

FlareSolverr is an open source tool for bypassing Cloudflare challenges and DDoS-Guard protection. It sets up a proxy server for your requests, mimics the Chrome browser to pass security checks, and displays the site content.
In this article, you’ll learn how to set up FlareSolverr and configure the tool for web scraping. You’ll also explore some options for bypassing website security challenges.
Implementing FlareSolverr
FlareSolverr offers multiple installation methods. However, using Docker is recommended for consistent implementations as it packages all the dependencies and configurations within your Docker container.
Setting Up FlareSolverr with Docker
With Docker installed on your device, download the latest FlareSolverr version, available on DockerHub, the GitHub Registry, and Community-updated repositories. The following shell command pulls the latest FlareSolverr Docker image:
docker pull 21hsmw/flaresolverr:nodriverYou can run the docker image ls command to confirm the image is available in your system:

FlareSolverr runs as a proxy server on your device, so you need to define the ports where it can be served and accessed. The following command sets 8191 as your FlareSolverr port and creates a container for the service:
docker run -d --name flaresolverr -p 8191:8191 21hsmw/flaresolverr:nodriverYou can also configure environment variables to your Docker execution. FlareSolverr offers options for logging and monitoring within the server, the time zone and language to be used, and any CAPTCHA solver mechanisms you want to use with your server. For the purpose of this tutorial, the default Docker settings are enough.
Verify that FlareSolverr is running by accessing http://localhost:8191 in your browser:

Obtaining Prerequisites
This tutorial was made for a Python environment. Apart from installing FlareSolverr and Docker, you might need to install certain Python packages, such as Beautiful Soup.
Read more about web scraping with BeautifulSoup here.
Scraping Data with FlareSolverr
Note: Always adhere to the terms of service on any website you are scraping from. Responsible use of publicly available data can be enforced with IP bans and other legal consequences.
Scraping with FlareSolverr is very similar to your regular scraping process, with your target website and request parameters going to the FlareSolverr server instead. The server spins up a browser instance with your website parameters and waits until the Cloudflare challenge is passed before sending the site content back to you. You can send requests to your FlareSolverr server through your curl executions, Python scripts, and third-party programs.
You can check that a website is Cloudflare-protected by performing lookups on its HTML code, headers, or DNS records, which would have references to Cloudflare. You can also use third-party tools, such as Check for Cloudflare:

Let’s test out the FlareSolverr process with Python. Create a Python file in your environment and copy the following script. This sample script retrieves the HTML content from a Cloudflare-protected website:
# import Requests python library
import requests
# define the payload for your request execution
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
data = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000
}
# structure the payload and make the request call
response = requests.post(url, headers=headers, json=data)
# print the request codes
print("Status:", response.json().get('status', {}))
print("Status Code:", response.status_code)
print("FlareSolverr message:", response.json().get('message', {}))
This script sends a request to your FlareSolverr server to scrape the Temu website. FlareSolverr detects a Cloudflare challenge on the target website, solves the challenge, and then sends back the HTML content and session information.
To execute your Python script, you can use the CLI command python3 <scriptname>.py:
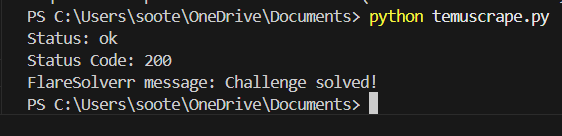
Getting a Cloudflare challenge can be dependent on your IP and the measures the website you are accessing has taken.
With the Cloudflare challenge bypassed, you can parse the HTML content normally with Beautiful Soup or other Python libraries.
Ensure the Python package is installed in your environment. You can use the pip package manager to install, with the command pip install bs4.
Let’s go through the scraping process. Start by getting the correct HTML tags for the information needed. Here’s the article title and author name:

