
In this guide, you will see:
- What the Google ADK library for building AI agents is.
- Why its native support for MCP makes it special.
- How to integrate it with the Bright Data Web MCP server to build an extremely potent AI agent
Let’s dive in!
What Is Google ADK?
Google ADK, short for Google Agent Development Kit, is an open-source Python framework for building and deploying AI agents. While it is optimized for Gemini and the broader Google ecosystem, it remains model-agnostic and deployment-agnostic.
ADK emphasizes the developer experience, offering tools and data structures that make it easy to build powerful multi-agent systems. It enables you to define AI agents that can reason, collaborate, and interact with the world through tools and integrations.
The ultimate goal of Google ADK is to make agent development feel more like traditional software development. That is achieved by simplifying the process of creating, deploying, and orchestrating agentic architectures.
What Makes Google ADK Special
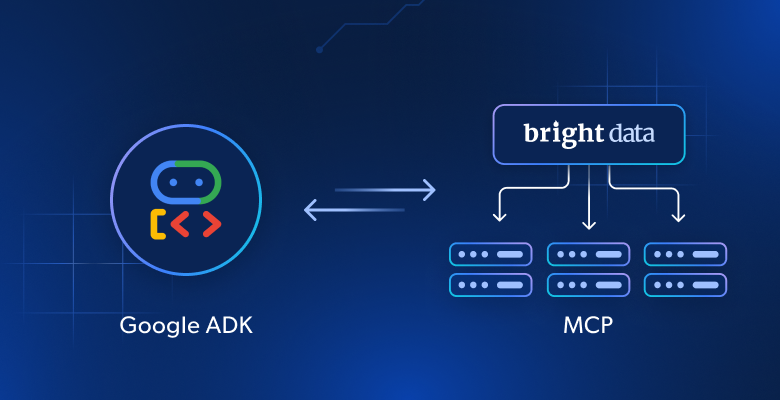
Compared to other AI agent creation libraries, Google ADK stands out with built-in support for MCP (Model Context Protocol). If you are not familiar with it, MCP is a standardized way for AI models to interact with external tools and data sources—such as APIs, databases, and file systems.
In simpler terms, MCP allows your Google ADK agent to leverage the capabilities of any MCP-compatible server. Think of it as plug-and-play integration that extends your AI agent beyond the limitations of the underlying LLM by giving it access to real-world data and actions.
That option provides a structured, secure, and scalable way to connect your agent with external capabilities—without requiring you to build those connections from scratch. MCP integration becomes especially compelling when integrated with a rich MCP server like the Bright Data Web MCP server.
That MCP server operates over Node.js and seamlessly connects to all Bright Data’s powerful AI data retrieval tools. These tools enable your agent to interact with live web data, structured datasets, and scraping capabilities.
As of this writing, the supported MCP tools are:
| Tool | Description |
|---|---|
search_engine |
Scrape search results from Google, Bing, or Yandex. Returns SERP results in markdown format (URL, title, description). |
scrape_as_markdown |
Scrape a single webpage and return the extracted content in Markdown format. Works even on bot-protected or CAPTCHA-secured pages. |
scrape_as_html |
Same as above, but returns content in raw HTML. |
session_stats |
Provides a summary of tool usage during the current session. |
web_data_amazon_product |
Retrieve structured Amazon product data using a /dp/ URL. More reliable than scraping due to caching. |
web_data_amazon_product_reviews |
Retrieve structured Amazon review data using a /dp/ URL. Cached and reliable. |
web_data_linkedin_person_profile |
Access structured LinkedIn profile data. Cached for consistency and speed. |
web_data_linkedin_company_profile |
Access structured LinkedIn company data. Cached version improves reliability. |
web_data_zoominfo_company_profile |
Retrieve structured ZoomInfo company data. Requires a valid ZoomInfo URL. |
web_data_instagram_profiles |
Structured Instagram profile data. Requires a valid Instagram URL. |
web_data_instagram_posts |
Retrieve structured data for Instagram posts. |
web_data_instagram_reels |
Retrieve structured data for Instagram reels. |
web_data_instagram_comments |
Retrieve Instagram comments as structured data. |
web_data_facebook_posts |
Access structured data for Facebook posts. |
web_data_facebook_marketplace_listings |
Retrieve structured listings from Facebook Marketplace. |
web_data_facebook_company_reviews |
Retrieve Facebook company reviews. Requires a company URL and number of reviews. |
web_data_x_posts |
Retrieve structured data from X (formerly Twitter) posts. |
web_data_zillow_properties_listing |
Access structured Zillow listing data. |
web_data_booking_hotel_listings |
Retrieve structured hotel listings from Booking.com. |
web_data_youtube_videos |
Structured YouTube video data. Requires a valid video URL. |
scraping_browser_navigate |
Navigate the scraping browser to a new URL. |
scraping_browser_go_back |
Navigate back to the previous page. |
scraping_browser_go_forward |
Navigate forward in the browser history. |
scraping_browser_click |
Click a specific element on the page. Requires element selector. |
scraping_browser_links |
Retrieve all links on the current page along with their selectors and text. |
scraping_browser_type |
Simulate typing text into an input field. |
scraping_browser_wait_for |
Wait for a specific element to become visible. |
scraping_browser_screenshot |
Take a screenshot of the current page. |
scraping_browser_get_html |
Retrieve the full HTML of the current page. Use with care if full-page content is not needed. |
scraping_browser_get_text |
Retrieve the visible text content of the current page. |
For another possible integration, see our article on web scraping using the MCP servers.
