

In this tutorial, you will learn:
- How an AI-powered LinkedIn Job Hunting assistant could work.
- How to build it by integrating LinkedIn jobs data from Bright Data with an OpenAI-powered workflow.
- How to improve and extend this workflow into a robust job search assistant.
You can view the final project files here.
Let’s dive in!
LinkedIn Job Hunting AI Assistant Workflow Explained
First of all, you cannot build a LinkedIn job hunting AI assistant without access to LinkedIn job listings data. This is where Bright Data comes into play!
Thanks to the LinkedIn Jobs Scraper, you can retrieve public job listings data from LinkedIn via web scraping. The experience you get is just like searching on the LinkedIn Jobs portal. But instead of a web page, you receive the structured job data directly in JSON or CSV format.
Given that data, you can then ask an AI to score each job based on your skills and the desired position you are seeking. At a high level, that is what the LinkedIn Job AI Assistant does for you.
Technical Steps
The steps required to implement the LinkedIn job AI workflow are:
- Load the CLI arguments: Parse command-line arguments to get runtime parameters. This allows flexible execution and easy customization without changing the code.
- Load the environment variables: Load OpenAI and Bright Data API keys from environment variables. These are required to connect to the third-party integrations powering this AI workflow.
- Load the configuration file: Read a JSON configuration file containing job search parameters, candidate profile details, and desired job description. That config information guides job retrieval and AI scoring.
- Scrape the jobs from LinkedIn: Fetch job listings filtered according to the configuration from the LinkedIn Jobs Scraper API.
- Score the jobs via AI: Send each batch of job postings to OpenAI. The AI scores them from
0to100based on your profile and desired job. It also adds a short comment explaining each score to help you understand the match quality. - Expand the jobs with AI scores and comments: ****Merge the AI-generated scores and comments back into the original job postings, enriching each job record with these new AI-generated fields.
- Export the scored jobs data: Export the enriched job data to a CSV file for further analysis and processing.
- Print the top job matches: Display the top job matches directly in the console with main details, providing immediate insight into the most relevant opportunities.
See how to implement this AI workflow in Python!
How to Use OpenAI and Bright Data to Build a LinkedIn Job Hunting AI Workflow
In this tutorial, you will learn how to build an AI workflow to help you find jobs on LinkedIn. The LinkedIn job data will be sourced from Bright Data, while the AI capabilities will be provided by OpenAI. Note that you can use any other LLM as well.
By the end of this section, you will have a complete Python AI workflow that you can run from the command line. It will identify the best LinkedIn job positions, saving you time and effort in the grueling and energy-draining task of job seeking.
Let’s build a LinkedIn job hunting AI assistant!
Prerequisites
To follow this tutorial, make sure you have the following:
- Python 3.8 or higher installed locally (we recommend using the latest version).
- A Bright Data API key.
- An OpenAI API key.
If you do not have a Bright Data API key yet, create a Bright Data account and follow the official setup guide. Similarly, follow the official OpenAI instructions to obtain your OpenAI API key.
Step #0: Set Up Your Python Project
Open a terminal and create a new directory for your LinkedIn job hunting AI assistant:
mkdir linkedin-job-hunting-ai-assistant/The linkedin-job-hunting-ai-assistant folder will hold all the Python code for your AI workflow.
Next, navigate into the project directory and initialize a virtual environment inside it:
cd linkedin-job-hunting-ai-assistant/
python -m venv venvNow, open the project in your favorite Python IDE.. We recommend Visual Studio Code with the Python extension or PyCharm Community Edition.
Inside the project folder, create a new file named assistant.py. Your directory structure should look like this:
linkedin-job-hunting-ai-assistant/
├── venv/
└── assistant.pyActivate the virtual environment in your terminal. In Linux or macOS, execute:
source venv/bin/activateEquivalently, on Windows, launch this command:
venv/Scripts/activateIn the next steps, you will be guided through installing the required Python packages. If you prefer to install all of them now, in the activated virtual environment, run:
pip install python-dotenv requests openai pydanticIn particular, the required libraries are:
python-dotenv: Loads environment variables from a.envfile, making it easy to manage API keys securely.pydantic: Helps validate and parse the configuration file into structured Python objects.requests: Handles HTTP requests to call APIs like Bright Data and retrieve data.openai: Provides the OpenAI client to interact with OpenAI’s language models for AI job scoring.
Note: We are installing the openai library here because this tutorial relies on OpenAI as the language model provider. If you plan to use a different LLM provider, make sure to install the corresponding SDK or dependencies.
You are all set! Your Python development environment is now ready to build an AI workflow using OpenAI and Bright Data.
Step #1: Load the CLI Arguments
The LinkedIn job hunting AI script requires a few arguments. To keep it reusable and customizable without changing the code, you should read them via the CLI.
In detail, you will need the following CLI arguments:
--config_file: The path to the JSON config file containing your job search parameters, candidate profile details, and desired job description. Default isconfig.json.--batch_size: The number of jobs to send to the AI for scoring at a time. Default is5.--jobs_number: The maximum number of job entries the Bright Data LinkedIn Jobs Scraper should return. Default is20.--output_csv: The name of the output CSV file containing the enriched job data with AI scores and comments. Default isjobs_scored.csv.
