Target is one of the most difficult eCommerce sites to scrape today. Between dynamic CSS selectors, lazy loaded content and a powerful blocking system, it can feel impossible. By the end of this guide, you’ll be able to scrape Target like a pro. We’ll cover two different ways of extracting product listings.
- How to scrape Target with Python and Scraping Browser
- How to scrape Target with Claude and Bright Data’s MCP Server
How To Scrape Target With Python
We’ll go through the process of scraping Target listings manually using Python. Target’s content is dynamically loaded, so results are often spotty at best without a headless browser. First, we’ll go through with Requests and BeautifulSoup. Then, we’ll go through and extract content with Selenium.
Inspecting the Site
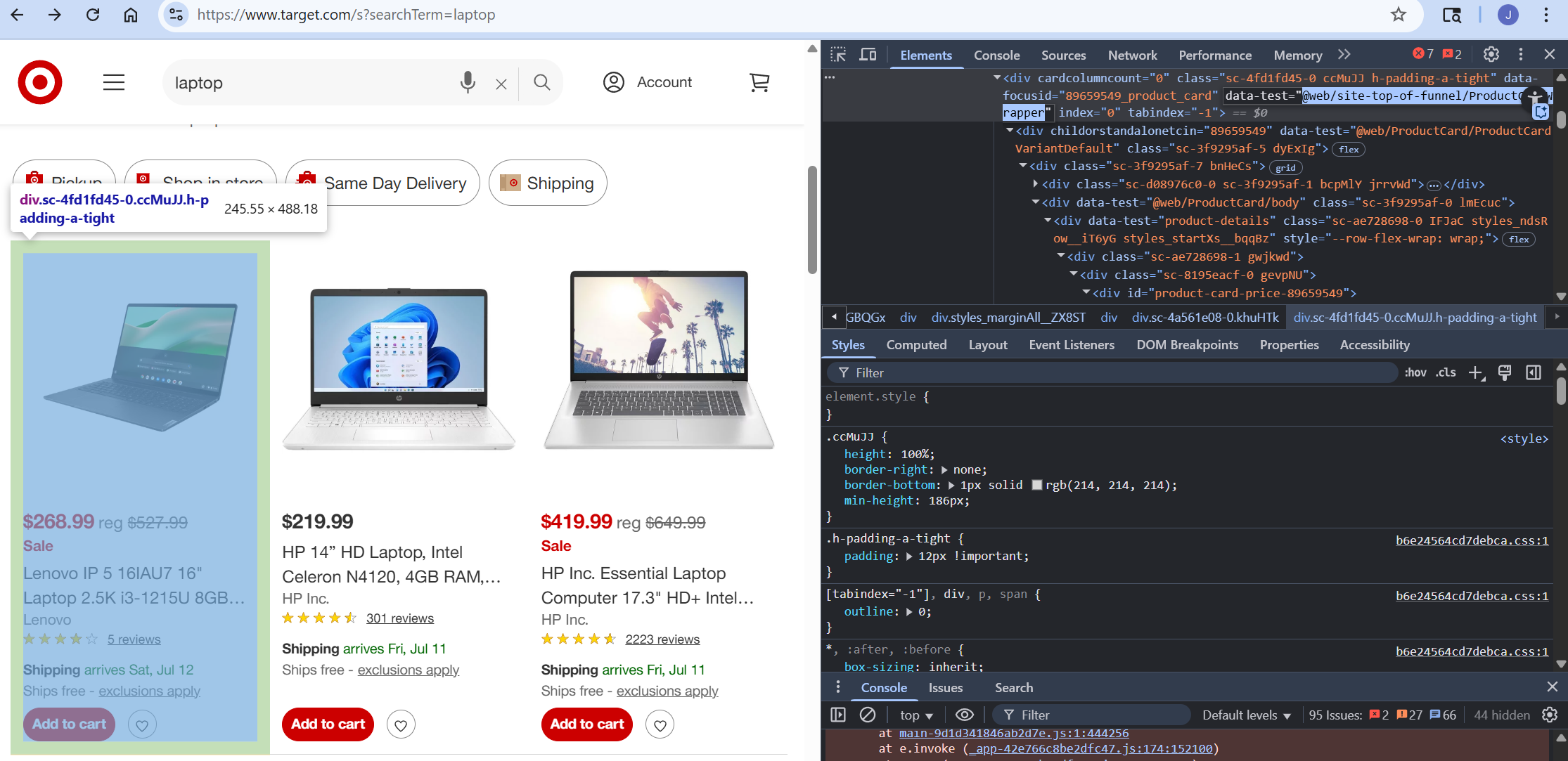
Before we start coding, we need to actually inspect Target’s results page. If you inspect the page, you should notice that all product cards come with a data-test value of @web/site-top-of-funnel/ProductCardWrapper. We’ll use this value as a CSS selector when extracting our data.