Note: New tools are regularly added to the Bright Data Web MCP server, making it increasingly powerful and feature-rich over time.
See how to take advantage of those tools with Google ADK!
How To Integrate Google ADK with the Bright Data MCP Server
In this tutorial section, you will learn how to use Google ADK to build a powerful AI agent. This will be equipped with live scraping, data retrieval, and transformation capabilities provided by the Bright Data Web MCP server.
This setup was initially implemented by Meir Kadosh, so be sure to check out his original GitHub repository.
Specifically, the AI agent will be able to:
- Retrieve URLs from search engines.
- Scrape text from those web pages.
- Generate source-based answers using the extracted data.
Note: By chaning the prompts in the code, you can easily adapt the AI agent to any other scenario or use case.
Follow the steps below to build your Bright Data MCP-powered Google ADK agent in Python!
Prerequisites
To follow this tutorial, you need:
- Python 3.9 or higher installed locally.
- Node.js installed locally.
- A UNIX-based system, such as Linux or macOS, or the WSL (Windows Subsystem for Linux).
Note: Google ADK’s integration with the Bright Data Web MCP server currently does not work natively on Windows. Attempting to run it may raise a NotImplementedError from this section of code:
transport = await self._make_subprocess_transport(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
protocol, popen_args, False, stdin, stdout, stderr,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
bufsize, **kwargs)
^^^^^^^^^^^^^^^^^^
raise NotImplementedErrorFor this reason, the tutorial assumes you are using Linux, macOS, or the WSL.
You will also need:
- A Bright Data account
- A Gemini API key
This tutorial will guide you through setting up both the Gemini and Bright Data credentials when needed. So, do not worry about them right now.
While not required, the following will help you get the most out of this tutorial:
- A general idea of how the MCP functions.
- A basic understanding of how Google ADK works.
- Familiarity with the Bright Data Web MCP server and its available tools.
- Some experience with asynchronous programming in Python.
Step #1: Project Setup
Open your terminal and create a new folder for your scraping agent:
mkdir google_adk_mcp_agentThe google_adk_mcp_agent folder will contain all the code for your Python AI agent.
Next, navigate into the project folder and create a virtual environment inside it:
cd google_adk_mcp_agent
python3 -m venv .venvOpen the project folder in your preferred Python IDE. We recommend using Visual Studio Code with the Python extension or PyCharm Community Edition.
Inside google_adk_mcp_agent, create a subfolder named web_search_agent. This subfolder will contain the core logic of your agent and should include the following two files:
__init__.py: Exports the logic fromagent.py.agent.py: Contains the Google ADK agent definition.
This is the folder structure required for the Google ADK library to function properly:

Now, initialize the __init__.py file with the following line:
from . import agentInstead, agent.py will be defined with the agent AI agent logic soon.
In the IDE’s terminal, activate the virtual environment. In Linux or macOS, execute this command:
./.venv/bin/activateEquivalently, on Windows, launch:
.venv/Scripts/activateYou are all set! You now have a Python environment to build an AI agent using the Google ADK and the Bright Data Web MCP server.
Step #2: Set Up Environment Variables Reading
Your project will interact with third-party services like Gemini and Bright Data. Rather than hardcoding API keys and authentication secrets directly into your Python code, it is best practice to load them from environment variables.
