

Etsy is a notoriously difficult site to scrape. They employ a variety of blocking tactics and have one of the most sophisticated bot blocking systems on the web. From detailed header analysis to a seemingly endless wave of CAPTCHAs, Etsy is the bane of web scrapers all over the world. If you can get past these roadblocks, Etsy becomes a relatively easy site to scrape.
If you can scrape Etsy, you gain access to a wealth of small business data from one of the biggest marketplaces the internet has to offer. Follow along today, and you’ll be scraping Etsy like a pro in no time. We’ll learn how to scrape all of the following page types from Etsy.
- Search Results
- Product Pages
- Shop Pages
Getting Started
Python Requests and BeautifulSoup will be our tools of choice for this tutorial. You can install them with the commands below. Requests allows us to make HTTP requests and communicate with Etsy’s servers. BeautifulSoup gives us the power to parse the web pages using Python. We suggest you read our guide on how to use BeautifulSoup for web scraping first.
Install Requests
pip install requests
Install BeautifulSoup
pip install beautifulsoup4
What to Scrape from Etsy
If you inspect an Etsy page, you might get caught in a nasty web of nested elements. If you know where to look, this is easy enough to overcome. Etsy’s pages use JSON data to render the page in the browser. If you can find the JSON, you can find all the data they used to build the page… without having to dig too deeply through the HTML of the document.
Search Results
Etsy’s search pages contain an array of JSON objects. If you look at the image below, all of this data comes inside a script element with type="application/ld+json". If you look really closely, this JSON data contains an array called itemListElement. If we can extract this array, we get all the data they used to build the page.

Product Information
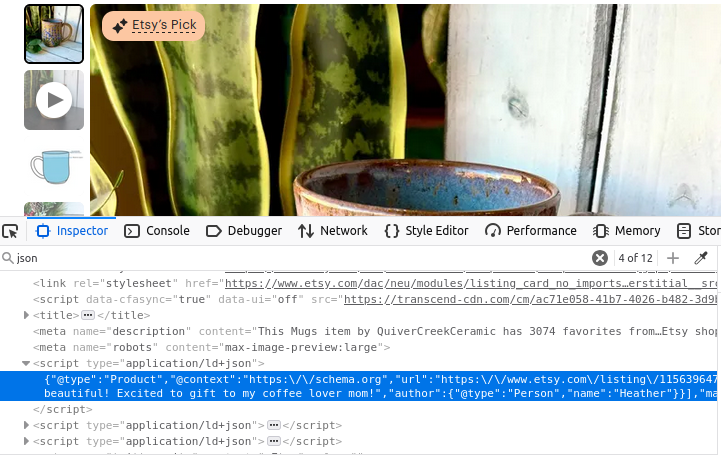
Their product pages aren’t much different. Look at the image below, once again, we’ve got a script tag with type="application/ld+json". This tag contains all the information that was used to create the product page.
Shops
You probably guessed, our shop pages are also built the same way. Find the first script object on the page with type="application/ld+json" and you’ve got your data.

