
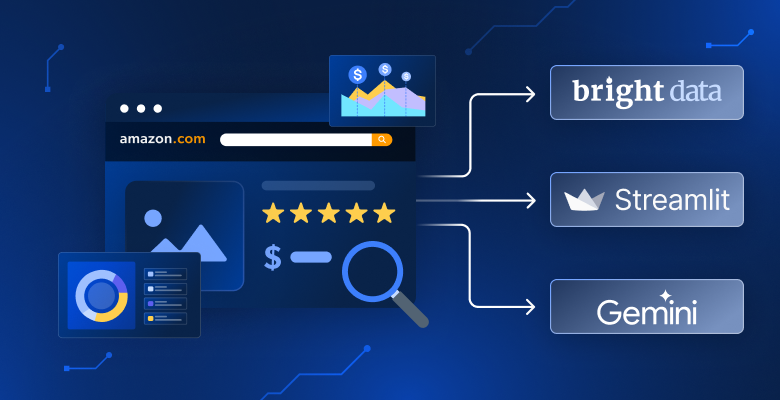
Tired of manually comparing products on Amazon? Want to ask AI questions about your search results? Need better insights than just sorting by price or rating? In this tutorial, you’ll build an Amazon product analyzer that searches any of 23 Amazon marketplaces, analyzes the results with AI, and presents insights through interactive dashboards.
What you’ll build
By the end of this guide, you’ll have a functional web app that fetches Amazon product data and organizes it into an easy-to-browse dashboard with AI-powered insights.
Core features and user workflow
Here’s how it works:
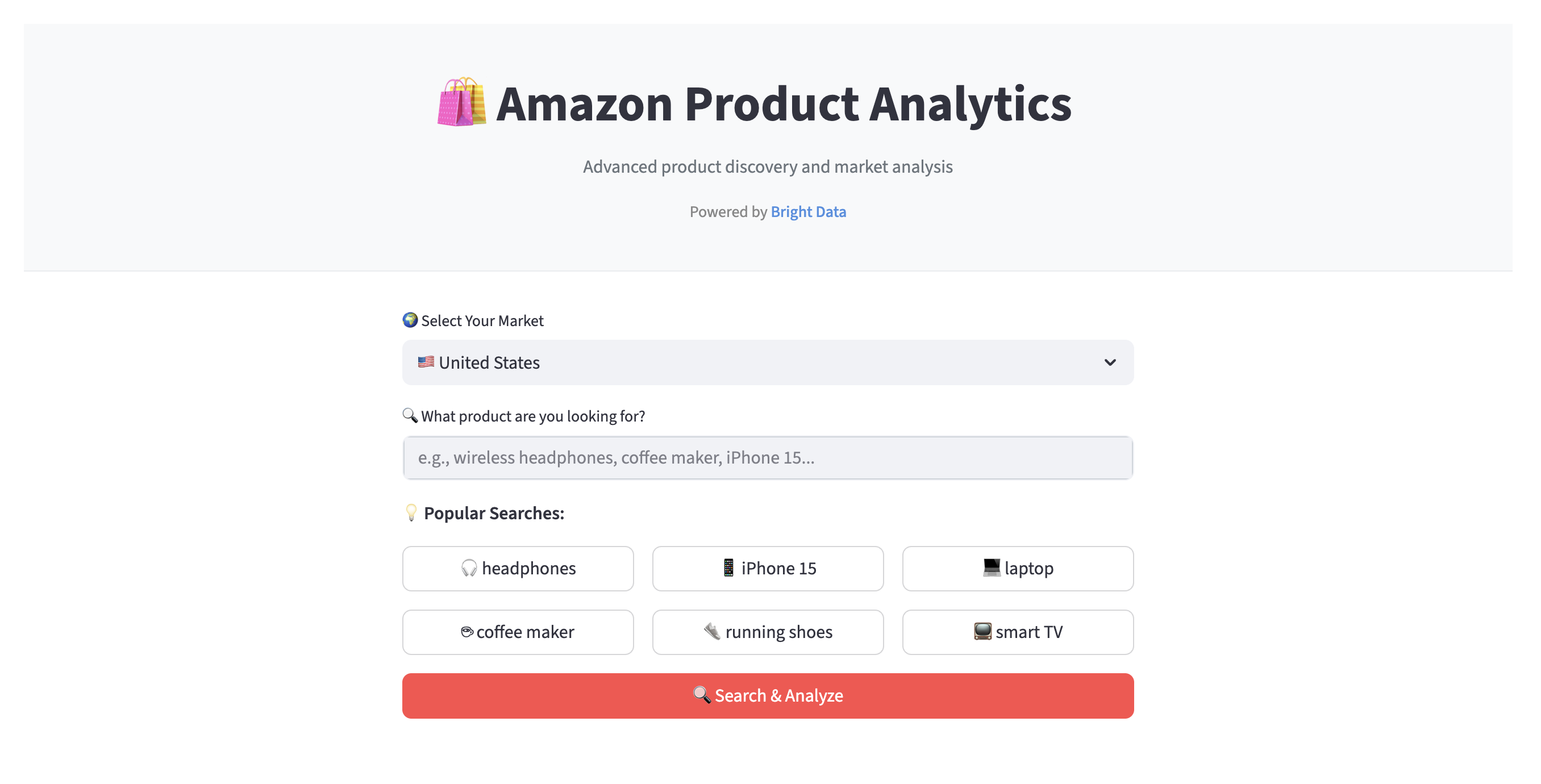
- Search and data collection. Select one of 23 Amazon marketplaces (United States, Germany, Japan, etc.) and enter a product keyword like “wireless headphones”. The app uses Bright Data’s Web Scraper API to collect product information.
