

Creating specialized models that understand your domain often needs more than prompt engineering or retrieval-augmented generation (RAG). The publicly available models are powerful, but they lack the latest knowledge or the specific taste to your use case demands. Since we have web data, ranging from articles, documentations, product listings and video transcripts, this gap can be bridged by fine tuning.
In this blog post you will learn:
- How to collect and prepare domain specific web data using Bright Data’s scrapers and datasets.
- How to fine-tune an open-source GPT model with the collected data
- How to evaluate and deploy your fine-tuned model for real-world tasks.
Let’s dive in!
What is Fine-Tuning
In simple words, fine-tuning is the process of taking a model that has already been pre-trained on a large, general dataset and adapting it to perform well on a new, often more specific, dataset or task. When you do fine-tuning, under the hood you are changing the weights of the model instead of building from scratch. Changing the weights is what makes it behave differently or in a way that you desire.
Web data is useful for fine-tuning because it gives you:
- Freshness: It is continuously updated to capture the latest trends, events and technology.
- Diversity: Access to different writing styles, sources, thoughts which reduces bias from narrow datasets.
The process of fine-tuning works as shown here:
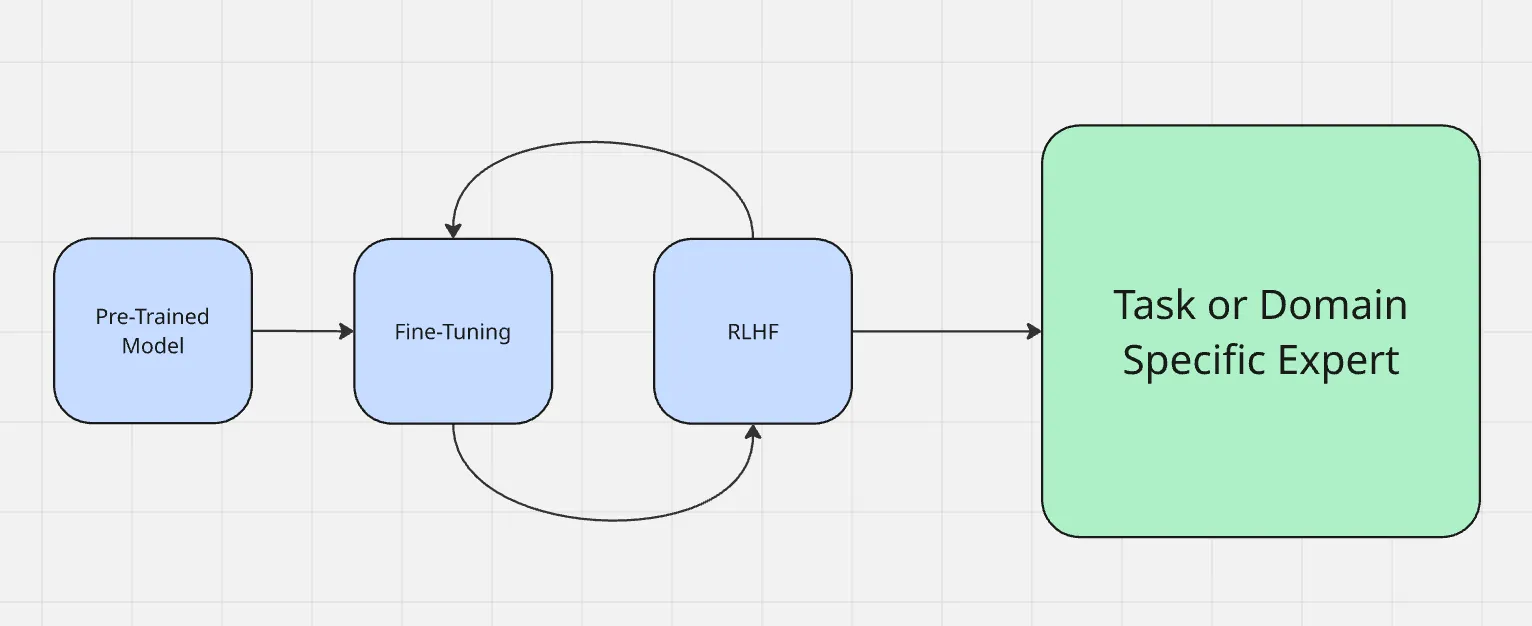
Fine-tuning is different from other commonly used adaptation methods like prompt engineering and retrieval-augmented generation. Prompt engineering changes how you ask a model questions, but doesn’t change the model itself. RAG adds an external knowledge source at runtime like giving context of something new. Fine-tuning, on the other hand, updates directly the model’s params, which makes it more reliable for producing domain precise output without extra context each time.
