

In this article, we’ll cover:
- What the Playwright MCP server is and how it can be used for web scraping
- The different tools available in the Playwright MCP server
- How the Bright Data Web MCP server can provide a simpler alternative for web scraping.
Let’s dive in!
The Playwright MCP server
Playwright is widely known as a browser automation tool, often used for testing and automating browser tasks. The Playwright MCP Server builds on this functionality, only this time it is designed not for direct human use but for AI agents.
By running the server, you can connect any MCP host and grant AI agents access to Playwright’s full automation toolkit.
This means your AI agent can interact with a web browser just like a human would, performing actions such as making online purchases, fetching the latest news, replying to emails, and more.
In this article, our main focus will be on web scraping. With Playwright MCP Server, you get the low-level tools required not only for browser automation but also for enabling an LLM to scrape and extract data directly from the web.
The Playwright MCP server
Like every MCP server, the Playwright MCP server comes with a set of tools that can be exposed to an AI agent. These tools map directly to the Playwright APIs that developers already know and use. Let’s look at some of the most important ones:
- Browser_click: Allows the AI agent to click on elements, just like a human using a mouse.
- Browser_drag: Enables drag-and-drop interactions.
- Browser_close: Closes the browser instance.
- Browser_evaluate: Lets the AI agent execute JavaScript code directly in the page.
- Browser_file_upload: Handles file uploads through the browser.
- Browser_fill_form: Fills out forms on a webpage.
- Browser_hover: Moves the mouse pointer over elements.
- Browser_navigate: Navigates to any URL.
- Browser_press_key: Simulates key presses, giving the agent full access to keyboard input.
