

Manual content research across dozens of Google search results takes too much time and often misses key insights scattered across multiple sources. Traditional web scraping provides raw HTML but lacks the intelligence to synthesize information into coherent narratives. This guide shows you how to build an AI-powered system that automatically scrapes Google SERP results, analyzes content using embeddings, and generates comprehensive articles or outlines.
You will learn:
- How to build an automated research-to-article pipeline using Bright Data and vector embeddings
- How to analyze scraped content semantically and identify recurring themes
- How to generate structured outlines and full articles using LLMs
- How to create an interactive Streamlit interface for content generation
Let’s Begin!
The Challenges of Research for Content Creation
Content creators face significant obstacles when researching topics for articles, blog posts, or marketing materials. Manual research involves opening dozens of browser tabs, reading through lengthy articles, and attempting to synthesize information from disparate sources. This process is prone to human error, time-intensive, and difficult to scale.
Traditional web scraping approaches using BeautifulSoup or Scrapy provide raw HTML text but lack the intelligence to understand content context, identify key themes, or synthesize information across multiple sources. The result is a collection of unstructured text that still requires significant manual processing.
Combining Bright Data’s robust scraping capabilities with modern AI techniques like vector embeddings and large language models automates the entire research-to-article pipeline. This transforms hours of manual work into minutes of automated analysis.
What We Are Building: AI-Powered Content Research System
You will create an intelligent content generation system that automatically scrapes Google search results for any given keyword. The system extracts full content from target web pages, analyzes the information using vector embeddings to identify themes and insights, and generates either structured article outlines or complete draft articles through an intuitive Streamlit interface.
Prerequisites
Set up your development environment with these requirements:
- Python 3.9 or higher
- Bright Data account: Sign up and create an API token (free tier credits available)
- OpenAI API key: Create a key in your OpenAI dashboard for embeddings and LLM access
- Python virtual environment: Keeps dependencies isolated
- LangChain + Vector Embeddings (FAISS): Handles content analysis and storage.
- Streamlit: Provide the interactive user interface, allowing users to utilize the tool.
Environment Setup
Create your project directory and install dependencies. Start by setting up a clean virtual environment to avoid conflicts with other Python projects.
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venv\Scripts\activate
pip install langchain langchain-community langchain-openai streamlit "crewai-tools[mcp]" crewai mcp python-dotenvCreate a new file called article_generator.py and add the following imports. These libraries handle web scraping, text processing, embeddings, and the user interface.
import streamlit as st
import os
import json
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain_community.vectorstores import FAISS
from mcp import StdioServerParameters
from crewai_tools import MCPServerAdapter
load_dotenv()Bright Data Configuration
Store your API credentials securely using environment variables. Create a .env file to store your credentials, keeping sensitive information separate from your code.
BRIGHT_DATA_API_TOKEN="your_bright_data_api_token_here"
BRIGHT_DATA_ZONE="your_serp_zone_name"
OPENAI_API_KEY="your_openai_api_key_here"You need:
- Bright Data API token: Generate from your Bright Data dashboard
- SERP scraping zone: Create a new Web Scraper zone configured for Google SERP
- OpenAI API key: For embeddings and LLM text generation
Configure the API connections in article_generator.py. This class handles all communication with Bright Data’s scraping infrastructure.
class BrightDataScraper:
def __init__(self):
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": "mcp_unlocker",
"BROWSER_ZONE": "scraping_browser1",
},
)
def scrape_serp(self, keyword, num_results=10):
with MCPServerAdapter(self.server_params) as mcp_tools:
try:
if not mcp_tools:
st.warning("No MCP tools available")
return {'results': []}
for tool in mcp_tools:
try:
tool_name = getattr(tool, 'name', str(tool))
if 'search_engine' in tool_name and 'batch' not in tool_name:
try:
if hasattr(tool, '_run'):
result = tool._run(query=keyword)
elif hasattr(tool, 'run'):
result = tool.run(query=keyword)
elif hasattr(tool, '__call__'):
result = tool(query=keyword)
else:
result = tool.search_engine(query=keyword)
if result:
return self._parse_serp_results(result)
except Exception as method_error:
st.warning(f"Method failed for {tool_name}: {str(method_error)}")
continue
except Exception as tool_error:
st.warning(f"Tool {tool_name} failed: {str(tool_error)}")
continue
st.warning(f"No search_engine tool could process: {keyword}")
return {'results': []}
except Exception as e:
st.error(f"MCP scraping failed: {str(e)}")
return {'results': []}
def _parse_serp_results(self, mcp_result):
"""Parse MCP tool results into expected format."""