Unlike retrieval-augmented generation (RAG), which enriches a model with external context at runtime, fine-tuning adapts the model itself. If you want a deeper dive into the trade-offs, see RAG vs Fine-Tuning.
Why Use Web Data for Fine-Tuning
Web data comes in rich and latest formats (articles, product listings, forum posts, video transcripts, and even video-derived text), giving an advantage that neither static nor synthetic datasets can match. This variety helps a model handle different input types more effectively.
Here are some examples of different contexts where web data shines:
- Social media data: Tokens from social platforms help models understand informal language, slang, and real-time trends, which are essential for applications like sentiment analysis or chat bots.
- Structured datasets: Token from structured sources like product catalogs or financial reports enable a precise, domain-specific understanding, critical for recommendation systems or financial forecasting.
- Niche context: Startups and specialized applications benefit from tokens sourced from relevant datasets tailored to their use cases, such as legal documents for legal tech or medical journals for medicare AI.
Web data introduces natural variety and context, improving realism and robustness in a fine-tuned model.
Data Collection Strategies
Large-scale scrapers and dataset providers such as Bright Data make it possible to gather massive volumes of web content quickly and reliably. This allows you to build domain-specific datasets without spending months on manual collection.
Bright data built the industry’s most diversified and reliable web data collection infrastructure, constructed of several different network outlets and sources. While web data isn’t limited to plain text. Bright data can capture multi-modal inputs like metadata, product attributes, and video transcripts, which help a model learn richer context.
Collecting data using raw scrapes should be avoided since they almost always contain noise, irrelevant content, or formatting artifacts. Filtering, de duplication, and structured cleaning are important steps to ensure the training dataset improves performance instead of introducing confusion.
Preparing Web Data for Fine-Tuning
- Converting raw scrapes into structured input/output pairs. Unprocessed data is rarely ready for training as is. The first step involves converting the data into structured input/output pairs. For example, a documentation about fine-tuning can be formatted into a prompt such as “What is fine-tuning?” with the original answer as the target output. This type of structure ensures the model learns from well-defined examples instead of unorganized text.
- Handling diverse formats: JSON, CSV, transcripts, web pages. Web data usually comes in different formats like JSON from APIs, CSV exports, raw HTML, or transcripts from videos. Standardizing web data into a consistent format like JSONL makes it simpler to manage and feed into training pipelines.
- Packing datasets for efficient training. To improve training results and process, datasets are often “arranged”, meaning multiple shorter examples are combined into a single sequence to reduce wasted tokens and optimize GPU memory usage during fine-tuning.
- Balancing domain-specific vs. general web data. Finding a balance matters. An excess of single-domain data can make the model narrow and shallow, while too much general data may dilute the specialized knowledge targeted. The best results usually come from blending a strong base of general web data curated domain specific examples.
Choosing a Base Model
Choosing the right base model has a direct impact on how well your fine-tuned system performs. There’s no one-size-fits-all solution, especially considering the variety of offerings within each model family. Depending on your data type, desired outcomes, and budget, one model might suit your needs better than another.
To choose the right model to get started with, follow this checklist:
- What modality or modalities will your model need?
- How big is your input and output data?
- How complex are the tasks you are trying to perform?
- How important is performance versus budget?
- How critical is AI assistant safety to your use case?
- Does your company have an existing arrangement with Azure or GCP?
For instance, if you are dealing with extremely long videos or texts (hours long of hundreds of thousands of words), Gemini 1.5 pro might be an optimal choice, providing a context window of up to 1 million tokens.
Several open-source models are strong candidates for web data fine-tuning, including Gemma 3, Llama 3.1, Mistral 7B or Falcon models. The smaller versions are practical for most fine-tuning projects, while larger ones shine when your domain needs high coverage and precision. You can also check this guide on adapting Gemma 3 for fine-tuning.
