

Exa is a semantic search engine. Bright Data is web data infrastructure. They are fundamentally different products, and the question of which to use depends entirely on what your AI agent actually needs to do.
This comparison cuts through both products on every dimension that matters for production AI teams: cost, rate limits, coverage, access, and historical data. No vague assessments, just numbers and facts.
TL;DR – Bright Data vs. Exa at a Glance
- Exa is a semantic search engine; Bright Data is web data infrastructure.
- Bright Data SERP API costs $1.50/1k requests; Exa charges $7/1k.
- Exa’s default
/searchrate limit is 10 QPS. Bright Data has no concurrent request limit. - Bright Data Web Unlocker can crawl anti-bot protected pages. Exa cannot.
- Bright Data holds 50PB+ of historical web data. Exa is live-only.
- Exa’s Find Similar feature is unique, with no direct Bright Data equivalent.
- Use Exa for semantic discovery. Use Bright Data for ground-truth extraction at scale.
Bright Data vs. Exa: Head-to-Head Comparison
| Dimension | Bright Data | Exa |
|---|---|---|
| Product category | Web data infrastructure (proxy network + scraping + datasets) | Semantic search engine API |
| Search approach | Real search engine scraping (Google, Bing, Yandex, etc.) via SERP API + live discovery via Discover API | Custom embeddings-based neural index (own index) |
| Results per query | Up to 1,000 (Discover API) | Up to 100 (standard); up to 1,000 on Enterprise |
| Full page content | Yes, live extraction via Web Unlocker, returned as Markdown | Yes, via /contents endpoint ($1/1k pages extra) |
| Anti-bot & CAPTCHA bypass | Yes, built into Web Unlocker; 400M+ proxy IPs | No, cannot crawl behind login walls or anti-bot protection |
| Historical data | Yes, 50PB+ Web Archive; pre-built Datasets | No, live index only |
| Rate limits | No limit on concurrent requests (SERP API) | 10 QPS default on /search; custom on Enterprise |
| Pricing (PAYG) | From $1.50/1,000 requests (SERP API) | $7/1,000 requests (standard search, 1-10 results) |
| Supported search engines | Google, Bing, DuckDuckGo, Yandex, Baidu, Naver, Yahoo | Exa’s own proprietary neural index |
| Compliance | GDPR, CCPA, SOC 2, SOC 3, ISO 27701 | SOC 2 Type II, ZDR option |
| MCP integration | Yes, Bright Data MCP Server (free, 5,000 free requests/month) | Yes, Exa MCP Server |
| Framework integrations | LangChain, LlamaIndex, CrewAI, Agno, Dify, n8n, Zapier, 70+ | LangChain, LlamaIndex, CrewAI, Vercel AI SDK, 20+ |
| Free tier | Yes, free trial | Yes, 1,000 requests/month |
| Enterprise SLA | Yes, 99.9% SLA, dedicated account manager | Yes, custom SLA, 1:1 onboarding |
What Is Exa?
Exa is a search engine built specifically for AI applications. Rather than using traditional keyword indexing, Exa built its own neural index, a large-scale embeddings model trained on the web. When you query Exa, it performs semantic vector search across that index and returns results ranked by conceptual relevance, not keyword overlap.
This architectural choice is Exa’s primary differentiator. It answers questions like “find papers similar to this arXiv URL” or “companies that do what Nvidia does for semiconductors” in ways that a keyword-based SERP scraper cannot. As of March 2026, Exa’s index includes over 1 billion people profiles and 70 million company entries, and they offer dedicated search modes for news, code, and financial reports. If you’re evaluating alternatives to Exa, the top Exa alternatives for AI web search covers a detailed comparison of competing tools including Bright Data, Tavily, and Firecrawl.
What Exa Does Well
Semantic “Find Similar” search. No other search API offers “find me pages conceptually similar to this URL.” It’s a genuine capability gap that Bright Data does not fill.
Low-latency retrieval. Exa Instant delivers sub-200ms responses. Standard search runs 100-1,200ms. For interactive chat interfaces and real-time agents, this speed is a real advantage.