With all of these tools at the AI agent’s disposal, it can easily maneuver through the web and scrape data. Let’s see how we can do that.
Web Scraping with the Playwright MCP server
In this section, we’ll perform a web scraping task using the Playwright MCP server. Our AI agent will collect the latest pricing information for iPhone 16 models. To keep things simple, we’ll limit the task to a single source: Best Buy.
Configuring the Server
To run the Playwright MCP server, we need an MCP host. You can use any host of your choice such as Claude Desktop, Cursor, or Gemini CLI. For this article, we’ll be using VS Code.
The Playwright MCP server is a local MCP server implemented in Node.js, so before you proceed, make sure you have Node installed.
To set up the server, we need to add the following configuration to our MCP host:
{
"servers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}This configuration applies to how MCP servers are set up in VS Code, though it may differ slightly in other MCP hosts. Once the setup is complete, our AI agent will have access to the tools provided by the server. With that in place, we can begin scraping.
Scraping with the MCP Server
The first step is to navigate to the BestBuy website. To do this, we simply instruct the AI agent to open the site, and it will use the Browser_navigate tool to get there.
Next, we’ll instruct the AI agent to search for iPhone 16. To accomplish this, it will use the Browser_press_key tool to enter the search query.
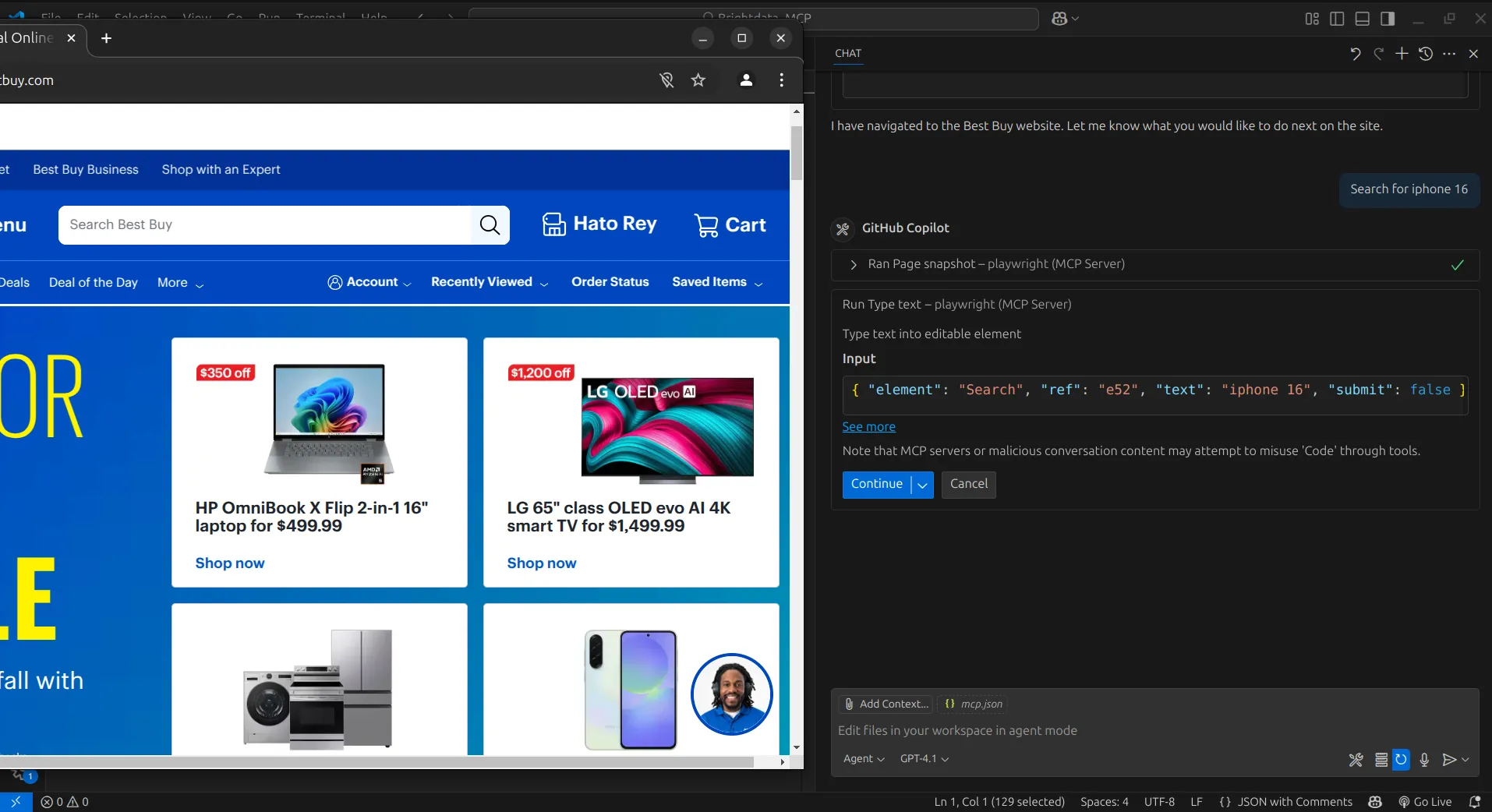
Then, the AI agent will use the Browser_click tool to click on the search button.
With this, we get our results. At each step as the agent navigates the page, it captures a snapshot of the current state. We can then use these snapshots to instruct the agent to extract the information we need and organize it into a structured format.
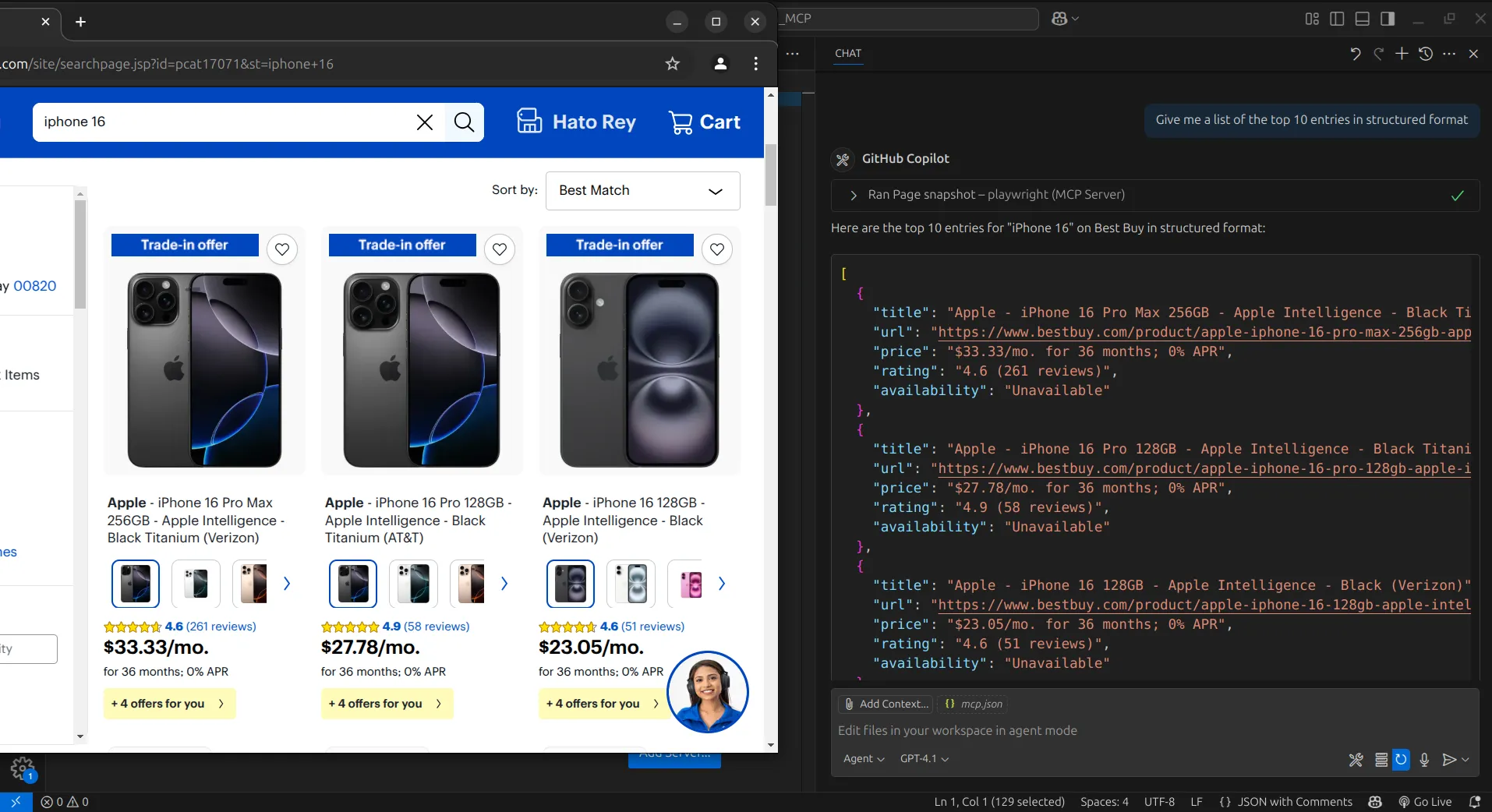