- Organized results display. Data is presented through a clean, tab-based interface:
- Recommendations. View products ranked by a custom scoring algorithm (combines rating, review count, and discounts) with 3 categories: “Best Overall Value”, “Highest Rated”, and “Best Deals”.
- Market analysis. Explore interactive charts showing price distributions and rating patterns to understand the product landscape.
- AI assistant. Ask questions in plain English, like “Which products have the highest ratings under $100?”. The AI analyzes your current search results and provides answers with product citations.
- Product results. Browse, sort, and export the complete dataset to CSV for further analysis.
Now that we’ve seen what the app does, let’s look at the technologies that make it possible.
The technology stack and project architecture
Our app uses a modern, Python-based stack, with each component chosen for its specific strengths in data handling, AI, and web development.
| Component | Technology | Purpose |
|---|---|---|
| Data source | Bright Data Amazon Scraper API | Reliable, enterprise-scale Amazon data collection without the hassle of managing proxies or solving CAPTCHAs. |
| Frontend | Streamlit | Rapidly build an interactive and beautiful web dashboard using only Python. |
| AI integration | Google Gemini | Natural-language insights, data summarization, and AI assistant functionality. |
| Data processing | Pandas | The cornerstone for all data cleaning, transformation, and analysis. |
| Mathematical operations | NumPy | Value scoring algorithms and statistical computations. |
| Visualizations | Plotly | Rich, interactive charts and graphs that users can explore. |
| HTTP(S) & retries | Requests + Tenacity | Robust and resilient communication with external APIs. |
Project architecture
The project is organized into a modular structure to ensure clean separation of concerns, making the code easier to maintain and extend.
├── streamlit_app.py # Main Streamlit application entry point
├── requirements.txt # Project dependencies
├── .env # API keys and environment variables (private)
└── amazon_analytics/ # Core application logic module
├── __init__.py # Package initialization
├── api.py # Bright Data API integration
├── data_processor.py # Data cleaning, normalization, and feature engineering
├── shopping_intelligence.py # Product recommendation and scoring engine
├── gemini_ai_engine.py # AI analysis and prompt engineering with Gemini
├── ai_engine_interface.py # Abstract AI engine interface
├── ai_response.py # Standardized AI response objects
└── config.py # Configuration managementWith the architecture clear, let’s get your development environment ready.
Prerequisites
Before we start coding, make sure you have the following ready:
- Python 3.8+. If you don’t have it installed, download it from the official Python website.
- A Bright Data account. You’ll need an API key to access the Amazon Scraper API. Sign up for free to get started and generate your API key.
- A Google API key. This is required for using the Gemini AI model. You can generate one from the Google AI Studio.
- Basic knowledge. Familiarity with Python, Pandas, and the concept of web APIs will be helpful.
Once you have these, we can proceed with setting up the project.
Step 1 – setting up your development environment
First, let’s clone the project repository, create a virtual environment to isolate our dependencies, and install the required packages.