Developer experience. SDKs in Python and TypeScript, native LangChain, LlamaIndex, and CrewAI integrations, MCP Server support, and a generous 1,000 free requests/month. Getting from zero to a working agent integration takes minutes.
Specialized domain indexes. Exa’s people index (1B+ profiles, 50M+ weekly updates) and company index (70M+ companies) are purpose-built for recruiting agents, sales intelligence pipelines, and company enrichment workflows.
Strong benchmark accuracy. On WebWalker multi-hop retrieval, Exa scored 81% vs. Tavily’s 71% in a Fortune 100 enterprise evaluation (January 2025). In AIMultiple’s 100-query benchmark across 8 APIs, Exa ranked 3rd with an Agent Score of 14.39.
Exa’s Core Limitations at Scale
Exa’s rate limit caps production workloads. The default /search limit is 10 QPS (600 requests per minute). Confirmed directly from Exa’s official rate limits docs. For multi-agent pipelines running thousands of parallel research tasks, this ceiling forces teams to build retry logic and request queuing from day one. Enterprise customers can negotiate higher limits, but that requires a separate sales conversation.
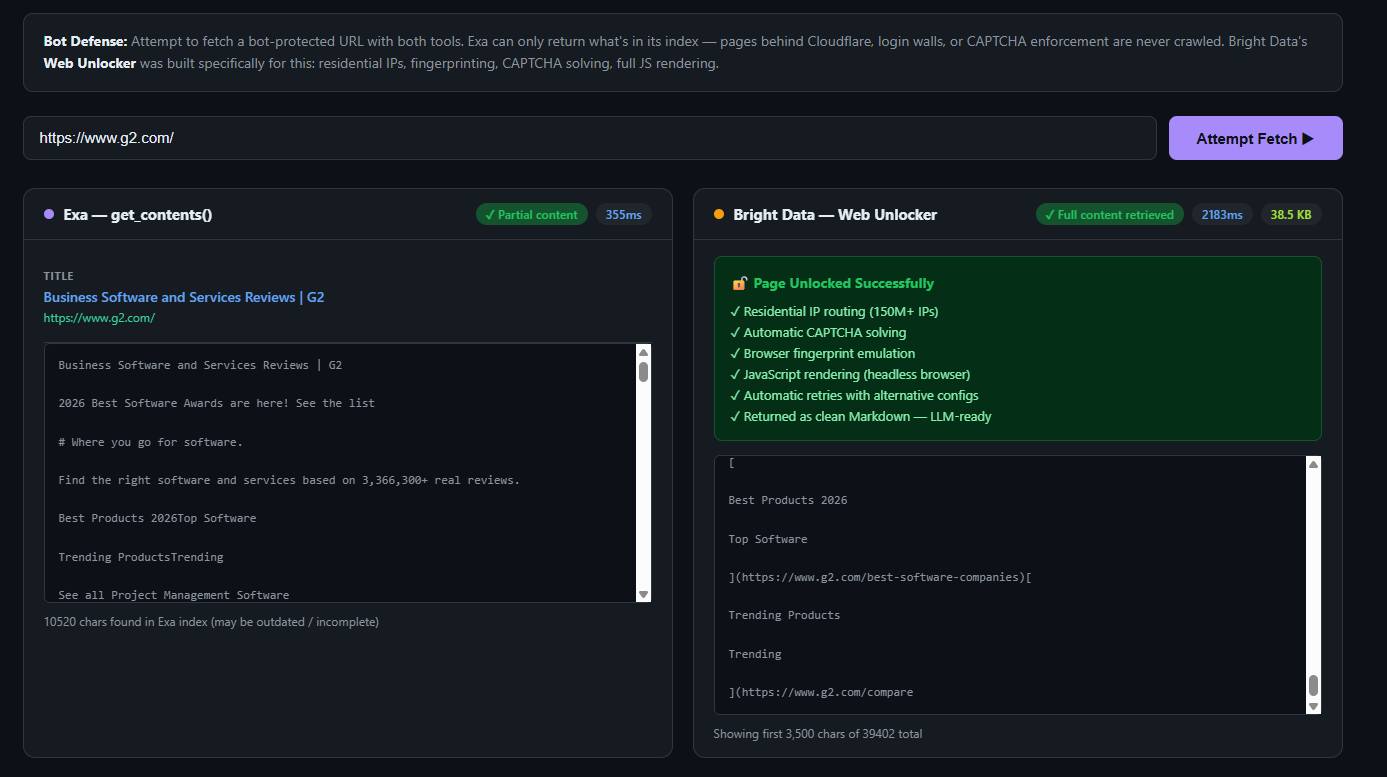
Exa cannot penetrate anti-bot protection. Exa crawls the open web on its own schedule. It cannot fetch pages behind Cloudflare, login walls, CAPTCHA systems, or JavaScript-heavy bot detection. For competitive intelligence, pricing monitoring, or any use case where the most valuable pages are also the most protected, this is a hard limit.