Python Requests and BeautifulSoup Won’t Work
If you don’t have Requests and BeautifulSoup, you can install them via pip.
pip install requests beautifulsoup4The code below outlines a basic scraper we can use. We set our headers using our Bright Data API Key and application/json. Our data holds our actual configuration such as our zone name, Target URL and format. After finding the product cards, we iterate through them and extract each product’s title, link and price.
All of our extracted products get stored in an array and then we write the array to a JSON file when the scrape is complete. Notice the continue statements when elements aren’t found. If a product is on the page without these elements, it hasn’t finished loading. Without a browser, we can’t render the page to wait for the content to load.
import requests
from bs4 import BeautifulSoup
import json
#headers to send to the web unlocker api
headers = {
"Authorization": "your-bright-data-api-key",
"Content-Type": "application/json"
}
#our configuration
data = {
"zone": "web_unlocker1",
"url": "https://www.target.com/s?searchTerm=laptop",
"format": "raw",
}
#send the request to the api
response = requests.post(
"https://api.brightdata.com/request",
json=data,
headers=headers
)
#array for scraped products
scraped_products = []
card_selector = "@web/site-top-of-funnel/ProductCardWrapper"
#parse them with beautifulsoup
soup = BeautifulSoup(response.text, "html.parser")
cards = soup.select(f"div[data-test='{card_selector}']")
#log the amount of cards found for debugging purposes
print("products found", len(cards))
#iterate through the cards
for card in cards:
#find the product data
#if a product hasn't loaded yet, drop it from the list
listing_text = card.text
link_element = card.select_one("a[data-test='product-title']")
if not link_element:
continue
title = link_element.get("aria-label").replace("\"")
link = link_element.get("href")
price = card.select_one("span[data-test='current-price'] span")
if not price:
continue
product_info = {
"title": title,
"link": f"https://www.target.com{link}",
"price": price.text
}
#add the extracted product to our scraped data
scraped_products.append(product_info)
#write our extracted data to a JSON file
with open("output.json", "w", encoding="utf-8") as file:
json.dump(scraped_products, file, indent=4)Skipping unrendered objects severely limits our extracted data. As you can see in the results below, we only were able to extract four complete results.
[
{
"title": "Lenovo LOQ 15 15.6\" 1920 x 1080 FHD 144Hz Gaming Laptop Intel Core i5-12450HX 12GB RAM DDR5 512GB SSD NVIDIA GeForce RTX 3050 6GB Luna Grey",
"link": "https://www.target.com/p/lenovo-loq-15-15-6-1920-x-1080-fhd-144hz-gaming-laptop-intel-core-i5-12450hx-12gb-ram-ddr5-512gb-ssd-nvidia-geforce-rtx-3050-6gb-luna-grey/-/A-93972673#lnk=sametab",
"price": "$569.99"
},
{
"title": "Lenovo Flex 5i 14\" WUXGA 2-in-1 Touchscreen Laptop, Intel Core i5-1235U, 8GB RAM, 512GB SSD, Intel Iris Xe Graphics, Windows 11 Home",
"link": "https://www.target.com/p/lenovo-flex-5i-14-wuxga-2-in-1-touchscreen-laptop-intel-core-i5-1235u-8gb-ram-512gb-ssd-intel-iris-xe-graphics-windows-11-home/-/A-91620960#lnk=sametab",
"price": "$469.99"
},
{
"title": "HP Envy x360 14\" Full HD 2-in-1 Touchscreen Laptop, Intel Core 5 120U, 8GB RAM, 512GB SSD, Windows 11 Home",
"link": "https://www.target.com/p/hp-envy-x360-14-full-hd-2-in-1-touchscreen-laptop-intel-core-5-120u-8gb-ram-512gb-ssd-windows-11-home/-/A-92708401#lnk=sametab",
"price": "$569.99"
},
{
"title": "HP Inc. Essential Laptop Computer 17.3\" HD+ Intel Core 8 GB memory; 256 GB SSD",
"link": "https://www.target.com/p/hp-inc-essential-laptop-computer-17-3-hd-intel-core-8-gb-memory-256-gb-ssd/-/A-92469343#lnk=sametab",
"price": "$419.99"
}
]With Requests and BeautifulSoup, we can get through to the page but we’re unable to load all the results.
Scraping With Python Selenium
We need a browser to render the page. This is where Selenium comes in. Run the command below to install Selenium.
pip install seleniumIn the code below, we connect to a remote instance of Selenium using Scraping Browser. Pay attention to the actual code here. Our logic here is largely the same as the example above. Most of the extra code you see below is error handling and preprogrammed waits for the page content to load.
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import json
import time
import sys
AUTH = 'brd-customer-<your-username>-zone-<your-zone-name>:<your-password>'
SBR_WEBDRIVER = f'https://{AUTH}@brd.superproxy.io:9515'
def safe_print(*args):
#force safe ascii-only output on windows terminals
text = " ".join(str(arg) for arg in args)
try:
sys.stdout.write(text + '\n')
except UnicodeEncodeError:
sys.stdout.write(text.encode('ascii', errors='replace').decode() + '\n')
#our actual runtime
def main():
#array for scraped products
scraped_products = []
card_selector = "@web/site-top-of-funnel/ProductCardWrapper"
safe_print('Connecting to Bright Data SBR Browser API...')
