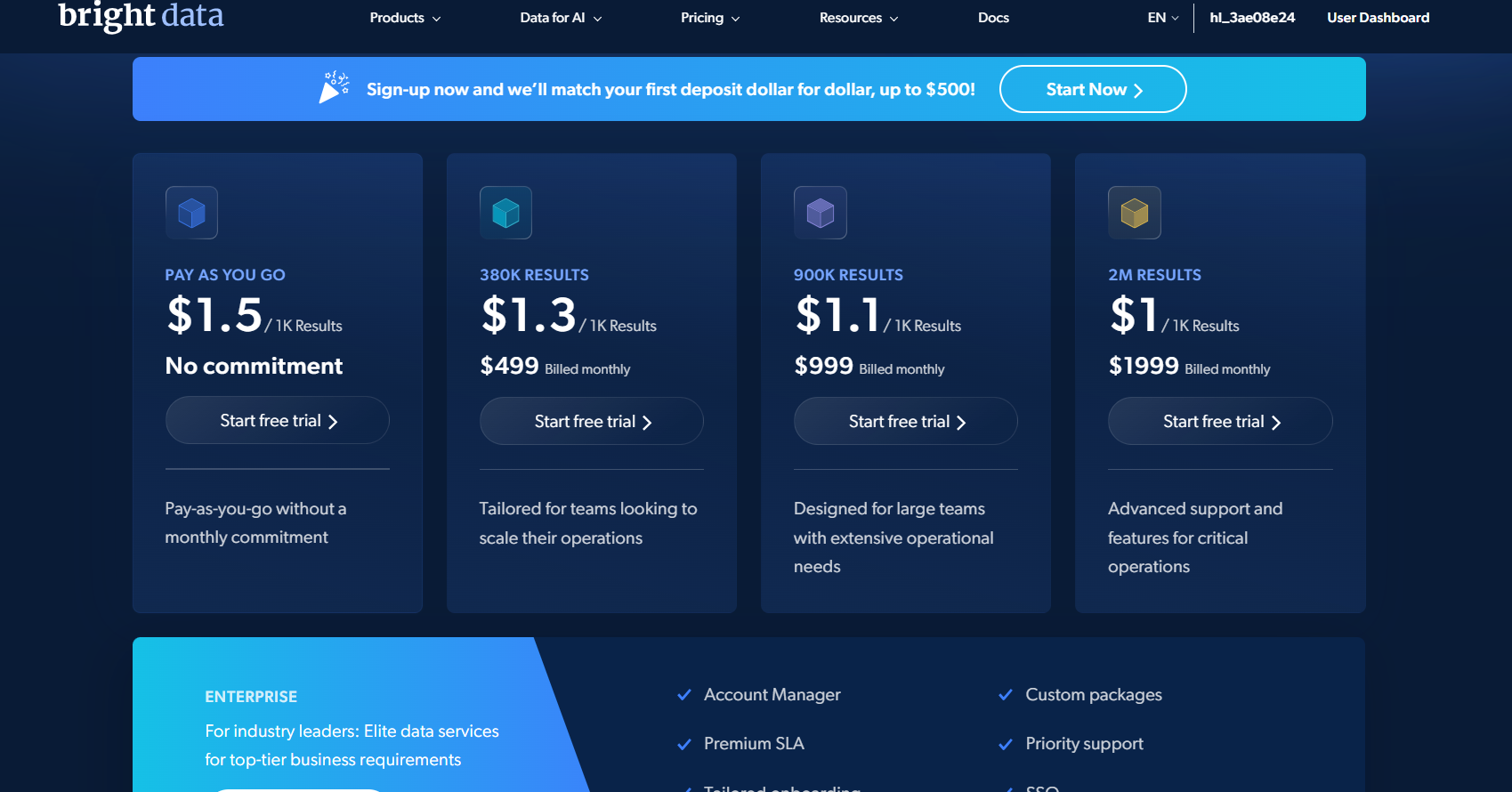
Bright Data: flat-rate pricing
Bright Data’s Web Scraper API costs $1.5 per 1,000 records on pay-as-you-go. You pay only for successful results. The free tier includes 5,000 records a month with no credit card. The Scale plan is $499 a month for 384,000 records.