Read these arguments from the command line interface using the following function:
def parse_cli_args():
# Parse command-line arguments for config and runtime options
parser = argparse.ArgumentParser(description="LinkedIn Job Hunting Assistant")
parser.add_argument("--config_file", type=str, default="config.json", help="Path to config JSON file")
parser.add_argument("--jobs_number", type=int, default=20, help="Limit the number of jobs returned by Bright Data Scraper API")
parser.add_argument("--batch_size", type=int, default=5, help="Number of jobs to score in each batch")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="Output CSV filename")
return parser.parse_args()Do not forget to import argparse from the Python Standard Library:
import argparseGreat! You now have access to arguments from the CLI.
Step #2: Load the Environment Variables
Configure your script to read secrets from environment variables. To simplify loading environment variables, use the python-dotenv package. With your virtual environment activated, install it by running:
pip install python-dotenvNext, in your assistant.py file, import the library and call load_dotenv() to load your environment variables:
from dotenv import load_dotenv
load_dotenv()Your assistant can now read variables from a local .env file. Thus, add a .env file to the root of your project directory:
linkedin-job-hunting-ai-assistant/
├── venv/
├── .env # <-----------
└── assistant.pyOpen the .env file and add the OPENAI_API_KEY and BRIGHT_DATA_API_KEY envs to it:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Replace the <YOUR_OPENAI_API_KEY> placeholder with your actual OpenAI API key. Similarly, replace the <YOUR_BRIGHT_DATA_API_KEY> placeholder with your Bright Data API key.
Then, add this function to your script to load those two environment variables:
def load_env_vars():
# Read required API keys from environment and verify presence
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
if not openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")
if missing:
raise EnvironmentError(
f"Missing required environment variables: {', '.join(missing)}\n"
"Please set them in your .env or environment."
)
return openai_api_key, brightdata_api_keyAdd the required import from the Python Standard Library:
import osWonderful! You have now securely loaded third-party integration secrets using environment variables.
Step #3: Load the Configuration File
Now, you need a programmatic way to tell your assistant which jobs you are interested in. For its results to be accurate, the assistant must also know your work experience and what kind of job you are seeking.
To avoid hardcoding that information directly into your code, it makes sense to read it from a JSON configuration file. Specifically, this file should contain:
location: The geographic location where you want to search for jobs. This defines the main area where job listings will be collected.keyword: Specific words or phrases related to the job title or role you are looking for, such as “Python Developer”. Use quotation marks to enforce exact matches.country: A two-letter country code (e.g.,USfor the United States,FRfor France) to narrow the job search to a specific country.time_range: The timeframe within which job postings were made, to filter for recent or relevant openings (e.g.,Past week,Past month, etc.).job_type: The employment type to filter by, such asFull-time,Part-time, etc.experience_level: The required level of professional experience, such asEntry level,Associate, etc.remote: Filter jobs based on work location mode (e.g.,Remote,On-site, orHybrid).company: Focus the search on job openings from a specific company or employer.selective_search: When enabled, excludes job listings whose titles do not contain the specified keywords to produce more targeted results.jobs_to_not_include: A list of specific job IDs to exclude from search results, useful for removing duplicates or unwanted postings.location_radius: Defines how far around the specified location the search should extend, including nearby areas.profile_summary: A summary of your professional profile. This information is used by the AI to assess how well each job matches you.desired_job_summary: A brief description of the kind of job you are seeking, helping the AI score job listings based on fit.
These correspond exactly to the arguments required by the Bright Data LinkedIn job listings “discover by keyword” API (which is part of their LinkedIn Jobs Scraper solution):
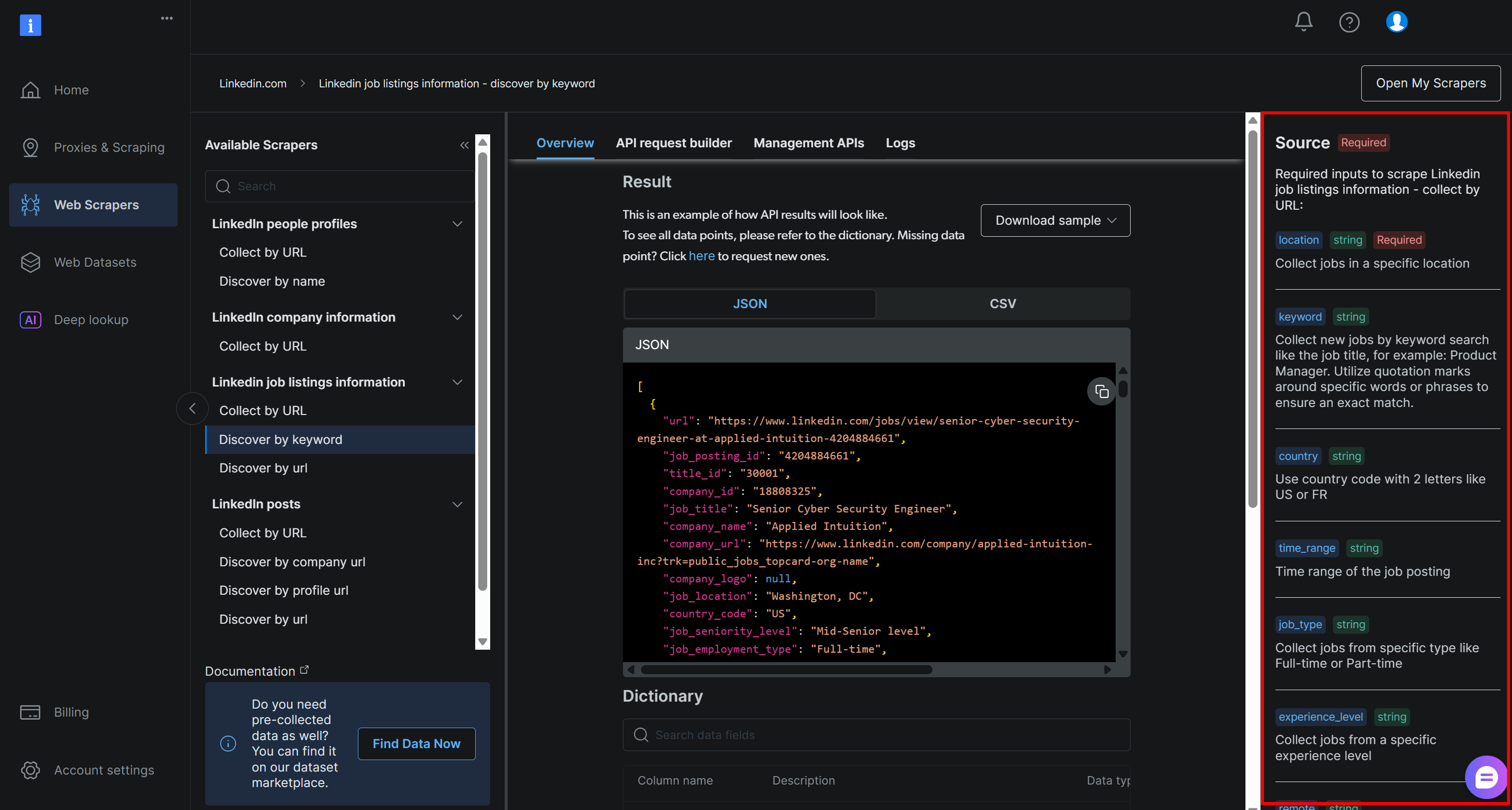
For more information on these fields and which values they can assume, refer to the official docs.
The last two fields (profile_summary and desired_job_summary) describe who you are professionally and what you are looking for. These will be passed to the AI to score each job posting returned by Bright Data.