#remote connection config to scraping browser
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')
#launch scraping browser
with Remote(sbr_connection, options=ChromeOptions()) as driver:
safe_print('Connected! Navigating...')
driver.get("https://www.target.com/s?searchTerm=laptop")
#set a 30 second timeout for items to load
wait = WebDriverWait(driver, 30)
safe_print('Waiting for initial product cards...')
try:
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, f"div[data-test='{card_selector}']"))
)
except TimeoutException:
safe_print("No product cards loaded at all — possible block or site structure change.")
return
#get the document height for some scrolling math
safe_print('Starting pixel-step scroll loop...')
last_height = driver.execute_script("return document.body.scrollHeight")
scroll_attempt = 0
max_scroll_attempts = 10
#gently scroll down the page
while scroll_attempt < max_scroll_attempts:
driver.execute_script("window.scrollBy(0, window.innerHeight);")
time.sleep(1.5)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
safe_print("Reached page bottom.")
break
last_height = new_height
scroll_attempt += 1
safe_print("Scrolling done — doing final settle nudges to keep session alive...")
try:
for _ in range(5):
driver.execute_script("window.scrollBy(0, -50); window.scrollBy(0, 50);")
time.sleep(1)
except Exception as e:
safe_print(f"Connection closed during final settle: {type(e).__name__} — {e}")
return
#now that everything's loaded, find the product cards
safe_print("Scraping product cards...")
try:
product_cards = driver.find_elements(By.CSS_SELECTOR, f"div[data-test='{card_selector}']")
safe_print(f"Found {len(product_cards)} cards.")
except Exception as e:
safe_print(f"Failed to find product cards: {type(e).__name__} — {e}")
return
#drop empty cards and extract data from the rest
for card in product_cards:
inner_html = card.get_attribute("innerHTML").strip()
if not inner_html or len(inner_html) < 50:
continue
safe_print("\n--- CARD HTML (truncated) ---\n", inner_html[:200])
try:
link_element = card.find_element(By.CSS_SELECTOR, "a[data-test='product-title']")
title = link_element.get_attribute("aria-label") or link_element.text.strip()
link = link_element.get_attribute("href")
except NoSuchElementException:
safe_print("Link element not found in card, skipping.")
continue
try:
price_element = card.find_element(By.CSS_SELECTOR, "span[data-test='current-price'] span")
price = price_element.text.strip()
except NoSuchElementException:
price = "N/A"
product_info = {
"title": title,
"link": f"https://www.target.com{link}" if link and link.startswith("/") else link,
"price": price
}
scraped_products.append(product_info)
#write the extracted products to a json file
if scraped_products:
with open("scraped-products.json", "w", encoding="utf-8") as file:
json.dump(scraped_products, file, indent=2)
safe_print(f"Done! Saved {len(scraped_products)} products to scraped-products.json")
else:
safe_print("No products scraped — nothing to save.")
if __name__ == '__main__':
main()As you can see, we get more complete results using Selenium. Instead of four listings, we’re able to extract eight. This is much better than our first attempt.
[
{
"title": "Lenovo LOQ 15 15.6\" 1920 x 1080 FHD 144Hz Gaming Laptop Intel Core i5-12450HX 12GB RAM DDR5 512GB SSD NVIDIA GeForce RTX 3050 6GB Luna Grey",