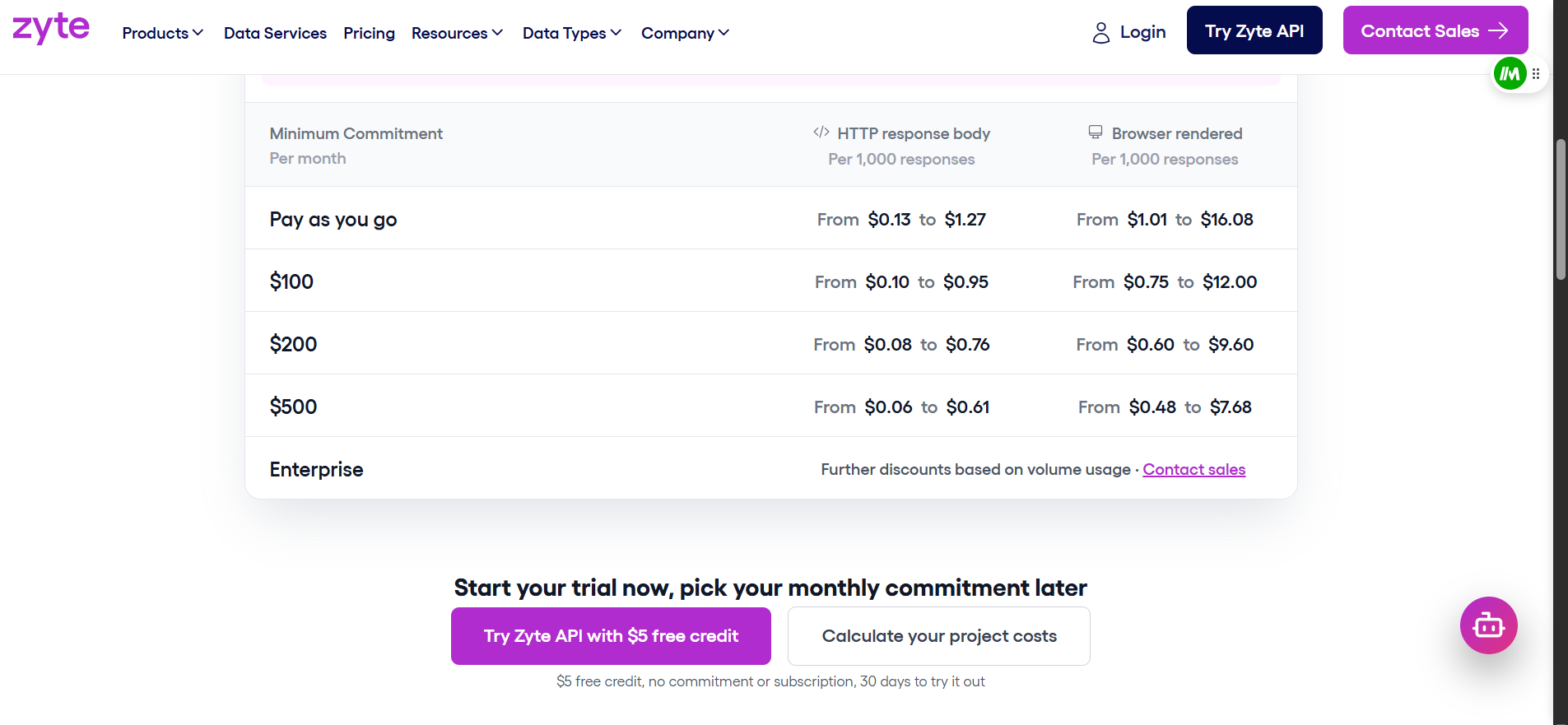
Zyte: five difficulty tiers
Zyte sorts every site into five difficulty tiers. HTTP requests run from $0.06 to $1.27 per 1,000. Browser-rendered requests run from $0.48 to $16.08 per 1,000. The exact rate depends on the tier and your monthly commitment.
The pricing math in practice
Take 100,000 requests against a hard site with browser rendering. Bright Data costs $150 on pay-as-you-go. Zyte costs $402 at a mid tier, and up to $1,608 at its hardest tier.
Now take 100,000 requests against a simple HTTP-only site. Zyte costs as little as $13. Bright Data still costs $150. Zyte wins on trivial sites, but those rarely need a paid scraping API.