To simplify that task, we will use the python-dotenv library. With your virtual environment activated, install it by running:
pip install python-dotenvIn your agent.py file, import the library and load the environment variables with load_dotenv():
from dotenv import load_dotenv
load_dotenv()This allows you to read variables from a local .env file. Thus, add a .env file to your nested agent directory:

You can now read environment variables in your code with this line of code:
env_value = os.getenv("<ENV_NAME>")Do not forget to import the os module from the Python standard library:
import osGreat! You are now ready to read secrets from the env for securely integrating with third-party services.
Step #3: Get Started With Google ADK
In your virtual environment activated, install the Google ADK Python library by running:
pip install google-adk==0.5.0Then, open agent.py and add the following imports:
from google.adk.agents import Agent, SequentialAgent
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset, StdioServerParametersThese will be used in the next steps for Google ADK integration.
Now, keep in mind that Google ADK requires integration with an AI provider. Here, we will use Gemini—as the library is optimized for Google’s AI models.
If you have not obtained your API key yet, follow Google’s official documentation. Log in to your Google account and access Google AI Studio. Then navigate to the “Get API Key” section, and you will see this modal:

Click the “Get API key” button. In the next screen, press the “Create API key” button:

Once generated, you will see your key displayed in a modal:

Copy the key and store it in a safe place. Note that with the same key, you can perform web scraping with Gemini.
Note: The free Gemini tier is sufficient for this tutorial. The paid tier is only needed if you require higher rate limits or do not want your prompts and responses to be used to improve Google products. Refer to the Gemini billing page.
Now, initialize your .env file with the following environment variables:
GOOGLE_GENAI_USE_VERTEXAI="False"
GOOGLE_API_KEY="<YOUR_GEMINI_API_KEY>"Replace <YOUR_GEMINI_API_KEY> with the actual key you just generated. No additional code is required in agent.py as the google-adk library automatically looks for the GOOGLE_API_KEY environment variable.
Similarly, the GOOGLE_GENAI_USE_VERTEXAI setting determines whether Google ADK should integrate with Vertex AI. Set it to "False" to use the Gemini API directly instead.
Amazing! You can now use the Gemini in Google ADK. Let’s continue with the initial setup of the thrid-party solution required for the integration.
Step #4: Set Up the Bright Data MCP Server
If you have not already, [create a Bright Data account](). If you already have one, simply log in.
Next, follow the official instructions to:
- Retrieve your Bright Data API token.
- Configure Web Unlocker and Scraping Browser for MCP integration.
You will end up with:
- A Bright Data API token.
- A Web Unlocker zone (here, we will assume this has the default name, which is
mcp_unlocker). - Scraping Browser authentication credentials in the format:
<BRIGHT_DATA_SB_USERNAME>:<BRIGHT_DATA_SB_PASSWORD>.
You are now ready to install the Bright Data Web MCP server globally in your Node.js environment with:
npm install -g @brightdata/mcpThen, launch the MCP server via @brightdata/mcp npm package with:
API_TOKEN="<YOUR_BRIGHT_DATA_API_TOKEN>"
BROWSER_AUTH="<BRIGHT_DATA_SB_USERNAME>:<BRIGHT_DATA_SB_PASSWORD>"
npx -y @brightdata/mcpThe above command sets the required environment variables (API_TOKEN and BROWSER_AUTH) and starts the MCP server locally. If everything is set up correctly, you should see output indicating the server is running successfully:
Checking for required zones...
Required zone "mcp_unlocker" already exists
Starting server...Terrific! The Bright Data Web MCP server works like a charm.
Add those environment variables to your .env file in the root of your Google ADK project:
BRIGHT_DATA_API_TOKEN="<YOUR_BRIGHT_DATA_API_TOKEN>"
BRIGHT_DATA_BROWSER_AUTH="<BRIGHT_DATA_SB_USERNAME>:<BRIGHT_DATA_SB_PASSWORD>"Replace the placeholders with the actual values.
Next, read those envs in your code with:
BRIGHT_DATA_API_TOKEN = os.getenv("BRIGHT_DATA_API_TOKEN")
BRIGHT_DATA_BROWSER_AUTH = os.getenv("BRIGHT_DATA_BROWSER_AUTH")Perfect! You now have everything set up to integrate the Bright Data Web MCP server with Google ADK. But first, time to define the AI agents.
Step #5: Define the Agents
As mentioned in the introduction, the MCP-powered Google ADK agent will act as a content summarization agent. Its primary goal is to take a user’s input and return a high-quality, well-sourced summary.