Installation
Open your terminal and run the following commands:
# Clone the repository
git clone https://github.com/triposat/amazon-product-analytics.git
cd amazon-product-analytics
# Create and activate a virtual environment
python -m venv venv
source venv/bin/activate # On Windows use: venv\Scripts\activate
# Install the required libraries
pip install -r requirements.txtAPI key configuration
Next, create a .env file in the root directory of the project to securely store your API keys.
# Create the .env file
touch .envNow, open the .env file in a text editor and add your keys:
BRIGHT_DATA_TOKEN=your_bright_data_token_here
GOOGLE_API_KEY=your_google_api_key_hereYour environment is now fully configured. Let’s dive into the core logic, starting with data collection.
Step 2 – scraping Amazon product data with Bright Data
The foundation of our app is high-quality data. Manually scraping a site like Amazon is complex – you have to manage proxies, handle different page layouts, and find ways to bypass Amazon’s CAPTCHAs and blocking mechanisms.
Bright Data’s Amazon Web Scraper API abstracts all this complexity away. It provides:
- Enterprise-grade reliability. Built on a network of over 150M ethically-sourced residential proxy IPs across 195 countries, ensuring consistent and uninterrupted access.
- Zero infrastructure hassle. Automatic IP rotation, CAPTCHA solving, and proxy management are handled for you behind the scenes.
- Comprehensive structured data. Delivers clean, structured JSON data with 20+ data points per product, including ASIN, prices, ratings, reviews, seller information, product descriptions, images, availability, and much more.
- Cost-effective pricing. Pay-as-you-go model starting from $0.001 per record, making it scalable for projects of any size.
API integration (api.py)
Our BrightDataAPI class in api.py handles all interactions with the API. It uses a trigger-poll-download workflow, which is ideal for handling potentially long-running scraping jobs.
The trigger_search method initiates the scraping job. Notice the use of the @retry decorator from the tenacity library – this adds resilience by automatically retrying the request with exponential backoff if it fails.
# amazon_analytics/api.py
class BrightDataAPI:
def __init__(self, token: Optional[str] = None):
self.token = token or BRIGHT_DATA_TOKEN
self.base_url = "https://api.brightdata.com/datasets/v3"
self.headers = {
"Authorization": f"Bearer {self.token}",
"Content-Type": "application/json"
}
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10),
retry=retry_if_exception_type((requests.RequestException, BrightDataAPIError))
)
def trigger_search(self, keyword: str, amazon_url: str, pages_to_search: str = "") -> str:
"""Triggers a new scraping job and returns the snapshot ID."""
payload = [{
"keyword": keyword,
"url": amazon_url,
"pages_to_search": pages_to_search
}]
response = requests.post(
f"{self.base_url}/trigger",
headers=self.headers,
json=payload,
params={
"dataset_id": BRIGHT_DATA_DATASET_ID,
"include_errors": "true",
"limit_multiple_results": "150"
},
timeout=30
)
response.raise_for_status()
return response.json()["snapshot_id"]After triggering a search, the wait_for_results method polls the API until the job is complete and then downloads the data. This prevents the app from hanging while waiting and includes a timeout to avoid infinite loops.
With reliable data collection in place, the next step is to clean and enrich this raw data.
Step 3 – building the data processing pipeline
Raw data from any source is rarely in the perfect format for analysis. Our DataProcessor class in data_processor.py is responsible for cleaning, normalizing, and engineering new features from the scraped Amazon data, making it ready for our AI and visualization layers. For a broader look at data processing, see our guide on data analysis with Python.
Intelligent price parsing
A significant challenge in eCommerce data is handling international formats. For example, a price in Germany might be “1.234,56” while in the US it’s “1,234.56”. The parse_float_locale function intelligently handles these variations.
# amazon_analytics/data_processor.py (simplified for readability)
def parse_float_locale(self, value: Any) -> Optional[float]:
"""Robust float parser handling international number formats."""
if value is None or value == "":
return None
if isinstance(value, (int, float)):
return float(value)
if isinstance(value, str):
s = re.sub(r"[^0-9.,]", "", value)
has_comma = "," in s
has_dot = "." in s
if has_comma and has_dot:
# Determine decimal separator by last position
if s.rfind(',') > s.rfind('.'):
s = s.replace('.', '').replace(',', '.') # European format
else:
s = s.replace(',', '') # US format
elif has_comma:
# Check if comma is thousands separator or decimal
if re.search(r",\d{3}$", s):
s = s.replace(',', '') # Thousands separator
else:
s = s.replace(',', '.') # Decimal separator
return float(s)
return NoneCustom value scoring algorithm
To help users quickly identify the best products, we created a custom value_score. This composite metric combines multiple factors into a single, easy-to-understand score.