No historical data layer. Exa is live-only. There is no archive product, no historical dataset, no way to compare today’s results against last quarter’s. For anomaly detection, trend analysis, or baseline-grounded agent outputs, this is a structural gap.
Exa’s index is not Google. Exa returns results from its own proprietary neural index, not from Google, Bing, or Yandex. For any use case that requires knowing exactly what a real user sees in Google right now (SEO monitoring, ad intelligence, rank tracking, brand protection), Exa’s index is the wrong data source.
Pricing scales poorly at high volume. At 1 million requests/month, Exa’s standard search costs $7,000+. With full page content, that number climbs to $8,000+. Exa updated its pricing in March 2026, raising standard search from $5/1k to $7/1k and introducing an Agentic tier at $12/1k.
What Is Bright Data?
Bright Data is web data infrastructure. It doesn’t have its own search index, it accesses the actual live web at scale, through a suite of products designed for different data acquisition patterns.
The SERP API scrapes real Google, Bing, Yandex, Baidu, DuckDuckGo, Yahoo, and Naver results in real time, from any of 195 countries, with city-level geo-targeting. It returns what a real user in that location would see, right now, not what any index thinks they should see.
The Discover API is purpose-built for agent workloads that need broader, deeper evidence from the live web rather than a shallow list of SEO-ranked links. It finds live URLs with up to 1,000 results per request, ranked for the agent’s specific intent rather than SEO position, with optional cleaned Markdown content for RAG grounding and verification. Unlike search engines or cached indexes, every Discover request is executed at query time against the live web, making it particularly well-suited for competitive intelligence, risk monitoring, and due diligence workflows.
The Web Unlocker fetches any web page, including those behind Cloudflare, CAPTCHAs, login walls, or JavaScript rendering, and returns clean Markdown content. It routes requests through a network of 400M+ residential IPs in 195 countries, handling detection bypass automatically.
The Datasets layer provides pre-built structured data across 100+ domains. The Web Archive API provides 50PB+ of historical web data going back years, making it the perfect solution for historic grounding.
How Bright Data Approaches Web Data for AI
Bright Data’s architecture is built around a core premise: the ground truth is the actual live web, not any index’s approximation of it. For enterprise AI teams building production systems, this matters when:
- Your agent needs to fetch a competitor’s pricing page, and that page blocks scrapers
- Your agent needs to know what Google actually shows for a keyword, not what a neural index estimates
- Your agent needs to run 10,000 queries in parallel without hitting a rate limit ceiling
- Your agent needs to understand whether today’s results are anomalous compared to six months ago
Bright Data is trusted by 20,000+ customers including Fortune 500 companies and is cited in Gartner’s Competitive Landscape for Web Data Collection Solutions. It holds GDPR, CCPA, SOC 2, SOC 3, and ISO 27701 certifications.