In detail, the agent will follow this workflow:
- Interpret the user’s request and break it down into Google-style search queries.
- Process the search queries using a sub-agent that:
- Leverages the
search_enginetool from the Bright Data Web MCP server to retrieve relevant links from Google SERPs via the SERP API. - Passes the most relevant URLs to Scraping Browser, which navigates to those pages and extracts textual content.
- Extracts and understands the key insights from the scraped content.
- Leverages the
- Generate a Markdown report in response to the user’s original query. The process will use the freshly gathered content as a source and include links for further reading.
Since the process naturally breaks into three distinct stages, it makes sense to split the top-level AI agent into three sub-agents:
- Planner: Converts complex topics into well-formed search queries.
- Researcher: Executes the searches and extracts meaningful information from the resulting web pages.
- Publisher: Synthesizes the research into a well-written and structured document.
Implement these three agents in Google ADK using the following Python code:
- Planner:
def create_planner_agent():
return Agent(
name="planner",
model="gemini-2.0-flash",
description="Breaks down user input into focused search queries for research purposes.",
instruction="""
You are a research planning assistant. Your task is to:
1. Analyze the user's input topic or question.
2. Break it down into 3 to 5 focused and diverse search engine-like queries that collectively cover the topic.
3. Return your output as a JSON object in the following format:
{
"queries": ["query1", "query2", "query3"]
}
IMPORTANT:
- The queries should be phrased as if typed into a search engine.
""",
output_key="search_queries"
)- Researcher:
def create_researcher_agent(mcp_tools):
return Agent(
name="researcher",
model="gemini-2.0-flash",
description="Performs web searches and extracts key insights from web pages using the configured tools.",
instruction="""
You are a web research agent. Your task is to:
1. Receive a list of search queries from the planner agent.
2. For each search query, apply the `search_engine` tool to get Google search results.
3. From the global results, select the top 3 most relevant URLs.
4. Pass each URL to the `scraping_browser_navigate` tool.
5. From each page, use the `scraping_browser_get_text` tool to extract the main page content.
6. Analyze the extracted text and summarize the key insights in the following JSON format:
[
{
"url": "https://example.com",
"insights": [
"Main insight one",
"Main insight two"
]
},
...
]
IMPORTANT:
- You are only allowed to use the following tools: `search_engine`, `scraping_browser_navigate`, and `scraping_browser_get_text`.
""",
tools=mcp_tools
)Note: The mcp_tools input argument is a list that specifies which MCP tools the agent can interact with. In the next step, you will see how to populate this list using the tools provided by the Bright Data Web MCP server.
- Publisher:
def create_publisher_agent():
return Agent(
name="publisher",
model="gemini-2.0-flash",
description="Synthesizes research findings into a comprehensive, well-structured final document.",
instruction="""
You are an expert writer. Your task is to take the structured research output from the scraper agent and craft a clear, insightful, and well-organized report.
GUIDELINES:
- Use proper Markdown-like structure: title (#), subtitle, introduction, chapters (##), subchapters (###), and conclusion (##).
- Integrate contextual links (where needed) using the URLs from the output of the researcher agent.
- Maintain a professional, objective, and informative tone.
- Go beyond restating findings—synthesize the information, connect ideas, and present them as a coherent narrative.
"""
)Note that each AI agent prompt corresponds to one specific step in the overall 3-step workflow. In other words, each sub-agent is responsible for a distinct task within the process.
Step #6: Add the MCP Integration
As mentioned in the previous step, the research agent depends on the tools exported by the Bright Data Web MCP server. Retrieve them with this function:
async def initialize_mcp_tools():
print("Connecting to Bright Data MCP...")
tools, exit_stack = await MCPToolset.from_server(
connection_params=StdioServerParameters(
command='npx',
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_TOKEN,
"BROWSER_AUTH": BRIGHT_DATA_BROWSER_AUTH,
}
)
)
print(f"MCP Toolset created successfully with {len(tools)} tools")
tool_names = [tool.name for tool in tools]
print(f"Available tools include: {', '.join(tool_names)}")
print("MCP initialization complete!")
return tools, exit_stackTo load the MCP tools, Google ADK provides the MCPToolset.from_server() function. This method accepts the command used to start the MCP server, along with any required environment variables. In this case, the command configured in the code corresponds to the command you used in Step #4 to test the MCP server locally.