To make it easier to handle the config file in the code, it is a good idea to map it to a Pydantic model. First, install Pydantic in your virtual environment:
pip install pydanticThen, define the Pydantic model mapping the JSON config file as below:
class JobSearchConfig(BaseModel):
location: str
keyword: Optional[str] = None
country: Optional[str] = None
time_range: Optional[str] = None
job_type: Optional[str] = None
experience_level: Optional[str] = None
remote: Optional[str] = None
company: Optional[str] = None
selective_search: Optional[bool] = Field(default=False)
jobs_to_not_include: Optional[List[str]] = Field(default_factory=list)
location_radius: Optional[str] = None
# Additional fields
profile_summary: str # Candidate's profile summary for AI scoring
desired_job_summary: str # Description of the desired job for AI scoringNote how only the first and last two config fields are required.
Next, create a function to read the JSON configs from the --config_file file path. Deserialize it into a JobSearchConfig instance:
def load_and_validate_config(filename: str) -> JobSearchConfig:
# Load JSON config file
try:
with open(filename, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f"Config file '{filename}' not found.")
try:
# Deserialize the input JSON data to a JobSearchConfig instance
config = JobSearchConfig(**data)
except ValidationError as e:
raise ValueError(f"Config deserialization error:\n{e}")
return configThis time, you will need these imports:
from pydantic import BaseModel, Field, ValidationError
from typing import Optional, List
import jsonAwesome! Now your config file is properly read and deserialized as intended.
Step #4: Scrape the jobs from LinkedIn
It is time to use the configuration you loaded earlier to call the Bright Data LinkedIn Jobs Scraper API.
If you are not familiar with how Bright Data’s Web Scraper APIs work, it is worth checking the documentation first.
In short, Web Scraper APIs provide API endpoints that let you retrieve public data from specific domains. Behind the scenes, Bright Data initializes and runs a ready-made scraping task on its servers. These APIs handle IP rotation, CAPTCHA, and other measures to effectively and ethically collect public data from web pages. Once the task completes, the scraped data is parsed into a structured format and made available to you as a snapshot.
Thus, the general workflow is:
- Trigger the API call to start a web scraping task.
- Periodically check if the snapshot containing the scraped data is ready.
- Retrieve the data from the snapshot once it is available.
You can implement the above logic with just a few lines of code:
def trigger_and_poll_linkedin_jobs(config: JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Trigger the Bright Data LinkedIn job search
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization": f"Bearer {brightdata_api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l", # Bright Data "Linkedin job listings information - discover by keyword" dataset ID
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": str(jobs_number),
}
# Prepare payload for Bright Data API based on user config
data = [{
"location": config.location,
"keyword": config.keyword or "",
"country": config.country or "",
"time_range": config.time_range or "",
"job_type": config.job_type or "",
"experience_level": config.experience_level or "",
"remote": config.remote or "",
"company": config.company or "",
"selective_search": config.selective_search,
"jobs_to_not_include": config.jobs_to_not_include or "",
"location_radius": config.location_radius or "",
}]
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code != 200:
raise RuntimeError(f"Trigger request failed: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("No snapshot_id returned from Bright Data trigger.")
print(f"LinkedIn job search triggered! Snapshot ID: {snapshot_id}")
# Poll snapshot endpoint until data is ready or timeout
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f"Bearer {brightdata_api_key}"}
print(f"Polling snapshot for ID: {snapshot_id}")
while True:
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# Snapshot ready: return job postings JSON data
print("Snapshot is ready")
return snap_resp.json()
elif snap_resp.status_code == 202:
# Snapshot not ready yet: wait and retry
print(f"Snapshot not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
raise RuntimeError(f"Snapshot polling failed: {snap_resp.status_code} - {snap_resp.text}")This function triggers Bright Data’s LinkedIn Jobs Scraper using search parameters from the config file, ensuring you only get listings that match your criteria. It then polls until the data snapshot is ready, and once available, returns the job listings in JSON format. Note that authentication is handled using the Bright Data API key loaded earlier from your environment variables.
