In this guide, you will learn:
- What a ZoomInfo scraper is and how it works
- The types of data you can automatically extract from ZoomInfo
- How to create a ZoomInfo scraping script using Python
- When and why a more advanced solution might be necessary
Let’s dive in!
What Is a ZoomInfo Scraper?
A ZoomInfo scraper is a tool to extract data from ZoomInfo, a leading platform offering detailed company and professional information. This solution automates the scraping process, allowing you to collect a lot of data. The scraper relies on techniques like browser automation to navigate the site and retrieve content.
Data You Can Retrieve From ZoomInfo
Here is some of the most important data you can scrape from ZoomInfo:
- Company information: Names, industries, revenue, headquarters, and employee counts.
- Employee details: Names, job titles, emails, and phone numbers.
- Industry insights: Competitors, market trends, and company hierarchies.
Scraping ZoomInfo in Python: Step-by-Step Guide
In this section, you’ll learn how to build a ZoomInfo scraper.
The goal is to walk you through creating a Python script that automatically collects data from the NVIDIA ZoomInfo company page.
Follow the steps below!
Step #1: Project Setup
Before getting started, make sure you have Python 3 installed on your machine. Otherwise, download it and install it by following the wizard.
Now, use the following command to create a folder for your project:
mkdir zoominfo-scraper
The zoominfo-scraper directory represents the project folder of your Python ZoomInfo scraper.
Enter it, and initialize a virtual environment within it:
cd zoominfo-scraper
python -m venv env
Load the project folder in your favorite Python IDE. Visual Studio Code with the Python extension or PyCharm Community Edition will do.
Create a scraper.py file in the project’s folder, which should contain the file structure below:

Right now, scraper.py is a blank Python script. Soon, it will soon contain the desired scraping logic.
In the IDE’s terminal, activate the virtual environment. In Linux or macOS, fire this command:
./env/bin/activate
Equivalently, on Windows, execute:
env/Scripts/activate
Wonderful, you now have a Python environment for web scraping!
Step #2: Select the Scraping Library
Before diving into coding, you must understand which tools are best suited to achieve the goal. To do that, you should first perform a preliminary test to study the target site. Here is how:
- Open the target page in incognito mode in your browser. This prevents pre-stored cookies and preferences from affecting your analysis.
- Right-click anywhere on the page and select “Inspect” to open the browser’s developer tools.
- Navigate to the “Network” tab.
- Reload the page and examine the activity in the “Fetch/XHR” tab.
This will give you insight into how the webpage behaves at rendering time:
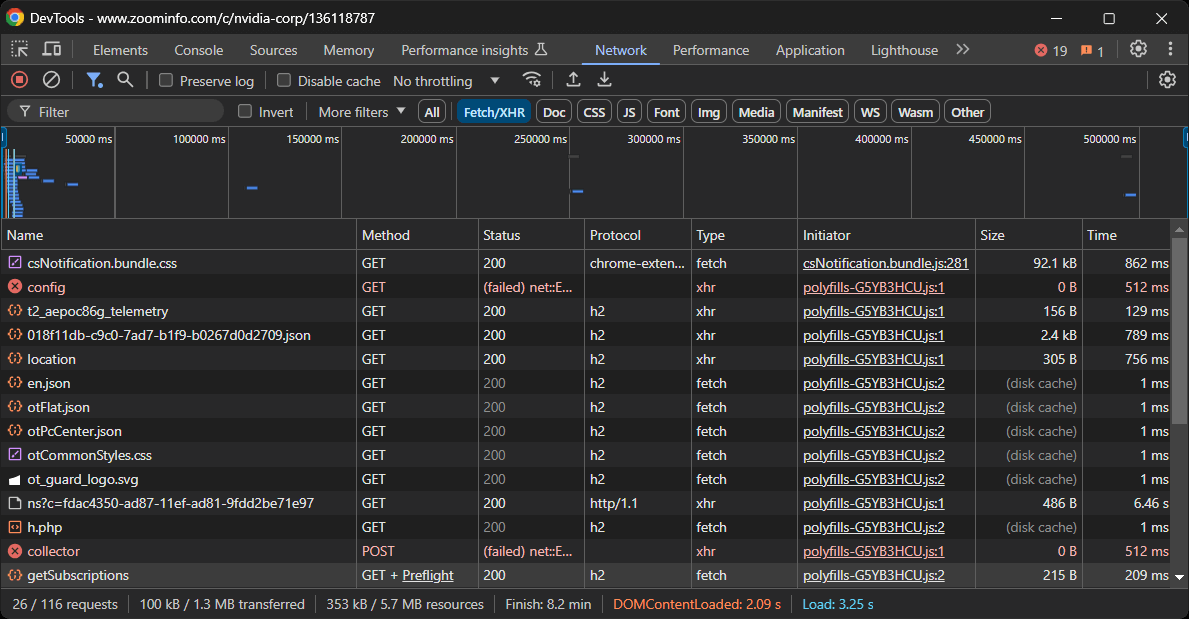
In this section, you can view all the dynamic AJAX requests made by the page. Inspect each request, and you will notice that none of them contain relevant data. This indicates that most of the information on the page is already embedded in the HTML document returned by the server.