⚠️ Warning: Configuring MCP tools and mentioning them in your agent prompts does not guarantee that the library will actually use them. It is ultimately up to the LLM to decide whether those tools are necessary to accomplish the task. Keep in mind that the MCP integration in Google ADK is still in its early stages and may not always behave as expected.
Nice work! All that is left is to call this function and integrate the resulting tools into an agent that runs your sub-agents sequentially.
Step #7: Create the Root Agent
Google ADK supports several types of agents. In this case, your workflow follows a clear sequence of steps, so a root sequential agent is the right choice. You can define one like this:
async def create_root_agent():
# Load the MCP tools
mcp_tools, exit_stack = await initialize_mcp_tools()
# Define an agent that applies the configured sub-agents sequentially
root_agent = SequentialAgent(
name="web_research_agent",
description="An agent that researches topics on the web and creates comprehensive reports.",
sub_agents=[
create_planner_agent(),
create_researcher_agent(mcp_tools),
create_publisher_agent(),
]
)
return root_agent, exit_stackTo make this work, Google ADK expects you to define a root_agent variable in your agent.py file. Achieve that with:
root_agent = create_root_agent()Note: Do not worry about calling an async function without await here. That is the recommended approach in the official Google ADK docs. Thus, the framework will handle the asynchronous execution for you.
Great job! Your integration between the Bright Data Web MCP server and Google ADK is now complete.
Step #8: Put It All Together
Your agent.py file should now contain:
from dotenv import load_dotenv
import os
from google.adk.agents import Agent, SequentialAgent
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset, StdioServerParameters
# Load the environment variables from the .env file
load_dotenv()
# Read the envs for integration with the Bright Data Web MCP server
BRIGHT_DATA_API_TOKEN = os.getenv("BRIGHT_DATA_API_TOKEN")
BRIGHT_DATA_BROWSER_AUTH = os.getenv("BRIGHT_DATA_BROWSER_AUTH")
# Define the functions for the creation of the required sub-agents
def create_planner_agent():
return Agent(
name="planner",
model="gemini-2.0-flash",
description="Breaks down user input into focused search queries for research purposes.",
instruction="""
You are a research planning assistant. Your task is to:
1. Analyze the user"s input topic or question.
2. Break it down into 3 to 5 focused and diverse search engine-like queries that collectively cover the topic.
3. Return your output as a JSON object in the following format:
{
"queries": ["query1", "query2", "query3"]
}
IMPORTANT:
- The queries should be phrased as if typed into a search engine.
""",
output_key="search_queries"
)
def create_researcher_agent(mcp_tools):
return Agent(
name="researcher",
model="gemini-2.0-flash",
description="Performs web searches and extracts key insights from web pages using the configured tools.",
instruction="""
You are a web research agent. Your task is to:
1. Receive a list of search queries from the planner agent.
2. For each search query, apply the `search_engine` tool to get Google search results.
3. From the global results, select the top 3 most relevant URLs.
4. Pass each URL to the `scraping_browser_navigate` tool.
5. From each page, use the `scraping_browser_get_text` tool to extract the main page content.
6. Analyze the extracted text and summarize the key insights in the following JSON format:
[
{
"url": "https://example.com",
"insights": [
"Main insight one",
"Main insight two"
]
},
...
]
IMPORTANT:
- You are only allowed to use the following tools: `search_engine`, `scraping_browser_navigate`, and `scraping_browser_get_text`.
""",
tools=mcp_tools
)
def create_publisher_agent():
return Agent(
name="publisher",
model="gemini-2.0-flash",
description="Synthesizes research findings into a comprehensive, well-structured final document.",
instruction="""
You are an expert writer. Your task is to take the structured research output from the scraper agent and craft a clear, insightful, and well-organized report.
GUIDELINES:
- Use proper Markdown-like structure: title (#), subtitle, introduction, chapters (##), subchapters (###), and conclusion (##).
- Integrate contextual links (where needed) using the URLs from the output of the researcher agent.
- Maintain a professional, objective, and informative tone.
- Go beyond restating findings—synthesize the information, connect ideas, and present them as a coherent narrative.