With this approach, we’ve successfully scraped the site. However, while it gives us full control to do almost anything we want, it is still quite low-level. This can feel excessive if our only goal is to scrape data, since we may not need the broader web automation capabilities.
Next, let’s explore how the Bright Data Web MCP server can achieve the same task from a much higher-level perspective.
Bright Data Web MCP Server: A high level Web Scraping MCP server
The Bright Web Data MCP server comes with a range of high-level tools built specifically for web scraping. These include tools for extracting data from platforms like Amazon, retrieving individual and company profiles, and even collecting Instagram profiles, posts, and reels.
Unlike Playwright MCP, which operates at a lower level, the Bright Data Web MCP server simplifies the scraping process for your AI agent. It even handles web pages protected by bot detection or CAPTCHA, giving your agent reliable access where traditional methods might fail.
For this walkthrough, we’ll use the Bright Data Web MCP server to perform the same task we tackled earlier with Playwright MCP. Out of the box, it provides two core tools:
- Search engine tool
- Scrape data as markdown tool
Additional tools can be unlocked by enabling Pro Mode, but for now, we’ll stick with these two. You can find more details in this article.
Configuring the Server
Unlike the Playwright MCP server, which runs locally, the Bright Data Web MCP server is a remote MCP server. This means the configuration process is slightly different. Here’s how you can set it up in VS Code:
"BrightData": {
"url": "https://mcp.brightdata.com/mcp?token=YOUR_API_KEY",
}To connect, you’ll need your Bright Data API key. Once configured, your agent is ready to begin scraping.
Scraping with the MCP Server
First, we’ll instruct the agent to perform a web search for the price of the iPhone 16.