Fine-Tuning with Bright Data
To demonstrate how web data fuels fine-tuning, let’s walk through an example using Bright Data as the source. In this example, we will use Bright Data’s Scraper API to collect product information from Amazon and then fine-tune a Llama 4 model on Hugging Face.
Step #1: Collecting the dataset
Using Bright Data’s web scraper API, you can retrieve structured product data (title, products, descriptions, reviews, etc) with just a few lines of Python.
The Goal in this step is to create a small project that:
- Activates a Python virtual environment
- Calls Bright Data’s Web Scraper API
- Saves results to amazon-data.json
Prerequisites
- Python 3.10+
- A Bright Data API token
- A Bright Data collector ID (from Bright Data dashboard) /cp/scrapers
- An OPENAI_API_KEY since we will be fine-tuning a GPT-4 model.
Make a project folder
mkdir web-scraper && cd web-scrapperCreate and activate a virtual environment
Activate a virtual environment, and you should see (venv) at the start of your shell prompt.
//macOS/Linux (bash or zsh):
python3 -m venv venv
source venv/bin/activate
Windows
python -m venv venv
.\venv\Scripts\Activate.ps1Install dependencies
This is a library for making HTTP web requests
pip install requestsOnce this is complete, you are now ready to get the data of interest using the scraper APIs by Bright Data.
Define the Scraping Logic
The following snippet will trigger your Bright Data collector (eg., Amazon products), poll until the scrape is finishes, and save the results to a local JSON file.
Replace your api key in the api key string here
import requests
import json
import time
def trigger_amazon_products_scraping(api_key, urls):
url = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_l7q7dkf244hwjntr0",
"include_errors": "true",
"type": "discover_new",
"discover_by": "best_sellers_url",
}
data = [{"category_url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Response: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(F"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "your_api_key"
urls = [
"https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-products"
]
snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "amazon-data.json")Run the code
python3 web_scraper.pyYou should see:
- A snapshot ID printed
- Scrape completed.
- Saved to amazon-data.json (…items)
The process automatically creates the data that contains our scraped data. This is the expected structure of the data:
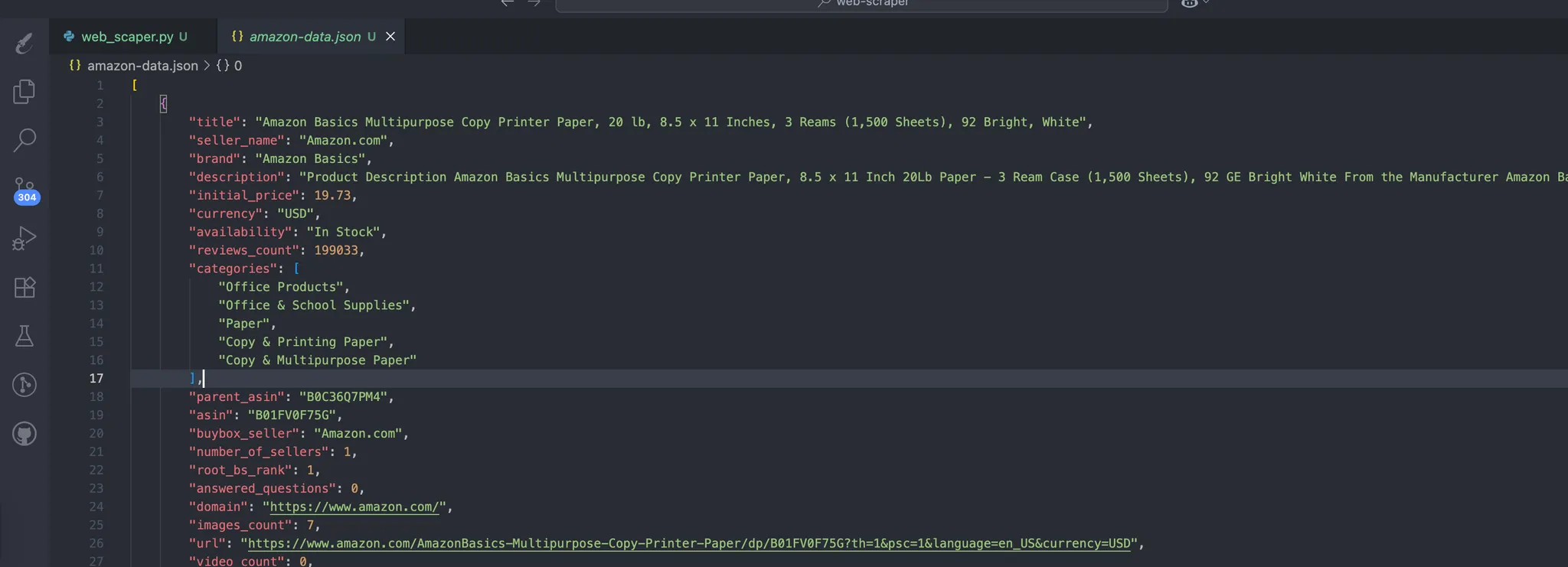
Step #2: Turn JSON into training pairs
Create prepare_pair.py in the root of the project, with the following snippet to structure our data in JSONL format to make it ready for your fine-tuning step.
