

In this guide, you’ll discover:
- What a research agent is and why traditional methods fail
- How to configure Bright Data for reliable data collection
- How to build a local AI-powered research agent with Streamlit UI
- How to integrate Bright Data APIs with local models for structured insights
Let’s dive into building your intelligent research assistant. We also suggest you check out Deep Lookup, Bright Data’s AI-powered search engine that allows you to search the web like a database.
Industry Problem
- Researchers face too much information from many sources, making manual review impractical.
- Traditional research involves slow, manual searches, extraction, and synthesis.
- Results are often incomplete, disconnected, and poorly organized.
- Simple scraping tools provide raw data without credibility or context.
Solution: Research Agent
A Deep Research Agent is an AI system that automates research from collection to reporting. It handles context, manages tasks, and delivers well-structured insights.
Key components:
- Planner Agent: breaks research into tasks
- Research SubAgents: perform searches and extract data
- Writer Agent: compiles structured reports
- Condition Agent: checks quality and triggers deeper research if needed
This guide shows how to build a local research system using Bright Data’s APIs, a Streamlit UI, and local LLMs for privacy and control.
Prerequisites
- Bright Data account with API key.
- Python 3.10+
- Dependencies:
requestsfaissorchromadbpython-dotenvstreamlitollama(for local models)
Bright Data Configuration
Create Bright Data Account
- Sign up at Bright Data
- Navigate to the API credentials section
- Generate your API token
Store your API credentials securely using environment variables. Create a .env file to store your credentials, keeping sensitive information separate from your code.
BRIGHT_DATA_API_KEY="your_bright_data_api_token_here"Environment Setup
# Create venv
python -m venv venv
source venv/bin/activate
# Install dependencies
pip install requests openai chromadb python-dotenv streamlitImplementation
Step 1: Research
This will be our research task.
query = "AI use cases in healthcare"Step 2: Fetch Data
This step demonstrates how to programmatically fetch data from the web using Bright Data’s Data Collection API. The code sends a research query and retrieves relevant data while securely handling API credentials.
import requests, os
from dotenv import load_dotenv
load_dotenv()
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit": 20}
headers = {"Authorization": f"Bearer {os.getenv('BRIGHT_DATA_API_KEY')}"}
res = requests.post(url, json=payload, headers=headers)
print(res.json())Step 3: Process and Embed
This step processes the fetched research data and stores it in ChromaDB, a vector database that enables semantic search and similarity matching. This creates a searchable knowledge base from your research results that can be queried for AI use cases in healthcare or any other research topic.
import chromadb
from chromadb.config import Settings
# Initialize ChromaDB
client = chromadb.PersistentClient(path="./research_db")
collection = client.get_or_create_collection("research_data")
# Store research results
def store_research_data(results):
documents = []
metadatas = []
ids = []
for i, item in enumerate(results):
documents.append(item.get('content', ''))
metadatas.append({
'source': item.get('source', ''),
'query': query,
'timestamp': item.get('timestamp', '')
})
ids.append(f"doc_{i}")
collection.add(
documents=documents,
metadatas=metadatas,
ids=ids
)Step 4: Local Model Summarization
This step demonstrates how to leverage locally-run large language models (LLMs) through Ollama to generate concise summaries of research content. This approach keeps data processing private and enables offline summarization capabilities.
import subprocess
import json
def summarize_with_ollama(content, model="llama2"):
"""Summarize research content using local Ollama model"""
try:
result = subprocess.run(
['ollama', 'run', model, f"Summarize this research content: {content[:2000]}"],
capture_output=True,
text=True,
timeout=120
)
return result.stdout.strip()
except Exception as e:
return f"Summarization failed: {str(e)}"
# Example usage
research_data = res.json().get('results', [])
for item in research_data:
summary = summarize_with_ollama(item.get('content', ''))
print(f"Summary: {summary}")ollama run llama2 "Summarize AI use cases in healthcare"Streamlit UI
Finally create a complete web UI that combines data collection from Bright Data with local AI summarization through Ollama. The interface allows users to configure research parameters, run data collection, and generate AI summaries through an intuitive dashboard.