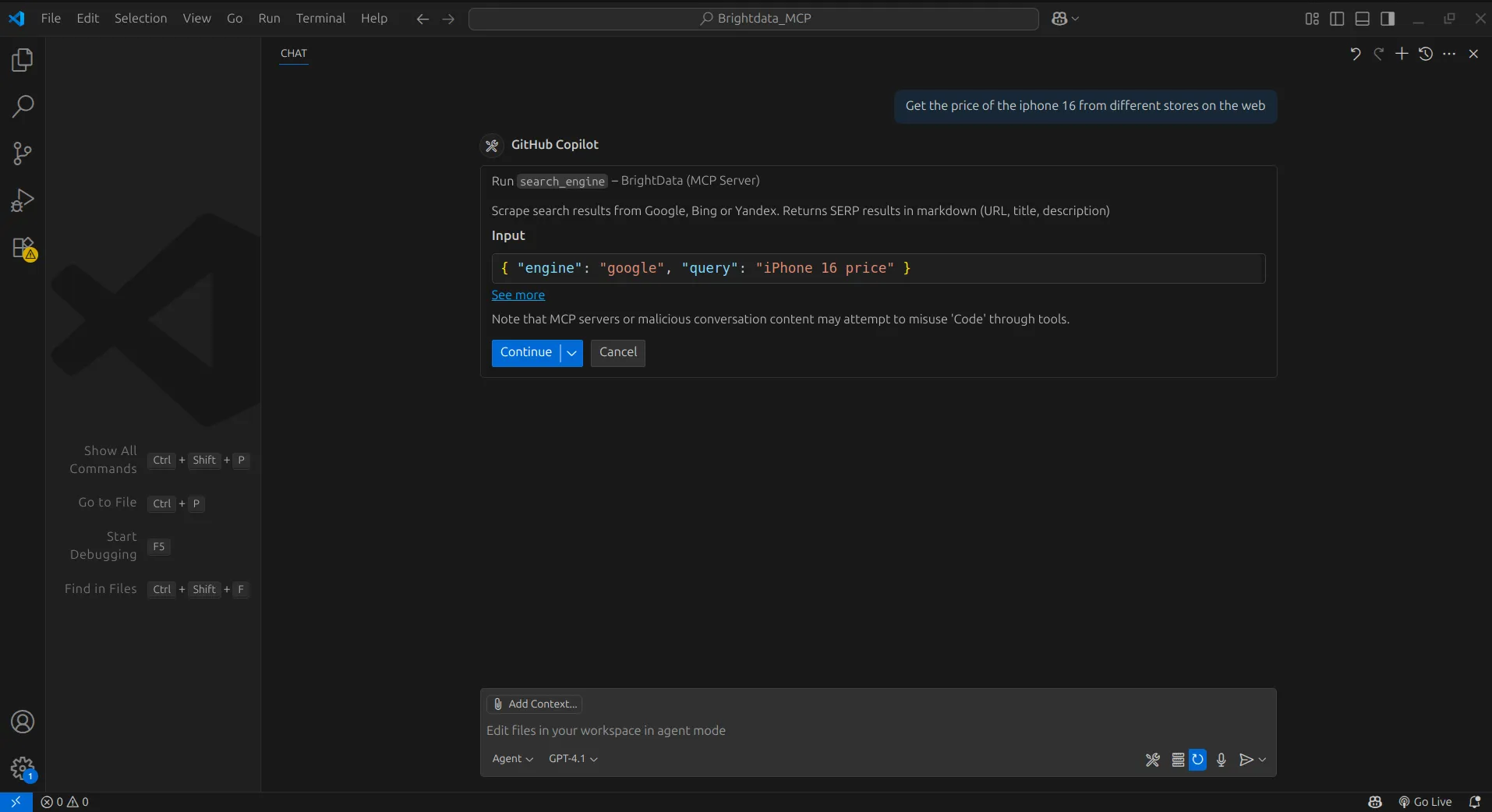
The agent then used the server’s search engine tool to carry out the request.