The Key Products: SERP API, Discover API, Web Unlocker, Datasets
| Product | What it does | Pricing |
|---|---|---|
| SERP API | Real-time scraping of 7 search engines, 195 countries, structured JSON/Markdown output | From $1.50/1k results (PAYG); down to $1.00/1k at 2M/mo |
| Discover API | Live URL discovery up to 1,000 results/request, intent-ranked, optional Markdown content | Free (beta) |
| Web Unlocker | Fetches any page behind anti-bot protection, returns clean Markdown | From $1/1k requests |
| Datasets | Pre-built structured data from 100+ domains | From $250/100K records |
| Web Archive API | 50PB+ historical web data | From $0.20/1k HTML pages |
| MCP Server | Connect AI agents directly to Bright Data’s full product suite | Free, 5,000 requests/month |
Pricing Comparison: Bright Data vs. Exa
Exa Pricing (March 2026)
| Product | Price |
|---|---|
| Standard Search (1-10 results) | $7 / 1,000 requests |
| Additional results beyond 10 | +$1 / 1,000 results |
| Agentic / Deep Search | $12 / 1,000 requests |
| Deep Search with Reasoning | $15 / 1,000 requests |
| Contents (full page text) | $1 / 1,000 pages |
| Answer API | $5 / 1,000 answers |
| Free tier | 1,000 requests/month |
| Enterprise | Custom |
Important nuance: Exa’s pricing is additive. If your agent needs 10 results plus full page content, you pay for search ($7) plus contents ($1) per 1,000 requests. The minimum effective cost for agents that need full text inline is $8/1k.
Bright Data Pricing
| Product | Price |
|---|---|
| SERP API (PAYG) | $1.50 / 1,000 results |
| SERP API (380K results/month) | $1.30 / 1,000 results |
| SERP API (900K results/month) | $1.10 / 1,000 results |
| SERP API (2M results/month) | $1.00 / 1,000 results |
| Web Unlocker | From $1 / 1,000 requests |
| Datasets | From $250 / 100K records |
| Web Archive | From $0.20 / 1,000 HTML pages |
| Discover API | Free (beta) |
| MCP Server | Free (5,000 requests/month) |
Cost at Scale: The Numbers Are Stark
| Volume | Exa (standard search only) | Exa (search + content) | Bright Data SERP API |
|---|---|---|---|
| 10,000 requests | $70 | $80 | $15 |
| 100,000 requests | $700 | $800 | $130-150 |
| 1,000,000 requests | $7,000+ | $8,000+ | $1,000-1,500 |
At 1 million requests per month, Bright Data is 5-7x cheaper than Exa on search alone. For a full comparison of SERP and web search API providers at scale, see the best SERP APIs and web search APIs of 2026. For agents that need full page content, the gap widens further: Exa adds $1/1k on top; Bright Data Web Unlocker starts at $1/1k all-in.
Bright Data Has No Concurrent Request Limit
This is not a subtle difference. Exa’s default /search rate limit is 10 QPS, 10 queries per second, 600 per minute. This is confirmed in Exa’s official rate limits documentation.
Bright Data’s SERP API has no limit on concurrent requests. From their own FAQ: “There is no limit to the number of concurrent requests. SERP API is built for scale.”
For single-agent, one-query-at-a-time workloads, this doesn’t matter. For production AI pipelines running dozens or hundreds of parallel research tasks, competitive intelligence systems, multi-agent research frameworks, real-time monitoring stacks, the difference is fundamental. With Exa, you’re engineering around a ceiling from day one.
Bright Data Can Reach Pages That Exa Cannot
Exa crawls the open web. It cannot access:
- Pages behind Cloudflare protection
- Sites with login walls or authentication requirements
- Pages with CAPTCHA enforcement
- JavaScript-heavy sites that serve no content to raw HTTP requests
- Geo-restricted content requiring local IP addresses
This isn’t a criticism, it’s simply outside Exa’s product scope.
Bright Data’s Web Unlocker was built specifically for this problem. It routes requests through 400M+ residential IPs, handles browser fingerprinting, manages CAPTCHA solving, and returns the full rendered page content as clean Markdown. For teams needing to understand the full scope of what anti-bot bypass entails, the guide to bypassing Cloudflare for web scraping covers the relevant techniques in depth. For competitive pricing intelligence, where the most valuable data is often on the most protected pages, this is the critical capability.