The results will naturally lead you to adopt an HTTP client and an HTML parser for scraping ZoomInfo. However, the site uses strict anti-bot technologies that can block most automated requests not originating from a browser. The simplest way to bypass this is by using a browser automation tool like Selenium!
Selenium enables you to control a web browser programmatically, instructing it to perform specific actions on web pages as real users would do. Time to install it and get started with it!
Step #3: Install and Configure Selenium
In Python, Selenium is available via the selenium pip package. In an activated Python virtual environment, install it with this command:
pip install -U selenium
For guidance on how to use the tool, follow our tutorial on web scraping with Selenium.
Import Selenium in scraper.py and initialize a WebDriver object to control a Chrome instance:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
The code above creates a WebDriver instance to operate over Chrome. Note that ZoomInfo uses anti-scraping technology that blocks headless browsers. Thus, you cannot set the --headless flag. As an alternative solution, consider exploring Playwright Stealth.
As the last line of your scraper, remember to close the web driver:
driver.quit()
Amazing! You are now fully configured to start scraping ZoomInfo.
Step #4: Connect to the Target Page
Use the get() method from a Selenium WebDriver object to instruct the browser to visit the desired page:
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
Your scraper.py file should now contain these lines of code:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# connect to the target page
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
# scraping logic...
# close the browser
driver.quit()
Place a debugging breakpoint on the final line and run the script. It should take you to the NVIDIA company page.
The “Chrome is being controlled by automated test software.” message certifies that Selenium is controlling Chrome as expected. Well done!
Step #5: Scrape the General Company Info
You need to analyze the DOM structure of the page to understand how to scrape the required data. The goal is to identify the HTML elements containing the desired data. Start by inspecting the elements in the top section of the company info section:

The <app-company-header> element contains:
- The company image in an
<img>tag within a<div>with the classcompany-logo-wrapper. - The company name within a node with the class
company-name. - The company subtitle stored in a node with the class
company-header-subtitle.
Use Selenium to locate these elements and collect data from them:
logo_element = driver.find_element(By.CSS_SELECTOR, ".company-logo-wrapper img")
logo_url = logo_element.get_attribute("src")
name_element = driver.find_element(By.CSS_SELECTOR, ".company-name")
name = name_element.text
subtitle_element = driver.find_element(By.CSS_SELECTOR, ".company-header-subtitle")
subtitle = subtitle_element.text
To make the code work, do not forget to import By:
from selenium.webdriver.common.by import By
Note that the find_element() method selects a node using the specified node selection strategy. Above, we used CSS selectors. Learn more about the difference between XPath and CSS selectors.