import json, random, os
INPUT = "amazon-data.json"
OUTPUT = "pairs.jsonl"
SYSTEM = "You are an expert copywriter. Generate concise, accurate product descriptions."
def make_example(item):
title = item.get("title") or item.get("name") or "Unknown product"
brand = item.get("brand") or "Unknown brand"
features = item.get("features") or item.get("bullets") or []
features_str = ", ".join(features) if isinstance(features, list) else str(features)
target = item.get("description") or item.get("about") or ""
user = f"Write a crisp product description.\nTitle: {title}\nBrand: {brand}\nFeatures: {features_str}\nDescription:"
assistant = target.strip()[:1200] # keep it tight
return {"system": SYSTEM, "user": user, "assistant": assistant}
def main():
if not os.path.exists(INPUT):
raise SystemExit(f"Missing {INPUT}")
data = json.load(open(INPUT, "r", encoding="utf-8"))
pairs = [make_example(x) for x in data if isinstance(x, dict)]
random.shuffle(pairs)
with open(OUTPUT, "w", encoding="utf-8") as out:
for ex in pairs:
out.write(json.dumps(ex, ensure_ascii=False) + "\n")
print(f"Wrote {len(pairs)} examples to {OUTPUT}")
if __name__ == "__main__":
main()Run the following command:
python3 prepare_pairs.pyAnd should give the following output in the file:
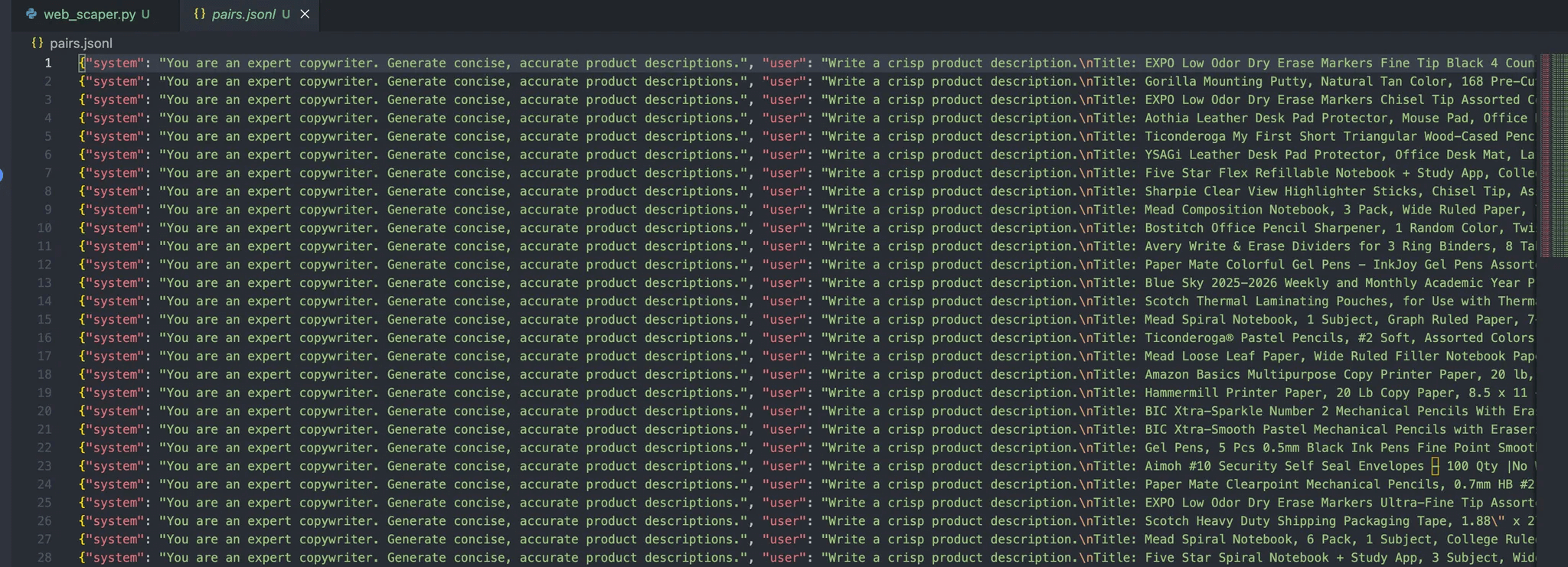
Each message in these object contains three roles:
- System: Provides initial context for the assistant.