Here’s a minimal example of how a production agent would use the Bright Data SERP API vs. Exa for the same task:
# Bright Data SERP API - real Google results, no rate limit ceiling
import requests
response = requests.get(
"https://api.brightdata.com/serp/req",
headers={"Authorization": "Bearer YOUR_API_KEY"},
params={
"q": "competitor pricing enterprise 2026",
"gl": "us",
"num": 10,
"data_format": "markdown" # LLM-ready output
}
)
results = response.json()
# Exa - semantic search, 10 QPS limit
from exa_py import Exa
exa = Exa(api_key="YOUR_EXA_KEY")
results = exa.search_and_contents(
"competitor pricing enterprise 2026",
num_results=10,
text=True
)
# $7/1k (search) + $1/1k (contents) = $8/1k effective costThe functional output is similar for basic queries. The differences emerge when you need to run this in parallel for 1,000 competitors, or when the target page blocks Exa’s crawlers. See this example:
If you want to try it yourself, check out this demo on GitHub.
Exa Has No Historical Data Layer
AI agents that detect pricing changes, policy shifts, or market movements need a baseline to work from. You cannot label something as an anomaly without knowing what normal looks like.
Exa is live-only. There is no archive product, no historical dataset, no time-series capability.
Bright Data’s Web Archive API holds 50PB+ of historical web data, growing daily. Pre-built structured Datasets cover 100+ domains and provide historical baselines for e-commerce, social media, real estate, and more. For longitudinal intelligence work, monitoring how a competitor’s pricing page has changed over 12 months, tracking regulatory filings over time, detecting shifts in public sentiment, Bright Data has the infrastructure and Exa does not.
Use Case Decision Guide
| Use Case | Best Choice | Reason |
|---|---|---|
| RAG prototyping / hackathon | Exa | Fast, free tier, native LangChain, minimal setup |
| Semantic similarity search (“find pages like this URL”) | Exa | Find Similar endpoint has no equivalent in Bright Data |
| People / company enrichment (recruiting agents, sales intel) | Exa | 1B+ indexed profiles, structured company index |
| Competitive pricing intelligence (live page content) | Bright Data | Web Unlocker bypasses anti-bot; Exa cannot reach protected pages |
| Production agent with 1,000+ concurrent queries | Bright Data | No rate limit ceiling; SERP API built for parallel workloads |
| Real Google SERP data (SEO, ad monitoring, rank tracking) | Bright Data | SERP API scrapes actual Google, Exa uses own index |
| Historical baseline / anomaly detection | Bright Data | Web Archive 50PB+, Datasets, time-series capability |
| Pages behind Cloudflare / login walls | Bright Data | Web Unlocker; Exa cannot access protected content |
| Multi-engine search (Google + Bing + Yandex) | Bright Data | SERP API covers 7 major engines across 195 countries |
| Low-latency interactive chat UX | Exa | Exa Instant delivers sub-200ms |
| Cost-sensitive at high volume (100k+ queries/month) | Bright Data | $1-1.50/1k vs. Exa’s $7-15/1k |
When to Choose Exa
Exa is the right tool if:
- You’re building a prototype or doing early-stage research. The 1,000 free monthly requests, native LangChain/LlamaIndex support, and simple SDK onboarding make Exa the lowest-friction way to add web search to an AI agent.
- Your core use case is semantic similarity. “Find me pages like this URL” is unique to Exa. If that’s your primary search pattern, choose Exa.
- You need structured people or company data. Exa’s 1B+ profile index and 70M+ company index are genuinely purpose-built for sales and recruiting intelligence agents.
- Latency is the primary constraint. Sub-200ms via Exa Instant outperforms any live-scraping solution for real-time interactive applications.
- Your query volume is under 50,000-100,000 requests/month and you don’t need real Google data or access to protected pages.
When to Choose Bright Data
Bright Data is the right tool if:
- You’re running at production scale. Unlimited concurrent requests and a 99.9% uptime SLA mean no engineering workarounds for rate limits.