The snapshot retrieved with the LinkedIn Jobs Scraper will contain job listings in JSON format like this:
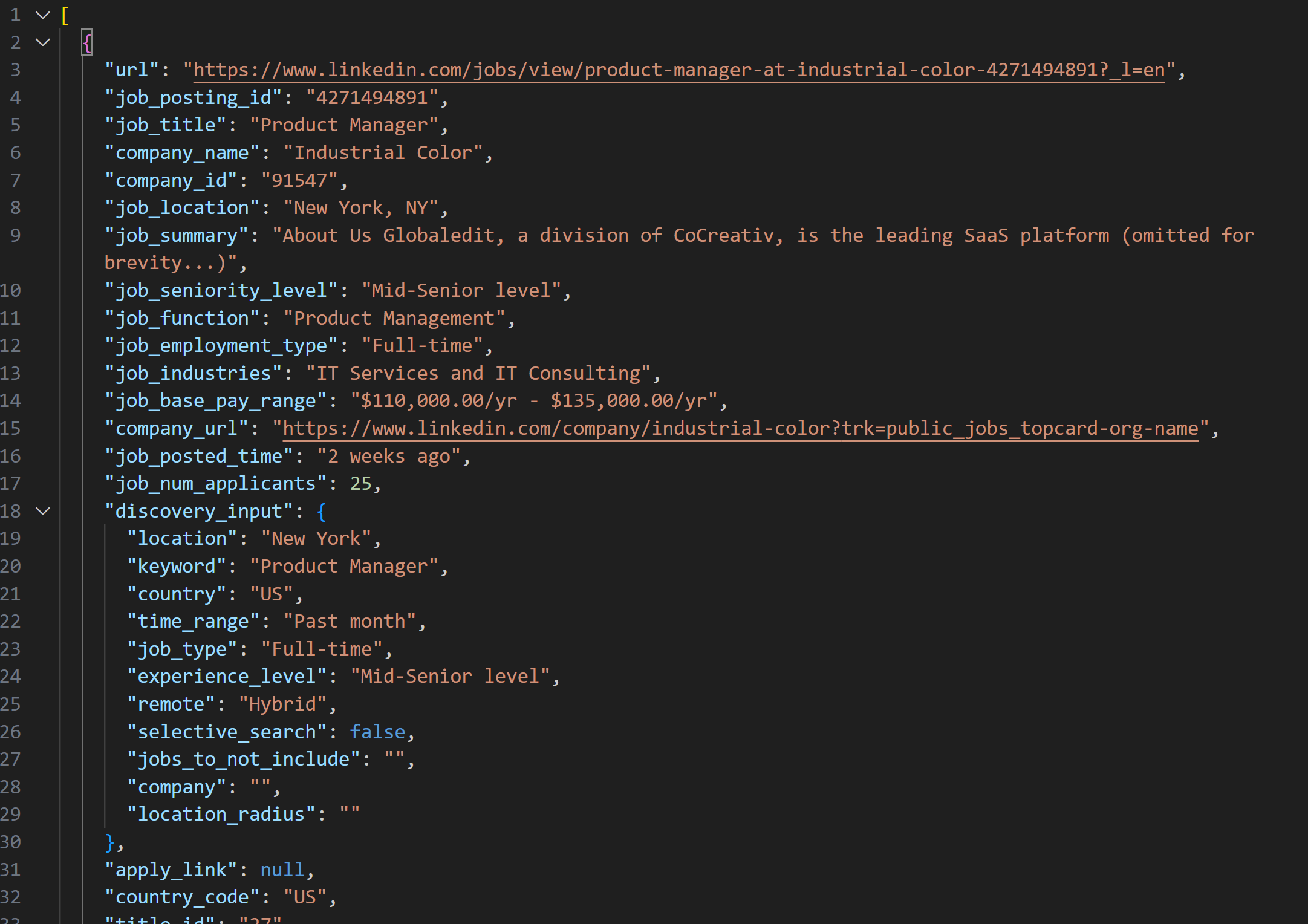
Note: The produced JSON snapshot contains exactly up to --jobs_number jobs. In this case, it contains 20 jobs.
To make the above function work, you need to install requests:
pip install requestsFor more information on how it works, refer to our advanced guide on Python HTTP Requests.
Next, do not forget to import it together with time from the Python Standard Library:
import requests
import timeTerrific! You just integrated with Bright Data to gather fresh, specific LinkedIn job listings data.
Step #5: Score the Jobs via AI
Now, it is time to ask an LLM (such as OpenAI’s models) to evaluate each scraped job posting.
The goal is to assign a score from 0 to 100 along with a short comment, based on how well the job matches:
- Your work experience (
profile_summary) - Your desired position (
desired_job_summary)
To reduce API round-trips and speed things up, it makes sense to process jobs in batches. In particular, you will evaluate a number --batch_size of jobs at a time.