if isinstance(mcp_result, dict) and 'results' in mcp_result:
return mcp_result
elif isinstance(mcp_result, list):
return {'results': mcp_result}
elif isinstance(mcp_result, str):
return self._parse_html_search_results(mcp_result)
else:
try:
parsed = json.loads(str(mcp_result))
return parsed if isinstance(parsed, dict) else {'results': parsed}
except:
return {'results': []}
def _parse_html_search_results(self, html_content):
"""Parse HTML search results page to extract search results."""
import re
results = []
link_pattern = r'<a[^>]*href="([^"]*)"[^>]*>(.*?)</a>'
title_pattern = r'<h3[^>]*>(.*?)</h3>'
links = re.findall(link_pattern, html_content, re.DOTALL)
for link_url, link_text in links:
if (link_url.startswith('http') and
not any(skip in link_url for skip in [
'google.com', 'accounts.google', 'support.google',
'/search?', 'javascript:', '#', 'mailto:'
])):
clean_title = re.sub(r'<[^>]+>', '', link_text).strip()
if clean_title and len(clean_title) > 10:
results.append({
'url': link_url,
'title': clean_title[:200],
'snippet': '',
'position': len(results) + 1
})
if len(results) >= 10:
break
if not results:
specific_pattern = r'\[(.*?)\]\((https?://[^\)]+)\)'
matches = re.findall(specific_pattern, html_content)
for title, url in matches:
if not any(skip in url for skip in ['google.com', '/search?']):
results.append({
'url': url,
'title': title.strip(),
'snippet': '',
'position': len(results) + 1
})
if len(results) >= 10:
break
return {'results': results}Building the Article Generator
Step 1: Scrape SERP & Target Pages
The foundation of our system is comprehensive data collection. You need to build a scraper that first extracts Google SERP results, then follows those links to gather full page content from the most relevant sources.
class ContentScraper:
def __init__(self):
self.bright_data = BrightDataScraper()
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": "mcp_unlocker",
"BROWSER_ZONE": "scraping_browser1",
},
)
def extract_serp_urls(self, keyword, max_results=10):
"""Extract URLs from Google SERP results."""
serp_data = self.bright_data.scrape_serp(keyword, max_results)
urls = []
results_list = serp_data.get('results', [])
for result in results_list:
if 'url' in result and self.is_valid_url(result['url']):
urls.append({
'url': result['url'],
'title': result.get('title', ''),
'snippet': result.get('snippet', ''),
'position': result.get('position', 0)
})
elif 'link' in result and self.is_valid_url(result['link']):
urls.append({
'url': result['link'],
'title': result.get('title', ''),
'snippet': result.get('snippet', ''),
'position': result.get('position', 0)
})
return urls
def is_valid_url(self, url):
"""Filter out non-article URLs like images, PDFs, or social media."""
excluded_domains = ['youtube.com', 'facebook.com', 'twitter.com', 'instagram.com']
excluded_extensions = ['.pdf', '.jpg', '.png', '.gif', '.mp4']
return (not any(domain in url for domain in excluded_domains) and
not any(ext in url.lower() for ext in excluded_extensions))
def scrape_page_content(self, url, max_length=10000):
"""Extract clean text content from a webpage using Bright Data MCP tools."""