- You need actual Google results. SERP API scrapes real Google (and Bing, Yandex, Baidu, Yahoo, Naver, DuckDuckGo) in real time, in any country, showing what real users see, not what a neural index estimates.
- Your agent needs to reach protected pages. Web Unlocker handles Cloudflare, CAPTCHA walls, login pages, and JavaScript rendering. Exa cannot.
- You need historical data. Web Archive API provides 50PB+ of historical data for baseline grounding and longitudinal analysis.
- Cost at scale is a factor. At 100,000+ requests/month, Bright Data is 5-7x cheaper than Exa.
- You’re building enterprise-grade systems. 20,000+ customers, Fortune 500 adoption, Gartner recognition, and 70+ AI framework integrations mean Bright Data fits into existing enterprise data stacks.
Conclusion: Two Different Tools for Two Different Jobs
Exa and Bright Data are not competing for the same job.
Exa is excellent at what it was designed for: semantic neural search, fast developer onboarding, and specialized indexes for people and companies. If you need to find conceptually similar pages, explore a semantic neighborhood, or search 1 billion LinkedIn profiles, Exa’s architecture is well-suited to those tasks.
Bright Data is built for a different problem set: accessing the ground truth of the live web at production scale, including the parts of the web that block crawlers. The SERP API delivers real Google results at $1.50/1k with no concurrent request ceiling. The Web Unlocker reaches pages that Exa’s crawlers cannot touch. The Web Archive provides the historical baseline that live-only APIs cannot offer.
Here’s the decision framework:
- If your agent needs to find semantically similar pages, search 1B+ profiles, or return answers in under 200ms, Exa is designed for that.
- If your agent needs production scale, real Google data, anti-bot access, historical baselines, or cost efficiency above 100,000 queries/month, Bright Data is the right infrastructure.
Many production AI teams use both: Exa for semantic discovery in the early stages of a pipeline, and Bright Data for live verification, full-page extraction, and SERP intelligence at scale. They’re not mutually exclusive. They just have different ceilings, and at enterprise scale, Exa’s ceiling shows up quickly. For teams evaluating the full range of top MCP servers for AI workflows, Bright Data’s MCP Server consistently ranks as the leading option for grounding agents in real-time web data.
Frequently Asked Questions
What is the difference between Bright Data and Exa?
Exa is a semantic search engine API, it returns results from its own neural index. Bright Data is web data infrastructure, it scrapes real search engines, extracts pages behind anti-bot protection, and provides historical datasets. They solve different problems at different scales.
Is Bright Data cheaper than Exa?
Yes. Bright Data’s SERP API starts at $1.50 per 1,000 requests on a pay-as-you-go basis. Exa’s standard search costs $7 per 1,000 requests. At 1 million requests per month, Bright Data is roughly 5-7x cheaper.
Can Exa crawl websites behind Cloudflare?
No. Exa cannot crawl pages protected by Cloudflare, login walls, or CAPTCHA systems. Bright Data’s Web Unlocker is specifically built to bypass anti-bot protection, using a network of 400M+ residential IPs.
Does Exa have a rate limit?
Yes. Exa’s default /search rate limit is 10 QPS (600 requests per minute). Enterprise customers can negotiate higher limits. Bright Data’s SERP API has no concurrent request limit.
What is the best Exa alternative for enterprise AI agents?
Bright Data is the leading enterprise Exa alternative. It offers unlimited concurrent requests, real-time scraping of Google/Bing/Yandex, anti-bot bypass via Web Unlocker, historical data archives, and support for MCP-based AI agent workflows, all with pay-per-success pricing.
Does Exa have historical data?
No. Exa is live-only with no archive or dataset products. Bright Data’s Web Archive API holds 50PB+ of historical web data, growing daily.

Web Data & AI Expert
Daniel Shashko is a Senior SEO/GEO at Bright Data, specializing in B2B marketing, international SEO, and building AI-powered agents, apps, and web tools.