Start by installing the openai package:
pip install openaiThen, import OpenAI and initialize the client:
from openai import OpenAI
# ...
# Initialize OpenAI client
client = OpenAI()Note that you do not need to manually pass your API key to the OpenAI constructor. The library automatically reads it from the OPENAI_API_KEY environment variable, which you have already set.
Proceed by creating the AI-powered job scoring function:
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# Construct prompt for AI to score job matches based on candidate profile
prompt = f"""
"You are an expert recruiter. Given the following candidate profile:\n"
"{profile_summary}\n\n"
"Desired job description:\n{desired_job_summary}\n\n"
"Score each job posting accurately from 0 to 100 on how well it matches the profile and desired job.\n"
"For each job, add a short comment (max 50 words) explaining the score and match quality.\n"
"Return an array of objects with keys 'job_posting_id', 'score', and 'comment'.\n\n"
"Jobs:\n{json.dumps(jobs_batch)}\n"
"""
messages = [
{"role": "system", "content": "You are a helpful job scoring assistant."},
{"role": "user", "content": prompt},
]
# Use OpenAI API to parse structured response into JobScoresResponse model
response = client.responses.parse(
model="gpt-5-mini",
input=messages,
text_format=JobScoresResponse,
)
# Return list of scored jobs
return response.output_parsed.scoresThis uses the new gpt-5-mini model to have OpenAI score each scraped job posting from 0 to 100, along with a short explanatory comment.
To make sure that the response is always returned in the exact format you need, the parse() method is called. That method enforces a structured output model, defined here with the following Pydantic models:
class JobScore(BaseModel):
job_posting_id: str
score: int = Field(..., ge=0, le=100)
comment: str
class JobScoresResponse(BaseModel):
scores: List[JobScore]Basically, the AI will return structured JSON data as below:
{
"scores": [
{
"job_posting_id": "4271494891",
"score": 80,
"comment": "Strong SaaS product fit with end-to-end ownership, APIs, and cross-functional work—aligns with your startup PM and customer-first experience. Role targets 2–4 yrs, so it's slightly junior for your 7 years."
},
// omitted for brevity...
{
"job_posting_id": "4273328527",
"score": 65,
"comment": "Product role with heavy data/technical emphasis; agile and cross-functional responsibilities align, but it prefers quantitative/technical domain experience (finance/stat modeling) which may be a weaker fit."
}
]
}The parse() method will then convert the JSON response into a JobScoresResponse instance. Then, you will be able to programmatically access both the scores and comments in your code.
Note: If you prefer to use a different LLM provider, be sure to adjust the code above to work with your chosen provider accordingly.
Here we go! AI job evaluation is complete.
Step #6: Expand the Jobs with AI Acores and Comments
Take a look at the raw JSON output returned by the AI shown earlier. You can see that each job score contains a job_posting_id field. This corresponds to the ID LinkedIn uses to identify job listings.
Since those IDs also appear in the snapshot data produced by the Bright Data LinkedIn Jobs Scraper, you can use them to:
- Find the original job posting objects from the array of scraped jobs.
- Enrich that job posting object by adding the AI-generated score and comment.
Achieve that with the following function:
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# Where to store the enriched data
extended_jobs = []
# Combine original jobs with AI scores and comments
for score_obj in all_scores:
matched_job = None
for job in jobs:
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
break
if matched_job:
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = score_obj.comment
extended_jobs.append(job_with_score)
# Sort extended jobs by AI score (highest first)
extended_jobs.sort(key=lambda j: j["ai_score"], reverse=True)
return extended_jobsAs you can tell, a couple of for loops are enough to tackle the task. Before returning the enriched data, sort the list in descending order by ai_score. That way, the best-matching jobs appear at the top—making them quick and easy to spot.
Cool! Your LinkedIn job-hunting AI assistant is now almost ready to roll!
Step #7: Export the Scored Jobs Data
Use Python’s built-in csv package to export the scraped and enriched job data into a CSV file.
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# Dynamically get the field names from the first element in the array
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# Write extended job data with AI scores to CSV
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in extended_jobs:
writer.writerow(job)
print(f"Exported {len(extended_jobs)} jobs to {output_csv}") The above function will be called by replacing output_csv with the --output_csv CLI argument.
Do not forget to import csv:
import csvPerfect! The LinkedIn job hunting AI assistant now exports the AI-enriched data to an output CSV file.
Step #8: Print the Top Job Matches
To get immediate feedback in the terminal without opening the output CSV file, write a function to print key details from the top 3 job matches:
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"\n*** Top {top} job matches ***")
for job in extended_jobs[:3]:
print(f"URL: {job.get('url', 'N/A')}")
print(f"Title: {job.get('job_title', 'N/A')}")
print(f"AI Score: {job.get('ai_score')}")
print(f"AI Comment: {job.get('ai_comment', 'N/A')}")
print("-" * 40)Step #9: Put It All Together
Combine all the functions from the previous steps into the main LinkedIn job hunting assistant logic:
# Get runtime parameters from CLI
args = parse_cli_args()
try:
# Load API keys from environment
_, brightdata_api_key = load_env_vars()
# Load job search config file
config = load_and_validate_config(args.config_file)
# Fetch jobs
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} jobs found!")
except Exception as e:
print(f"[Error] {e}")
return
all_scores = []
# Process jobs in batches to avoid overloading API and to handle large datasets
for i in range(0, len(jobs_data), args.batch_size):
batch = jobs_data[i : i + args.batch_size]
print(f"Scoring batch {i // args.batch_size + 1} with {len(batch)} jobs...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # To avoid triggering API rate limits
# Merge scores into scraped jobs
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# Save results to CSV
export_extended_jobs(extended_jobs, args.output_csv)
# Print top job matches with key info for quick review
print_top_jobs(extended_jobs)Incredible! It only remains to review the complete code of the assistant and verify it works as expected.
