
In this tutorial, you will learn:
- What Flyte is and what makes it special for AI, data, and machine learning workflows.
- Why Flyte workflows become even more powerful when you incorporate web data into them.
- How to integrate Flyte with the Bright Data SDK to build an AI-powered workflow for SEO analysis.
Let’s dive in!
What Is Flyte?
Flyte is a modern, open-source workflow orchestration platform that helps you create production-grade AI, data, and machine learning pipelines. Its main strength lies in unifying teams and technology stacks, fostering collaboration between data scientists, ML engineers, and developers.
Built on Kubernetes, Flyte is built for scalability, reproducibility, and distributed processing. You can use it to define workflows via its Python SDK. Then, deploy them in cloud or on-premises environments, opening the door to efficient resource utilization and simplified workflow management.
At the time of writing, the Flyte GitHub repository boasts over 6.5k stars!
Core Features
The main features supported by Flyte are:
- Strongly typed interfaces: Define data types at every step to ensure correctness and enforce data guardrails.
- Immutability: Immutable executions guarantee reproducibility by preventing changes to a workflow’s state.
- Data lineage: Track the movement and transformation of data across the entire workflow lifecycle.
- Map tasks and parallelism: Execute tasks in parallel efficiently with minimal configuration.
- Granular reruns and failure recovery: Retry only failed tasks or rerun specific tasks without altering previous workflow states.
- Caching: Cache task outputs to optimize repeated executions.
- Dynamic workflows and branching: Build adaptable workflows that evolve based on requirements and selectively execute branches.
- Language flexibility: Develop workflows using Python, Java, Scala, JavaScript SDKs, or raw containers in any language.
- Cloud-native deployment: Deploy Flyte on AWS, GCP, Azure, or other cloud providers.
- Dev-to-prod simplicity: Move workflows from development or staging to production with no effort.
- External input handling: Pause execution until required inputs are available.
To explore all capabilities, refer to the official Flyte docs.
Why AI Workflows Need Fresh Web Data
AI workflows are only as powerful as the data they process. Sure, open data is valuable, but access to real-time data is what makes the difference from a business perspective. And what is the biggest and richest source of data? The web!
By incorporating real-time web data into your AI workflows, you can gain deeper insights, improve prediction accuracy, and make more informed decisions. For example, tasks such as SEO analysis, market research, or brand sentiment tracking all rely on up-to-date information, which is constantly changing online.
The problem is that getting fresh web data is challenging. Websites have different structures, require different scraping approaches, and are subject to frequent updates. This is where a solution like the Bright Data Python SDK comes in!
The SDK lets you search, scrape, and interact with live web content programmatically. More specifically, it provides access to the most useful products in the Bright Data infrastructure through just a few simple method calls. This makes accessing web data both reliable and scalable.
By combining Flyte’s and Bright Data’s web capabilities, you can create automated AI workflows that stay up-to-date with the constantly changing web. See how in the next chapter!
How to Build an SEO AI Workflow in Flyte and Bright Data Python SDK
In this guided section, you will learn how to build an AI agent in Flyte that:
- Takes a keyword (or keyphrase) as input and uses the Bright Data SDK to search the web for relevant results.
- Utilizes the Bright Data SDK to scrape the top 3 pages for the given keyword.
- Passes the content of the resulting pages to OpenAI to generate a Markdown report with SEO insights.
In other words, thanks to the Flyte + Bright Data integration, you will craft a real-world AI workflow for SEO analysis. This provides actionable, content-related insights based on what top-performing pages are doing to rank well.
Let’s get started!
Prerequisites
To follow along with this tutorial, make sure you have:
- Python installed locally
- A Bright Data API key (with Admin permissions)
- An OpenAI API key
You will be guided through setting up your Bright Data account for use with the Bright Data Python SDK, so no need to worry about that right now. For more information, take a look at the documentation.
The official Flyte installation guide recommends installing via uv. So, install/update uv globally with:
pip install -U uvStep #1: Project Setup
Open a terminal and create a new directory for your SEO analysis AI project:
mkdir flyte-seo-workflowThe flyte-seo-workflow/ folder will contain the Python code for your Flyte workflow.