"link": "https://www.target.com/p/lenovo-loq-15-15-6-1920-x-1080-fhd-144hz-gaming-laptop-intel-core-i5-12450hx-12gb-ram-ddr5-512gb-ssd-nvidia-geforce-rtx-3050-6gb-luna-grey/-/A-93972673#lnk=sametab",
"price": "$569.99"
},
{
"title": "Lenovo Flex 5i 14\" WUXGA 2-in-1 Touchscreen Laptop, Intel Core i5-1235U, 8GB RAM, 512GB SSD, Intel Iris Xe Graphics, Windows 11 Home",
"link": "https://www.target.com/p/lenovo-flex-5i-14-wuxga-2-in-1-touchscreen-laptop-intel-core-i5-1235u-8gb-ram-512gb-ssd-intel-iris-xe-graphics-windows-11-home/-/A-91620960#lnk=sametab",
"price": "$469.99"
},
{
"title": "HP Inc. Essential Laptop Computer 15.6\" HD Intel Core i5 8 GB memory; 256 GB SSD",
"link": "https://www.target.com/p/hp-inc-essential-laptop-computer-15-6-hd-intel-core-i5-8-gb-memory-256-gb-ssd/-/A-1002589475#lnk=sametab",
"price": "$819.99"
},
{
"title": "HP Envy x360 14\" Full HD 2-in-1 Touchscreen Laptop, Intel Core 5 120U, 8GB RAM, 512GB SSD, Windows 11 Home",
"link": "https://www.target.com/p/hp-envy-x360-14-full-hd-2-in-1-touchscreen-laptop-intel-core-5-120u-8gb-ram-512gb-ssd-windows-11-home/-/A-92708401#lnk=sametab",
"price": "$569.99"
},
{
"title": "Lenovo Legion Pro 7i 16\" WQXGA OLED 240Hz Gaming Notebook Intel Core Ultra 9 275HX 32GB RAM 1TB SSD NVIDIA GeForce RTX 5070Ti Eclipse Black",
"link": "https://www.target.com/p/lenovo-legion-pro-7i-16-wqxga-oled-240hz-gaming-notebook-intel-core-ultra-9-275hx-32gb-ram-1tb-ssd-nvidia-geforce-rtx-5070ti-eclipse-black/-/A-1002300555#lnk=sametab",
"price": "$2,349.99"
},
{
"title": "Lenovo LOQ 15.6\" 1920 x 1080 FHD 144Hz Gaming Notebook Intel Core i5-12450HX 12GB DDR5 512GB SSD NVIDIA GeForce 2050 4GB DDR6 Luna Grey",
"link": "https://www.target.com/p/lenovo-loq-15-6-1920-x-1080-fhd-144hz-gaming-notebook-intel-core-i5-12450hx-12gb-ddr5-512gb-ssd-nvidia-geforce-2050-4gb-ddr6-luna-grey/-/A-1000574845#lnk=sametab",
"price": "$519.99"
},
{
"title": "HP Envy x360 14\u201d WUXGA 2-in-1 Touchscreen Laptop, AMD Ryzen 5 8640HS, 16GB RAM, 512GB SSD, Windows 11 Home",
"link": "https://www.target.com/p/hp-envy-x360-14-wuxga-2-in-1-touchscreen-laptop-amd-ryzen-5-8640hs-16gb-ram-512gb-ssd-windows-11-home/-/A-92918585#lnk=sametab",
"price": "$669.99"
},
{
"title": "Acer Aspire 3 - 15.6\" Touchscreen Laptop AMD Ryzen 5 7520U 2.80GHz 16GB RAM 1TB SSD W11H - Manufacturer Refurbished",
"link": "https://www.target.com/p/acer-aspire-3-15-6-touchscreen-laptop-amd-ryzen-5-7520u-2-80ghz-16gb-1tb-w11h-manufacturer-refurbished/-/A-93221896#lnk=sametab",
"price": "$299.99"
}
]Our results here are better, but we can improve them even more — with less work and zero code.
How To Scrape Target With Claude
Next, we’ll go through and perform the same task using Claude with Bright Data’s MCP server. You can get started by opening up Claude Desktop. Make sure you’ve got active Web Unlocker and Scraping Browser zones. Scraping Browser isn’t required for the MCP Server, but Target requires a browser.
Configuring The MCP Connection
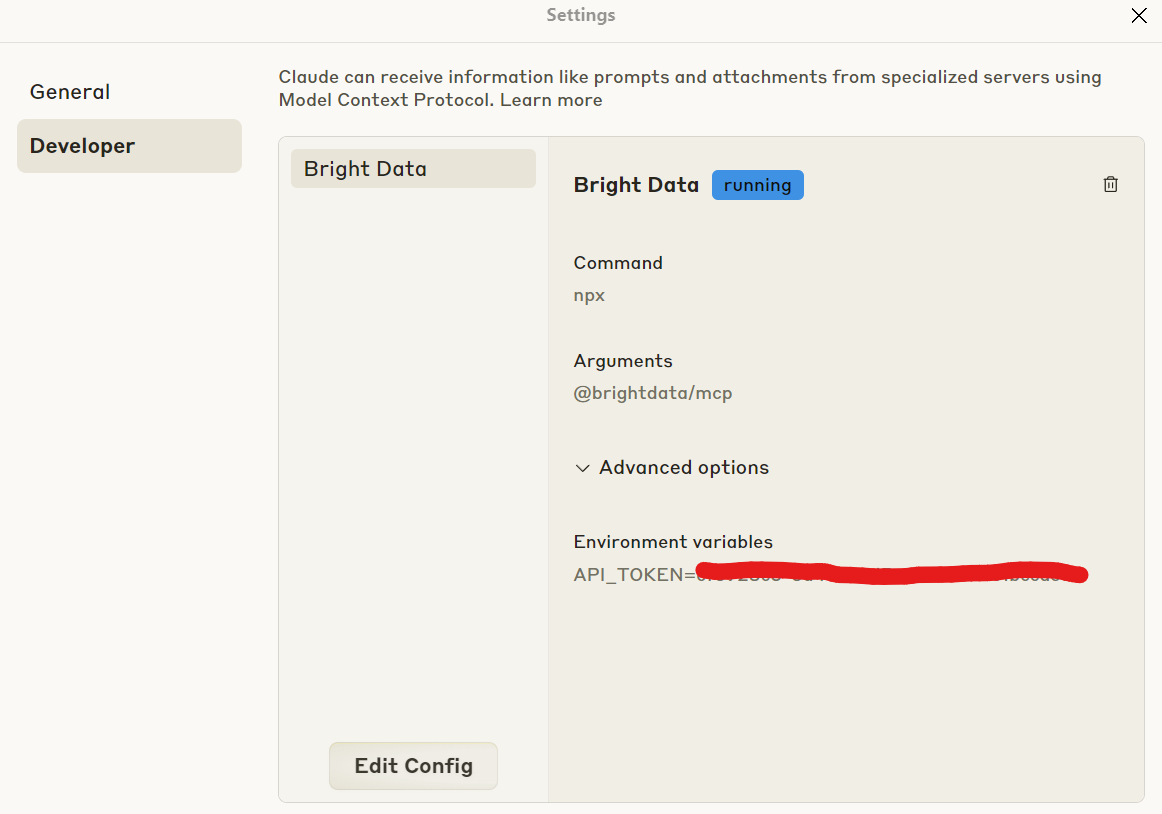
From Claude Desktop, click “File” and choose “Settings.” Click on “Developer” and then choose “Edit Config.” Copy and paste the code below into your config file. Make sure to replace the API key and zone names with your own.