Step #10: Complete Code and First Run
Your final assistant.py file should contain:
# pip install python-dotenv requests openai pydantic
import argparse
from dotenv import load_dotenv
import os
from pydantic import BaseModel, Field, ValidationError
from typing import Optional, List
import json
import requests
import time
from openai import OpenAI
import csv
# Load environment variables from .env file
load_dotenv()
# Pydantic models supporting the project
class JobSearchConfig(BaseModel):
# Source: https://docs.brightdata.com/api-reference/web-scraper-api/social-media-apis/linkedin#discover-by-keyword
location: str
keyword: Optional[str] = None
country: Optional[str] = None
time_range: Optional[str] = None
job_type: Optional[str] = None
experience_level: Optional[str] = None
remote: Optional[str] = None
company: Optional[str] = None
selective_search: Optional[bool] = Field(default=False)
jobs_to_not_include: Optional[List[str]] = Field(default_factory=list)
location_radius: Optional[str] = None
# Additional fields
profile_summary: str # Candidate's profile summary for AI scoring
desired_job_summary: str # Description of the desired job for AI scoring
class JobScore(BaseModel):
job_posting_id: str
score: int = Field(..., ge=0, le=100)
comment: str
class JobScoresResponse(BaseModel):
scores: List[JobScore]
def parse_cli_args():
# Parse command-line arguments for config and runtime options
parser = argparse.ArgumentParser(description="LinkedIn Job Hunting Assistant")
parser.add_argument("--config_file", type=str, default="config.json", help="Path to config JSON file")
parser.add_argument("--jobs_number", type=int, default=20, help="Limit the number of jobs returned by Bright Data Scraper API")
parser.add_argument("--batch_size", type=int, default=5, help="Number of jobs to score in each batch")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="Output CSV filename")
return parser.parse_args()
def load_env_vars():
# Read required API keys from environment and verify presence
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
if not openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")
if missing:
raise EnvironmentError(
f"Missing required environment variables: {', '.join(missing)}\n"
"Please set them in your .env or environment."
)
return openai_api_key, brightdata_api_key
def load_and_validate_config(filename: str) -> JobSearchConfig:
# Load JSON config file
try:
with open(filename, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f"Config file '{filename}' not found.")
try:
# Deserielizing the input JSON data to a JobSearchConfig instance
config = JobSearchConfig(**data)
except ValidationError as e:
raise ValueError(f"Config deserialization error:\n{e}")
return config
def trigger_and_poll_linkedin_jobs(config: JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Trigger the Bright Data LinkedIn job search
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization": f"Bearer {brightdata_api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l", # Bright Data "Linkedin job listings information - discover by keyword" dataset ID
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": str(jobs_number),
}
# Prepare payload for Bright Data API based on user config
data = [{
"location": config.location,
"keyword": config.keyword or "",
"country": config.country or "",
"time_range": config.time_range or "",
"job_type": config.job_type or "",
"experience_level": config.experience_level or "",
"remote": config.remote or "",
"company": config.company or "",
"selective_search": config.selective_search,
"jobs_to_not_include": config.jobs_to_not_include or "",
"location_radius": config.location_radius or "",
}]
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code != 200:
raise RuntimeError(f"Trigger request failed: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("No snapshot_id returned from Bright Data trigger.")
print(f"LinkedIn job search triggered! Snapshot ID: {snapshot_id}")
# Poll snapshot endpoint until data is ready or timeout
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f"Bearer {brightdata_api_key}"}
print(f"Polling snapshot for ID: {snapshot_id}")
while True:
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# Snapshot ready: return job postings JSON data
print("Snapshot is ready")
return snap_resp.json()
elif snap_resp.status_code == 202:
# Snapshot not ready yet: wait and retry
print(f"Snapshot not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
raise RuntimeError(f"Snapshot polling failed: {snap_resp.status_code} - {snap_resp.text}")
# Initialize OpenAI client
client = OpenAI()
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# Construct prompt for AI to score job matches based on candidate profile
prompt = f"""
"You are an expert recruiter. Given the following candidate profile:\n"
"{profile_summary}\n\n"
"Desired job description:\n{desired_job_summary}\n\n"
"Score each job posting accurately from 0 to 100 on how well it matches the profile and desired job.\n"
"For each job, add a short comment (max 50 words) explaining the score and match quality.\n"
"Return an array of objects with keys 'job_posting_id', 'score', and 'comment'.\n\n"
"Jobs:\n{json.dumps(jobs_batch)}\n"
"""
messages = [
{"role": "system", "content": "You are a helpful job scoring assistant."},
{"role": "user", "content": prompt},
]
# Use OpenAI API to parse structured response into JobScoresResponse model
response = client.responses.parse(
model="gpt-5-mini",
input=messages,
text_format=JobScoresResponse,
)
# Return list of scored jobs
return response.output_parsed.scores
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# Where to store the enriched data
extended_jobs = []
# Combine original jobs with AI scores and comments
for score_obj in all_scores:
matched_job = None
for job in jobs:
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
break
if matched_job:
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = score_obj.comment
extended_jobs.append(job_with_score)
# Sort extended jobs by AI score (highest first)
extended_jobs.sort(key=lambda j: j["ai_score"], reverse=True)
return extended_jobs
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# Dynamically get the field names from the first element in the array
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# Write extended job data with AI scores to CSV
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in extended_jobs:
writer.writerow(job)
print(f"Exported {len(extended_jobs)} jobs to {output_csv}")
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"\n*** Top {top} job matches ***")
for job in extended_jobs[:3]:
print(f"URL: {job.get('url', 'N/A')}")
print(f"Title: {job.get('job_title', 'N/A')}")
print(f"AI Score: {job.get('ai_score')}")
print(f"AI Comment: {job.get('ai_comment', 'N/A')}")
print("-" * 40)
def main():
# Get runtime parameters from CLI
args = parse_cli_args()
try:
# Load API keys from environment
_, brightdata_api_key = load_env_vars()
# Load job search config file
config = load_and_validate_config(args.config_file)
# Fetch jobs
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} jobs found!")