Next, navigate into the project directory:
cd flyte-seo-workflowAs of this writing, Flyte supports only Python versions >=3.9 and <3.13 (version 3.12 is recommended).
Set up a virtual environment for Python 3.12 with:
uv venv --python 3.12Activate the virtual environment. In Linux or macOS, execute:
source .venv/bin/activateEquivalently, on Windows, run:
.venv/Scripts/activateAdd a new file called workflow.py. Your project should now contain:
flyte-seo-workflow/
├── .venv/
└── workflow.pyworkflow.py represents your main Python file.
With the virtual environment activated, install the required dependencies:
uv pip install flytekit brightdata-sdk openaiThe libraries you just installed are:
flytekit: To author Flyte workflows and tasks.brightdata-sdk: To help you access Bright Data’s solutions in Python.openai: To interact with OpenAI’s LLMs.
Note: Flyte provides an official ChatGPT connector (ChatGPTTask), but this relies on an older version of the OpenAI APIs. It also comes with some limitations, such as strict timeouts. For these reasons, it is generally better to proceed with a custom integration.
Load the project in your favorite Python IDE. We recommend Visual Studio Code with the Python extension or PyCharm Community Edition.
Done! You now have a Python environment ready for AI workflow development in Flyte.
Step #2: Devise Your AI Workflow
Before jumping straight into coding, it is helpful to take a step back and think about what your AI workflow needs to do.
First, remember that a Flyte workflow consists of:
- Tasks: Functions marked with the
@taskannotation. These are the fundamental units of compute in Flyte. Tasks are independently executable, strongly typed, and containerized building blocks that make up workflows. - Workflows: Marked with
@workflow, workflows are constructed by chaining tasks together, with the output of one task feeding into the input of the next to form a directed acyclic graph (DAG).
In this case, you can achieve your goal with the following three simple tasks:
get_seo_urls: Given an input keyword or keyphrase, use the Bright Data SDK to retrieve the top 3 URLs from the resulting Google SERP (Search Engine Results Page).get_content_pages: Receives the URLs as input and uses the Bright Data SDK to scrape the pages, returning their content in Markdown format (which is ideal for AI processing).generate_seo_report: Gets the page content list and passes it to a prompt, asking it to produce a Markdown report containing SEO insights, such as common approaches, key statistics (number of words, paragraphs, H1s, H2s, etc.), and other relevant metrics.
Prepare to implement the Flyte tasks and workflow by importing them from flytekit:
from flytekit import task, workflowWonderful! Now, all that remains is to implement the actual workflow.
Step #3: Manage the API Keys
Before implementing the tasks, you need to take care of API key management for OpenAI and Bright Data integrations.
Flyte comes with a dedicated secrets management system, which enables you to securely handle secrets in your scripts, such as API keys and credentials. In production, relying on Flyte’s secrets management system is best practice and highly recommended.
For this tutorial, since we are working with a simple script, we can simplify things by setting the API keys directly in the code:
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHTDATA_API_TOKEN>"Replace the placeholders with your actual API key values:
<YOUR_OPENAI_API_KEY>→ Your OpenAI API key.<YOUR_BRIGHT_DATA_API_TOKEN>→ Your Bright Data API token (retrieve it as explained in the official Bright Data guide)
Keep in mind that it is recommended to use a Bright Data API key with admin permissions. This allows the Bright Data Python SDK to automatically connect to your account and set up the required products when initializing the client.
In other words, the Bright Data Python SDK with an admin API key will automatically set up your account with everything it needs to operate.
Remember: Never hardcode secrets in production scripts! Always use a secrets manager in Flyte.
Step #4: Implement the get_seo_urls Task
Define a get_seo_urls() function that accepts a keyword as a string, and annotate it with @task so it becomes a valid Flyte task. Inside the function, use the search() method from the Bright Data Python SDK to perform a web search.