try:
with MCPServerAdapter(self.server_params) as mcp_tools:
if not mcp_tools:
st.warning("No MCP tools available for content scraping")
return ""
for tool in mcp_tools:
try:
tool_name = getattr(tool, 'name', str(tool))
if 'scrape_as_markdown' in tool_name:
try:
if hasattr(tool, '_run'):
result = tool._run(url=url)
elif hasattr(tool, 'run'):
result = tool.run(url=url)
elif hasattr(tool, '__call__'):
result = tool(url=url)
else:
result = tool.scrape_as_markdown(url=url)
if result:
content = self._extract_content_from_result(result)
if content:
return self._clean_content(content, max_length)
except Exception as method_error:
st.warning(f"Method failed for {tool_name}: {str(method_error)}")
continue
except Exception as tool_error:
st.warning(f"Tool {tool_name} failed for {url}: {str(tool_error)}")
continue
st.warning(f"No scrape_as_markdown tool could scrape: {url}")
return ""
except Exception as e:
st.warning(f"Failed to scrape {url}: {str(e)}")
return ""
def _extract_content_from_result(self, result):
"""Extract content from MCP tool result."""
if isinstance(result, str):
return result
elif isinstance(result, dict):
for key in ['content', 'text', 'body', 'html']:
if key in result and result[key]:
return result[key]
elif isinstance(result, list) and len(result) > 0:
return str(result[0])
return str(result) if result else ""
def _clean_content(self, content, max_length):
"""Clean and format scraped content."""
if isinstance(content, dict):
content = content.get('text', content.get('content', str(content)))
if '<' in content and '>' in content:
import re
content = re.sub(r'<script[^>]*>.*?</script>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<style[^>]*>.*?</style>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<[^>]+>', '', content)
lines = (line.strip() for line in content.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
text = ' '.join(chunk for chunk in chunks if chunk)
return text[:max_length]This scraper intelligently filters URLs to focus on article content while avoiding multimedia files and social media links that won’t provide valuable text content for analysis.
Step 2: Vector Embeddings & Content Analysis
Transform scraped content into searchable vector embeddings that capture semantic meaning and enable intelligent content analysis. The embedding process converts text into numerical representations that machines understand and compare.
class ContentAnalyzer:
def __init__(self):
self.embeddings = OpenAIEmbeddings(openai_api_key=os.getenv("OPENAI_API_KEY"))
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n\n", "\n", ".", "!", "?", ",", " ", ""]
)
def process_content(self, scraped_data):
"""Convert scraped content into embeddings and analyze themes."""
all_texts = []
metadata = []
for item in scraped_data:
if item['content']:
chunks = self.text_splitter.split_text(item['content'])
for chunk in chunks:
all_texts.append(chunk)
metadata.append({
'url': item['url'],
'title': item['title'],
'position': item['position']
})
if not all_texts:
raise ValueError("No content available for analysis")
vectorstore = FAISS.from_texts(all_texts, self.embeddings, metadatas=metadata)
return vectorstore, all_texts, metadata
def identify_themes(self, vectorstore, query_terms, k=5):
"""Use semantic search to identify key themes and topics."""
theme_analysis = {}
for term in query_terms:
similar_docs = vectorstore.similarity_search(term, k=k)
theme_analysis[term] = {
'relevant_chunks': len(similar_docs),
'key_passages': [doc.page_content[:200] + "..." for doc in similar_docs[:3]],
'sources': list(set([doc.metadata['url'] for doc in similar_docs]))
}
return theme_analysis
def generate_content_summary(self, all_texts, metadata):
"""Generate statistical summary of scraped content."""
total_words = sum(len(text.split()) for text in all_texts)
total_chunks = len(all_texts)
avg_chunk_length = total_words / total_chunks if total_chunks > 0 else 0
return {
'total_sources': len(set(meta['url'] for meta in metadata)),
'total_chunks': total_chunks,
'total_words': total_words,
'avg_chunk_length': round(avg_chunk_length, 1)
}The analyzer breaks content into semantic chunks and creates a searchable vector database that enables intelligent theme identification and content synthesis.