except Exception as e:
print(f"[Error] {e}")
return
all_scores = []
# Process jobs in batches to avoid overloading API and to handle large datasets
for i in range(0, len(jobs_data), args.batch_size):
batch = jobs_data[i : i + args.batch_size]
print(f"Scoring batch {i // args.batch_size + 1} with {len(batch)} jobs...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # To avoid triggering API rate limits
# Merge scores into scraped jobs
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# Save results to CSV
export_extended_jobs(extended_jobs, args.output_csv)
# Print top job matches with key info for quick review
print_top_jobs(extended_jobs)
if __name__ == "__main__":
main()Suppose you are a product manager with 7 years of experience looking for a hybrid job position in New York. Configure your config.json file as follows:
{
"location": "New York",
"keyword": "Product Manager",
"country": "US",
"time_range": "Past month",
"job_type": "Full-time",
"experience_level": "Mid-Senior level",
"remote": "Hybrid",
"profile_summary": "Experienced product manager with 7 years in tech startups, specializing in agile methodologies and cross-functional team leadership.",
"desired_job_summary": "Looking for a full-time product manager role focusing on SaaS products and customer-centric development."
}Then, you can run the LinkedIn job hunting assistant with:
python assistant.pyOptional: For a customized run, write something like:
python assistant.py --config_file=config.json --batch_size=10 --jobs_number=40 --output_csv=results.csvThis command runs the assistant using your specified config.json file. It processes jobs in batches of 10, retrieves up to 40 job listings from Bright Data, and saves the enriched results with AI scores and comments into results.csv.
Now, if you run the assistant with default CLI arguments, you should see something like this in the terminal:
LinkedIn job search triggered! Snapshot ID: s_me6x0s3qldm9zz0wv
Polling snapshot for ID: s_me6x0s3qldm9zz0wv
Snapshot not ready yet. Retrying in 10 seconds...
# Omitted for brevity...
Snapshot not ready yet. Retrying in 10 seconds...
Snapshot is ready
20 jobs found!
Scoring batch 1 with 5 jobs...
Scoring batch 2 with 5 jobs...
Scoring batch 3 with 5 jobs...
Scoring batch 4 with 5 jobs...
Exported 20 jobs to jobs.csvThen, the output with the top 3 job insights will be something like:
*** Top 3 job matches ***
URL: https://www.linkedin.com/jobs/view/product-manager-growth-at-yext-4267903356?_l=en
Title: Product Manager, Growth
AI Score: 92
AI Comment: Excellent fit: SaaS-focused growth PM with customer-centric objectives, product-led growth, experimentation and cross-functional collaboration—direct match to candidate's experience and desired role.
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-industrial-color-4271494891?_l=en
Title: Product Manager
AI Score: 90
AI Comment: Strong match: SaaS product, API/integrations, agile and cross-functional leadership emphasized. Only minor mismatch is the listed 2–4 years target (you have 7), which likely makes you overqualified but highly applicable.
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-resourceful-talent-group-4277945862?_l=en
Title: Product Manager
AI Score: 88
AI Comment: Very similar SaaS/integrations role with agile practices and customer-driven iteration. Recruiter listing targets 2–4 years, but your 7 years of startup PM experience and cross-functional leadership map well.