Behind the scenes, search() calls the Brigh Data SERP API, which returns the search results as a JSON string with this format:
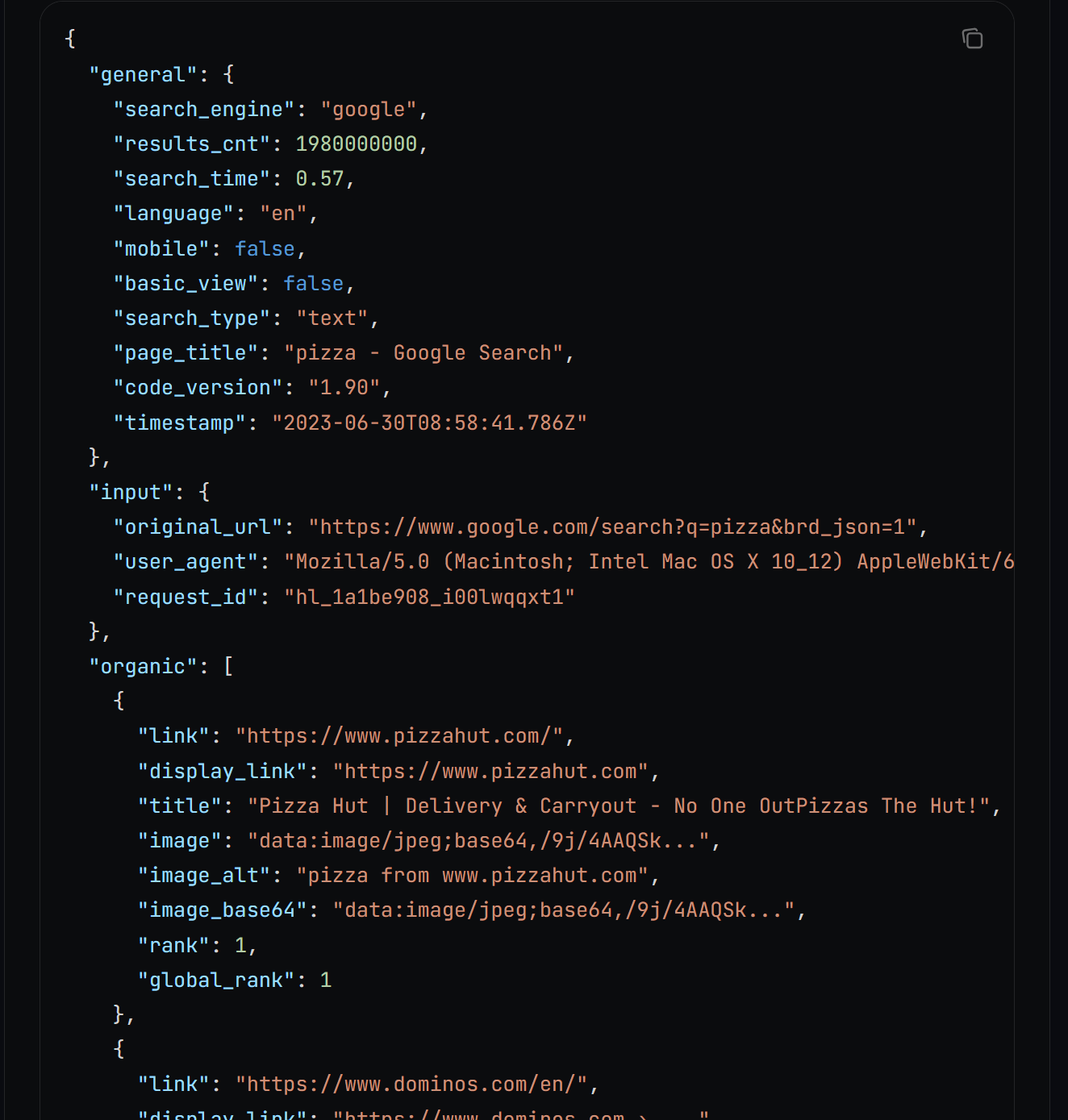
Learn more about the JSON output feature in the docs.
Parse the JSON string into a dictionary and extract a given number of SEO URLs. These URLs correspond to the top X results you would normally get from Google when searching for the input keyword.