Create app.py
import streamlit as st
import requests, os
from dotenv import load_dotenv
import subprocess
import json
load_dotenv()
st.set_page_config(page_title="Deep Research Agent", page_icon="🔎")
st.title("🔎 Local Deep Research Agent with Bright Data")
# Sidebar configuration
with st.sidebar:
st.header("Configuration")
api_key = st.text_input(
"Bright Data API Key",
type="password",
value=os.getenv('BRIGHT_DATA_API_KEY', '')
)
model_choice = st.selectbox(
"Ollama Model",
["llama2", "mistral", "codellama"]
)
research_depth = st.slider("Research Depth", 5, 50, 20)
# Main research interface
query = st.text_input("Enter research topic:", "AI use cases in healthcare")
col1, col2 = st.columns(2)
with col1:
if st.button("🚀 Run Research", type="primary"):
if not api_key:
st.error("Please enter your Bright Data API key")
elif not query:
st.error("Please enter a research topic")
else:
with st.spinner("Collecting research data..."):
# Fetch data from Bright Data
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit": research_depth}
headers = {"Authorization": f"Bearer {api_key}"}
res = requests.post(url, json=payload, headers=headers)
if res.status_code == 200:
st.success(f"Successfully collected {len(res.json().get('results', []))} sources!")
st.session_state.research_data = res.json()
# Display results
for i, item in enumerate(res.json().get('results', [])):
with st.expander(f"Source {i+1}: {item.get('title', 'No title')}"):
st.write(item.get('content', 'No content available'))
else:
st.error(f"Failed to fetch data: {res.status_code}")
with col2:
if st.button("🤖 Summarize with Ollama"):
if 'research_data' in st.session_state:
with st.spinner("Generating AI summaries..."):
for i, item in enumerate(st.session_state.research_data.get('results', [])):
content = item.get('content', '')[:1500] # Limit content length
try:
result = subprocess.run(
['ollama', 'run', model_choice, f"Summarize this content: {content}"],
capture_output=True,
text=True,
timeout=60
)
summary = result.stdout.strip()
with st.expander(f"AI Summary {i+1}"):
st.write(summary)
except Exception as e:
st.error(f"Summarization failed for source {i+1}: {str(e)}")
else:
st.warning("Please run research first to collect data")
# Display raw data if available
if 'research_data' in st.session_state:
with st.expander("View Raw Research Data"):
st.json(st.session_state.research_data)Run the application:
streamlit run app.pyWhen you run the application and visit port 8501, this should be the UI:
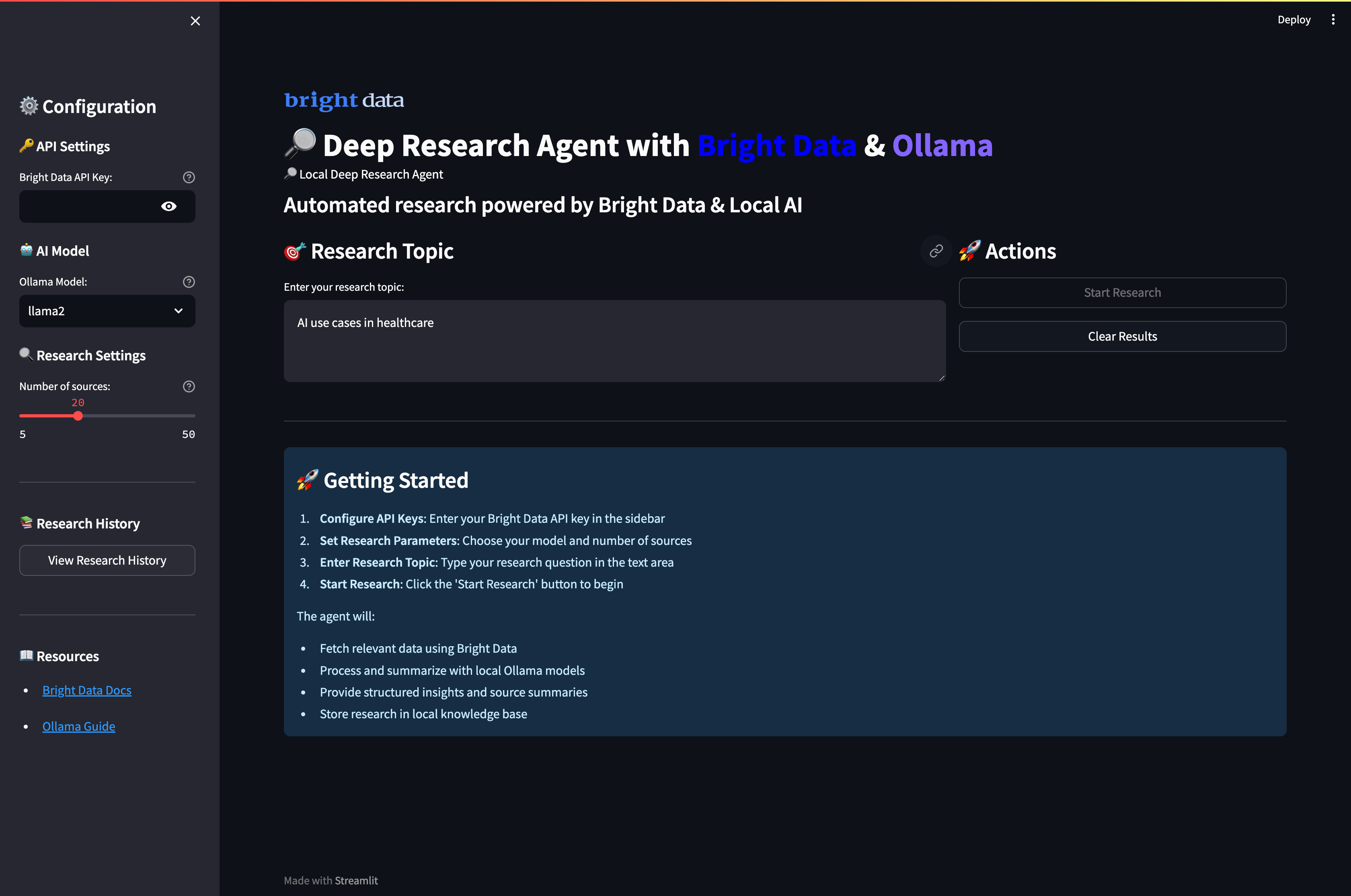
Running Your Deep Research Agent
Run the application to start conducting comprehensive research with AI-powered analysis. Open your terminal and navigate to your project directory.