----------------------------------------Open the generated jobs_scored.csv file. In the main columns, you will see:
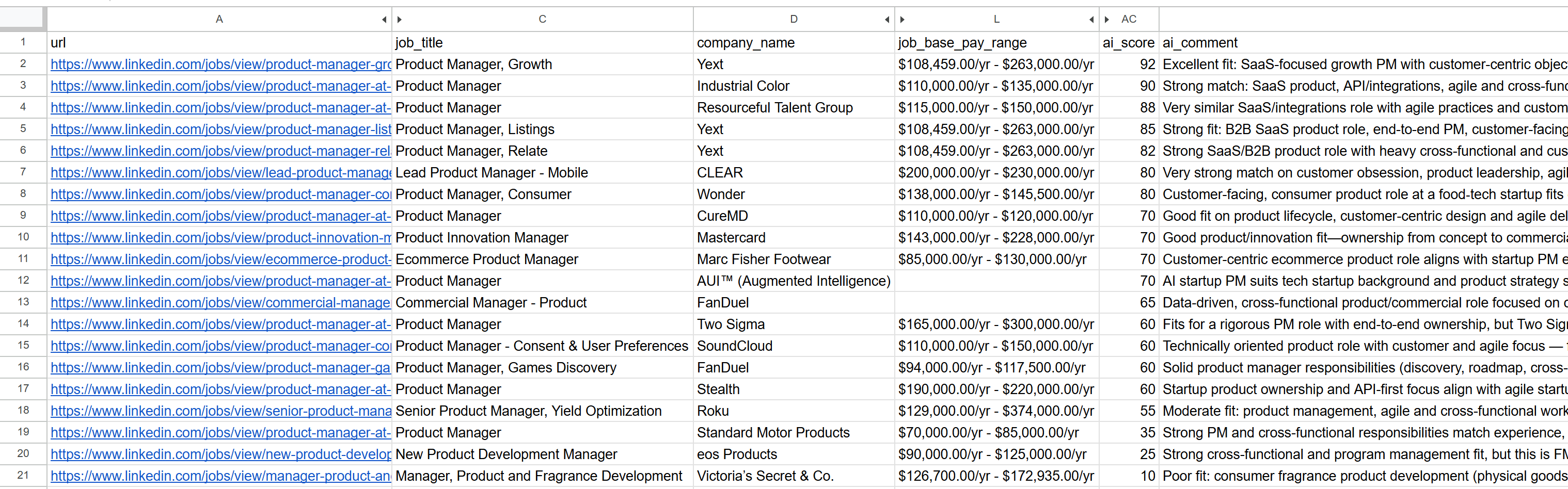
Notice how each job has been scored and commented on by the AI. This helps you focus only on the jobs where you have a real chance of success!
Et voilà! Thanks to this AI-powered LinkedIn job hunting workflow, finding your next job has never been easier.
Next Steps
The LinkedIn job hunting assistant built here works like a chat, but there are a few enhancements worth exploring:
- Avoid evaluating the same jobs repeatedly: To evaluate different jobs each time you run the script, set the
jobs_to_not_includearray in yourconfig.jsonfile. This should contain thejob_posting_ids of jobs the assistant already analyzed. For example, to exclude the current scraped jobs, your config might look like this:
{
"location": "New York",
"keyword": "Product Manager",
"country": "US",
"time_range": "Past month",
"job_type": "Full-time",
"experience_level": "Mid-Senior level",
"remote": "Hybrid",
"jobs_to_not_include": ["4267903356", "4271494891", "4277945862", "4267906118", "4255405781", "4267537560", "4245709356", "4265355147", "4277751182", "4256914967", "4281336197", "4232207277", "4273328527", "4277435772", "4253823512", "4279286518", "4224506933", "4250788498", "4256023955", "4252894407"], // <--- NOTE: The IDs of the jobs to exclude
"profile_summary": "Experienced product manager with 7 years in tech startups, specializing in agile methodologies and cross-functional team leadership.",
"desired_job_summary": "Looking for a full-time product manager role focusing on SaaS products and customer-centric development."
}- Automate periodic script runs: Schedule the script to run regularly (e.g., daily) with tools like Cron. In this case, remember to set the right
time_rangeargument (e.g., “Past 24 hours”) and update thejobs_to_not_includelist to exclude jobs you have already evaluated. This helps you focus on fresh postings. - Use a dedicated AI judge model: Instead of a general GPT-5 model, consider using a specialized AI model fine-tuned for job matching and scoring. This simple change can greatly improve the accuracy and relevance of job evaluations.
Conclusion
In this article, you learned how to leverage Bright Data’s LinkedIn jobs scraping capabilities to build an AI-powered job search assistant.
The AI workflow built here is perfect for anyone looking for a new job and wanting to maximize their chances by focusing only on the best opportunities. It helps you save time and energy by applying to jobs that truly match their career goals and have a higher chance of hiring.
To build more advanced workflows, explore the full range of solutions for fetching, validating, and transforming live web data in the Bright Data AI infrastructure.
Create a free Bright Data account and start experimenting with our AI-ready data tools!
FAQs
The example above uses LinkedIn as the data source, but you can easily extend the script to work with Indeed or any other job listing sources available through Bright Data. For more details on integrating with Indeed, refer to the Indeed Jobs Scraper.
This AI workflow relies on OpenAI for its wide adoption and popularity. However, you can easily adapt the workflow to operate with other LLM providers like Gemini, Anthropic, Cohere, or any API-available large language model.
The data returned by the LinkedIn Jobs Scraper is so high-quality and well-structured that you can process it for scoring using an LLM directly. Because of that, you do not necessarily need the complexity of an autonomous agent with reasoning and decision-making capabilities.
Still, if you do want to build a more advanced LinkedIn job hunting AI agent, you could consider the following multi-agent architecture:
Job fetcher agent: An AI agent integrated with the Bright Data infrastructure (via tooling or MCP) that calls the LinkedIn Jobs Scraper API to continuously fetch and update job listings.
Job scorer agent: An agent specialized in evaluating and scoring jobs based on the candidate’s profile and preferences using an LLM.
Orchestrator agent: A top-level agent that coordinates the other two agents, repeatedly triggering data retrieval and scoring cycles until a desired number of high-scoring, relevant job listings are obtained.
You could even program the agent to automatically apply to those job openings for you. If you are considering building such a LinkedIn job hunting system, we recommend using a multi-agent platform like CrewAI.

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