# amazon_analytics/data_processor.py
def compute_value_score(
self,
rating: Optional[float],
num_ratings: Optional[int],
discount_pct: Optional[float],
min_reviews: int = 10
) -> float:
"""Computes a composite value score based on quality, social proof, and deal value."""
score = 0.0
# 40% weight for product quality (rating)
if rating and rating > 0:
score += (rating / 5.0) * 0.4
# 30% weight for social proof (number of ratings)
if num_ratings and num_ratings >= min_reviews:
# Logarithmic scale to prevent mega-popular items from dominating
review_score = min(math.log10(num_ratings) / 4, 1.0)
score += review_score * 0.3
# 30% weight for deal value (discount percentage)
if discount_pct and discount_pct > 0:
discount_score = min(discount_pct / 50, 1.0) # Cap at 50% discount
score += discount_score * 0.3
return round(score, 2)This algorithm balances quality (rating), social proof (review volume), and deal value (discount) to provide a holistic measure of a product’s appeal.
Now that our data is clean and enriched, we can feed it to our AI engine for deeper insights.
Step 4 – integrating AI for smart analysis with Gemini
This is where our app becomes truly intelligent. We use Google’s Gemini AI to analyze the processed data and answer user questions. A major challenge with LLMs is hallucination – inventing facts not present in the source data. Our GeminiAIEngine is designed to prevent this.
# amazon_analytics/gemini_ai_engine.py (significantly simplified for tutorial clarity)
def _create_anti_hallucination_prompt(self, user_query: str, df: pd.DataFrame) -> str:
"""Creates a hallucination-proof prompt by including all data context."""
# Note: The actual implementation includes detailed field mapping,
# type conversion, and NaN handling for 20+ product attributes
products_data = []
for _, row in df.iterrows():
product = {
'name': str(row.get('name', 'N/A')),
'asin': str(row.get('asin', 'N/A')),
'final_price': float(row.get('final_price', 0)) if pd.notna(row.get('final_price')) else 0,
'rating': float(row.get('rating', 0)) if pd.notna(row.get('rating')) else 0,
'num_ratings': int(row.get('num_ratings', 0)) if pd.notna(row.get('num_ratings')) else 0,
# ... additional fields with proper type handling
}
products_data.append(product)
return f"""You are an expert Amazon product analyst with advanced reasoning capabilities.
ZERO HALLUCINATION RULES:
1. NEVER make up or invent ANY product information
2. ONLY use data explicitly provided below
3. If information is missing, clearly state "This information is not available"
4. Always cite specific product ASINs for verification
5. Use your reasoning to provide valuable insights based on the actual data
REASONING CAPABILITIES:
- Compare products by analyzing price, ratings, reviews, and features
- Identify best value products by considering price vs rating relationship
- Assess product trust by evaluating rating quality and review volume
- Detect deals by comparing initial_price vs final_price
USER QUERY: {user_query}
AVAILABLE PRODUCT DATA ({len(df)} products):
{json.dumps(products_data, indent=2)}
Use your reasoning to analyze this data and provide helpful, accurate insights. Include specific ASINs and numbers for verification."""Key anti-hallucination techniques:
- Complete data inclusion. All product information is provided to the AI, leaving no gaps for speculation.
- Explicit boundaries. Clear rules about what the AI can and cannot do.
- ASIN citations. Forces the AI to reference specific products for verification.
- Structured data format. JSON format makes data parsing reliable for the AI.
This prompt engineering approach transforms the AI into a reliable data analyst, making its output trustworthy and verifiable.
With the AI engine ready, we can build the recommendation system.
Step 5 – creating the shopping intelligence engine
The ShoppingIntelligenceEngine in shopping_intelligence.py uses the processed data to generate 3 main recommendations: “Best Overall Value”, “Highest Rated”, and “Best Deal”. The engine applies sophisticated filtering criteria to ensure quality recommendations.
The system works with a list of product dictionaries and uses separate helper methods for each recommendation category, each with specific quality thresholds.