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "<your-brightdata-api-token>",
"WEB_UNLOCKER_ZONE": "<optional—override default zone name 'mcp_unlocker'>",
"BROWSER_AUTH": "<optional—enable full browser control via Scraping Browser>"
}
}
}
}After saving the config and restarting Claude, you can open up your developer settings and you should see Bright Data as an option. If you click on Bright Data to inspect your configuration, it should look similar to what you see in the image below.
Once connected, check with Claude to make sure it’s got access to the MCP Server. The prompt below should be just fine.
Are you connected to the Bright Data MCP?
If everything is hooked up, Claude should respond similarly to the image below. Claude acknowledges the connection and then explains what it can do.

Running the Actual Scrape
From this point, the job is easy. Give Claude your Target listings URL and just let it go to work. The prompt below should work just fine.
Please extract laptops from https://www.target.com/s?searchTerm=laptop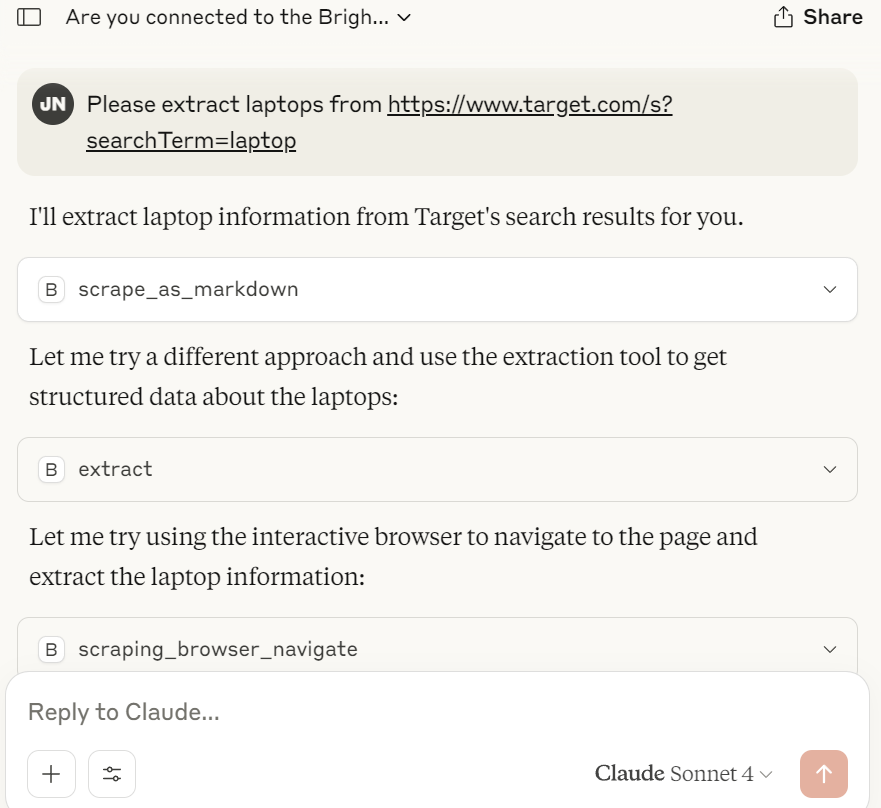
During this process, don’t be surprised if you get popups asking if Claude can use certain tools. This is a nice security feature. Claude won’t use these tools unless you explicitly give it permission.
Claude will likely ask permission to use tools like scrape_as_markdown, extract and probably a few others. Just make sure to give permission to use the tools. Without them, Claude can’t scrape the results.
Storing the Results
Next, ask Claude to store the results in a JSON file. Within seconds, Claude will be writing all the extracted results in a highly detailed, well structured JSON file.

If you choose to view the file, it should look similar to the screenshot below. Claude extracts far more detail about each product than we did initially.