Step 3: Generate Article or Outline with LLM
Transform analyzed content into structured outputs using carefully crafted prompts that leverage the semantic insights from your embedding analysis. The LLM takes your research data and creates coherent, well-structured content.
class ArticleGenerator:
def __init__(self):
self.llm = OpenAI(
openai_api_key=os.getenv("OPENAI_API_KEY"),
temperature=0.7,
max_tokens=2000
)
def generate_outline(self, keyword, theme_analysis, content_summary):
"""Generate a structured article outline based on research data."""
themes_text = self._format_themes_for_prompt(theme_analysis)
outline_prompt = f"""
Based on comprehensive research about "{keyword}", create a detailed article outline.
Research Summary:
- Analyzed {content_summary['total_sources']} sources
- Processed {content_summary['total_words']} words of content
- Identified key themes and insights
Key Themes Found:
{themes_text}
Create a structured outline with:
1. Compelling headline
2. Introduction hook and overview
3. 4-6 main sections with subsections
4. Conclusion with key takeaways
5. Suggested call-to-action
Format as markdown with clear hierarchy.
"""
return self.llm(outline_prompt)
def generate_full_article(self, keyword, theme_analysis, content_summary, target_length=1500):
"""Generate a complete article draft."""
themes_text = self._format_themes_for_prompt(theme_analysis)
article_prompt = f"""
Write a comprehensive {target_length}-word article about "{keyword}" based on extensive research.
Research Foundation:
{themes_text}
Content Requirements:
- Engaging introduction that hooks readers
- Well-structured body with clear sections
- Include specific insights and data points from research
- Professional, informative tone
- Strong conclusion with actionable takeaways
- SEO-friendly structure with subheadings
Write the complete article in markdown format.
"""
return self.llm(article_prompt)
def _format_themes_for_prompt(self, theme_analysis):
"""Format theme analysis for LLM consumption."""