The deeper problem is predictability. You often do not know a site’s tier before you scrape it. Budgeting gets hard when targets span tiers. Bright Data’s flat rate removes that variable entirely.
Product Depth: A Full Stack vs. One API
This is Bright Data’s biggest structural advantage. Zyte offers three products. Bright Data offers a full data infrastructure stack. Its network spans 400M+ residential IPs, 1,300,000+ datacenter IPs, and 1,300,000+ ISP IPs across 195 countries.
What Bright Data has that Zyte does not
1. Pre-built datasets. Bright Data maintains ready-to-use datasets for 100+ domains. These include LinkedIn, Amazon, Zillow, and Google Maps. You query a dataset with filters and get structured records back. No scraper, no crawl, no parsing.
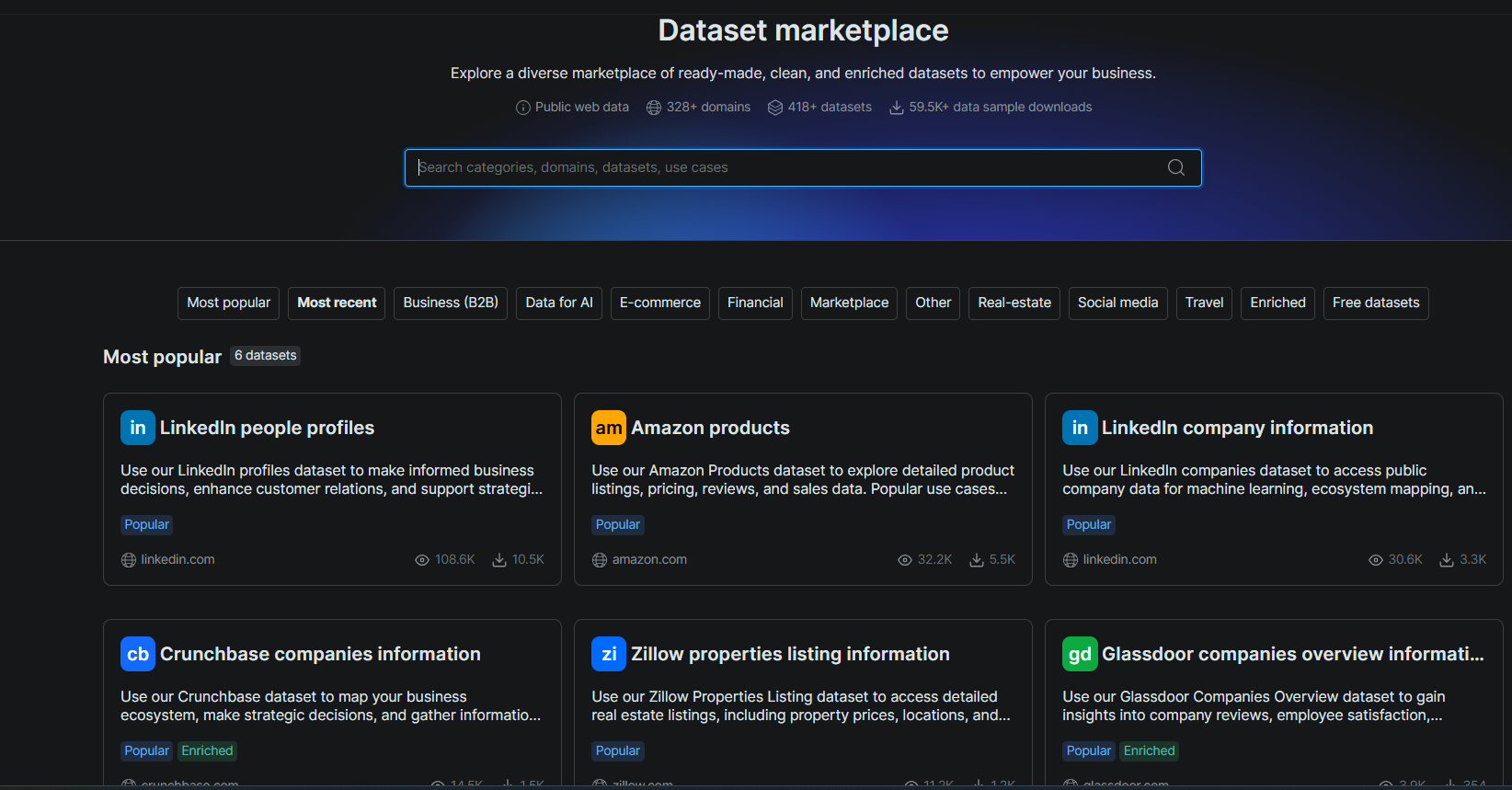
In our testing, the Dataset Filter API returned 100 LinkedIn companies in 46.5 seconds. Each record carried firmographics, funding history, and a Crunchbase URL. Zyte has no equivalent. The same task on Zyte means building and maintaining a custom scraper.