- User: The user’s input.
- Assistant: The assistant’s response.
Step #3: Uploading the File for Fine-Tuning
Once the file is ready, the next steps are just wiring it into the OpenAI fine-tuning pipelines with the following steps:
Install OpenAI dependencies
pip install openaiCreate a upload.py to Upload your dataset
This script will read from the pairs.jsonl file we already have
from openai import OpenAI
client = OpenAI(api_key="your_api_key_here")
with open("pairs.jsonl", "rb") as f:
uploaded = client.files.create(file=f, purpose="fine-tune")
print(uploaded)Run the following command:
python3 upload.pyYou should now see a response like:
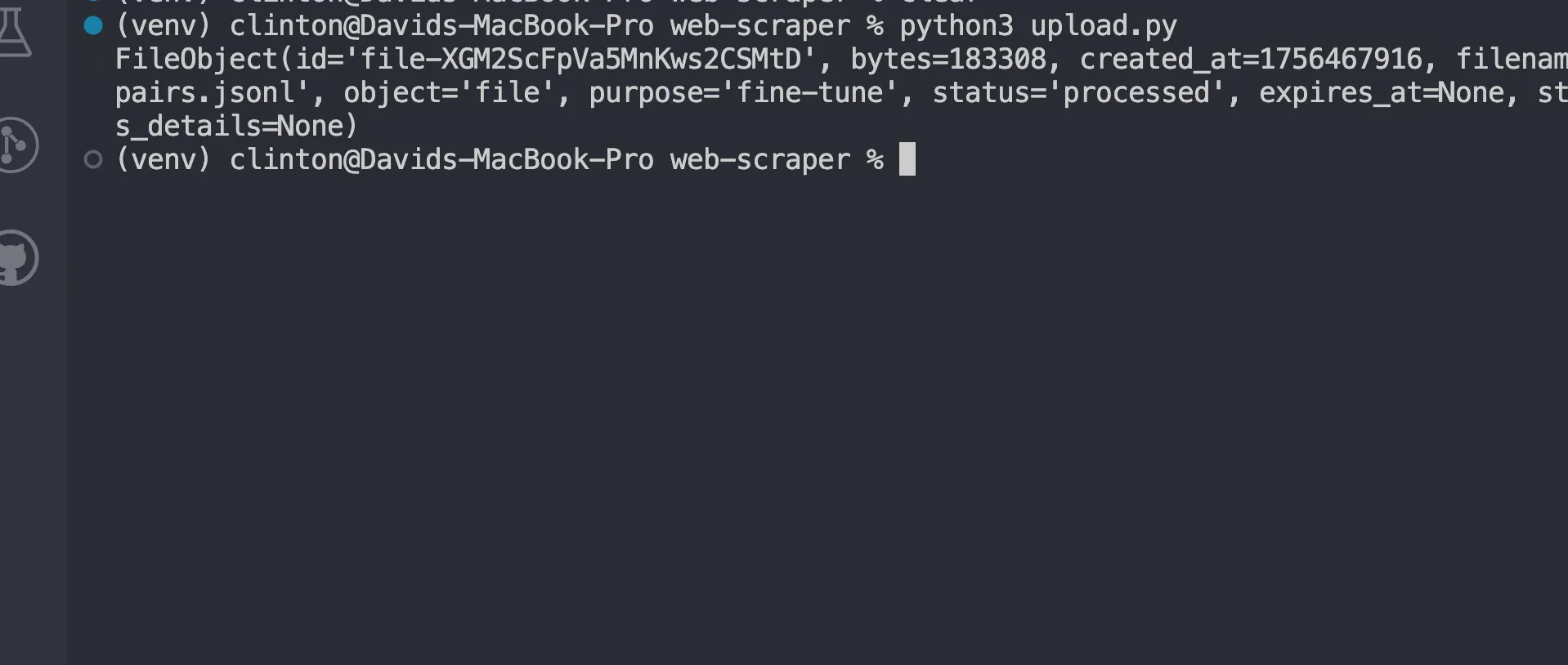
Fine-tune the model
Create a file fine-tune.py and replace the FILE_ID with the uploaded file id we got from our response above, and run the file:
from openai import OpenAI