Then, you can access the node’s content with the text attribute. For accessing an attribute, utilize the get_attribute() method.
Print the scraped data:
print(logo_url)
print(name)
print(subtitle)
This is what you would get:
https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com
NVIDIA
Computer Equipment & Peripherals · California, United States · 29,600 Employees
Wow! The ZoomInfo scraper works like a charm.
Step #6: Scrape the About Info
Focus on the “About” section of the company page:

The <app-about> node contains elements with generic classes and seemingly randomly generated attributes. Since these attributes may change with every build, you should avoid relying on them to target elements for scraping.
To scrape the information from this section, start by selecting the <app-about> node:
about_element = driver.find_element(By.CSS_SELECTOR, "app-about")
Now, focus on all .icon-text-container elements inside <app-about>. Then, inspect their labels (.icon-label) to identify the specific elements of interest. If the label matches, extract the data from the .content element. Encapsulate this logic in a function:
def scrape_about_node(text_container_elements, text_label):
# iterate through them to scrape data from the
# specific nodes of interest
for text_container_element in text_container_elements:
label = text_container_element.find_element(By.CSS_SELECTOR, ".icon-label").text.strip()
if label == text_label:
# select the content element and extract data from it
content_element = text_container_element.find_element(By.CSS_SELECTOR, ".content")
return content_element.text
return None
You can then scrape the “About” info with:
headquarters = scrape_about_node(text_container_elements, "Headquarters")
phone_number = scrape_about_node(text_container_elements, "Phone Number")
revenue = scrape_about_node(text_container_elements, "Revenue")
stock_symbol = scrape_about_node(text_container_elements, "Stock Symbol")
Next, target the industry and company tags.
Select the company industry with h3 .incon-label and the tags with zi-directories-chips a. Scrape data from them with:
industry_element = about_element.find_element(By.CSS_SELECTOR, "h3.icon-label")
industry = industry_element.text
tag_elements = about_element.find_elements(By.CSS_SELECTOR, "zi-directories-chips a")
tags = [tag_element.text for tag_element in tag_elements]
Incredible! The ZoomInfo data scraping logic is complete.
Step #7: Collect the Scraped Data
You currently have the scraped data spread across several variables. Populate a new company object with that data:
company = {
"logo_url": logo_url,
"name": name,
"subtitle": subtitle,
"headquarters": headquarters,
"phone_number": phone_number,
"revenue": revenue,
"stock_symbol": stock_symbol,
"industry": industry,
"tags": tags
}
Print the scraped data to make sure that it contains the desired information
print(items)
This will produce the following output:
{'logo_url': 'https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com', 'name': 'NVIDIA', 'subtitle': 'Computer Equipment & Peripherals · California, United States · 29,600 Employees', 'headquarters': '2788 San Tomas Expy, Santa Clara, California, 95051, United States', 'phone_number': '(408) 486-2000', 'revenue': '$79.8 Billion', 'stock_symbol': 'NVDA', 'industry': 'Headquarters', 'tags': ['Computer Networking Equipment', 'Network Security Hardware & Software', 'Computer Equipment & Peripherals', 'Manufacturing']}
Fantastic! It only remains to export this information to a human-readable file like JSON.
Step #8: Export to JSON
Export company to a company.json file with:
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
First, open() creates a company.json output file. Then, json.dump() transforms company into its JSON representation and writes it to the output file.