2. Direct proxy access. Bright Data lets you use its proxy network directly. You control country, city, and ASN targeting. Zyte manages proxies internally, so you get no control over type, location, or rotation.
3. Scraping Browser. The Scraping Browser connects your existing Playwright, Puppeteer, or Selenium scripts to managed infrastructure. It handles proxy rotation, CAPTCHA solving, and fingerprints. Zyte requires you to rewrite that logic as API requests.
4. SERP API. The SERP API returns structured search results from Google, Bing, and more. Zyte has no dedicated search product.
5. MCP integration. The MCP server gives AI agents native web-data tools. Agents built with LangChain, CrewAI, or LlamaIndex can call it directly. Zyte has no MCP integration.
What Zyte has that Bright Data does not
1. Scrapy Cloud. Zyte created Scrapy and runs the best managed host for Scrapy spiders. It handles deployment, scheduling, and monitoring from $9 per unit a month. Scrapy-heavy teams get a natural home here.
2. AI no-code extraction. Zyte’s AI returns structured data for supported page types without selectors. It works well for products, articles, and job pages. Bright Data’s Scraper Studio covers no-code building, but Zyte’s zero-config approach is smoother for those schemas.
3. Zyte Data. Zyte Data is a fully managed extraction service from $500 a month. Their team builds and maintains the pipeline for you. Bright Data’s datasets are self-serve rather than fully managed.
Hands-On: Bright Data Web Scraper API
Bright Data returns structured JSON directly. You send a URL and get parsed fields back, with no HTML to handle:
import requests
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": "gd_l7q7dkf244hwjntr0", "format": "json"},
headers={"Authorization": "Bearer YOUR_API_TOKEN"},
json=[{"url": "https://www.amazon.com/dp/B0D1XD1ZV3"}],
)
product = response.json()
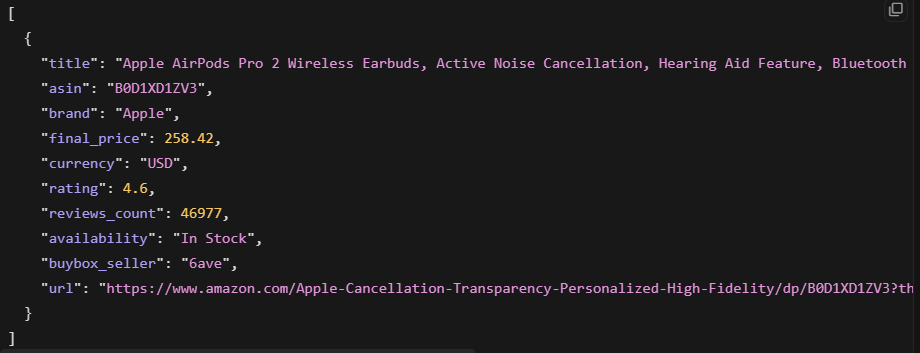
This returned the product title, price, rating, review count, and availability. The output was clean structured JSON, ready to use.
For sites without a pre-built scraper, the Web Unlocker returns unblocked HTML to parse yourself:
response = requests.post(
"https://api.brightdata.com/request",
headers={"Authorization": "Bearer YOUR_API_TOKEN"},
json={"zone": "YOUR_ZONE_NAME", "url": "https://example.com/page", "format": "json"},
)
html = response.json().get("body", "")
Web Unlocker handles proxy selection, CAPTCHA solving, and retries. You keep control over proxy type and geographic targeting.