"""
)
# To load the MCP tools exposed by the Bright Data Web MCP server
async def initialize_mcp_tools():
print("Connecting to Bright Data MCP...")
tools, exit_stack = await MCPToolset.from_server(
connection_params=StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_TOKEN,
"BROWSER_AUTH": BRIGHT_DATA_BROWSER_AUTH,
}
)
)
print(f"MCP Toolset created successfully with {len(tools)} tools")
tool_names = [tool.name for tool in tools]
print(f"Available tools include: {", ".join(tool_names)}")
print("MCP initialization complete!")
return tools, exit_stack
# Define the root agent required by Google ADK to start
async def create_root_agent():
# Load the MCP tools
mcp_tools, exit_stack = await initialize_mcp_tools()
# Define an agent that applies the configured sub-agents sequentially
root_agent = SequentialAgent(
name="web_research_agent",
description="An agent that researches topics on the web and creates comprehensive reports.",
sub_agents=[
create_planner_agent(),
create_researcher_agent(mcp_tools),
create_publisher_agent(),
]
)
return root_agent, exit_stack
# Google ADK will load the root agent in the web UI or CLI
root_agent = create_root_agent()In the root folder of your project, and with the virtual environment enabled, launch your AI agent in a web UI with:
adk webThe following application will start on http://localhost:8000:

After running your first request, the Google ADK library will attempt to access the root_agent variable. This will trigger the create_root_agent() function, which in turn calls initialize_mcp_tools().
As a result, in the terminal, you will see:
Connecting to Bright Data MCP...
Checking for required zones...
Required zone "mcp_unlocker" already exists
Starting server...
MCP Toolset created successfully with 30 tools
Available tools include: search_engine, scrape_as_markdown, scrape_as_html, session_stats, web_data_amazon_product, web_data_amazon_product_reviews, web_data_linkedin_person_profile, web_data_linkedin_company_profile, web_data_zoominfo_company_profile, web_data_instagram_profiles, web_data_instagram_posts, web_data_instagram_reels, web_data_instagram_comments, web_data_facebook_posts, web_data_facebook_marketplace_listings, web_data_facebook_company_reviews, web_data_x_posts, web_data_zillow_properties_listing, web_data_booking_hotel_listings, web_data_youtube_videos, scraping_browser_navigate, scraping_browser_go_back, scraping_browser_go_forward, scraping_browser_links, scraping_browser_click, scraping_browser_type, scraping_browser_wait_for, scraping_browser_screenshot, scraping_browser_get_text, scraping_browser_get_html
MCP initialization complete!As you can see, Google ADK loaded the 30 Bright Data MCP tools correctly.
Now, after entering a request in the chat, the AI agent will:
- Convert your request into search-engine-style keyphrases.
- Send those keyphrases to the
search_engineMCP tool to:- Retrieve the top-ranking pages for the keyphrases.
- Select the top 3 most relevant results.
- Use the
scraping_browser_navigatetool to visit those URLs. - Extract their content using
scraping_browser_get_text. - Summarize the extracted text into key, actionable insights.
- Generate a contextually relevant article or report based on those insights to answer your query.
Note that, as mentioned in Step #6, Gemini (or any other LLM) may sometimes skip MCP tools entirely. That is true even if they are configured in the code and explicitly mentioned in the sub-agent prompts. In detail, it might return a direct response or run sub-agents without using the recommended MCP tools.
To avoid that side effect, tweak your sub-agent prompts carefully. Also, remember that MCP integration in Google ADK is still evolving and may not always behave as expected. Thus, make sure the library is up to date.
Now, suppose you want to know the biography of the recently elected Pope. Normally, LLMs would struggle with current-event queries. But thanks to Bright Data’s SERP API and web scraping capabilities, your AI agent can fetch and summarize real-time information effortlessly:

Et voilà! Mission complete.
Conclusion
In this blog post, you learned how to use the Google ADK framework in combination with the Bright Data MCP to build a powerful AI agent in Python.
As demonstrated, combining a feature-rich MCP server with Google ADK allows you to create AI agents capable of retrieving real-time data from the web and much more. This is just one example of how Bright Data’s tools and services can empower advanced, AI-driven automation.
this is a test quote
Explore our solutions for AI agent development:
- Autonomous AI agents: Search, access, and interact with any website in real-time using a powerful set of APIs.
- Vertical AI apps: Build reliable, custom data pipelines to extract web data from industry-specific sources.
- Foundation models: Access compliant, web-scale datasets to power pre-training, evaluation, and fine-tuning.
- Multimodal AI: Tap into the world’s largest repository of images, videos, and audio—optimized for AI.
- Data providers: Connect with trusted providers to source high-quality, AI-ready datasets at scale.
- Data packages: Get curated, ready-to-use, structured, enriched, and annotated datasets.
For more information, explore our AI hub.
Create a Bright Data account and try all our products and services for AI agent development!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.