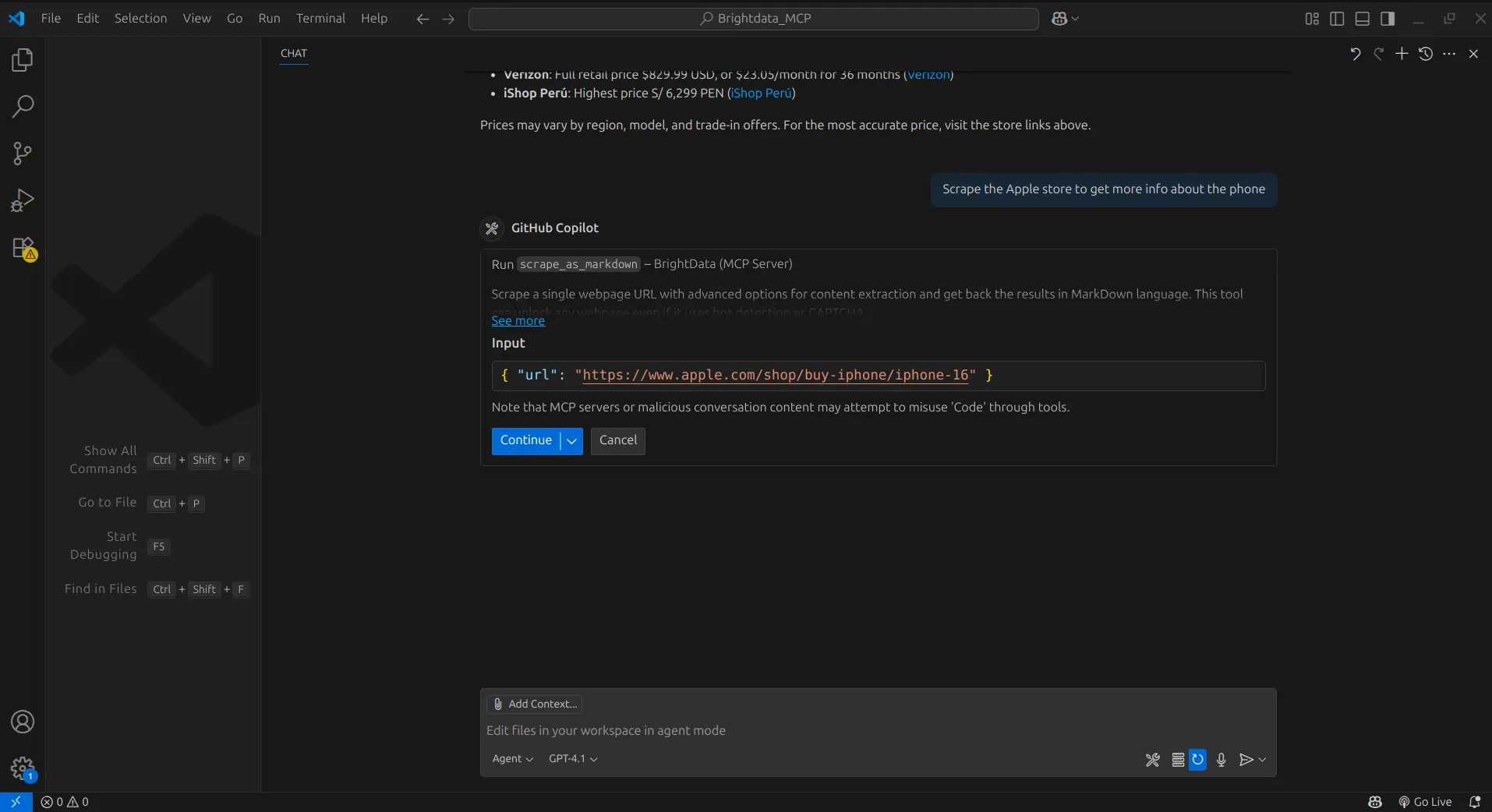
After getting the results, we instruct the agent to extract information from a site of our choice, in this case the Apple Store. The agent then uses the scrape data as markdown tool to pull the content, returning it in Markdown format, which the agent can easily process and understand.