streamlit run app.pyYou will see the system’s intelligent multi agent workflow as it processes your research requests:
- Data collection Phase: The agent fetches comprehensive research data from diverse web sources using Bright Data’s reliable APIs, automatically filtering for relevance and credibility.
- Content Processing: Each source undergoes intelligent analysis where the system extracts key information,indentifies main themes, and evaluates content quality using semantic understanding.
- AI Summarization: Local Ollama models process the collected data, generating concise summaries while preserving critical insights and maintaining contextual accuracy across all sources.
- Knowledge Synthesis: They system identifies recurring patterns, connects related concepts, and detects emerging trends by analyzing information across multiple sources simulataneously.
- Structured Reporting: Finally, the agent compiles all findings into a comprehensive research report with proper organization, clear citations, and professional formatting that highlights key discoveries and insights.
Enhanced Research Pipeline
For more advanced research capabilities, extend the implementation.
This enhanced pipeline creates a complete research workflow that goes beyond simple summarization to provide structured analysis, key insights, and actionable findings from collected research data. The pipeline integrates Bright Data for information gathering and local Ollama models for intelligent analysis.
# advanced_research.py
def comprehensive_research_pipeline(query, api_key, model="llama2"):
"""Complete research pipeline with data collection and AI analysis"""
# Step 1: Fetch data from Bright Data
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit": 20}
headers = {"Authorization": f"Bearer {api_key}"}
response = requests.post(url, json=payload, headers=headers)
if response.status_code != 200:
return {"error": "Data collection failed"}
research_data = response.json()
# Step 2: Process and analyze with Ollama
insights = []
for item in research_data.get('results', []):
content = item.get('content', '')
# Generate insights for each source
analysis_prompt = f"""
Analyze this content and provide key insights:
{content[:2000]}
Focus on:
- Main points and findings
- Key data and statistics
- Potential applications
- Limitations mentioned
"""
try:
result = subprocess.run(
['ollama', 'run', model, analysis_prompt],
capture_output=True,
text=True,
timeout=90
)
insights.append({
'source': item.get('source', ''),
'analysis': result.stdout.strip(),
'title': item.get('title', '')
})
except Exception as e:
insights.append({
'source': item.get('source', ''),
'analysis': f"Analysis failed: {str(e)}",
'title': item.get('title', '')
})
return {
'research_data': research_data,
'ai_insights': insights,
'query': query
}Conclusion
This Local Deep Research Agent demonstrates how to build an automated research system that combines Bright Data’s reliable web data collection with local AI processing using Ollama. The implementation provides:
- Privacy First Approach: All AI processing happens locally with Ollama
- Reliable Data Collection: Bright Data ensures high quality, structured web data
- User Friendly Interface: Streamlit UI makes complex research accessible
- Customizable Workflow: Adaptable to various research domains and requirements
The system addresses key industry challenges by automating data collection, processing, and analysis transforming hours of manual research into minutes of automated insight generation.
To enhance your research capabilities further, explore Bright Data’s dataset solutions for industry specific data and consider using Deep Lookup for querying and searching the world’s biggest database of web data.
Ready to build your own research agent? Create a free Bright Data account to get started with reliable web data collection and begin transforming your research workflows today.

Technical Writer
Arindam Majumder is a developer advocate, YouTuber, and technical writer who simplifies LLMs, agent workflows, and AI content for 5,000+ followers.