Using that information, you can write a script to parse the data using the tags:
# import python libraries
import requests
from bs4 import BeautifulSoup
# define the payload for your request execution
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
data = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000
}
# structure the payload and make the request call
response = requests.post(url, headers=headers, json=data)
# print the request codes
print("Status:", response.json().get('status', {}))
print("Status Code:", response.status_code)
print("FlareSolverr message:", response.json().get('message', {}))
# parse logic
page_content = response.json().get('solution', {}).get('response', '')
soup = BeautifulSoup(page_content, 'html.parser')
# find the div with class 'space-y-3'
target_div = soup.find('div', class_='space-y-3')
# article author
spans = target_div.find_all('span')
span_element = spans[-1]
span_text = span_element.get_text(strip=True)
# article title
h2_element = target_div.find('h2', class_=['font-semibold', 'font-poppins'])
h2_text = h2_element.get_text(strip=True)
print(f"article author: ",span_text, " article title: ", h2_text)
This script initially bypasses the site’s Cloudflare challenge, returns the HTML content, and parses it with Beautiful Soup for the information you want.
Execute the updated Python file with the CLI command python <scriptname>.py:

FlareSolverr is a flexible tool that can be integrated into your scraping process and scaled to fit more complex use cases. For websites with geographical bans and restrictions, you can also use FlareSolverr with proxy support features. You’ll explore how that works in the next section.
Using Proxies with FlareSolverr
Utilizing proxies in your web scraping strategy improves efficiency and enables sustainable scraping. Proxies allow you to avoid geographic restrictions and IP bans and mask your web identity for better anonymity. Proxies can also directly help scale your scraping operations with concurrent requests that allow you to stay within rate limits. Depending on the quality of your proxies, your requests can better mimic real user behavior and appear legitimate to website monitors.
Based on usage and functionality, you can have mobile, residential, and datacenter proxies. A mobile proxy utilizes real IP addresses assigned by telecom companies to route your traffic through mobile carrier networks (3G, 4G, 5G). With thousands of users sharing the same IP at different times, this proxy type is hard to pin to a specific user, and they are unlikely to trigger CAPTCHA, Cloudflare, or other security challenges. However, it can be expensive and slower than other proxy categories.
The residential proxy is another proxy category that utilizes real user IPs, enabling you to better mask scraping behavior. It is also expensive, but it does not have the specific user anonymity of the mobile proxy; that is, overuse and other suspicious behavior can lead to the residential IP being blocked. It is best used to bypass geographical restrictions and monitoring. Data center proxies are cloud or data server proxies not associated with an ISP. They provide high-speed, low-latency connections at a low cost, making them best for bulk scraping needs. They are less able to simulate real-user behavior, increasing the likelihood of being blocked by website challenges and rate-limiting features.
You can add proxies to your FlareSolverr requests by specifying them in the request payload. Free public proxies are available online, but for production use cases that require reliability, managed proxy services are a better option.
The following example script attaches rotating proxies from BrightData, for your FlareSolverr requests:
import requests
import random
proxy_list = [
'185.150.85.170',
'45.154.194.148',
'104.244.83.140',
'58.97.241.46',
'103.250.82.245',
'83.229.13.167',
]
proxy_ip = random.choice(proxy_list)
proxies = {
'http': f'http://{proxy_ip}',
'https': f'https://{proxy_ip}',
}
payload = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000
}
response = requests.post(url, headers=headers, json=data, proxies=proxies)
print("Status Code:", response.status_code)
For production, you can maintain a larger proxy list and cycle through it before each request to ensure rotating proxy selections for web scraping.
Managing Sessions and Handling Cookies
Cloudflare generates and attaches cookies to user traffic within websites. This helps manage traffic and protect against repeated malicious requests without monopolizing network resources for each individual request. FlareSolverr collects and passes the cookie data within the response JSON, which can validate your subsequent requests instead of solving individual Cloudflare challenges on every request:

FlareSolverr offers session handling for better consistency across multiple requests. Once a session is created, it will retain all cookies in the browser instance until the session is destroyed. This allows for better scale and response speed over your scraping requests.
The following code demonstrates how to create sessions within your code scripts:
import requests
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
data = {
"cmd": "sessions.create",
}
response = requests.post(url, headers=headers, json=data)
print(response.text)
The command in the request payload is changed to sessions.create (instead of requests.get). The url value is not needed for this command, but you can set a proxy for the session. Check out the FlareSolverr command structure to explore other commands, such as session destroy, session list, and post requests:

Your session ID value can then be used in subsequent requests by adding it to the payload:
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
data = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000,
"session":"<SESSION_ID>"
}
response = requests.post(url, headers=headers, json=data)
print(response.text)
The timeout value is the maximum time in seconds your request will be executed. If a response is not given within that time, you will get an error response. Let’s look at the combined script of taking the session creation and using the session ID:
import requests
import time
# creating the session
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
first_request = {
"cmd": "sessions.create",
}
first_response = requests.post(url, headers=headers, json=first_request)
session_id = first_response.json().get('session', {})
# using the session id
second_request = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000,
"session":f"{session_id}"
}
second_response = requests.post(url, headers=headers, json=second_request)
print("Status:", second_response.json().get('status', {}))
You can find all the Python scripts in this GitHub repository.
You’ve now explored how to make requests with FlareSolverr and interpret responses, but it’s equally important to understand how to handle failures.
Troubleshooting Your FlareSolverr Requests
Cloudflare frequently updates its protocols, and differences in websites and use cases can lead to unexpected behavior. This section covers common errors, how FlareSolverr handles them, and what you can do to resolve issues.
To troubleshoot your scraping requests, you should always start with the following:
- FlareSolverr logs
Here are a few more specific errors and how you can address them:
- Repeated challenge/CAPTCHA failures: This may mean the site has marked your requests as suspicious. Tweak your requests and switch proxies to more closely emulate real user behavior. Cookies can also expire, so ensure you refresh regularly while maintaining your request sessions.
Challenge not detectederror: This may be due to no challenge being available, the presence of unrecognized security measures that are incompatible with FlareSolverr, the use of an outdated version of FlareSolverr, or the challenge being deliberately hidden. You might still get the desired content if a challenge isn’t detected, but if it’s not working, try updating your FlareSolverr version and retest to pinpoint the issue.Cookies Provided by FlareSolverr Are Not Validerror: This error occurs when the cookies returned by FlareSolverr fail to function correctly. It often occurs due to IP or network mismatches between Docker and FlareSolverr, especially when using VPNs.
You can always find more information online if you encounter other issues not mentioned here. There is a large open source community behind FlareSolverr, so there’s a good possibility a solution to any issues you have is already available.
FlareSolverr Alternatives
FlareSolverr is an open source tool designed for users with the technical skills to build on its foundation. However, it may not always be up-to-date with Cloudflare’s latest changes, which can affect time-sensitive operations. As of January 2026, its CAPTCHA solvers are nonfunctional, and some sites present Cloudflare challenges that it cannot bypass.
If you need a solution for large-scale scraping or more robust Cloudflare bypassing, the following alternatives offer additional features and reliability:
- Scraping Browser: A scraping browser is a GUI browser designed specifically for web scraping with features such as automated proxy rotation and built-in CAPTCHA solving. The Bright Data Scraping Browser offers easy integration with web frameworks like Playwright, Puppeteer, and Selenium, enabling programmatic workflows directly linked with an interactive browser environment at scale.
- Web Scraper APIs: Web Scraper APIs are frameworks already integrated to target domains, allowing you to collate data on demand without the manual scraping process. They are easy to use, with ready-made data structures and architecture to handle bulk data calls. The Bright Data Web Scraper APIs connect to a number of popular domains, such as LinkedIn, Zillow, Yelp, and Instagram, offering 100 percent compliant data collection.
- On-demand Datasets: With on-demand datasets, you get a managed service for ready-to-use datasets. This offers a labor-free avenue to get the data you need, already structured and formatted for your data operations. Bright Data offers a wide marketplace for various popular datasets, such as LinkedIn and Instagram profiles, Walmart and Shein products, and Booking.com listings. These datasets are maintained and updated regularly, with subscription plans for data access.
- Managed Scraping Solution: Finally, full-on managed solutions can streamline the scraping process with features to take care of most website security features such as javascript rendering, browser fingerprints, captcha, and geo-location. For example, BrightData’s Web Unlocker can unlock any domain.
Conclusion
In this article, you explored FlareSolverr and how it can bypass Cloudflare challenges. You configured FlareSolverr for multiproxy scraping and maintaining data access over the course of multiple requests. Lastly, you learned how to troubleshoot your FlareSolverr requests and the common errors you might face.
If you’re looking for a consistent and compliant data collection tool, our Scraping browser and Web Scrapers offer optimized tools for your scraping processes. You get managed services with reliable proxies, an intuitive user interface, and close to 100 percent web scraping success rates.
Sign up now and start your free trial!