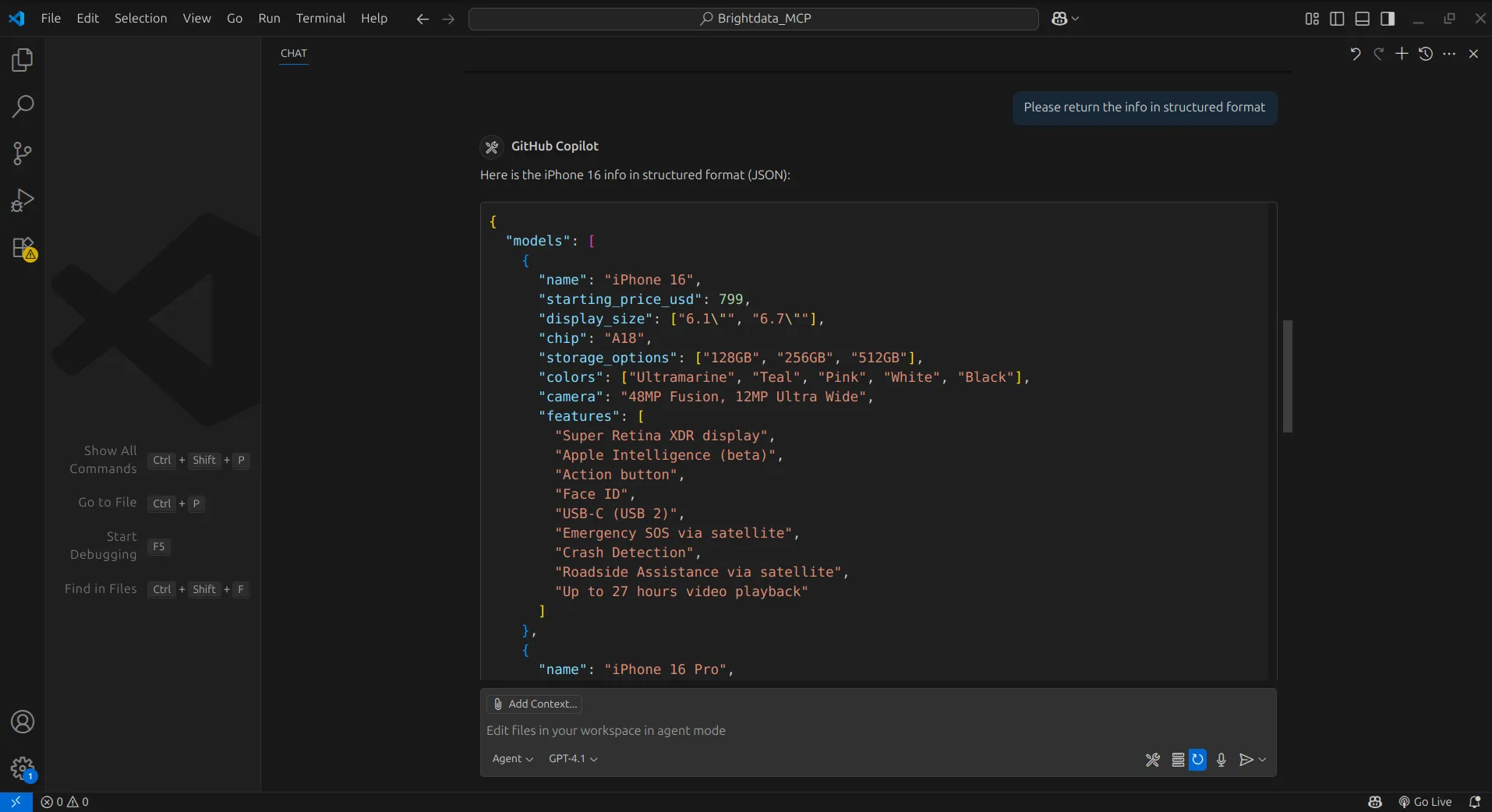
With the extracted information, we can instruct the agent to organize it into a structured format, and just like that, we have our data.
In this example, we used only two tools to complete the scraping task. However, the Bright Data Web MCP server also offers additional tools in Pro Mode that you can explore for more advanced use cases. You can find further examples in this detailed article.
Conclusion
In this article, we explored how MCP servers can be used to scrape the web with the help of AI agents. We first looked at the Playwright MCP server, which provides low-level access to browser automation, giving your agent full control over every interaction. We then explored the Bright Data’s Web MCP server, which operates at a higher level and equips your agent with specialized tools designed specifically for web scraping, even on sites protected by bot detection.
Both approaches have their strengths, Playwright is ideal when you need fine-grained browser control, while Bright Data simplifies the process, allowing you to focus purely on extracting the information you need.
Now it’s your turn to experiment with both MCP servers and decide which one best fits your next project.

Technical Writer
Amitesh Anand is a developer advocate and technical writer sharing content on AI, software, and devtools, with 10k followers and 400k+ views.