# amazon_analytics/shopping_intelligence.py
class ShoppingIntelligenceEngine:
def analyze_products(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Generate shopping intelligence from product data."""
if not products:
return {'total_items': 0, 'top_picks': []}
top_picks = self._generate_top_picks(products)
return {
'total_items': len(products),
'top_picks': top_picks
}
def _generate_top_picks(self, products: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""Generate top product recommendations with reasoning."""
try:
# First, filter for valid products only
valid_products = []
for product in products:
rating = product.get('rating')
price = product.get('final_price')
if rating is not None and price is not None and rating > 0 and price > 0:
valid_products.append(product)
if not valid_products:
return []
picks = []
used_asins = set()
# Find each category using specialized methods
best_value = self._find_best_value(valid_products)
if best_value and best_value.get('asin') not in used_asins:
picks.append({
'product': best_value,
'reason': 'Best Overall Value',
'explanation': 'Excellent balance of quality, price, and customer reviews'
})
used_asins.add(best_value['asin'])
highest_rated = self._find_highest_rated(valid_products)
if highest_rated and highest_rated.get('asin') not in used_asins:
picks.append({
'product': highest_rated,
'reason': 'Highest Rated',
'explanation': 'Top customer satisfaction with proven track record'
})
used_asins.add(highest_rated['asin'])
best_deal = self._find_best_deal(valid_products)
if best_deal and best_deal.get('asin') not in used_asins:
picks.append({
'product': best_deal,
'reason': 'Best Deal',
'explanation': 'Great value with significant savings and good quality'
})
used_asins.add(best_deal['asin'])
# Fill remaining slots with quality products if needed
if len(picks) < 3:
remaining_products = [p for p in valid_products if p.get('asin') not in used_asins]
remaining_products.sort(key=lambda x: x.get('value_score', 0), reverse=True)
for product in remaining_products[:3-len(picks)]:
picks.append({
'product': product,
'reason': 'Quality Choice',
'explanation': 'Good balance of quality and value'
})
return picks[:3]
except Exception:
return []Quality filtering methods
Each recommendation category has specific quality thresholds to ensure reliable recommendations:
def _find_best_value(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Find product with best value score - requires 10+ reviews."""
candidates = [p for p in products if
p.get('value_score') is not None and
p.get('num_ratings', 0) >= 10]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('value_score', 0))
def _find_highest_rated(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Find highest rated product - requires 4.0+ rating and 50+ reviews."""
candidates = [p for p in products if
p.get('rating', 0) >= 4.0 and
p.get('num_ratings', 0) >= 50]
if not candidates:
return None
return max(candidates, key=lambda p: (p.get('rating', 0), p.get('num_ratings', 0)))
def _find_best_deal(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Find best discount - requires 10%+ discount and 3.5+ rating."""
candidates = [p for p in products if
p.get('discount_pct') is not None and
p.get('discount_pct', 0) >= 10 and
p.get('rating', 0) >= 3.5]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('discount_pct', 0))Key design decisions:
- Quality thresholds. Each category has minimum standards to prevent recommending poor products.
- No duplicates.
used_asinsset ensures each product appears only once. - Fallback logic. If fewer than 3 recommendations found, fills with next-best value scores.
- Error handling. Try/catch prevents crashes on malformed data.
This approach ensures users get reliable, high-quality recommendations rather than just the first products found.
Now we have all the backend components. Let’s build the user interface to bring it all together.
Step 6 – designing the interactive dashboard with Streamlit
The final piece is the user interface, handled by streamlit_app.py. Streamlit allows you to build a reactive, web-based dashboard with minimal code. The app uses a sophisticated tab-based layout with real-time progress tracking and multiple chart types.
Session state and component caching
The app uses specific session state variables to manage data flow and caches backend components for performance:
# streamlit_app.py - Session state initialization
if 'search_results' not in st.session_state:
st.session_state.search_results = []
if 'shopping_intelligence' not in st.session_state:
st.session_state.shopping_intelligence = {}
if 'current_run_id' not in st.session_state:
st.session_state.current_run_id = None
@st.cache_resource
def get_backend_components():
"""Initialize and cache backend components."""
api = BrightDataAPI()
processor = DataProcessor()
intelligence = ShoppingIntelligenceEngine()
ai_engine = get_gemini_ai()
return api, processor, intelligence, ai_engineInline search processing with progress tracking
The search logic is embedded directly in the main app flow with detailed progress tracking and data persistence:
# streamlit_app.py - Search processing (simplified)
# Search execution with progress tracking
if search_clicked and keyword.strip():
progress_bar = st.progress(0)
status_text = st.empty()
start_time = time.time()
try:
# Trigger search
status_text.text("Starting Amazon search...")