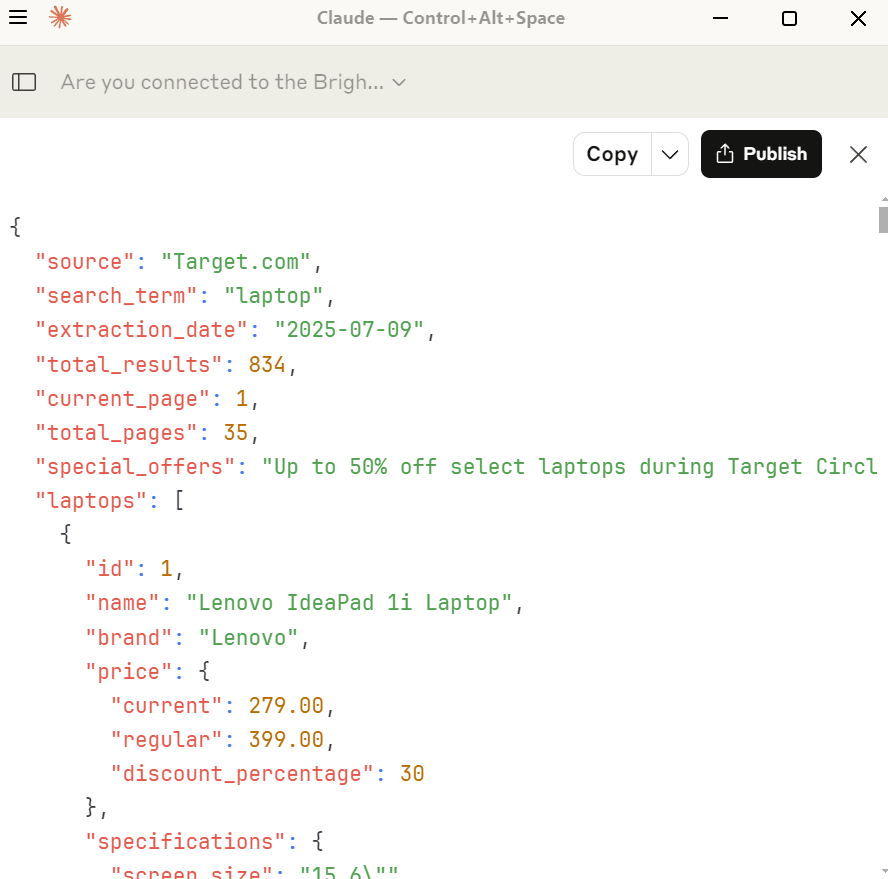
{
"source": "Target.com",
"search_term": "laptop",
"extraction_date": "2026-07-09",
"total_results": 834,
"current_page": 1,
"total_pages": 35,
"special_offers": "Up to 50% off select laptops during Target Circle week (ends 7/12)",
"laptops": [
{
"id": 1,
"name": "Lenovo IdeaPad 1i Laptop",
"brand": "Lenovo",
"price": {
"current": 279.00,
"regular": 399.00,
"discount_percentage": 30
},
"specifications": {
"screen_size": "15.6\"",
"display_type": "FHD Display",
"processor": "Intel Celeron N4500",
"graphics": "Intel UHD Graphics",
"memory": "4GB RAM",
"storage": "128GB eMMC",
"operating_system": "Windows 11 Home",
"connectivity": "Wi-Fi 6"
},
"color": "Grey",
"rating": {
"stars": 4.4,
"total_reviews": 22
},
"availability": {
"shipping": "Arrives Fri, Jul 11",
"free_shipping": true
},
"sponsored": true
},
{
"id": 2,
"name": "HP Essential Laptop",
"brand": "HP Inc.",
"price": {
"current": 489.00,
"regular": 599.00,
"discount_percentage": 18
},
"specifications": {
"screen_size": "17.3\"",
"display_type": "HD+ 1600×900 Touchscreen 60Hz",
"processor": "Intel Core i3-N305",
"graphics": "Intel UHD Graphics",
"memory": "4GB RAM",
"storage": "128GB SSD",
"operating_system": "Windows 11 Home",
"connectivity": "Wi-Fi 6"
},
"color": "Silver",
"rating": {
"stars": null,
"total_reviews": 0
},
"availability": {
"shipping": "Arrives Fri, Jul 11",
"free_shipping": true
},
"sponsored": true
},
{
"id": 3,
"name": "HP 15.6\" FHD IPS Notebook",
"brand": "HP Inc.",
"price": {
"current": 399.99,
"regular": 669.99,
"discount_percentage": 40
},
"specifications": {
"screen_size": "15.6\"",
"display_type": "FHD IPS",
"processor": "Intel Core i5-1334U",
"graphics": null,
"memory": "12GB RAM",
"storage": "512GB SSD",
"operating_system": null,
"connectivity": null
},
"color": "Natural Silver",
"rating": {
"stars": 5.0,
"total_reviews": 2
},
"availability": {
"shipping": "Arrives Sat, Jul 12",
"free_shipping": true
},
"bestseller": true,
"sponsored": false
},
{
"id": 4,
"name": "Lenovo Flex 5i 14\" WUXGA 2-in-1 Touchscreen Laptop",
"brand": "Lenovo",
"price": {
"current": 469.99,
"regular": 679.99,
"discount_percentage": 31
},
"specifications": {
"screen_size": "14\"",
"display_type": "WUXGA 2-in-1 Touchscreen",
"processor": "Intel Core i5-1235U",
"graphics": "Intel Iris Xe Graphics",
"memory": "8GB RAM",
"storage": "512GB SSD",
"operating_system": "Windows 11 Home",
"connectivity": null
},
"color": null,
"rating": {
"stars": 4.3,
"total_reviews": 3
},
"availability": {
"shipping": "Arrives Fri, Jul 11",
"free_shipping": true
},
"sponsored": false
},
{
"id": 5,
"name": "HP Envy x360 14\" Full HD 2-in-1 Touchscreen Laptop",
"brand": "HP Inc.",
"price": {
"current": 569.99,
"regular": 799.99,
"discount_percentage": 29
},
"specifications": {
"screen_size": "14\"",
"display_type": "Full HD 2-in-1 Touchscreen",
"processor": "Intel Core 5 120U",
"graphics": null,
"memory": "8GB RAM",
"storage": "512GB SSD",
"operating_system": "Windows 11 Home",
"connectivity": null
},
"color": null,
"rating": {
"stars": 4.3,
"total_reviews": 152
},
"availability": {
"shipping": "Arrives Fri, Jul 11",
"free_shipping": true
},
"sponsored": false
},
{
"id": 6,
"name": "HP Inc. Essential Laptop Computer",
"brand": "HP Inc.",
"price": {
"current": 419.99,
"regular": 649.99,
"discount_percentage": 35
},
"specifications": {
"screen_size": "17.3\"",
"display_type": "HD+",
"processor": "Intel Core",