formatted_themes = []
for theme, data in theme_analysis.items():
theme_info = f"**{theme}**: Found in {data['relevant_chunks']} content sections\n"
theme_info += f"Key insights: {data['key_passages'][0][:150]}...\n"
theme_info += f"Sources: {len(data['sources'])} unique references\n"
formatted_themes.append(theme_info)
return "\n".join(formatted_themes)The generator creates two distinct output formats: structured outlines for content planning and complete articles for immediate publication. Both outputs are grounded in the semantic analysis of scraped content.

Step 4: Build Streamlit UI
Create an intuitive interface that guides users through the content generation workflow with real-time feedback and customization options. The interface makes complex AI operations accessible to non-technical users.
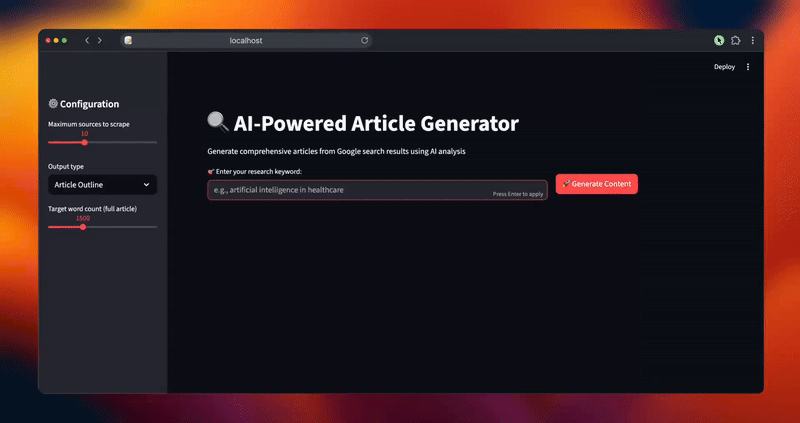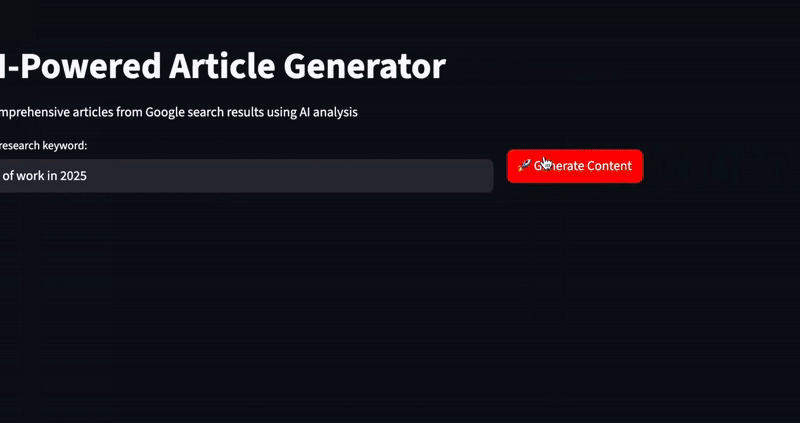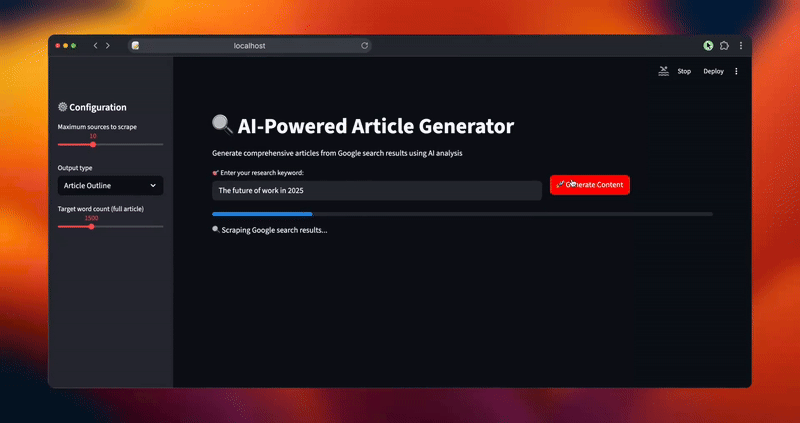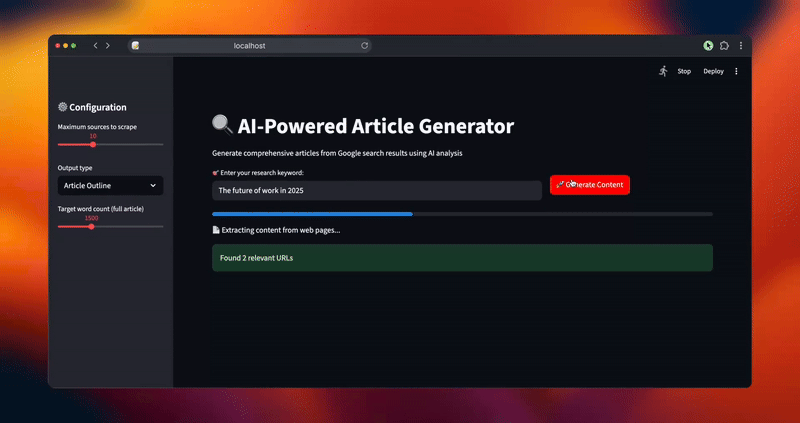
def main():
st.set_page_config(page_title="AI Article Generator", page_icon="📝", layout="wide")
st.title("🔍 AI-Powered Article Generator")
st.markdown("Generate comprehensive articles from Google search results using AI analysis")
scraper = ContentScraper()
analyzer = ContentAnalyzer()
generator = ArticleGenerator()
st.sidebar.header("⚙️ Configuration")
max_sources = st.sidebar.slider("Maximum sources to scrape", 5, 20, 10)
output_type = st.sidebar.selectbox("Output type", ["Article Outline", "Full Article"])
target_length = st.sidebar.slider("Target word count (full article)", 800, 3000, 1500)
col1, col2 = st.columns([2, 1])
with col1:
keyword = st.text_input("🎯 Enter your research keyword:", placeholder="e.g., artificial intelligence in healthcare")
with col2:
st.write("")
generate_button = st.button("🚀 Generate Content", type="primary")
if generate_button and keyword:
try:
progress_bar = st.progress(0)
status_text = st.empty()
status_text.text("🔍 Scraping Google search results...")