client = OpenAI()
# replace with your uploaded file id
FILE_ID = "file-xxxxxx"
job = client.fine_tuning.jobs.create(
training_file=FILE_ID,
model="gpt-4o-mini-2024-07-18"
)
print(job)This should give us this response:
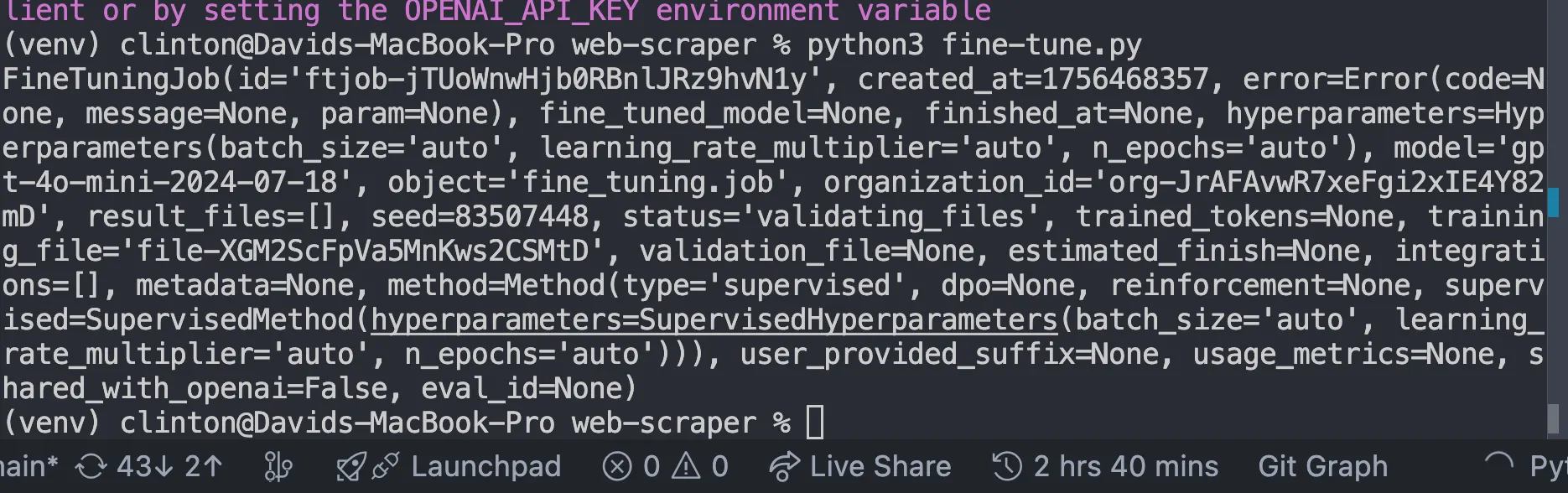
Monitor Until Training Finishes
Once you’ve started the fine-tuning job, the model needs time to train on your dataset. Depending on the dataset size, this can take a few minutes to hours.
But you don’t want to guess when it’s ready; instead, write and run this code in monitor.py
from openai import OpenAI
client = OpenAI()
jobs = client.fine_tuning.jobs.list(limit=1)
print(jobs)Then run the file with python3 [manage.py](http://manage.py) in the terminal, and it should show details like:
- Whether the training succeeded or failed.
- How many tokens were trained
- The ID of the new fine-tuned model.