"graphics": null,
"memory": "8GB RAM",
"storage": "256GB SSD",
"operating_system": null,
"connectivity": null
},
"color": null,
"rating": {
"stars": 4.4,
"total_reviews": 2222
},
"availability": {
"shipping": "Arrives Sat, Jul 12",
"free_shipping": true
},
"sponsored": false
},
{
"id": 7,
"name": "ASUS Vivobook 17.3\" FHD Daily Laptop",
"brand": "ASUS",
"price": {
"current": 429.00,
"regular": 579.00,
"discount_percentage": 26
},
"specifications": {
"screen_size": "17.3\"",
"display_type": "FHD",
"processor": "Intel Core i3",
"graphics": "Intel UHD",
"memory": "4GB RAM",
"storage": "128GB SSD",
"operating_system": "Windows 11 Home",
"connectivity": "Wi-Fi",
"features": ["HDMI", "Webcam"]
},
"color": "Blue",
"rating": {
"stars": null,
"total_reviews": 0
},
"availability": {
"shipping": "Arrives Fri, Jul 11",
"free_shipping": true
},
"sponsored": true
},
{
"id": 8,
"name": "Lenovo Legion Pro 7i 16\" WQXGA OLED 240Hz Gaming Notebook",
"brand": "Lenovo",
"price": {
"current": 2349.99,
"regular": 2649.99,
"discount_percentage": 11
},
"specifications": {
"screen_size": "16\"",
"display_type": "WQXGA OLED 240Hz",
"processor": "Intel Core Ultra 9 275HX",
"graphics": "NVIDIA GeForce RTX 5070Ti",
"memory": "32GB RAM",
"storage": "1TB SSD",
"operating_system": null,
"connectivity": null
},
"color": "Eclipse Black",
"rating": {
"stars": null,
"total_reviews": 0
},
"availability": {
"shipping": "Arrives Sat, Jul 12",
"free_shipping": true
},
"category": "Gaming",
"sponsored": false
},
{
"id": 9,
"name": "Acer 315 - 15.6\" 1920 x 1080 Chromebook",
"brand": "Acer",
"price": {
"current": 109.99,
"regular": 199.00,
"discount_percentage": 45,
"price_range": "109.99 - 219.99",
"regular_range": "199.00 - 404.99"
},
"specifications": {
"screen_size": "15.6\"",
"display_type": "1920 x 1080",
"processor": null,
"graphics": null,
"memory": null,
"storage": null,
"operating_system": "ChromeOS",
"connectivity": null
},
"color": null,
"rating": {
"stars": 3.8,
"total_reviews": 69
},
"availability": {
"shipping": null,
"free_shipping": null
},
"condition": "Manufacturer Refurbished",
"sponsored": false
},
{
"id": 10,
"name": "HP Chromebook 14\" HD Laptop",
"brand": "HP",
"price": {
"current": 219.00,
"regular": 299.00,
"discount_percentage": 27
},
"specifications": {
"screen_size": "14\"",
"display_type": "HD",
"processor": "Intel Celeron N4120",
"graphics": null,
"memory": "4GB RAM",
"storage": "64GB eMMC",
"operating_system": "Chrome OS",
"connectivity": null
},
"color": null,
"rating": {
"stars": 4.1,
"total_reviews": 40
},
"availability": {
"shipping": null,
"free_shipping": null
},
"sponsored": false
},
{
"id": 11,
"name": "HP 15.6\" Laptop - Intel Pentium N200",
"brand": "HP",
"price": {
"current": 419.99,
"regular": null,
"discount_percentage": null
},
"specifications": {
"screen_size": "15.6\"",
"display_type": null,
"processor": "Intel Pentium N200",
"graphics": null,
"memory": "8GB RAM",
"storage": "256GB SSD",
"operating_system": null,
"connectivity": null
},
"color": "Blue",
"model": "15-fd0015tg",
"rating": {
"stars": 4.0,
"total_reviews": 516
},
"availability": {
"shipping": null,
"free_shipping": null
},
"highly_rated": true,
"sponsored": false
},
{
"id": 12,
"name": "Lenovo IP 5 16IAU7 16\" Laptop 2.5K",
"brand": "Lenovo",
"price": {
"current": 268.99,
"regular": 527.99,
"discount_percentage": 49
},
"specifications": {
"screen_size": "16\"",
"display_type": "2.5K",