snapshot_id = api.trigger_search(keyword, amazon_url)
progress_bar.progress(25)
# Wait for results with smart progress updates
status_text.text("Amazon is processing your search...")
results = smart_wait_for_results(api, snapshot_id, progress_bar, status_text)
progress_bar.progress(75)
# Process results
status_text.text("Analyzing products...")
processed_results = processor.process_raw_data(results)
shopping_intel = intelligence.analyze_products(processed_results)
# Store comprehensive results in session state
st.session_state.search_results = processed_results
st.session_state.shopping_intelligence = shopping_intel
st.session_state.current_run_id = str(uuid.uuid4())
st.session_state.raw_data = results
st.session_state.search_metadata = {
'keyword': keyword,
'country': countries[selected_country],
'domain': amazon_url,
'timestamp': datetime.now(timezone.utc).isoformat()
}
elapsed_time = time.time() - start_time
status_text.text(f"Found {len(processed_results)} products in {elapsed_time:.1f}s!")
progress_bar.progress(100)
except Exception as e:
st.error(f"Search failed: {str(e)}")Multiple interactive visualizations
The Market Analysis tab creates various chart types inline, each with specific styling and annotations:
# streamlit_app.py - Price distribution with median line
fig_price = px.histogram(
x=display_prices,
nbins=min(20, max(1, unique_prices)),
title="Price Range",
labels={'x': f'Price ({currencies.get(current_country_code, "USD")})', 'y': 'Number of Products'},
color_discrete_sequence=['#667eea']
)
# Add median line for context
fig_price.add_vline(x=q50, line_dash="dash", line_color="orange", annotation_text="Median")
st.plotly_chart(fig_price, use_container_width=True)
# Rating vs Price scatter with size and color encoding
fig_scatter = px.scatter(
df_scatter,
x='final_price',
y='rating',
size='num_ratings',
hover_data=['name', 'num_ratings'],
title="Quality vs Price",
labels={'final_price': f'Price ({currencies.get(current_country_code, "USD")})', 'rating': 'Rating (Stars)'},
color='rating',
color_continuous_scale='Viridis'
)
st.plotly_chart(fig_scatter, use_container_width=True)
# Value score distribution with percentile markers
fig_value = px.histogram(
x=value_scores,
nbins=20,
title="Best Value Products",
labels={'x': 'Value Score (0.0-1.0)', 'y': 'Number of Products'},
color_discrete_sequence=['#28a745']
)
p50 = np.percentile(value_scores, 50)
p75 = np.percentile(value_scores, 75)
fig_value.add_vline(x=p50, line_dash="dash", line_color="orange", annotation_text="Median")
fig_value.add_vline(x=p75, line_dash="dash", line_color="red", annotation_text="75th %ile")
st.plotly_chart(fig_value, use_container_width=True)Advanced chart features
The dashboard includes sophisticated visualizations with business intelligence:
- Price histograms. With median and quartile markers for market positioning.
- Rating scatter plots. Size represents review volume, color shows rating quality.
- Position pie charts. Shows search ranking distribution (1-5, 6-10, 11-20, 21+).
- Price category bar charts. Segments products into Budget/Value/Premium/Luxury tiers.
- Discount analysis. Identifies genuine deals vs. inflated pricing.
This comprehensive approach creates a professional analytics dashboard that provides actionable market insights.
Conclusion
You’ve successfully built an Amazon product analyzer that leverages enterprise-grade data collection, advanced AI, and interactive data visualization. The complete source code for this project is available for you to explore and adapt on GitHub.
You’ve seen how to:
- Use Bright Data’s Web Scraper API to reliably scrape Amazon data at scale.
- Implement a robust data processing pipeline to handle complex, real-world data challenges.
- Engineer a hallucination-proof AI assistant with Google Gemini for trustworthy analysis.
- Build an intuitive and interactive user interface with Streamlit and Plotly.
This project serves as a powerful template for any app that requires turning vast amounts of web data into actionable business intelligence. From here, you could extend it to build a dedicated Amazon price tracker or integrate other data sources.
The world of eCommerce data is vast. If you need pre-collected, ready-to-use datasets, explore Bright Data’s marketplace for a wide range of options.

Technical Writer
Satyam Tripathi helps SaaS and data startups turn complex tech into actionable content, boosting developer adoption and user understanding.