Hands-On: How Zyte API Works
Zyte API returns raw or browser-rendered HTML, and you handle the parsing:
import requests
response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={"url": "https://books.toscrape.com/", "browserHtml": True},
)
html = response.json().get("browserHtml")
Zyte’s AI extraction adds structured output for supported schemas. You set a flag and skip the selectors:
response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={"url": "https://books.toscrape.com/", "product": True},
)
product = response.json().get("product")
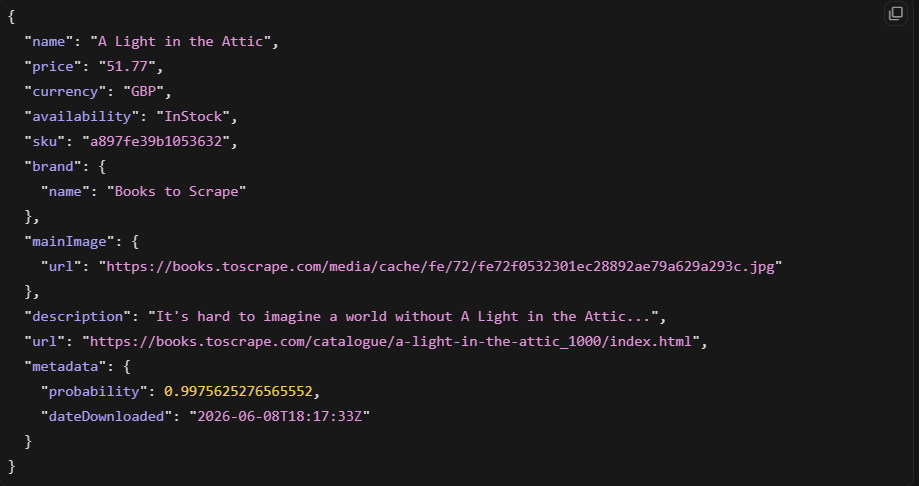
This returned a clean product object in our test. The AI extraction is genuinely useful for supported page types. The catch is that it only works where Zyte has trained models.
When to Choose Which
- Choose Bright Data for high success rates, pre-built datasets, proxy control, AI agents, and predictable pricing
- Choose Zyte if your team is built on Scrapy and scrapes mostly simple, unprotected sites
- Use both if you run Scrapy spiders on Scrapy Cloud but need Bright Data for hard targets
Conclusion
Zyte is a capable platform for Scrapy-native teams on simple sites. The gap appears when the work gets harder. Bright Data scores higher on protected sites, offers far more products, and prices without guesswork.
For reliable data at scale, Bright Data is the stronger, broader foundation. It is backed by ISO 27001 certification and GDPR and CCPA compliance. See the Trust Center for details. You can also read our Bright Data vs. Apollo comparison.
Start your free trial today and test Bright Data on your hardest targets.
Frequently Asked Questions
Is Bright Data or Zyte better for web scraping?
Bright Data is better for most teams. It scored 98.87% versus Zyte’s 91.43% in Scrape.do’s 2026 benchmark. It also offers far more products. Zyte fits Scrapy-native teams scraping simple sites.
How do Bright Data and Zyte pricing compare?
Bright Data charges a flat $1.5 per 1,000 records, with 5,000 free monthly. Zyte charges by site difficulty, from $0.06 to $16.08 per 1,000 requests. Bright Data’s pricing is more predictable.
Does Zyte have pre-built datasets like Bright Data?
No. Bright Data offers ready-made datasets for 100+ domains, including LinkedIn and Amazon. Zyte has no equivalent. You would build and maintain those scrapers yourself.
Can I use my existing Scrapy or Playwright code?
Zyte runs Scrapy Cloud, the best managed host for Scrapy spiders. Bright Data’s Scraping Browser connects existing Playwright, Puppeteer, and Selenium scripts to its infrastructure.
Which should I choose, Bright Data or Zyte?
Choose Bright Data for reliability at scale, datasets, proxy control, and AI agents. Choose Zyte if your team is Scrapy-native and scrapes mostly simple, unprotected sites.

Technical Writer
Amitesh Anand is a developer advocate and technical writer sharing content on AI, software, and devtools, with 10k followers and 400k+ views.