Implement the task with:
@task()
def get_seo_urls(kw: str, num_links: int = 3) -> List[str]:
import json
# Initialize the Bright Data SDK client
from brightdata import bdclient
bright_data_client = bdclient()
# Get the Google SERP for the given keyword as a parsed JSON string
res = bright_data_client.search(kw, response_format="json", parse=True)
json_response = res["body"]
data = json.loads(json_response)
# Extract the top "num_links" SEO page URLs from the SERP
seo_urls = [item["link"] for item in data["organic"][:num_links]]
return seo_urlsRemember the required import for typing:
from typing import ListNote: You may be wondering why the Bright Data Python SDK client is imported inside the task rather than globally. This is intentional, as Flyte tasks should be independently executable. In other terms, each task must include everything it needs to run on its own, without relying on global dependencies.
Step #5: Implement the get_content_pages Task
Now that you have retrieved the SEO URLs, you can pass them to the scrape() method from the Bright Data Python SDK. This method scrapes all the pages in parallel and returns their content. To receive the output in Markdown format, simply set the data_format="markdown" argument:
@task()
def get_content_pages(page_urls:List[str]) -> List[str]:
# Initialize the Bright Data SDK client
from brightdata import bdclient
bright_data_client = bdclient()
# Get the Markdown content from each page
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_listpage_content_list will be a list of strings, where each string is the Markdown representation of the corresponding input page.
Under the hood, scrape() calls the Bright Data Web Unlocker API. This is a general-purpose scraping API capable of accessing any web page, regardless of its anti-bot protections.
No matter which URLs you obtain in the previous task, get_content_pages() will successfully fetch their content and convert it from raw HTML into optimized, AI-ready Markdown.
Step #6: Implement the generate_seo_report Task
Call the OpenAI API with the appropriate prompt to generate an SEO report based on the scraped page content:
def generate_seo_report(page_content_list: List[str]) -> str:
# Initialize the OpenAI client to call the OpenAI APIs
from openai import OpenAI
openai_client = OpenAI()
# The prompt to generate the desired SEO report
prompt = f"""
# Given the content below for a few web pages,
# produce a structured report in Markdown format containing SEO insights obtained by analyzing the content of each page.
# The report should include:
# - Common topics and elements among all pages
# - Key differences between the pages
# - A summary table including statistics such as the number of words, number of paragraphs, counts of H2 and H3 headings, etc.
# CONTENT:
# {"\n\nPAGE:".join(page_content_list)}
# """
# Execute the prompt on the selected AI model
response = openai_client.responses.create(
model="gpt-5-mini",
input=prompt,
)
return response.output_textThe output of this task will be the desired SEO Markdown report.
Note: The OpenAI model used above was GPT-5-mini, but you can replace it with any other OpenAI model. Similarly, you could swap out the OpenAI integration entirely and use any other LLM provider.
Fantastic! The tasks are ready, and it is now time to combine them in a Flyte AI workflow.
Step #7: Define the AI Workflow
Create a @workflow function that orchestrates the tasks in sequence:
@workflow
def seo_ai_workflow() -> str:
input_kw = "best llms"
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
return reportIn this workflow:
- The
get_seo_urlstask retrieves the top 3 SEO URLs for the “best llms” keyphrase. - The
get_content_pagestask scrapes and converts the content of those URLs into Markdown. - The
generate_seo_reporttask takes that Markdown content and produces a final SEO insights report in Markdown format.
Mission complete!
Step #8: Put It All Together
Your final workflow.py file should contain:
from flytekit import task, workflow
import os
from typing import List
# Set the required secrets (replace them with your API keys)
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHTDATA_API_TOKEN>"
@task()
def get_seo_urls(kw: str, num_links: int = 3) -> List[str]:
import json
# Initialize the Bright Data SDK client
from brightdata import bdclient
bright_data_client = bdclient()
# Get the Google SERP for the given keyword as a parsed JSON string
res = bright_data_client.search(kw, response_format="json", parse=True)
# Parse the JSON string to convert it into a dictionary
json_response = res["body"]
data = json.loads(json_response)
# Extract the top "num_links" SEO page URLs from the SERP
seo_urls = [item["link"] for item in data["organic"][:num_links]]
return seo_urls
@task()
def get_content_pages(page_urls: List[str]) -> List[str]:
# Initialize the Bright Data SDK client
from brightdata import bdclient
bright_data_client = bdclient()
# Get the Markdown content from each page
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_list
@task
def generate_seo_report(page_content_list: List[str]) -> str:
# Initialize the OpenAI client to call the OpenAI APIs
from openai import OpenAI
openai_client = OpenAI()
# The prompt to generate the desired SEO report
prompt = f"""
# Given the content below for a few web pages,
# produce a structured report in Markdown format containing SEO insights obtained by analyzing the content of each page.
# The report should include:
# - Common topics and elements among all pages
# - Key differences between the pages
# - A summary table including statistics such as the number of words, number of paragraphs, counts of H2 and H3 headings, etc.