How to Scrape Etsy With Python
Now, we’ll go over all the required components we need to build. As mentioned earlier, Etsy employs a variety of tactics to block us from accessing the site. We use Web Unlocker as a swiss army knife for these blocks. Not only does it manage proxy connections for us, it also solves any CAPTCHAs that come our way. You’re welcome to try without a proxy, but in our initial testing, we were unable to get past Etsy’s blocking systems without Web Unlocker.
Once you’ve got a Web Unlocker instance, you can set up your proxy connection by creating a simple dict. We use Bright Data’s SSL certificate to ensure that our data remains encrypted in transit. In the code below, we specify the path to our SSL certificate and then use our username, zone name, and password to create the proxy url. Our proxies are built by constructing a custom url that forwards all of our requests through one of Bright Data’s proxy services.
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:33335',
'https': 'http://brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:33335'
}
Search Results
To extract our search results, we make a request using our proxies. We then use BeautifulSoup to parse the incoming HTML document. We find the data inside the script tag and load it as a JSON object. Then we return the itemListElement field from the JSON.
def etsy_search(keyword):
encoded_keyword = urlencode({"q": keyword})
url = f"https://www.etsy.com/search?{encoded_keyword}"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
full_json = json.loads(script.text)
return full_json["itemListElement"]
Product Information
Our product information gets extracted basically the same way. Our only real difference is the absence of itemListElement. This time, we use our listing_id to create our url and we extract the entire JSON object.
def etsy_product(listing_id):
url = f"https://www.etsy.com/listing/{listing_id}/"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)
Shops
When extracting shops, we follow the same model we used with products. We use the shop_name to construct the url. Once we’ve got the response, we find the JSON, load it as JSON, and return the extracted page data.
def etsy_shop(shop_name):
url = f"https://www.etsy.com/shop/{shop_name}"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)
Storing the Data
Our data is neatly structured JSON as soon as we extract it. We can write our output to a file using Python’s basic file handling and json.dumps(). We write it with indent=4 so it’s clean and readable when humans look at the file.
with open("products.json", "w") as file:
json.dump(products, file, indent=4)
Putting Everything Together
Now that we know how to build our pieces, we’ll put it all together. The code below uses the functions we just wrote and returns our desired data in JSON format. We then write each of these objects to their own individual JSON files.
import requests
import json
from bs4 import BeautifulSoup
from urllib.parse import urlencode
# Proxy and certificate setup (HARD-CODED CREDENTIALS)
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:22225',
'https': 'http://brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:22225'
}
def fetch_etsy_data(url):
"""Fetch and parse JSON-LD data from an Etsy page."""
try:
response = requests.get(url, proxies=proxies, verify=path_to_cert)
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
return None
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
if not script:
print("JSON-LD script not found on the page.")
return None
try:
return json.loads(script.text)
except json.JSONDecodeError as e:
print(f"JSON parsing error: {e}")
return None
def etsy_search(keyword):
"""Search Etsy for a given keyword and return results."""
encoded_keyword = urlencode({"q": keyword})
url = f"https://www.etsy.com/search?{encoded_keyword}"
data = fetch_etsy_data(url)
return data.get("itemListElement", []) if data else None
def etsy_product(listing_id):
"""Fetch product details from an Etsy listing."""
url = f"https://www.etsy.com/listing/{listing_id}/"
return fetch_etsy_data(url)
def etsy_shop(shop_name):
"""Fetch shop details from an Etsy shop page."""
url = f"https://www.etsy.com/shop/{shop_name}"
return fetch_etsy_data(url)
def save_to_json(data, filename):
"""Save data to a JSON file with error handling."""
try:
with open(filename, "w", encoding="utf-8") as file:
json.dump(data, file, indent=4, ensure_ascii=False, default=str)
print(f"Data successfully saved to {filename}")
except (IOError, TypeError) as e:
print(f"Error saving data to {filename}: {e}")
if __name__ == "__main__":
# Product search
products = etsy_search("coffee mug")
if products:
save_to_json(products, "products.json")
# Specific item
item_info = etsy_product(1156396477)
if item_info:
save_to_json(item_info, "item.json")
# Etsy shop
shop = etsy_shop("QuiverCreekCeramic")
if shop:
save_to_json(shop, "shop.json")
Below is some sample data from products.json.
{
"@context": "https://schema.org",
"@type": "Product",
"image": "https://i.etsystatic.com/34923795/r/il/8f3bba/5855230678/il_fullxfull.5855230678_n9el.jpg",
"name": "Custom Coffee Mug with Photo, Personalized Picture Coffee Cup, Anniversary Mug Gift for Him / Her, Customizable Logo-Text Mug to Men-Women",
"url": "https://www.etsy.com/listing/1193808036/custom-coffee-mug-with-photo",
"brand": {
"@type": "Brand",
"name": "TheGiftBucks"
},
"offers": {
"@type": "Offer",
"price": "14.99",
"priceCurrency": "USD"
},
"position": 1
},
Consider Using Datasets
Our datasets offer a great alternative to web scraping. You can buy ready-to-go Etsy datasets or one of our other eCommerce datasets and eliminate your scraping process entirely! Once you’ve got an account, head over to our dataset marketplace.

Type in “Etsy” and click on the Etsy dataset.

This gives you access to millions of records from Etsy data… right at your fingertips. You can even download sample data to see what it’s like to work with.

Conclusion
In this tutorial, we explored Etsy scraping in great detail. You received a crash course in proxy integration. You know how to use Web Unlocker to get past even the most stringent of bot blockers. You know how to extract the data, and you also know how to store it. You also got a taste of our pre-made datasets that eliminate your scraping duties entirely. However you get your data, we’ve got you covered.
Sign up now and start your free trial.

Technical Writer
Jacob Nulty is a Detroit-based software developer and technical writer exploring AI and human philosophy, with experience in Python, Rust, and blockchain.