Remember to import json from the Python standard library:
import json
Step #9: Put It All Together
Below is the final scraper.py file:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
def scrape_about_node(text_container_elements, text_label):
# iterate through them to scrape data from the
# specific nodes of interest
for text_container_element in text_container_elements:
label = text_container_element.find_element(By.CSS_SELECTOR, ".icon-label").text.strip()
if label == text_label:
# select the content element and extract data from it
content_element = text_container_element.find_element(By.CSS_SELECTOR, ".content")
return content_element.text
return None
# create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# connect to the target page
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
# scrape the company info
logo_element = driver.find_element(By.CSS_SELECTOR, ".company-logo-wrapper img")
logo_url = logo_element.get_attribute("src")
name_element = driver.find_element(By.CSS_SELECTOR, ".company-name")
name = name_element.text
subtitle_element = driver.find_element(By.CSS_SELECTOR, ".company-header-subtitle")
subtitle = subtitle_element.text
# scrape data from the "About" section
about_element = driver.find_element(By.CSS_SELECTOR, "app-about")
text_container_elements = about_element.find_elements(By.CSS_SELECTOR, ".icon-text-container")
headquarters = scrape_about_node(text_container_elements, "Headquarters")
phone_number = scrape_about_node(text_container_elements, "Phone Number")
revenue = scrape_about_node(text_container_elements, "Revenue")
stock_symbol = scrape_about_node(text_container_elements, "Stock Symbol")
# scrape the company industry and tags
industry_element = about_element.find_element(By.CSS_SELECTOR, "h3.icon-label")
industry = industry_element.text
tag_elements = about_element.find_elements(By.CSS_SELECTOR, "zi-directories-chips a")
tags = [tag_element.text for tag_element in tag_elements]
# collect the scraped data
company = {
"logo_url": logo_url,
"name": name,
"subtitle": subtitle,
"headquarters": headquarters,
"phone_number": phone_number,
"revenue": revenue,
"stock_symbol": stock_symbol,
"industry": industry,
"tags": tags
}
# export the scraped data to JSON
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
# close the browser
driver.quit()
In just over 70 lines of code, you just built a ZoomInfo data scraping script in Python!
Launch the scraper with the following command:
python3 script.py
Or, on Windows:
python script.py
A company.json file will appear in your project’s folder. Open it and you will see:
{
"logo_url": "https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com",
"name": "NVIDIA",
"subtitle": "Computer Equipment & Peripherals · California, United States · 29,600 Employees",
"headquarters": "2788 San Tomas Expy, Santa Clara, California, 95051, United States",
"phone_number": "(408) 486-2000",
"revenue": "$79.8 Billion",
"stock_symbol": "NVDA",
"industry": "Headquarters",
"tags": [
"Computer Networking Equipment",
"Network Security Hardware & Software",
"Computer Equipment & Peripherals",
"Manufacturing"
]
}Congrats, mission complete!
Unlocking ZoomInfo Data With Ease
ZoomInfo offers much more than just company overviews—it provides a wealth of useful information. The problem is that scraping that data can be quite challenging as most pages under the ZoomInfo domain are protected by anti-bot measures.
If you try to access these pages using Selenium or other browser automation tools, you will likely encounter a CAPTCHA page blocking your attempts.
As a first step, consider following our guide on how to bypass CAPTCHAs in Python. However, you might still face 429 Too Many Requests errors due to the site’s strict rate limiting. In such cases, you could integrate a proxy into Selenium to rotate your exit IP.
Those issues summarize how scraping ZoomInfo without the right tools can quickly become a frustrating process. Also, the fact that you cannot use headless browsers make your scraping script slow and resource-intensive.
The solution? Using Bright Data’s dedicated ZoomInfo Scraper API to retrieve data from the target site via simple API calls and without getting blocked!
Conclusion
In this step-by-step tutorial, you learned what a ZoomInfo scraper is and the types of data it can retrieve. You also built a Python script to scrape ZoomInfo for company overview data, which required way less than 100 lines of code.
The challenge is that ZoomInfo employs strict anti-bot measures, including CAPTCHAs, browser fingerprinting, and IP bans, to block automated scripts. Forget about all those challenges with our ZoomInfo Scraper API.
If web scraping is not for you but you are still interested in company or employee data, explore our ZoomInfo datasets!
Create a free Bright Data account today to try our scraper APIs or explore our datasets.

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.