"processor": "i3-1215U",
"graphics": null,
"memory": "8GB RAM",
"storage": "128GB eMMC",
"operating_system": "Chrome OS",
"connectivity": null
},
"color": null,
"rating": {
"stars": 4.0,
"total_reviews": 5
},
"availability": {
"shipping": null,
"free_shipping": null
},
"condition": "Manufacturer Refurbished",
"sponsored": false
},
{
"id": 13,
"name": "Lenovo IdeaPad 3 Chrome 15IJL6 15.6\" Laptop",
"brand": "Lenovo",
"price": {
"current": 144.99,
"regular": 289.99,
"discount_percentage": 50
},
"specifications": {
"screen_size": "15.6\"",
"display_type": null,
"processor": "Celeron N4500",
"graphics": null,
"memory": "4GB RAM",
"storage": "64GB eMMC",
"operating_system": "Chrome OS",
"connectivity": null
},
"color": null,
"rating": {
"stars": 4.1,
"total_reviews": 19
},
"availability": {
"shipping": null,
"free_shipping": null
},
"condition": "Manufacturer Refurbished",
"sponsored": false
},
{
"id": 14,
"name": "Acer Chromebook 315 15.6\" HD Laptop",
"brand": "Acer",
"price": {
"current": 229.00,
"regular": 349.00,
"discount_percentage": 34
},
"specifications": {
"screen_size": "15.6\"",
"display_type": "HD",
"processor": "Intel Pentium N6000",
"graphics": null,
"memory": "4GB RAM",
"storage": "128GB eMMC",
"operating_system": "Chrome OS",
"connectivity": null
},
"color": null,
"rating": {
"stars": 4.3,
"total_reviews": 7
},
"availability": {
"shipping": null,
"free_shipping": null
},
"includes": "Protective Sleeve",
"sponsored": false
},
{
"id": 15,
"name": "Acer 315 - 15.6\" Chromebook Intel Celeron 64GB Flash",
"brand": "Acer",
"price": {
"current": 109.99,
"regular": 219.99,
"discount_percentage": 50,
"price_range": "109.99 - 152.99",
"regular_range": "219.99 - 279.99"
},
"specifications": {
"screen_size": "15.6\"",
"display_type": null,
"processor": "Intel Celeron",
"graphics": null,
"memory": null,
"storage": "64GB Flash",
"operating_system": "ChromeOS",
"connectivity": null
},
"color": null,
"rating": {
"stars": 4.0,
"total_reviews": 60
},
"availability": {
"shipping": null,
"free_shipping": null
},
"condition": "Manufacturer Refurbished",
"sponsored": false
}
],
"popular_filters": [
"Gaming",
"HP",
"Deals",
"Under $300",
"Windows"
],
"price_ranges": {
"minimum": 109.99,
"maximum": 2349.99,
"budget_under_300": true,
"mid_range_300_800": true,
"premium_800_plus": true
},
"brands_available": [
"Lenovo",
"HP",
"HP Inc.",
"ASUS",
"Acer"
],
"operating_systems": [
"Windows 11 Home",
"Chrome OS",
"ChromeOS"
],
"screen_sizes": [
"14\"",
"15.6\"",
"16\"",
"17.3\""
],
"notes": {
"shipping_policy": "Most items ship within 1-2 days with free shipping",
"promotion_end_date": "2026-07-12",
"data_completeness": "This represents page 1 of 35 total pages of results"
}
}Conclusion
Target is tough, but not impossible. Manually, you need a smart approach with a real browser, automated scrolling, waits and a proxy connection. You can also create an AI agent that knows exactly how to handle Target’s dynamic content. Bright Data’s Scraping Browser and MCP Server make it possible — whether you’re a developer or you’d rather let an AI handle the heavy lifting.
Bright Data also offers a dedicated Target Scraper API that delivers the results to your preferred storage.
Sign up for a free trial and get started today!

Technical Writer
Jacob Nulty is a Detroit-based software developer and technical writer exploring AI and human philosophy, with experience in Python, Rust, and blockchain.