# CONTENT:
# {"\n\nPAGE:".join(page_content_list)}
# """
# Execute the prompt on the selected AI model
response = openai_client.responses.create(
model="gpt-5-mini",
input=prompt,
)
return response.output_text
@workflow
def seo_ai_workflow() -> str:
input_kw = "best llms" # Change it to match your SEO analysis goals
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
return report
if __name__ == "__main__":
seo_ai_workflow()Wow! In less than 80 lines of Python code, you just built a full SEO AI workflow. This would not have been possible without Flyte and the Bright Data SDK.
You can run your workflow from the CLI with:
pyflyte run workflow.py seo_ai_workflowThis command will launch the seo_ai_workflow @workflow function from the workflow.py file.
Note: The results may take a little while to appear, as web searching, scraping, and AI processing all take some time.
When the workflow completes, you should get a Markdown output similar to this:
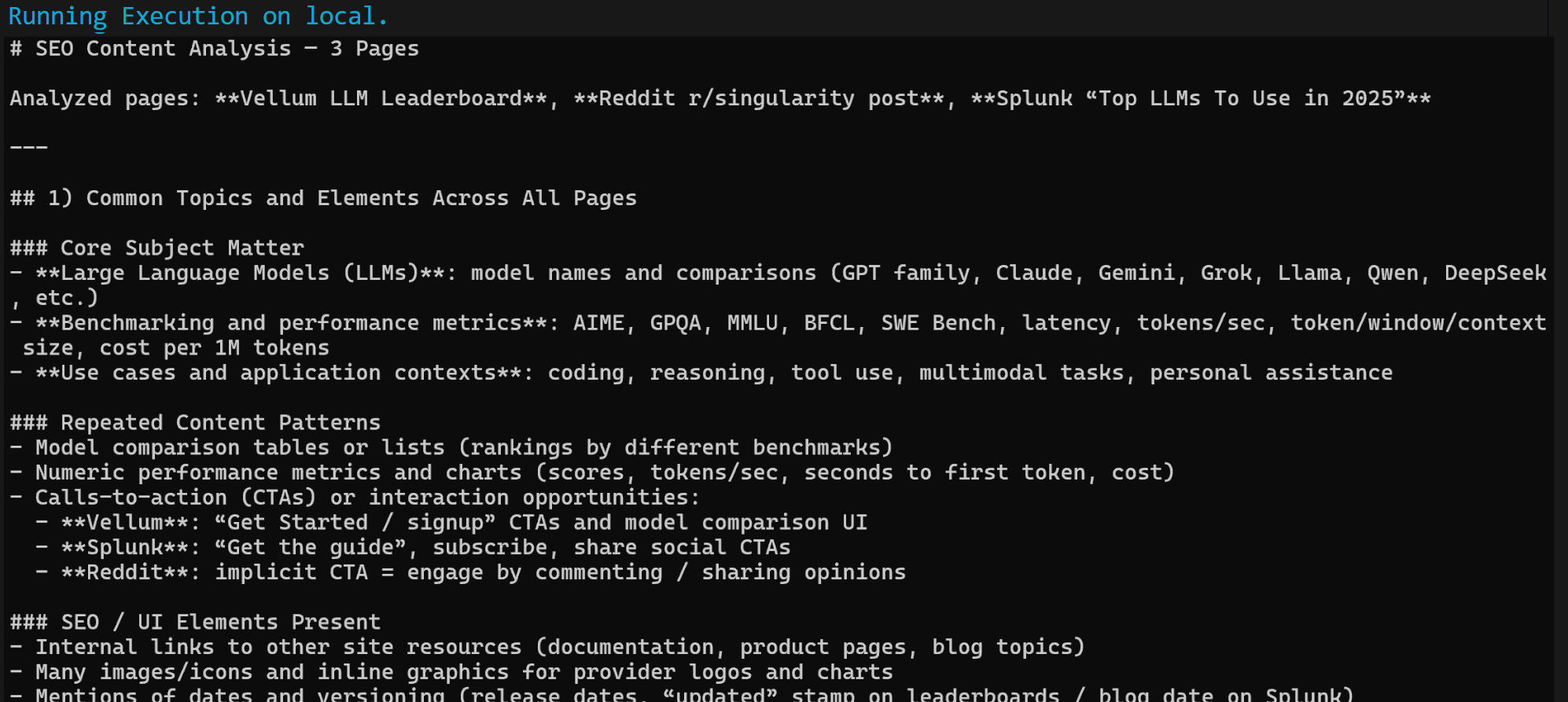
Paste the Markdown output into any Markdown viewer to scroll through and explore it. It should look something like below:
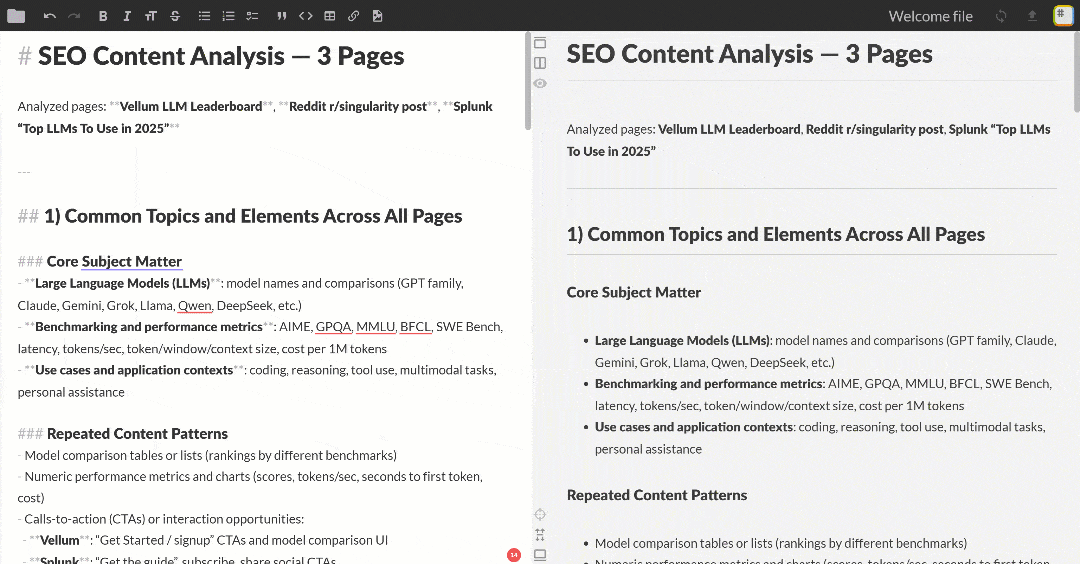
The output contains several SEO insights and a summary table, exactly as requested from OpenAI. This was just a simple example of the power of Flyte + Bright Data integration!
Et voilà! Feel free to define other tasks and try different LLMs to implement other useful agentic and AI workflow use cases.
Next Steps
The Flyte AI workflow implementation provided here is just an example. To make it production-ready, or to proceed with a proper implementation, the next steps are:
- Integrate a secrets management system supported by Flyte: Avoid hardcoding API keys in the code. Use Flyte task secrets or other supported systems to handle credentials securely and elegantly.
- Prompt handling: Generating prompts inside a task is acceptable, but for reproducibility, consider versioning your prompts or storing them externally.
- Deploy the workflow: Follow the official instructions to dockerize your workflow and prepare it for deployment using Flyte’s capabilities.
Conclusion
In this blog post, you learned how to use Bright Data’s web search and scraping capabilities within Flyte to create an AI-powered SEO analysis workflow. The implementation process was made simpler thanks to the Bright Data SDK, which provides easy access to Bright Data products through straightforward method calls.
To build more sophisticated workflows, explore the full suite of solutions in the Bright Data AI infrastructure for fetching, validating, and transforming live web data.
Sign up for a Bright Data account for free and start experimenting with our AI-ready web data solutions!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