progress_bar.progress(0.2)
urls = scraper.extract_serp_urls(keyword, max_sources)
st.success(f"Found {len(urls)} relevant URLs")
status_text.text("📄 Extracting content from web pages...")
progress_bar.progress(0.4)
scraped_data = []
for i, url_data in enumerate(urls):
content = scraper.scrape_page_content(url_data['url'])
scraped_data.append({
'url': url_data['url'],
'title': url_data['title'],
'content': content,
'position': url_data['position']
})
progress_bar.progress(0.4 + (0.3 * (i + 1) / len(urls)))
status_text.text("🧠 Analyzing content with AI embeddings...")
progress_bar.progress(0.75)
vectorstore, all_texts, metadata = analyzer.process_content(scraped_data)
query_terms = [keyword] + keyword.split()[:3]
theme_analysis = analyzer.identify_themes(vectorstore, query_terms)
content_summary = analyzer.generate_content_summary(all_texts, metadata)
status_text.text("✍️ Generating AI-powered content...")
progress_bar.progress(0.9)
if output_type == "Article Outline":
result = generator.generate_outline(keyword, theme_analysis, content_summary)
else:
result = generator.generate_full_article(keyword, theme_analysis, content_summary, target_length)
progress_bar.progress(1.0)
status_text.text("✅ Content generation complete!")
st.markdown("---")
st.subheader(f"📊 Research Analysis for '{keyword}'")
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Sources Analyzed", content_summary['total_sources'])
with col2:
st.metric("Content Chunks", content_summary['total_chunks'])
with col3:
st.metric("Total Words", content_summary['total_words'])
with col4:
st.metric("Avg Chunk Size", f"{content_summary['avg_chunk_length']} words")
with st.expander("🎯 Key Themes Identified"):
for theme, data in theme_analysis.items():
st.write(f"**{theme}**: {data['relevant_chunks']} relevant sections found")
st.write(f"Sample insight: {data['key_passages'][0][:200]}...")
st.write(f"Sources: {len(data['sources'])} unique references")
st.write("---")
st.markdown("---")
st.subheader(f"📝 Generated {output_type}")
st.markdown(result)
st.download_button(
label="💾 Download Content",
data=result,
file_name=f"{keyword.replace(' ', '_')}_{output_type.lower().replace(' ', '_')}.md",
mime="text/markdown"
)
except Exception as e:
st.error(f"❌ Generation failed: {str(e)}")
st.write("Please check your API credentials and try again.")
if __name__ == "__main__":
main()The Streamlit interface provides an intuitive workflow with real-time progress tracking, customizable parameters, and immediate preview of both research analysis and generated content. Users download their results in markdown format for further editing or publication.
Running Your Article Generator
Execute the application to start generating content from web research. Open your terminal and navigate to the directory of your project.
streamlit run article_generator.pyYou will see the system’s intelligent workflow as it processes your requests:
- Extracts comprehensive search results from Google SERP with relevance filtering
- Scrapes full content from target web pages with anti-bot protection
- Processes content semantically using vector embeddings and theme identification
- Analyzes recurring patterns and key insights across multiple sources
- Generates structured content with proper flow and professional formatting
Final Thoughts
You now have a complete article generation system that automatically collects research data from multiple sources and transforms it into comprehensive content. The system performs semantic content analysis, identifies recurring themes across sources, and generates structured articles or outlines.
You adapt this framework for different industries by modifying the scraping targets and analysis criteria. The modular design allows you to add new content platforms, embedding models, or generation templates as your needs evolve.
To craft more advanced workflows, explore the full range of solutions in the Bright Data AI infrastructure for fetching, validating, and transforming live web data.
Create a free Bright Data account and start experimenting with our AI-ready web data solutions!

Technical Writer
Arindam Majumder is a developer advocate, YouTuber, and technical writer who simplifies LLMs, agent workflows, and AI content for 5,000+ followers.