In this section, you should only move forward when the status field says
"succeeded"Chat With Your Fine-Tuned Model
Once the job is finished, you now have your own custom GPT model. To use it, open chat.py, update the MODEL_ID with the one returned from your fine-tuning job, and run the file:
from openai import OpenAI
client = OpenAI()
# replace with your fine-tuned model id
MODEL_ID = "ft:gpt-4o-mini-2024-07-18:your-org::custom123"
while True:
user_input = input("User: ")
if user_input.lower() in ["quit", "q"]:
break
response = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "You are a helpful assistant fine-tuned on domain data."},
{"role": "user", "content": user_input}
]
)
print("Assistant:", response.choices[0].message.content)This step proves the fine-tuning worked. Instead of using the general-purpose base model, you’re now talking to a model trained specifically on your data.
This is where you will see your results come to life.
You can expect results like:
--- Generating Descriptions with Fine-Tuned Model using Synthetic Test Data ---
PROMPT for item: ErgoPro-EL100
GENERATED (Fine-tuned):
**Introducing the ErgoPro-EL100: The Ultimate Executive Ergonomic Office Chair**
Experience the pinnacle of comfort and support with the ComfortLuxe ErgoPro-EL100, designed to elevate your work experience. This premium office chair boasts a high-back design that cradles your upper body, providing unparalleled lumbar support and promoting a healthy posture.
The breathable mesh fabric ensures a cool and comfortable seating experience, while the synchronized tilt mechanism allows for seamless adjustments to your preferred working position. The padded armrests provide additional support and comfort, reducing strain on your shoulders and wrists.
Built to last, the ErgoPro-EL100 features a heavy-duty nylon base that ensures stability and durability. Whether you're working long hours or simply
--------------------------------------------------
PROMPT for item: HeightRise-FD20
GENERATED (Fine-tuned):
**Elevate Your Productivity with FlexiDesk's HeightRise-FD20 Adjustable Standing Desk Converter**
Take your work to new heights with FlexiDesk's HeightRise-FD20, the ultimate adjustable standing desk converter. Designed to revolutionize your workspace, this innovative converter transforms any desk into a comfortable and ergonomic standing station.
**Experience the Benefits of Standing**
The HeightRise-FD20 features a spacious dual-tier surface, perfect for holding your laptop, monitor, and other essential work tools. The smooth gas spring lift allows for effortless height adjustments, ranging from 6 to 17 inches, ensuring a comfortable standing position that suits your needs.
**Durable and Reliable**
With a sturdy construction and non-slip rubber feet
--------------------------------------------------Conclusion
When working with fine-tuning at web scale, it’s important to be realistic about constraints and workflows:
- Resource requirements: Training on large, diverse datasets requires compute and storage. If you’re experimenting, start with smaller slices of your data before scaling.
- Iterate gradually: Instead of dumping millions of records in your first attempt, refine with a smaller dataset. Use the results to spot gaps or errors in your preprocessing pipeline.
- Deployment workflows: Treat fine-tuned models like any other software artifact. Version them, integrate into CI/CD where possible, and maintain rollback options in case a new model underperforms.
Luckily, Bright Data has you covered with numerous AI-ready services for dataset acquisition or creation:
- Scraping Browser: A Playwright, Selenium-, Puppeter-compatible browser with built-in unlocking capabilities.
- Web Scraper APIs: Pre-configured APIs for extracting structured data from 100+ major domains.
- Web Unlocker: An all-in-one API that handles site unlocking on sites with anti-bot protections.
- SERP API: A specialized API that unlocks search engine results and extracts complete SERP data.
- Data for foundation models: Access compliant, web-scale datasets to power pre-training, evaluation, and fine-tuning.
- Data providers: Connect with trusted providers to source high-quality, AI-ready datasets at scale.
- Data packages: Get curated, ready-to-use datasets—structured, enriched, and annotated.
Fine-tuning large language models with web data unlocks powerful domain specialization. The web provides fresh, diverse, and multimodal content , from articles and reviews to transcripts and structured metadata , that curated datasets alone cannot match.
Create a Bright Data account for free to test our AI-ready data infrastructure!

Technical Writer
Arindam Majumder is a developer advocate, YouTuber, and technical writer who simplifies LLMs, agent workflows, and AI content for 5,000+ followers.



